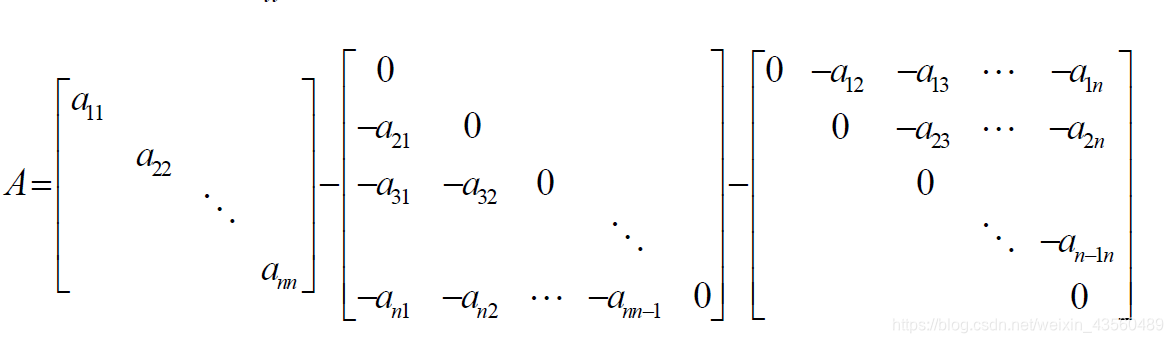对于熟悉直接法的人而言,可以发现这种方法的求解过程在计算机下编程实际是较为复杂的,例如:高斯消去法常规的求解过程就要求先构建增广矩阵,而后做初等行变换消元将系数矩阵化为一个上三角矩阵,然后再回代求解出解向量
X
X
X,并且从计算量而言也是较为复杂的,尽管之后变形出了例如三角分解(LU分解)这样的变形解法,但从编程的角度考虑依然是不直观的。 而迭代法,其基本思想是将线性方程组转化为便于迭代的等价方程组,然后基于初始
X
X
X值即
X
=
x
i
(
0
)
=
0
(
i
=
1
,
2
,
3
,
.
.
.
n
)
X = x_{i}^{(0)} = 0 (i = 1,2,3,...n)
X=xi(0)=0(i=1,2,3,...n),然后按照一定的计算规则,不断地修正得到新的解
X
X
X,最终得到满足精度要求的方程组的近似解。这显然是更加直观且易于编程设计的一种方法。而这其中就有三种最常见的迭代方式,即:
雅克比(Jacobi)迭代
高斯-塞德尔(Gauss-Seidel)迭代
超松弛(SOR)迭代
二、解线性方程组的迭代法及其代码实现
1. 迭代法的收敛性
在直接引入三种迭代法及其MATLAB实现之前,需要先提到一点就是迭代法的收敛性,简单的理解其实就是迭代法并不适用于所有线性方程组,即对于一类方程组迭代时会收敛,近似解会不断逼近精确解,但是对于另外一类方程组则会发散,近似解不断远离精确解。而决定迭代法是否收敛,是否可用于该方程组,主要需要考虑的其实就是系数矩阵
A
A
A。这里直接给出使上述三种迭代法收敛的充分条件:系数矩阵
A
A
A按行(或列)严格对角占优或满足弱对角占优不可约。
基本参数:矩阵阶数,计算误差,最大迭代次数。其中计算误差和最大迭代次数是迭代终止的判断要求,达到精度或者迭代到最大次数时停止迭代并输出结果。此处对计算误差进行说明,当计算精度满足
m
a
x
1
⩽
i
⩽
n
∣
x
i
(
k
+
1
)
−
x
i
(
k
)
∣
<
e
p
s
\mathop{max}\limits_{1\leqslant i\leqslant n}\left | x_{i}^{(k+1)} - x_{i}^{(k)}\right | < eps
1⩽i⩽nmax∣∣∣xi(k+1)−xi(k)∣∣∣<eps 时结束迭代。
雅克比迭代实际是将系数矩阵A分解为了三个矩阵的组合,如下图 将其记做
A
=
D
−
L
−
U
A = D-L-U
A=D−L−U,则原方程组
A
X
=
b
AX=b
AX=b 等价于
(
D
−
L
−
U
)
X
=
b
(D-L-U)X = b
(D−L−U)X=b,即
D
X
=
(
L
+
U
)
X
+
b
DX = (L+U)X+b
DX=(L+U)X+b 因为
a
i
i
≠
0
(
i
=
1
,
2
,
.
.
.
n
)
a_{ii}\neq 0 (i = 1,2,...n)
aii=0(i=1,2,...n),故
X
=
D
−
1
(
L
+
U
)
X
+
D
−
1
b
X = D^{-1}(L+U)X+D^{-1}b
X=D−1(L+U)X+D−1b 由此便可以得到一个迭代公式
X
(
k
+
1
)
=
D
−
1
(
L
+
U
)
X
(
k
)
+
D
−
1
b
X^{(k+1)}=D^{-1}(L+U)X^{(k)}+D^{-1}b
X(k+1)=D−1(L+U)X(k)+D−1b 令
B
=
D
−
1
(
L
+
U
)
B = D^{-1}(L+U)
B=D−1(L+U),
f
=
D
−
1
b
f = D^{-1}b
f=D−1b,即可得到雅克比迭代公式
X
(
k
+
1
)
=
B
X
(
k
)
+
f
X^{(k+1)}=BX^{(k)}+f
X(k+1)=BX(k)+f 写成便于编程理解的形式即:
X
i
(
k
+
1
)
=
1
a
i
i
(
b
i
−
∑
j
=
1
j
≠
i
n
a
i
j
X
j
(
k
)
)
X_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i} - \sum\limits_{\mathop{j=1}\limits_{j\neq i}}^{n}a_{ij}X_{j}^{(k)})
Xi(k+1)=aii1(bi−j=ij=1∑naijXj(k)) 代码:
在雅克比迭代中,我们可以看出,每一次迭代得到的新的解向量
X
(
k
+
1
)
X^{(k+1)}
X(k+1)中的每一个元素均是由上一个解向量
X
(
k
)
X^{(k)}
X(k)的所有元素计算得出,但实际上计算新的解向量
X
(
k
+
1
)
X^{(k+1)}
X(k+1)的一个元素时,其前面的元素实际已经计算得出了,所以高斯-塞德尔(Gauss-Seidel)迭代的核心思想即:将本次迭代中前面已经计算出来的元素加入到迭代公式中,替代掉相对应的上一个解向量中的元素,从而实现加速收敛。
高斯-塞德尔(Gauss-Seidel)迭代迭代公式可以写作
X
i
(
k
+
1
)
=
1
a
i
i
(
b
i
−
∑
j
=
1
i
−
1
a
i
j
X
j
(
k
+
1
)
−
∑
j
=
i
+
1
n
a
i
j
X
j
(
k
)
)
X_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i} - \sum\limits_{j = 1}^{i - 1}a_{ij}X_{j}^{(k+1)} - \sum\limits_{\mathop{j=i+1}}^{n}a_{ij}X_{j}^{(k)})
Xi(k+1)=aii1(bi−j=1∑i−1aijXj(k+1)−j=i+1∑naijXj(k)) 代码:
用高斯-塞德尔迭代公式定义一个辅助量
X
~
i
(
k
+
1
)
=
1
a
i
i
(
b
i
−
∑
j
=
1
i
−
1
a
i
j
X
j
(
k
+
1
)
−
∑
j
=
i
+
1
n
a
i
j
X
j
(
k
)
)
\widetilde{X}_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i} - \sum\limits_{j = 1}^{i - 1}a_{ij}X_{j}^{(k+1)} - \sum\limits_{\mathop{j=i+1}}^{n}a_{ij}X_{j}^{(k)})
Xi(k+1)=aii1(bi−j=1∑i−1aijXj(k+1)−j=i+1∑naijXj(k))
将
X
i
(
k
+
1
)
X_{i}^{(k+1)}
Xi(k+1)取做
X
~
i
(
k
+
1
)
\widetilde{X}_{i}^{(k+1)}
Xi(k+1)与
X
i
(
k
)
X_{i}^{(k)}
Xi(k)的加权平均
X
i
(
k
+
1
)
=
(
1
−
ω
)
X
i
(
k
)
+
ω
X
~
i
(
k
+
1
)
X_{i}^{(k+1)}=(1-\omega )X_{i}^{(k)} + \omega\widetilde{X}_{i}^{(k+1)}
Xi(k+1)=(1−ω)Xi(k)+ωXi(k+1) 即
X
i
(
k
+
1
)
=
(
1
−
ω
)
X
i
(
k
)
+
ω
a
i
i
(
b
i
−
∑
j
=
1
i
−
1
a
i
j
X
j
(
k
+
1
)
−
∑
j
=
i
+
1
n
a
i
j
X
j
(
k
)
)
X_{i}^{(k+1)}=(1-\omega )X_{i}^{(k)} + \frac{\omega}{a_{ii}}(b_{i} - \sum\limits_{j = 1}^{i - 1}a_{ij}X_{j}^{(k+1)} - \sum\limits_{\mathop{j=i+1}}^{n}a_{ij}X_{j}^{(k)})
Xi(k+1)=(1−ω)Xi(k)+aiiω(bi−j=1∑i−1aijXj(k+1)−j=i+1∑naijXj(k)) 式中的系数
ω
\omega
ω被称为松弛因子,当
ω
=
1
\omega = 1
ω=1时即为高斯-塞德尔迭代,为了保证迭代过程收敛,要求
0
<
ω
<
2
0 < \omega<2
0<ω<2 当
0
<
ω
<
1
0 < \omega<1
0<ω<1时,是低松弛法; 当
1
<
ω
<
2
1 < \omega<2
1<ω<2时,是超松弛法;
从结果上来看,对于所设置的系数矩阵A,要满足小数点后6位的精度要求,雅克比迭代法迭代次数39次;高斯赛德尔迭代法迭代次数22次;松弛因子为1.3时的SOR超松弛迭代法迭代12次。可见SOR迭代法是三种迭代法中收敛最快的。 除此之外,在测试SOR超松弛迭代法时还发现尽管其作为一种高斯赛德尔迭代法的加速,但有时,对于某些矩阵而言,松弛因子
w
>
1
w>1
w>1反而会有反作用,此时使用
w
=
1
w=1
w=1(即高斯赛德尔迭代法)效果会更好,个人认为关于
w
w
w的取值值得思考和探究。