计划完成深度学习入门的126篇论文第二十三篇,UT的Alex Graves等领导研究通过LSTM来生成不同风格的文本和手写体handwriting。
ABSTRACT&INTRODUCTION
摘要
本文通过对一个数据点的预测,说明了LSTM怎样生成具有长期结构的复杂序列。该方法适用于文本(数据是离散的)和在线手写(数据是实值的)。然后,它被扩展到手写合成,通过允许网络对文本序列的预测设定条件。由此产生的系统能够生成多种风格的高度逼真的草书手写体。
介绍
递归神经网络(RNNs)是一类丰富的动态模型,已被用于生成各种领域的序列,如音乐[6,4]、文本[30]和运动捕捉数据[29]。RNNs可以通过一步一步地处理真实数据序列并预测接下来会发生什么来训练序列生成。假设预测是概率性的,通过对网络输出分布进行迭代采样,然后将样本作为下一步的输入,从训练好的网络中生成新的序列。换句话说,让网络把它的发明当作是真实的,就像一个人在做梦一样。虽然网络本身是确定性的,但采样注入的随机性导致了序列上的分布。这种分布是有条件的,因为网络的内部状态(因此其预测分布)依赖于以前的输入。
RNNs是模糊的,因为它们不使用训练数据中的精确模板来进行预测,而是像其他神经网络一样,使用它们的内部表示来在训练实例之间执行高维插值。这与部分匹配的[5]预测等n-gram模型和压缩算法不同,例如Partial Matching[5]的预测分布是通过计算最近历史与训练集之间的精确匹配来确定的从本文的样本中可以看出,RNNs(不像基于模板的算法)以一种复杂的方式对训练数据进行合成和重构,很少生成相同的东西两次。此外,模糊预测不受维数的诅咒,因此在建模实值或多元数据方面比精确匹配要好得多。
原则上,一个足够大的RNN应该足以生成任意复杂度的序列。然而,在实践中,对于长时间过去的输入,标准的RNNs无法存储大量数据[15]。这种“健忘症”“amnesia”不仅降低了他们对长期结构建模的能力,还使他们在生成序列时容易出现不稳定性。问题是(所有条件生成模型都存在的问题),如果网络的预测只基于最后几个输入,而这些输入本身就是由网络预测的,那么它就几乎没有机会从过去的错误中恢复过来。拥有更长的记忆有一个稳定的效果,因为即使网络不能理解它最近的历史,它可以回顾过去来制定它的预测。对于实值数据,不稳定性问题尤其严重,在实值数据中,预测很容易偏离训练数据所在的流形。对条件模型提出的一种补救方法是,在将预测反馈到模型[31]之前,将噪声注入预测,从而提高模型s对意外输入的鲁棒性。然而,我们相信更好的记忆是一个更深刻和有效的解决方案。
长短时记忆(LSTM)[16]是一种RNN结构,它比标准的RNNs更适合于存储和访问信息。LSTM最近在一系列序列处理任务中给出了最先进的结果,包括语音和手写识别[10,12]。本文的主要目的是证明LSTM可以利用它的内存生成包含长时间结构的复杂、真实的序列。
第2节定义了一个由多层LSTM层组成的深度RNN,并解释了如何训练它进行下一步预测,从而生成序列。第三部分将预测网络应用于来自Penn Treebank和Hutter Prize Wikipedia数据集的文本。该网络的性能与最先进的语言模型具有竞争力,它在一次预测一个字符和预测一个单词时几乎同样有效。本节的重点是生成的Wikipedia文本示例,它展示了网络建模长期依赖关系的能力。第4节演示了预测网络如何通过混合密度输出层应用于实值数据,并在IAM在线手写数据库上提供了实验结果。它还提供了生成的手写样本,证明了该网络能够直接从手写轨迹学习字母和短单词,并对手写风格的全局特征进行建模。第5节介绍了对预测网络的扩展,该扩展允许预测网络将其输出设置在一个短注释序列上,该短注释序列与预测的一致性是未知的。这使得它适合于手写合成,在手写合成中,人类用户输入文本,算法生成手写文本。综合网络在IAM数据库上进行训练,生成草书笔迹样本,其中部分样本无法与裸眼的真实数据进行区分。描述了一种将样本偏向于更高概率(和更清晰性)的方法,以及一种将样本“启动”于真实数据的技术,从而模仿特定作者的风格。最后,第六节给出结论和今后工作的方向。
2 Prediction Network
图1给出了本文所采用的基本递归神经网络预测体系结构。一个输入向量序列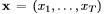 通过加权连接被传递到一个由N个递归连接的隐层堆栈中,首先计算隐向量序列
通过加权连接被传递到一个由N个递归连接的隐层堆栈中,首先计算隐向量序列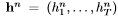 输出向量序列
输出向量序列 每个输出向量
每个输出向量 用于参数化一个预测分布
用于参数化一个预测分布 对可能的下一个输入
对可能的下一个输入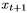 。每个输入序列的第一个元素
。每个输入序列的第一个元素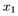 总是一个零向量,它的所有项都是零;因此,网络发出
总是一个零向量,它的所有项都是零;因此,网络发出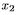 的预测,这是第一个真实的输入,没有先验信息。网络在空间和时间上都很深,在这个意义上,通过计算图垂直或水平传递的每条信息都将受到多个连续的权重矩阵和非线性的作用。
的预测,这是第一个真实的输入,没有先验信息。网络在空间和时间上都很深,在这个意义上,通过计算图垂直或水平传递的每条信息都将受到多个连续的权重矩阵和非线性的作用。

注意从输入到所有隐藏层的“跳过连接”,以及从所有隐藏层到输出的“跳过连接”。这使得训练深层网络更加容易,通过减少网络底部和顶部之间的处理步骤的数量,从而减轻“消失梯度”问题[1]。在N = 1的特殊情况下,该结构简化为一个普通的单层下一步预测RNN。
隐层激活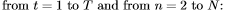
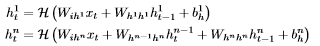
W表示的矩阵的权重(例如 是矩阵权重连接输入第n个隐藏层,
是矩阵权重连接输入第n个隐藏层,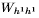 是复发性连接在第一个隐藏层,等等),b表示偏差向量(例如输出偏差向量)和H是隐藏层的功能。
是复发性连接在第一个隐藏层,等等),b表示偏差向量(例如输出偏差向量)和H是隐藏层的功能。
给定隐藏序列,计算输出序列如下:

其中Y为输出层函数。因此,整个网络定义了一个由权重矩阵参数化的函数,从输入历史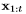 到输出向量
到输出向量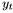 。
。
输出向量用于参数化下一个输入的预测分布 。必须仔细选择
。必须仔细选择 的形式来匹配输入数据。特别是,为高维实值数据(通常称为密度模型)找到一个好的预测分布是非常具有挑战性的。
的形式来匹配输入数据。特别是,为高维实值数据(通常称为密度模型)找到一个好的预测分布是非常具有挑战性的。
由网络给出的输入序列x的概率为
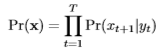
用于训练网络的序列损失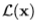 为
为 的负对数:
的负对数:
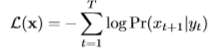
在图1所示的计算图上应用高效计算反向传播[33],可以有效地计算出损失对网络权值的偏导数,然后用梯度下降法对网络进行训练。
2.1 Long Short-Term Memory
在大多数RNNs中,隐层函数H是sigmoid函数的基本应用。然而,我们发现,长期的短期记忆(LSTM)架构[16]使用专门构建的内存单元来存储信息,它更善于发现和利用数据中的长期依赖关系。

图2显示了单个LSTM存储单元。对于本文使用的LSTM版本,[7]H通过以下复合函数实现:

 是sigmoid函数,d i, f, o and c 分别代表input gate, forget gate, output gate, cell and cell input ,所有都与隐藏向量h是同样大小。权重矩阵下标有明显的意义,例如
是sigmoid函数,d i, f, o and c 分别代表input gate, forget gate, output gate, cell and cell input ,所有都与隐藏向量h是同样大小。权重矩阵下标有明显的意义,例如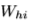 隐藏输入门矩阵,
隐藏输入门矩阵,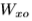 输入-输出门矩阵等。从单元格到gate向量(例如
输入-输出门矩阵等。从单元格到gate向量(例如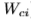 )的权重矩阵是对角的,因此每个gate向量中的元素m只接收单元格向量的元素m的输入。为了清晰起见,省略了偏置项(添加到i、f、c和o中)。
)的权重矩阵是对角的,因此每个gate向量中的元素m只接收单元格向量的元素m的输入。为了清晰起见,省略了偏置项(添加到i、f、c和o中)。
原始的LSTM算法使用了自定义设计的近似梯度计算,允许在每一步[16]之后更新权值。然而,本文所采用的方法是通过时间的反向传播来计算全梯度[11]。在训练全梯度LSTM时,一个困难是导数有时会变得过大,导致数值问题。为了防止这种情况的发生,本文中的所有实验都将LSTM层(在应用sigmoid和tanh函数之前)的网络输入的损耗导数裁剪为位于预定义范围内。
3 Text Prediction
文本数据是离散的,通常使用“one-hot”输入向量呈现给神经网络。也就是说,如one-hot总共有K个文本类,并且类K在t时刻输入,那么xt就是一个长度为K的向量,除了第K个元素是1外,其他元素都是0。 是一个多项式分布,可以在输出层自然地用softmax函数参数化:
是一个多项式分布,可以在输出层自然地用softmax函数参数化:

代入式(6),可以看到
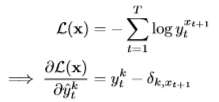
唯一需要决定的是使用哪一组类。在大多数情况下,文本预测(通常称为语言建模)是在单词级执行的。因此K是字典中的单词数。对于实际的任务,这可能会有问题,因为单词的数量(包括不同的词形变化、专有名称等)常常超过100,000。除了需要许多参数来建模外,拥有如此多的类还需要大量的训练数据来充分覆盖单词的可能上下文。在softmax模型的情况下,另一个困难是在训练期间评估所有指数的计算成本很高(尽管已经设计了几种方法来提高训练大型softmax层的效率,包括基于树的模型[25,23]、低秩近似[27]和随机导数[26])。此外,单词级模型不适用于包含非单词字符串的文本数据,例如多位数数字或web地址。
使用神经网络的字符级语言建模最近被[30,24]发现其性能略低于等价的单词级模型。尽管如此,从序列生成的角度来看,一次预测一个字符更有趣,因为它允许网络创建新的单词和字符串。一般来说,本文的实验旨在预测数据中发现的最细粒度,从而最大化网络的生成灵活性。
3.1 Penn Treebank Experiments
第一组文本预测实验集中在《华尔街日报》语料库[22]的Penn Treebank部分。这是一个初步的研究,其主要目的是衡量网络的预测能力,而不是生成有趣的序列。
尽管相对较小的文本语料库(总共超过100万个单词),Penn Treebank的数据被广泛用作语言建模的基准。训练集93万字,验证集7.4万字,测试集8.2万字。词汇表被限制为10,000个单词,所有其他单词都映射到一个特殊的未知单词标记。将句末标记包含在输入序列中,并将其计算在序列丢失中。句子开始标记被忽略,因为它的作用已经由开始序列的空向量完成(c.f。Section 2)。
在这两种情况下,网络架构都是一个包含1000个LSTM单元的单层隐藏层。对于字符级网络,输入和输出层的大小为49,总共给出了大约430万的权重,而单词级网络有10,000个输入和输出,权重大约为5400万。因此,这种比较有点不公平,因为字级网络有更多的参数。然而,由于数据集较小,这两个网络都很容易对训练数据进行过度拟合,而且不清楚字符级网络是否会从更大的权重中获益。所有网络均采用随机梯度下降训练,学习率为0.0001,动量为0.99。LSTM衍生物的剪切范围为[1,1](c.f。第2.1节)。
神经网络通常是在具有固定权重的测试数据上进行评估的。然而,对于输入是目标的预测问题,允许网络在评估时调整其权重是合理的(只要它只看到测试数据一次)。Mikolov将其称为动态评估。动态评估允许与压缩算法进行更公平的比较,压缩算法没有训练集和测试集之间的划分,因为所有数据只预测一次。
因为网络overfit训练数据,我们也尝试两种regularisation:权重噪声[18]标准偏差为0.075应用于网络权值在每个训练序列的开始,权重和自适应噪声[8],噪声的方差在哪里学习使用最小描述长度随着重量损失函数(或等价变分推理)。当使用权值噪声时,网络初始化为非正则化网络的最终权值。同样地,当使用自适应权值噪声时,权值与使用权值噪声训练的网络的权值初始化。我们发现,使用迭代增加正则化的再训练要比使用正则化的随机权重训练快得多。自适应权值噪声在词级网络中速度慢得令人望而却步,因此只能用固定方差权值噪声对其进行正则化。自适应权重的一个优点是不需要提前停止(网络可以在训练数据的最小总描述长度处安全停止)。然而,为了保持比较的公平性,所有的实验都使用相同的训练、验证和测试集。
结果用两个等价的度量标准表示:每字符位(BPC),即 在整个测试集上的平均值;perplexity是2的2次方,表示每个单词的平均比特数(测试集中单词的平均长度约为5.6个字符,所以perplexity为
在整个测试集上的平均值;perplexity是2的2次方,表示每个单词的平均比特数(测试集中单词的平均长度约为5.6个字符,所以perplexity为 )。perplexity 是语言建模的常用性能度量。
)。perplexity 是语言建模的常用性能度量。

表1显示,单词级RNN的性能优于字符级网络,但是当使用正则化时,这种差距似乎缩小了。总的来说,这些结果与Tomas Mikolov的论文[23]中收集到的结果相比是比较好的。例如,他记录了一个5-gram KeyserNey平滑的复杂度为141,一个单词级前馈神经网络的复杂度为141.8,最先进的压缩算法PAQ8的复杂度为131.1,一个动态评估的单词级RNN的复杂度为123.2。然而,通过将多个RNNs、一个5-gram的内存模型和一个缓存模型组合在一起,他可以得到一个令人困惑的89.4。有趣的是,动态评估的好处在这里比在Mikolov的论文中更明显(他记录了一个令人困惑的改进,从124.7到123.2的单词级RNNs)。这表明LSTM比普通RNNs更善于快速适应新数据。
3.2 Wikipedia Experiments
在2006年,Marcus Hutter, Jim Bowery和Matt Mahoney组织了下面的挑战,通常被称为Hutter奖[17]:压缩完整的英文维基百科数据的前1亿字节(就像2006年3月3日的某个时间)到一个尽可能小的文件。该文件不仅必须包含压缩数据,还必须包含实现压缩算法的代码。因此,它的大小可以被认为是使用两部分编码方案测量数据的最小描述长度[13]。
从序列生成的角度来看,维基百科的数据很有趣,因为它不仅包含了大量的字典单词,而且还包含了许多传统上用于语言建模的文本语料库中不包含的字符序列。例如,外来词(包括来自非拉丁字母的字母,如阿拉伯语和中文)、缩进的XML标记用于定义元数据、网站地址,以及用于指示页面格式(如标题、项目符号等)的标记。Hutter prize数据集的摘录如图3和图4所示。


数据中的前96M字节被均匀地分割成100字节的序列,用于训练网络,其余4M用于验证。数据总共包含205个单字节unicode符号。字符的总数要高得多,因为许多字符(尤其是来自非拉丁语言的字符)被定义为多符号序列。根据对数据中有意义的最小单位建模的原则,网络每次预测一个字节,因此大小为205个输入和输出层。
维基百科包含长期的规律,比如文章的主题,可以跨越数千个单词。为了使网络能够捕获这些,它的内部状态(即隐藏层的输出激活ht和层内LSTM细胞的激活ct)仅每100个序列重置一次。此外,序列的顺序在训练过程中没有打乱,通常是对神经网络。因此,在过去进行预测时,该网络能够访问多达10K个字符的信息。错误项仅反向传播到每个100字节序列的开始,这意味着梯度计算是近似的。这种形式的截断反向传播以前被用于RNN语言建模[23],并被发现在不影响网络学习长期依赖关系的能力的情况下,可以加快训练(通过减少序列长度,从而增加随机权值更新的频率)。
该数据使用了一个比Penn数据大得多的网络(反映了训练集更大的规模和复杂性),其中包含7层隐藏的700个LSTM单元,给出了大约2130万的权重。该网络采用随机梯度下降训练,学习率为0.0001,动量为0.9。经过了四个训练时代的交汇。LSTM衍生物被剪切在[1,1]范围内。
与Penn的数据一样,我们在验证数据上测试了网络,包括动态评估和非动态评估(其中权重随着数据的预测而更新)。从表2可以看出,动态评估的性能要好得多。这可能是因为维基百科数据的长期一致性;例如,某些词汇在某些文章中出现的频率要比其他词汇高得多,能够在评估期间适应这些词汇是有利的。看起来奇怪,验证动态结果集大大优于在训练集上。但是这很容易解释为两个因素:首先,网络underfit训练数据,第二部分的数据是比其他人更加困难(例如,纯文本更难预测比XML标签)。

把结果放在背景下来看,目前的 Hutter Prize 得主(PAQ-8压缩算法[20]的变体)达到1.28 BPC相同的数据(包括所需的代码来实现算法),主流压缩机等邮政通常得到超过2,和一个人物等级RNN应用于数据的文本版本(即所有的XML标记标签等删除)1.54实现了数据,提高到1.47 RNN时结合最大熵模型[24]。
由预测网络生成的四页样本如图5 - 8所示。样本表明,该网络从数据中学习了很多结构,范围很广,范围不同。最明显的是,它已经学习了大量的字典词汇,以及一个子单词模型,使它能够发明看起来可行的单词和名称:例如Lochroom River、Mughal Ralvaldens、submandration、swalloped。它还学习了基本的标点符号,逗号、句号和段落断句在文本块中以大致正确的节奏出现。
能够正确地打开和关闭引号和圆括号是语言模型s内存的一个清晰指示器,因为不能从中间文本预测闭包,因此不能使用较短的上下文[30]建模。示例显示,网络不仅能够平衡圆括号和引号,还能够平衡格式化标记(如用于表示标题的等号),甚至能够平衡嵌套的XML标记和缩进。
网络生成非拉丁字符如斯拉夫字母,中文和阿拉伯语,似乎学到了基本的模型除英语之外的其他语言(如生成es: Geotnia slago西班牙语版的一篇文章,并用荷兰语问:nl:Rodenbaueri),这看起来也会产生令人信服的互联网地址(似乎没有真正的)。
网络生成不同的大型区域,比如XML头、项目符号列表和文章文本。与图3和图4的比较表明,这些区域相当准确地反映了真实数据的构成(尽管生成的版本往往更短,而且更混乱)。这很重要,因为每个区域可能跨越数百甚至数千个时间步长。网络能够在如此大的时间间隔内保持一致(甚至以近似正确的顺序排列区域,例如在文章开头有标题,在文章末尾有项目符号,参见列表),这证明了它的长期记忆。
与所有由语言模型生成的文本一样,该示例在短语级别之外没有任何意义。现实主义也许可以通过更大的网络和/或更多的数据得到改善。然而,指望一台从未接触过语言所指的感官世界的机器说出有意义的语言似乎是徒劳的。最后,在提取过程中可以清楚地观察到网络对训练过程中最近序列的适应性(这使得网络能够从动态评估中受益)。在训练集结束之前的最后一篇完整的文章是关于洲际弹道导弹的。从大量的导弹相关术语可以看出本文对网络语言模型的影响。最近的话题还包括个人无政府主义、意大利作家伊塔洛·卡尔维诺和国际标准化组织(ISO),所有这些都在网络词汇中有所体现。
4 Handwriting Prediction
为了测试预测网络是否也可以用来生成令人信服的实值序列,我们将其应用到在线手写数据中(在这种情况下,在线意味着书写被记录为笔尖位置的序列,而离线手写则只有页面图像可用)。由于其低维性(每个数据点两个实数)和易于可视化,在线手写是序列生成的一个有吸引力的选择。
本文所用数据均来自IAM在线手写数据库(IAM- ondb)[21]。IAM-OnDB由使用智能白板从221位不同作者那里收集的手写行组成。作家们被要求写来自Lancaster-Oslo-Bergen文本语料库[19]的表格,他们的笔的位置通过黑板角落里的红外线设备进行跟踪。训练数据的样本如图9所示。原始的输入数据包括x和y笔的坐标,以及当笔从白板上拿起时顺序中的点。记录x、y数据中的错误,通过插值来填补缺失的读数,并删除长度超过一定阈值的步骤来纠正。除此之外,没有使用预处理,网络被训练来预测x,y坐标和 endof-stroke 标记点一次一个点。这与依赖于复杂预处理和特征提取技术的手写识别和合成方法形成了鲜明对比。我们避免使用这样的技术,因为它们倾向于减少我们希望网络建模的数据的变化(例如,通过标准化字符大小、倾斜、倾斜等等)。预测笔的轨迹是一次一个点,这给了网络创造新笔迹的最大灵活性,但也需要大量的内存,平均每个字母占用25个以上的时间步长,平均一行占用700左右。预测延迟的笔画(比如is上的点或ts上的叉,这些笔画是在单词的其余部分写完之后添加的)尤其困难。
IAM-OnDB分为一个训练集、两个验证集和一个测试集,分别包含从775、192、216和544个表单中提取的5364、1438、1518和3859个手写行。在我们的实验中,每一行都被视为一个单独的序列(这意味着连续行之间可能的依赖关系被忽略)。为了使训练数据的量最大化,我们使用了训练集、测试集和较大的验证集来进行训练,较小的验证集用于早期停止。缺乏独立的测试集意味着所记录的结果可能在验证集上有些过拟合;然而,验证结果是次要的,因为没有基准测试结果存在,主要目标是生成令人信服的笔迹。
将预测网络应用于在线手写数据的主要挑战是确定一个适用于实值输入的预测分布。下面的部分描述了如何实现这一点。

4.1 Mixture Density Outputs
混合密度网络[2,3]的思想是利用神经网络的输出参数化混合分布。输出的子集用于定义混合权重,其余输出用于参数化单独的混合组件。混合重量与softmax函数输出正常,确保它们形成一个有效的离散分布,和其他的输出是通过合适的函数来保持它们的值有意义的范围内(例如指数函数通常用于输出作为尺度参数,必须积极)。通过最大限度地提高目标在诱导分布下的对数概率密度,训练混合密度网络。注意,密度是标准化的(达到一个固定的常数),因此可以直接从有限的玻尔兹曼机[14]和其他无向模型中区分和选择无偏样本。
混合密度输出也可用于递归神经网络[28]。在这种情况下,输出分布不仅取决于当前输入,而且取决于以前输入的历史。直观地说,组件的数量就是给定到目前为止的输入,网络对下一个输出有多少个选择。
对于本文的笔迹实验,基本的RNN结构和更新方程与第2节保持不变。每个输入向量xt由一对实值x1, x2,定义了笔抵消从之前的输入;连同一个二进制x3,值1是如果向量stroke (也就是说,如果笔在记录下一个向量之前被从黑板上拿开),值0代表其他。用二元高斯混合预测x1和x2,用伯努利分布预测x3。每个输出向量 因此包括stroke的概率e,连同一套意味着 means µj, standard deviations σj, correlations ρj and mixture weights πj的混合组件。这是
因此包括stroke的概率e,连同一套意味着 means µj, standard deviations σj, correlations ρj and mixture weights πj的混合组件。这是
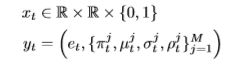
注意,均值和标准差是二维向量,而分量权重、相关性和行程结束概率是标量。向量输出都来自网络


给定输出向量 ,下一个输入
,下一个输入 的概率密度
的概率密度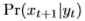 定义为:
定义为:


将其代入式(6),确定序列损失(直到一个常数,该常数仅依赖于数据的量化,不影响网络训练):
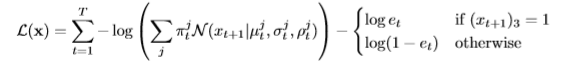
损失对行程结束输出的导数很简单:

导数对混合物密度输出可以找到首先定义组件 :
:
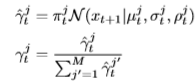

图10为用于在线手写预测的混合密度输出层的运行情况。

从密度图中可以看到两种类型的预测:拼出字母的小点是笔画正在书写时的预测,三个大点是笔画末尾对下一笔画第一点的预测。笔划结束预测的方差要大得多,因为笔离开白板时没有记录笔的位置,因此在一次笔划结束和下一次笔划开始之间可能有很大的距离。
底部的热图显示了相同顺序下混合组分的权重。这里也可以看到冲程结束,最活跃的组件在三个位置关闭,其他组件打开:显然,冲程结束预测使用的是一组与冲程内预测不同的混合组件。
4.2 Experiments
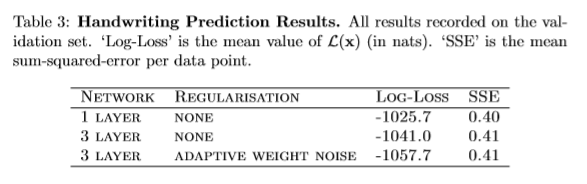
数据序列中的每个点由三个数字组成:与前一个点的x和y偏移量,以及二进制行程结束特性。因此,网络输入层的大小为3。坐标偏移量在训练集上归一化为均值0,std. dev. 1。使用20个混合分量对偏移量进行建模,每个时间步共给出120个混合参数(20个权重、40个平均值、40个标准差和20个相关性)。进一步的参数被用来建模行程结束的概率,给出了一个121的输出层。比较了两种隐含层的网络结构:一种是三个隐含层,每个包含400个LSTM单元,另一种是一个包含900个LSTM单元的单层隐含层。这两个网络的权重都在340万左右。采用自适应权值噪声[8]对三层网络进行再训练,所有层均采用std. devs。初始化到0.075。用固定方差权值噪声训练被证明是无效的,可能是因为它阻止了混合密度层使用精确指定的权值。

表3显示,三层网络的每序列平均损失比一层网络低15.3 nat。而单层网络的平方和误差略低。相对于非正则化的三层网络,使用自适应权值噪声降低了16.7nats的损失,但并没有显著改变平方和误差。自适应权值噪声网络似乎产生了最好的样本。
4.3 Samples
图11为预测网络生成的笔迹样本。该网络显然已经学会了模仿笔划、字母,甚至是简短的单词(尤其是常见的“of”和“The”)。它似乎还学会了一种基本的字符级语言模型,因为它发明的单词(“eald”、“bryoes”、“lenrest”)在英语中似乎有些可信。考虑到平均字符占用超过25个时间步长,这再次证明了网络生成一致的远程结构的能力。

5 Handwriting Synthesis
手写合成是生成给定文本的手写。显然,我们目前描述的预测网络无法做到这一点,因为没有办法限制网络写的字母。本节描述一种增强,它允许预测网络根据某些高级注释序列生成数据序列(在手写合成的情况下是字符串)。由此产生的序列足以令人信服,以至于它们往往无法与真实笔迹区分开来。此外,在不牺牲前一节所展示的写作风格多样性的情况下,实现了这种现实主义。
调整对文本的预测的主要挑战是,这两个序列的长度非常不同(钢笔轨迹的平均长度是文本的25倍),在生成数据之前,它们之间的对齐是未知的。这是因为每个字符所使用的坐标的数量会随着样式、大小、笔速等的不同而发生很大的变化。RNN transducer[9]是一种神经网络模型,它能够根据两种不同长度的未知对准序列进行序列预测。然而,使用RNN传感器进行手写合成的初步实验并不令人鼓舞。一种可能的解释是,传感器使用两个独立的RNNs来处理这两个序列,然后将它们的输出组合起来做出决策,而通常更希望将所有信息提供给单个网络。这项工作提出了另一种模型,其中软窗口与文本字符串进行卷积,并作为额外的输入输入到预测网络中。窗口的参数由网络输出同时进行预测,以便动态地确定文本和笔位置之间的对齐。简单地说,它学会决定接下来要写哪个字符。
5.1 Synthesis Network
图12展示了用于手写合成的网络体系结构。与预测网络一样,隐藏层是堆叠在一起的,每一层都向上向上,从输入到所有隐藏层和从所有隐藏层到输出都有跳过连接。不同之处在于由窗口层调节的字符序列的添加输入。

注意κt被定义为位置参数较前位置偏移ct−1,偏移的大小限制是大于零的。直观地说,这意味着network知道在每个步骤中滑动每个窗口的距离,而不是一个绝对位置。使用偏移量对于使网络将文本与钢笔轨迹对齐至关重要。


