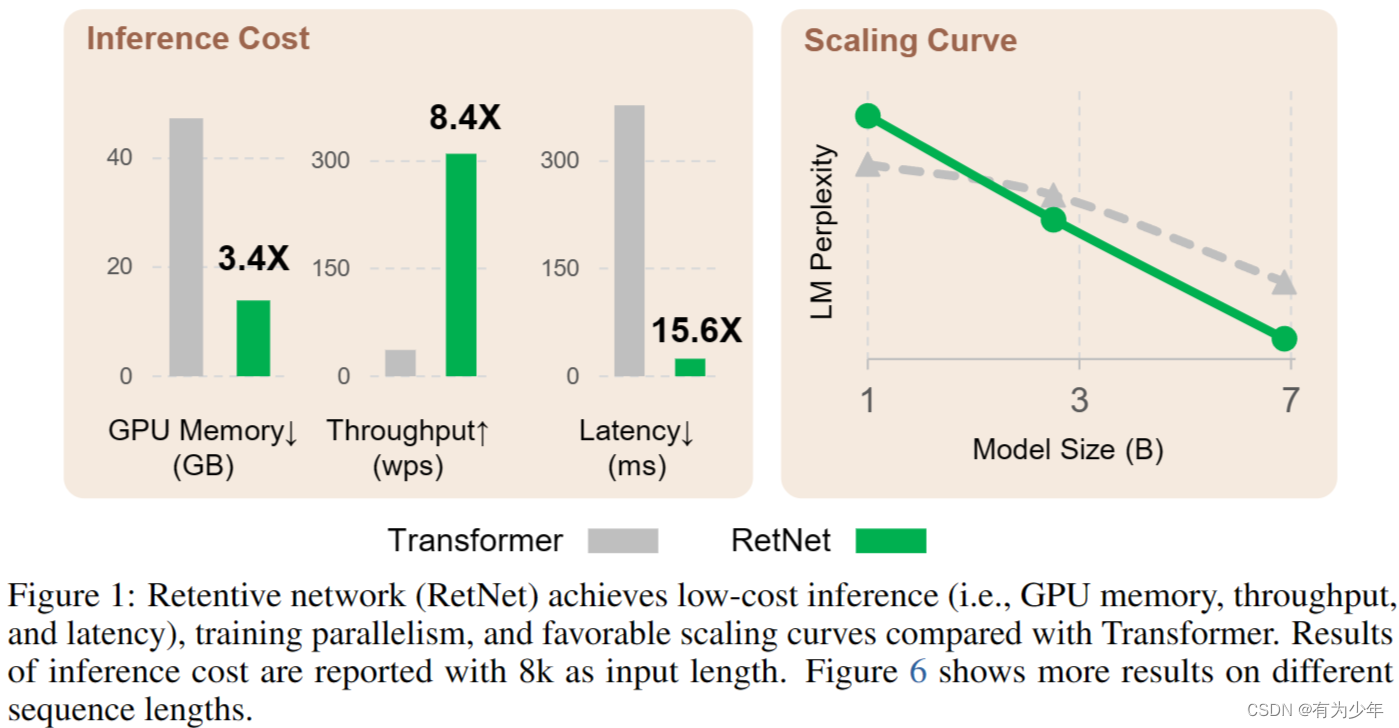
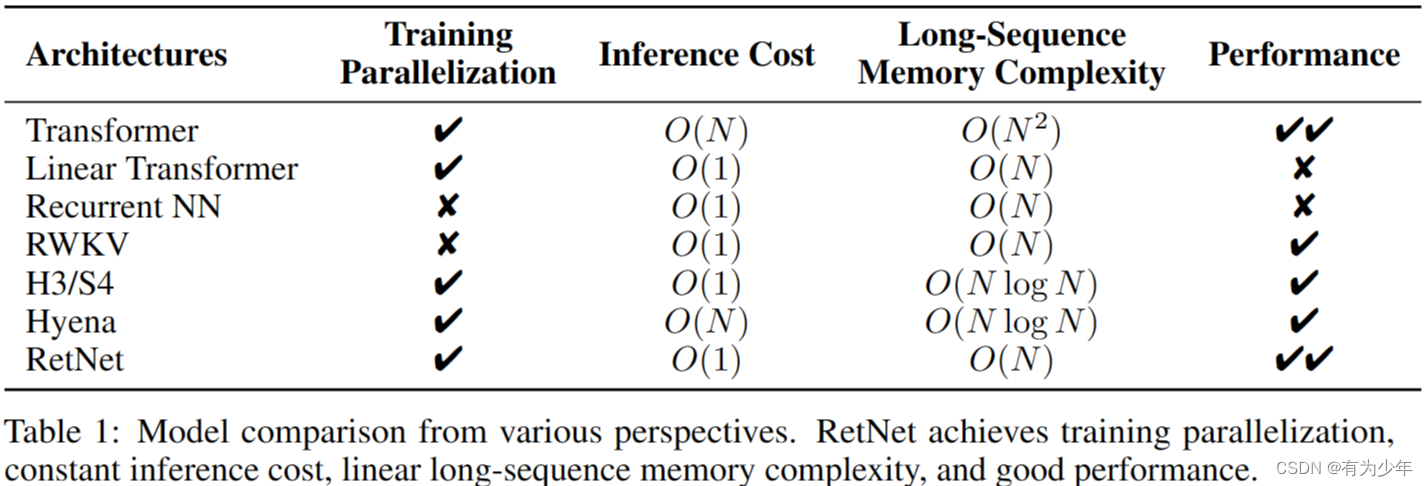
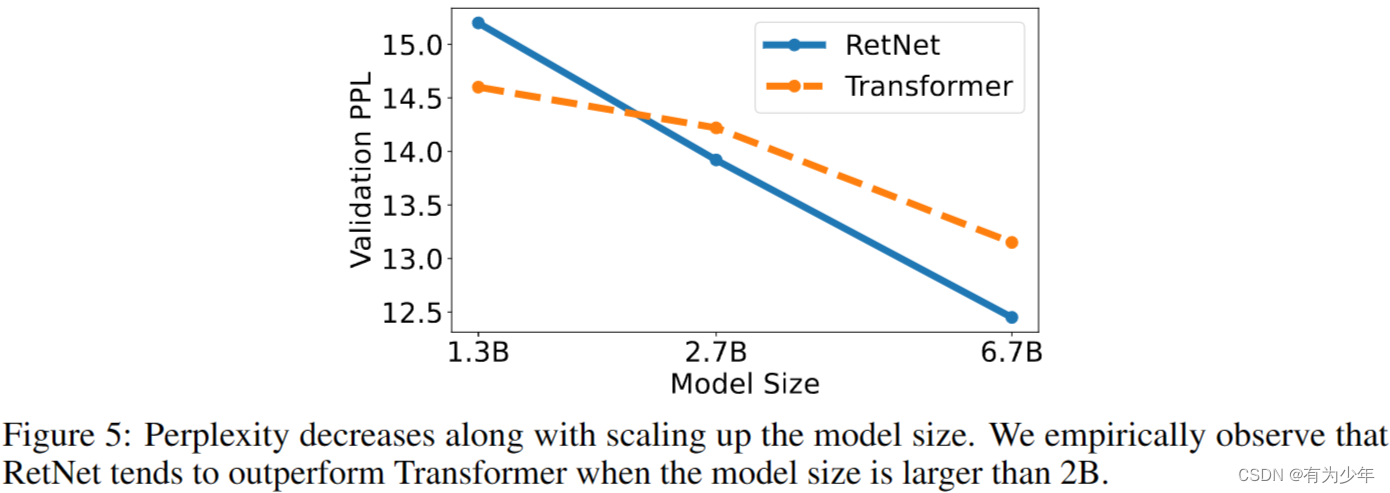
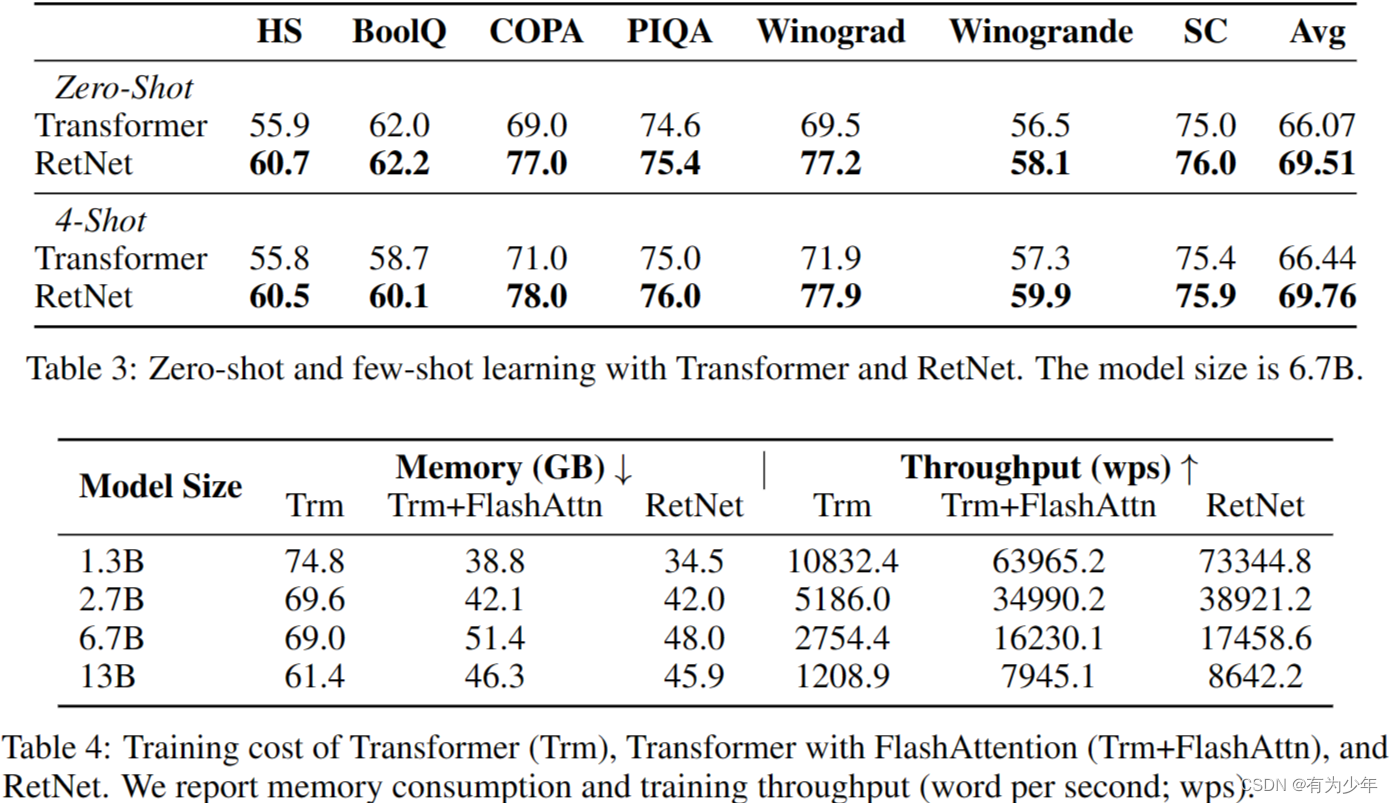
对于输入的长度为
N
N
N的文本嵌入序列,由于其本身信息的前后依赖关系和因果关系的需求,所以本文是从循环模型的角度开始构建模型的。
基础的迭代形式:
对于第n次迭代的输入
X
n
X_n
Xn,有
Q
n
=
X
n
⋅
W
Q
,
K
n
=
X
n
⋅
W
K
,
V
n
=
X
n
⋅
W
V
∈
R
1
×
d
Q_n = X_n \cdot W_Q, K_n = X_n \cdot W_K, V_n = X_n \cdot W_V \in \mathbb{R}^{1 \times d}
Qn=Xn⋅WQ,Kn=Xn⋅WK,Vn=Xn⋅WV∈R1×d
将序列建模认为成通过状态
S
n
S_n
Sn,将
V
(
n
)
V(n)
V(n)映射为
O
(
n
)
O(n)
O(n)**的过程。**于是可以得到下式:
S
n
=
A
s
n
−
1
+
K
n
⊤
V
n
=
A
n
−
1
K
1
⊤
V
1
+
A
n
−
2
K
2
⊤
V
2
+
⋯
+
K
n
⊤
V
n
=
∑
m
=
1
n
A
n
−
m
K
m
⊤
V
m
S_n = As_{n-1} + K^{\top}_n V_n = A^{n-1} K^{\top}_1 V_1 + A^{n-2} K^{\top}_2 V_2 + \dots + K^{\top}_n V_n = \sum^{n}_{m=1} A^{n-m} K^{\top}_m V_m
Sn=Asn−1+Kn⊤Vn=An−1K1⊤V1+An−2K2⊤V2+⋯+Kn⊤Vn=m=1∑nAn−mKm⊤Vm
这里的
A
∈
R
d
×
d
A \in \mathbb{R}^{d \times d}
A∈Rd×d描述了各个位置之间的相对关系。
O
n
=
Q
n
S
n
=
∑
m
=
1
n
Q
n
A
n
−
m
K
m
⊤
V
m
,
Q
n
∈
R
1
×
d
O_n = Q_n S_n = \sum^{n}_{m=1}Q_n A^{n-m} K^{\top}_m V_m, Q_n \in \mathbb{R}^{1 \times d}
On=QnSn=∑m=1nQnAn−mKm⊤Vm,Qn∈R1×d
Parallel Retention
通过设置一个特殊的矩阵
A
A
A,将其对角化处理获得
A
=
Λ
(
γ
e
i
θ
)
Λ
−
1
A = \Lambda (\gamma e^{i \theta}) \Lambda^{-1}
A=Λ(γeiθ)Λ−1,这里的两个矩阵
Λ
\Lambda
Λ由于在公式中紧邻
Q
n
,
K
n
Q_n, K_n
Qn,Kn,所以可以将其合并到二者各自的权重矩阵
W
Q
,
W
K
W_Q, W_K
WQ,WK中一同随着网络去学习,从而上式可以改写:
O
n
=
Q
n
S
n
=
∑
m
=
1
n
Q
n
(
γ
e
i
θ
)
n
−
m
K
m
⊤
V
m
=
∑
m
=
1
n
[
Q
n
(
γ
e
i
θ
)
n
]
[
K
m
(
γ
e
i
θ
)
−
m
]
⊤
V
m
=
∑
m
=
1
n
γ
n
−
m
(
Q
n
e
i
n
θ
)
(
K
m
e
i
m
θ
)
†
V
m
O_n = Q_n S_n = \sum^{n}_{m=1} Q_n (\gamma e^{i \theta})^{n-m} K^{\top}_m V_m = \sum^{n}_{m=1} [Q_n (\gamma e^{i \theta})^{n}] [K_m (\gamma e^{i \theta})^{-m}]^{\top} V_m = \sum^{n}_{m=1} \gamma^{n-m} (Q_n e^{i n \theta}) (K_m e^{i m \theta})^{\dagger} V_m
On=QnSn=m=1∑nQn(γeiθ)n−mKm⊤Vm=m=1∑n[Qn(γeiθ)n][Km(γeiθ)−m]⊤Vm=m=1∑nγn−m(Qneinθ)(Kmeimθ)†Vm
由于这里
Q
,
K
Q, K
Q,K索引上的独立性,所以很容易改为并行的基于矩阵运算的结构。将复数矩阵系数极其共轭形式分别合并到
Q
,
K
Q, K
Q,K计算过程中,从而可以得到:
Q
=
(
X
W
Q
)
⊙
Θ
,
K
=
(
X
W
K
)
⊙
Θ
ˉ
,
V
=
X
W
V
,
Θ
n
=
e
i
n
θ
D
n
m
=
γ
n
−
m
if
n
≥
m
else
0
Q=(XW_Q) \odot \Theta, K=(XW_K) \odot \bar{\Theta}, V=XW_V, \Theta_{n} = e^{i n \theta} \\ D_{nm}=\gamma^{n-m} \text{ if } n \ge m \text{ else } 0
Q=(XWQ)⊙Θ,K=(XWK)⊙Θˉ,V=XWV,Θn=einθDnm=γn−m if n≥m else 0
从而得到整体模块的计算过程:
R
e
t
e
n
t
i
o
n
(
X
)
=
(
Q
K
⊤
⊙
D
)
V
,
D
∈
R
N
×
N
Retention(X) = (QK^{\top} \odot D) V, D \in \mathbb{R}^{N \times N}
Retention(X)=(QK⊤⊙D)V,D∈RN×N
这里由于有
Q
K
⊤
QK^\top
QK⊤,使用了三种归一化方式来提升数值精度,这些归一化策略实际上都是在GN输入上乘以了一个常数,而由于GN本身的尺度不变性,所以必不会影响GN的输出和反向的梯度。
使用特征维度归一化
Q
K
⊤
/
d
Q K^\top / \sqrt{d}
QK⊤/d
设置
D
=
{
D
n
m
∑
i
=
1
n
D
n
i
}
D = \{\frac{D_{nm}}{\sqrt{\sum^n_{i=1}D_{ni}}}\}
D={∑i=1nDniDnm}
假定
R
=
Q
K
⊤
⊙
D
R = Q K^{\top} \odot D
R=QK⊤⊙D,设置
R
=
{
R
n
m
max
(
∣
∑
i
=
1
n
R
n
i
∣
,
1
)
}
R = \{ \frac{R_{nm}}{\max(|\sum^{n}_{i=1} R_{ni}|, 1)} \}
R={max(∣∑i=1nRni∣,1)Rnm}
作者也提出了一种将上述两种形式进行混合的形式,通过将序列划分为连续的块,块内部执行并行形式的处理,块之间执行循环处理,实际的,对于第
i
i
i个块,处理形式如下:
R
e
t
e
n
t
i
o
n
(
X
[
i
]
)
=
(
Q
[
i
]
K
[
i
]
⊤
⊙
D
)
V
[
i
]
⏟
块内并行
+
(
Q
[
i
]
S
i
)
⊙
ξ
⏟
块间循环
,
ξ
i
j
=
γ
i
+
1
Retention(X_{[i]})=\underbrace{(Q_{[i]} K^{\top}_{[i]} \odot D)V_{[i]}}_{块内并行} + \underbrace{(Q_{[i]} S_i) \odot \xi}_{块间循环}, \xi_{ij} = \gamma^{i+1}
Retention(X[i])=块内并行(Q[i]K[i]⊤⊙D)V[i]+块间循环(Q[i]Si)⊙ξ,ξij=γi+1