pytorch做自己的目标检测模型
先放上代码的百度云链接:
链接:https://pan.baidu.com/s/1ms12_2aUvm5M9hjofP8UHA
提取码:8xpf
第一章:制作数据集
要训练自己的pytorch目标检测模型,第一步就是要制作自己的数据集。我这里只是尝试,所以做了很小的数据集,只有一个分类,15张图片,就是手机随便拍的。

如图,在桌子上随便拍了些益达口香糖的瓶子,目的就是设计一个目标检测模型,最终实现能够检测到这个益达口香糖的瓶子。因为手机拍的图片较大,所以需要先将图像缩小到500x375,打开data文件夹,originalImage中存放的是原图,processImage中存放的是处理过后大小为500x375的图。如果要训练自己的数据集,只需要将自己的图片保存到originalImage文件夹中,然后打开终端运行processing.py文件,就可以在processImage文件夹中得到缩小后的图像。
然后打开labelImg文件夹,打开终端直接运行labelImg.py,如图:


打开labelImg,点击open dir选择图像所在的文件夹,即processImage,打开之后还要指定好xml文件保存的文件夹,然后开始标注

如图可以看见右下角位置会显示所有的图片路径,然后点击create RectBox就可以进行标注了,选好框框,然后输入自己的分类名字,点击ok,再点击save,然后就可以下一张了,因为我现在只对一个益达瓶子进行标注,所以我只标注了一个,如果做多分类问题,图中同时有多个类别的物体存在,要逐个标注。标注完成后,在Boxes文件夹中能看到与图像对应的xml文件,记事本打开看一下内容,如图:能够看见里面有图像的路径,图像的长宽,标注框的起点终点坐标,类别的名称等信息。

标注完成后,在data目录下打开终端运行makeTXT.py,在imagSet文件夹中生成train和val两个txt文件,两个文件分别保存了训练集和验证集的图像名称,然后退回到项目的根目录,打开终端运行encodeAnnotation.py即可在根目录下得到train和val两个txt文件,里面保存了图像的具体路径和标注的像素坐标以及类别标签。

如果要使用自己的数据集,记得一定要修改encodeAnnotation.py中的classes,改成自己的类别名称,然后还有修改myConfig中的类别数,改成类别数+1。
第二章:读取数据集
关于读取数据集这一点,pytorch有很多成型的方法,不需要自己写batch,如果只是做分类,完全可以直接调用torchvision.transform里面的几个方法
transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪,再缩放成 224×224
transforms.RandomHorizontalFlip(p=0.5), # 水平方向随机翻转,概率为 0.5, 即一半的概率翻转, 一半的概率不翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
但是目标检测不一样,目标检测因为有先验框的原因,并不适合直接调用这个方法,而是要自己写调用方法,其实主要内容还是这些,只不过需要把先验框提取出来,由上面创建的数据集可知,输入的数据除了图像之外,还需要有先验框的坐标和类别标签,而图像中的先验框和类别标签,就是用来计算loss的标签,打开模型目录中的MyDataloader文件夹内的dataloader.py,简单说一下pytorch调用数据的方法,就是先写继承了Dataset类的新类,然后通过Dataloader这个方法给模型不断的喂数据,喂入的量可以通过参数决定,这个具体可以看Dataloader的使用方法。这里重点说一下继承于Dataset的这个类,这里我也是仿照SSD的源码来写的。
# 调整图片大小
new_ar = w / h * self.rand(1 - jitter, 1 + jitter) / self.rand(1 - jitter, 1 + jitter)
scale = self.rand(.25, 2)
if new_ar < 1:
nh = int(scale * h)
nw = int(nh * new_ar)
else:
nw = int(scale * w)
nh = int(nw / new_ar)
image = image.resize((nw, nh), Image.BICUBIC)
首先来看调整图片大小这一部分,self.rand是个生成随机数的函数,所以这个调整图片大小实际上是随机调整的,我觉得这个的目的是让同一张图片,通过大小不同,能够适应检测环境中实物的大小变换,同时也是为了加强数据,强化数据集。
# 放置图片
dx = int(self.rand(0, w - nw))
dy = int(self.rand(0, h - nh))
new_image = Image.new('RGB', (w, h),
(np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255)))
new_image.paste(image, (dx, dy))
image = new_image
放置图片这一步其实还有一个叫法叫添加灰条,其目的是让所有的输入图片都是同样大小的正方形图片,因为上面的图片是做个缩放的,所以大小不能确定,大小不够的就需要添加灰条,这里就可以简单理解为放了一张正方形白纸在那里,你可以在纸上随便画你想要的东西,填不满的就保留白纸,最终训练的时候也是将这张白纸直接输入,这样就能实现输入图像都是一样大的,但是图内物体的大小却不同。是否翻转和色域变换就没什么好说的了,色域这方面可以了解一下hsv。
# 调整目标框坐标
box_data = np.zeros((len(box), 5))
if len(box) > 0:
np.random.shuffle(box)
box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx
box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy
if flip:
box[:, [0, 2]] = w - box[:, [2, 0]]
调整目标坐标框这一块我写的比较简单,没有像SSD或者yolo的官方代码那么高级,主要是为了方便理解,其实就是把坐标框读取出来并按照图片缩放的比例同比缩放,然后转换成中点和宽高的形式,再对图像和边框都做个归一化。最后不要忘了要把类别标签也加在后面。这样数据读取就算基本完成了,在训练的时候只需要用Dataloader方法读取数据就可以了。
第三章:设计网络模型
我这里的模型比较简单,因为主要是为了复现目标检测的原理,方便理解,所以我一vgg16为基础,简单加了一点东西,还有我的先验框套框的方式也是完全仿照SSD的,SSD一共套了8732个框,太多了,我这里就只套136个。很多初学者在刚开始看目标检测的时候,很难理解这个套框方式,尤其是网上很多都简单说了原理,却没有深入的讲解具体的代码,在这里我就详细的讲解一下,希望能给大家带来帮助。网上关于SSD的先验框原理很多,反正大概就都是38x38什么的,我这里的136是用的5x5x4+3x3x4就这么点框框,当然可能效果非常差,这个就不重要了,主要看原理。首先来说一下这个5x5其实就是把图片分成了5x5的25个部分,那么这25个部分又是怎么来的呢,答案是:卷积。
其实SSD中也是一样,我们知道卷积,就是不断的增加深度,同时池化会降低大小,那么300x300的图片,经历过几次池化之后,就会变成5x5大小,甚至是3x3大小
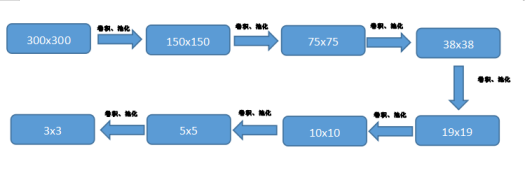
如图,一张300x300的图片,可以通过卷积池化不断的缩小,而图像的压缩过程中,比如300到150,那么150中的一个像素点,就可以代表300中的两个像素点,依次类推,当图像的大小只有38x38那么大的时候,一个像素点代表的就是原图的38x38分之1,所以就相当于把原图分成38x38份,那么我选择的5x5也是一样的饿,5x5中一个像素点就能代表原图中的二十五分之一,可能有人会觉得一个像素点,怎么可能保存的了之前那么多的特征,那就不要忘了,在这个宽度减小的过程中,图像的深度却是不断加深的,也就是说图像的特征放到深度上了,比如我5x5大小的时候,我的深度是512那么一个像素点就有512个特征,是不是还是很多的呢。说到这里,还有一个问题,那就是图像的分类和先验框的坐标是怎么产生的,先说分类,不管是SSD还是Yolo,计算分类都是对所有先验框圈中的小图像都做一次分类预测,也就是说假如你用的是voc数据集,你有20个分类,那么你对每张图输出的分类预测应该就是8732x(20+1)其中8732是框的个数,20是分类数,1是背景。那么这个分类是怎么实现的呢,大家应该都知道简单分类的模型中,会在卷积结束后进行全连接,直接将所有的特征拉平,最终链接成最终的分类数,就可以得出结果,那么一张图中的一部分,要怎么去给他分类呢,答案还是:卷积。这里的卷积的作用,就不是为了获取特征而卷积了,这里的卷积就是完完全全用卷积去代替全连接,这里的卷积只压缩深度,相当于对每一个像素点的深度方向做全连接,就比如我之前说的5x5图像深度是512,因为我只有一个物体,所以最终分类就是一类加背景就是两个,那就将这512的深度压缩到深度为2就可以了,相当于在深度上去实现分类。
所以我设计的模型是类似于vgg的,通过一系列的卷积池化,最终的图像只有3x3x512大小,并且在5x5和3x3的最后一次输出时,将输出保存,最后用卷积代替全连接得出分类结果,以及先验框的中点坐标和宽高,还有先验框的回归系数。所以最终我的模型代码为:
def conv_2(in_c, out_c):
return nn.Conv2d(in_c, out_c, kernel_size=3, padding=1)
def models(in_channels):
layers = []
layers += [conv_2(in_channels, 64), nn.ReLU(inplace=True)]
layers += [conv_2(64, 64), nn.ReLU(inplace=True)]
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
layers += [conv_2(64, 128), nn.ReLU(inplace=True)]
layers += [conv_2(128, 128), nn.ReLU(inplace=True)]
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
layers += [conv_2(128, 256), nn.ReLU(inplace=True)]
layers += [conv_2(256, 256), nn.ReLU(inplace=True)]
layers += [conv_2(256, 256), nn.ReLU(inplace=True)]
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
layers += [conv_2(256, 512), nn.ReLU(inplace=True)]
layers += [conv_2(512, 512), nn.ReLU(inplace=True)]
layers += [conv_2(512, 512), nn.ReLU(inplace=True)]
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
layers += [conv_2(512, 512), nn.ReLU(inplace=True)]
layers += [conv_2(512, 512), nn.ReLU(inplace=True)]
layers += [conv_2(512, 512), nn.ReLU(inplace=True)]
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
layers += [conv_2(512, 1024), nn.ReLU(inplace=True)]
layers += [conv_2(1024, 1024), nn.ReLU(inplace=True)]
layers += [conv_2(1024, 1024), nn.ReLU(inplace=True)]
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
layers += [conv_2(1024, 512), nn.ReLU(inplace=True)]
layers += [conv_2(512, 512), nn.ReLU(inplace=True)]
layers += [conv_2(512, 512), nn.ReLU(inplace=True)]
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
layers += [conv_2(512, 512), nn.ReLU(inplace=True)]
layers += [conv_2(512, 512), nn.ReLU(inplace=True)]
layers += [conv_2(512, 512), nn.ReLU(inplace=True)]
loc_layers = []
conf_layers = []
for i in range(2):
loc_layers += [nn.Conv2d(512, 16, kernel_size = 3, padding=1)]
conf_layers += [nn.Conv2d(512, 8, kernel_size = 3, padding=1)]
第四章:前向传播
前向传播这一部分主要来分析一下模型的调用和输出,首先来看调用
def forward(self, x):
sources = list()
loc = list()
conf = list()
# 取出5x5的网格放入列表
for k in range(44):
x = self.model[k](x)
sources.append(x)
# 取出3x3的网格放入列表
for k in range(44, len(self.model)):
x = self.model[k](x)
sources.append(x)
# 利用卷积代替全连接计算先验框的回归和分类回归
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
# 重置维度
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
# 返回输出,包括先验框的回归,分类回归,实际划分的先验框坐标
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
self.priors
)
在这里主要说一下取出网络中间部分,因为卷积最终只会输出一个结果,所以只能在中途取出5x5和3x3大小的网格,而取出之后,要在卷积完全结束之后再去处理得到想要的输出结果。
loc_layers = []
conf_layers = []
for i in range(2):
loc_layers += [nn.Conv2d(512, 16, kernel_size = 3, padding=1)]
conf_layers += [nn.Conv2d(512, 8, kernel_size = 3, padding=1)]
这部分代码就是模型中用卷积代替全连接的部分,这个东西我上面已经说的比较详细了,希望读者能努力理解。然后来看输出的三组变量分别是什么。
Loc:这个是先验框的回归,这个回归我理解的是这样的,比如要识别的物体有的是长的有的是宽的,但是一般整体的长宽比是差不多的,就比如人,一般是竖着的长方形,那么这个回归每次训练就会根据输入的人的标注框进行回归分析,大概得到一个比例,这样在类别检测到人的时候,那么就可以大概知道人的先验框的比例,然后根据回归系数去调节先验框的宽高,最终能更好的契合人的大小,这是我个人的理解,如果不对,还望指出。
conf:这个输出就是分类了,比如你有20个分类,那么在这个输出中,就是每一个先验框对于21类(包括分类数和背景)的特征匹配的值,也就是在检测过程中输出的softmax值,再直白些,就是置信概率。
priors:这个输出的是实际划分的先验框,就像SSD里面38x38的先验框有4个,10x10的有6个,那么这些个数是怎么确定的呢,其实就是在这里了,看下面这幅图,图中就是几个先验框的例子,先验框为什么需要很多个呢,因为物体的形状多种多样,如果先验框的是正方形的,那就不能很好的嵌套物体了,所以每个先验框的实际大小,是需要人为设置的,入下图:实线划分的网格是我们根据卷积得出的网格,然后以一个网格为基础,分别做四个先验框,大小长度都不同,这样才能更好的捕获物体。但是这个怎么设置呢,具体看代码。

这是设置先验框位置的代码,先验框中的四个数据分别是中心点的坐标和先验框的宽高。
def forward(self):
mean = []
for k, f in enumerate(self.feature_maps):
x,y = np.meshgrid(np.arange(f),np.arange(f))
x = x.reshape(-1)
y = y.reshape(-1)
for i, j in zip(y,x):
f_k = self.image_size / self.steps[k]
# 计算网格的中心
cx = (j + 0.5) / f_k
cy = (i + 0.5) / f_k
# 求短边
s_k = self.min_sizes[k]/self.image_size
mean += [cx, cy, s_k, s_k]
# 求长边
s_k_prime = self.max_sizes[k]/self.image_size
mean += [cx, cy, s_k_prime, s_k_prime]
# 获得长方形
mean += [cx, cy, s_k_prime*sqrt(2), s_k/sqrt(2)]
mean += [cx, cy, s_k/sqrt(2), s_k_prime*sqrt(2)]
output = torch.Tensor(mean).view(-1, 4)
这里计算得到的并非实际的宽高和中点坐标,而是相对的位置关系,具体的数据可以看一下我的myConfig文件中的数据,我设置的先验框比较简单,想看复杂的可以去看SSD的源码。
最后再看下前向传播输入输出的维度,有利于理解。
(1, 3, 300, 300)
torch.Size([1, 136, 4])
torch.Size([1, 136, 2])
torch.Size([136, 4])
第一个维度是输入图像的维度,我们读取的图像一般都是300x300x3这样的,所以在读取之后需要变化维度。这里的1是输入的batch的数目,因为我就10张图片,所以只能一张一张的喂。
后面三个是输出的维度,136是先验框的个数,4是先验框的中点和宽高,2是分类。
第五章:反向传播
反向传播这一部分主要是loss的计算,说实话这一段我是完全抄袭了SSD的loss计算,接下来就来逐一分析一下计算方法。
打开model_training中的MultiBoxloss类。
# 回归信息,置信度,先验框
loc_data, conf_data, priors = predictions
# 计算出batch_size
num = loc_data.size(0)
# 取出所有的先验框
priors = priors[:loc_data.size(1), :]
# 先验框的数量
num_priors = (priors.size(0))
# 创建一个tensor进行处理
loc_t = torch.Tensor(num, num_priors, 4)
conf_t = torch.LongTensor(num, num_priors)
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
priors = priors.cuda()
for idx in range(num):
# 获得框
truths = targets[idx][:, :-1]
# 获得标签
labels = targets[idx][:, -1]
# 获得先验框
defaults = priors
# 找到标签对应的先验框
match(self.threshold, truths, defaults, self.variance, labels,
loc_t, conf_t, idx)
这几部就是常规操作了,把模型卷积之后的结果和实际的标签都获取之后,准备计算loss。然后重点是这个match函数,看一下这个函数的内容。
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
# 计算所有的先验框和真实框的重合程度
overlaps = jaccard(
truths,
point_form(priors)
)
# 所有真实框和先验框的最好重合程度
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
best_prior_idx.squeeze_(1)
best_prior_overlap.squeeze_(1)
# 所有先验框和真实框的最好重合程度
# [1,prior]
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
best_truth_idx.squeeze_(0)
best_truth_overlap.squeeze_(0)
# 找到与真实框重合程度最好的先验框,用于保证每个真实框都要有对应的一个先验框
best_truth_overlap.index_fill_(0, best_prior_idx, 2)
# 对best_truth_idx内容进行设置
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
# 找到每个先验框重合程度最好的真实框
matches = truths[best_truth_idx]
conf = labels[best_truth_idx] + 1
# 如果重合程度小于threhold则认为是背景
conf[best_truth_overlap < threshold] = 0
# 偏移量学习
loc = encode(matches, priors, variances)
loc_t[idx] = loc
# 每个先验框的最优标签
conf_t[idx] = conf
这部分函数虽然看似不长,但是真的是不怎么好理解,首先看第一步:
# 计算所有的先验框和真实框的重合程度
overlaps = jaccard(
truths,
point_form(priors))
计算所有先验框与真实框的重合度,传入两个参数,一个是真实的先验框,来自于标注的图像,另一个是net输出的先验框,也就是自己划分的先验框。然后再转到jaccard函数。
def jaccard(box_a, box_b):
inter = intersect(box_a, box_b)
# 计算先验框和真实框各自的面积
area_a = ((box_a[:, 2]-box_a[:, 0]) *
(box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2]-box_b[:, 0]) *
(box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
# 求IOU
union = area_a + area_b - inter
return inter / union # [A,B]
Jaccard函数主要目的是计算真实框与先验框重合部分的面积与相交的面积比,即A交B比上A并B,如图:即图中的C / ((A+B) - C)
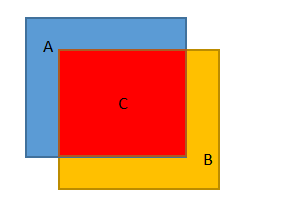
既然知道了要算什么,那就看看代码是怎么实现的吧,jaccard中的area_a和area_b就是分别算了A和B的面积,而C的面积,好吧,又一个函数,intersect。
def intersect(box_a, box_b):
A = box_a.size(0)
B = box_b.size(0)
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
box_b[:, :2].unsqueeze(0).expand(A, B, 2))
inter = torch.clamp((max_xy - min_xy), min=0)
# 计算先验框和所有真实框的重合面积
return inter[:, :, 0] * inter[:, :, 1]
Intersect函数中,max_xy计算的是A和B两个左下角点中像素值较小的那一个,min_xy计算的是A和B两个左下角点中像素值较大的那一个,这样就可以得到C的左上角点和右下角点,inter中max_xy和min_xy相减,就得到了C的两条边长,然后返回两边长的乘积,就得到相交部分C的面积。然后再回到jaccard中就可以很清楚的知道那个返回值返回的就是一个面积比。再解释两行特殊的代码:
def point_form(boxes):
return torch.cat((boxes[:, :2] - boxes[:, 2:]/2, # xmin, ymin
boxes[:, :2] + boxes[:, 2:]/2), 1) # xmax, ymax
这个是因为先验框本来是中点和宽高形式的,但是真实框是左上点和右下点的形式的,所以要转换成同样的形式。
box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
这句代码的目的是把真实框的个数变的和先验框一样多,就是将真实框复制,这样就方便一步计算,不然就需要循环一步一步算,显然这是torch语法的方便之处。
接下来看看这个重合度是怎么使用的:
# 所有真实框和先验框的最好重合程度
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
best_prior_idx.squeeze_(1)
best_prior_overlap.squeeze_(1)
# 所有先验框和真实框的最好重合程度
# [1,prior]
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
best_truth_idx.squeeze_(0)
best_truth_overlap.squeeze_(0)
这里上面是真实框和先验框的最好重合度,而下面是先验框和真实框的最好重合度,乍一看这不是一个事么,但是这确实不是一个事,举个栗子:

如图:行数代表真实框的个数,列数代表先验框的个数,显然一幅图中的真实框个数是比较少的,先验框是比较多的,先说真实框和先验框的最好重合度,其实就是所有的先验框与所有的真实框去比较,体现在代码中,就是真实框假设我有三个,那就找出三个与真实框重合度最好的先验框,也就是说如上图中的样子,在每一行中寻找一个最大值,而先验框和真实框的最好重合度则是要为每一个先验框都匹配一个最大值,所以要按列去每列中寻找一个最大值。
# 找到每个先验框重合程度最好的真实框
matches = truths[best_truth_idx]
conf = labels[best_truth_idx] + 1
# 如果重合程度小于threhold则认为是背景
conf[best_truth_overlap < threshold] = 0
这三行代码最终目的是为了得到重合度最好的先验框所在的位置
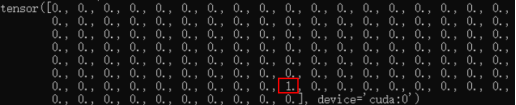
如图可以看到1所在的位置就是与真实框重合度最好的先验框,因为我只有一个真实框,所以也就只有一个1。
# 偏移量学习
loc = encode(matches, priors, variances)
Match中的最后一行代码,调用了一个encode的函数。
def encode(matched, priors, variances):
g_cxcy = (matched[:, :2] + matched[:, 2:]) / 2 - priors[:, :2]
g_cxcy /= (variances[0] * priors[:, 2:])
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh) / variances[1]
return torch.cat([g_cxcy, g_wh], 1)
这个函数内容很简单,就是简单的数学运算,前两行就是对先验框中心点位置的调整,后两行是对先验框宽高的调整,至于为什么这么算,这个应该是SSD开发者的经验和智慧了。
# 所有conf_t>0的地方,代表内部包含物体
pos = conf_t > 0
# 求和得到每一个图片内部有多少正样本
num_pos = pos.sum(dim=1, keepdim=True)
# 计算回归loss
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
这部分代码是计算先验框的回归loss,这里用了smooth_l1_loss的损失函数,pytorch中几个常用的损失函数具体可以自行到网上查。接下来看下分类的损失函数。
# 你可以把softmax函数看成一种接受任何数字并转换为概率分布的非线性方法
# 获得每个框预测到真实框的类的概率
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
这一步就是交叉熵损失函数的计算方法,可以参考下面这个公式,这行代码就是实现了这个公式。目的是为了计算每一个框预测到真实框的概率。
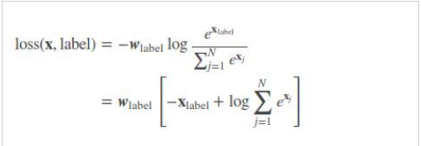
# 获得每一张图新的softmax的结果
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
# 计算每一张图的正样本数量
num_pos = pos.long().sum(1, keepdim=True)
# 限制负样本数量
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1) -1)
neg = idx_rank < num_neg.expand_as(idx_rank)
接下来为计算得到的概率进行排序,将概率最大的框放在最前面,然后获取到正样本的数量,再根据正样本的数量去限制负样本的数量,因为如果不限制的话负样本会远多于正样本,而一般负样本是正样本的三倍就够了。
计算正样本的loss和负样本的loss
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_c lasses)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average =False)
最后这部分重点了解一下torch.gt,这里的conf_p中保存的是预测的每个框的内容的类别置信度,targets_weighted中保存的是框内的真实标签,然后计算loss值。
本博客的内容仅为学习目标检测的小伙伴提供一个理解学习的方式,模型并不适合实际应用,如果需要做目标检测的训练,建议还是使用经典方案。