前言
一系列DML(deep metric learning)方法被称为基于对(pair-based)的方法,其目标可以根据小批量内的成对相似性来定义。例如Constrative loss、Triplet loss、Lifted Structure loss、N-pairs loss、Multi-similarity loss等等。
提示:以下是本篇文章正文内容
一、Constrative loss[1]
文章提出了一种从数据中训练相似性度量的方法。这种方法适用于识别和验证任务,其中任务特点:
(1)数据所属的类别特别多
(2)有些类别在训练的时候是未知的
(3)并且每个类别的训练样本特别少。
孪生神经网络一般采用Contrastive Loss处理成对的数据,对于positive pair,输出特征向量距离要尽量小;对于negative pair,输出特征距离要尽量大,但若Ew>m则不处理这种easy negative pair。
根据论文[1]的推导得到最终表达式:
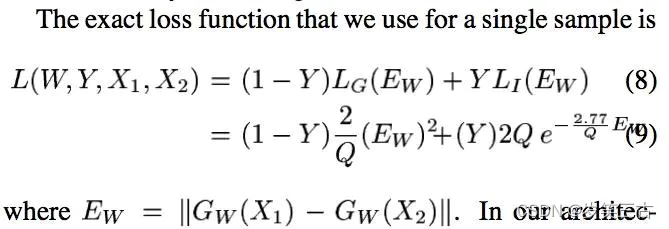
其中W表示是网络权重,Y是成对标签,如果X1,X2这对样本属于同一个类,则Y=0,属于不同类则Y=1。EW为定义的一个标量“能量方程(energy function),Gw定义为映射后的特征值。LG为相似对损失,LI为不相似对损失。
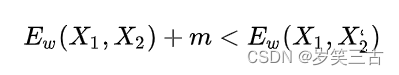
整套机制应满足如上条件,其中m为margin。
代码表示如下:
# 自定义ContrastiveLoss
class ContrastiveLoss(torch.nn.Module):
"""
Contrastive loss function.
Based on: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
"""
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2, keepdim=True)
loss_contrastive = torch.mean((1 - label) * torch.pow(euclidean_distance, 2) +
label * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
二、Triplet loss[2]
Triplet Loss即三元组损失,定义为:最小化Anchor和Positive之间的距离,最大化Anchor和不同身份的Negative之间的距离。
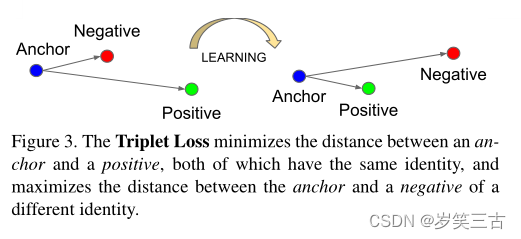
我们期望下式成立:
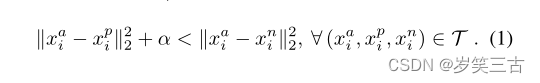
其中α为margin,T为就是样本容量为N的数据集的各种三元组。然后根据上式,Triplet Loss可以写成:
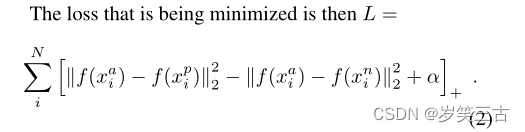
生成所有可能的三元组将导致许多容易满足的三元组(即满足等式(1)中的约束)。这些三胞胎不会对训练做出贡献,并导致较慢的融合,因为它们仍然会通过网络传递。关键是要选择hard triplets,它们是活跃的,因此有助于改进模型。
Offline and online triplet mining
- 每n步离线生成triplet,使用最新的网络检查点并计算数据子集上的argmin和argmax。
- 在线生成triplet。这可以通过从mini-batch中选择hard positive/negative样本来实现。
下面是在线生成的triplet loss代码:
class TripletLoss(nn.Module):
"""Triplet loss with hard positive/negative mining.
Reference:
Hermans et al. In Defense of the Triplet Loss for Person Re-Identification. arXiv:1703.07737.
Imported from `<https://github.com/Cysu/open-reid/blob/master/reid/loss/triplet.py>`_.
Args:
margin (float, optional): margin for triplet. Default is 0.3.
"""
def __init__(self, margin=0.3,global_feat, labels):
super(TripletLoss, self).__init__()
self.margin = margin
# https://pytorch.org/docs/1.2.0/nn.html?highlight=marginrankingloss#torch.nn.MarginRankingLoss
# 计算两个张量之间的相似度,两张量之间的距离>margin,loss 为正,否则loss 为 0
self.ranking_loss = nn.MarginRankingLoss(margin=margin)
def forward(self, inputs, targets):
"""
Args:
inputs (torch.Tensor): feature matrix with shape (batch_size, feat_dim).
targets (torch.LongTensor): ground truth labels with shape (num_classes).
"""
n = inputs.size(0) # batch_size
# Compute pairwise distance, replace by the official when merged
dist = torch.pow(inputs, 2).sum(dim=1, keepdim=True).expand(n, n)
dist = dist + dist.t()
dist.addmm_(1, -2, inputs, inputs.t())
dist = dist.clamp(min=1e-12).sqrt() # for numerical stability
# For each anchor, find the hardest positive and negative
mask = targets.expand(n, n).eq(targets.expand(n, n).t())
dist_ap, dist_an = [], []
for i in range(n):
dist_ap.append(dist[i][mask[i]].max().unsqueeze(0))
dist_an.append(dist[i][mask[i] == 0].min().unsqueeze(0))
dist_ap = torch.cat(dist_ap)
dist_an = torch.cat(dist_an)
# Compute ranking hinge loss
y = torch.ones_like(dist_an)
loss = self.ranking_loss(dist_an, dist_ap, y)
return loss
参考
PyTorch TripletMarginLoss(三元损失)
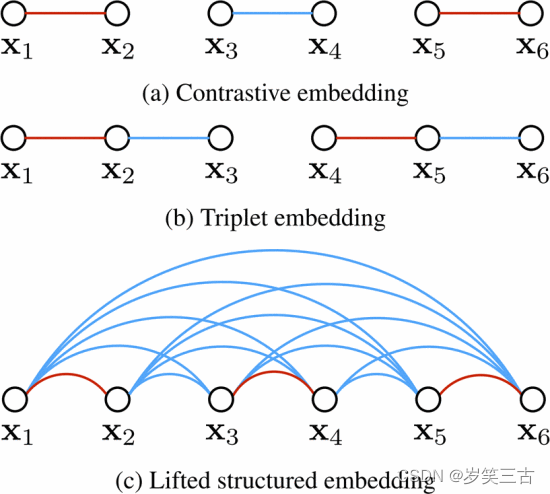
三、Lifted Structure Loss
Lifted Structure loss的思想是对于一对正样本对而言,不去区分这个样本对中谁是anchor,谁是positive,而是让这个正样本对中的每个样本与其他所有负样本的距离都大于给定的阈值。此方法能够充分的利用mini-batch中的所有样本,挖掘出所有的样本对。
每个batch的loss定义为:
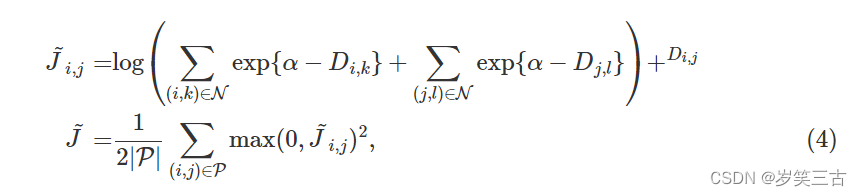
代码:
class LiftedStructureLoss(GenericPairLoss):
def __init__(self, neg_margin=1, pos_margin=0, **kwargs):
super().__init__(mat_based_loss=False, **kwargs)
self.neg_margin = neg_margin
self.pos_margin = pos_margin
self.add_to_recordable_attributes(
list_of_names=["pos_margin", "neg_margin"], is_stat=False
)
def _compute_loss(self, pos_pairs, neg_pairs, indices_tuple):
a1, p, a2, _ = indices_tuple
dtype = pos_pairs.dtype
if len(a1) > 0 and len(a2) > 0:
pos_pairs = pos_pairs.unsqueeze(1)
n_per_p = c_f.to_dtype(
(a2.unsqueeze(0) == a1.unsqueeze(1))
| (a2.unsqueeze(0) == p.unsqueeze(1)),
dtype=dtype,
)
neg_pairs = neg_pairs * n_per_p
keep_mask = ~(n_per_p == 0)
remaining_pos_margin = self.distance.margin(pos_pairs, self.pos_margin)
remaining_neg_margin = self.distance.margin(self.neg_margin, neg_pairs)
neg_pairs_loss = lmu.logsumexp(
remaining_neg_margin, keep_mask=keep_mask, add_one=False, dim=1
)
loss_per_pos_pair = neg_pairs_loss + remaining_pos_margin
loss_per_pos_pair = torch.relu(loss_per_pos_pair) ** 2
loss_per_pos_pair /= (
2 # divide by 2 since each positive pair will be counted twice
)
return {
"loss": {
"losses": loss_per_pos_pair,
"indices": (a1, p),
"reduction_type": "pos_pair",
}
}
return self.zero_losses()
class GeneralizedLiftedStructureLoss(GenericPairLoss):
# The 'generalized' lifted structure loss shown on page 4
# of the "in defense of triplet loss" paper
# https://arxiv.org/pdf/1703.07737.pdf
def __init__(self, neg_margin=1, pos_margin=0, **kwargs):
super().__init__(mat_based_loss=True, **kwargs)
self.neg_margin = neg_margin
self.pos_margin = pos_margin
self.add_to_recordable_attributes(
list_of_names=["pos_margin", "neg_margin"], is_stat=False
)
def _compute_loss(self, mat, pos_mask, neg_mask):
remaining_pos_margin = self.distance.margin(mat, self.pos_margin)
remaining_neg_margin = self.distance.margin(self.neg_margin, mat)
pos_loss = lmu.logsumexp(
remaining_pos_margin, keep_mask=pos_mask.bool(), add_one=False
)
neg_loss = lmu.logsumexp(
remaining_neg_margin, keep_mask=neg_mask.bool(), add_one=False
)
return {
"loss": {
"losses": torch.relu(pos_loss + neg_loss),
"indices": c_f.torch_arange_from_size(mat),
"reduction_type": "element",
}
}
四、N-pairs loss [4]
Triplet loss同时拉近一对正样本和一对负样本,这就导致在选取样本对的时候,当前样本对只能够关注一对负样本对,而缺失了对其他类别样本的区分能力。
为了改善这种情况,N-pair loss[4]就选取了多个负样本对,即一对正样本对,选取其他所有不同类别的样本作为负样本与其组合得到负样本对。如果数据集中有 N个类别,则每个正样本对Yii都对应了N-1个负样本对。N+1元组一般不会提前构建好,而是在训练的过程中,从同一个mini batch中构建出来。
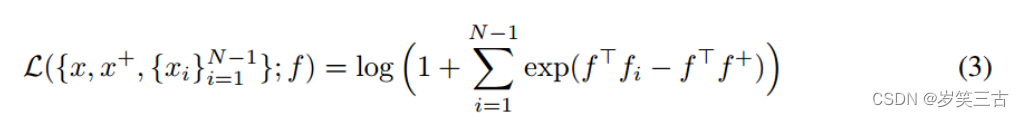
相关代码:
def cross_entropy(logits, target, size_average=True):
if size_average:
return torch.mean(torch.sum(- target * F.log_softmax(logits, -1), -1))
else:
return torch.sum(torch.sum(- target * F.log_softmax(logits, -1), -1))
class NpairLoss(nn.Module):
"""the multi-class n-pair loss"""
def __init__(self, l2_reg=0.02):
super(NpairLoss, self).__init__()
self.l2_reg = l2_reg
def forward(self, anchor, positive, target):
batch_size = anchor.size(0)
target = target.view(target.size(0), 1)
target = (target == torch.transpose(target, 0, 1)).float()
target = target / torch.sum(target, dim=1, keepdim=True).float()
logit = torch.matmul(anchor, torch.transpose(positive, 0, 1))
loss_ce = cross_entropy(logit, target)
l2_loss = torch.sum(anchor**2) / batch_size + torch.sum(positive**2) / batch_size
loss = loss_ce + self.l2_reg*l2_loss*0.25
return
五、Multi-similarity (MS) loss
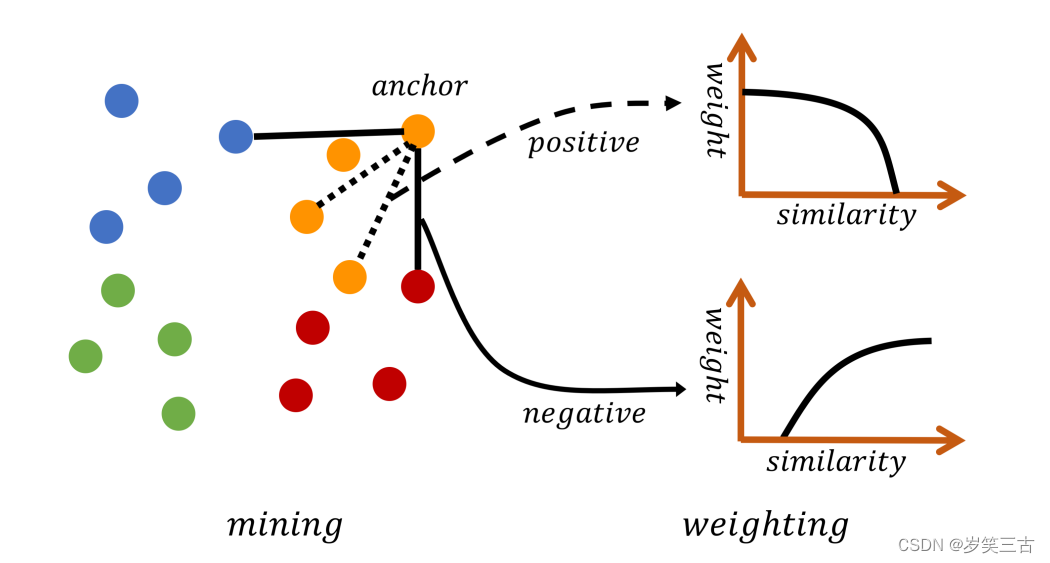
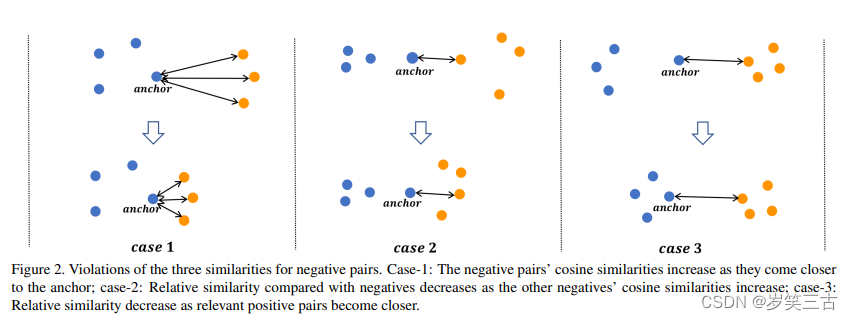
S:Self-similarity:从自身对计算而来,是最重要的相似性。一个反例对有一个更大的余弦相似对意味着从不同的类别中区分两对样例是更困难的。这样的对被视为硬反例对(hard negative pairs),他们有更多的信息并且更有意义去学习一个可区分的特征。Contrastive loss和Binomial Deviance Loss就是基于这个准则,如图case-1,当反例样例变得更近的时候,三个反例对的权重是被增加的。
N: Negative relative similarity:通过考虑附近反例对的关系计算而来的,如图case-2,即使自相似度(self-similarity)不变,相对相似度也减少。这是因为附近的反例样例变得更近,增加了这些对的自相似度(self-similarity),所以减少了相对相似度。Lifted Structure Loss就是基于这个的。
P:Positive relative similarity:相对相似度也考虑其他的正例对的关系,如果case-3,当这些正例样例变得和anchor更近的时候,当前对的相对相似度就变小了,因此该对的权重也变小。Triplet loss就是基于这个相似度。
主要分为两步:1. 首先通过Similarity-P来将信息丰富的对采样;2. 然后使用Similarity-S和Similarity-N一起给选择的对加权。

相关代码:
class MultiSimilarityLoss(nn.Module):
def __init__(self, cfg):
super(MultiSimilarityLoss, self).__init__()
self.thresh = 0.5
self.margin = 0.1
self.scale_pos = cfg.LOSSES.MULTI_SIMILARITY_LOSS.SCALE_POS
self.scale_neg = cfg.LOSSES.MULTI_SIMILARITY_LOSS.SCALE_NEG
def forward(self, feats, labels):
# feats = features extracted from backbone model for images
# labels = ground truth classes corresponding to images
batch_size = feats.size(0)
sim_mat = torch.matmul(feats, torch.t(feats))
# since feats are l2 normalized vectors, taking
its dot product with transpose of itself will yield a similarity matrix whose i,j (row and column) will correspond to similarity between i'th embedding and j'th embedding of the batch, dim of sim mat = batch_size * batch_size. zeroth row of this matrix correspond to similarity between zeroth embedding of the batch with all other embeddings in the batch.
epsilon = 1e-5
loss = list()
for i in range(batch_size):
# i'th embedding is the anchor
pos_pair_ = sim_mat[i][labels == labels[i]]
# get all positive pair simply by matching ground truth labels of those embedding which share the same label with anchor
pos_pair_ = pos_pair_[pos_pair_ < 1 - epsilon]
# remove the pair which calculates similarity of anchor with itself i.e the pair with similarity one.
neg_pair_ = sim_mat[i][labels != labels[i]]
# get all negative embeddings which doesn't share the same ground truth label with the anchor
neg_pair = neg_pair_[neg_pair_ + self.margin > min(pos_pair_)]
# mine hard negatives using the method described in the blog, a margin of 0.1 is added to the neg pair similarity to fetch negatives which are just lying on the brink of boundary for hard negative which would have been missed if this term was not present.
pos_pair = pos_pair_[pos_pair_ - self.margin < max(neg_pair_)]
# mine hard positives using the method described in the blog with a margin of 0.1.
if len(neg_pair) < 1 or len(pos_pair) < 1:
continue
# continue calculating the loss only if both hard pos and hard neg are present.
# weighting step
pos_loss = 1.0 / self.scale_pos * torch.log(
1 + torch.sum(torch.exp(-self.scale_pos * (pos_pair - self.thresh))))
neg_loss = 1.0 / self.scale_neg * torch.log(
1 + torch.sum(torch.exp(self.scale_neg * (neg_pair - self.thresh))))
# losses as described in the equation
loss.append(pos_loss + neg_loss)
if len(loss) == 0:
return torch.zeros([], requires_grad=True)
loss = sum(loss) / batch_size
return loss
参考文献
[1]: S. Chopra, R. Hadsell and Y. LeCun, “Learning a similarity metric discriminatively, with application to face verification,” 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), 2005, pp. 539-546 vol. 1, doi: 10.1109/CVPR.2005.202.
[2]: Schroff, Florian et al. “FaceNet: A unified embedding for face recognition and clustering.” 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015): 815-823.
[3]: Hyun Oh Song, Yu Xiang, Stefanie Jegelka, and Silvio Savarese. Deep metric learning via lifted structured feature embedding. In CVPR, 2016.
[4]: Kihyuk Sohn. Improved deep metric learning with multi-class n-pair loss objective. In NeurIPS. 2016.
[5]: Xun Wang, Xintong Han, Weilin Huang, Dengke Dong, and Matthew R Scott. Multi-similarity loss with general pair weighting for deep metric learning. In CVPR, 2019.