本文是CVPR2021最新的视频目标检测的论文
原文地址:https://arxiv.org/abs/2103.01353v1
代码:https://github.com/robot-learning-freiburg/MM-DistillNet
注意:文中的“知识”可以理解为网络提取的特征图
-
摘要
对象固有的声音属性可以为学习对象检测和跟踪的丰富表示提供有价值的线索。①本文提出了一个新的自我监督的多媒体教学网络框架,该框架由多个teacher组成,他们利用包括RGB、深度和热图像在内的多种形式,同时利用互补的线索,并将知识提取到一个单一的音频student网络中。②提出了新的MTA损失函数,它有助于以自我监督的方式从多模态教师那里提取信息。③为音频学生提出了一个新颖的自我监督pretext任务,能够不依赖标注/注释。
本文主要与之前的StereoSoundNet做对比。
-
引言
视频中图像和音频等形态为监督提供了线索,可以利用这些线索以自我监管的方式学习更鲁棒的感知模型。场景中对象固有的声音属性还包含丰富的时域和频域信息,声音和视觉的结合使我们能够用一种方式来监督另一种方式,也可以用两种方式来共同监督对方。
检测目标的训练模型需要大量的基础事实注释来进行监督。然而,我们可以通过师生策略联合利用视听学习来训练模型识别产生声音的对象,而不依赖于标记的数据。

跨模态多媒体提取器通过从多模态视觉teacher那里获得互补线索来提取知识,并将其转化为听觉学生。在预测过程中,模型仅使用音频作为输入来检测和跟踪视觉帧中的多个对象
框架如图所示:由多个teacher网络组成,每个teacher网络采用一个特定的模态作为输入,这里作者使用RGB、深度和热图来最大化我们可以利用的互补线索(外观、几何形状、反射率)。teache首先在不同的预先存在的数据集上被单独训练,以预测他们各自形式的边界框。然后,训练音频student网络,只在未标记的视频上学习从麦克风阵列到组合teacher预测的边界框坐标的声音映射。为了做到这一点,作者提出了新的MTA损失,以同时利用互补线索和提取目标检测知识从多模态teacher到音频student网络在自我监督的方式。在预测过程中,音频student网络仅使用声音作为输入来检测和跟踪视觉框架中的对象。此外,提出了一个自我监督的pretext任务来初始化音频student网络,以避免依赖手动注释,加速训练。
本文收集了一个大规模的驱动数据集,其中包含超过113,000个时间同步的RGB、深度、热图和多通道音频模式帧。
该模型还可以仅使用麦克风阵列的声音在视觉帧中执行对象检测和跟踪,允许系统在不使用任何摄像机姿态信息的情况下,在环境中移动时同时检测多辆车辆。
为了减少基础事实标签依赖性,利用模态的共现作为自我监督机制来获得标注。
将来自多个预先训练的模态特定teacher网络的“知识”整合到音频学生网络中,该网络从未标记的视频中学习,并且在推理过程中仅使用音频。该方法在训练时利用了替代模态的互补特征,努力提高整个系统的鲁棒性,而不增加预测的开销。
除了生成伪标签,我们还使用模态特定的教师网络通过知识提炼来指导音频学生网络的训练。该框架并不仅仅是平均不同teacher之间的双重损失,而是使用概率方法来对齐中间师生层的特征。
每个模态特定的“老师”提取目标检测“知识”(可以理解为特征图)给音频学生(用于预测),这可以归类为跨模态知识提取。
-
技术方法
本节主要介绍了多模态提取框架
用于从一组预先训练的多模态教师网络中提取知识到一个学生中,该学生使用一个未标记的模态作为输入。我们选择RGB、深度和热图像作为教师模式,为学生提供8声道单声道麦克风阵列的音频。具体来说,目标是学习从环境声音的频谱图到边界框坐标的映射在视觉空间中指示车辆位置。

该网络建立在EfficientDet-D2 的基础上,预测视觉空间中的边界框,以及一个音频学生网络,该网络将来自麦克风阵列的声音频谱图作为输入。
每个预先训练的模态特定的教师预测边界框,该边界框指示车辆在它们各自的模态空间中的位置。这些预测被融合以获得单个多教师预测,然后该预测被用作训练音频学生网络的伪标签。为了有效地利用来自特定模态教师的补充线索,提出了多教师对齐(MTA)损失,以将学生的中间表征与教师的中间表征对齐。提出的新pretext任务,以更好地初始化音频学生网络。
3.1. 网络结构
建立在针对特定模式的教师网络的EfficientDet架构之上。EfficientDet有三个主要组件:一个EfficientNet主干,接着是一个双向特征金字塔网络,最后是一个分类和回归。
EfficientNet使用多级移动反向瓶颈单元从输入数据中提取相关特征。为了选择从EfficientNet的哪个阶段提取特征(以及如何将这些特征融合在一起),EfficientNet通过自动机器学习和手动调整的结合引入了加权双向特征金字塔。网络的最后一个阶段是一个分类器和回归器分支,由一系列可分离的卷积、批量标准化和一种节省内存的swish组成。
使用768×768像素的输入图像分辨率,重复5个BiFPN单元,每个单元有112个通道。
数据集使用:
-
RGB teacher :COCO,VOC,imageNet
-
Depth teacher:Argoverse
-
Thermal teacher :FLIR ADAS
MM-DistillNet
音频学生网络学习将车辆检测作为一个回归问题。对音频学生网络采用相同的EfficientNet-D2拓扑结构,该拓扑结构采用8个声道连接的频谱图(代表来自8声道单声道麦克风阵列的环境声音)作为输入,并预测在视觉参考框架中定位车辆的边界框。
-
首先获得给定时间戳的RGB、深度和热图像三元组,每个三元组的分辨率为1920×650像素。
-
从麦克风阵列中选择一秒钟的环境声音片段,以图像时间戳为中心,并使用短时傅立叶变换(STFT)为八个麦克风中的每一个生成80×173像素的声谱图。
-
将光谱图调整到768×768像素的分辨率,以匹配教师的输入比例。
-
给定这个8通道级联光谱图作为输入,音频学生在不同的纵横比和比例下为每个EfficientDet层产生4个坐标(xmin,ymin,xmax,ymax)(EfficientDet默认使用3个纵横比(1.0,1.0),(1.4,0.7),(0.7,1.4),在3个不同的比例下[2∙0,2∙∗(1.0/3.0),2∗ ∗(2.0/3.0)]。
3.2. 音频学生的自我监督pretext任务
为音频学生提出了一个简单的pretext任务,计算出现的汽车数量。这项任务旨在通过音频使学生网络能够学习到汽车的数量,仅使用8通道声谱图作为输入。为此,首先使用多个预先培训过的teacher的预测来识别图像中出现的汽车数量。随后,我们使用相应的8通道谱图作为输入到EfficientNet 网络,在其输出端具有MLP分类器,并且我们使用交叉熵损失函数来训练网络以预测场景中的汽车数量。然后,我们使用在这个pretext任务上训练的模型的权重来初始化我们的MM-StephallenT框架中的音频学生网络,同时训练从作为输入的声音频谱图中检测视觉帧中的汽车。
3.3多模态教师的特征提取
使用了两种损失函数
- 在网络的最终预测中采用目标检测损失函数
- 使用MTA损失函数来对齐和利用来自模态特定教师和音频学生的中间层的补充线索。
假设我们使用多个教师,可以获得多组包围盒预测。每个教师网络仅接收其输入模态,并预测一组边界框,这些边界框对应于他们对车辆在视觉空间中的位置的最佳个体估计。每个特定模态的老师预测不同数量的边界框。因此,我们需要巩固这样的预测。为此,获得来自RGB、深度和热的三组,它们使用NMS合并在一起,交集超过联合IoU = 0.5。这将从特定于模态的教师那里生成一个统一的预测,在学生使用Focal loss。Focal loss是交叉熵损失的一种形式,带有一个惩罚参数,该参数减少了分类良好的例子的相对损失,允许网络集中在难以分类的训练例子上。
Focal loss:
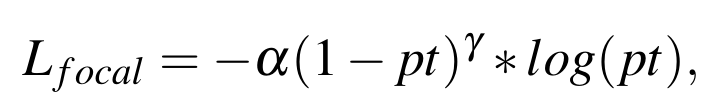
α是分配给难分类示例的权重(设置为α = 0.25),γ是聚焦超参数,用于平衡将难分类示例与简单背景情况(设置为γ = 2.0)进行分类的工作量。
根据MTA损失,目标是利用每一位特定模态教师的中间层所包含的互补线索。为了实现这一点,使得学生和多个教师的特定层中的激活分布是一致的。加强了高效网主干的(p3,p4,p5)层的对齐,使用归一化到[0,1]范围的每个层的注意力图来计算激活的分布。我们将学生注意力图计算为
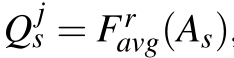
其中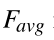 是一个函数,它通过给定层上神经元输出的平均值来折叠通道维度上的激活张量A,j ∈ {P3,P4,P5},r是向量第i个元素上的指数,它显示了给定层上高值激活与低值激活的重要性。
是一个函数,它通过给定层上神经元输出的平均值来折叠通道维度上的激活张量A,j ∈ {P3,P4,P5},r是向量第i个元素上的指数,它显示了给定层上高值激活与低值激活的重要性。
在教师网络的模块下,每个模态
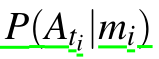
的激活分布指示每个教师的置信度,即给定输入模态,中间表示具有检测车辆的相关关键指示器的高可能性。
通过在所选层的模态特定激活分布的乘积来利用多个教师的注意力图。这里假设模态是独立的,使用概率的链式法则
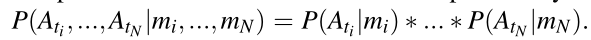
如果多种模式在一个边界框上达成一致,则鼓励这种提议的可能性。然而,一个模态也可以以小概率提出一个不相交的包围盒,允许学生学习一个特定模态独有的包围盒。给定每个模态的特征知识,我们有效地估计在场景中检测到汽车的概率。这使得我们能够灵活地将其他知识作为每个边界框的置信度得分,从而减少错误预测的发生。
多教师注意力图计算为
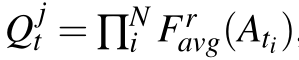
其中i表示N个模态中的每一个。
MTA loss
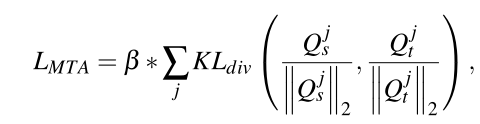
总和从倒金字塔中选择的每个效率网层(例如,p3、p4和p5层)上迭代,s和t代表学生和教师,β = 0.5用于损耗平衡。
最后的优化loss
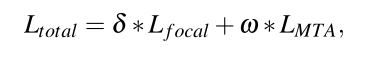
3.4 跟踪
利用检测到的边界框,并使用连续帧框之间的IoU值将对象与同一轨迹关联起来。将IoU阈值设置为0.5,以将不同时间步长的两个边界框分配给同一个对象。每次检测到置信度高于0.8的对象时,我们都会初始化一个轨迹。通过将其与当前帧的检测进行比较,选择与该轨迹相关的下一个边界框。轨迹和边界框之间的关联过程使得IoU最大化。如果在随后的帧中没有IoU > 0.5的边界框,则轨迹线被设置为非活动的。
- 实验评估
4.1 多模态视听检测数据集
作者自己收集的,汽车静止的静态状态和近300公里的行驶数据,只保留了场景中至少有一辆车的图像。用于训练检测阶段的子集包含24589个静态日间图像、26901个静态夜间图像、26357个日间驾驶图像和35436个夜间驾驶图像,总计113283个同步多通道音频、RGB、深度图和热图。
4.2训练
评估度量:我们使用标准平均精度度量来评估对象检测性能和中心距离。平均精度是每类精度和召回率曲线下插值区域的类平均。中心距离CDx和CDy度量指示预测精度,因为空间信息不能直接用于音频(预测的边界框中心和基础事实之间可能存在误差)。
参数设置:r=2.0 t=9.0 δ = 1.0和ω = 0.05
所有RGB/深度/热像的原始分辨率为1920×650。根据efficientNet D2变型,将大小调整为768×768。对于音频,在注册时间戳之前0.5秒和之后0.5秒提取一个RGB图像。对这个1秒钟的原始波形进行归一化,并进一步在80个频段的Mel频率范围内对其进行重新采样,得到8 (80,173)个阵列。这进一步归一化为[0-1],并重新缩放为768×768×8的维数。
4.3定量结果
- 比较了MM-DistillNet 和 StereoSoundNet网络的i性能。StereoSoundNet使用单个RGB教师和Rank loss来提取信息到音频学生网络。
- 比较了2M-DistillNet 只使用一个RGB老师网络和MTA 损失,用来训练学生网络。这样可以证明MTA由于Rank loss
- 比较单独使用2M-DistillNet 深度图和2M-DistillNet 热度图,MTA损失来培训学生音频网络的性能。
- 与MM-Stephenlnet Avg 进行了比较,通过对单个特定模态的网络激活进行平均,将来自RGB、深度和热图老师的预测结合起来。
假设由任何模态预测的所有边界框都是有效的(在应用IoU=0.5的非最大抑制之后)。所有上述baseline都使用来自麦克风阵列的8通道声谱图作为输入,并经过训练以执行多目标检测。
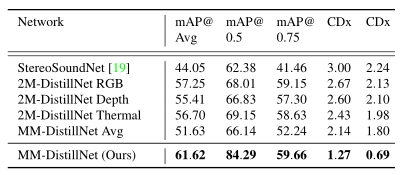
“2M-DistillNet”指的是使用MTA损失来训练音频学生的双模态提取方法。“平均”指的是平均个别特定模态的教师激活。
由结果很容易看出,不管是多模态的教师训练,还是单教师训练(只是用RGB/深度图/热力图)对于结果的预测,与 StereoSoundNet相比,都具有明显的提升。这说明MTA损失由于RANK loss 损失。
还观察到,使用平均来组合对单个RGB、深度和热力图教师的预测并不能提高性能。
还评估了MTA损失相对于其他损失的比较。

所有的模型都是用相同的mmDistillNet结构训练的,但损失函数不同。‘R,D,T’指RGB,深度,热力图。
其中Avg.表示的意思是平均三个教师模态的特征图。
比较跟踪性能
不同模态教师和pretext任务对音频学生影响的消融研究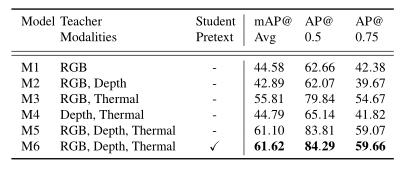
4.4. 消融研究
很容易看出,RGB和热力图是性能提升的主要原因
可视化:红色区域代表是汽车的可能性

4.5 定性评估

结论:
- 提出MM-DistillNet框架
- MTA损失函数优于rank loss
补充说明:
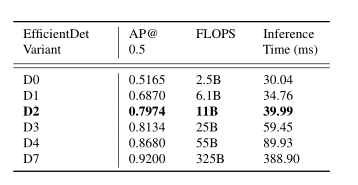
1.EfficientDet 复合系数选择
EfficientDet包含八种不同的架构配置,可在性能和运行时间之间进行权衡。结合微软COCO 、PASCAL VOC和ImageNet创建了一个大型数据集。训练EfficientDet D0-D7来检测这个组合数据集中的对象汽车。根据IoU = 0.5时的平均精度(AP)以及推理时间和每秒浮点运算(FLOPS)来呈现性能。
2.麦克风数量的影响

左轴(蓝线)显示了网络性能与麦克风数量的关系。右轴(红色)显示使用N个麦克风导致的GLOPS增加。可以看出,在FLOPS中,更多的通道可以在给定的任务中提高性能,而影响可以忽略不计。
3.不同的学生网络
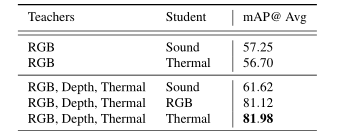
对比试验,结果显而易见。
4.MTA
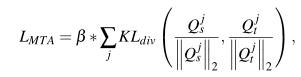
学生注意力图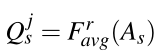
教师注意力图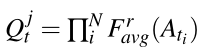
在计算教师和学生之间概率分布差异的度量的KLdivas时,对软最大值应用参数t。增加软最大值计算中的t,以适应每个个体概率分布的置信度。
student normalized activation
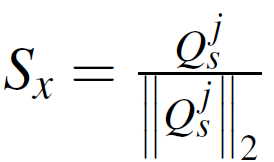
integrated normalized teacher attention
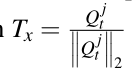
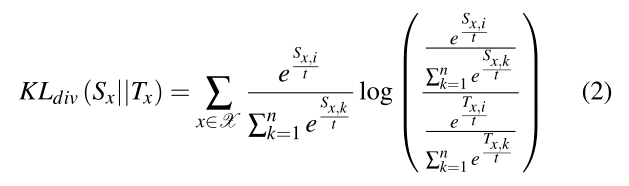

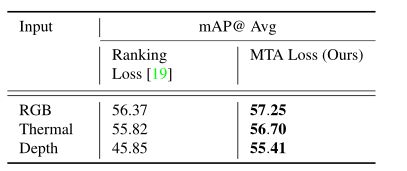
pretext任务的比较
夜间白天汽车状态的不同比较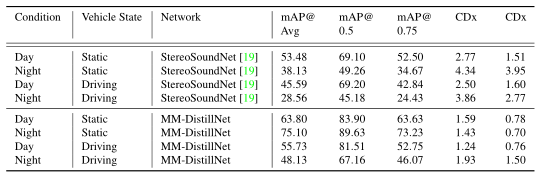
剩下的内容就是实验结果,大家可以去原文自己去看一下实验。