p r o g r a m ➔ b l o c k b l o c k ➔ { d e c l s s t m t s } \begin{aligned} program &➔ block\\ block &➔ \{ decls\ \ stmts\}\\ \end{aligned} programblock➔block➔{decls stmts}
语义动作:
p
r
o
g
r
a
m
➔
b
l
o
c
k
{
B
A
C
K
P
A
T
C
H
(
b
l
o
c
k
.
C
H
A
I
N
,
N
X
Q
)
;
G
E
N
(
E
n
d
,
_
,
_
,
_
)
;
}
\begin{aligned} program &➔ block\\ \{ &BACKPATCH (block.CHAIN,NXQ);\\ &GEN(End, \_, \_, \_);\}\end{aligned}
program{➔blockBACKPATCH(block.CHAIN,NXQ);GEN(End,_,_,_);}
b l o c k ➔ { d e c l s s t m t s } { b l o c k . C H A I N : = s t m t s . C H A I N } \begin{aligned} block &➔ \{ decls\ \ stmts\}\\ \{ &block .CHAIN := stmts.CHAIN\}\\\end{aligned} block{➔{decls stmts}block.CHAIN:=stmts.CHAIN}
在自底向上的语法制导翻译中,我主要运用符号栈进行语义处理,所以在使用一个产生式进行归约时,产生式右部的符号就会弹出,属性就会丢失;因此翻译时的关键就是对需要归约的产生式右部各个文法符号的属性进行及时的保存或回填;下面还有很多产生式的语义处理以及文法的改造也都是基于这个原则
d e c l s ➔ d e c l ; d e c l s ∣ ε d e c l ➔ d e c l , i d ∣ i n t i d ∣ r e a l i d \begin{aligned} decls ➔& decl;decls\\ &| \varepsilon\\ decl➔& decl,id\\ &|int\ \ id\\ &| real\ \ id\\ \end{aligned} decls➔decl➔decl;decls∣εdecl,id∣int id∣real id
int a, b, c, d;
语义动作:
d
e
c
l
s
➔
d
e
c
l
;
d
e
c
l
s
(
1
)
{
}
d
e
c
l
s
➔
ε
{
}
d
e
c
l
➔
d
e
c
l
(
1
)
,
i
d
{
F
I
L
L
(
E
N
T
R
Y
(
i
d
)
,
d
e
c
l
(
1
)
.
T
Y
P
E
)
;
d
e
c
l
.
T
Y
P
E
:
=
d
e
c
l
(
1
)
.
T
Y
P
E
}
d
e
c
l
➔
i
n
t
i
d
{
F
I
L
L
(
E
N
T
R
Y
(
i
d
)
,
i
n
t
)
;
d
e
c
l
.
T
Y
P
E
:
=
i
n
t
}
d
e
c
l
➔
r
e
a
l
i
d
{
F
I
L
L
(
E
N
T
R
Y
(
i
d
)
,
r
e
a
l
)
;
d
e
c
l
.
T
Y
P
E
:
=
r
e
a
l
}
\begin{aligned} decls ➔& decl;decls^{(1)}\\ \{&\}\\ decls ➔& \varepsilon\\ \{&\}\\ decl➔ &decl ^{(1)},id\\ \{&FILL(ENTRY(id),decl ^{(1)}.TYPE);\\ &decl .TYPE:= decl ^{(1)}.TYPE\}\\ decl➔ & int\ id\\ \{&FILL(ENTRY(id),int);\\&decl .TYPE:= int\}\\ decl ➔ &real\ id\\ \{&FILL(ENTRY(id),real);\\&decl .TYPE:= real\} \end{aligned}
decls➔{decls➔{decl➔{decl➔{decl➔{decl;decls(1)}ε}decl(1),idFILL(ENTRY(id),decl(1).TYPE);decl.TYPE:=decl(1).TYPE}int idFILL(ENTRY(id),int);decl.TYPE:=int}real idFILL(ENTRY(id),real);decl.TYPE:=real}
s t m t s ➔ s t m t s s t m t ∣ ε s t m t ➔ b l o c k \begin{aligned} stmts ➔& stmts\ \ stmt \ \\&| \ \varepsilon\\ stmt➔& block \end{aligned} stmts➔stmt➔stmts stmt ∣ εblock
为了方便的进行自底向上归约 (及时进行回填),需要对上述文法进行改写:
s
t
m
t
s
➔
L
S
s
t
m
t
∣
ε
L
S
➔
s
t
m
t
s
s
t
m
t
➔
b
l
o
c
k
\begin{aligned} stmts ➔& L^S\ \ stmt \ \\&| \ \varepsilon\\ L^S➔&stmts\\ stmt➔& block \end{aligned}
stmts➔LS➔stmt➔LS stmt ∣ εstmtsblock
语义动作:
s
t
m
t
s
➔
L
S
s
t
m
t
{
s
t
m
t
s
.
C
H
A
I
N
:
=
s
t
m
t
.
C
H
A
I
N
}
s
t
m
t
s
➔
ε
{
s
t
m
t
s
.
C
H
A
I
N
:
=
0
}
L
S
➔
s
t
m
t
s
{
B
A
C
K
P
A
T
C
H
(
s
t
m
t
s
.
C
H
A
I
N
,
N
X
Q
)
}
s
t
m
t
➔
b
l
o
c
k
{
s
t
m
t
.
C
H
A
I
N
=
b
l
o
c
k
.
C
H
A
I
N
}
\begin{aligned} stmts➔&L^S\ stmt\\ \{ &stmts .CHAIN := stmt.CHAIN\}\\ stmts ➔&\varepsilon\\ \{ &stmts.CHAIN:=0\}\\ L^S➔&stmts\\ \{ &BACKPATCH(stmts.CHAIN,NXQ) \} \\ stmt ➔&block\\ \{&stmt.CHAIN=block.CHAIN\}\\ \end{aligned}
stmts➔{stmts➔{LS➔{stmt➔{LS stmtstmts.CHAIN:=stmt.CHAIN}εstmts.CHAIN:=0}stmtsBACKPATCH(stmts.CHAIN,NXQ)}blockstmt.CHAIN=block.CHAIN}
s t m t ➔ i f b o o l t h e n s t m t ∣ i f b o o l t h e n s t m t e l s e s t m t \begin{aligned} stmt➔ & if\ bool\ then\ stmt\\ &|if\ bool\ then\ stmt\ else\ stmt\\\end{aligned} stmt➔if bool then stmt∣if bool then stmt else stmt
对文法进行改写:
s
t
m
t
➔
C
s
t
m
t
∣
T
P
s
t
m
t
C
➔
i
f
b
o
o
l
t
h
e
n
T
P
➔
C
s
t
m
t
e
l
s
e
\begin{aligned} stmt➔ & C\ stmt\\ &| T^P\ stmt\\ C➔ &if\ bool\ then\\ T^P➔ &C\ stmt\ else\\\end{aligned}
stmt➔C➔TP➔C stmt∣TP stmtif bool thenC stmt else


语义动作:
C
➔
i
f
b
o
o
l
t
h
e
n
{
B
A
C
K
P
A
T
C
H
(
b
o
o
l
.
T
C
,
N
X
Q
)
;
C
.
C
H
A
I
N
:
=
b
o
o
l
.
F
C
}
s
t
m
t
➔
C
s
t
m
t
(
1
)
{
s
t
m
t
.
C
H
A
I
N
:
=
M
E
R
G
(
C
.
C
H
A
I
N
,
s
t
m
t
(
1
)
.
C
H
A
I
N
)
}
T
P
➔
C
s
t
m
t
(
1
)
e
l
s
e
{
q
:
=
N
X
Q
;
G
E
N
(
j
,
_
,
_
,
0
)
;
B
A
C
K
P
A
T
C
H
(
C
.
C
H
A
I
N
,
N
X
Q
)
;
T
P
.
C
H
A
I
N
:
=
M
E
R
G
E
(
s
t
m
t
(
1
)
.
C
H
A
I
N
,
q
)
}
s
t
m
t
➔
T
P
s
t
m
t
(
2
)
{
s
t
m
t
.
C
H
I
A
N
:
=
M
E
R
G
(
T
P
.
C
H
I
A
N
,
s
t
m
t
(
2
)
.
C
H
I
A
N
)
}
\begin{aligned} C ➔ &if\ bool\ then\\ \{ &BACKPATCH (bool.TC, NXQ);\\ &C.CHAIN := bool.FC \}\\ stmt➔ &C\ stmt^{(1)}\\ \{&stmt.CHAIN := MERG(C.CHAIN, stmt^{(1)}.CHAIN)\}\\ T^P ➔ &C\ stmt^{(1)}\ else\\ \{ &q := NXQ;\\ &GEN(j, \_, \_, 0);\\ &BACKPATCH(C.CHAIN,NXQ);\\ &T^P.CHAIN := MERGE(stmt^{(1)}.CHAIN,q)\}\\ stmt➔ &T^P\ stmt^{(2)}\\ \{ &stmt.CHIAN := MERG(T^P.CHIAN, stmt^{(2)}.CHIAN)\}\end{aligned}
C➔{stmt➔{TP➔{stmt➔{if bool thenBACKPATCH(bool.TC,NXQ);C.CHAIN:=bool.FC}C stmt(1)stmt.CHAIN:=MERG(C.CHAIN,stmt(1).CHAIN)}C stmt(1) elseq:=NXQ;GEN(j,_,_,0);BACKPATCH(C.CHAIN,NXQ);TP.CHAIN:=MERGE(stmt(1).CHAIN,q)}TP stmt(2)stmt.CHIAN:=MERG(TP.CHIAN,stmt(2).CHIAN)}
s t m t ➔ w h i l e b o o l d o s t m t ∣ d o s t m t w h i l e b o o l ; \begin{aligned} stmt➔ &while\ bool\ do\ stmt\\ &|do\ \ stmt\ \ while\ \ bool;\end{aligned} stmt➔while bool do stmt∣do stmt while bool;
对文法进行改写:
s
t
m
t
➔
W
d
s
t
m
t
∣
W
w
b
o
o
l
;
W
d
➔
W
b
o
o
l
D
W
w
➔
D
s
t
m
t
W
W
➔
w
h
i
l
e
D
➔
d
o
\begin{aligned} stmt➔ & W^d\ stmt\\ |&W^w\ \ bool;\\ W^d➔ &W\ bool\ D\\ W^w➔ &D\ \ stmt\ \ W\\ W ➔ &while\\ D➔ &do\end{aligned}
stmt➔∣Wd➔Ww➔W➔D➔Wd stmtWw bool;W bool DD stmt Wwhiledo
语义动作:
W
➔
w
h
i
l
e
{
W
.
Q
U
A
D
:
=
N
X
Q
}
\begin{aligned} W ➔ &while\\ \{ &W.QUAD := NXQ \}\end{aligned}
W➔{whileW.QUAD:=NXQ}
W w ➔ D s t m t W { B A C K P A T C H ( s t m t . C H A I N , N X Q ) ; W w . Q U A D : = D . Q U A D } s t m t ➔ W w b o o l ; { B A C K P A T C H ( b o o l . T C , W w . Q U A D ) ; s t m t . C H A I N : = b o o l . F C } s t m t ➔ W d s t m t ( 1 ) { B A C H P A T C H ( s t m t ( 1 ) . C H A I N , W d . Q U A D ) ; G E N ( j , _ , _ , W d . Q U A D ) ; s t m t . C H A I N : = W d . C H A I N } W d ➔ W b o o l D { B A C K P A T C H ( b o o l . T C , N X Q ) ; W d . C H A I N : = b o o l . F C ; W d . Q U A D : = W . Q U A D } D ➔ d o { D . Q U A D : = N X Q } \begin{aligned} W^w➔ &D\ \ stmt\ \ W\\ \{ &BACKPATCH (stmt.CHAIN,NXQ);\\ &W^w.QUAD := D.QUAD \}\\ stmt➔ &W^w\ \ bool;\\ \{ &BACKPATCH(bool.TC,W^w.QUAD);\\ &stmt.CHAIN := bool.FC\}\\ stmt➔ &W^d stmt^{(1)}\\ \{ &BACHPATCH(stmt^{(1)}.CHAIN,W^d.QUAD);\\ &GEN(j,\_,\_, W^d.QUAD); \\ &stmt.CHAIN := W^d.CHAIN\}\\ W^d ➔ &W\ bool\ D\\ \{ &BACKPATCH (bool.TC,NXQ);\\ &W^d.CHAIN := bool.FC;\\ &W^d.QUAD := W.QUAD \}\\ D➔ &do\\ \{ &D.QUAD:=NXQ\} \end{aligned} Ww➔{stmt➔{stmt➔{Wd➔{D➔{D stmt WBACKPATCH(stmt.CHAIN,NXQ);Ww.QUAD:=D.QUAD}Ww bool;BACKPATCH(bool.TC,Ww.QUAD);stmt.CHAIN:=bool.FC}Wdstmt(1)BACHPATCH(stmt(1).CHAIN,Wd.QUAD);GEN(j,_,_,Wd.QUAD);stmt.CHAIN:=Wd.CHAIN}W bool DBACKPATCH(bool.TC,NXQ);Wd.CHAIN:=bool.FC;Wd.QUAD:=W.QUAD}doD.QUAD:=NXQ}
s t m t ➔ i d = e x p r ; \begin{aligned} stmt➔&\ \ \ id=expr; \end{aligned} stmt➔ id=expr;
语义动作:
s
t
m
t
➔
i
d
=
e
x
p
r
;
{
s
t
m
t
.
C
H
A
I
N
:
=
0
G
E
N
(
=
,
e
x
p
r
.
P
L
A
C
E
,
_
,
E
N
T
R
Y
(
i
d
)
)
}
\begin{aligned} stmt➔&\ \ \ id=expr;\\ \{ &stmt.CHAIN := 0\\ &GEN(=,expr.PLACE,\_,ENTRY(id))\}\end{aligned}
stmt➔{ id=expr;stmt.CHAIN:=0GEN(=,expr.PLACE,_,ENTRY(id))}
e x p r ➔ e x p r + t e r m ∣ e x p r − t e r m ∣ t e r m t e r m ➔ t e r m ∗ u n a r y ∣ t e r m / u n a r y ∣ u n a r y u n a r y ➔ − u n a r y ∣ f a c t o r f a c t o r ➔ ( e x p r ) ∣ i d ∣ n u m \begin{aligned} expr ➔&expr+ term\ \ |\ \ expr - term\ \ |\ \ term\\ term ➔& term* unary\ \ |\ \ term / unary\ \ |\ \ unary\\ unary ➔&-unary\ \ |\ \ factor\\ factor ➔& (expr )\ \ |\ \ id\ \ |\ \ num\\ \end{aligned} expr➔term➔unary➔factor➔expr+term ∣ expr−term ∣ termterm∗unary ∣ term/unary ∣ unary−unary ∣ factor(expr) ∣ id ∣ num
语义动作:
e
x
p
r
➔
e
x
p
r
(
1
)
+
t
e
r
m
{
e
x
p
r
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
+
,
e
x
p
r
(
1
)
.
P
L
A
C
E
,
t
e
r
m
.
P
L
A
C
E
,
e
x
p
r
.
P
L
A
C
E
)
}
e
x
p
r
➔
e
x
p
r
(
1
)
−
t
e
r
m
{
e
x
p
r
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
−
,
e
x
p
r
(
1
)
.
P
L
A
C
E
,
t
e
r
m
.
P
L
A
C
E
,
e
x
p
r
.
P
L
A
C
E
)
}
e
x
p
r
➔
t
e
r
m
{
e
x
p
r
.
P
L
A
C
E
:
=
t
e
r
m
.
P
L
A
C
E
}
t
e
r
m
➔
t
e
r
m
(
1
)
∗
u
n
a
r
y
{
t
e
r
m
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
∗
,
t
e
r
m
(
1
)
.
P
L
A
C
E
,
u
n
a
r
y
.
P
L
A
C
E
,
t
e
r
m
.
P
L
A
C
E
)
}
t
e
r
m
➔
t
e
r
m
(
1
)
/
u
n
a
r
y
{
t
e
r
m
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
/
,
t
e
r
m
(
1
)
.
P
L
A
C
E
,
u
n
a
r
y
.
P
L
A
C
E
,
t
e
r
m
.
P
L
A
C
E
)
}
t
e
r
m
➔
u
n
a
r
y
{
t
e
r
m
.
P
L
A
C
E
:
=
u
n
a
r
y
.
P
L
A
C
E
}
u
n
a
r
y
➔
−
u
n
a
r
y
(
1
)
{
u
n
a
r
y
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
@
,
u
n
a
r
y
(
1
)
.
P
L
A
C
E
,
_
,
u
n
a
r
y
.
P
L
A
C
E
)
}
u
n
a
r
y
➔
f
a
c
t
o
r
{
u
n
a
r
y
.
P
L
A
C
E
:
=
f
a
c
t
o
r
.
P
L
A
C
E
}
f
a
c
t
o
r
➔
(
e
x
p
r
)
{
f
a
c
t
o
r
.
P
L
A
C
E
:
=
e
x
p
r
.
P
L
A
C
E
}
f
a
c
t
o
r
➔
i
d
{
f
a
c
t
o
r
.
P
L
A
C
E
=
E
N
T
R
Y
(
i
d
)
}
f
a
c
t
o
r
➔
n
u
m
{
f
a
c
t
o
r
.
P
L
A
C
E
=
n
u
m
.
P
L
A
C
E
}
\begin{aligned} expr ➔&expr^{(1)}+ term\\ \{&expr.PLACE:=NEWTEMP;\\ &GEN(+,expr^{(1)}.PLACE,term.PLACE,expr.PLACE)\}\\ expr ➔&expr^{(1)}-term\\ \{&expr.PLACE:=NEWTEMP;\\ &GEN(-,expr^{(1)}.PLACE,term.PLACE,expr.PLACE)\}\\ expr ➔&term\\ \{&expr.PLACE:=term.PLACE\}\\ term ➔&term ^{(1)}*unary\\ \{&term .PLACE:=NEWTEMP;\\ &GEN(*,term ^{(1)}.PLACE,unary.PLACE,term .PLACE)\}\\ term ➔&term ^{(1)}/unary\\ \{&term .PLACE:=NEWTEMP;\\ &GEN(/,term ^{(1)}.PLACE,unary.PLACE,term .PLACE)\}\\ term ➔&unary\\ \{&term .PLACE:=unary.PLACE\}\\ unary ➔&-unary^{(1)}\\ \{&unary .PLACE:=NEWTEMP;\\ &GEN(@,unary^{(1)}.PLACE,\_,unary .PLACE)\}\\ unary ➔&factor\\ \{&unary .PLACE:=factor.PLACE\}\\ factor ➔& (expr)\\ \{&factor.PLACE:=expr.PLACE\}\\ factor ➔& id\\ \{&factor.PLACE=ENTRY(id)\}\\ factor ➔& num\\ \{&factor.PLACE=num.PLACE\}\\ \end{aligned}
expr➔{expr➔{expr➔{term➔{term➔{term➔{unary➔{unary➔{factor➔{factor➔{factor➔{expr(1)+termexpr.PLACE:=NEWTEMP;GEN(+,expr(1).PLACE,term.PLACE,expr.PLACE)}expr(1)−termexpr.PLACE:=NEWTEMP;GEN(−,expr(1).PLACE,term.PLACE,expr.PLACE)}termexpr.PLACE:=term.PLACE}term(1)∗unaryterm.PLACE:=NEWTEMP;GEN(∗,term(1).PLACE,unary.PLACE,term.PLACE)}term(1)/unaryterm.PLACE:=NEWTEMP;GEN(/,term(1).PLACE,unary.PLACE,term.PLACE)}unaryterm.PLACE:=unary.PLACE}−unary(1)unary.PLACE:=NEWTEMP;GEN(@,unary(1).PLACE,_,unary.PLACE)}factorunary.PLACE:=factor.PLACE}(expr)factor.PLACE:=expr.PLACE}idfactor.PLACE=ENTRY(id)}numfactor.PLACE=num.PLACE}
b o o l ➔ b o o l o r j o i n ∣ j o i n j o i n ➔ j o i n a n d e q u a l i t y ∣ e q u a l i t y e q u a l i t y ➔ e q u a l i t y = = r e l ∣ e q u a l i t y ! = r e l ∣ r e l ∣ t r u e ∣ f a l s e r e l ➔ r e l < r e l e x p r ∣ r e l < = r e l e x p r ∣ r e l > = r e l e x p r ∣ r e l > r e l e x p r ∣ r e l e x p r r e l e x p r ➔ r e l e x p r + r e l t e r m ∣ r e l e x p r − r e l t e r m ∣ r e l t e r m r e l t e r m ➔ r e l t e r m ∗ r e l u n a r y ∣ r e l t e r m / r e l u n a r y ∣ r e l u n a r y r e l u n a r y ➔ ! r e l u n a r y ∣ − r e l u n a r y ∣ r e l f a c t o r r e l f a c t o r ➔ ( b o o l ) ∣ i d ∣ n u m \begin{aligned} bool➔&bool\ \ or\ \ join\ \ |\ \ join\\ join➔&join\ \ and\ \ equality\ \ |\ \ equality\\ equality➔&equality==rel\ \ |\ \ equality\ \ !=\ \ rel \ \ |\ \ rel\\ &|\ \ true\ \ |\ \ false\\ rel➔& rel<relexpr\ \ |\ \ rel<=relexpr\ \ |\ \ rel>=relexpr\ \ |\\ &rel>relexpr\ \ |\ \ relexpr\\ relexpr ➔&relexpr+ relterm\ \ |\ \ relexpr -relterm\ \ |\ \ relterm\\ relterm ➔& relterm* relunary\ \ |\ \ relterm / relunary\ \ |\ \ relunary\\ relunary ➔&!relunary\ \ |\ \ -relunary\ \ |\ \ relfactor\\ relfactor ➔& (bool)\ \ |\ \ id\ \ |\ \ num\\ \end{aligned} bool➔join➔equality➔rel➔relexpr➔relterm➔relunary➔relfactor➔bool or join ∣ joinjoin and equality ∣ equalityequality==rel ∣ equality != rel ∣ rel∣ true ∣ falserel<relexpr ∣ rel<=relexpr ∣ rel>=relexpr ∣rel>relexpr ∣ relexprrelexpr+relterm ∣ relexpr−relterm ∣ reltermrelterm∗relunary ∣ relterm/relunary ∣ relunary!relunary ∣ −relunary ∣ relfactor(bool) ∣ id ∣ num
为了更方便地进行语义分析,对该文法进一步改造:
b
o
o
l
➔
b
o
o
l
o
r
j
o
i
n
∣
j
o
i
n
j
o
i
n
➔
j
o
i
n
a
n
d
b
o
o
l
t
e
r
m
∣
b
o
o
l
t
e
r
m
b
o
o
l
o
r
➔
b
o
o
l
o
r
j
o
i
n
a
n
d
➔
j
o
i
n
a
n
d
b
o
o
l
t
e
r
m
➔
e
q
u
a
l
i
t
y
e
q
u
a
l
i
t
y
➔
e
q
u
a
l
i
t
y
=
=
r
e
l
∣
e
q
u
a
l
i
t
y
!
=
r
e
l
∣
r
e
l
∣
t
r
u
e
∣
f
a
l
s
e
r
e
l
➔
r
e
l
<
r
e
l
e
x
p
r
∣
r
e
l
<
=
r
e
l
e
x
p
r
∣
r
e
l
>
=
r
e
l
e
x
p
r
∣
r
e
l
>
r
e
l
e
x
p
r
∣
r
e
l
e
x
p
r
r
e
l
e
x
p
r
➔
r
e
l
e
x
p
r
+
r
e
l
t
e
r
m
∣
r
e
l
e
x
p
r
−
r
e
l
t
e
r
m
∣
r
e
l
t
e
r
m
r
e
l
t
e
r
m
➔
r
e
l
t
e
r
m
∗
r
e
l
u
n
a
r
y
∣
r
e
l
t
e
r
m
/
r
e
l
u
n
a
r
y
∣
r
e
l
u
n
a
r
y
r
e
l
u
n
a
r
y
➔
!
r
e
l
u
n
a
r
y
∣
−
r
e
l
u
n
a
r
y
∣
r
e
l
f
a
c
t
o
r
r
e
l
f
a
c
t
o
r
➔
(
b
o
o
l
)
∣
i
d
∣
n
u
m
\begin{aligned} bool➔&bool^{or}\ \ join\ \ |\ \ join\\ join➔&join^{and}\ \ bool^{term}\ \ |\ \ bool^{term}\\ bool^{or}➔&bool\ \ or\\ join^{and}➔&join\ \ and\\ bool^{term}➔&equality\\ equality➔&equality==rel\ \ |\ \ equality\ \ !=\ \ rel \ \ |\ \ rel\\ &|\ \ true\ \ |\ \ false\\ rel➔& rel<relexpr\ \ |\ \ rel<=relexpr\ \ |\ \ rel>=relexpr\ \ |\\ &rel>relexpr\ \ |\ \ relexpr\\ relexpr ➔&relexpr+ relterm\ \ |\ \ relexpr -relterm\ \ |\ \ relterm\\ relterm ➔& relterm* relunary\ \ |\ \ relterm / relunary\ \ |\ \ relunary\\ relunary ➔&!relunary\ \ |\ \ -relunary\ \ |\ \ relfactor\\ relfactor ➔& (bool)\ \ |\ \ id\ \ |\ \ num\\ \end{aligned}
bool➔join➔boolor➔joinand➔boolterm➔equality➔rel➔relexpr➔relterm➔relunary➔relfactor➔boolor join ∣ joinjoinand boolterm ∣ booltermbool orjoin andequalityequality==rel ∣ equality != rel ∣ rel∣ true ∣ falserel<relexpr ∣ rel<=relexpr ∣ rel>=relexpr ∣rel>relexpr ∣ relexprrelexpr+relterm ∣ relexpr−relterm ∣ reltermrelterm∗relunary ∣ relterm/relunary ∣ relunary!relunary ∣ −relunary ∣ relfactor(bool) ∣ id ∣ num
语义动作
b
o
o
l
➔
b
o
o
l
o
r
j
o
i
n
{
b
o
o
l
.
P
L
A
C
E
=
b
o
o
l
o
r
.
P
L
A
C
E
∣
∣
j
o
i
n
.
P
L
A
C
E
b
o
o
l
.
T
C
=
M
E
R
G
(
b
o
o
l
o
r
.
T
C
,
j
o
i
n
.
T
C
)
;
b
o
o
l
.
F
C
=
j
o
i
n
.
F
C
}
b
o
o
l
➔
j
o
i
n
{
b
o
o
l
.
P
L
A
C
E
=
j
o
i
n
.
P
L
A
C
E
b
o
o
l
.
T
C
=
j
o
i
n
.
T
C
;
b
o
o
l
.
F
C
=
j
o
i
n
.
F
C
}
j
o
i
n
➔
j
o
i
n
a
n
d
b
o
o
l
t
e
r
m
{
j
o
i
n
.
P
L
A
C
E
=
j
o
i
n
a
n
d
.
P
L
A
C
E
&
&
b
o
o
l
t
e
r
m
.
P
L
A
C
E
j
o
i
n
.
F
C
=
M
E
R
G
(
j
o
i
n
a
n
d
.
F
C
,
b
o
o
l
t
e
r
m
.
F
C
)
;
j
o
i
n
.
T
C
=
b
o
o
l
t
e
r
m
.
T
C
}
j
o
i
n
➔
b
o
o
l
t
e
r
m
{
j
o
i
n
.
P
L
A
C
E
=
b
o
o
l
t
e
r
m
.
P
L
A
C
E
j
o
i
n
.
T
C
=
b
o
o
l
t
e
r
m
.
T
C
;
j
o
i
n
.
F
C
=
b
o
o
l
t
e
r
m
.
F
C
}
b
o
o
l
o
r
➔
b
o
o
l
o
r
{
b
o
o
l
o
r
.
P
L
A
C
E
=
b
o
o
l
.
P
L
A
C
E
B
A
C
K
P
A
T
C
H
(
b
o
o
l
.
F
C
,
N
X
Q
)
;
b
o
o
l
o
r
.
T
C
=
b
o
o
l
.
T
C
}
j
o
i
n
a
n
d
➔
j
o
i
n
a
n
d
{
j
o
i
n
a
n
d
.
P
L
A
C
E
=
j
o
i
n
.
P
L
A
C
E
B
A
C
K
P
A
T
C
H
(
j
o
i
n
.
T
C
,
N
X
Q
)
;
j
o
i
n
a
n
d
.
F
C
=
j
o
i
n
.
F
C
}
b
o
o
l
t
e
r
m
➔
e
q
u
a
l
i
t
y
{
b
o
o
l
t
e
r
m
.
P
L
A
C
E
=
e
q
u
a
l
i
t
y
.
P
L
A
C
E
b
o
o
l
t
e
r
m
.
T
C
=
N
X
Q
;
b
o
o
l
t
e
r
m
.
F
C
=
N
X
Q
+
1
;
G
E
N
(
j
t
r
u
e
,
e
q
u
a
l
i
t
y
.
P
L
A
C
E
,
_
,
0
)
;
G
E
N
(
j
,
_
,
_
,
0
)
}
e
q
u
a
l
i
t
y
➔
e
q
u
a
l
i
t
y
(
1
)
=
=
r
e
l
{
e
q
u
a
l
i
t
y
.
P
L
A
C
E
=
N
E
W
T
E
M
P
;
G
E
N
(
=
=
,
e
q
u
a
l
i
t
y
(
1
)
.
P
L
A
C
E
,
r
e
l
.
P
L
A
C
E
,
e
q
u
a
l
i
t
y
.
P
L
A
C
E
)
}
e
q
u
a
l
i
t
y
➔
e
q
u
a
l
i
t
y
(
1
)
!
=
r
e
l
{
e
q
u
a
l
i
t
y
.
P
L
A
C
E
=
N
E
W
T
E
M
P
;
G
E
N
(
!
=
,
e
q
u
a
l
i
t
y
(
1
)
.
P
L
A
C
E
,
r
e
l
.
P
L
A
C
E
,
e
q
u
a
l
i
t
y
.
P
L
A
C
E
)
}
e
q
u
a
l
i
t
y
➔
r
e
l
{
e
q
u
a
l
i
t
y
.
P
L
A
C
E
=
r
e
l
.
P
L
A
C
E
}
e
q
u
a
l
i
t
y
➔
t
r
u
e
{
e
q
u
a
l
i
t
y
.
P
L
A
C
E
=
t
r
u
e
}
e
q
u
a
l
i
t
y
➔
f
a
l
s
e
{
e
q
u
a
l
i
t
y
.
P
L
A
C
E
=
f
a
l
s
e
}
r
e
l
➔
r
e
l
(
1
)
<
r
e
l
e
x
p
r
{
r
e
l
.
P
L
A
C
E
=
N
E
W
T
E
M
P
;
G
E
N
(
<
,
r
e
l
(
1
)
.
P
L
A
C
E
,
r
e
l
e
x
p
r
.
P
L
A
C
E
,
r
e
l
.
P
L
A
C
E
)
}
r
e
l
➔
r
e
l
(
1
)
<
=
r
e
l
e
x
p
r
{
r
e
l
.
P
L
A
C
E
=
N
E
W
T
E
M
P
;
G
E
N
(
<
=
,
r
e
l
(
1
)
.
P
L
A
C
E
,
r
e
l
e
x
p
r
.
P
L
A
C
E
,
r
e
l
.
P
L
A
C
E
)
}
r
e
l
➔
r
e
l
(
1
)
>
r
e
l
e
x
p
r
{
r
e
l
.
P
L
A
C
E
=
N
E
W
T
E
M
P
;
G
E
N
(
>
,
r
e
l
(
1
)
.
P
L
A
C
E
,
r
e
l
e
x
p
r
.
P
L
A
C
E
,
r
e
l
.
P
L
A
C
E
)
}
r
e
l
➔
r
e
l
(
1
)
>
=
r
e
l
e
x
p
r
{
r
e
l
.
P
L
A
C
E
=
N
E
W
T
E
M
P
;
G
E
N
(
>
=
,
r
e
l
(
1
)
.
P
L
A
C
E
,
r
e
l
e
x
p
r
.
P
L
A
C
E
,
r
e
l
.
P
L
A
C
E
)
}
r
e
l
➔
r
e
l
e
x
p
r
{
r
e
l
.
P
L
A
C
E
=
r
e
l
e
x
p
r
.
P
L
A
C
E
)
}
r
e
l
e
x
p
r
➔
r
e
l
e
x
p
r
(
1
)
+
r
e
l
t
e
r
m
{
r
e
l
e
x
p
r
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
+
,
r
e
l
e
x
p
r
(
1
)
.
P
L
A
C
E
,
r
e
l
t
e
r
m
.
P
L
A
C
E
,
r
e
l
e
x
p
r
.
P
L
A
C
E
)
}
r
e
l
e
x
p
r
➔
r
e
l
e
x
p
r
(
1
)
−
t
e
r
m
{
r
e
l
e
x
p
r
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
−
,
r
e
l
e
x
p
r
(
1
)
.
P
L
A
C
E
,
r
e
l
t
e
r
m
.
P
L
A
C
E
,
r
e
l
e
x
p
r
.
P
L
A
C
E
)
}
r
e
l
e
x
p
r
➔
r
e
l
t
e
r
m
{
r
e
l
e
x
p
r
.
P
L
A
C
E
:
=
r
e
l
t
e
r
m
.
P
L
A
C
E
}
r
e
l
t
e
r
m
➔
r
e
l
t
e
r
m
(
1
)
∗
r
e
l
u
n
a
r
y
{
r
e
l
t
e
r
m
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
∗
,
r
e
l
t
e
r
m
(
1
)
.
P
L
A
C
E
,
r
e
l
u
n
a
r
y
.
P
L
A
C
E
,
r
e
l
t
e
r
m
.
P
L
A
C
E
)
}
r
e
l
t
e
r
m
➔
r
e
l
t
e
r
m
(
1
)
/
r
e
l
u
n
a
r
y
{
r
e
l
t
e
r
m
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
/
,
t
e
r
m
(
1
)
.
P
L
A
C
E
,
r
e
l
u
n
a
r
y
.
P
L
A
C
E
,
r
e
l
t
e
r
m
.
P
L
A
C
E
)
}
r
e
l
t
e
r
m
➔
r
e
l
u
n
a
r
y
{
r
e
l
t
e
r
m
.
P
L
A
C
E
:
=
r
e
l
u
n
a
r
y
.
P
L
A
C
E
}
r
e
l
u
n
a
r
y
➔
−
r
e
l
u
n
a
r
y
(
1
)
{
r
e
l
u
n
a
r
y
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
@
,
r
e
l
u
n
a
r
y
(
1
)
.
P
L
A
C
E
,
_
,
r
e
l
u
n
a
r
y
.
P
L
A
C
E
)
}
r
e
l
u
n
a
r
y
➔
!
r
e
l
u
n
a
r
y
(
1
)
{
r
e
l
u
n
a
r
y
.
P
L
A
C
E
:
=
N
E
W
T
E
M
P
;
G
E
N
(
!
,
r
e
l
u
n
a
r
y
(
1
)
.
P
L
A
C
E
,
_
,
r
e
l
u
n
a
r
y
.
P
L
A
C
E
)
}
r
e
l
u
n
a
r
y
➔
r
e
l
f
a
c
t
o
r
{
r
e
l
u
n
a
r
y
.
P
L
A
C
E
:
=
r
e
l
f
a
c
t
o
r
.
P
L
A
C
E
}
r
e
l
f
a
c
t
o
r
➔
n
u
m
{
r
e
l
f
a
c
t
o
r
.
P
L
A
C
E
=
n
u
m
.
P
L
A
C
E
}
r
e
l
f
a
c
t
o
r
➔
i
d
{
r
e
l
f
a
c
t
o
r
.
P
L
A
C
E
=
E
N
T
R
Y
(
i
d
)
}
r
e
l
f
a
c
t
o
r
➔
(
b
o
o
l
)
{
B
A
C
K
P
A
T
C
H
(
b
o
o
l
.
T
C
,
N
X
Q
)
;
B
A
C
K
P
A
T
C
H
(
b
o
o
l
.
F
C
,
N
X
Q
)
;
r
e
l
f
a
c
t
o
r
.
P
L
A
C
E
=
b
o
o
l
.
P
L
A
C
E
}
\begin{aligned} bool➔&bool^{or}\ \ join\\ \{&bool.PLACE=bool^{or}.PLACE\ ||\ join.PLACE\\ &bool.TC=MERG(bool^{or}.TC,join.TC);\\ &bool.FC=join.FC\}\\ bool➔&join\\ \{&bool.PLACE=join.PLACE\\ &bool.TC=join.TC;\\ &bool.FC=join.FC\}\\ join➔&join^{and}\ \ bool^{term}\\ \{&join.PLACE=join^{and}.PLACE\ \&\&\ bool^{term}.PLACE\\ &join.FC=MERG(join^{and}.FC, bool^{term}.FC);\\ &join.TC= bool^{term}.TC\}\\ join➔&bool^{term}\\ \{&join.PLACE=bool^{term}.PLACE\\ &join.TC= bool^{term}.TC;\\ &join.FC= bool^{term}.FC\}\\ bool^{or}➔&bool\ \ or\\ \{&bool^{or}.PLACE=bool.PLACE\\ &BACKPATCH(bool.FC,NXQ);\\ &bool^{or}.TC=bool.TC\}\\ join^{and}➔&join\ \ and\\ \{&join^{and}.PLACE=join.PLACE\\ &BACKPATCH(join.TC,NXQ);\\ &join^{and}.FC=join.FC\}\\ bool^{term}➔&equality\\ \{&bool^{term}.PLACE=equality.PLACE\\ &bool^{term}.TC=NXQ;\\ &bool^{term}.FC=NXQ+1;\\ &GEN(j_{true},equality.PLACE,\_,0);\\ &GEN(j,\_,\_,0)\}\\ equality➔&equality^{(1)}==rel\\ \{&equality.PLACE=NEWTEMP;\\ &GEN(==,equality^{(1)}.PLACE,rel.PLACE,equality.PLACE)\}\\ equality➔&equality^{(1)}!=rel\\ \{&equality.PLACE=NEWTEMP;\\ &GEN(!=,equality^{(1)}.PLACE,rel.PLACE,equality.PLACE)\}\\ equality➔&rel\\ \{&equality.PLACE=rel.PLACE\}\\ equality➔&true\\ \{&equality.PLACE=true\}\\ equality➔&false\\ \{&equality.PLACE=false\}\\ rel➔& rel^{(1)}<relexpr\\ \{&rel.PLACE=NEWTEMP;\\ &GEN(<,rel^{(1)}.PLACE,relexpr.PLACE,rel.PLACE)\}\\ rel➔& rel^{(1)}<=relexpr\\ \{&rel.PLACE=NEWTEMP;\\ &GEN(<=,rel^{(1)}.PLACE,relexpr.PLACE,rel.PLACE)\}\\ rel➔& rel^{(1)}>relexpr\\ \{&rel.PLACE=NEWTEMP;\\ &GEN(>,rel^{(1)}.PLACE,relexpr.PLACE,rel.PLACE)\}\\ rel➔& rel^{(1)}>=relexpr\\ \{&rel.PLACE=NEWTEMP;\\ &GEN(>=,rel^{(1)}.PLACE,relexpr.PLACE,rel.PLACE)\}\\ rel➔& relexpr\\ \{&rel.PLACE=relexpr.PLACE)\}\\ relexpr ➔&relexpr^{(1)}+ relterm\\ \{&relexpr.PLACE:=NEWTEMP;\\ &GEN(+,relexpr^{(1)}.PLACE,relterm.PLACE,relexpr.PLACE)\}\\ relexpr ➔&relexpr^{(1)}-term\\ \{&relexpr.PLACE:=NEWTEMP;\\ &GEN(-,relexpr^{(1)}.PLACE,relterm.PLACE,relexpr.PLACE)\}\\ relexpr ➔&relterm\\ \{&relexpr.PLACE:=relterm.PLACE\}\\ relterm ➔&relterm ^{(1)}*relunary\\ \{&relterm .PLACE:=NEWTEMP;\\ &GEN(*,relterm ^{(1)}.PLACE,relunary.PLACE,relterm .PLACE)\}\\ relterm ➔&relterm ^{(1)}/relunary\\ \{&relterm .PLACE:=NEWTEMP;\\ &GEN(/,term ^{(1)}.PLACE,relunary.PLACE,relterm .PLACE)\}\\ relterm ➔&relunary\\ \{&relterm .PLACE:=relunary.PLACE\}\\ relunary ➔&-relunary^{(1)}\\ \{&relunary .PLACE:=NEWTEMP;\\ &GEN(@,relunary^{(1)}.PLACE,\_,relunary .PLACE)\}\\ relunary ➔&!relunary^{(1)}\\ \{&relunary .PLACE:=NEWTEMP;\\ &GEN(!,relunary^{(1)}.PLACE,\_,relunary .PLACE)\}\\ relunary ➔&relfactor\\ \{&relunary .PLACE:=relfactor.PLACE\}\\ relfactor ➔& num\\ \{&relfactor.PLACE=num.PLACE\}\\ relfactor ➔& id\\ \{&relfactor.PLACE=ENTRY(id)\}\\ relfactor➔& (bool)\\ \{&BACKPATCH(bool.TC,NXQ);\\ &BACKPATCH(bool.FC,NXQ);\\ &relfactor.PLACE=bool.PLACE\}\\ \end{aligned}
bool➔{bool➔{join➔{join➔{boolor➔{joinand➔{boolterm➔{equality➔{equality➔{equality➔{equality➔{equality➔{rel➔{rel➔{rel➔{rel➔{rel➔{relexpr➔{relexpr➔{relexpr➔{relterm➔{relterm➔{relterm➔{relunary➔{relunary➔{relunary➔{relfactor➔{relfactor➔{relfactor➔{boolor joinbool.PLACE=boolor.PLACE ∣∣ join.PLACEbool.TC=MERG(boolor.TC,join.TC);bool.FC=join.FC}joinbool.PLACE=join.PLACEbool.TC=join.TC;bool.FC=join.FC}joinand booltermjoin.PLACE=joinand.PLACE && boolterm.PLACEjoin.FC=MERG(joinand.FC,boolterm.FC);join.TC=boolterm.TC}booltermjoin.PLACE=boolterm.PLACEjoin.TC=boolterm.TC;join.FC=boolterm.FC}bool orboolor.PLACE=bool.PLACEBACKPATCH(bool.FC,NXQ);boolor.TC=bool.TC}join andjoinand.PLACE=join.PLACEBACKPATCH(join.TC,NXQ);joinand.FC=join.FC}equalityboolterm.PLACE=equality.PLACEboolterm.TC=NXQ;boolterm.FC=NXQ+1;GEN(jtrue,equality.PLACE,_,0);GEN(j,_,_,0)}equality(1)==relequality.PLACE=NEWTEMP;GEN(==,equality(1).PLACE,rel.PLACE,equality.PLACE)}equality(1)!=relequality.PLACE=NEWTEMP;GEN(!=,equality(1).PLACE,rel.PLACE,equality.PLACE)}relequality.PLACE=rel.PLACE}trueequality.PLACE=true}falseequality.PLACE=false}rel(1)<relexprrel.PLACE=NEWTEMP;GEN(<,rel(1).PLACE,relexpr.PLACE,rel.PLACE)}rel(1)<=relexprrel.PLACE=NEWTEMP;GEN(<=,rel(1).PLACE,relexpr.PLACE,rel.PLACE)}rel(1)>relexprrel.PLACE=NEWTEMP;GEN(>,rel(1).PLACE,relexpr.PLACE,rel.PLACE)}rel(1)>=relexprrel.PLACE=NEWTEMP;GEN(>=,rel(1).PLACE,relexpr.PLACE,rel.PLACE)}relexprrel.PLACE=relexpr.PLACE)}relexpr(1)+reltermrelexpr.PLACE:=NEWTEMP;GEN(+,relexpr(1).PLACE,relterm.PLACE,relexpr.PLACE)}relexpr(1)−termrelexpr.PLACE:=NEWTEMP;GEN(−,relexpr(1).PLACE,relterm.PLACE,relexpr.PLACE)}reltermrelexpr.PLACE:=relterm.PLACE}relterm(1)∗relunaryrelterm.PLACE:=NEWTEMP;GEN(∗,relterm(1).PLACE,relunary.PLACE,relterm.PLACE)}relterm(1)/relunaryrelterm.PLACE:=NEWTEMP;GEN(/,term(1).PLACE,relunary.PLACE,relterm.PLACE)}relunaryrelterm.PLACE:=relunary.PLACE}−relunary(1)relunary.PLACE:=NEWTEMP;GEN(@,relunary(1).PLACE,_,relunary.PLACE)}!relunary(1)relunary.PLACE:=NEWTEMP;GEN(!,relunary(1).PLACE,_,relunary.PLACE)}relfactorrelunary.PLACE:=relfactor.PLACE}numrelfactor.PLACE=num.PLACE}idrelfactor.PLACE=ENTRY(id)}(bool)BACKPATCH(bool.TC,NXQ);BACKPATCH(bool.FC,NXQ);relfactor.PLACE=bool.PLACE}
Token 类为词法单元的基类,定义了词类编码以及词法单元的行数;Num 类 (数值常量)、Word 类 (标识符 & 关键字)、RelOpt 类 (关系运算符 >= <= != ==)、Char 类 (字符常量)、String 类 (字符串常量) 均为 Token 类的派生类,分别添加了词素、数值等属性值// 词法单元
class Token {
public:
// 下面是词法单元的词类符号
// 用大于 char (255) 的数值表示终结符号
// 小于 255 :用作 operator (运算符), delimiter (界符)
enum TAGS : unsigned {
NUM = 256, // 数值常量
ID, // 标识符
REL_OPT, // 关系运算符
CHAR, // 字符常量
STRING, // 字符串常量
// 以下为关键字,均用大写表示
// ***********在这里添加关键字之后也要在 lexer.cpp 的 Keywords 中添加相应项目***********
KEYWORD_POS, // 保留,标记关键字开始的数值
TRUE,
FALSE,
IF,
ELSE,
THEN,
WHILE,
DO,
INT,
REAL,
OR,
AND,
};
Token(const int &t = 0) : tag(t) {}
virtual ~Token() = default;
virtual std::ostream& print(std::ostream& os)
{ os << "line" << line << ": <" << static_cast<char>(tag)
<< '>'; return os; }
int tag; // 词类编码
size_t line; // 每个词法单元出现的行数
};
Lexer 类实现// 词法分析器
class Lexer {
public:
Lexer(std::string name = ".\\code.txt");
~Lexer();
Token* gen_token();
// ... 这里省略了一些源代码,只粘贴一些比较重要的代码
private:
char peek = ' '; // 从源文件预读的一个字符
std::unordered_map<std::string, int> ID_table; // 关键字表
std::ifstream in; // 源文件
// 功能函数
Token* scan();
Token* skip_blank(void); // 跳过空白
Token* handle_slash(void); // 处理斜杠 /,可能使注释或除号
// 处理 > < = !,可能是关系运算符,也可能是赋值运算符或取反运算符
Token* handle_relation_opterator(void);
Token* handle_digit(void); // 处理数字
// 处理单词 (标识符 或 关键字) 允许下划线或字母打头,后面跟下划线/数字/字母
Token* handle_word(void);
Token* handle_char(void); // 处理字符常量
Token* handle_string(void); // 处理字符串常量
};
Token* Lexer::scan(){
Token *token; // 识别出的词法单元
if (!(in >> peek))
{
return nullptr;
}
char judger = peek; // 放在 switch case 里做条件判断
if (isdigit(judger))
{
judger = '0'; // 所有数字都转成 0
}
else if (isalpha(judger))
{
judger = 'a'; // 所有字母都转成 a
}
switch (judger)
{
case ' ': case '\t': case '\n':
token = skip_blank(); // 跳过空白
break;
case '/':
token = handle_slash(); // 处理注释和除号
break;
case '>': case '<': case '!': case '=':
token = handle_relation_opterator();
break;
case '0': // 处理数字
token = handle_digit();
break;
case 'a': case '_': // 处理 标识符 / 关键字
token = handle_word();
break;
case '\'': // 处理字符常量
token = handle_char();
break;
case '\"': // 处理字符串常量
token = handle_string();
break;
default: // 其他单个的字符,组成词法单元
token = new Token(peek);
break;
}
if (token)
{
token->line = line;
}
return token;
}
下面仅介绍识别关键字、标识符、数字常量的功能函数,其余函数较简单且思路相同
Lexer 的初始化函数中将所有关键字以及对应的词类编码加入关键字表中;关键字表的数据类型为 unordered_map<string, int>,底层使用哈希函数进行查找,效率较高next_peek,只要预读的符号为字母、数字或下划线,就一直读入,直至读出整个标识符的词素;接着在关键字表中查找该单词的词素,如果关键字表中找到该词素,说明单词为关键字,返回关键字表中的词类编码;否则返回标识符的词类编码Token* Lexer::handle_word(void)
{
string lexeme;
char next_peek;
Token* token;
lexeme.push_back(peek);
next_peek = in.peek();
while (in && (isalpha(next_peek) || isdigit(next_peek) || next_peek == '_'))
{
in >> peek;
lexeme.push_back(peek);
next_peek = in.peek();
}
auto it = ID_table.find(lexeme);
if (it == ID_table.end()) // 该词素不在关键字表内
{
token = new Word(lexeme, Token::ID);
}else{
token = new Word(lexeme, it->second);
}
return token;
}

// 支持科学计数法
Token* Lexer::handle_digit(void)
{
char next_peek = in.peek();
auto to_digit = [](const char c) -> int { return (c - '0'); };
double num = to_digit(peek); // 数字常量的值
double decimal = 0; // 小数部分
int decimal_bit = 0; // 小数的位数
// 把 e 之前的数字都读出来存到 string 里,然后用 stod(s) 转成 double 更方便些,但是不想改了
while (in && isdigit(next_peek))
{
in >> peek;
next_peek = in.peek();
num = num * 10 + to_digit(peek);
}
if (in && next_peek == '.')
{
in >> peek; // 读出小数点
next_peek = in.peek();
if (!in || !isdigit(next_peek)) // 小数点后必须要跟一位数字,不然就是拼写错误
{
string line_msg = "Line" + to_string(line) + ": ";
throw runtime_error(line_msg + "No number after \'.\' !");
}
in >> peek; // 读出小数点后的一位数
next_peek = in.peek();
decimal = to_digit(peek);
decimal_bit = 1;
while (in && isdigit(next_peek))
{
in >> peek;
next_peek = in.peek();
decimal = decimal * 10 + to_digit(peek);
++decimal_bit;
}
decimal /= pow(10, decimal_bit);
num += decimal;
}
if (in && next_peek == 'e')
{
int exp = 0; // 指数
int flag = 1; // 指数符号
in >> peek; // 读入 e
next_peek = in.peek();
if (in && (next_peek == '+' || next_peek == '-'))
{
in >> peek;
flag = (peek == '+') ? 1 : -1;
next_peek = in.peek();
}
if (!isdigit(next_peek)) // e 后必须要跟一位数字,不然就是拼写错误
{
string line_msg = "Line" + to_string(line) + ": ";
throw runtime_error(line_msg + "No number after \'e\' !");
}
while (isdigit(next_peek) && in >> peek)
{
next_peek = in.peek();
exp = exp * 10 + to_digit(peek);
}
num = num * pow(10, exp);
}
return new Num(num);
}
Grammer 类:主要用来存储输入的文法并计算该文法的所有文法符号的
F
I
R
S
T
FIRST
FIRST 集
grammer.txt 中即可自动读入文法并求出
F
I
R
S
T
FIRST
FIRST 集;默认读入的文法为增广文法并且第一条规则左部即为开始符号。允许文法存在二义性 (例如
i
f
if
if-
e
l
s
e
else
else 语句),但这意味着之后
L
R
LR
LR 分析表有冲突,因此必须在程序中手动解决冲突;输入样例如下:// 输入样例:(符号与符号之间一定要有空格,终结符和非终结符支持多个字母)
// 先输入产生式,后输入非终结符,最后输入终结符,中间用 # 隔开
A -> S
S -> C C
C -> c C
C -> d
#
A S C #
c d #
Grammer 类中的 first_set() 成员函数提供了求
F
I
R
S
T
FIRST
FIRST 集的功能,思路如下:
$ 表示),则将其加入到产生式左部非终结符
S
S
S 的
F
I
R
S
T
FIRST
FIRST 集中void Grammer::first_set()
{
// 终结符的 FIRST 集为它本身
for (auto it = T.begin(); it != T.end(); ++it)
{
first[*it].insert(*it);
}
// 当非终结符的 FIRST 集发生变化时循环
bool change = true;
while (change)
{
change = false;
// 枚举每个产生式
for (auto it = productions.begin(); it != productions.end(); ++it) {
sym_t left = it->get_left(); // 产生式左部
vector<sym_t> right = it->get_right(); // 产生式右部
// A -> $
// 如果右部第一个符号是空或者是终结符,则加入到左部的 FIRST 集中
if (first_is_T(*it))
{
// 查找 FIRST 集是否已经存在该符号
if (first[left].find(right[0]) == first[left].end())
{
// FIRST 集不存在该符号
change = true; // 标注 FIRST 集发生变化,循环继续
first[it->get_left()].insert((it->get_right())[0]);
}
}
else { // 当前符号是非终结符
bool next = true; // 如果当前符号可以推出空,则还需判
// 断下一个符号
size_t idx = 0; // 待判断符号的下标
while (next && idx != right.size()) {
next = false;
sym_t n = right[idx]; // 当前处理的右部非终结符
for (auto it = first[n].begin(); it != first[n].end(); ++it) {
// 把当前符号的 FIRST 集中非空元素加入
// 到左部符号的 FIRST 集中
if (*it != Production::epsilon
&& first[left].find(*it) == first[left].end()) {
change = true;
first[left].insert(*it);
}
}
// 当前符号的 FIRST 集中有空, 标记 next 为真,
// idx 下标+1
if (first[n].find(Production::epsilon) != first[n].end()) {
if (idx + 1 == right.size()
&& first[left].find(Production::epsilon) == first[left].end())
{
// 此时说明产生式左部可以推出空;因此需要
// 把 epsilon 加入 FIRST 集
change = true;
first[left].insert(Production::epsilon);
}
else {
next = true;
++idx;
}
}
}
}
}
}
}
Grammer 类同样提供了 first_set_string() 用于求一个字符串的
F
I
R
S
T
FIRST
FIRST 集,思路如下:
LR1Item 类 (继承自产生式类 Production) 表示一个 LR1 项目,而 LR(1) 项集用 unordered_set<LR1Item> 表示,通过类型别名定义为 LR1_items_t;LR(1) 项集族用 vector<LR1_items_t> 表示
LR1Item 具有产生式左部 left、产生式右部 right、向前看符号 next、项目中点的位置 loc 四个属性hash 模板类,定义了 LR1Item (LR1 项目) 以及 LR1_items_t (LR(1) 项集) 的哈希函数,便于之后利用 unordered_set 高效实现在 LR(1) 项集中插入 LR(1) 项目以及在 LR(1) 规范项集族中插入 LR(1) 项集 (避免 LR(1) 项集中加入重复的 LR(1) 项目 或者 LR(1) 规范项集族中加入重复的 LR(1) 项集而导致算法无限循环)LR1DFA 类提供C l o s u r e ( ) Closure() Closure() 用于对一个 LR1 项集求闭包,具体算法步骤如下:
unordered_set 实现的,因此可以保证最后求得的闭包中没有重复的 LR1 项目)
LR1DFA::LR1_items_t LR1DFA::closure(const LR1_items_t& items)
{
LR1_items_t closure_set; // 最后求得的闭包
stack<LR1Item> s;
// 对原项集中的每个项,先把它们存到堆栈里
for (const auto& item : items)
{
s.push(item);
}
// 每次从堆栈里弹出一个项,将该项增加的其他 LR1 项压入栈中
while (!s.empty())
{
LR1Item item = s.top();
s.pop();
closure_set.insert(item);
vector<sym_t> right = item.get_right(); // 产生式右部
if (item.loc == right.size()) // 归约项,直接跳过
{
continue;
}
// [A -> alpha . B beta, u], B -> gamma => [B -> .gamma, b], b is in FIRST(beta u)
sym_t B = right[item.loc];
if (item.loc != right.size() && grammer.N.find(B) != grammer.N.end())
{
vector<sym_t> beta_u;
if (item.loc + 1 != right.size()) // beta 不为空
{
beta_u.push_back(right[item.loc + 1]);
}
beta_u.push_back(item.next);
unordered_set<sym_t> first_b_u = grammer.first_set_string(beta_u); // FIRST(beta u)
// 查找每个 B -> gamma 产生式,将 [B -> .gamma, b] 入栈
for (const auto p : grammer.productions)
{
if (p.get_left() == B)
{
vector<sym_t> r = p.get_right();
// 因为之前处理的时候都把空规则$直接当成终结符来处理,所以在这里把它消掉
if (r.size() == 1 && r[0] == Production::epsilon)
{
r = vector<sym_t>{};
}
for (const auto& b : first_b_u)
{
LR1Item tmp = LR1Item(B, r, b, 0);
if (closure_set.find(tmp) == closure_set.end())
{ // 只加入没有加进闭包的项目集
s.push(tmp);
}
}
}
}
}
}
return closure_set;
}
G o t o ( ) Goto() Goto() 为构造转换函数,具体算法步骤如下:
LR1DFA::LR1_items_t LR1DFA::go_to(const LR1_items_t& items, sym_t sym)
{
LR1_items_t res;
for (const auto& item : items)
{
auto right = item.get_right();
if (item.loc != right.size() && right[item.loc] == sym)
{
res.insert(LR1Item(item.get_left(), right, item.next, item.loc + 1));
}
}
return closure(res);
}
vector<unordered_map<sym_t, string>>
action_table[0]['{'] 就表示第 0 个 LR1 规范项集在识别出 ‘{’ 后需要执行的 ACTION 动作string 表示;例如,ACTION 表中的移进符号并转移到状态 3 用字符串 S3 表示,使用第 3 条产生式归约则用字符串 R3 表示;GOTO 表中的动作统统用数字表示LR1Processor 类的 construct_table() 成员函数实现,是在求 LR1 规范项集族的过程中逐步构建的算法思路:
记录 LR1 分析表中的冲突项
ambiguity_terms 中,之后在 LR1Processor::solve_ambiguity() 中对所有冲突项进行集中处理,消除冲突项,使其能够被 LR1 分析法分析void LR1Processor::construct_table()
{
queue<LR1DFA::LR1_items_t> q; // 保存待处理的 LR1 项集
unordered_map<LR1DFA::LR1_items_t, size_t> items_set; // 记录已经处理过的 LR1 项集及其在LR1规范项集族中的序号,防止重复处理
// 初始项目:[S' -> .S, #]
LR1DFA::LR1_items_t lr1_items{ LR1Item(grammer.productions[0], Grammer::end_of_sentence, 0) };
lr1_items = dfa.closure(lr1_items); // closure([S' -> .S, #])
q.push(lr1_items); // 加入待处理的项集队列
lr1_sets.push_back(lr1_items); // 将初始项目加入最终的 LR1 规范项集族
action_table.push_back({}); // 先将对应的空表项加入action表
goto_table.push_back({}); // 先将对应的空表项加入goto表
items_set.insert(make_pair(lr1_items, lr1_sets.size() - 1)); // 项集+序号
size_t idx = 0; // 记录正在填的LR1分析表的行数
while (!q.empty())
{
lr1_items = q.front();
q.pop();
// 查看该项集中是否有可以归约的项目,根据其对应的向前看符号将其填入 ACTION 表
for (const auto& item : lr1_items)
{
if (item.loc == item.len()) // 可归约
{
// 找到当前归约的规则对应的序号
size_t i = 0;
for (i = 0; i != grammer.productions.size(); ++i)
{
sym_t grammer_left = grammer.productions[i].get_left();
sym_t item_left = item.get_left();
vector<sym_t> grammer_right = grammer.productions[i].get_right();
vector<sym_t> item_right = item.get_right();
if (grammer_left == item_left
&& (grammer_right == item_right
|| (item_right.size() == 0 && grammer_right.size() == 1 && grammer_right[0] == Production::epsilon)))// 空规则
{
break;
}
}
if (i == 0) // 用第一条产生式归约,说明归约到开始符号
{
action_table[idx][item.next] = string("ACC");
}
else {
ostringstream formatted;
formatted << "R" << i;
action_table[idx][item.next] = formatted.str();
}
}
}
// 对每个符号,调用 GOTO 求新的 LR1 项集
// 同时填 action 和 goto 表
for (const auto& t : grammer.T) // action 表
{
if (t != Production::epsilon && t != Grammer::end_of_sentence)
{
LR1DFA::LR1_items_t tmp = dfa.go_to(lr1_items, t); // 新的 LR1 项集 或 已经出现过的 LR1 项集
if (tmp.size() != 0) // 项集有效,说明 t 在该状态是合法符号
{
auto it = items_set.find(tmp);
ostringstream formatted; // 最后填入 ACTION 表的字符串流
if (it != items_set.end()) // 该项集已经出现过了
{
formatted << "S" << it->second;
}
else { // 新的 LR1 项集
q.push(tmp);
lr1_sets.push_back(tmp); // 加入最终的 LR1 规范项集族
action_table.push_back({}); // 先将对应的空表项加入action表
goto_table.push_back({}); // 先将对应的空表项加入goto表
items_set.insert(make_pair(tmp, lr1_sets.size() - 1));
formatted << "S" << lr1_sets.size() - 1;
}
// 把转换关系填入 ACTION 表
if (action_table[idx].find(t) != action_table[idx].end())
{
// LR1 分析表冲突
cout << endl << "************************************" << endl;
cout << "Warning: This is not an LR1 grammer!" << endl;
action_table[idx][t] += " " + formatted.str(); // 把两项都填入表内
cout << "冲突项 [ " << idx << ", " << t << " ]: " << action_table[idx][t] << endl << endl;
ambiguity_terms.push_back({ static_cast<int>(idx), t });
cout << "************************************" << endl << endl;
}
else {
action_table[idx][t] = formatted.str();
}
}
}
}
for (const auto& n : grammer.N) // goto 表
{
if (n != grammer.productions[0].get_left()) // 开始符号的归约在遇到ACTION表中的ACC时就已经完成了,不用填到GOTO表中
{
LR1DFA::LR1_items_t tmp = dfa.go_to(lr1_items, n); // 新的 LR1 项集 或 已经出现过的 LR1 项集
if (tmp.size() != 0) // 项集有效,说明 n 在该状态是合法符号
{
auto it = items_set.find(tmp);
ostringstream formatted; // 最后填入 GOTO 表的字符串流
if (it != items_set.end()) // 该项集已经出现过了
{
formatted << it->second;
}
else { // 新的 LR1 项集
q.push(tmp);
lr1_sets.push_back(tmp); // 加入最终的 LR1 规范项集族
action_table.push_back({}); // 先将对应的空表项加入action表
goto_table.push_back({}); // 先将对应的空表项加入goto表
items_set.insert(make_pair(tmp, lr1_sets.size() - 1));
formatted << lr1_sets.size() - 1;
}
// 把转换关系填入 GOTO 表
if (goto_table[idx].find(n) != goto_table[idx].end())
{
// LR1 分析表冲突
cout << "Warning: This is not an LR1 grammer!" << endl << endl;
goto_table[idx][n] = " " + formatted.str(); // 把两项都填入表内
ambiguity_terms.push_back({ static_cast<int>(idx), n });
}
else {
goto_table[idx][n] = formatted.str();
}
}
}
}
++idx;
}
}
/*
*
*如果之后有其他二义性问题需要解决,也应该在该函数中添加相应的功能函数
*/
void LR1Processor::solve_ambiguity()
{
solve_ambiguity_if();
}

ambiguity_terms,如果其中存在移进 - 归约冲突,且向前看符号为
e
l
s
e
else
else,则强制移进,使
e
l
s
e
else
else 能够和
i
f
if
if 就近配对/*
该函数中处理了 if 语句的二义性问题,即遇到移进 - 归约冲突,且向前看符号为 else,则强制移进
*/
void LR1Processor::solve_ambiguity_if()
{
int change_flag = 1;
while (change_flag)
{
change_flag = 0;
for (auto it = ambiguity_terms.begin(); it != ambiguity_terms.end(); ++it)
{
if (it->second == "else")
{
istringstream is(action_table[it->first][it->second]);
string tmp;
while (is >> tmp)
{
if (tmp[0] == 'S') // 移进项目
{
action_table[it->first][it->second] = tmp; // 只取移进项目
break;
}
}
ambiguity_terms.erase(it);
change_flag = 1;
break; // 去除了一个冲突项之后就马上跳出,进行下一次遍历,因为删除元素后会使迭代器失效
}
}
}
}
type (
i
n
t
int
int /
r
e
a
l
real
real) 和值 value 两个,因此我将变量抽象为了 Id 类,而符号表则抽象为 SymTable 类SymTable 类只有一个成员变量 unordered_map<std::string, Id> table,因此查表的过程都是利用了哈希函数,给出变量名,就可以以较高的效率对符号表进行相应的查找与插入操作。同时 SymTable 类还进一步进行了封装,提供了在符号表中插入新的变量、获取符号表中信息、更改符号表中变量的值等成员函数{”) 都要新增一个符号表用来存储该块内的变量信息;每退出一个块 (读入 “}”) 都要删除该块对应的符号表vector<SymTable> 类型的数据结构中,它保存在类 LR1Processor 中;类 LR1Processor 同时还提供了两个成员函数用于和符号表进行交互:
LR1Processor::get_info() 用于在符号表中通过标识符查找指定变量的信息,需要从最内层块对应的符号表开始,逐层向外查找所需信息,如果所有块对应的符号表中都没有该标识符,则返回 false 表示查找失败,否则返回 true
LR1Processor::set_val() 用于更改变量值,过程与 get_info() 类似Quad 实现,属性有操作符、两个源操作数以及一个目标操作数// 四元式
struct Quad {
friend std::ostream& operator<< (std::ostream& os, const Quad& q);
Quad() = default;
Quad(std::string o, std::string l, std::string r, std::string d)
: opt(o), lhs(l), rhs(r), dest(d) {}
std::string opt;
std::string lhs;
std::string rhs;
std::string dest;
};
LR1Processor::driver() 实现,它主要负责根据输入符号查找 LR1 分析表,执行分析表所规定的动作,对符号栈、状态栈、属性栈进行操作来完成语法及语义处理算法步骤:
{”,则表示进入了一个新的块,需要压入一个新的符号表;如果为 “}”,则表示退出了一个块,需要弹出一个符号表LR1Processor::production_action() 用于完成产生式相应的语义动作 (该函数之后会说明)ACC!”LR1Processor::production_action() 用于完成第0条产生式相应的语义动作LR1Processor::err_proc() 进行错误处理 (该函数之后会说明)短语层次错误恢复
; } ) 这三个分界符中的一个,这种情况说明程序中可能忘写了一个分界符,此时在输入的符号串中直接插入缺少的分界符,并进行相应的归约,同时输出相应的出错信息无法错误恢复
LR1Processor::production_action() 提供,该成员函数通过形参提供的产生式编号执行产生式相应的语义动作,生成四元式switch-case 语句进行语义动作的执行:部分代码示例如下,每一个 case 分支都对应相应的产生式动作,可读性较高,也便于修改:switch (n) // n 为产生式编号
{
case 0:
// program->block
pchain = &Attribute::chain; // 回填最后一部分
attr_cache[0].backpatch(pchain, nxq, quads);
quads.push_back(Quad("End", "_", "_", "_")); // 产生最后一条产生式
++nxq;
break;
case 1: // block -> { decls stmts }
res.chain = attr_cache[1].chain;
break;
case 2: // decls -> decl ; decls
break;
case 3: // decls -> $
break;
case 4: // decl -> decl , id
res.type = attr_cache[2].type;
if (!now_sym_table->insert(Id(attr_cache[0].lexeme, res.type)))
{
// 重定义
string err_msg = "Line" + std::to_string(res.line) + ": ";
throw runtime_error(err_msg + "multiple definition!");
}
break;
// ...
grammer.txt 以及所有源文件 xxx.txt 放入一个文件夹中,同时一定要更改文件夹路径;即修改 main 函数中的 path_prefix,例如我现在的源文件 code.txt 放在 E:\\Workspace\\diy_compiler\\compiler\\Debug\\ 目录下,那修改 path_prefix 为该路径即可lianli xxx.txt 来编译相应的源文件,命令末尾加上 -v 命令可以输出归约时使用的产生式,输出顺序为最右推导的逆序,效果如下图所示: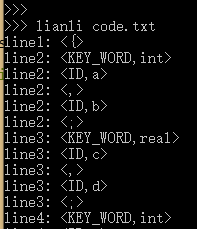
grammer.txt 中添加相应的产生式 (最好添加在最后,这样不会改变其他产生式的序号)LR1Processor::production_action 函数的相应 case 分支下添加语义动作即可// code.txt
{
int a, b;
real c, d;
int e, g, h;
a = 1.3e3;
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
do{
a = 1;
}while (true);
{
int a;
a = 1;
}
if (1)
then a = 3;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1;
}
}
output:
-v,还会输出语法分析时所使用的产生式,即输出最右推导的逆序列,但是因为输出信息太多,所以这里没加>>> lianli code.txt
line1: <{>
line2: <KEY_WORD,int>
line2: <ID,a>
line2: <,>
line2: <ID,b>
line2: <;>
line3: <KEY_WORD,real>
line3: <ID,c>
line3: <,>
line3: <ID,d>
line3: <;>
line4: <KEY_WORD,int>
line4: <ID,e>
line4: <,>
line4: <ID,g>
line4: <,>
line4: <ID,h>
line4: <;>
line5: <ID,a>
line5: <=>
line5: <NUM,1300>
line5: <;>
line7: <KEY_WORD,if>
line7: <!>
line7: <(>
line7: <ID,a>
line7: <*>
line7: <->
line7: <ID,b>
line7: <RELOPT,>=>
line7: <ID,c>
line7: <+>
line7: <ID,d>
line7: <)>
line8: <KEY_WORD,then>
line9: <{>
line10: <ID,e>
line10: <=>
line10: <ID,g>
line10: <+>
line10: <ID,h>
line10: <;>
line11: <}>
line12: <KEY_WORD,else>
line13: <ID,e>
line13: <=>
line13: <ID,g>
line13: <*>
line13: <ID,h>
line13: <;>
line15: <KEY_WORD,do>
line15: <{>
line16: <ID,a>
line16: <=>
line16: <NUM,1>
line16: <;>
line17: <}>
line17: <KEY_WORD,while>
line17: <(>
line17: <KEY_WORD,true>
line17: <)>
line17: <;>
line18: <{>
line19: <KEY_WORD,int>
line19: <ID,a>
line19: <;>
line20: <ID,a>
line20: <=>
line20: <NUM,1>
line20: <;>
line21: <}>
line22: <KEY_WORD,if>
line22: <(>
line22: <NUM,1>
line22: <)>
line23: <KEY_WORD,then>
line23: <ID,a>
line23: <=>
line23: <NUM,3>
line23: <;>
line25: <KEY_WORD,while>
line25: <ID,a>
line25: <RELOPT,>=>
line25: <NUM,10>
line26: <KEY_WORD,do>
line27: <{>
line28: <KEY_WORD,if>
line28: <(>
line28: <ID,a>
line28: <RELOPT,==>
line28: <ID,a>
line28: <*>
line28: <ID,b>
line28: <)>
line29: <KEY_WORD,then>
line30: <ID,a>
line30: <=>
line30: <ID,a>
line30: <->
line30: <NUM,1>
line30: <;>
line31: <}>
line32: <}>
***********************************
No Warning!
************************************
四元式:
1: ( rtoi, 1300.000000, _, t0 )
2: ( =, t0, _, ENTRY(a) )
3: ( @, ENTRY(b), _, t1 )
4: ( *, ENTRY(a), t1, t2 )
5: ( +, ENTRY(c), ENTRY(d), t3 )
6: ( >=, t2, t3, t4 )
7: ( jtrue, t4, _, 9 )
8: ( j, _, _, 9 )
9: ( !, t4, _, t5 )
10: ( jtrue, t5, _, 12 )
11: ( j, _, _, 15 )
12: ( +, ENTRY(g), ENTRY(h), t6 )
13: ( =, t6, _, ENTRY(e) )
14: ( j, _, _, 17 )
15: ( *, ENTRY(g), ENTRY(h), t7 )
16: ( =, t7, _, ENTRY(e) )
17: ( rtoi, 1.000000, _, t8 )
18: ( =, t8, _, ENTRY(a) )
19: ( jtrue, true, _, 21 )
20: ( j, _, _, 21 )
21: ( jtrue, true, _, 17 )
22: ( j, _, _, 23 )
23: ( rtoi, 1.000000, _, t9 )
24: ( =, t9, _, ENTRY(a) )
25: ( jtrue, 1.000000, _, 27 )
26: ( j, _, _, 27 )
27: ( jtrue, 1.000000, _, 29 )
28: ( j, _, _, 31 )
29: ( rtoi, 3.000000, _, t10 )
30: ( =, t10, _, ENTRY(a) )
31: ( >=, ENTRY(a), 10.000000, t11 )
32: ( jtrue, t11, _, 34 )
33: ( j, _, _, 45 )
34: ( *, ENTRY(a), ENTRY(b), t12 )
35: ( ==, ENTRY(a), t12, t13 )
36: ( jtrue, t13, _, 38 )
37: ( j, _, _, 38 )
38: ( jtrue, t13, _, 40 )
39: ( j, _, _, 31 )
40: ( itor, ENTRY(a), _, t14 )
41: ( -, t14, 1.000000, t15 )
42: ( rtoi, t15, _, t16 )
43: ( =, t16, _, ENTRY(a) )
44: ( j, _, _, 31 )
45: ( End, _, _, _ )
e 后面必须跟一个数字// code1.txt
{
int a, b;
real c, d;
int e, g, h;
a = 1.3e; // 词法分析阶段报错
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1;
b = b + 1
}
{
int a;
a = 1;
}
do{
a = 1;
}while (true);
if (1
then a = 3
}
output:
>>> lianli code1.txt
line1: <{>
line2: <KEY_WORD,int>
line2: <ID,a>
line2: <,>
line2: <ID,b>
line2: <;>
line3: <KEY_WORD,real>
line3: <ID,c>
line3: <,>
line3: <ID,d>
line3: <;>
line4: <KEY_WORD,int>
line4: <ID,e>
line4: <,>
line4: <ID,g>
line4: <,>
line4: <ID,h>
line4: <;>
line5: <ID,a>
line5: <=>
************************************
ERROR!
Line5: No number after 'e' !
************************************
>>>
// code2.txt
{
int a, b;
real c, d;
real a; // 多重定义
int e, g, h;
a = 1.3e3;
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1;
b = b + 1
}
{
int a;
a = 1;
}
do{
a = 1;
}while (true);
if (1
then a = 3
}
output:
>>> lianli code2.txt
line1: <{>
// 省略了部分词法分析输出
line34: <}>
************************************
ERROR!
Line4: multiple definition!
************************************
>>>
a,但却没有定义,因此存在无定义错误// code3.txt
{
int b; // 无定义
real c, d;
int e, g, h;
a = 1.3e3;
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1;
b = b + 1
}
{
int a;
a = 1;
}
do{
a = 1;
}while (true);
if (1
then a = 3
}
output:
>>> lianli code3.txt
line1: <{>
// 省略了部分词法分析输出
line33: <}>
************************************
ERROR!
Line5: Undefined variant a !
************************************
// code4.txt
{
int a, b;
real c, d;
int e, g, h;
a = 1.3e3 / 0; // 除以0
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1;
b = b + 1
}
{
int a;
a = 1;
}
do{
a = 1;
}while (true);
if (1
then a = 3
}
output:
>>> lianli code4.txt
line1: <{>
// 省略了部分词法分析输出
line33: <}>
************************************
ERROR!
Line5: Err: Divided by zero!
************************************
) / ; / } 这样的分界符,在这种情况下会在语法分析阶段报错。但我使用了错误恢复,因此会自动在程序输入流程中插入缺少的分界符,最后依然能够生成正确的四元式,但会产生相应的 Warning,提示哪一行没有加分界符// code5.txt
{
int a, b;
real c, d;
int e, g, h;
a = 1.3e3;
if !(a * -b >= c + d // 缺少右圆括号
then
{
e = g + h;
}
else
e = g * h;
do{
a = 1;
}while (true) // 缺少分号
{
int a;
a = 1; // 缺少右大括号
if (1)
then a = 3;
while a >= 10
do
{
if (a == a * b)
then
a = a - 1; // 缺少右大括号
}
output:
>>> lianli code5.txt
line1: <{>
// 省略了部分词法分析输出
line32: <}>
***********************************
Line7:
Warning 0: Lack of )
Line17:
Warning 1: Lack of ;
Line32:
Warning 2: Lack of }
Line32:
Warning 3: Lack of }
4 Warning(s)!
************************************
四元式:
1: ( rtoi, 1300.000000, _, t0 )
2: ( =, t0, _, ENTRY(a) )
3: ( @, ENTRY(b), _, t1 )
4: ( *, ENTRY(a), t1, t2 )
5: ( +, ENTRY(c), ENTRY(d), t3 )
6: ( >=, t2, t3, t4 )
7: ( jtrue, t4, _, 9 )
8: ( j, _, _, 9 )
9: ( !, t4, _, t5 )
10: ( jtrue, t5, _, 12 )
11: ( j, _, _, 15 )
12: ( +, ENTRY(g), ENTRY(h), t6 )
13: ( =, t6, _, ENTRY(e) )
14: ( j, _, _, 17 )
15: ( *, ENTRY(g), ENTRY(h), t7 )
16: ( =, t7, _, ENTRY(e) )
17: ( rtoi, 1.000000, _, t8 )
18: ( =, t8, _, ENTRY(a) )
19: ( jtrue, true, _, 21 )
20: ( j, _, _, 21 )
21: ( jtrue, true, _, 17 )
22: ( j, _, _, 23 )
23: ( rtoi, 1.000000, _, t9 )
24: ( =, t9, _, ENTRY(a) )
25: ( jtrue, 1.000000, _, 27 )
26: ( j, _, _, 27 )
27: ( jtrue, 1.000000, _, 29 )
28: ( j, _, _, 31 )
29: ( rtoi, 3.000000, _, t10 )
30: ( =, t10, _, ENTRY(a) )
31: ( >=, ENTRY(a), 10.000000, t11 )
32: ( jtrue, t11, _, 34 )
33: ( j, _, _, 45 )
34: ( *, ENTRY(a), ENTRY(b), t12 )
35: ( ==, ENTRY(a), t12, t13 )
36: ( jtrue, t13, _, 38 )
37: ( j, _, _, 38 )
38: ( jtrue, t13, _, 40 )
39: ( j, _, _, 31 )
40: ( itor, ENTRY(a), _, t14 )
41: ( -, t14, 1.000000, t15 )
42: ( rtoi, t15, _, t16 )
43: ( =, t16, _, ENTRY(a) )
44: ( j, _, _, 31 )
45: ( End, _, _, _ )
// code6.txt
{
int a, b;
real c, d;
int e, g, h;
a = 1.3e3;
if !(a * -b >= c + d)
then
{
e = g + h;
}
else
e = g * h;
do{
a = 1;
}while (true);
{
int a;
a = 1;
}
if (1)
then a = 3;
while a >= 10
do
{
if a == a b // 缺少运算符
then
a = a - 1;
}
}
output:
if 语句的 then
>>> lianli code6.txt
line1: <{>
// 省略了部分词法分析输出
line32: <}>
************************************
ERROR!
Line28:
state 32 can't accept id !
possible symbols are:
<= / then >= + - * or and == != < >
************************************