前言
Hive的学习告一段落,接下来开始了解大数据主流NoSql数据库HBase,本文主要讲解HBase集群的安装部署,为后续Hbase学习作准备。
1. HBase是什么(5分钟)
1.1 HBase的概念
- HBase基于Google的BigTable论文,是建立的HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的分布式数据库系统。
- 在需要实时读写随机访问超大规模数据集时,可以使用HBase。
1.2 HBase的特点
-
海量存储
-
列式存储
- HBase表的数据是基于列族进行存储的,列族是在列的方向上的划分。
-
极易扩展
- 底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加datanode节点就可以了
- 可以通过增加服务器来对集群的存储进行扩容
-
高并发
-
稀疏
- 稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
-
数据的多版本
- HBase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳
-
数据类型单一
2. HBase集群安装部署
2.1 准备安装包
[hadoop@node01 ~]$ cd /kkb/soft/
[hadoop@node01 soft]$ tar -xzvf hbase-1.2.0-cdh5.14.2.tar.gz -C /kkb/install/
2.2 修改HBase配置文件
2.2.1 hbase-env.sh
[hadoop@node01 soft]$ cd /kkb/install/hbase-1.2.0-cdh5.14.2/conf/
[hadoop@node01 conf]$ vim hbase-env.sh
export JAVA_HOME=/kkb/install/jdk1.8.0_141
export HBASE_MANAGES_ZK=false


2.2.2 hbase-site.xml
[hadoop@node01 conf]$ vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node01:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01,node02,node03</value>
</property>
<!-- 此属性可省略,默认值就是2181 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/kkb/install/zookeeper-3.4.5-cdh5.14.2/zkdatas</value>
</property>
<!-- 此属性可省略,默认值就是/hbase -->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
</configuration>
2.2.3 regionservers
[hadoop@node01 conf]$ vim regionservers
- 指定HBase集群的从节点;原内容清空,添加如下三行
node01
node02
node03
2.2.4 back-masters
- 创建back-masters配置文件,里边包含备份HMaster节点的主机名,每个机器独占一行,实现HMaster的高可用
[hadoop@node01 conf]$ vim backup-masters
2.3 分发安装包
- 将node01上的HBase安装包,拷贝到其他机器上
[hadoop@node01 conf]$ cd /kkb/install
[hadoop@node01 install]$ scp -r hbase-1.2.0-cdh5.14.2/ node02:$PWD
[hadoop@node01 install]$ scp -r hbase-1.2.0-cdh5.14.2/ node03:$PWD
2.4 创建软连接
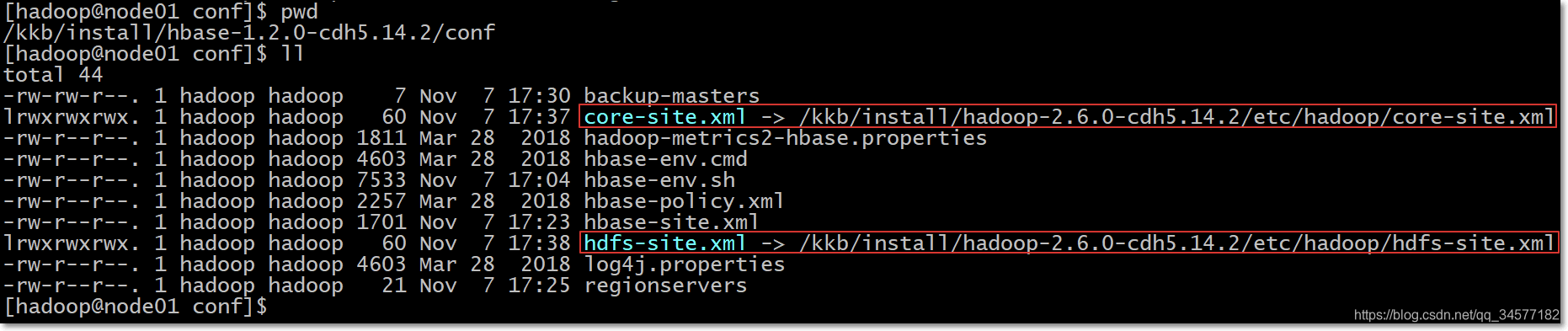
ln -s /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/core-site.xml /kkb/install/hbase-1.2.0-cdh5.14.2/conf/core-site.xml
ln -s /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/hdfs-site.xml /kkb/install/hbase-1.2.0-cdh5.14.2/conf/hdfs-site.xml
- 执行完后,出现如下效果,以node01为例
2.5 添加HBase环境变量
- **注意:三台机器**均执行以下命令,添加环境变量
sudo vim /etc/profile
export HBASE_HOME=/kkb/install/hbase-1.2.0-cdh5.14.2
export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile
2.6 HBase的启动与停止
[hadoop@node01 ~]$ start-hbase.sh

#HMaster节点上启动HMaster命令
hbase-daemon.sh start master
#启动HRegionServer命令
hbase-daemon.sh start regionserver
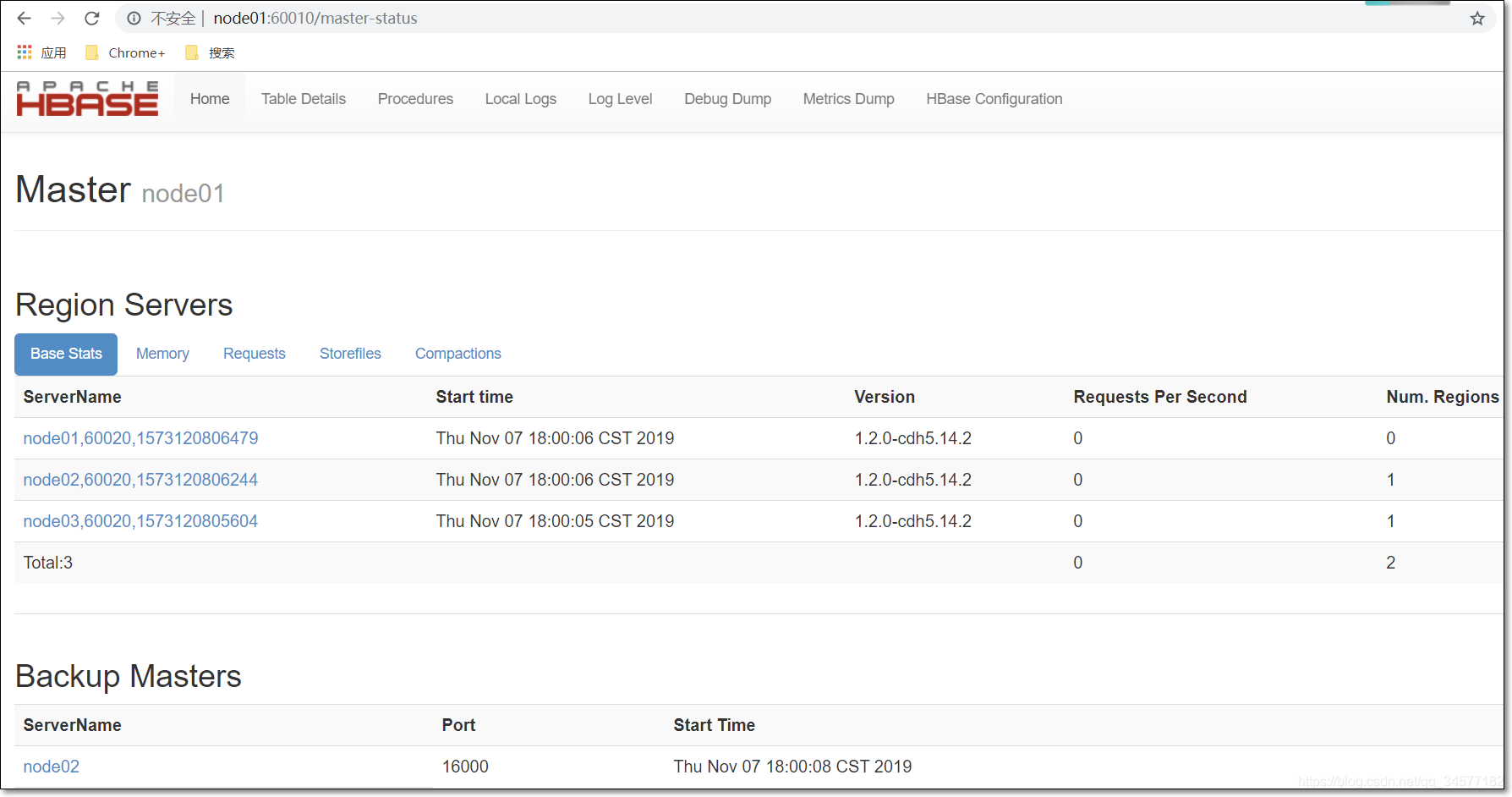
2.7 访问WEB页面
1.8 停止HBase集群
[hadoop@node01 ~]$ stop-hbase.sh
- 若需要关闭虚拟机,则还需要关闭ZooKeeper、Hadoop集群
总结
Hbase集群搭建完成了,接下来就可以开始愉快的学习Hbase了。
获取更多干货,请关注我的个人公众号,关注领取福利
