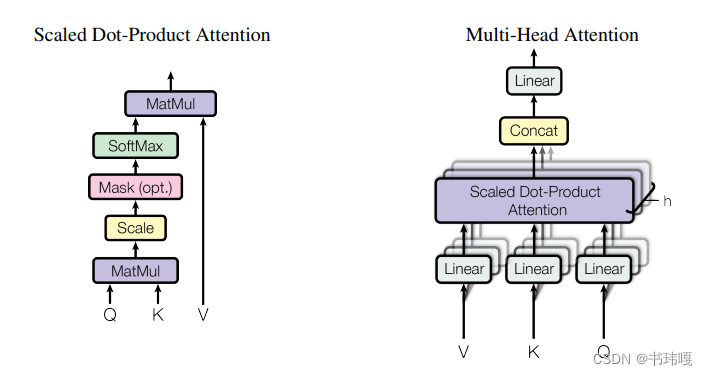
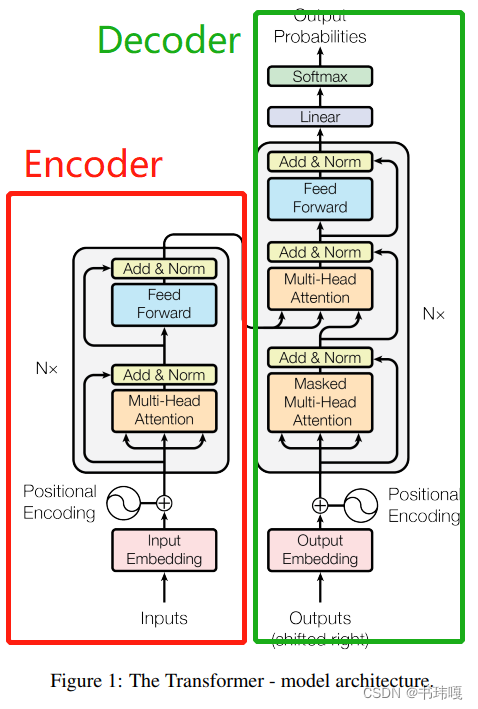
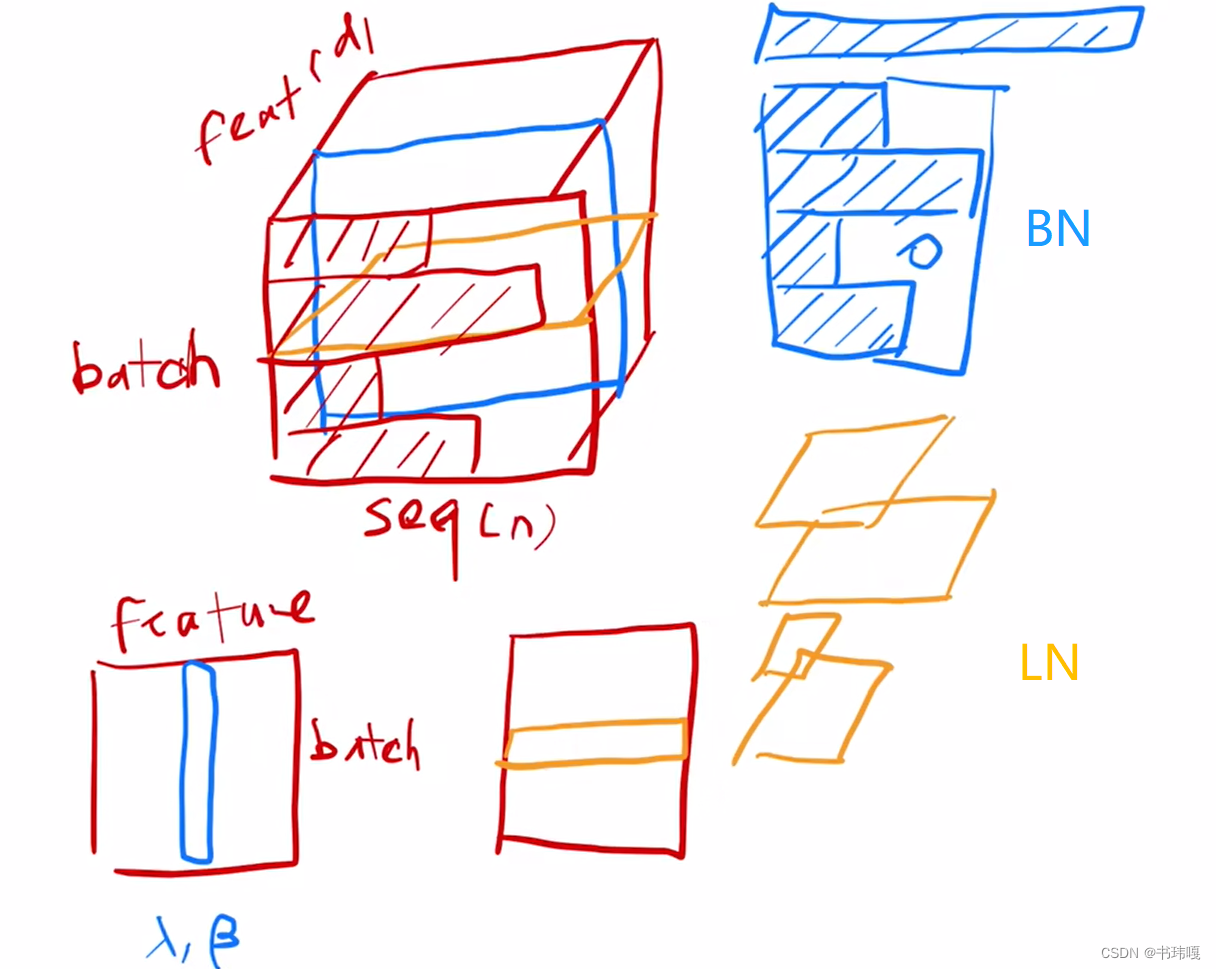
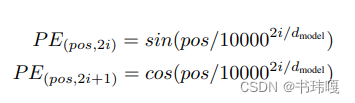注意力机制的计算公式如下:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V 其基本流程为:将query和key之间两两计算相似度,依据相似度对各个value进行加权; 在这里,要求Q与K的单个向量是等长的,对这两个向量计算内积,也就是余弦相似度,如果两个向量正交,则内积为0,也就是不相关;反之,如果相关,则二者内积就会很大。 其中,key与query的计算方式不同,决定了这是什么类型的注意力机制。上述为scaled dot-product机制(有加性注意力和乘性注意力)。
主要的动机在于: 1)乘性注意力中,没有可学习的参数; 2)用单头注意力获得一个高维向量(512),不如用多头注意力获得多个低维向量(64/32等)效果好,有些类似于CNN中的多通道数; 因此多头注意力主要进行了如下操作: 1)利用多组可学习的参数矩阵
W
q
,
W
k
,
W
v
W^q, W^k, W^v
Wq,Wk,Wv,将
Q
,
K
,
V
Q,K,V
Q,K,V映射成低维向量; 2)对多组低维
Q
,
K
,
V
Q,K,V
Q,K,V向量进行注意力计算,得到多组注意力结果; 3)将多组注意力结果concat成高维向量并通过MLP,最后输出;