一、Flink 专栏
Flink 专栏 系统介绍某一知识点,并辅以具体的示例进行说明。
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏 是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击: Flink 系列文章汇总索引
本文介绍了通过Table API和SQL创建表、视图以及查询示例,同时介绍了Table API 操作表的列、聚合、join操作。
如果需要了解更多内容,可以在本人 Flink 专栏 中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本示例依赖hive、hadoop、kafka环境好用,代码中示例的hive配置文件路径根据你自己的环境而设置。
本文更详细的内容可参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
本专题分为以下几篇文章:
【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表
【flink番外篇】9、Flink Table API 支持的操作示例(2)- 通过Table API 和 SQL 创建视图
【flink番外篇】9、Flink Table API 支持的操作示例(3)- 通过API查询表和使用窗口函数的查询
【flink番外篇】9、Flink Table API 支持的操作示例(4)- Table API 对表的查询、过滤操作
【flink番外篇】9、Flink Table API 支持的操作示例(5)- 表的列操作
【flink番外篇】9、Flink Table API 支持的操作示例(6)- 表的聚合(group by、Distinct、GroupBy/Over Window Aggregation)操作
【flink番外篇】9、Flink Table API 支持的操作示例(7)- 表的join操作(内联接、外联接以及联接自定义函数等)
【flink番外篇】9、Flink Table API 支持的操作示例(8)- 时态表的join(scala版本)
【flink番外篇】9、Flink Table API 支持的操作示例(9)- 表的union、unionall、intersect、intersectall、minus、minusall和in的操作
【flink番外篇】9、Flink Table API 支持的操作示例(10)- 表的OrderBy、Offset 和 Fetch、insert操作
【flink番外篇】9、Flink Table API 支持的操作示例(11)- Group Windows(tumbling、sliding和session)操作
【flink番外篇】9、Flink Table API 支持的操作示例(12)- Over Windows(有界和无界的over window)操作
【flink番外篇】9、Flink Table API 支持的操作示例(13)- Row-based(map、flatmap、aggregate、group window aggregate等)操作
【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
【flink番外篇】9、Flink Table API 支持的操作示例(1)-完整版
【flink番外篇】9、Flink Table API 支持的操作示例(2)-完整版
本文或本专题依赖的maven,为了节省篇幅不再每个示例再单独列出,可能存在多余的maven依赖。
<properties>
<encoding>UTF-8</encoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-gateway</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-uber -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-uber</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-runtime -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>3.1.0-1.17</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hive -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>1.17.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<!-- flink连接器 -->
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-compress -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.24.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
</dependency>
</dependencies>
本示例着重展示基本的程序结构,不涉及复杂的source、transformation和sink。
为了节省篇幅,本示例包含本专题所需要的所有import,下面的示例不再引入。
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.and;
import static org.apache.flink.table.api.Expressions.lit;
import static org.apache.flink.table.expressions.ApiExpressionUtils.unresolvedCall;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.table.KafkaConnectorOptions;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Over;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableDescriptor;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.CatalogView;
import org.apache.flink.table.catalog.Column;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.ResolvedCatalogView;
import org.apache.flink.table.catalog.ResolvedSchema;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.functions.BuiltInFunctionDefinitions;
import org.apache.flink.types.Row;
import com.google.common.collect.Lists;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
public class TestTableAPIDemo {
final static List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 20, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L)
);
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// 0、运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 2、数据源
DataStream<User> users = env.fromCollection(userList);
// 3、DataStream 转 Table
Table sourceTable = tenv.fromDataStream(users);
// 4、查询
Table resultQuery = sourceTable.groupBy($("name")).select($("name"), $("age").sum().as("age_sum"));
// 5、Table 转 DataStream
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(resultQuery, Row.class);
// 6、sink
resultDS.print();
// 7、执行
env.execute();
}
static void testTableEnvironment() throws Exception {
// TableEnvironment 的主要职能包括:
// 注册 Catlog
// 在内部 Catlog 中注册表
// 加载可插拔模块
// 执行 SQL 查询
// 注册用户自定义函数
// DataStream 和 Table 之间的转换(在 StreamTableEnvironment 的情况下)
// 提供更详细的配置选项
// 设置方式一
// inStreamingMode/inBatchMode,批处理或流式,默认流式
// useBlinkPlanner/useOldPlanner/useAnyPlanner,执行计划,默认blink(和flink版本有关),anyplanner不需要显式设置
EnvironmentSettings env = EnvironmentSettings.newInstance().inStreamingMode().build();
// EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
// EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
// EnvironmentSettings.newInstance().useAnyPlanner().inStreamingMode().build();
TableEnvironment tenv = TableEnvironment.create(env);
// 设置方式二,基于 StreamExecutionEnvironment 创建 StreamTableEnvironment 来与 DataStream
// API 进行相互转换
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 表 Table 有两种类型的表,一种是连接器表(Connector Tables) Table,一种是虚拟表(Virtual Tables)
// VIEW。连接器表一般用来描述外部数据,例如文件、数据库表或者消息队列。虚拟表通常是 Table API 或 SQL 查询的结果,可以基于现有的连接器表
// Table 对象来创建。
// 1、连接器 Connector 表
// 创建 Table 最直观的方式,就是通过连接器(Connector)连接到一个外部系统,然后定义出对应的表结构。
// 例如我们可以连接到 Kafka 或者文件系统,将存储在这些外部系统的数据以表 Table 的形式定义出来,
// 这样对表 Table的读写就可以通过连接器转换成对外部系统的读写。连接器表可以直接通过 SQL DDL 方式创建:
// 2、虚拟表
// 。。。。。。
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class User {
private long id;
private String name;
private int age;
private Long rowtime;
}
}
本示例是通过Table API 和 SQL 两种方式创建一张kafka表,其中表结构涉及使用kafka的元数据,即kafka的事件时间、分区编号和kafka数据offset。
同时,提供验证方法,即输入数据和预期输出数据。
/**
* @author alanchan
*
*/
public class TestTableAPIDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// testCreateTableByAPI();
testCreateTableBySQL();
}
static void testCreateTableByAPI() throws Exception {
// EnvironmentSettings env = EnvironmentSettings.newInstance().inStreamingMode().build();
// TableEnvironment tenv = TableEnvironment.create(env);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
//API创建表
Schema schema = Schema.newBuilder()
.columnByMetadata("event_time", DataTypes.TIME(3), "timestamp")
.columnByMetadata("partition", DataTypes.BIGINT(), true)
.columnByMetadata("offset", DataTypes.BIGINT(), true)
.column("user_id", DataTypes.BIGINT())
.column("item_id", DataTypes.BIGINT())
.column("behavior", DataTypes.STRING())
.build();
TableDescriptor kafkaDescriptor = TableDescriptor.forConnector("kafka")
.comment("kafka source table")
.schema(schema)
.option(KafkaConnectorOptions.TOPIC, Lists.newArrayList("user_behavior"))
.option(KafkaConnectorOptions.PROPS_BOOTSTRAP_SERVERS, "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.option(KafkaConnectorOptions.PROPS_GROUP_ID, "testGroup")
.option("scan.startup.mode", "earliest-offset")
.format("csv")
.build();
tenv.createTemporaryTable("Alan_KafkaTable", kafkaDescriptor);
//查询
String sql = "select * from Alan_KafkaTable ";
Table resultQuery = tenv.sqlQuery(sql);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(resultQuery, Row.class);
// 6、sink
resultDS.print();
// 7、执行
env.execute();
//kafka中输入测试数据
// 1,1001,login
// 1,2001,p_read
//程序运行控制台输入如下
// 11> (true,+I[16:32:19.923, 0, 0, 1, 1001, login])
// 11> (true,+I[16:32:32.258, 0, 1, 1, 2001, p_read])
}
static void testCreateTableBySQL() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// SQL 创建输入表
String sourceSql = "CREATE TABLE Alan_KafkaTable (\r\n" +
" `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',\r\n" +
" `partition` BIGINT METADATA VIRTUAL,\r\n" +
" `offset` BIGINT METADATA VIRTUAL,\r\n" +
" `user_id` BIGINT,\r\n" +
" `item_id` BIGINT,\r\n" +
" `behavior` STRING\r\n" +
") WITH (\r\n" +
" 'connector' = 'kafka',\r\n" +
" 'topic' = 'user_behavior',\r\n" +
" 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',\r\n" +
" 'properties.group.id' = 'testGroup',\r\n" +
" 'scan.startup.mode' = 'earliest-offset',\r\n" +
" 'format' = 'csv'\r\n" +
");";
tenv.executeSql(sourceSql);
//查询
String sql = "select * from Alan_KafkaTable ";
Table resultQuery = tenv.sqlQuery(sql);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(resultQuery, Row.class);
// 6、sink
resultDS.print();
// 7、执行
env.execute();
//kafka中输入测试数据
// 1,1001,login
// 1,2001,p_read
//程序运行控制台输入如下
// 11> (true,+I[16:32:19.923, 0, 0, 1, 1001, login])
// 11> (true,+I[16:32:32.258, 0, 1, 1, 2001, p_read])
}
}
本示例是通过sql创建一个简单的表,然后再通过sql创建一个视图,最后查询视图并输出结果。
/**
* @author alanchan
*
*/
public class TestTableAPIDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// SQL 创建输入表
String sourceSql = "CREATE TABLE Alan_KafkaTable (\r\n" +
" `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',\r\n" +
" `partition` BIGINT METADATA VIRTUAL,\r\n" +
" `offset` BIGINT METADATA VIRTUAL,\r\n" +
" `user_id` BIGINT,\r\n" +
" `item_id` BIGINT,\r\n" +
" `behavior` STRING\r\n" +
") WITH (\r\n" +
" 'connector' = 'kafka',\r\n" +
" 'topic' = 'user_behavior',\r\n" +
" 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',\r\n" +
" 'properties.group.id' = 'testGroup',\r\n" +
" 'scan.startup.mode' = 'earliest-offset',\r\n" +
" 'format' = 'csv'\r\n" +
");";
tenv.executeSql(sourceSql);
//
String sql = "select user_id , behavior from Alan_KafkaTable group by user_id ,behavior ";
Table resultQuery = tenv.sqlQuery(sql);
tenv.createTemporaryView("Alan_KafkaView", resultQuery);
String queryViewSQL = " select * from Alan_KafkaView ";
Table queryViewResult = tenv.sqlQuery(queryViewSQL);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(queryViewResult, Row.class);
// 6、sink
resultDS.print();
// 7、执行
env.execute();
// kafka中输入测试数据
// 1,1001,login
// 1,2001,p_read
// 程序运行控制台输入如下
// 3> (true,+I[1, login])
// 14> (true,+I[1, p_read])
}
}
本示例是通过Table API创建一个hive的表,将数据写入hive,然后再创建视图,最后查询视图输出。
本示例依赖hive、hadoop、kafka环境好用,代码中示例的hive配置文件路径根据你自己的环境而设置。
/**
* @author alanchan
*
*/
public class TestTableAPIDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// SQL 创建输入表
String sourceSql = "CREATE TABLE Alan_KafkaTable (\r\n" +
" `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',\r\n" +
" `partition` BIGINT METADATA VIRTUAL,\r\n" +
" `offset` BIGINT METADATA VIRTUAL,\r\n" +
" `user_id` BIGINT,\r\n" +
" `item_id` BIGINT,\r\n" +
" `behavior` STRING\r\n" +
") WITH (\r\n" +
" 'connector' = 'kafka',\r\n" +
" 'topic' = 'user_behavior',\r\n" +
" 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',\r\n" +
" 'properties.group.id' = 'testGroup',\r\n" +
" 'scan.startup.mode' = 'earliest-offset',\r\n" +
" 'format' = 'csv'\r\n" +
");";
tenv.executeSql(sourceSql);
// 创建视图
String catalogName = "alan_hive";
String defaultDatabase = "default";
String databaseName = "viewtest_db";
String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";
HiveCatalog hiveCatalog = new HiveCatalog(catalogName, defaultDatabase, hiveConfDir);
tenv.registerCatalog(catalogName, hiveCatalog);
tenv.useCatalog(catalogName);
hiveCatalog.createDatabase(databaseName, new CatalogDatabaseImpl(new HashMap(), hiveConfDir) {
}, true);
tenv.useDatabase(databaseName);
String viewName = "Alan_KafkaView";
String originalQuery = "select user_id , behavior from Alan_KafkaTable group by user_id ,behavior ";
String expandedQuery = "SELECT user_id , behavior FROM " + databaseName + "." + "Alan_KafkaTable group by user_id ,behavior ";
String comment = "this is a comment";
ObjectPath path = new ObjectPath(databaseName, viewName);
createView(originalQuery, expandedQuery, comment, hiveCatalog, path);
// 查询视图
String queryViewSQL = " select * from Alan_KafkaView ";
Table queryViewResult = tenv.sqlQuery(queryViewSQL);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(queryViewResult, Row.class);
// 6、sink
resultDS.print();
// 7、执行
env.execute();
// kafka中输入测试数据
// 1,1001,login
// 1,2001,p_read
// 程序运行控制台输入如下
// 3> (true,+I[1, login])
// 14> (true,+I[1, p_read])
}
static void createView(String originalQuery, String expandedQuery, String comment, HiveCatalog hiveCatalog, ObjectPath path) throws Exception {
ResolvedSchema resolvedSchema = new ResolvedSchema(
Arrays.asList(
Column.physical("user_id", DataTypes.INT()),
Column.physical("behavior", DataTypes.STRING())),
Collections.emptyList(),
null);
CatalogView origin = CatalogView.of(
Schema.newBuilder().fromResolvedSchema(resolvedSchema).build(),
comment,
originalQuery,
expandedQuery,
Collections.emptyMap());
CatalogView view = new ResolvedCatalogView(origin, resolvedSchema);
hiveCatalog.createTable(path, view, false);
}
}
本示例实现了Tumble和Over窗口。
如果使用sql的窗口函数参考:
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
本示例仅仅是基本的查询表用法,包含2种方式,即Table API 与 SQL的方式,关于SQL的方式上面的示例中有介绍,即【三、示例:通过Table API和SQL创建表】中的testCreateTableBySQL()方法。
/**
* @author alanchan
*
*/
public class TestTableAPIDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// testQueryTableBySQL();
testQueryTableByAPI();
}
static void testQueryTableByAPI() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// SQL 创建输入表
String sourceSql = "CREATE TABLE Alan_KafkaTable (\r\n" +
" `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',\r\n" +
" `partition` BIGINT METADATA VIRTUAL,\r\n" +
" `offset` BIGINT METADATA VIRTUAL,\r\n" +
" `user_id` BIGINT,\r\n" +
" `item_id` BIGINT,\r\n" +
" `behavior` STRING\r\n" +
") WITH (\r\n" +
" 'connector' = 'kafka',\r\n" +
" 'topic' = 'user_behavior',\r\n" +
" 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',\r\n" +
" 'properties.group.id' = 'testGroup',\r\n" +
" 'scan.startup.mode' = 'earliest-offset',\r\n" +
" 'format' = 'csv'\r\n" +
");";
tenv.executeSql(sourceSql);
// 2、将流转成table
String sql = "select * from Alan_KafkaTable ";
Table streamTable = tenv.sqlQuery(sql);
// 3、API查询
Table resultQuery = streamTable
.groupBy($("user_id"), $("behavior"))
.select($("user_id"), $("behavior"), $("behavior").count().as("count(*)"));
// 4、将流转成table
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(resultQuery, Row.class);
// 5、sink
resultDS.print();
// 6、执行
env.execute();
// kafka中输入测试数据
// 1,1001,login
// 1,2001,p_read
// 程序运行控制台输入如下
// 14> (true,+I[1, p_read, 1])
// 3> (true,+I[1, login, 1])
}
static void testQueryTableBySQL() throws Exception {
// 参考 testCreateTableBySQLAndAPI()
}
}
/**
* @author alanchan
*
*/
public class TestTableAPIDemo {
final static List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 20, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L));
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
testQueryTableWithWindwosByAPI();
}
static void testQueryTableWithWindwosByAPI() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
)
;
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("age"),$("rt").rowtime());
// tumble
Table result = usersTable
.filter(
and(
// $("name").equals("alanchan"),
// $("age").between(1, 20),
$("name").isNotNull(),
$("age").isGreaterOrEqual(19)
)
)
.window(Tumble.over(lit(1).hours()).on($("rt")).as("hourlyWindow"))// 定义滚动窗口并给窗口起一个别名
.groupBy($("name"),$("hourlyWindow"))// 窗口必须出现的分组字段中
.select($("name"),$("name").count().as("count(*)"), $("hourlyWindow").start(), $("hourlyWindow").end())
;
result.printSchema();
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
env.execute();
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class User {
private long id;
private String name;
private int age;
private Long rowtime;
}
}
/**
* @author alanchan
*
*/
public class TestTableAPIDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
testQueryTableWithWindwosByAPI();
}
static void testQueryTableWithWindwosByAPI() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
)
;
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("age"),$("rt").rowtime());
// over
usersTable
.window(Over.partitionBy($("name")).orderBy($("rt")).preceding(unresolvedCall(BuiltInFunctionDefinitions.UNBOUNDED_RANGE)).as("hourlyWindow"))
.select($("id"), $("rt"), $("id").count().over($("hourlyWindow")).as("count_t"))
.execute()
.print()
;
env.execute();
}
}
Table API支持如下操作。请注意不是所有的操作都可以既支持流也支持批;这些操作都具有相应的标记。
具体示例如下,运行结果在源文件中
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.row;
import static org.apache.flink.table.api.Expressions.and;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @author alanchan
*
*/
public class TestTableAPIOperationDemo {
static String sourceSql = "CREATE TABLE Alan_KafkaTable (\r\n"
+ " `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',\r\n"
+ " `partition` BIGINT METADATA VIRTUAL,\r\n"
+ " `offset` BIGINT METADATA VIRTUAL,\r\n"
+ " `user_id` BIGINT,\r\n"
+ " `item_id` BIGINT,\r\n"
+ " `behavior` STRING\r\n"
+ ") WITH (\r\n"
+ " 'connector' = 'kafka',\r\n"
+ " 'topic' = 'user_behavior',\r\n"
+ " 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',\r\n"
+ " 'properties.group.id' = 'testGroup',\r\n"
+ " 'scan.startup.mode' = 'earliest-offset',\r\n"
+ " 'format' = 'csv'\r\n"
+ ");";
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// test1();
// test2();
test3();
}
static void test3() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 建表
tenv.executeSql(sourceSql);
Table table1 = tenv.from("Alan_KafkaTable");
// 重命名字段。
Table result = table1.as("a","b","c","d","e","f");
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
//11> (true,+I[2023-11-01T11:00:30.183, 0, 2, 1, 1002, login])
//和 SQL 的 WHERE 子句类似。 过滤掉未验证通过过滤谓词的行。
Table table2 = result.where($("f").isEqual("login"));
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(table2, Row.class);
result2DS.print();
//11> (true,+I[2023-11-01T11:00:30.183, 0, 2, 1, 1002, login])
Table table3 = result.where($("f").isNotEqual("login"));
DataStream<Tuple2<Boolean, Row>> result3DS = tenv.toRetractStream(table3, Row.class);
result3DS.print();
// 没有匹配条件的记录,无输出
Table table4 = result
.filter(
and(
$("f").isNotNull(),
// $("d").isGreater(1)
$("e").isNotNull()
)
);
DataStream<Tuple2<Boolean, Row>> result4DS = tenv.toRetractStream(table4, Row.class);
result4DS.print("test filter:");
//test filter::11> (true,+I[2023-11-01T11:00:30.183, 0, 2, 1, 1002, login])
env.execute();
}
/**
* 和 SQL 查询中的 VALUES 子句类似。 基于提供的行生成一张内联表。
*
* 你可以使用 row(...) 表达式创建复合行:
*
* @throws Exception
*/
static void test2() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
Table table = tenv.fromValues(row(1, "ABC"), row(2L, "ABCDE"));
table.printSchema();
// (
// `f0` BIGINT NOT NULL,
// `f1` VARCHAR(5) NOT NULL
// )
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(table, Row.class);
resultDS.print();
// 1> (true,+I[2, ABCDE])
// 2> (true,+I[1, ABC])
Table table2 = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.DECIMAL(10, 2)),
DataTypes.FIELD("name", DataTypes.STRING())
),
row(1, "ABCD"),
row(2L, "ABCDEF")
);
table2.printSchema();
// (
// `id` DECIMAL(10, 2),
// `name` STRING
// )
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(table2, Row.class);
result2DS.print();
// 15> (true,+I[2.00, ABCDEF])
// 14> (true,+I[1.00, ABCD])
env.execute();
}
/**
* 和 SQL 查询的 FROM 子句类似。 执行一个注册过的表的扫描。
*
* @throws Exception
*/
static void test1() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 建表
tenv.executeSql(sourceSql);
// 查询
// tenv.from("Alan_KafkaTable").execute().print();
// kafka输入数据
// 1,1002,login
// 应用程序控制台输出如下
// +----+-------------------------+----------------------+----------------------+----------------------+----------------------+--------------------------------+
// | op | event_time | partition | offset | user_id | item_id | behavior |
// +----+-------------------------+----------------------+----------------------+----------------------+----------------------+--------------------------------+
// | +I | 2023-11-01 11:00:30.183 | 0 | 2 | 1 | 1002 | login |
Table temp = tenv.from("Alan_KafkaTable");
//和 SQL 的 SELECT 子句类似。 执行一个 select 操作
Table result1 = temp.select($("user_id"), $("item_id").as("behavior"), $("event_time"));
DataStream<Tuple2<Boolean, Row>> result1DS = tenv.toRetractStream(result1, Row.class);
// result1DS.print();
// 11> (true,+I[1, 1002, 2023-11-01T11:00:30.183])
//选择星号(*)作为通配符,select 表中的所有列。
Table result2 = temp.select($("*"));
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(result2, Row.class);
result2DS.print();
// 11> (true,+I[2023-11-01T11:00:30.183, 0, 2, 1, 1002, login])
env.execute();
}
}
针对表的字段进行操作,具体示例如下,运行结果在源文件中。
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.row;
import static org.apache.flink.table.api.Expressions.and;
import static org.apache.flink.table.api.Expressions.concat;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @author alanchan
*
*/
public class TestTableAPIOperationDemo {
static String sourceSql = "CREATE TABLE Alan_KafkaTable (\r\n"
+ " `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',\r\n"
+ " `partition` BIGINT METADATA VIRTUAL,\r\n"
+ " `offset` BIGINT METADATA VIRTUAL,\r\n"
+ " `user_id` BIGINT,\r\n"
+ " `item_id` BIGINT,\r\n"
+ " `behavior` STRING\r\n"
+ ") WITH (\r\n"
+ " 'connector' = 'kafka',\r\n"
+ " 'topic' = 'user_behavior',\r\n"
+ " 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',\r\n"
+ " 'properties.group.id' = 'testGroup',\r\n"
+ " 'scan.startup.mode' = 'earliest-offset',\r\n"
+ " 'format' = 'csv'\r\n"
+ ");";
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// test1();
// test2();
test3();
}
static void test3() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 建表
tenv.executeSql(sourceSql);
Table table1 = tenv.from("Alan_KafkaTable");
// 重命名字段。
Table result = table1.as("a","b","c","d","e","f");
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
//11> (true,+I[2023-11-01T11:00:30.183, 0, 2, 1, 1002, login])
//和 SQL 的 WHERE 子句类似。 过滤掉未验证通过过滤谓词的行。
Table table2 = result.where($("f").isEqual("login"));
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(table2, Row.class);
result2DS.print();
//11> (true,+I[2023-11-01T11:00:30.183, 0, 2, 1, 1002, login])
Table table3 = result.where($("f").isNotEqual("login"));
DataStream<Tuple2<Boolean, Row>> result3DS = tenv.toRetractStream(table3, Row.class);
result3DS.print();
// 没有匹配条件的记录,无输出
Table table4 = result
.filter(
and(
$("f").isNotNull(),
// $("d").isGreater(1)
$("e").isNotNull()
)
);
DataStream<Tuple2<Boolean, Row>> result4DS = tenv.toRetractStream(table4, Row.class);
result4DS.print("test filter:");
//test filter::11> (true,+I[2023-11-01T11:00:30.183, 0, 2, 1, 1002, login])
env.execute();
}
/**
* 和 SQL 查询中的 VALUES 子句类似。 基于提供的行生成一张内联表。
*
* 你可以使用 row(...) 表达式创建复合行:
*
* @throws Exception
*/
static void test2() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
Table table = tenv.fromValues(row(1, "ABC"), row(2L, "ABCDE"));
table.printSchema();
// (
// `f0` BIGINT NOT NULL,
// `f1` VARCHAR(5) NOT NULL
// )
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(table, Row.class);
resultDS.print();
// 1> (true,+I[2, ABCDE])
// 2> (true,+I[1, ABC])
Table table2 = tenv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.DECIMAL(10, 2)),
DataTypes.FIELD("name", DataTypes.STRING())
),
row(1, "ABCD"),
row(2L, "ABCDEF")
);
table2.printSchema();
// (
// `id` DECIMAL(10, 2),
// `name` STRING
// )
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(table2, Row.class);
result2DS.print();
// 15> (true,+I[2.00, ABCDEF])
// 14> (true,+I[1.00, ABCD])
env.execute();
}
/**
* 和 SQL 查询的 FROM 子句类似。 执行一个注册过的表的扫描。
*
* @throws Exception
*/
static void test1() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 建表
tenv.executeSql(sourceSql);
// 查询
// tenv.from("Alan_KafkaTable").execute().print();
// kafka输入数据
// 1,1002,login
// 应用程序控制台输出如下
// +----+-------------------------+----------------------+----------------------+----------------------+----------------------+--------------------------------+
// | op | event_time | partition | offset | user_id | item_id | behavior |
// +----+-------------------------+----------------------+----------------------+----------------------+----------------------+--------------------------------+
// | +I | 2023-11-01 11:00:30.183 | 0 | 2 | 1 | 1002 | login |
Table temp = tenv.from("Alan_KafkaTable");
//和 SQL 的 SELECT 子句类似。 执行一个 select 操作
Table result1 = temp.select($("user_id"), $("item_id").as("behavior"), $("event_time"));
DataStream<Tuple2<Boolean, Row>> result1DS = tenv.toRetractStream(result1, Row.class);
// result1DS.print();
// 11> (true,+I[1, 1002, 2023-11-01T11:00:30.183])
//选择星号(*)作为通配符,select 表中的所有列。
Table result2 = temp.select($("*"));
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(result2, Row.class);
result2DS.print();
// 11> (true,+I[2023-11-01T11:00:30.183, 0, 2, 1, 1002, login])
env.execute();
}
static void test5() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 建表
tenv.executeSql(sourceSql);
Table table = tenv.from("Alan_KafkaTable");
//和 SQL 的 GROUP BY 子句类似。 使用分组键对行进行分组,使用伴随的聚合算子来按照组进行聚合行。
Table result = table.groupBy($("user_id")).select($("user_id"), $("user_id").count().as("count(user_id)"));
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 12> (true,+I[1, 1])
env.execute();
}
static void test4() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 建表
tenv.executeSql(sourceSql);
Table table = tenv.from("Alan_KafkaTable");
//执行字段添加操作。 如果所添加的字段已经存在,将抛出异常。
Table result2 = table.addColumns($("behavior").plus(1).as("t_col1"));
result2.printSchema();
// (
// `event_time` TIMESTAMP(3),
// `partition` BIGINT,
// `offset` BIGINT,
// `user_id` BIGINT,
// `item_id` BIGINT,
// `behavior` STRING,
// `t_col1` STRING
// )
Table result = table.addColumns($("behavior").plus(1).as("t_col3"), concat($("behavior"), "alanchan").as("t_col4"));
result.printSchema();
// (
// `event_time` TIMESTAMP(3),
// `partition` BIGINT,
// `offset` BIGINT,
// `user_id` BIGINT,
// `item_id` BIGINT,
// `behavior` STRING,
// `t_col3` STRING,
// `t_col4` STRING
// )
Table result3 = table.addColumns(concat($("behavior"), "alanchan").as("t_col4"));
result3.printSchema();
// (
// `event_time` TIMESTAMP(3),
// `partition` BIGINT,
// `offset` BIGINT,
// `user_id` BIGINT,
// `item_id` BIGINT,
// `behavior` STRING,
// `t_col4` STRING
// )
//执行字段添加操作。 如果添加的列名称和已存在的列名称相同,则已存在的字段将被替换。 此外,如果添加的字段里面有重复的字段名,则会使用最后一个字段。
Table result4 = result3.addOrReplaceColumns(concat($("t_col4"), "alanchan").as("t_col"));
result4.printSchema();
// (
// `event_time` TIMESTAMP(3),
// `partition` BIGINT,
// `offset` BIGINT,
// `user_id` BIGINT,
// `item_id` BIGINT,
// `behavior` STRING,
// `t_col4` STRING,
// `t_col` STRING
// )
Table result5 = result4.dropColumns($("t_col4"), $("t_col"));
result5.printSchema();
// (
// `event_time` TIMESTAMP(3),
// `partition` BIGINT,
// `offset` BIGINT,
// `user_id` BIGINT,
// `item_id` BIGINT,
// `behavior` STRING
// )
//执行字段重命名操作。 字段表达式应该是别名表达式,并且仅当字段已存在时才能被重命名。
Table result6 = result4.renameColumns($("t_col4").as("col1"), $("t_col").as("col2"));
result6.printSchema();
// (
// `event_time` TIMESTAMP(3),
// `partition` BIGINT,
// `offset` BIGINT,
// `user_id` BIGINT,
// `item_id` BIGINT,
// `behavior` STRING,
// `col1` STRING,
// `col2` STRING
// )
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(table, Row.class);
resultDS.print();
// 11> (true,+I[2023-11-01T11:00:30.183, 0, 2, 1, 1002, login])
env.execute();
}
}
本示例较多,下文是本部分示例的公共代码部分。
本部分仅仅就是用的公共对象,比如User的定义,和需要引入的包。
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.lit;
import static org.apache.flink.table.expressions.ApiExpressionUtils.unresolvedCall;
import java.time.Duration;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Over;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.BuiltInFunctionDefinitions;
import org.apache.flink.types.Row;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
public class TestTableAPIOperationDemo2 {
final static List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 25, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L)
);
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class User {
private long id;
private String name;
private int balance;
private Long rowtime;
}
}
本示例仅仅展示了group by操作,比较简单。
static void test2() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 建表
tenv.executeSql(sourceSql);
Table table = tenv.from("Alan_KafkaTable");
//和 SQL 的 GROUP BY 子句类似。 使用分组键对行进行分组,使用伴随的聚合算子来按照组进行聚合行。
Table result = table.groupBy($("user_id")).select($("user_id"), $("user_id").count().as("count(user_id)"));
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 12> (true,+I[1, 1])
env.execute();
}
使用分组窗口结合单个或者多个分组键对表进行分组和聚合。
static void test3() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
)
;
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
//使用分组窗口结合单个或者多个分组键对表进行分组和聚合。
Table result = usersTable
.window(Tumble.over(lit(5).minutes()).on($("rowtime")).as("w")) // 定义窗口
.groupBy($("name"), $("w")) // 按窗口和键分组
// 访问窗口属性并聚合
.select(
$("name"),
$("w").start(),
$("w").end(),
$("w").rowtime(),
$("balance").sum().as("sum(balance)")
);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 2> (true,+I[alan, 2023-10-31T08:50, 2023-10-31T08:55, 2023-10-31T08:54:59.999, 62])
// 16> (true,+I[alanchan, 2023-10-31T08:50, 2023-10-31T08:55, 2023-10-31T08:54:59.999, 57])
env.execute();
}
和 SQL 的 OVER 子句类似。
static void test4() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
//所有的聚合必须定义在同一个窗口上,比如同一个分区、排序和范围内。目前只支持 PRECEDING 到当前行范围(无界或有界)的窗口。
//尚不支持 FOLLOWING 范围的窗口。ORDER BY 操作必须指定一个单一的时间属性。
Table result = usersTable
// 定义窗口
.window(
Over
.partitionBy($("name"))
.orderBy($("rowtime"))
.preceding(unresolvedCall(BuiltInFunctionDefinitions.UNBOUNDED_RANGE))
.following(unresolvedCall(BuiltInFunctionDefinitions.CURRENT_RANGE))
.as("w"))
// 滑动聚合
.select(
$("id"),
$("balance").avg().over($("w")),
$("balance").max().over($("w")),
$("balance").min().over($("w"))
);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 2> (true,+I[1, 18, 18, 18])
// 16> (true,+I[4, 28, 28, 28])
// 2> (true,+I[2, 18, 19, 18])
// 16> (true,+I[5, 28, 29, 28])
// 2> (true,+I[3, 20, 25, 18])
env.execute();
}
/**
* 和 SQL DISTINCT 聚合子句类似,例如 COUNT(DISTINCT a)。
* Distinct 聚合声明的聚合函数(内置或用户定义的)仅应用于互不相同的输入值。
* Distinct 可以应用于 GroupBy Aggregation、GroupBy Window Aggregation 和 Over Window Aggregation。
* @throws Exception
*/
static void test5() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
// 按属性分组后的的互异(互不相同、去重)聚合
Table groupByDistinctResult = usersTable
.groupBy($("name"))
.select($("name"), $("balance").sum().distinct().as("sum_balance"));
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(groupByDistinctResult, Row.class);
// resultDS.print();
// 2> (true,+I[alan, 18])
// 16> (true,+I[alanchan, 28])
// 16> (false,-U[alanchan, 28])
// 2> (false,-U[alan, 18])
// 16> (true,+U[alanchan, 57])
// 2> (true,+U[alan, 37])
// 2> (false,-U[alan, 37])
// 2> (true,+U[alan, 62])
//按属性、时间窗口分组后的互异(互不相同、去重)聚合
Table groupByWindowDistinctResult = usersTable
.window(Tumble
.over(lit(5).minutes())
.on($("rowtime"))
.as("w")
)
.groupBy($("name"), $("w"))
.select($("name"), $("balance").sum().distinct().as("sum_balance"));
DataStream<Tuple2<Boolean, Row>> result2DS = tenv.toRetractStream(groupByDistinctResult, Row.class);
// result2DS.print();
// 16> (true,+I[alanchan, 28])
// 2> (true,+I[alan, 18])
// 16> (false,-U[alanchan, 28])
// 2> (false,-U[alan, 18])
// 16> (true,+U[alanchan, 57])
// 2> (true,+U[alan, 37])
// 2> (false,-U[alan, 37])
// 2> (true,+U[alan, 62])
//over window 上的互异(互不相同、去重)聚合
Table result = usersTable
.window(Over
.partitionBy($("name"))
.orderBy($("rowtime"))
.preceding(unresolvedCall(BuiltInFunctionDefinitions.UNBOUNDED_RANGE))
.as("w"))
.select(
$("name"), $("balance").avg().distinct().over($("w")),
$("balance").max().over($("w")),
$("balance").min().over($("w"))
);
DataStream<Tuple2<Boolean, Row>> result3DS = tenv.toRetractStream(result, Row.class);
result3DS.print();
// 16> (true,+I[alanchan, 28, 28, 28])
// 2> (true,+I[alan, 18, 18, 18])
// 2> (true,+I[alan, 18, 19, 18])
// 16> (true,+I[alanchan, 28, 29, 28])
// 2> (true,+I[alan, 20, 25, 18])
env.execute();
}
用户定义的聚合函数也可以与 DISTINCT 修饰符一起使用。如果计算不同(互异、去重的)值的聚合结果,则只需向聚合函数添加 distinct 修饰符即可。
Table orders = tEnv.from("Orders");
// 对 user-defined aggregate functions 使用互异(互不相同、去重)聚合
tEnv.registerFunction("myUdagg", new MyUdagg());
orders.groupBy("users")
.select(
$("users"),
call("myUdagg", $("points")).distinct().as("myDistinctResult")
);
和 SQL 的 DISTINCT 子句类似。 返回具有不同组合值的记录。
static void test6() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 25, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L),
new User(5L, "alanchan", 29, 1698742362424L)
);
DataStream<User> users = env.fromCollection(userList)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner((user, recordTimestamp) -> user.getRowtime())
);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"), $("balance"),$("rowtime").rowtime());
// Table orders = tableEnv.from("Orders");
Table result = usersTable.distinct();
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 数据集有6条记录,并且有一条是重复的,故只输出5条
// 9> (true,+I[2, alan, 19, 2023-10-31T08:52:39.396])
// 1> (true,+I[1, alan, 18, 2023-10-31T08:52:38.391])
// 13> (true,+I[3, alan, 25, 2023-10-31T08:52:40.407])
// 7> (true,+I[4, alanchan, 28, 2023-10-31T08:52:41.409])
// 13> (true,+I[5, alanchan, 29, 2023-10-31T08:52:42.424])
env.execute();
}
本部分介绍了表的join主要操作,比如内联接、外联接以及联接自定义函数等,其中时态表的联接以scala的示例进行说明。
关于自定义函数的联接将在flink 自定义函数中介绍,因为使用函数和联接本身关系不是非常密切。
19、Flink 的Table API 和 SQL 中的自定义函数(2)
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.and;
import static org.apache.flink.table.api.Expressions.call;
import java.util.Arrays;
import java.util.List;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.table.functions.TemporalTableFunction;
import org.apache.flink.types.Row;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
public class TestTableAPIJoinOperationDemo {
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class User {
private long id;
private String name;
private double balance;
private Long rowtime;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Order {
private long id;
private long user_id;
private double amount;
private Long rowtime;
}
final static List<User> userList = Arrays.asList(
new User(1L, "alan", 18, 1698742358391L),
new User(2L, "alan", 19, 1698742359396L),
new User(3L, "alan", 25, 1698742360407L),
new User(4L, "alanchan", 28, 1698742361409L),
new User(5L, "alanchan", 29, 1698742362424L)
);
final static List<Order> orderList = Arrays.asList(
new Order(1L, 1, 18, 1698742358391L),
new Order(2L, 2, 19, 1698742359396L),
new Order(3L, 1, 25, 1698742360407L),
new Order(4L, 3, 28, 1698742361409L),
new Order(5L, 1, 29, 1698742362424L),
new Order(6L, 4, 49, 1698742362424L)
);
static void testInnerJoin() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"),$("balance"),$("rowtime"));
DataStream<Order> orders = env.fromCollection(orderList);
Table ordersTable = tenv.fromDataStream(orders, $("id"), $("user_id"), $("amount"),$("rowtime"));
Table left = usersTable.select($("id").as("userId"), $("name"), $("balance"),$("rowtime").as("u_rowtime"));
Table right = ordersTable.select($("id").as("orderId"), $("user_id"), $("amount"),$("rowtime").as("o_rowtime"));
Table result = left.join(right)
.where($("user_id").isEqual($("userId")))
.select($("orderId"), $("user_id"), $("amount"),$("o_rowtime"),$("name"),$("balance"));
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 15> (true,+I[4, 3, 28.0, 1698742361409, alan, 25])
// 12> (true,+I[1, 1, 18.0, 1698742358391, alan, 18])
// 3> (true,+I[6, 4, 49.0, 1698742362424, alanchan, 28])
// 12> (true,+I[2, 2, 19.0, 1698742359396, alan, 19])
// 12> (true,+I[3, 1, 25.0, 1698742360407, alan, 18])
// 12> (true,+I[5, 1, 29.0, 1698742362424, alan, 18])
env.execute();
}
/**
* 和 SQL LEFT/RIGHT/FULL OUTER JOIN 子句类似。 关联两张表。 两张表必须有不同的字段名,并且必须定义至少一个等式连接谓词。
* @throws Exception
*/
static void testOuterJoin() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"),$("balance"),$("rowtime"));
DataStream<Order> orders = env.fromCollection(orderList);
Table ordersTable = tenv.fromDataStream(orders, $("id"), $("user_id"), $("amount"),$("rowtime"));
Table left = usersTable.select($("id").as("userId"), $("name"), $("balance"),$("rowtime").as("u_rowtime"));
Table right = ordersTable.select($("id").as("orderId"), $("user_id"), $("amount"),$("rowtime").as("o_rowtime"));
Table leftOuterResult = left.leftOuterJoin(right, $("user_id").isEqual($("userId")))
.select($("orderId"), $("user_id"), $("amount"),$("o_rowtime"),$("name"),$("balance"));
DataStream<Tuple2<Boolean, Row>> leftOuterResultDS = tenv.toRetractStream(leftOuterResult, Row.class);
// leftOuterResultDS.print();
// 12> (true,+I[null, null, null, null, alan, 18])
// 3> (true,+I[null, null, null, null, alanchan, 28])
// 12> (false,-D[null, null, null, null, alan, 18])
// 12> (true,+I[1, 1, 18.0, 1698742358391, alan, 18])
// 15> (true,+I[4, 3, 28.0, 1698742361409, alan, 25])
// 12> (true,+I[null, null, null, null, alan, 19])
// 3> (false,-D[null, null, null, null, alanchan, 28])
// 12> (false,-D[null, null, null, null, alan, 19])
// 3> (true,+I[6, 4, 49.0, 1698742362424, alanchan, 28])
// 12> (true,+I[2, 2, 19.0, 1698742359396, alan, 19])
// 12> (true,+I[3, 1, 25.0, 1698742360407, alan, 18])
// 3> (true,+I[null, null, null, null, alanchan, 29])
// 12> (true,+I[5, 1, 29.0, 1698742362424, alan, 18])
Table rightOuterResult = left.rightOuterJoin(right, $("user_id").isEqual($("userId")))
.select($("orderId"), $("user_id"), $("amount"),$("o_rowtime"),$("name"),$("balance"));
DataStream<Tuple2<Boolean, Row>> rightOuterResultDS = tenv.toRetractStream(rightOuterResult, Row.class);
// rightOuterResultDS.print();
// 12> (true,+I[1, 1, 18.0, 1698742358391, alan, 18])
// 3> (true,+I[6, 4, 49.0, 1698742362424, alanchan, 28])
// 15> (true,+I[4, 3, 28.0, 1698742361409, alan, 25])
// 12> (true,+I[2, 2, 19.0, 1698742359396, alan, 19])
// 12> (true,+I[3, 1, 25.0, 1698742360407, alan, 18])
// 12> (true,+I[5, 1, 29.0, 1698742362424, alan, 18])
Table fullOuterResult = left.fullOuterJoin(right, $("user_id").isEqual($("userId")))
.select($("orderId"), $("user_id"), $("amount"),$("o_rowtime"),$("name"),$("balance"));
DataStream<Tuple2<Boolean, Row>> fullOuterResultDS = tenv.toRetractStream(fullOuterResult, Row.class);
fullOuterResultDS.print();
// 3> (true,+I[6, 4, 49.0, 1698742362424, null, null])
// 12> (true,+I[1, 1, 18.0, 1698742358391, null, null])
// 15> (true,+I[4, 3, 28.0, 1698742361409, null, null])
// 12> (false,-D[1, 1, 18.0, 1698742358391, null, null])
// 3> (false,-D[6, 4, 49.0, 1698742362424, null, null])
// 12> (true,+I[1, 1, 18.0, 1698742358391, alan, 18])
// 3> (true,+I[6, 4, 49.0, 1698742362424, alanchan, 28])
// 3> (true,+I[null, null, null, null, alanchan, 29])
// 12> (true,+I[2, 2, 19.0, 1698742359396, null, null])
// 12> (false,-D[2, 2, 19.0, 1698742359396, null, null])
// 12> (true,+I[2, 2, 19.0, 1698742359396, alan, 19])
// 15> (false,-D[4, 3, 28.0, 1698742361409, null, null])
// 12> (true,+I[3, 1, 25.0, 1698742360407, alan, 18])
// 15> (true,+I[4, 3, 28.0, 1698742361409, alan, 25])
// 12> (true,+I[5, 1, 29.0, 1698742362424, alan, 18])
env.execute();
}
/**
* Interval join 是可以通过流模式处理的常规 join 的子集。
* Interval join 至少需要一个 equi-join 谓词和一个限制双方时间界限的 join 条件。
* 这种条件可以由两个合适的范围谓词(<、<=、>=、>)或一个比较两个输入表相同时间属性(即处理时间或事件时间)的等值谓词来定义。
* @throws Exception
*/
static void testIntervalJoin() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
DataStream<User> users = env.fromCollection(userList);
Table usersTable = tenv.fromDataStream(users, $("id"), $("name"),$("balance"),$("rowtime"));
DataStream<Order> orders = env.fromCollection(orderList);
Table ordersTable = tenv.fromDataStream(orders, $("id"), $("user_id"), $("amount"),$("rowtime"));
Table left = usersTable.select($("id").as("userId"), $("name"), $("balance"),$("rowtime").as("u_rowtime"));
Table right = ordersTable.select($("id").as("orderId"), $("user_id"), $("amount"),$("rowtime").as("o_rowtime"));
Table result = left.join(right)
.where(
and(
$("user_id").isEqual($("userId")),
$("user_id").isLess(3)
// $("u_rowtime").isGreaterOrEqual($("o_rowtime").minus(lit(5).minutes())),
// $("u_rowtime").isLess($("o_rowtime").plus(lit(10).minutes()))
)
)
.select($("orderId"), $("user_id"), $("amount"),$("o_rowtime"),$("name"),$("balance"))
;
result.printSchema();
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(result, Row.class);
resultDS.print();
// 12> (true,+I[1, 1, 18.0, 1698742358391, alan, 18.0])
// 12> (true,+I[2, 2, 19.0, 1698742359396, alan, 19.0])
// 12> (true,+I[3, 1, 25.0, 1698742360407, alan, 18.0])
// 12> (true,+I[5, 1, 29.0, 1698742362424, alan, 18.0])
env.execute();
}
/**
* join 表和表函数的结果。左(外部)表的每一行都会 join 表函数相应调用产生的所有行。
* 如果表函数调用返回空结果,则删除左侧(外部)表的一行。
* 该示例为示例性的,具体的验证将在自定义函数中进行说明
*
* @throws Exception
*/
static void testInnerJoinWithUDTF() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 注册 User-Defined Table Function
TableFunction<Tuple3<String,String,String>> split = new SplitFunction();
tenv.registerFunction("split", split);
// join
DataStream<Order> orders = env.fromCollection(orderList);
Table ordersTable = tenv.fromDataStream(orders, $("id"), $("user_id"), $("amount"),$("rowtime"));
Table result = ordersTable
.joinLateral(call("split", $("c")).as("s", "t", "v"))
.select($("a"), $("b"), $("s"), $("t"), $("v"));
env.execute();
}
/**
* join 表和表函数的结果。左(外部)表的每一行都会 join 表函数相应调用产生的所有行。
* 如果表函数调用返回空结果,则保留相应的 outer(外部连接)行并用空值填充右侧结果。
* 目前,表函数左外连接的谓词只能为空或字面(常量)真。
* 该示例为示例性的,具体的验证将在自定义函数中进行说明
*
* @throws Exception
*/
static void testLeftOuterJoinWithUDTF() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// 注册 User-Defined Table Function
TableFunction<Tuple3<String,String,String>> split = new SplitFunction();
tenv.registerFunction("split", split);
// join
DataStream<Order> orders = env.fromCollection(orderList);
Table ordersTable = tenv.fromDataStream(orders, $("id"), $("user_id"), $("amount"),$("rowtime"));
Table result = ordersTable
.leftOuterJoinLateral(call("split", $("c")).as("s", "t", "v"))
.select($("a"), $("b"), $("s"), $("t"), $("v"));
env.execute();
}
/**
* Temporal table 是跟踪随时间变化的表。
* Temporal table 函数提供对特定时间点 temporal table 状态的访问。
* 表与 temporal table 函数进行 join 的语法和使用表函数进行 inner join 的语法相同。
* 目前仅支持与 temporal table 的 inner join。
*
* @throws Exception
*/
static void testJoinWithTemporalTable() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
Table ratesHistory = tenv.from("RatesHistory");
// 注册带有时间属性和主键的 temporal table function
TemporalTableFunction rates = ratesHistory.createTemporalTableFunction(
$("r_proctime"),
$("r_currency")
);
tenv.registerFunction("rates", rates);
// 基于时间属性和键与“Orders”表关联
Table orders = tenv.from("Orders");
Table result = orders
.joinLateral(call("rates", $("o_proctime")), $("o_currency").isEqual($("r_currency")));
env.execute();
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// testInnerJoin();
// testOuterJoin();
// testIntervalJoin();
testInnerJoinWithUDTF();
}
static class SplitFunction extends TableFunction<Tuple3<String,String,String>>{
public void eval(Tuple3<String,String,String> tp) {
// for (String s : str.split(",")) {
// // use collect(...) to emit a row
collect(Row.of(s, s.length()));
// }
}
}
}
该示例来源于:https://developer.aliyun.com/article/679659
假设有一张订单表Orders和一张汇率表Rates,那么订单来自于不同的地区,所以支付的币种各不一样,那么假设需要统计每个订单在下单时候Yen币种对应的金额。
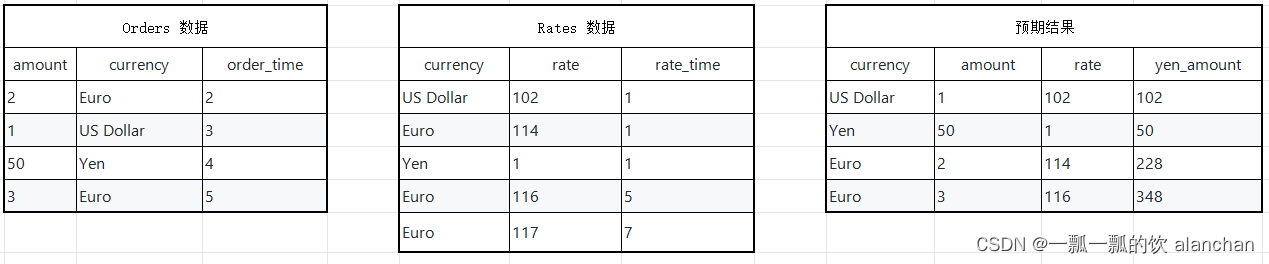
SELECT o.currency, o.amount, r.rate
o.amount * r.rate AS yen_amount
FROM
Orders AS o,
LATERAL TABLE (Rates(o.rowtime)) AS r
WHERE r.currency = o.currency
object TemporalTableJoinTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = TableEnvironment.getTableEnvironment(env)
env.setParallelism(1)
// 设置时间类型是 event-time env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 构造订单数据
val ordersData = new mutable.MutableList[(Long, String, Timestamp)]
ordersData.+=((2L, "Euro", new Timestamp(2L)))
ordersData.+=((1L, "US Dollar", new Timestamp(3L)))
ordersData.+=((50L, "Yen", new Timestamp(4L)))
ordersData.+=((3L, "Euro", new Timestamp(5L)))
//构造汇率数据
val ratesHistoryData = new mutable.MutableList[(String, Long, Timestamp)]
ratesHistoryData.+=(("US Dollar", 102L, new Timestamp(1L)))
ratesHistoryData.+=(("Euro", 114L, new Timestamp(1L)))
ratesHistoryData.+=(("Yen", 1L, new Timestamp(1L)))
ratesHistoryData.+=(("Euro", 116L, new Timestamp(5L)))
ratesHistoryData.+=(("Euro", 119L, new Timestamp(7L)))
// 进行订单表 event-time 的提取
val orders = env
.fromCollection(ordersData)
.assignTimestampsAndWatermarks(new OrderTimestampExtractor[Long, String]())
.toTable(tEnv, 'amount, 'currency, 'rowtime.rowtime)
// 进行汇率表 event-time 的提取
val ratesHistory = env
.fromCollection(ratesHistoryData)
.assignTimestampsAndWatermarks(new OrderTimestampExtractor[String, Long]())
.toTable(tEnv, 'currency, 'rate, 'rowtime.rowtime)
// 注册订单表和汇率表
tEnv.registerTable("Orders", orders)
tEnv.registerTable("RatesHistory", ratesHistory)
val tab = tEnv.scan("RatesHistory");
// 创建TemporalTableFunction
val temporalTableFunction = tab.createTemporalTableFunction('rowtime, 'currency)
//注册TemporalTableFunction
tEnv.registerFunction("Rates",temporalTableFunction)
val SQLQuery =
"""
|SELECT o.currency, o.amount, r.rate,
| o.amount * r.rate AS yen_amount
|FROM
| Orders AS o,
| LATERAL TABLE (Rates(o.rowtime)) AS r
|WHERE r.currency = o.currency
|""".stripMargin
tEnv.registerTable("TemporalJoinResult", tEnv.SQLQuery(SQLQuery))
val result = tEnv.scan("TemporalJoinResult").toAppendStream[Row]
// 打印查询结果
result.print()
env.execute()
}
}
import java.SQL.Timestamp
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.windowing.time.Time
class OrderTimestampExtractor[T1, T2]
extends BoundedOutOfOrdernessTimestampExtractor[(T1, T2, Timestamp)](Time.seconds(10)) {
override def extractTimestamp(element: (T1, T2, Timestamp)): Long = {
element._3.getTime
}
}
在实际的生产开发中,都需要实际的Connector的定义,下面我们以CSV格式的Connector定义来开发Temporal Table JOIN Demo。
1、genEventRatesHistorySource
def genEventRatesHistorySource: CsvTableSource = {
val csvRecords = Seq(
"ts#currency#rate",
"1#US Dollar#102",
"1#Euro#114",
"1#Yen#1",
"3#Euro#116",
"5#Euro#119",
"7#Pounds#108"
)
// 测试数据写入临时文件
val tempFilePath =
FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_rate", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("ts","currency","rate"),
Array(
Types.LONG,Types.STRING,Types.LONG
),
fieldDelim = "#",
rowDelim = CommonUtils.line,
ignoreFirstLine = true,
ignoreComments = "%"
)
}
2、genRatesOrderSource
def genRatesOrderSource: CsvTableSource = {
val csvRecords = Seq(
"ts#currency#amount",
"2#Euro#10",
"4#Euro#10"
)
// 测试数据写入临时文件
val tempFilePath =
FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_order", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("ts","currency", "amount"),
Array(
Types.LONG,Types.STRING,Types.LONG
),
fieldDelim = "#",
rowDelim = CommonUtils.line,
ignoreFirstLine = true,
ignoreComments = "%"
)
}
3、主程序
import java.io.File
import org.apache.flink.api.common.typeinfo.{TypeInformation, Types}
import org.apache.flink.book.utils.{CommonUtils, FileUtils}
import org.apache.flink.table.sinks.{CsvTableSink, TableSink}
import org.apache.flink.table.sources.CsvTableSource
import org.apache.flink.types.Row
object CsvTableSourceUtils {
def genWordCountSource: CsvTableSource = {
val csvRecords = Seq(
"words",
"Hello Flink",
"Hi, Apache Flink",
"Apache FlinkBook"
)
// 测试数据写入临时文件
val tempFilePath =
FileUtils.writeToTempFile(csvRecords.mkString("$"), "csv_source_", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("words"),
Array(
Types.STRING
),
fieldDelim = "#",
rowDelim = "$",
ignoreFirstLine = true,
ignoreComments = "%"
)
}
def genRatesHistorySource: CsvTableSource = {
val csvRecords = Seq(
"rowtime ,currency ,rate",
"09:00:00 ,US Dollar , 102",
"09:00:00 ,Euro , 114",
"09:00:00 ,Yen , 1",
"10:45:00 ,Euro , 116",
"11:15:00 ,Euro , 119",
"11:49:00 ,Pounds , 108"
)
// 测试数据写入临时文件
val tempFilePath =
FileUtils.writeToTempFile(csvRecords.mkString("$"), "csv_source_", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("rowtime","currency","rate"),
Array(
Types.STRING,Types.STRING,Types.STRING
),
fieldDelim = ",",
rowDelim = "$",
ignoreFirstLine = true,
ignoreComments = "%"
)
}
def genEventRatesHistorySource: CsvTableSource = {
val csvRecords = Seq(
"ts#currency#rate",
"1#US Dollar#102",
"1#Euro#114",
"1#Yen#1",
"3#Euro#116",
"5#Euro#119",
"7#Pounds#108"
)
// 测试数据写入临时文件
val tempFilePath =
FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_rate", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("ts","currency","rate"),
Array(
Types.LONG,Types.STRING,Types.LONG
),
fieldDelim = "#",
rowDelim = CommonUtils.line,
ignoreFirstLine = true,
ignoreComments = "%"
)
}
def genRatesOrderSource: CsvTableSource = {
val csvRecords = Seq(
"ts#currency#amount",
"2#Euro#10",
"4#Euro#10"
)
// 测试数据写入临时文件
val tempFilePath =
FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_order", "tmp")
// 创建Source connector
new CsvTableSource(
tempFilePath,
Array("ts","currency", "amount"),
Array(
Types.LONG,Types.STRING,Types.LONG
),
fieldDelim = "#",
rowDelim = CommonUtils.line,
ignoreFirstLine = true,
ignoreComments = "%"
)
}
/**
* Example:
* genCsvSink(
* Array[String]("word", "count"),
* Array[TypeInformation[_] ](Types.STRING, Types.LONG))
*/
def genCsvSink(fieldNames: Array[String], fieldTypes: Array[TypeInformation[_]]): TableSink[Row] = {
val tempFile = File.createTempFile("csv_sink_", "tem")
if (tempFile.exists()) {
tempFile.delete()
}
new CsvTableSink(tempFile.getAbsolutePath).configure(fieldNames, fieldTypes)
}
}
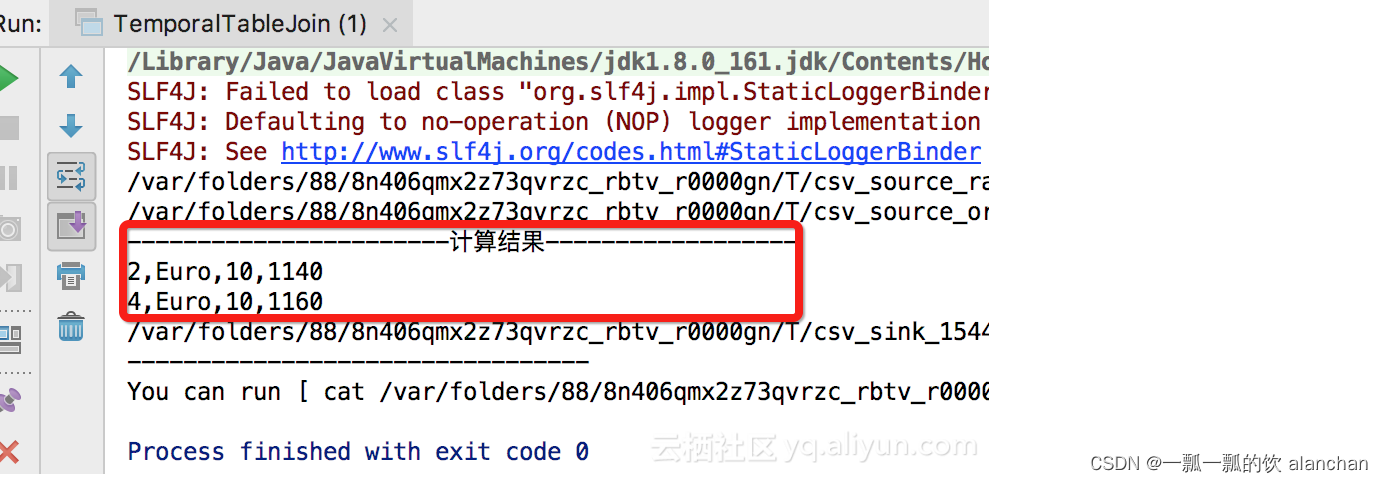
4、运行结果
以上,本文介绍了通过Table API和SQL创建表、视图以及查询示例,同时介绍了Table API 操作表的列、聚合、join操作。
如果需要了解更多内容,可以在本人
Flink 专栏
中了解更新系统的内容。
本文更详细的内容可参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
本专题分为以下几篇文章:
【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表
【flink番外篇】9、Flink Table API 支持的操作示例(2)- 通过Table API 和 SQL 创建视图
【flink番外篇】9、Flink Table API 支持的操作示例(3)- 通过API查询表和使用窗口函数的查询
【flink番外篇】9、Flink Table API 支持的操作示例(4)- Table API 对表的查询、过滤操作
【flink番外篇】9、Flink Table API 支持的操作示例(5)- 表的列操作
【flink番外篇】9、Flink Table API 支持的操作示例(6)- 表的聚合(group by、Distinct、GroupBy/Over Window Aggregation)操作
【flink番外篇】9、Flink Table API 支持的操作示例(7)- 表的join操作(内联接、外联接以及联接自定义函数等)
【flink番外篇】9、Flink Table API 支持的操作示例(8)- 时态表的join(scala版本)
【flink番外篇】9、Flink Table API 支持的操作示例(9)- 表的union、unionall、intersect、intersectall、minus、minusall和in的操作
【flink番外篇】9、Flink Table API 支持的操作示例(10)- 表的OrderBy、Offset 和 Fetch、insert操作
【flink番外篇】9、Flink Table API 支持的操作示例(11)- Group Windows(tumbling、sliding和session)操作
【flink番外篇】9、Flink Table API 支持的操作示例(12)- Over Windows(有界和无界的over window)操作
【flink番外篇】9、Flink Table API 支持的操作示例(13)- Row-based(map、flatmap、aggregate、group window aggregate等)操作
【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
【flink番外篇】9、Flink Table API 支持的操作示例(1)-完整版
【flink番外篇】9、Flink Table API 支持的操作示例(2)-完整版