第一章 回顾Python编程
1.1 安装Python(略)
1.2 搭建开发环境(略)
1.3 IO编程
文件读写
-
打开文件
open(name[.mode[.buffering]])
- 参数mode和buffering是可选的
- 默认模式是读模式,默认缓冲区是无
-
mode参数
| ‘r’ |
‘w’ |
‘a’ |
‘b’ |
‘+’ |
| 读模式 |
写模式 |
追加模式 |
二进制模式(可添加到其他模式中使用) |
读/写模式(可添加到其他模式中使用) |
- ‘b’参数一般用来处理二进制文件,如mp3音乐或者图像
-
缓冲区
- 如果无缓冲区,那么I/O操作会将数据直接写到硬盘上
- 如果参数为正数,则代表缓冲区的大小,数据先写到内存里,使用flush或者close函数才会将数据更新到硬盘
- 如果参数为负数,则取缓冲区的默认大小
-
文件读取
- read()方法可以一次性将文件内容全部读到内存中
- read(size)方法可以一次读取至多size个字节
- 如果文件是文本文件,readline()方法可以每次读取一行内容
- readlines()方法可以一次读取所有内容并按行返回列表
filename = '/file'
#######################
# VER 1
#######################
f = open(filename)
f.read() # 文件内容的str对象
f.close()
#######################
# VER 2
#######################
try:
f = open(filename)
print(f.read())
finally:
if(f):
f.close()
#######################
# VER 3
#######################
with open(filename) as f:
print(f.read())
#######################
# VER 4
#######################
with open(filename) as f:
for line in f.readlines():
print(line.strip())
-
文件写入
filename = '/file'
str = 'write content'
#######################
# VER 1
#######################
f = open(filename, 'w')
f.write(str)
f.close()
#######################
# VER 2
#######################
with open(filename, 'w') as f:
f.write(str)
操作文件和目录
| 操作 |
作用 |
| os.getcwd() |
获得当前Python脚本工作的目录路径 |
| os.listdir() |
返回指定目录下的所有文件和目录名 |
| os.remove(path) |
删除一个文件 |
| os.removedirs(dir) |
删除多个空目录 |
| os.path.isfile(filepath) |
检验给出的路径是否是一个文件 |
| os.path.isdir(dirpath) |
检验给出的路径是否是一个目录 |
| os.isabs() |
判断是否是绝对路径 |
| os.path.exists() |
检验路径是否真的存在 |
| os.path.split() |
分离一个路径的目录名和文件名 |
| os.path.splitext() |
分离扩展名 |
| os.path.dirname(filepath) |
获取路径名 |
| os.path.basename(filepath) |
获取文件名 |
| os.getenv(), os.putenv() |
读取和设置环境变量 |
| os.linesep |
给出当前平台的行终止符(Windows:\r\n,Linux:‘\n’,Mac:’r’) |
| os.name |
指示正在使用的平台(Windows:‘nt’,Linux/Unix:‘posix’) |
| os.rename(old, new) |
重命名文件或目录 |
| os.makedirs(dir) |
创建多级目录 |
| os.mkdir(dir) |
创建单个目录 |
| os.stat(file) |
获取文件属性 |
| os.chmod(file) |
修改文件权限与时间戳 |
| os.path.getsize(filename) |
获取文件大小 |
| shutil.copytree(olddir, newdir) |
复制文件夹,两个参数都必须是目录,且newdir必须不存在 |
| shutil.copyfile(oldfile, newfile), shutil.copy(oldfile, newfile) |
复制文件,copyfile()中两个参数都必须是文件;copy()中,oldfile只能是文件,而newfile可以是文件也可以是目标目录 |
| shutil.move(oldpos, newpos) |
移动文件或目录 |
| os.rmdir(dir), shutil.rmtree(dir) |
删除目录,os.rmdir()只能删除空目录;shutil.rmtree()可以删除空目录或有内容的目录 |
序列化操作
-
把内存中的变量编程可存储或可传输的过程,就是序列化
-
将内存中的变量序列化后,可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上,实现程序状态的保存和共享。读取这些数据的过程,称为反序列化。
-
在Python中提供了两个模块来实现序列化:cPickle和pickle,前者是使用C语言编写的,效率比后者高很多
-
一般编写程序时,会先导入cPickle模块,如果不存在该模块,再导入pickle模块:
try:
import cPickle as pickle
expect ImportError:
import pickle
-
dumps()方法可以将任意对象序列化成一个str,loads()方法可以读取这样的str并将其转换为对象
-
dump()方法可以将任意对象序列化并写入文件中,load()方法可以读取这样的文件并将其转换为对象
try:
import cPickle as pickle
expect ImportError:
import pickle
data = '要序列化的任意格式数据'
filename = './file'
#######################
# dumps
#######################
pickle.dumps(data)
#######################
# dump
#######################
f = open(filename, 'wb')
pickle.dump(data, f)
f.close()
#######################
# loads
#######################
loads(str) # 经过dumps得到的str
#######################
# dump
#######################
f = open(filename, 'rb')
data = pickle.load(f)
f.close()
1.4 进程和线程
多进程
- Python主要有两种方法实现多进程
- os.fork(),仅支持Unix/Linux操作系统
- multiprocessing模块中的Process类,是跨平台的实现方式
os模块中的fork方法
-
fork方法是调用一次,返回两次。fork方法会在当前进程中复制出一份几乎完全相同的子进程
-
子进程永远返回0,父进程返回子进程的ID
-
getpid方法用于获取当前进程的ID,getppid方法用户获取父进程的ID
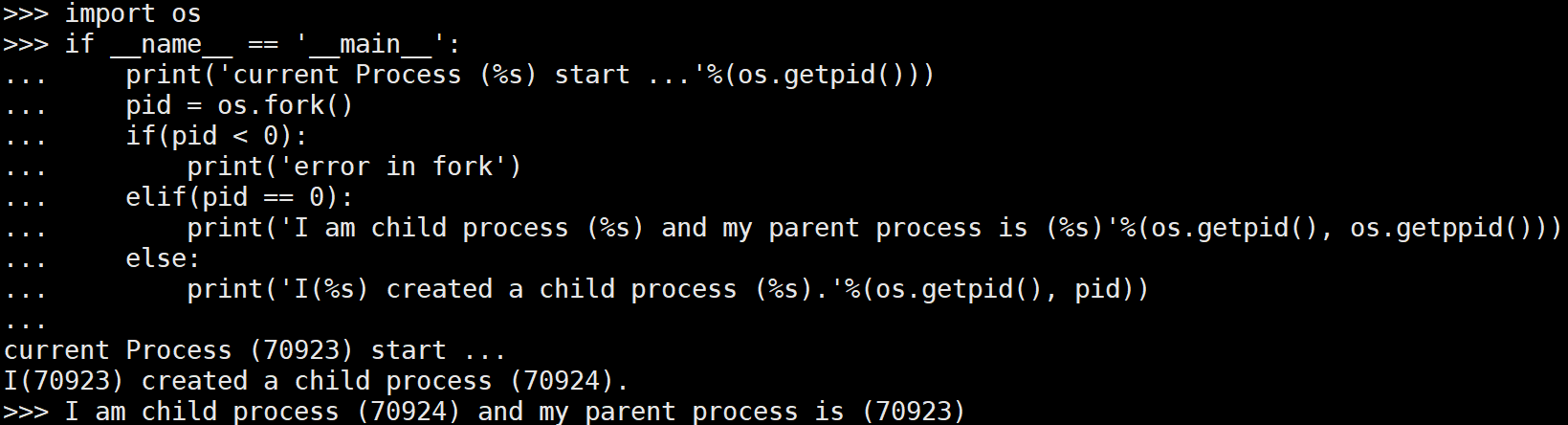
import os
if __name__ == '__main__':
print('current Process (%s) start ...'%(os.getpid()))
pid = os.fork()
if(pid < 0):
print('error in fork')
elif(pid == 0):
print('I am child process (%s) and my parent process is (%s)'%(os.getpid(), os.getppid()))
else:
print('I(%s) created a child process (%s).'%(os.getpid(), pid))
# 输出:
# current Process (70923) start ...
# I(70923) created a child process (70924).
# I am child process (70924) and my parent process is (70923)
multiprocessing中的Process类
-
创建子进程时,只需要传入一个执行函数和函数的参数
-
用start()方法启动进程
-
用join()方法实现进程间的同步
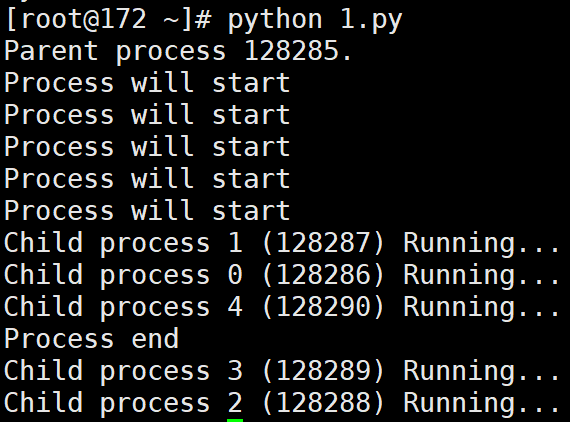
import os
from multiprocessing import Process
def run_proc(name):
print('Child process %s (%s) Running...' % (name, os.getpid()))
if __name__ == '__main__':
print('Parent process %s.' % os.getpid())
for i in range(5):
p = Process(target=run_proc, args=(str(i), ))
print('Process will start')
p.start()
p.join()
print('Process end')
# 输出:
# Parent process 128285.
# Process will start
# Process will start
# Process will start
# Process will start
# Process will start
# Child process 1 (128287) Running...
# Child process 0 (128286) Running...
# Child process 4 (128290) Running...
# Process end
# Child process 3 (128289) Running...
# Child process 2 (128288) Running...
multiprocessing模块进程池Pool类
-
Pool可以提供指定数量的进程供用户调用,默认大小是CPU的核数
-
当有新的请求到来时:
- 如果进程池未满,那么会创构建一个新的进程来执行请求
- 如果进程池已满,那么会等待已有进程结束,再创建新的进程来执行请求
-
apply_async()方法可以向进程池请求一个进程
-
Pool对象调用join()方法会等待所有子程序执行完毕
-
调用join()方法之前必须先调用close()方法,调用close()之后就不能继续添加新的Process了
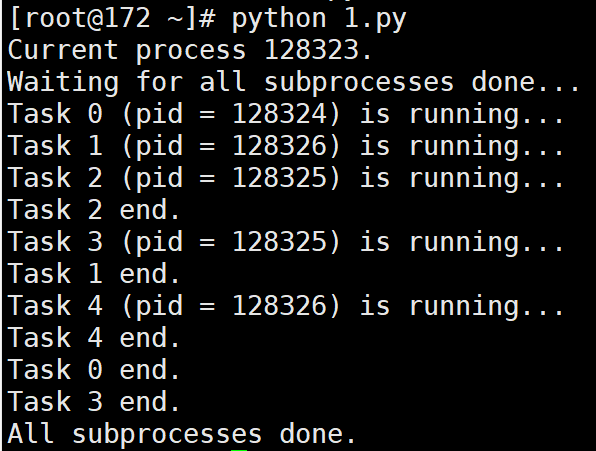
from multiprocessing import Pool
import os, time, random
def run_task(name):
print('Task %s (pid = %s) is running...' % (name, os.getpid()))
time.sleep(random.random()*3)
print('Task %s end.' %name)
if __name__ == '__main__':
print('Current process %s.' % os.getpid())
p = Pool(processes=3) # 设置进程池的最大进程数为3
for i in range(5):
p.apply_async(run_task, args=(i, ))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
# 输出:
# Current process 128323.
# Waiting for all subprocesses done...
# Task 0 (pid = 128324) is running...
# Task 1 (pid = 128326) is running...
# Task 2 (pid = 128325) is running...
# Task 2 end.
# Task 3 (pid = 128325) is running...
# Task 1 end.
# Task 4 (pid = 128326) is running...
# Task 4 end.
# Task 0 end.
# Task 3 end.
# All subprocesses done.
进程间通信
-
Python创建了多种进程间通信的方式,如Queue,Pipe,Value+Array等。本书主要讲解前两种方式。
-
Queue和Pipe的区别在于Pipe常用来在两个进程间通信,而Queue用来在多个进程间实现通信
-
Queue:
- Queue是多进程安全的队列
- put()方法用于插入数据到队列中
- 可选参数blocked和timeout:如果blocked为True(默认),且timeout为正值,则该方法会阻塞timeout的时间,直到该队列有剩余的空间,如果超时,会抛出Queue.Full异常。如果blocked为False,且队列已满,会立即抛出Queue.Full异常
- get()方法可以从队列中读取并删除一个元素
- 可选参数blocked和timeout:如果blocked为True(默认),且timeout为正值,则该方法会阻塞timeout的时间,直到该队列有可选的元素,如果超时,会抛出Queue.Empty异常。如果blocked为False,且队列为空,会立即抛出Queue.Empty异常
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def proc_write(q,urls):
print('Process(%s) is writing...' % os.getpid())
for url in urls:
q.put(url)
print('Put %s to queue...' % url)
time.sleep(random.random())
# 读数据进程执行的代码:
def proc_read(q):
print('Process(%s) is reading...' % os.getpid())
while True:
url = q.get(True)
print('Get %s from queue.' % url)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
proc_writer1 = Process(target=proc_write, args=(q,['url_1', 'url_2', 'url_3']))
proc_writer2 = Process(target=proc_write, args=(q,['url_4','url_5','url_6']))
proc_reader = Process(target=proc_read, args=(q,))
# 启动子进程proc_writer,写入:
proc_writer1.start()
proc_writer2.start()
# 启动子进程proc_reader,读取:
proc_reader.start()
# 等待proc_writer结束:
proc_writer1.join()
proc_writer2.join()
# proc_reader进程里是死循环,无法等待其结束,只能强行终止:
proc_reader.terminate()
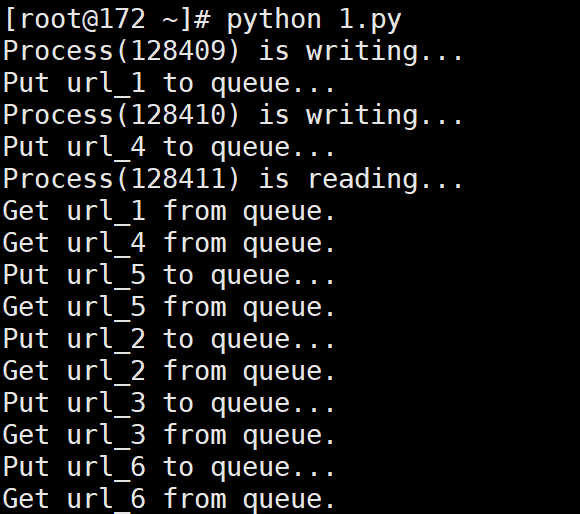
# 输出:
# Process(128409) is writing...
# Put url_1 to queue...
# Process(128410) is writing...
# Put url_4 to queue...
# Process(128411) is reading...
# Get url_1 from queue.
# Get url_4 from queue.
# Put url_5 to queue...
# Get url_5 from queue.
# Put url_2 to queue...
# Get url_2 from queue.
# Put url_3 to queue...
# Get url_3 from queue.
# Put url_6 to queue...
# Get url_6 from queue.
-
Pipe:
- Pipe常用来在两个进程间进行通信,两个进程分别位于管道的两端
- Pipe方法返回(conn1, conn2),代表一个管道的两个端
- duplex参数:如果为True,则为全双工模式,即管道两端均可收发;如果为False,则conn1只负责接收消息,conn2只负责发送消息
- send()方法:发送消息
- recv()方法:接收消息
- 如果没有消息可接收,recv方法会一直阻塞,如果管道已被关闭,那么recv方法会抛出EOFError
import multiprocessing
import random
import time,os
def proc_send(pipe,urls):
for url in urls:
print("Process(%s) send: %s" %(os.getpid(),url))
pipe.send(url)
time.sleep(random.random())
def proc_recv(pipe):
while True:
print("Process(%s) rev:%s" %(os.getpid(),pipe.recv()))
time.sleep(random.random())
if __name__ == '__main__':
pipe = multiprocessing.Pipe()
p1 = multiprocessing.Process(target=proc_send, args=(pipe[0], ['url_'+str(i) for i in range(10)]))
p2 = multiprocessing.Process(target=proc_recv, args=(pipe[1], ))
p1.start()
p2.start()
p1.join()
p2.terminate()
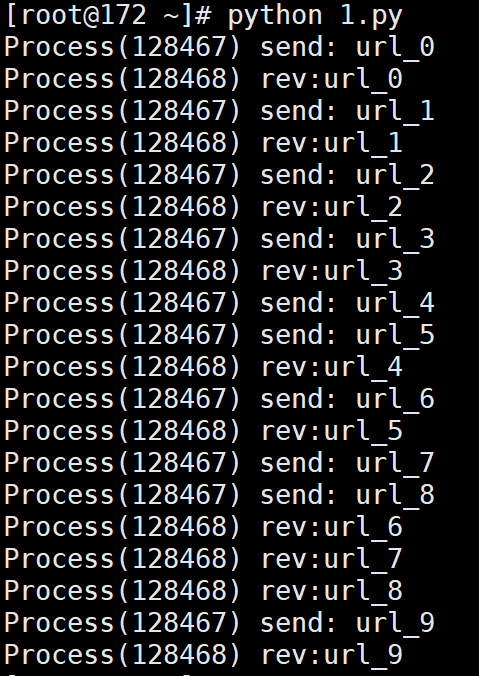
# 输出:
# Process(128467) send: url_0
# Process(128468) rev:url_0
# Process(128467) send: url_1
# Process(128468) rev:url_1
# Process(128467) send: url_2
# Process(128468) rev:url_2
# Process(128467) send: url_3
# Process(128468) rev:url_3
# Process(128467) send: url_4
# Process(128467) send: url_5
# Process(128468) rev:url_4
# Process(128467) send: url_6
# Process(128468) rev:url_5
# Process(128467) send: url_7
# Process(128467) send: url_8
# Process(128468) rev:url_6
# Process(128468) rev:url_7
# Process(128468) rev:url_8
# Process(128467) send: url_9
# Process(128468) rev:url_9
多线程
- 多线程类似于同时执行多个不同程序
- 可以把运行时间长的任务放到后台去处理
- 程序的运行速度可能加快
- 在一些需要等待的任务实现上,如用户输入、文件读写和网络收发数据等情况下,可以释放一些珍贵的资源如内存占用等
- Python标准库为多线程提供了两个模块:thread和threading,前者是低级模块;后者是高级模块,对前者进行了封装。绝大多数情况下只需要使用threading模块
用threading模块创建多线程:
- threading模块一般通过两种方式创建多线程:
- 把一个函数传入并创建Thread实例,然后调用start方法开始执行
- 直接从thread.Thread继承并创建线程类,然后重写__init__方法和run方法
- 第一种方法:
import random
import time, threading
# 新线程执行的代码:
def thread_run(urls):
print('Current %s is running...' % threading.current_thread().name)
for url in urls:
print('%s ---->>> %s' % (threading.current_thread().name,url))
time.sleep(random.random())
print('%s ended.' % threading.current_thread().name)
print('%s is running...' % threading.current_thread().name)
t1 = threading.Thread(target=thread_run, name='Thread_1',args=(['url_1','url_2','url_3'],))
t2 = threading.Thread(target=thread_run, name='Thread_2',args=(['url_4','url_5','url_6'],))
t1.start()
t2.start()
t1.join()
t2.join()
print('%s ended.' % threading.current_thread().name)
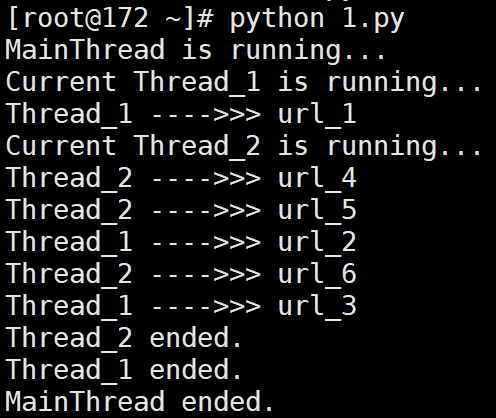
# 输出:
# MainThread is running...
# Current Thread_1 is running...
# Thread_1 ---->>> url_1
# Current Thread_2 is running...
# Thread_2 ---->>> url_4
# Thread_2 ---->>> url_5
# Thread_1 ---->>> url_2
# Thread_2 ---->>> url_6
# Thread_1 ---->>> url_3
# Thread_2 ended.
# Thread_1 ended.
# MainThread ended.
import random
import threading
import time
class myThread(threading.Thread):
def __init__(self,name,urls):
threading.Thread.__init__(self,name=name)
self.urls = urls
def run(self):
print('Current %s is running...' % threading.current_thread().name)
for url in self.urls:
print('%s ---->>> %s' % (threading.current_thread().name,url))
time.sleep(random.random())
print('%s ended.' % threading.current_thread().name)
print('%s is running...' % threading.current_thread().name)
t1 = myThread(name='Thread_1',urls=['url_1','url_2','url_3'])
t2 = myThread(name='Thread_2',urls=['url_4','url_5','url_6'])
t1.start()
t2.start()
t1.join()
t2.join()
print('%s ended.' % threading.current_thread().name)
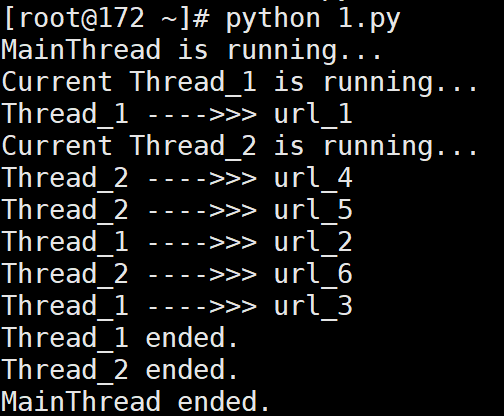
# 输出:
# MainThread is running...
# Current Thread_1 is running...
# Thread_1 ---->>> url_1
# Current Thread_2 is running...
# Thread_2 ---->>> url_4
# Thread_2 ---->>> url_5
# Thread_1 ---->>> url_2
# Thread_2 ---->>> url_6
# Thread_1 ---->>> url_3
# Thread_1 ended.
# Thread_2 ended.
# MainThread ended.
线程同步
-
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步
-
使用Thread对象的Lock和RLock可实现简单的线程同步
- 这两个对象都有acquire和release方法,对于那些每次只允许一个线程操作的数据,可以将其放到acquire和release之间
-
对于Lock对象,如果一个线程连续两次进行acquire操作,由于第一次acquire没有release,第二次acquire将挂起线程,导致永远都不会release,形成死锁
-
对于RLock对象,允许一个线程多次进行acquire操作,其内部有一个counter维护acquire的次数,而且每次acquire必须对应于一个release,在完成所有的release操作后,别的线程才能申请RLock对象
import threading
mylock = threading.RLock()
num=0
class myThread(threading.Thread):
def __init__(self, name):
threading.Thread.__init__(self,name=name)
def run(self):
global num
while True:
mylock.acquire()
print('%s locked, Number: %d'%(threading.current_thread().name, num))
if num>=4:
mylock.release()
print('%s released, Number: %d'%(threading.current_thread().name, num))
break
num+=1
print('%s released, Number: %d'%(threading.current_thread().name, num))
mylock.release()
if __name__== '__main__':
thread1 = myThread('Thread_1')
thread2 = myThread('Thread_2')
thread1.start()
thread2.start()
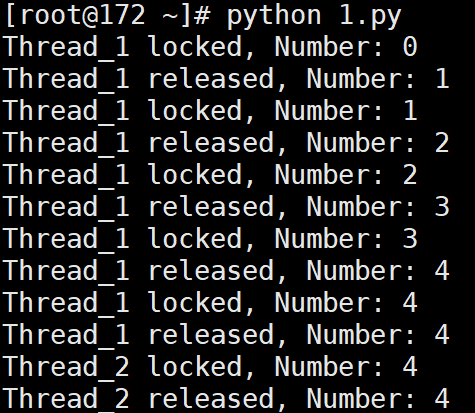
# 输出:
# Thread_1 locked, Number: 0
# Thread_1 released, Number: 1
# Thread_1 locked, Number: 1
# Thread_1 released, Number: 2
# Thread_1 locked, Number: 2
# Thread_1 released, Number: 3
# Thread_1 locked, Number: 3
# Thread_1 released, Number: 4
# Thread_1 locked, Number: 4
# Thread_1 released, Number: 4
# Thread_2 locked, Number: 4
# Thread_2 released, Number: 4
全局解释器锁(GIL)
- 在Python的原始解释器CPython中存在这GIL(Global Interpreter Lock全局解释器锁)
- 由于GIL的存在,在进行多线程操作的时候,不能调用多个CPU内核,只能利用一个内核
- 因此在进行CPU密集型操作的时候,不推荐使用多线程,而更倾向于多进程
- 对于IO密集型操作,如Python爬虫的开发,多线程可以明显提高效率。(绝大多数时间爬虫是在等待socket返回数据,网络IO的操作延时比CPU大得多)
协程
-
协程,又称微线程,纤程,是一种用户级的轻量级线程
-
协程拥有自己的寄存器上下文和栈
-
协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
-
在并发编程中,协程与线程类似,每个协程表示一个执行单元,有自己的本地数据,与其他协程共享全局数据和其他资源
-
协程需要用户自己来编写调度逻辑。对于CPU来说,协程其实是单线程,所以CPU不用处理调度、切换上下文,这就省去了CPU的切换开销
-
Python通过yield提供了对协程的基本支持,但是不完全。而使用第三方gevent库是更好的选择
-
gevent是一个基于协程的Python网络函数库,使用greenlet在libev事件循环顶部提供了以一个有高级别并发性的API
- 基于libev的快速事件循环,Linux上是epoll机制
- 基于greenlet的轻量级执行单元
- API复用了Python标准库里的内容
- 支持SSL的协作式sockets
- 可通过线程池或c-ares实现DNS查询
- 通过monkey patching功能使得第三方模块变成协作式
-
gevent对协程的支持,本质上是greenlet在实现切换工作
-
greenlet工作流程:如果进行访问网络的IO操作时出现阻塞,greenlet就显式切换到另一端没有被阻塞的代码段执行,直到原先的阻塞状况消失以后,再自动切换回原来的代码段继续处理
-
因此,greenlet是一种合理安排的串行方式
-
有了gevent自动切换协程,就保证总有greenlet在运行,而不是等待IO,这就是协程比一般多线程效率高的原因
-
spawn()方法可以用来形成协程
-
joinall()方法可以添加这些协程任务并启动运行
-
从运行结果来看,3个网络操作是并发执行的,而且结束顺序不同,但其实只有一个线程
from gevent import monkey; monkey.patch_all()
import gevent
import urllib.request
def run_task(url):
print('Visit --> %s' % url)
try:
response = urllib.request.urlopen(url)
data = response.read()
print('%d bytes received from %s.' % (len(data), url))
except Exception as e:
print(e)
if __name__=='__main__':
urls = ['https://github.com/','https://www.python.org/','http://www.cnblogs.com/']
greenlets = [gevent.spawn(run_task, url) for url in urls ]
gevent.joinall(greenlets)
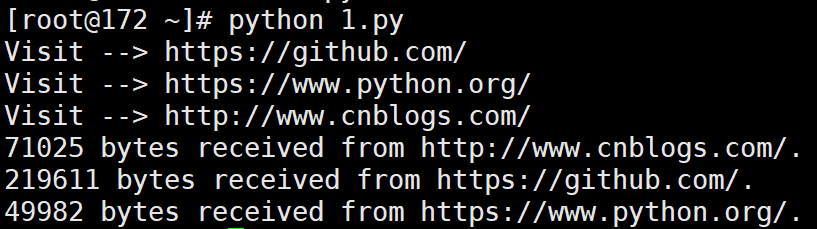
# 输出:
# Visit --> https://github.com/
# Visit --> https://www.python.org/
# Visit --> http://www.cnblogs.com/
# 71025 bytes received from http://www.cnblogs.com/.
# 219611 bytes received from https://github.com/.
# 49982 bytes received from https://www.python.org/.
-
gevent中还提供了对池的支持
-
当拥有动态数量的greenlet需要进行并发管理时,就可以使用池
from gevent import monkey
monkey.patch_all()
import urllib.request
from gevent.pool import Pool
def run_task(url):
print('Visit --> %s' % url)
try:
response = urllib.request.urlopen(url)
data = response.read()
print('%d bytes received from %s.' % (len(data), url))
except Exception as e:
print(e)
return 'url:%s --->finish' % url
if __name__=='__main__':
pool = Pool(2)
urls = ['https://github.com/','https://www.python.org/','http://www.cnblogs.com/']
results = pool.map(run_task,urls)
print(results)
# 输出:
# Visit --> https://github.com/
# Visit --> https://www.python.org/
# 219605 bytes received from https://github.com/.
# Visit --> http://www.cnblogs.com/
# 71065 bytes received from http://www.cnblogs.com/.
# 49982 bytes received from https://www.python.org/.
# ['url:https://github.com/ --->finish', 'url:https://www.python.org/ --->finish', 'url:http://www.cnblogs.com/ --->finish']

分布式进程
-
分布式进程指的是将Process进程分布到多台机器上,充分利用多台机器的性能完成复杂的任务
-
multiprocessing的managers子模块支持把多进程分布到多台机器上
-
通过一个服务进程作为调度者,将任务分布到其他多个进程中,依靠网络通信进行管理
-
举个例子:要爬取一个网站上所有的图片
- 如果使用多进程,一般是一个进程负责抓取图片的链接地址,其他进程负责从这些地址中进行下载和储存
- 如果使用分布式,则是一台机器负责抓取链接,其他机器负责下载存储
- 分布式遇到的问题是,抓取到的链接需要暴露在网络中,才能被其他机器访问到
- 分布式进程将这一过程进行了封装,即“本地队列的网络化”
-
实现上面的例子,创建分布式进程(服务进程)需要分为六个步骤
- 建立队列Queue,用于进程间通信。在分布式多进程环境下,必须通过QueueManager获得的Queue接口来添加任务
- 将队列在网络上注册,暴露给其他进程(主机),注册后获得网络队列,相当于本地队列的映像
- 建立一个对象(QueueManager(BaseManager))实例manager,绑定端口和验证口令
- 启动管理manager,监管信息通道
- 通过管理实例的方法获得通过网络访问的Queue对象,即把网络队列实体化成可以使用的本地队列
- 创建任务到本地队列中,自动上传任务到网络队列中,分配给任务进程进行处理
-
创建任务进程需要以下步骤:
- 使用QueueManager注册用于获取Queue的方法名称,任务进程只能通过名称来在网络上获取Queue
- 使用端口和验证口令连接服务器
- 从网络上获取Queue,进行本地化
- 从task队列中获取任务,并把结果写入result队列
-
服务进程样例(Linux版):
import random,time
import queue as Queue
from multiprocessing.managers import BaseManager
#实现第一步:建立task_queue和result_queue,用来存放任务和结果
task_queue=Queue.Queue()
result_queue=Queue.Queue()
class Queuemanager(BaseManager):
pass
#实现第二步:把创建的两个队列注册在网络上,利用register方法,callable参数关联了Queue对象,
# 将Queue对象在网络中暴露
Queuemanager.register('get_task_queue',callable=lambda:task_queue)
Queuemanager.register('get_result_queue',callable=lambda:result_queue)
#实现第三步:绑定端口8001,设置验证口令‘qiye’。这个相当于对象的初始化
manager=Queuemanager(address=('',8001),authkey=bytes('qiye', encoding='utf-8'))
#实现第四步:启动管理,监听信息通道
manager.start()
#实现第五步:通过管理实例的方法获得通过网络访问的Queue对象
task=manager.get_task_queue()
result=manager.get_result_queue()
#实现第六步:添加任务
for url in ["ImageUrl_"+str(i) for i in range(10)]:
print('put task %s ...' %url)
task.put(url)
#获取返回结果
print('try get result...')
for i in range(10):
print('result is %s' %result.get(timeout=10))
#关闭管理
manager.shutdown()
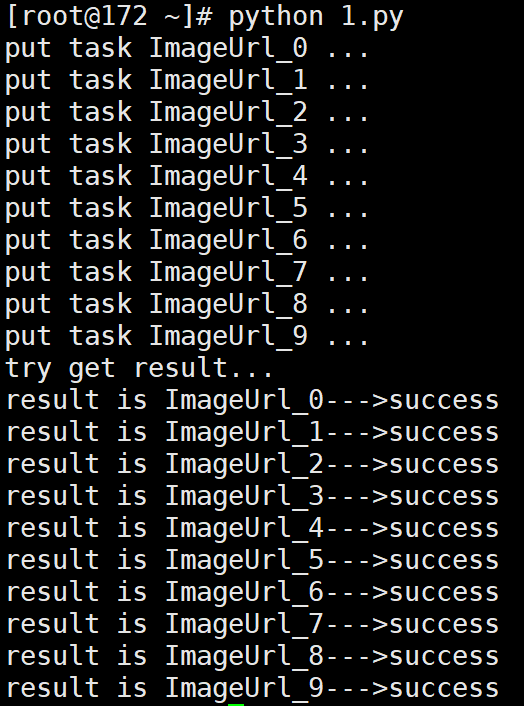
# 输出:
# put task ImageUrl_0 ...
# put task ImageUrl_1 ...
# put task ImageUrl_2 ...
# put task ImageUrl_3 ...
# put task ImageUrl_4 ...
# put task ImageUrl_5 ...
# put task ImageUrl_6 ...
# put task ImageUrl_7 ...
# put task ImageUrl_8 ...
# put task ImageUrl_9 ...
# try get result...
# result is ImageUrl_0--->success
# result is ImageUrl_1--->success
# result is ImageUrl_2--->success
# result is ImageUrl_3--->success
# result is ImageUrl_4--->success
# result is ImageUrl_5--->success
# result is ImageUrl_6--->success
# result is ImageUrl_7--->success
# result is ImageUrl_8--->success
# result is ImageUrl_9--->success
-
服务进程样例(Windows版):
# taskManager.py for windows
import queue as Queue
from multiprocessing.managers import BaseManager
from multiprocessing import freeze_support
#任务个数
task_number = 10
#定义收发队列
task_queue = Queue.Queue(task_number)
result_queue = Queue.Queue(task_number)
def get_task():
return task_queue
def get_result():
return result_queue
# 创建类似的QueueManager:
class QueueManager(BaseManager):
pass
def win_run():
#windows下绑定调用接口不能使用lambda,所以只能先定义函数再绑定
QueueManager.register('get_task_queue',callable = get_task)
QueueManager.register('get_result_queue',callable = get_result)
#绑定端口并设置验证口令,windows下需要填写ip地址,linux下不填默认为本地
manager = QueueManager(address = ('127.0.0.1',8001),authkey = b'qiye')
#启动
manager.start()
try:
#通过网络获取任务队列和结果队列
task = manager.get_task_queue()
result = manager.get_result_queue()
#添加任务
for url in ["ImageUrl_"+str(i) for i in range(10)]:
print('put task %s ...' %url)
task.put(url)
print('try get result...')
for i in range(10):
print('result is %s' %result.get(timeout=10))
except:
print('Manager error')
finally:
#一定要关闭,否则会爆管道未关闭的错误
manager.shutdown()
if __name__ == '__main__':
#windows下多进程可能会有问题,添加这句可以缓解
freeze_support()
win_run()
-
任务进程样例:
#coding:utf-8
import time
from multiprocessing.managers import BaseManager
# 创建类似的QueueManager:
class QueueManager(BaseManager):
pass
# 实现第一步:使用QueueManager注册获取Queue的方法名称
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue')
# 实现第二步:连接到服务器:
server_addr = '127.0.0.1'
print('Connect to server %s...' % server_addr)
# 端口和验证口令注意保持与服务进程设置的完全一致:
m = QueueManager(address=(server_addr, 8001), authkey=bytes('qiye', encoding='utf-8'))
# 从网络连接:
m.connect()
# 实现第三步:获取Queue的对象:
task = m.get_task_queue()
result = m.get_result_queue()
# 实现第四步:从task队列取任务,并把结果写入result队列:
while(not task.empty()):
image_url = task.get(True,timeout=5)
print('run task download %s...' % image_url)
time.sleep(1)
result.put('%s--->success'%image_url)
# 处理结束:
print('worker exit.')
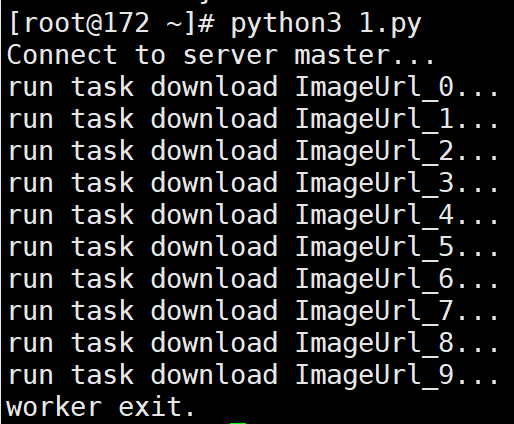
# 输出:
# Connect to server 127.0.0.1...
# run task download ImageUrl_0...
# run task download ImageUrl_1...
# run task download ImageUrl_2...
# run task download ImageUrl_3...
# run task download ImageUrl_4...
# run task download ImageUrl_5...
# run task download ImageUrl_6...
# run task download ImageUrl_7...
# run task download ImageUrl_8...
# run task download ImageUrl_9...
# worker exit.
-
服务进程(Linux版)输出:
-
任务进程输出:
1.5 网络编程
Socket
-
Socket(套接字)是网络编程的一个抽象概念,用于表示“打开了一个网络连接”
-
建立一个socket链接需要知道目标IP地址和端口号,以及指定协议类型
-
Python提供了两个基本的socket模块:
- Socket:提供了标准的BSD Sockets API
- SocketServer:提供了服务器中心类,可以简化网络服务器的开发
-
套接字格式为:socket(family, type[, protocal]),使用给定的地址族,套接字类型,协议编号(默认为0)来创建套接字
-
套接字类型:
| Socket类型 |
描述 |
| socket.AF_UNIX |
只能用于单一的Unix系统进程间通信 |
| socket.AF_INET |
服务器之间网络通信 |
| socket.AF_INET6 |
IPv6 |
| socket.SOCK_STREAM |
流式socket,用于TCP |
| socket.SOCK_DGRAM |
数据报式socket,用于UDP |
| socket.SOCK_RAW |
原始套接字,普通的套接字无法处理ICMP、IGMP等网络报文,而原始套接字可以。其次,SOCK_RAW可以处理特殊的IPv4报文;此外,利用原始套接字,可以通过IP_HDRINCL套接字选项由用户构造IP头 |
| socket.SOCK_SEQPACKET |
可靠的连续数据包服务 |
| 创建TCP Socket |
s=socket.socket(socket.AF_INET, socket.SOCK_STREAM) |
| 创建UDP Socket |
s=socket.socket(socket.AF_INET, socket.SOCK_DGRAM) |
-
Socket函数:
| Socket函数 |
描述 |
| 服务端Socket函数 |
|
| s.bind(address) |
将套接字绑定到地址,在AF_INET下,以元组(host, port)的形式表示地址 |
| s.listen(backlog) |
开始监听TCP传入连接。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量,至少为1,大部分应用程序设为5就可以了 |
| s.accept() |
接受TCP连接并返回(conn, address),其中conn是新的套接字对象,可以用来接收和发送数据。address是连接客户端的地址 |
| 客户端Socket函数 |
|
| s.connect(address) |
连接到address的套接字。一般address的格式为元组(hostname, port),如果连接出错,返回socket.error错误 |
| s.connect_ex(address) |
功能与s.connect相同,但成功返回0,失败返回errno的值 |
| 公共Socket函数 |
|
| s.recv(bufsize[,flag]) |
接受TCP套接字的数据。以字符串形式返回,bufsize指定要接收的最大数据量,flag提供有关消息的其他信息,通常可以忽略 |
| s.send(string[,flag]) |
发送TCP数据。将string中的数据发送到连接的套接字。返回值是要发送的字节数量,可能小于string的字节大小 |
| s.sendall(string[,flag]) |
完整发送TCP数据。将string中的数据发送到连接的套接字, 但在返回前会尝试发送所有数据,成功返回None,失败则抛出异常 |
| s.recvfrom(bufsize[,flag]) |
接受UDP套接字的数据。与s.recv()类似,但返回值是(data, address),data是包含接收数据的字符串,address是发送数据的套接字地址 |
| s.sendto(string[,flag], address) |
发送UDP数据,将数据发送到套接字。address格式为(ipaddr, port)的元组,指定远程地址。返回发送的字节数 |
| s.close() |
关闭套接字 |
| s.getpeername() |
返回连接套接字的远程地址。通常是元组(ipaddr, port) |
| s.getsockname() |
返回套接字自己的地址。通常是元组(ipaddr, port) |
| s.setsockopt(level, optname, value) |
设置给定套接字选项的值 |
| s.getsockopt(level, optname[, buflen]) |
返回套接字选项的值 |
| s.settimeout(timeout) |
设置套接字操作的超时期,timeout是一个浮点数,单位是秒,为None时表示没有超时期。一般应在刚创建套接字时设置,因为可能会用于连接操作。 |
| s.setblocking(flag) |
如果flag非0,则将套接字设为非阻塞模式,否则设为阻塞模式(默认)。非阻塞模式下,send无法发送数据,或recv无法接收数据,将引起socket.error异常 |
TCP编程
-
TCP是一种面向连接的通信方式,主动发起的连接叫客户端,被动响应连接的叫服务端
-
服务端创建和运行TCP连接需要以下步骤:
- 创建socket,绑定socket到本地IP与端口
- 开始监听连接
- 进入循环,不断接收客户端的连接请求
- 接收传来的数据,并发送给对方数据
- 传输完毕后,关闭socket
#coding:utf-8
import socket
import threading
import time
def dealClient(sock, addr):
#第四步:接收传来的数据,并发送给对方数据
print('Accept new connection from %s:%s...' % addr)
sock.send(b'Hello,I am server!')
while True:
data = sock.recv(1024)
time.sleep(1)
if not data or data.decode('utf-8') == 'exit':
break
print('-->>%s!' % data.decode('utf-8'))
sock.send(('Loop_Msg: %s!' % data.decode('utf-8')).encode('utf-8'))
#第五步:关闭套接字
sock.close()
print('Connection from %s:%s closed.' % addr)
if __name__=="__main__":
#第一步:创建一个基于IPv4和TCP协议的Socket
# 套接字绑定的IP(127.0.0.1为本机ip)与端口
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('127.0.0.1', 9999))
#第二步:监听连接
s.listen(5)
print('Waiting for connection...')
while True:
# 第三步:接受一个新连接:
sock, addr = s.accept()
# 创建新线程来处理TCP连接:
t = threading.Thread(target=dealClient, args=(sock, addr))
t.start()
# 输出:
# Waiting for connection...
# Accept new connection from 127.0.0.1:37092...
# -->>Hello,I am a client!
# Connection from 127.0.0.1:37092 closed.
-
客户端创建和运行TCP连接需要以下步骤:
- 创建socket,连接远程地址
- 连接后发送数据和接收数据
- 传输完毕后,关闭socket
#coding:utf-8
import socket
#初始化Socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
#连接目标的ip和端口
s.connect(('127.0.0.1', 9999))
# 接收消息
print('-->>'+s.recv(1024).decode('utf-8'))
# 发送消息
s.send(b'Hello,I am a client')
print('-->>'+s.recv(1024).decode('utf-8'))
s.send(b'exit')
#关闭套接字
s.close()
# 输出:
# -->>Hello,I am server!
# -->>Loop_Msg: Hello,I am a client!
-
服务器端输出:
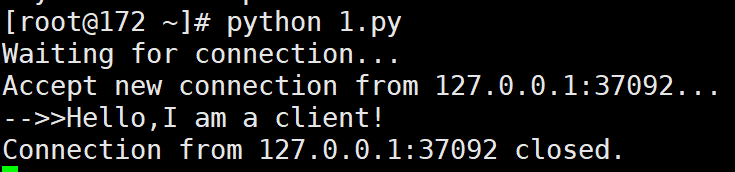
-
客户端输出

UDP编程
-
TCP是面向连接的协议,需要建立连接,以流的形式发送数据
-
UDP无连接的协议,但发送数据后无法确保数据能够到达目的端
-
UDP具有不可靠性,但速度比TCP快得多
-
服务端创建和运行UDP需要以下步骤:
- 创建socket,绑定指定的IP和端口
- 直接发送数据和接收数据
- 关闭socket
#coding:utf-8
import socket
#创建Socket,绑定指定的ip和端口
#SOCK_DGRAM指定了这个Socket的类型是UDP。绑定端口和TCP一样。
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.bind(('127.0.0.1', 9999))
print('Bind UDP on 9999...')
while True:
# 直接发送数据和接收数据
data, addr = s.recvfrom(1024)
print('Received from %s:%s.' % addr)
s.sendto(b'Hello, %s!' % data, addr)
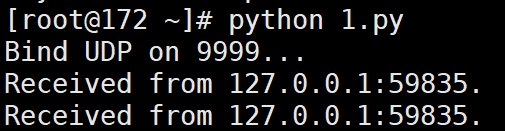
# 输出:
# Bind UDP on 9999...
# Received from 127.0.0.1:59835.
# Received from 127.0.0.1:59835.
-
客户端创建和运行UDP需要以下步骤:
- 创建socket
- 与服务端进行数据交换
- 关闭socket
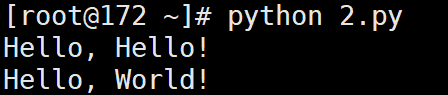
#coding:utf-8
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
for data in [b'Hello', b'World']:
# 发送数据:
s.sendto(data, ('127.0.0.1', 9999))
# 接收数据:
print(s.recv(1024).decode('utf-8'))
s.close()
# 输出:
# Hello, Hello!
# Hello, World!
-
服务器端输出:
-
客户端输出: