B站视频
B站第一章
参考资料
图片来自视频链接和参考资料。
本章目录:
SQL特点
SQL包括:数据查询、数据操作、数据定义、数据控制
它是一个非过程语言。
什么是非过程性语言?
我们在逻辑和物理模型里讲了层次、网状、关系模型。
其中层次模型和网状模型的查询是要有过程的,而关系模型不需要过程——这就是非过程性语言。
SQL特点:
-
综合统一:把定义、修改、删除、连接、安全性、完整性、事务控制、动态SQL等统一起来
-
高度非过程化:层次模型和网状模型是过程化的,关系模型是非过程化的
- 面向集合的操作方式
-
以同一种语法结构提供多种使用方式:既可以独立,也可以嵌入到Java或C++中
- 语言简洁,易学易用
SQL基本概念


这一章先将前三行的语法,数据控制是安全性里面的。
一些概念:
- 基本表:二维表
- 存储文件:存在数据库里的文件
- 视图:一个虚表,从一个或多个基本表中导出来的表,视图不是真正的表,他的数据都是在基本表中
外模式:视图与部分基本表
模式:基本表
内模式:存储文件

SQL
包括:
- 数据定义
- 数据查询
- 数据更新:修改和删除
- 视图
1.数据定义

定义模式:CREATE SCHEMA <模式名> AUTHORIZATION <用户名>
为用户WANG定义一个学生-课程模式S-T:(这里用户可以理解为一个账户)
CREATE SCHEMA "S-T" AUTHORIZATION WANG;
删除模式:DROP SCHEMA <模式名> <CASCADE|RESTRICT>
CASCADE(级联)
删除模式的同时把该模式下所有的数据库对象全部删除
RESTRICT(限制)
如果该模式中定义了下属的数据库对象(如表、视图等),则停止执行该语句。
基本表的定义,修改,删除
定义格式:
CREATE TABLE <表名>(
<列名> <数据类型>[ <列级完整性约束条件> ]
[,<列名> <数据类型>[ <列级完整性约束条件>] ]
………
[,<表级完整性约束条件> ]
);
举个定义的例子:
学生表:
CREATE TABLE Student( /*定义一个表名为Student的表*/
Sno(CHAR(9)) PRIMARY KAY,
/*第一列是Sno,是属性(列名),CHAR是数据类型,长度为9. PRIMARY KAY表示设置为主码,逗号分隔*/
Sname CHAR(20) UNIQUE,/*第二列是Sname,设置UNIQUE表示不允许重复*/
Ssex CHAR(2),/*中文'男''女'占两个字节*/
Sdept CHAR(20)
);
课程表:
CREATE TABLE Course(
Cno CHAR(4) PRIMARY KEY,/*列级完整性约数条件,Cno是主码*/
Cname CHAR(40) NOT NULL,/*Cname不能为空*/
Cpno CHAR(4),/*含义是先修课*/
Ccredit SMALLINT,
FOREIGN KEY(Cpno)REFERENCES Course(Cno)
/*表级完整性约束条件,Cpno是外码,被参照的表是Course,被参照的列是Cno*/
);
一些数据类型:

修改基本表
格式:
ALTER TABLE <表名>
[ ADD <新列名> <数据类型> [ 完整性约束 ] ]
[ DROP <完整性约束名> ]
[ ALTER COLUMN<列名> <数据类型> ];
如:向Student表增加“入学时间”列,其数据类型为日期型。
ALTER TABLE Student ADD S_entrance DATE;
/*向Student表 增加列,列名为S_entrance 数据类型为DATE*/
如:将年龄的数据类型由字符型(假设原来的数据类型是字符型)改为整数
ALTER TABLE Student ALTER COLUMN Sage INT;
/*选择表Student 选择列Sage 让它的数据类型为INT*/
如:增加课程名称必须取唯一值的约束条件
ALTER TABLE Course ADD UNIQUE(Sname);
/**选择表Course 令Sname这列属性UNIQUE**/
删除基本表
格式:
DROP TABLE <表名>[RESTRICT| CASCADE;
RESTRICT:删除表是有限制的。
- 欲删除的基本表不能被其他表的约束所引用
- 如果存在依赖该表的对象,则此表不能被删除
CASCADE:删除该表没有限制。
索引的建立和删除
索引就是为了加快查询的速度。
建立索引:
CREATE UNIQUE INDEX Stusno ON Student(Sno);/*这里Stusno就是索引名*/
修改索引名:
ALTER INDEX SCno RENAME SCSno;
删除索引:
DROP INDEX Stusname;
数据字典
数据字典是DBMS内部的系统表,它记录了数据库中所有的定义信息。
2.数据查询(重点)
数据查询部分是围绕这三个表展开的:

简单查询
查询学生的姓名、学号、所在系。
SELECT Sname,Sno,Sdept
FROM student;
/*这里查的是列*/
查询全体学生的详细记录。
SELECT *
FROM Student;
查全体学生的姓名及其出生年份。这里假定目前年份是2014年。
SELECT Sname,2014-Sage/*可以有算术表达式*/
FROM Student;
得到的表:
| Sname |
2014-Sage |
| 李勇 |
1994 |
| 刘晨 |
1995 |
| 王敏 |
1996 |
| 张立 |
1995 |
给列进行重命名:把Sname改为NAME,把BIRTH那一列全填满’Year of Birth:',把2014-Sage改为BIRTHDAY,让Sdept内的内容全都变为小写并把它这列改名为DEPARTMENT:
SELECT Sname NAME,
'Year of Birth:' BIRTH,
2014-Sage BIRTHDAY,
LOWER(Sdept) DEPARTMENT/*LOWER是一个函数*/
FROM Student;
/*前面是原来的名字,后面是改后的名字*/
得到的表:

去掉列的重复值:
SELECT DISTINCT Sno
FROM SC;
原表:
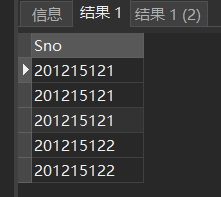
去重后:
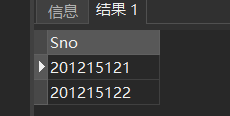
条件查询

查询计算机科学系的全体学生的名单:
SELECT Sname
FROM Student
WHERE Sdept='CS';
/*查姓名 在Student表里 条件是Sdept列的值为CS*/
查询所有年龄在20岁以下的学生姓名及年龄:
SELECT Sname,Sage
FROM Student
WHERE Sage<20;
查询所有年龄在20-23之间的学生姓名及年龄:
SELECT Sname,Sage
FROM Student
WHERE Sage BEWTEEN 20 AND 23;
查询CS系,MA系,IS系学生的姓名和性别:
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN('CS','MA','IS');
LIKEA模糊匹配

查询所有姓刘的学生的姓名、学号和性别:
SELECT Sname,Sno,Ssex
FROM student
WHERE Sname LIkE '刘%';/*以刘开头的字符串*/
查询姓”欧阳“且全名为三个汉字的学生的姓名:
SELECT Sname
FROM Student
WHERE Sname LIKE '欧阳_';/*必须是三个字了*/
查询所有不姓刘的学生的姓名、学号和性别:
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname NOT LIKE'刘%';
查询DB_Design课程的课程号和学分:当需要匹配的字符串里有_时,在前面加一个转义字符\
SELECT Cno,Ccredit
FROM Course
WHERE Sname LiKE 'DB\_Design' ESCAPE '\';
/*用escape '\'表示那是一个转义字符*/
涉及空值问题
谓词:
IS NULLIS NOT NULL-
IS不能用=代替
查询缺少成绩的学生的学号和相应的课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NULL;
查询所有有成绩的学生学号和课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NOT NULL;
多重条件查询
逻辑运算符:
- AND和 OR来联结多个查询条件
- AND的优先级高于OR
- 可以用括号改变优先级
可用来实现多种其他谓词:
[NOT] IN
[NOT] BETWEEN … AND …
AND 两个条件都满足
OR 只要满足一个就行
查询计算机系年龄在20岁以下的学生姓名:
SELECT Sname
FROM Student
WHERE Sdept='CS' AND Sage<20;
查询结果进行排序
用ORDER BY:
- 从高到低 即降序
DESC
- 从低到高 即升序 啥都不加,或者加
ASC
当排序含空值时,把空值当作无穷大了。即从高到低的话就最先显示,从低到高就最后显示。
查询选修了3号课程的学生的学号及其成绩,查询结果按分数降序排列:
SELECT Sno,Grade
FROM SC
WHERE Cno='3'
ORDER BY Grade DESC;
查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列:
SELECT *
FROM Student
ORDER BY Sdept , Sage DESC;
/*先对系号Sdept进行升序排序,所以它是第一关键字
再对年龄降序排列,它是第二关键字*/
聚集函数
用来统计的。
计数:
COUNT([DISTINCT|ALL] *)COUNT([DISTINCT|ALL] <列名>)
计算总和:
计算平均值:
最大最小值:
MAX([DISTINCT|ALL] <列名>)MIN([DISTINCT|ALL] <列名>)

查询学生总人数:
SELECT COUNT(*)
FROM Student;
查询选修了课程的学生人数:
SELECT COUNT(DISTINCT Sno)/*把课程号去重,查询选修了这些课的人数*/
FROM SC;
计算选修1号课程的学生平均成绩:
SELECT AVG(Grade)
FROM SC
WHERE Cno='1';
查询选修2号课程的学生最高分数:
SELECT MAX(Grade)
FROM SC
WHERE Cno='2';
查询学生201215012选修课程的总学分数:
SELECT SUM(Ccredit)
FROM SC,Course
WHERE Sno='201215012' AND SC.Cno=Course.Cno;
由SC表的学号Sno可以找到课程号Cno,但找不到学分,要根据课程号找学分,则需要Course表:

所以这里的条件是:WHERE Sno='201215012' AND SC.Cno=Course.Cno;
GROUP BY
假设一个学校有几千人,我们把他们分为多个班,这样就可以求出每个班的平均分,这就是group by.
HAVING与WHERE的区别:
-
HAVING用于组,从中选出满足条件的组
- 可以理解为:
HAVING是对GROUP BY 分类汇总的筛选
-
WHERE用于基表或视图,从中选出满足条件的元组(其实就是一行)
求各个课程号及相应的选课人数:
SELECT Cno,COUNT(Sno)
FROM SC
GROUP BY Cno;
查询选修了2门以上课程的学生学号:
SELECT Sno
FROM SC
GROUP BY Sno
HAVING COUNT(*)>2;
多表连接查询
假设现在有两个表:

如果我们直接:
SELECT *
FROM A,B
我们会得到这两个表的笛卡尔积:

而真正有意义的只有绿色部分:

所以,我们如果想得到有意义的表:
SELECT *
FROM A,B
WHERE A.学号=B.学号;

这里学号重复了,我们可以不像上面那样写,而是:
SELECT 学号,姓名,班级,课程,成绩
FROM A,B
WHERE A.学号=B.学号
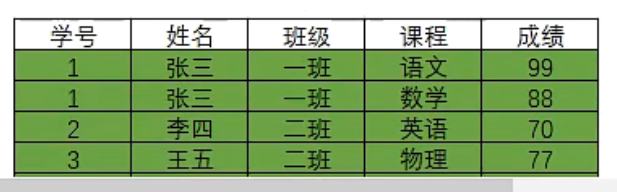
左外连接与右外连接
左外连接格式:
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student LEFT OUTER JOIN SC ON(Student.Sno=SC.Sno);
右外连接只需要把LEFT OUTER 改成RIGHT OUTER即可。
嵌套查询
- 一个
SELECT-FROM-WHERE语句称为一个查询块
- 将一个查询块嵌套在另一个查询块的
WHERE子句或HAVING短语的条件中的查询称为嵌套查询
- 限制:不能使用
ORDER BY 子句
选择2号课程的学生姓名:
SELECT Sname
FROM Student
WHERE Sno IN
(SELECT Sno
FROM SC
WHERE Cno='2';
);
括号里面是一个嵌套查询,它查到的是一个集合:Cno是2的Sno集合。
外面的查询是要查名字,其名字对应的Sno要在这个集合里。

存在EXISTS
在关系代数中我们可以用除法来查找某一全体。
查询选修了所有课程的学生姓名:(这里包含所有,所以要用存在语句)
- 有这样一个学生,对于任意Course中的课,该学生都选了
- 将上一句话
等价转换
- 有这样一个学生,不存在Course中的课,该学生没选
- 接下来转化成代码:
- 有这样一个学生:
SELECT Sname FROM Student
- 不存在:
NOT EXISTS
- Course中的课:
SELECT Cno FROM Course
- 该同学没选(SC对应选课表):
NOT EXISTS(SELECT * FROM SC)
即:
SELECT Sname FROM Student /*选一个学生*/
WHERE NOT EXISTS /*不存在*/
(
SELECT * FROM Course /*课程表里的课*/
WHERE NOT EXISTS
(
SELECT * FROM SC /*有没选的*/
WHERE Sno=Student.Sno AND Cno=Course.Cno;
)
)
查询所有选修了1号课程的学生姓名:
SELECT Sname
FROM Student
WHERE EXISTS
(
SELECT *
FROM SC
WHERE Cno='1' AND Sno=Student.Sno
)
集合查询
并集UNION
交集INTERSECTION
差集EXCEPT

3.数据更新
数据插入
INSERT
INTO Student(Sno,Sname,Ssex,Sdept,Sage)
/*这里指明插入的分别是什么*/
VALUES('201215128','陈冬','男','IS',18);
或
INSERT
INTO Student
/*不指明插入的是什么,则就是按照表中列的顺序*/
VALUES('201215128','陈冬','男',18,'IS');
可以把SELECT的查询结果插入表。
修改语句
将学生201215121的年龄改为22岁:
UPDATE Student
SET Sage=22
WHERE Sno='201215121';
将所有学生的年龄增加1岁:
UPDATE Student
SET Sage=Sage+1;
将计算机科学系全体学生的成绩置零:
UPDATE SC
SET GRADE=0
WHERE Sno in
(
SELECT Sno
FROM Student
WHERE Student.Sno=SC.Sno and Sdept='CS';
)
删除语句
删除学号为201215128的学生记录:
DELETE
FROM Student
WHERE Sno='201215128';
4.视图
视图是一种虚表,它真正的数据存在基本表上。
CREATE VIEW <视图名>[<列名>[,<列名>]...]
AS <子查询>
[WITH CHECK OPTION];
关于WITH CHECK OPTION:

举个例子:
CREATE VIEW IS_Student
AS
SELECT Sno,Sname,Sage
FROM Student
WHERE Sdept='IS'
WITH CHECK OPTION;
这一段代码产生的视图是专业为IS的,包含学生学号、姓名、年龄的视图。但我们在对这个视图进行操作的时候可能对专业为‘MA’的学生数据给改变了——它是不属于试图范围的。
因此我们可以加一句WITH CHECK OPTION,来防止上面说到的情况。

删除视图
DROP VIEW<视图>[CASCADE];
