MQ–1( Message queuing)>>>>RabbitMQ
MQ–2 Message queuing)>>>>ZooKeeper
三.Kafka
http://kafka.apache.org/ #官网链接
https://www.aliyun.com/product/kafka?spm=5176.10695662.1245776.1.1d6c6366RGQApw #阿里云kafka消息队列
Kafka 被称为下一代分布式消息系统,是非营利性组织 ASF( Apache Software Foundation ,简称为 ASF 基金会中的一个开源项目, 比如 HTTP Server 、 H adoop 、ActiveMQ 、 Tomcat 等开源软件都属于 Apache 基金会的开源软件, 类似的消息系统还有 RbbitMQ 、 ActiveMQ 、 ZeroMQ 。
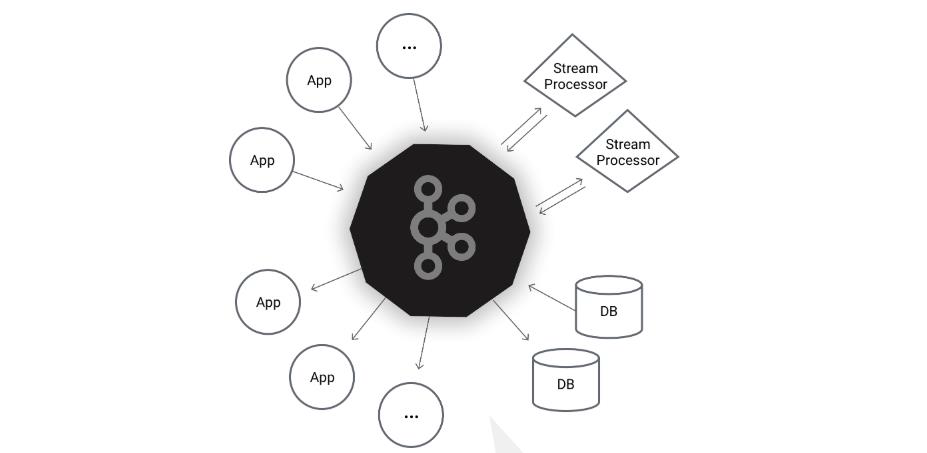
Kafka®用于构建实时数据管道和流应用程序。 它具有水平可伸缩性,容错性,快速快速性,可在数千家公司中投入生产。
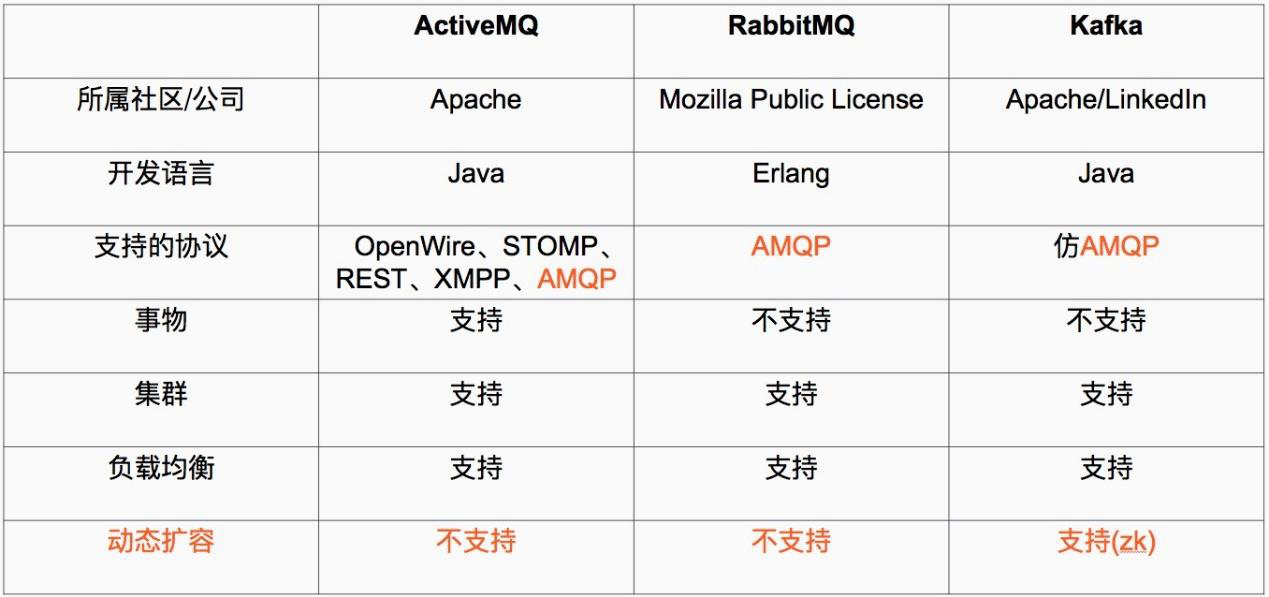
3.1常用消息队列对比
kafka最主要的优势是其具备分布式功能 、并可以结合 zookeeper 可以实现动态扩容 Kafka 是一种高吞吐量的分布式发布订阅消息系统 。
3.2 kafka 优势
kafka 通过 O(1) 的磁盘数据结构提供消息的持久化,这种结构对于即使数以 TB的消息存储也能够保持长时间的稳定性能。
o(1) 其实说的是复杂度,复杂度包括时间复杂度和空间复杂度,这里应该是时间复杂度,表示在取消息时就像数组一样,根据下标直接就获取到
高吞吐量:即使是非常普通的硬件 Kafka 也可以支持每秒数百万的消息。
支持通过 Kafka 服务器分区消息。
支持 Hadoop 并行数据加载。

O(1) 就是最低的时空复杂度了,也就是耗时 耗空间与输入数据大小无关,无论输入数据增大多少倍,耗时 耗空间都不变, 哈希算法就是典型的 O(1) 时间复杂度,无论数据规模多大,都可以在一次计算后找到目标.
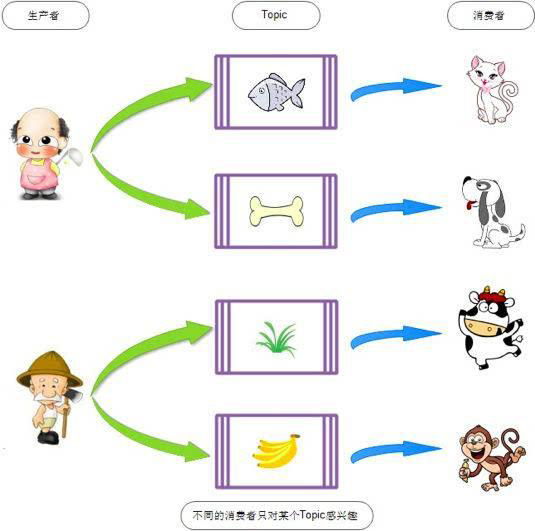
kafka 角色
https://www.jianshu.com/p/734cf729d77b #kafka基本简介
Broker: Kafka 集群包含一个或多个服务器,这种服务器被称为 broker 。
**Topic:**每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 topic ,(物理上不同 topic 的消息分开存储 在不同的文件夹 ,逻辑上 一个 topic 的消息虽然保存于一个或多个 broker 上但用户只需指定消息的 topic 即可生产或消费数据而
不必关心数据存于何处) 。
**Partition:**是物理上的概念,每个 topic 包含一个或多个 partition ,创建 topic 时可指定 parition 数量, 每个 partition 对应于一个文件夹,该文件夹下存储该partition: 的数据和索引文件 。
Producer: 负责发布消息到 Kafka broker 。
**Consumer:**消费消息,每个 consumer 属于一个特定的 consuer group 可为每个consumer 指定 group name ,若不指定 group name 则属于默认的 group 使用consumer high level API 时,同一 topic 的一条消息只能被同一个 consumer group
内的一个 consumer 消费,但多个 consumer group 可同时消费这一消息。
3.4kafka部署
http://kafka.apache.org/quickstart #kafka 快速开始
部署三台服务器 的 高可用 kafka 环境 。
部署环境:
Server 1 :172.18.0.101
Server2 :172.18.0.102
Server3 :172.18.0.103
3.4.1:版本选择
http://kafka.apache.org/downloads #kafka版本下载
目前最新版本为 kafka_2.4.1 版本格式 kafka _scala 版本 kafka 版本
http://distfiles.macports.org/ #scala 版本 选择 这里选择2.12
https://baike.baidu.com/item/Scala/2462287?fr=aladdin #scale 和java 简介
kafka_2.12-2.3.1 版本 更新 内容:
Kafka Connect REST API 进行了一些改进。
Kafka Connect 现在支持增量式合作再平衡。
Kafka Streams 现在支持内存中的会话存储和窗口存储。
AdminClient 现在允许用户确定他们有权对主题执行哪些操作。
有一个新的代理开始时间指标。
JMXTool 现在可以连接到安全的 RMI 端口。
已添加增量式 AlterConfigs API 。 旧的 AlterConfigs API 已被弃用。
现在,我们跟踪低于其最小 IS R 计数的分区。
现在,即使在代理上启用了自动主题创建,消费者也可以选择退出。
Kafka 组件现在可以使用外部配置存储( KIP 421 )。
遇到错误时,我们已实现了改进的副本获取程序行为。
3.4.2各节点部署 kafka
Kafka使用ZooKeeper,首先启动ZooKeeper服务器。
MQ–2 Message queuing)>>>>ZooKeeper #Zookeeper集群参考
实验:这里kafka的服务器既可以和zookeeper服务器复用也可以单独的拿出6个服务器 这里采取复用
172…20.10.100
172…20.10.101
172…20.10.102
3.4.2.1kafka 节点 1
# pwd
/usr/local/src
#tar xvf kafka_2.13-2.4.1.tgz
# ln -sv /usr/local/src/kafka_2.13-2.4.1 /usr/local/kafka
# cd /usr/local/kafka/config/
# mkdir /usr/local/kafka/data #在配置文件中给log.dirs是使用
#vim server.properties
21 broker.id=1 #每个 broker 在集群中的唯一标识,正整数。
31 listeners=PLAINTEXT://172.20.10.100:9092 #监听地址 本地地址不能写0.0.0.0
42 num.network.threads=128 #网络请求接受数
60 log.dirs=/usr/local/kafka/data #kakfa 用于保存数据的目录,所有的消息都会存储在该目录当中
65 num.partitions=1 #设置创新新的 topic 默认分区数量
103 log.retention .hours=168 #设置 kafka 中消息保存时间 默认为 168 小时即7天
zookeeper.connect #指定连接的 zk 的地址 zk 中存储了 broker 的元数据信息格式如下:
123 zookeeper.connect=172.20.10.100:2181,172.20.10.101:2181,172.20.10.102:2181
126 zookeeper.connection.timeout.ms=6000 #设置连接 zookeeper 的超时时间, 默认 6 秒钟
3.4.2.2kafka 节点 2
# pwd
/usr/local/src
#tar xvf kafka_2.13-2.4.1.tgz
# ln -sv /usr/local/src/kafka_2.13-2.4.1 /usr/local/kafka
# cd /usr/local/kafka/config/
# mkdir /usr/local/kafka/data #在配置文件中给log.dirs是使用
#vim server.properties
21 broker.id=2
31 listeners=PLAINTEXT://172.20.10.101 :9092
60 log.dirs=/usr/local/kafka/kafk-logs
65 num.partitions=1
103 log.retention.hours=168
123 zookeeper.connect=172.18.0.101:2181,172.18.0.102:2181,172.18.0.103:2181
126 zookeeper.connection.timeout.ms=6000
3.4.2.3kafka 节点 3
# pwd
/usr/local/src
#tar xvf kafka_2.13-2.4.1.tgz
# ln -sv /usr/local/src/kafka_2.13-2.4.1 /usr/local/kafka
# cd /usr/local/kafka/config/
# mkdir /usr/local/kafka/data #在配置文件中给log.dirs是使用
#vim server.properties
21 broker.id=3
31 listeners=PLAINTEXT://172.20.10.102 :9092
60 log.dirs=/usr/local/kafka/kafka-logs
65 num.partitions=1
103 log.retention.hours=168
123 zookeeper.connect=172.18.0.101:2181,172.18.0.102:2181,172.18.0.103:2181
126 zookeeper.connection.timeout.ms=6000
3.4.3 :各节点启动 kafka
#/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
# 此方式 zookeeper 会在shell断开后关闭 而且正常启动会占据终端
3.4.3.1 :节点 1 启动 kafka
# mkdir /usr/local/kafka/kafka-logs #创建数据目录
# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties #以守护进程启动
3.4.3.2 :节点 2 启动 kafka
# mkdir /usr/local/kafka/kafka-logs
# /usr/local/kafka/bin/kafka server start.sh -daemon /usr/local/kafka/config/server.properties
3.4.3.3 :节点 3 启动 kafka
# mkdir /usr/local/kafka/kafka-logs
# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
实验:
三台服务器都相同的方式启动kafka 如果有报错信息没有起来可能是内存不足导致
root@ZK-serverx:~# cd /usr/local/kafka
root@ZK-serverx:/usr/local/kafka# bin/kafka-server-start.sh config/server.properties
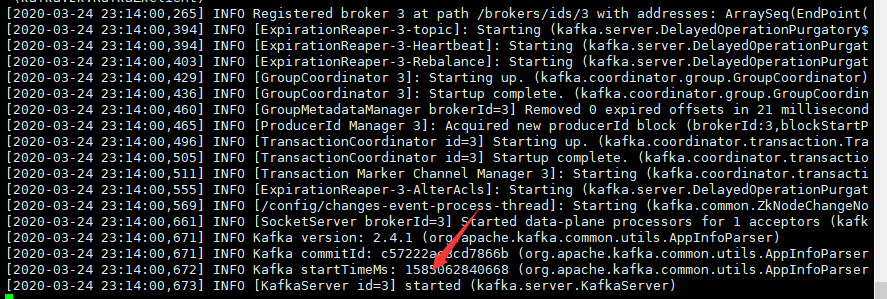
后台启动:
# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
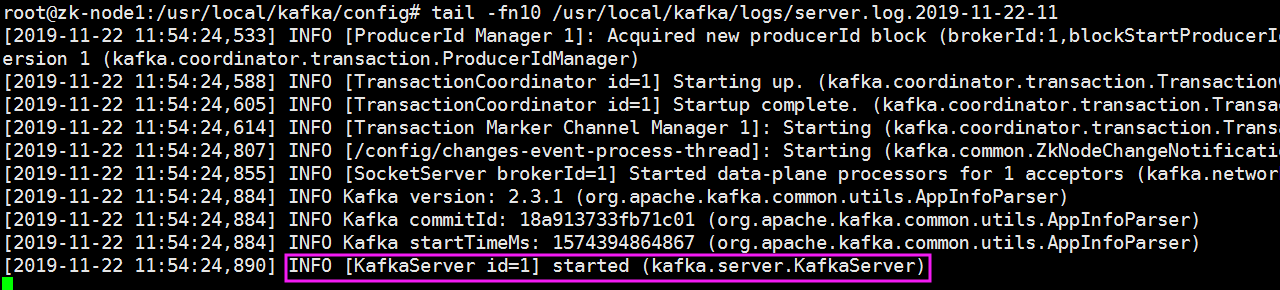
#tail /usr/local/kafka/logs/server.log #查看最后一行是否为INFO [KafkaServer id=1] started (kafka.server.KafkaServer) 的状态
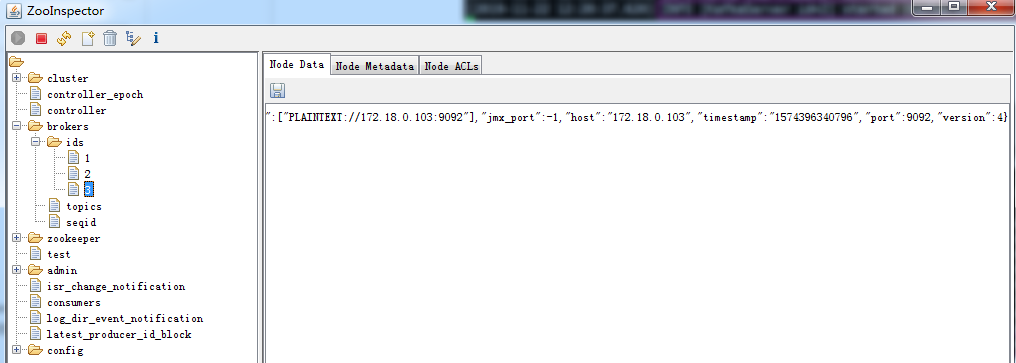
3.4.3.4验证 zookeeper 中 kafka 元数据:
1 、 Broker 依赖于 Zooke eper ,每个 Broker 的 id 和 Topic 、 Partition 这些元数据信息都会写入 Zookeeper 的 ZNode 节点中;
2 、 Consumer 依赖于 Zookeeper Consumer 在消费消息时,每消费完一条消息,会将产生的 offset 保存到 Zookeeper 中,下次消费在当前 offset 往后继续消费;
ps: kafka0.9 之前 Consumer 的 offset 存储在 Zookeeper 中, kafka0,9 以后 offset存储在本地。
3 、 Partition 依赖于 Zookeeper Partition 完成 Replication 备份后,选举出一个Leader ,这个是依托于 Zookeeper 的选举机制实现的;
3.5:测试 kafka 读写数据
http://kafka.apache.org/quickstart
3.5.1创建 topic
创建名为logstashtest,partitions (分区) 为 3 ,replication (复制) 为 3 的 topic 主题:
在任意 kafaka 服务器操作:
# /usr/local/kafka/bin/kafka-topics.sh -create --zookeeper 172.20.10.100:2181,172.20.10.100:2181,172.20.10.102:2181
--partitions 3 --replication-factor 3 --topic magedu
Created topic magedu.
实验:
用一个分区和一个副本创建一个名为“ test”的主题:
root@ZK-server1:/usr/local/kafka# bin/kafka-topics.sh --create --bootstrap-server 172.20.10.102:9092
--replication-factor 1 --partitions 1 --topic test #创建一个test topic
运行list topic命令,我们可以看到该主题,可以在集群的任何一个机器中去看都可以
root@ZK-server1:/usr/local/kafka# bin/kafka-topics.sh --list --bootstrap-server 172.20.10.101:9092
test
root@ZK-server1:/usr/local/kafka# bin/kafka-topics.sh --list --bootstrap-server 172.20.10.102:9092
test
root@ZK-server1:/usr/local/kafka# bin/kafka-topics.sh --list --bootstrap-server 172.20.10.100:9092
test
3.5.2验证 topic
状态说明:logstashtest 有三个分区分别为 0 、 1 、 2 ,分区 0 的 leader 是 3 broker.id
分区 0 有三个副本,并且状态都为 lsr (ln-sync ,表示可以参加选举成为 leader )。
# /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 172.18.0.101:2181,172.18.0.102:2181,172.18.0.103:2181 --topic magedu
Topic:magedu PartitionCount:3 ReplicationFactor:3 Configs:
Topic: magedu Par tition: 0 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: magedu Partition: 1 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
Topic: magedu Partition: 2 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2
root@ZK-server3:~# /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper
172.20.10.100:2181,172.20.10.101:2181,172.20.10.102:2181 --topic test
Topic: test PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1 Isr: 1
root@ZK-server3:~# /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 172.20.10.100:2181,172.20.10.101:2181,172.20.10.102:2181 --topic magedu
Topic: magedu PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: magedu Partition: 0 Leader: 1 Replicas: 1 Isr: 1
3.5.3获取所有 topic
# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 172.18.0.101:2181,172.18.0.102:2181,172.18.0.103:2181
magedu
3.5.4:测试发送消息
# /usr/local/kafka/bin/kafka-console-producer.sh --broker --list 172.18.0.101:9092,172.18.0.102:9092,172.18.0.103:9092 --topic magedu
>msg1
>msg2
>msg3
3.5.5:测试获取消息
可以到任意一台 kafka 服务器测试 消息获取,只要有相应的消息获取客户端即可。
# /usr/local/kafka/bin/kafka-console-consumer.sh --topic magedu --bootstrap-server 172.18.0.102:9092 --from-beginning
msg1
msg3
msg2

kafka数据会保留一定的时间
3.5.6删除 topic
# /usr/local/kafka/bin/kafka-topics.sh --delete --zookeeper 172.18.0.101:2181,172.18.0.102:2181,172.18.0.103:2181 --topic magedu
Topic magedu is marked for deletion.

http://www.kafkatool.com/download.html #kafka工具下载



https://www.cnblogs.com/frankdeng/p/9452982.html #参考链接