spark sql 创建rdd以及DataFrame和DataSet互转
仓库地址:https://gitee.com/jyq_18792721831/sparkmaven.git
使用SparkSession读取本地文件创建rdd
学习的最准确的资料一定是官方文档,所以我们根据官方文档进行学习RDD的使用RDD Programming Guide - Spark 3.2.1 Documentation (apache.org)
import org.apache.spark.sql.SparkSession
object SparkRddApp {
def main(args: Array[String]): Unit = {
// 1. 创建SparkSession
val sparkSession = SparkSession builder() master("local") appName("SparRddApp") getOrCreate()
// 2. 读取本地文件,获取rdd
val columnRdd = sparkSession.sparkContext.textFile("E:\\java\\sparkmaven\\data\\COLUMNS.csv")
// 3. 打印信息
columnRdd take(5) foreach println
// 4. 统计总数
println(columnRdd count)
// 5. 打印单元格数量
println(columnRdd
flatMap(_.split(",")) // 每行按照 , 分割,并进行扁平化处理
map(_.replaceAll("\"", "")) // 去除单元格的引号
count()) // 计数
// 打印去重的单元格数量
println(columnRdd
flatMap(_.split(",")) // 每行按照 , 分割,并进行扁平化处理
map(_.replaceAll("\"", "")) // 去除单元格的引号
distinct() // 去重
count()) // 计数
// 6. 获取第4列
println(columnRdd
// 每行按照 , 分割,将 String 转为数组
map(_.split(","))
// 过滤数组中元素个数少于 4 个的数组
filter(_.size >= 4)
// 将数组转为元素,只获取第 4 个
map(_(3))
// 去除元素中的双引号
map(_.replaceAll("\"",""))
// 提取全部数据中的 10 条数据
take(10)
// 将提取的10条数据按照 , 进行连接
reduce(_+","+_))
// 7. 第5列进行分组统计
(columnRdd
// 每行按照 , 分割,将 String 转为数组
map(_.split(","))
// 过滤数组中元素个数少于 5 个的数组
filter(_.size >= 5)
// 将数组转为元素,只获取第 5 个
map(_(4))
// 去除元素中的双引号
map(_.replaceAll("\"",""))
// 将元素转为数字
map(_.toInt)
// 将单个元素转为二元组
map(_->1)
// 按照二元组的key进行排序
sortByKey()
// 根据二元组的key进行汇总,值进行求和
reduceByKey(_+_)
// 打印
foreach println)
// 8. 关闭sparkSession
sparkSession close()
}
}
使用ide的一个优点是ide会把推断出来的类型进行展示,比如

需要注意的是,如果你在一行中有多个操作,那么推断的是最后一个操作的类型,如果是Unit类型,则不进行展示
这里告诉大家一个小技巧,如果我们的操作没有用括弧进行包含,而且是类似我这种喜欢省略 . 的调用,那么是不能换行的,这样一行就比较长,我们可以使用小括弧进行包起来,这样中间就可以换行了,比如下面这个例子
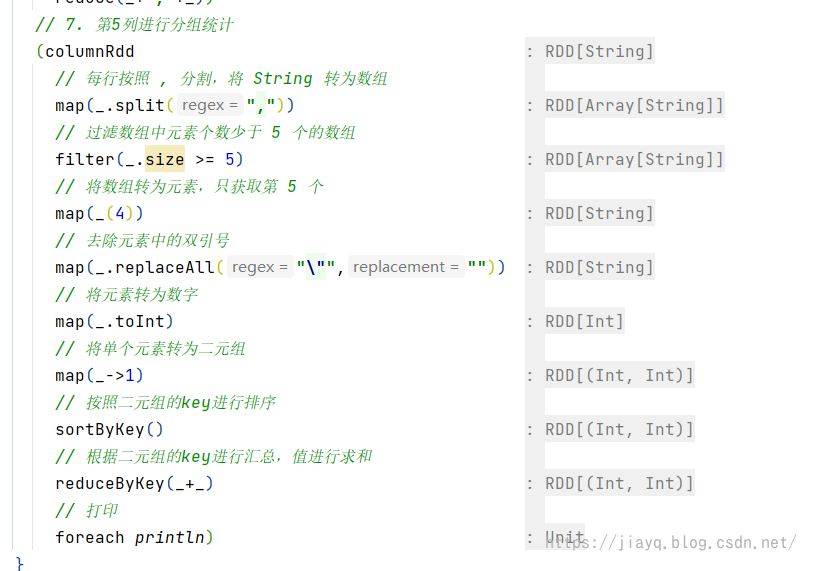
本来这应该放在一行中写完,但是这样在写的时候,ide无法帮助我们推断类型,写起来就比较费力,而我们用小括弧包起来,并每一个操作进行换行的话,ide就会在后面展示推断出来的类型的,这样对我们比较友好。
更多的RDD的操作可以参考这两篇文章
spark–RDD_a18792721831的博客-CSDN博客
spark–键值对操作_a18792721831的博客-CSDN博客
DateSet的介绍
今天的主角不是RDD,而是DataSet。在官网中,对DataSet的定义如下
A Dataset is a distributed collection of data. Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine.
DataSet是一个分布式的数据集合,是在spark 1.6 中引入的,DataSet提供了RDD的优点(强类型,lambda函数)以及 spark sql的优化。
虽然如此,但是DataSet到底是什么?
首先我们在根项目的pom.xml文件目录执行maven命令下载api文档和源码
下载api文档命令mvn dependency:resolve -Dclassifier=javadoc

下载源码命令mvn dependency:sources
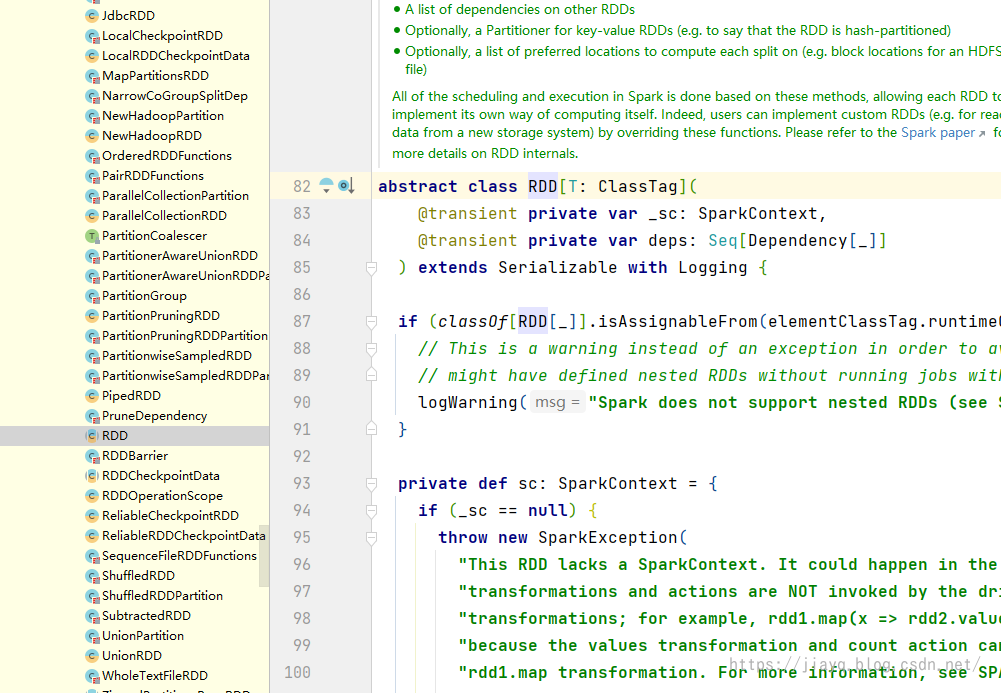
接着我们就可以查看DataSet的源码了
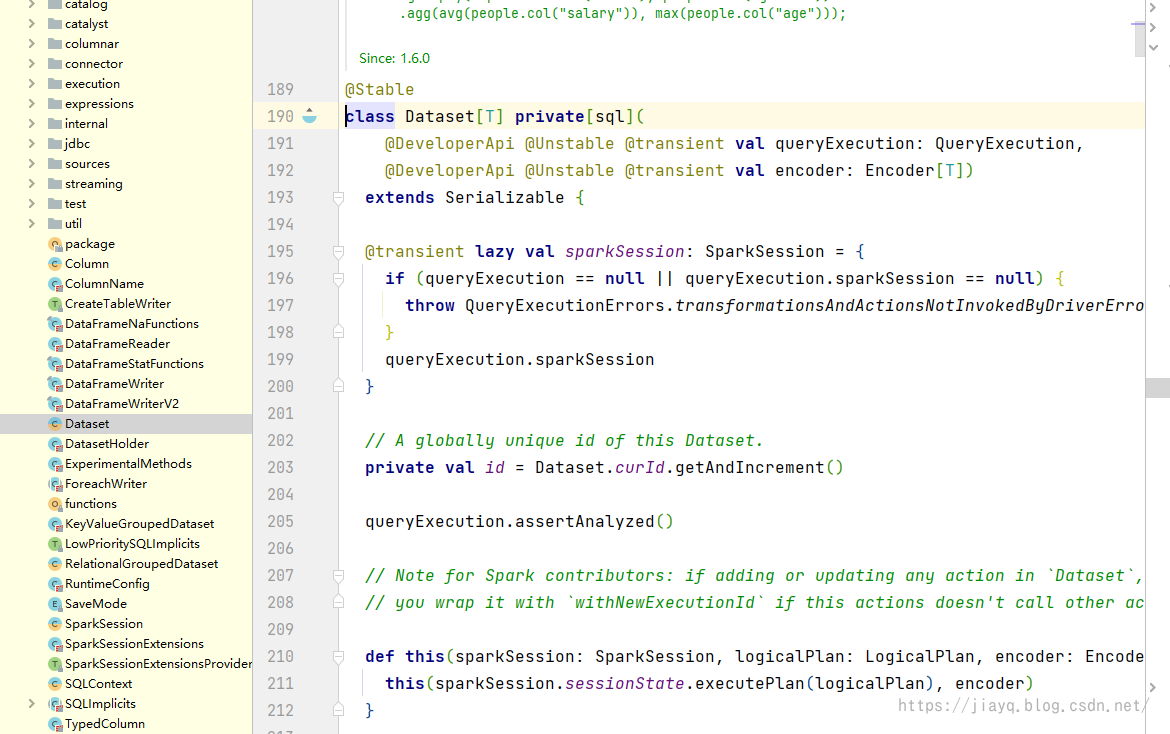
说白了DataSet和RDD差不多,就是一个类型而已,不要想的太复杂。
DataFrame的介绍
在官网中DataFrame的介绍如下
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs.
用大白话说DataFrame就是DataSet中比较特殊的一种,特殊在于以行为组织。DateFrame基本上等同于关系数据库中的表,但是进行了更加丰富的优化。DataFrame可以从多种来源构建,比如数据库,hive表或者是外部的数据源或者是RDD.
通过查看源码可能更加直观
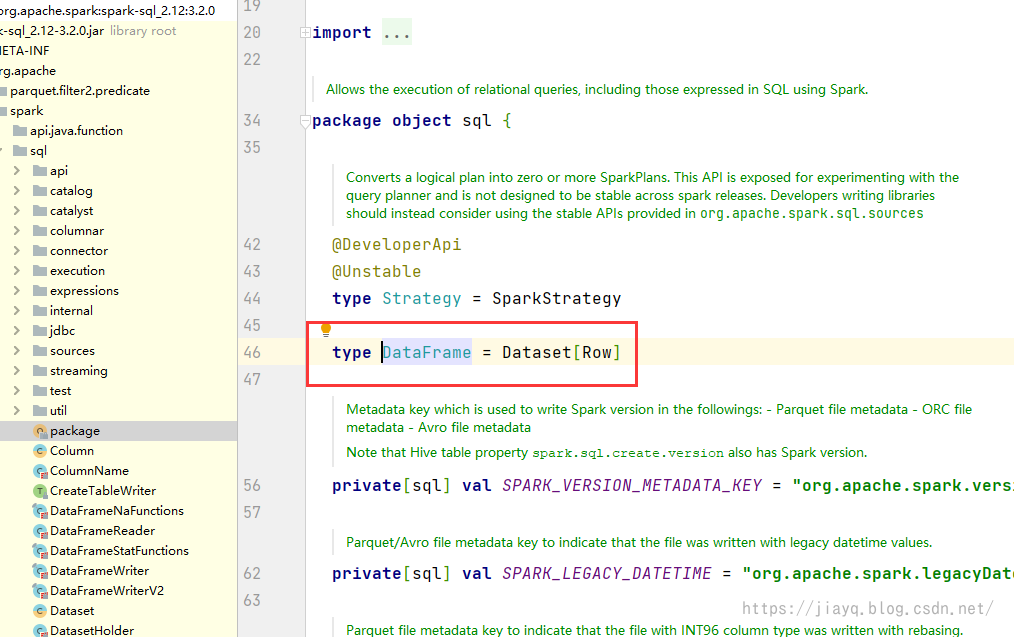
DataFrame就是DataSet[Row]
也就是定义中的DataFrame是以行为组织的DataSet.
Rdd转DateFrame
读取本地文件得到DataFrame
首先我们通过读取本地文件,获取DataFrame
import org.apache.spark.sql.SparkSession
object SparkDataSetApp {
def main(args: Array[String]): Unit = {
// 1. 获取SparkSession
val sparkSession = SparkSession builder() master("local") appName("SparkDataSetApp") getOrCreate()
// 2. 通过读取本地文件得到DataFrame
val columnDF = sparkSession.read format("csv") load("E:\\java\\sparkmaven\\data\\COLUMNS.csv")
// 3. 打印结构信息
columnDF printSchema()
columnDF show 5
// 4. 导入隐式方法
import sparkSession.implicits._
// 5. 使用DF风格的查询
columnDF select($"_c3" as "name") show 5
// 关闭sparkSession
sparkSession close()
}
}
不仅仅是csv文件,spark支持多种文件,常见的txt,json,csv等文件都支持,外部数据源通过jdbc也支持
我们这里选择csv文件,spark会自动按照csv文件的分割符号进行拆分列,如果你的csv文件有表头,那么可以设置表头配置,以csv文件中的表头构建结构信息。
使用.option("header","true")设置,如果你的csv文件一条数据以多行存储,也可以设置.option("multiLine", true)说明
比如
val columnDF = sparkSession.read format("csv") option("header", "true") option ("multiLine","true") load("E:\\java\\sparkmaven\\data\\COLUMNS.csv")
因为COLUMNS.csv文件中没有表头,而且也是一条数据一行的,所以不用这两个设置,当然还有其他的设置,更多在spark的文档中都有Generic Load/Save Functions - Spark 3.2.1 Documentation (apache.org)
csv文件相关配置见CSV Files - Spark 3.2.1 Documentation (apache.org)
读取后打印的结构信息如下
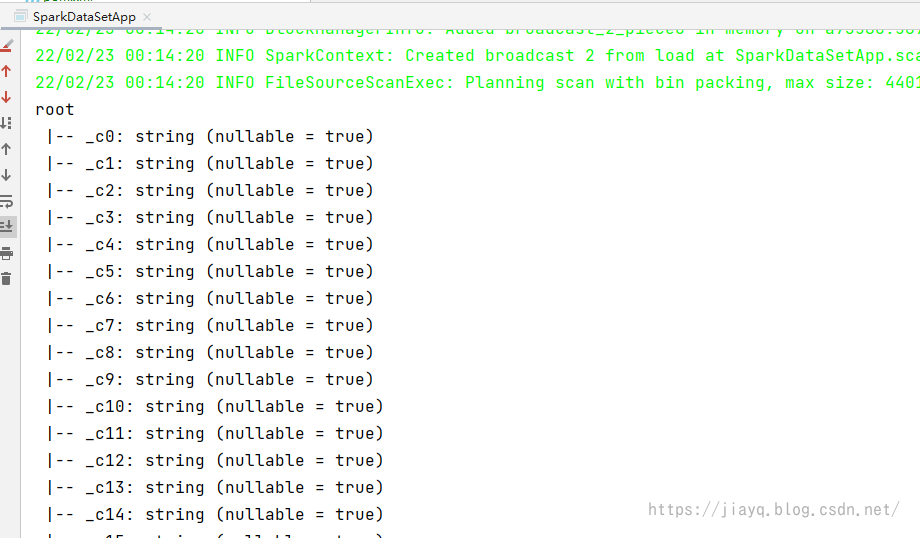
是以树形结构打印结构信息的,这个在json中可能存在嵌套,在csv中只是一颗简单的树结构。
读取的数据打印如下
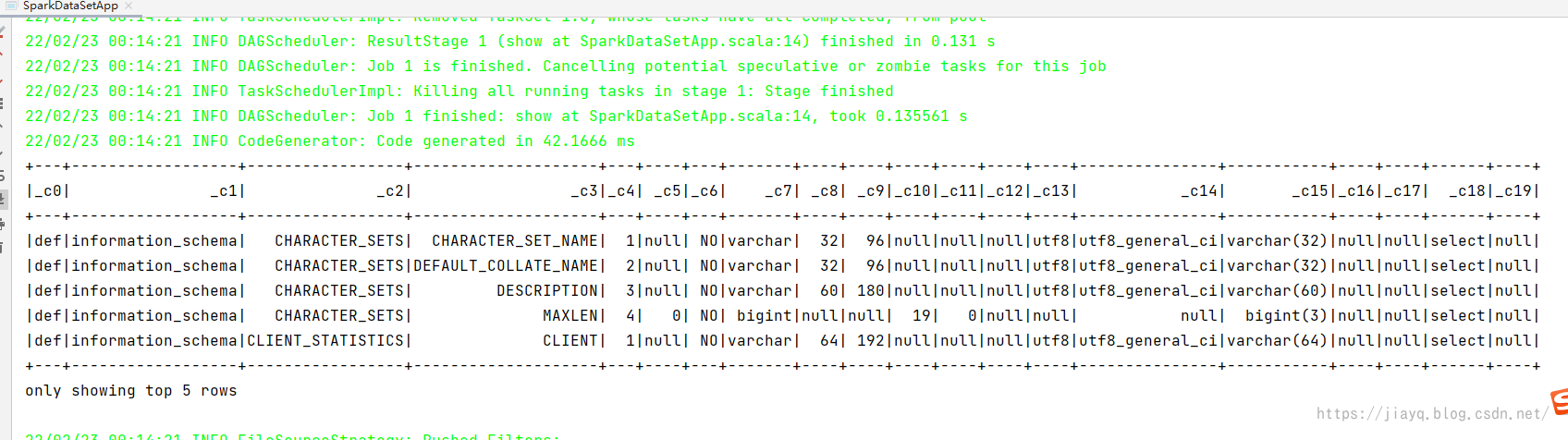
简单查询结果如下
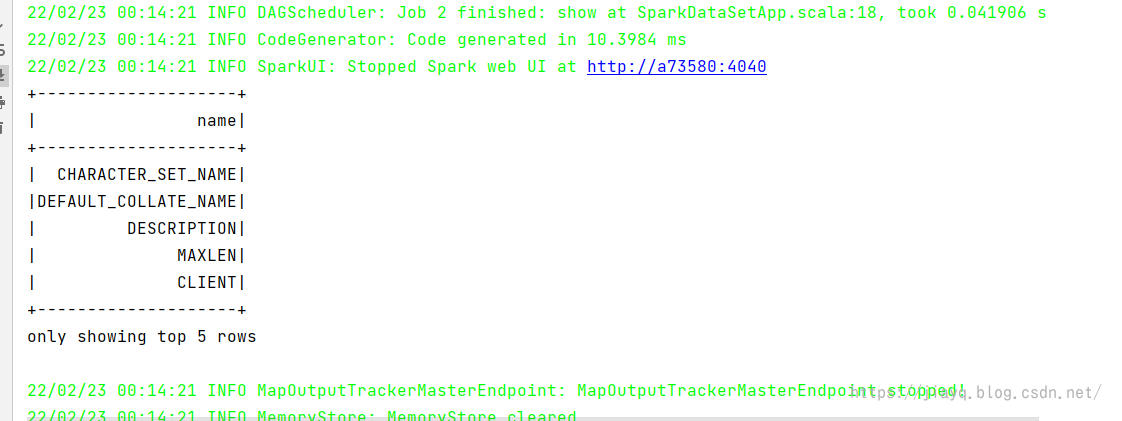
DF风格查询
我们可以使用DF风格的查询,比如
import org.apache.spark.sql.SparkSession
object SparkDataSetApp {
def main(args: Array[String]): Unit = {
// 1. 获取SparkSession
val sparkSession = SparkSession builder() master ("local") appName ("SparkDataSetApp") getOrCreate()
// 2. 通过读取本地文件得到DataFrame
val columnDF = sparkSession.read format ("csv") load ("E:\\java\\sparkmaven\\data\\COLUMNS.csv")
// 3. 打印结构信息
columnDF printSchema()
columnDF show 5
// 4. 导入隐式方法
import sparkSession.implicits._
// 5. 使用DF风格的查询
columnDF select ($"_c3" as "name") show 5
// 6. 查询c4列值为4的数据,只展示c3列
columnDF select (columnDF col ("_c3") as ("name")) filter ((columnDF col ("_c4")) === 4) show 5
// 7. 查询c4列,并进行分组计数
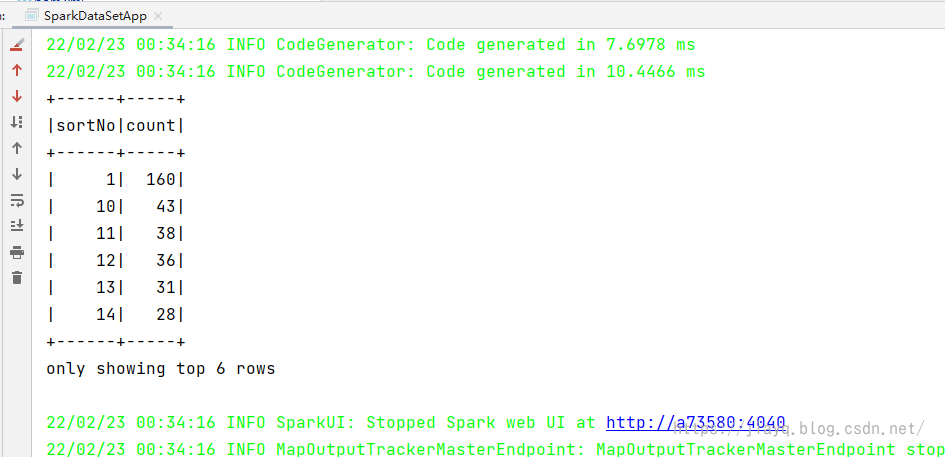
columnDF select ($"_c4" as "sortNo") groupBy ($"sortNo") count() orderBy ($"sortNo") show 6
// 关闭sparkSession
sparkSession close()
}
}
DF风格查询结果如下
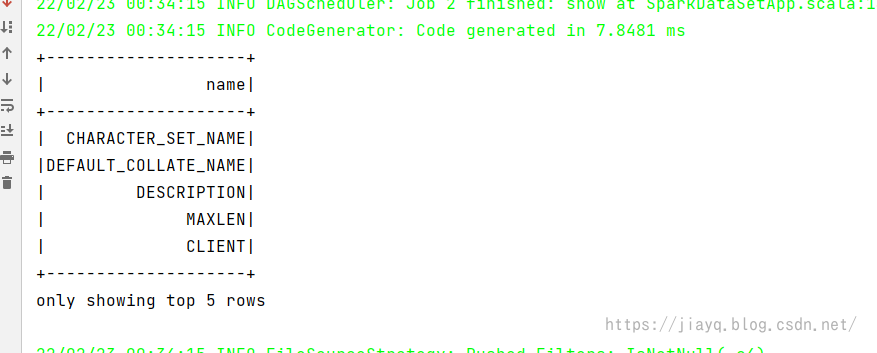
带有条件,只展示值为4的查询结果如下
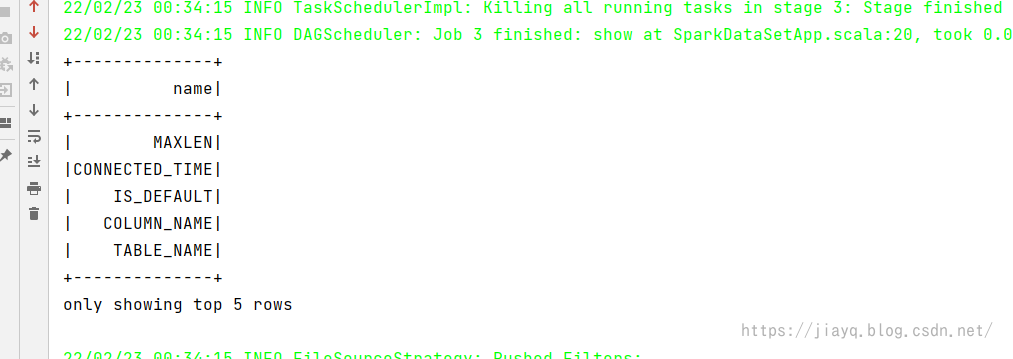
分组计数的查询结果如下
sql风格查询
我们可以把DataFrame注册为一个临时视图,然后完全使用sql的方式进行查询
import org.apache.spark.sql.SparkSession
object SparkDataSetApp {
def main(args: Array[String]): Unit = {
// 1. 获取SparkSession
val sparkSession = SparkSession builder() master ("local") appName ("SparkDataSetApp") getOrCreate()
// 2. 通过读取本地文件得到DataFrame
val columnDF = sparkSession.read format ("csv") load ("E:\\java\\sparkmaven\\data\\COLUMNS.csv")
// 3. 打印结构信息
columnDF printSchema()
columnDF show 5
// 4. 导入隐式方法
import sparkSession.implicits._
// 5. 使用DF风格的查询
columnDF select ($"_c3" as "name") show 5
// 6. 查询c4列值为4的数据,只展示c3列
columnDF select (columnDF col ("_c3") as ("name")) filter ((columnDF col ("_c4")) === 4) show 5
// 7. 查询c4列,并进行分组计数
columnDF select ($"_c4" as "sortNo") groupBy ($"sortNo") count() orderBy ($"sortNo") show 6
// 8. 注册视图
columnDF createOrReplaceTempView "column"
// 9. sql 查询
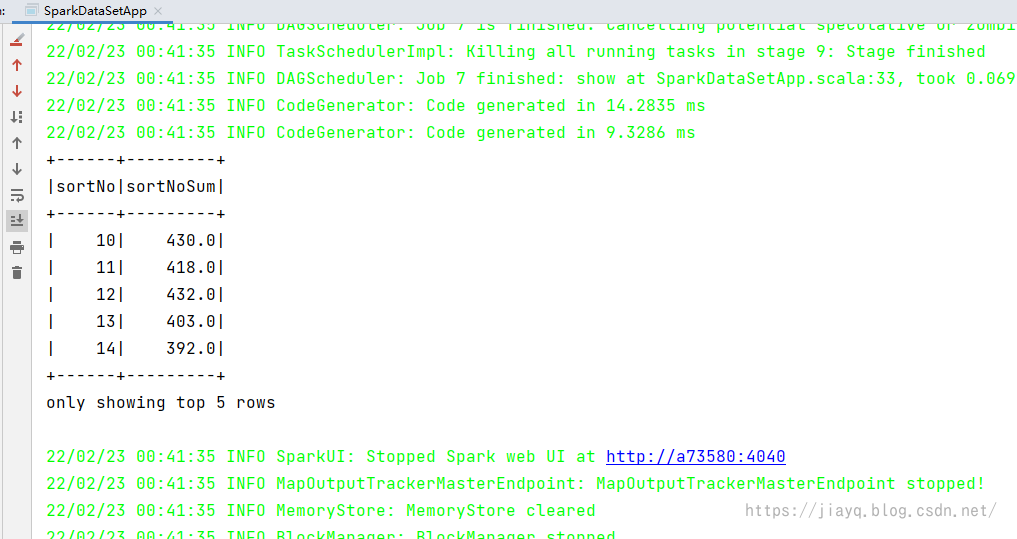
sparkSession sql
"""
|select _c4 as sortNo, sum(_c4) as sortNoSum
|from column
|where _c4 > 1
|group by _c4
|order by _c4 asc
|""".stripMargin show 5
// 关闭sparkSession
sparkSession close()
}
}
要使用sql风格查询,需要首先把DataFrame注册为视图,然后就可以写sql进行查询了
查询结果如下
查看sql的执行计划
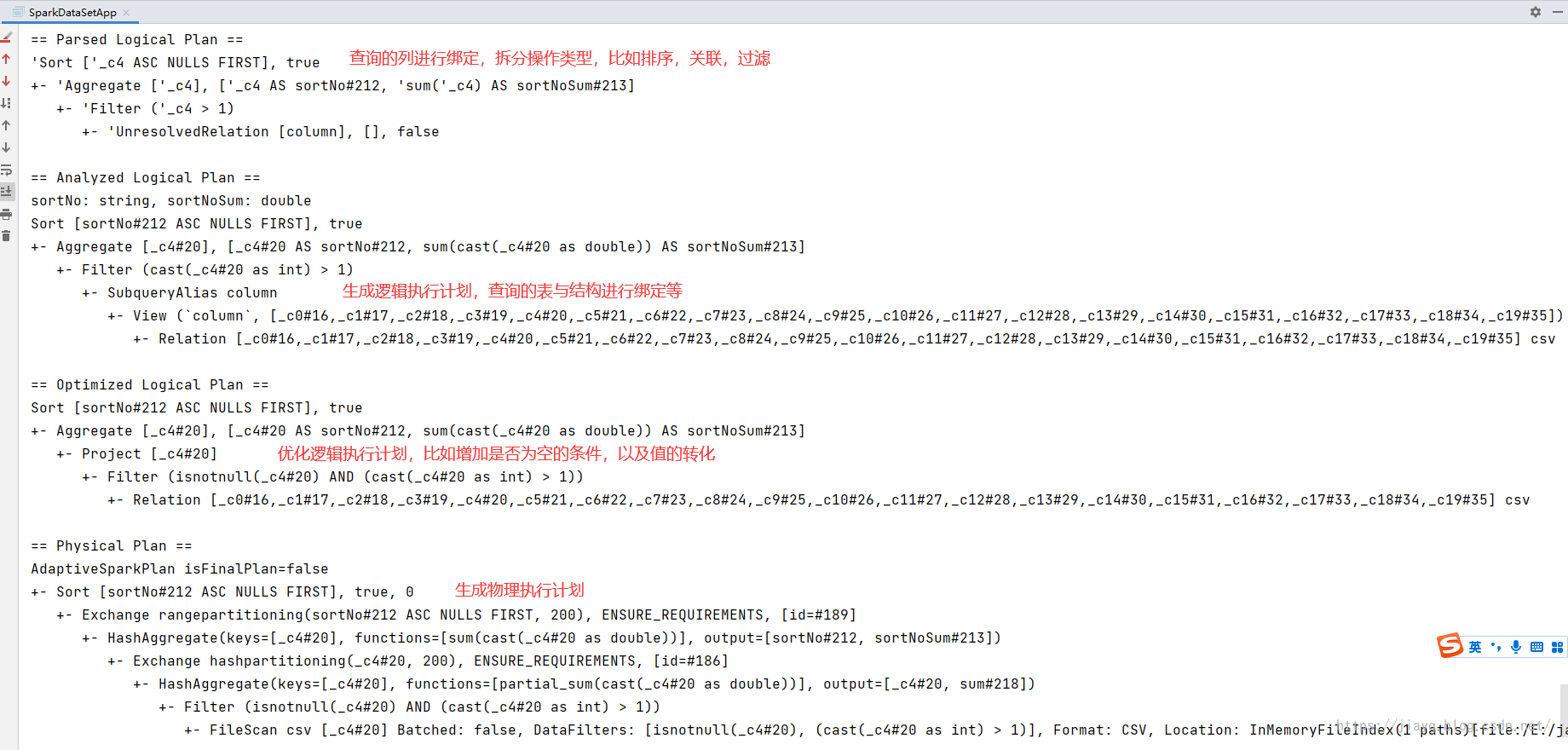
在spark sql 中,从sql到最终的执行任务task,需要经历这么几部:
- 解析sql:需要将我们写的sql进行文法,语法解析,主要验证sql的正确性,以及sql相关的语法检测等
- 生成逻辑执行计划:根据sql生成逻辑执行计划,这一步是验证sql中查询的数据或者条件和DataFrame中列是否能够准确对应
- 优化逻辑执行计划:根据相关的算法,对逻辑执行计划进行优化,比如分析哪些条件可以过滤更多的数据,那么先执行这个条件
- 生成物理执行计划:更具优化后的逻辑执行计划,生成spark的执行task
在代码中可以通过打印执行计划,查看详细过程
比如:
// 10. 打印执行计划
sparkSession sql
"""
|select _c4 as sortNo, sum(_c4) as sortNoSum
|from column
|where _c4 > 1
|group by _c4
|order by _c4 asc
|""".stripMargin explain true
打印结果如下
RDD通过指定结构转为DataFrame
直接使用sparkSession读取得到DataFrame是比较简单常用的,但是有时间我们没有本地文件,只有rdd,而且也想使用有结构的DataFrame进行操作,那么就需要将RDD转为DataFrame。
import org.apache.spark.sql.types.{BooleanType, IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
object SparkDataSetApp {
def main(args: Array[String]): Unit = {
// 1. 获取SparkSession
val sparkSession = SparkSession builder() master ("local") appName ("SparkDataSetApp") getOrCreate()
// 2. 获取 rdd,此时读取的是RDD[String]类型
val colRdd = sparkSession.sparkContext.textFile("E:\\java\\sparkmaven\\data\\COLUMNS.csv")
// 3. 构造DataFrame的结构
val colType = StructType(Array(StructField("scope", StringType, false),
StructField("name", StringType, false),
StructField("sortNo", IntegerType, false)))
// 4. 我们需要把 RDD[String]转为RDD[Row],注意需要和结构对应起来
val colRow = (colRdd
// 每行字符串按照 , 分割,转化为字符串数组
map (_ split (","))
// 将数组中每一个元素中多余的双引号进行去除
map { x =>
x collect ({
// 使用偏函数,如果是字符串就进行处理
case str: String => str replaceAll("\"", "")
})
}
// 对数字和布尔值进行获取的时候,增加判断,以类似三目运算符的方式使用
map (x => Row(x(2), x(3), if (x(4) isBlank) 0 else (x(4) toInt))))
// 5. RDD[Row]转为DataFrame,使用我们指定的结构
val colDF = sparkSession.createDataFrame(colRow, colType)
// 6. 使用DataFrame
colDF printSchema()
colDF show 5
colDF createOrReplaceTempView "col"
sparkSession sql
"""
|select scope,sortNo,name
|from col
|where sortNo = 3
|order by scope
|""".stripMargin show 5
// 关闭sparkSession
sparkSession close()
}
}
这种方式比较适合我们并不知道有多少列,但是我们可以从传入的每一行中提取我们需要的列,甚至我们可以不知道列的类型是什么,完全根据我们的需要进行提取。
这种方式的结构信息如下

随机打印5条数据
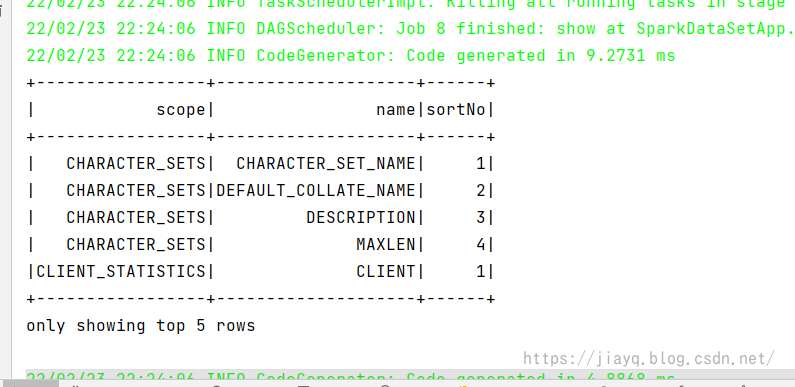
使用sql风格查询结果为
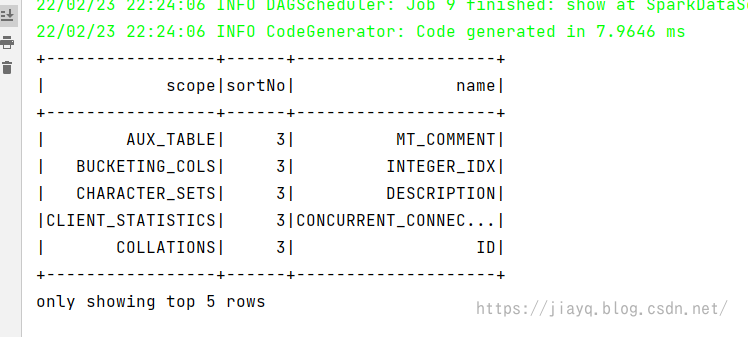
RDD通过反射构造结构转为DataFrame
使用指定结构的方式将RDD转为DataFrame的方式比较灵活,但是整体实现起来却比较繁琐。
如果我们能够确定数据列,那么就可以使用反射的方式来构造结构,进而转为DataFrame
import org.apache.spark.sql.types.{BooleanType, IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
object SparkDataSetApp {
def main(args: Array[String]): Unit = {
// 1. 获取SparkSession
val sparkSession = SparkSession builder() master ("local") appName ("SparkDataSetApp") getOrCreate()
// 2. 获取 rdd,此时读取的是RDD[String]类型
val clasRdd = sparkSession.sparkContext.textFile("E:\\java\\sparkmaven\\data\\COLUMNS.csv")
// 4. 我们需要把 RDD[String]转为RDD[Colu],注意需要和结构对应起来
val clasRow = (clasRdd
// 每行字符串按照 , 分割,转化为字符串数组
map (_ split (","))
// 将数组中每一个元素中多余的双引号进行去除
map { x =>
x collect ({
// 使用偏函数,如果是字符串就进行处理
case str: String => str replaceAll("\"", "")
})
}
// 对数字和布尔值进行获取的时候,增加判断,以类似三目运算符的方式使用
map (x => Colu(x(2), x(3), if (x(4) isBlank) 0 else (x(4) toInt))))
// 6. RDD[Colu]转为DataFrame,使用我们指定的结构
val clasDF = sparkSession.createDataFrame(clasRow)
// 7. 使用DataFrame
clasDF printSchema()
clasDF show 5
clasDF createOrReplaceTempView "clascol"
sparkSession sql
"""
|select cscope,csortNo,cname
|from clascol
|where csortNo = 3
|order by cscope
|""".stripMargin show 5
// 关闭sparkSession
sparkSession close()
}
// 5. 创建反射类
case class Colu(cscope:String, cname:String, csortNo:Int)
}
这种方式我们只需要定义一个反射的类即可
打印的结构与指定结构构造的DataFrame的结构相同的

随机展示几条数据也是一样的

sql风格的查询也是可以的
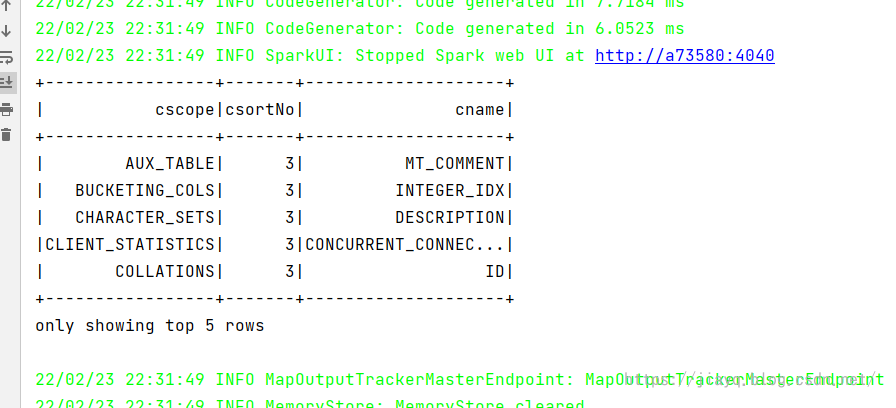
Rdd 转DataSet
在DataFrame的介绍中我们就知道,DataFrame和DataSet实际上是一回事(区别还是有的,不能完全等价),所以RDD转DataFrame和RDD转DataSet的方式完全相同。
借用网上的一些对比图
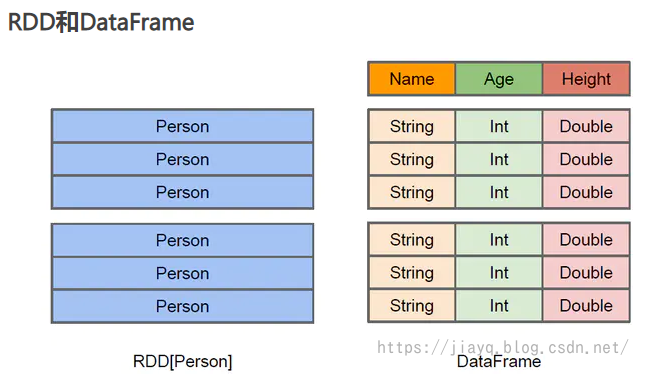
除了上面两种方式转化,我们还可以直接使用隐式方法直接转换
// 1. 使用隐式方法转为DataFrame
val _2DF = clasRow toDF()
_2DF printSchema()
// 2. 使用隐式方法转为DataSet
val _2DS = clasRow toDS()
_2DS printSchema()
打印的结构也是相同的
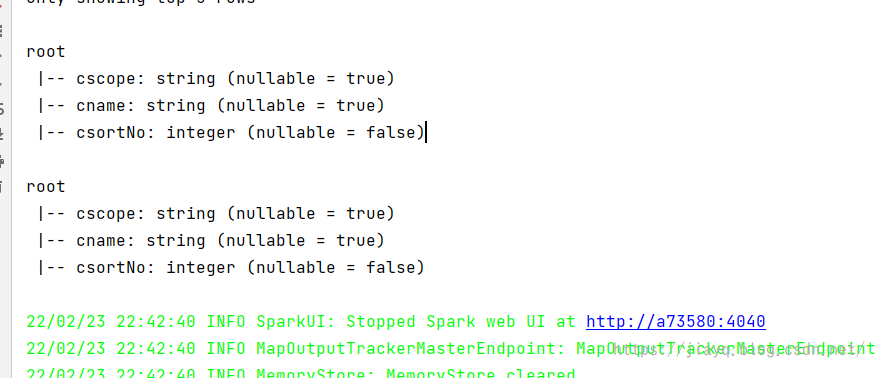
从DataFrame或DataSet中获取RDD
实际上DataFrame和DataSet中都会存储RDD,可以直接获取RDD
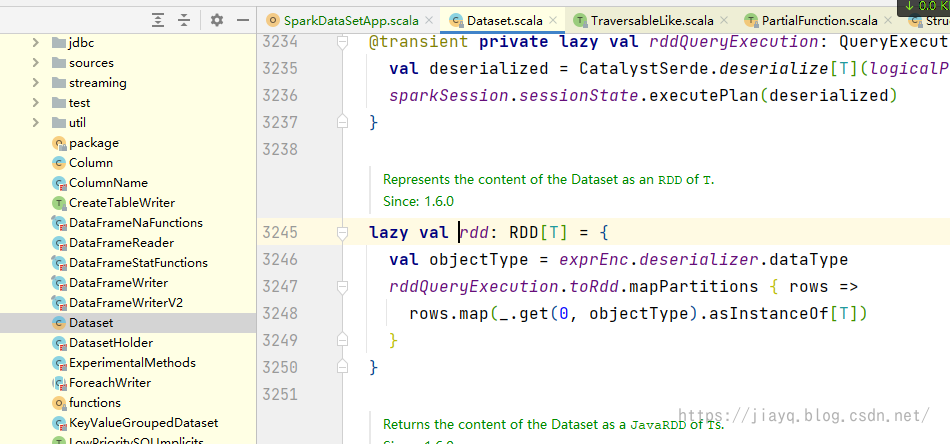
没错,在DataSet中有一个属性就是rdd,就可以直接从DataSet中获取到rdd。
比如
_2DF.rdd
_2DS.rdd
DataFrame和DateSet的互转
因为DataFrame是DataSet[Row],所以我们将DataFrame转为DataSet时,需要指定类型,以便于元素类型从Row转为具体的类型。
而DataSet转为DataFrame是从具体类型转为Row,所以可以直接转换。
在转换的时候可以指定哪些列做转换。
比如
val __2DS: Dataset[Colu] = _2DF.as[Colu] // 这里必须使用 .调用,因为使用了隐式变量
val __2DF: DataFrame = _2DS toDF()
spark sql 连接 thriftserver
使用spark-submit和spark-sql,每次执行一个sql,实际上都会产生一个spark application用于执行spark任务,如果我们执行的比较多的sql,就会频繁的创建spark application,这样就会在一定程度上耗费资源。为了实现spark application的复用,spark基本上把hive的hiveserver2照搬了过来,产生了 spark thriftserver,我们在使用thriftserver的时候,就能够复用spark application。
不过生产环境中每个查询因为数据量巨大,而且基本处于独立的查询操作,所以是不会使用thriftserver和hiveserver2的,这在开发中可能用的比较多。
要使用thriftserver就需要在依赖中加入hive-jdbc的依赖(前面说了,spark的thriftserver就是照搬hiveserver2的)
Maven Repository: org.apache.hive » hive-jdbc » 3.1.2 (mvnrepository.com)
直接增加会因为无法下载jdk-tools:jdk-toos.jar:1.6报错,无法下载
在实际测试中,这个确实比较恶心,网上有一种解决方案是自己下载依赖,然后使用maven本地安装,然后在加载依赖,经过测试,没用。
我自己的解决方案是不管他,报红就使用排除
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.jdbc.version}</version>
<exclusions>
<exclusion>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
</exclusion>
</exclusions>
</dependency>
然后在根目录下使用maven命令下载依赖mvn dependency:sources下载源码和依赖,然后重新加载maven项目,此时会把除了jdk.tools之外的依赖加入到项目中
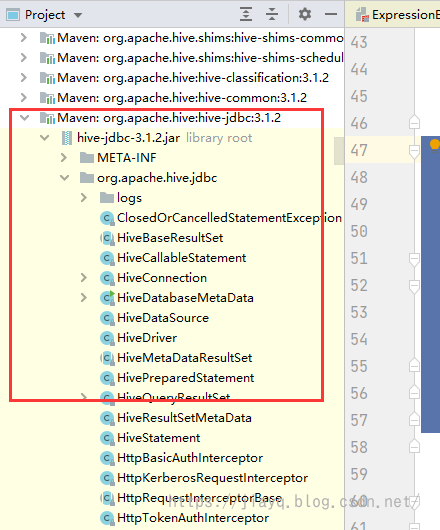
接着就可以开始编码了
import java.sql.DriverManager
object SparkThriftServerApp {
def main(args: Array[String]): Unit = {
// 1. 加载驱动
Class.forName("org.apache.hive.jdbc.HiveDriver")
// 2. 获取连接,用户名密码如果没有随便写,这里和beeline连接thriftserver是一样的
val coon = DriverManager getConnection("jdbc:hive2://hadoop01:10000/test_column", "root", "")
// 3. 编写查询sql
val pstmt = coon prepareStatement "select * from columns limit 10"
// 4. 查询
val rs = pstmt executeQuery()
// 5. 获取返回结果的元数据信息 --- 表头
val metaData = rs getMetaData()
// 6. 使用可变列表存储表头
var columsArray = List[String]()
// 7. 循环打印表头,切记从 1 开始,不是从 0 开始
for(i <- Range(1, metaData getColumnCount) inclusive) {
columsArray = columsArray :+ (metaData getColumnName i)
print(s"${metaData getColumnName i}\t")
}
println
// 8. 循环读取数据,也是从 1 开始,不是从 0 开始
while (rs next()) {
for (i <- Range(1, columsArray length) inclusive) {
print(s"${rs getString(i)}\t")
}
println
}
// 9. 关闭连接
rs close()
pstmt close()
coon close()
}
}
执行结果如下

我们也可以在thriftserver的监控界面查看执行的sql
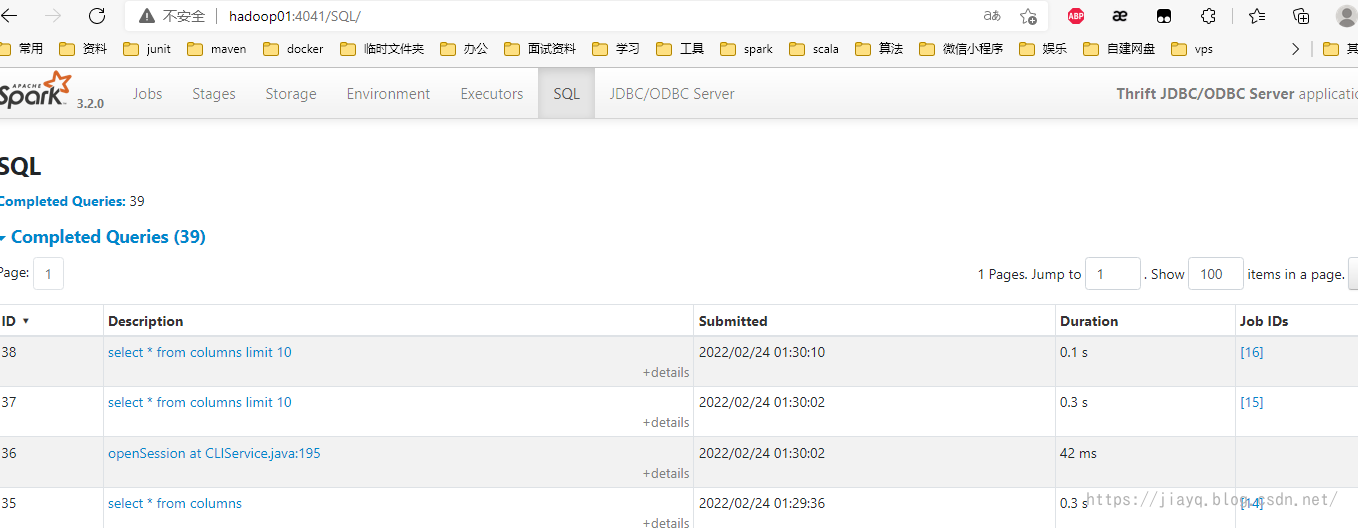
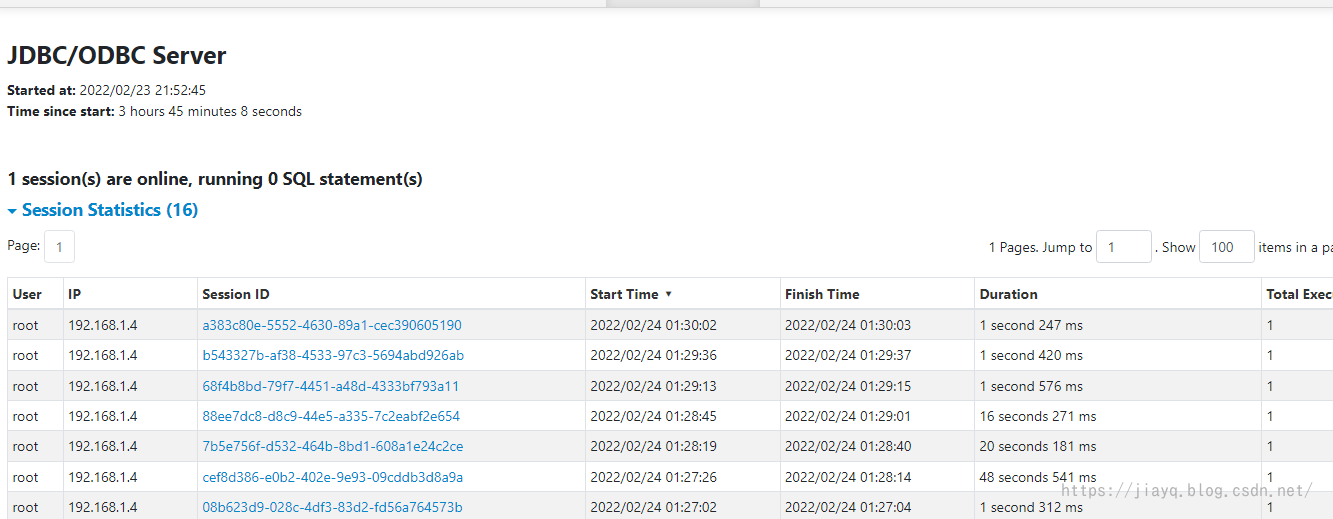
总结
我们在实际开发的时候,可能并不需要更多的关注使用的是DataFrame还是DataSet,我们只需要关注操作逻辑即可,而这恰恰是spark优化器的目的,让我们在不了解spark的底层的基础上,也能写出接近于高手写出的较高性能的代码。只能是接近,不是完全相同,高手到底是高手。
在我们不知道的底层中,spark做了很多优化。
上面基本上都是简单的使用,没有涉及到任何一点高深的地方,后续有机会一定好好研究。