1、Kafka 2 的安装与配置
1、上传kafka_2.12-1.0.2.tgz到服务器并解压:
tar -zxf kafka_2.12-1.0.2.tgz -C /opt
2、配置环境变量并更新:
编辑profile配置文件: vim /etc/profile
#设置kafka的环境变量
export KAFKA_HOME=/opt/kafka_2.12-1.0.2
export PATH=$PATH:$KAFKA_HOME/bin
重新加载profile文件: source /etc/profile
3、在/opt/kafka_2.12-1.0.2目录中输入kafka-按住tab键,如果能调出其他的指令说明我们配置
profile成功。
4、配置/opt/kafka_2.12-1.0.2/config中的server.properties文件:
> Kafka连接Zookeeper的地址:49.234.5.32:2181,后面的 myKafka 是Kafka在Zookeeper中的根节点路径。
zookeeper.connect=49.234.5.32:2181/mykafka
> 发消息到kafka,kafka会给你进行一个持久化,存储的目录。
Log.dir=/var/niko/kafka/kafka-logs
我们创建这个目录/var/niko/kafka/kafka-logs
mkdir -p /var/niko/kafka/kafka-logs
5、启动zookeeper
进入到/opt/zookeeper-3.4.14/bin目录
cd /opt/zookeeper-3.4.14/bin
启动
zkServer.sh start
6、验证zookeeper:
zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: standalone 说明成功了
7、启动Kafka:
进入Kafka安装的bin目录,执行如下命令:
cd /opt/kafka_2.12-1.0.2/bin
kafka-server-start.sh ../config/server.properties
启动成功,可以看到控制台输出的最后一行的started状态:
[2019-07-31 21:18:53,199] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
8、查看Zookeeper的节点
进入到Zookeeper安装目录的bin目录下
执行 zkCli.sh
执行命令ls / 查看所有的子节点
[mykafka, zookeeper]
9、此时Kafka是前台模式启动,要停止,使用Ctrl+C。
10、如果要后台启动
进入Kafka安装的bin目录,执行如下命令:
cd /opt/kafka_2.12-1.0.2/bin
执行:kafka-server-start.sh -daemon ../config/server.properties
11、查看Kafka的后台进程:ps aux | grep kafka
注意 kafka端口号9092
2、查看kafka是否启动
1、输入指令jps,查看kafka是否启动。
2、在任意目录下以后台的方式启动kafka
kafka-server-start.sh -daemon /opt/kafka_2.12-1.0.2/config/server.properties
3、再次输入jps,查看kafka是否启动成功。
3、在Linux使用命令生产与消费(了解)
3.1、kafka-topics.sh 用于管理主题
# 列出现有的主题(主题是放在zookeeper的节点上的)
kafka-topics.sh --list --zookeeper localhost:2181/mykafka
# 创建主题,该主题包含一个分区,该分区为Leader分区,它没有Follower分区副本。
--partitions 创建的分区个数
--replication-factor 创建的副本个数,用来实现高可用
kafka-topics.sh --zookeeper 49.234.5.32:2181/mykafka --create --topic topic_1 --partitions 1 --replication-factor 1
# 查看指定主题的详细信息
kafka-topics.sh --zookeeper 49.234.5.32:2181/mykafka --describe --topic topic_1
输出结果:
Topic:topic_1 PartitionCount:1 ReplicationFactor:1 Configs:
Topic: topic_1 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
#删除指定主题
kafka-topics.sh --zookeeper 49.234.5.32:2181/mykafka --delete --topic topic_1

3.2、kafka-console-producer.sh用于生产消息
kafka-console-producer.sh --topic topic_1 --broker-list 49.234.5.32:9092
3.3、kafka-console-consumer.sh用于消费消息
kafka-console-consumer.sh --bootstrap-server 49.234.5.32:9092 --topic topic_1
开启消费者方式二,从头消费,不按照偏移量消费
kafka-console-consumer.sh --bootstrap-server 49.234.5.32:9092 --topic topic_1 --from-beginning
注意:先开启消费消息,在开启生成消息,这样有生成消息的时候就可以直接消费了。
3.4、查看Kafka所有持久化的数据
进入到我们创建的用来保存持久化数据的目录:
cd /var/niko/kafka/kafka-logs
ls
有下面的偏移量,说明我们使用kafka成功。
__consumer_offsets-22 __consumer_offsets-35 __consumer_offsets-48
__consumer_offsets-10 __consumer_offsets-23
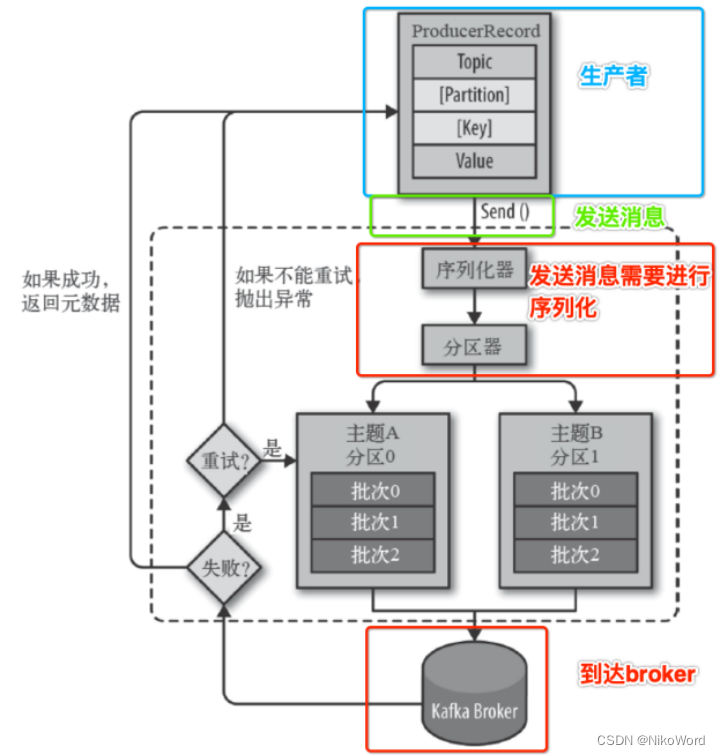
4、kafka发送消息的流程
5、Maven项目中使用Kafka开发实战(了解)
1、首先创建一个maven工程,我们将src目录删除,然后再pom.xml文件中设置这个工程的打包方式为pom。
<!-- 这是kafka的工程的父目录 我们使用pom的打包方式-->
<packaging>pom</packaging>
2、设置工程的maven仓库目录和setting文件。
3、创建子模块producer-consumer-test01 和 producer-product-test01
4、在模块producer-consumer-test01的pom.xml文件中导入依赖。
<dependencies>
<!-- kafka-clients的依赖-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<!-- 高版本兼容低版本,我们使用和broker一致的版本 -->
<version>1.0.2</version>
</dependency>
</dependencies>
5.1、生产者


消费者生产消息后,需要broker端的确认,可以同步确认,也可以异步确认。
同步确认效率低,异步确认效率高,但是需要设置回调对象。
package com.wei.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.header.Header;
import org.apache.kafka.common.header.internals.RecordHeader;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class MyProducer1 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
/**
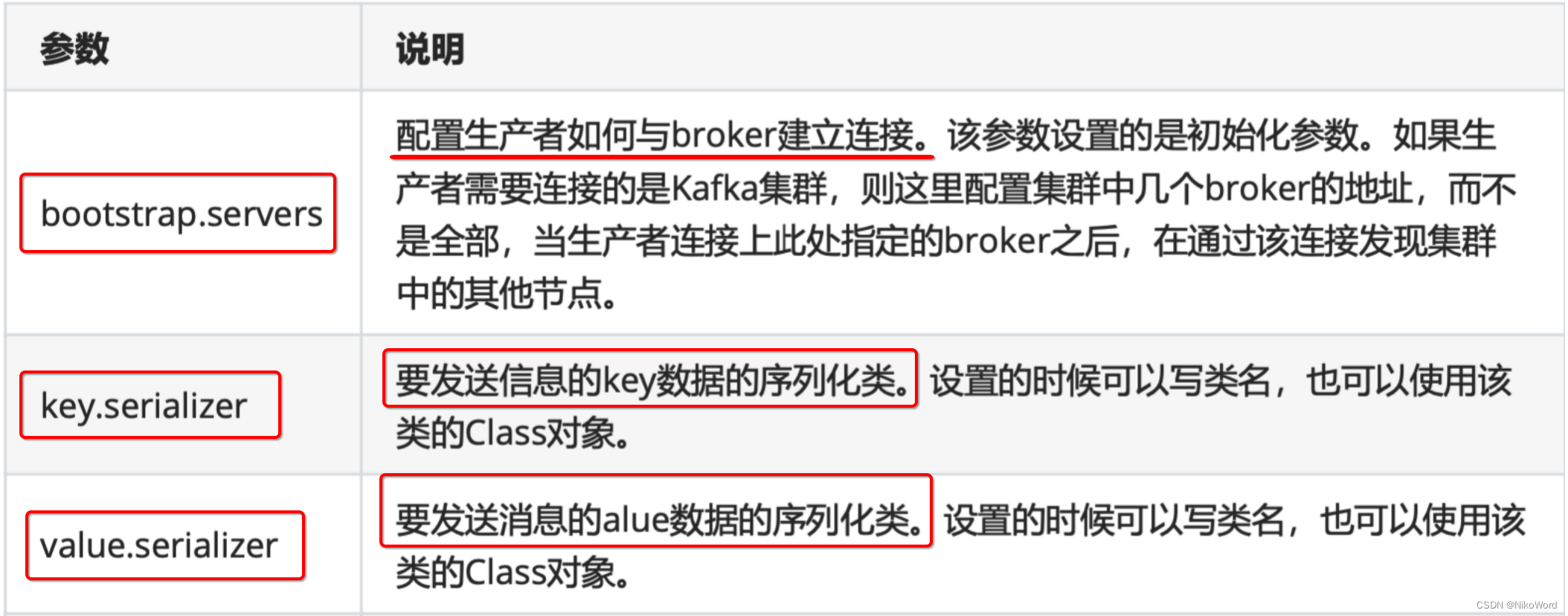
* 1.1、KafkaProducer 的创建需要指定的参数
* server地址 key的序列化 value的序列化 timeout ack retries
*/
Map<String,Object> map = new HashMap<>();
map.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"49.234.5.32:9092");
map.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
map.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// map.put("request.timeout.ms",55);
// map.put(ProducerConfig.ACKS_CONFIG,"all"); //有默认值可以不设置
// map.put(ProducerConfig.RETRIES_CONFIG,3); //也可以不设置
// 1、创建发送消息的类对象KafkaProducer
KafkaProducer<Integer, String> producer = new KafkaProducer<>(map);
/**
* -String topic: 主题
* -Integer partition: 分区
* -Long timestamp: 时间戳
* -K key: key
* -V value: value
* -Iterable<Header> headers) :用于设置用户自定义的消息头字段
*
*/
// 2.1、创建一个数组,里面存放的都是Header
ArrayList<Header> headers = new ArrayList<>();
// 添加的是Header接口的实现类RecordHeader 通过构造方法实例化一个RecordHeader对象
headers.add(new RecordHeader("wode.name","wode.value".getBytes(StandardCharsets.UTF_8)));
// 2、使用producerRecord用来给kafka发送封装的消息
ProducerRecord<Integer, String> producerRecord = new ProducerRecord<>(
"topic_2",
0,
0,
"nihao wudi",
headers
);
// 3、发送消息
// 消费者生产消息后,需要broker端的确认,可以同步确认,也可以异步确认。
// 同步确认效率低,异步确认效率高,但是需要设置回调对象。
// 3.1、同步发送
// final Future<RecordMetadata> future = producer.send(producerRecord);
// final RecordMetadata recordMetadata = future.get();
// System.out.println("主题是:"+recordMetadata.topic());
// System.out.println("分区是:"+recordMetadata.partition());
// System.out.println("变异量是:"+recordMetadata.offset());
// 3.2、异步发送
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("消息的主题:" + metadata.topic());
System.out.println("消息的分区号:" + metadata.partition());
System.out.println("消息的偏移量:" + metadata.offset());
} else {
System.out.println("异常消息:" + exception.getMessage());
}
}
});
// 4、关闭producer
producer.close();
}
}
5.2、消费者
package com.lagou.kafka.demo.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.function.Consumer;
public class MyConsumer2 {
public static void main(String[] args) {
Map<String, Object> configs = new HashMap<>();
// mac的hosts文件中手动配置域名解析
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "49.234.5.32:9092");
// 使用常量代替手写的字符串,配置key的反序列化器
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
// 配置value的反序列化器
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 配置消费组ID
configs.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer_demo2");
// 如果找不到当前消费者的有效偏移量,则自动重置到最开始
// latest表示直接重置到消息偏移量的最后一个
configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
KafkaConsumer<Integer, String> consumer = new KafkaConsumer<Integer, String>(configs);
// 先订阅,再消费
consumer.subscribe(Arrays.asList("topic_1"));
while (true) {
// 如果主题中没有可以消费的消息,则该方法可以放到while循环中,每过3秒重新拉取一次
// 如果还没有拉取到,过3秒再次拉取,防止while循环太密集的poll调用。
// 批量从主题的分区拉取消息
final ConsumerRecords<Integer, String> consumerRecords = consumer.poll(3_000);
// 遍历本次从主题的分区拉取的批量消息
consumerRecords.forEach(new Consumer<ConsumerRecord<Integer, String>>() {
@Override
public void accept(ConsumerRecord<Integer, String> record) {
System.out.println(record.topic() + "\t"
+ record.partition() + "\t"
+ record.offset() + "\t"
+ record.key() + "\t"
+ record.value());
}
});
}
// consumer.close();
}
}
6、SpringBoot整合 Kafka
1、首先是创建一个springboot-kafka-sum-demo02项目。
2、通过快速构建的方式添加spring-web 、spring-kafka或者是手动在pom.xml文件中添加spring-web 、spring-kafka的依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
3、resource目录下的application.properties文件:
#1、设置应用程序的名称和端口号
spring.application.name=springboot-kafka-02
server.port=8080
#2、kafka单体或者集群的host和端口号
spring.kafka.bootstrap-servers=49.234.5.32:9092
#3、producer的配置
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.IntegerSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#producer生产者每一批次可以放多少条记录
spring.kafka.producer.batch-size=16384
#生产者端 可以用来发送的缓冲区的大小 32MB 单位是字节
spring.kafka.producer.buffer-memory=33554432
#4、consumer的配置
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.IntegerDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.group-id=springboot-consumer02
#如果在kafka的消费者中找不到当前的偏移量 从最早的偏移量开始获取数据
spring.kafka.consumer.auto-offset-reset=earliest
#消费者的偏移量是自动提交还是手动提交 设置成true表示是自动提交变异量 如果有事务的情况下 我们通常是设置成手动提交
spring.kafka.consumer.enable-auto-commit=true
#消费者设置成自动提交偏移量的一个提交频率
spring.kafka.consumer.auto-commit-interval=1000
4、生产者同步发送消息
package com.wei.springbootkafka.producer;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.ExecutionException;
@RestController
public class MyProducer01 {
// 1、自动注入KafkaTemplate
@Autowired
private KafkaTemplate<Integer,String> template;
@RequestMapping("/send/sync/{message}")
public String sendSyncMessage(@PathVariable("message") String message){
// 2、使用KafkaTemplate发送消息
ListenableFuture<SendResult<Integer, String>> future =
template.send("spring-topic-01", 0, 0, message);
// 3、同步发送消息 get()
try {
SendResult<Integer, String> result = future.get();
RecordMetadata metadata = result.getRecordMetadata();
System.out.println("主题是:"+metadata.topic());
System.out.println("分区是:"+metadata.partition());
System.out.println("偏移量是:"+metadata.offset());
} catch (Exception e) {
e.printStackTrace();
System.out.println("异常了");
}
return "success";
}
}
5、生产者异步发送消息
@RestController
public class MyProducer02 {
// 1、自动注入KafkaTemplate
@Autowired
private KafkaTemplate<Integer,String> template;
@RequestMapping("/send/sync/{message}")
public String sendSyncMessage(@PathVariable("message") String message){
// 2、使用KafkaTemplate发送消息
ListenableFuture<SendResult<Integer, String>> future =
template.send("spring-topic-01", 0, 0, message);
// 3、异步发送消息
future.addCallback(new ListenableFutureCallback<SendResult<Integer, String>>() {
@Override
public void onFailure(Throwable ex) {
System.out.println("失败了"+ex.getMessage());
}
@Override
public void onSuccess(SendResult<Integer, String> result) {
RecordMetadata recordMetadata = result.getRecordMetadata();
System.out.println("发送消息成功:" + metadata.topic() + "\t"
+ metadata.partition() + "\t"
+ metadata.offset());
}
});
return "success";
}
}
6、消费者消费消息
package com.wei.springbootkafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
//1、交由spring进行管理
@Component
public class MyConsumer01 {
// 2、KafkaListener监听指定的主题
@KafkaListener(topics="spring-topic-01")
// 3、添加了@KafkaListener注解后 方法中就可以使用ConsumerRecord:用来接收kafka的消息
public void getMessage(ConsumerRecord<Integer,String> record){
System.out.println("consumer"
+ record.topic()+"\t"
+ record.partition()+"\t"
+ record.offset()+"\t"
+ record.key()+"\t"
+ record.value()+"\t"
);
}
}
7、kafka报错 UnknownHostException 解决方案
运行springboot和kafka整合项目报错java.net.UnknownHostException: VM-4-7-centos
解决方案:
1、cd 到/opt/kafka_2.12-1.0.2/config目录下
2、vim server.properties
设置成listeners=PLAINTEXT://VM-4-7-centos:9092
3、通过查看 linux服务器的 /etc/hosts 文件:将VM-4-7-centos指向的就是linux服务器ip。
127.0.0.1 VM-4-7-centos VM-4-7-centos
49.234.5.32 VM-4-7-centos VM-4-7-centos
4、由于我是在本机服务中访问到了linux服务器上的kafka服务,自然就无法解析到 VM-4-7-centos。因此需要在本机的hosts文件中也加入相应的配置!
5、Mac系统的hosts 文件就在 /etc/hosts 路径里,我们直接是无法编辑的,需要通过下面的方法来修改我们的 hosts 文件。
进入终端(命令窗口)里,输入 sudo vi /etc/hosts ,回车后再输入密码,再回车就可以打开我们的hosts文件了。
添加VM-4-7-centos 的服务器的ip地址:
49.234.5.32 VM-4-7-centos