一、常数操作:
常见固定时间的操作
1、常见算术运算+、-、*、/、
2、位运算 >>、>>>、 << 、 | 、 & 、^等
3、赋值、比较、自增、自减
4、数组寻址(可以通过计算偏移量直接获取第N位置的内容)
对比链表寻址(是没有办法直接计算得到第N位置的内容,所以它不是一个常数操作)
二、时间复杂度的概念
假设数据量为N的样本中,执行完整个流程,描述常数操作的数量关系。通常由O()表示,是一种渐进时间复杂度。
若存在函数 f(n),使得当n趋近于无穷大时,T(n)/ f(n)的极限值为不等于零的常数,则称 f(n)是T(n)的同数量级函数。
记作 T(n)= O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
T(n)为常数操作执行次数
简单理解,时间复杂度就是把T(n)简化为一个数量级,这个数量级可能为 n,n^2…
时间复杂度的推导
1.分解算法流程中的每一步直至常数操作,并进行T(n)的计算
2.只保留时间函数的最高阶项
下面利用简单选择排序进行说明:
选择排序流程:
- 0 ~ N-1 中,选择最小的数,并与第1位进行交换
- 1 ~ N-1 中,选择最小的数,并与第2位进行交换
- …
- 直到 N-1位置
分解至常数操作
- 0 ~ N-1中,查看 并进行 N-1次比较(1),将最小值放到0位置(1) 此时 进行了 N-1次比较 1次交换
- 1 ~ N-1中,查看并进行N-2次比较(1),将最少值放到1位置(1)
- …
我们可以得出总次数 是一个等差数列的求和 (N + N-1 + N-2 … + 1)=> T(n) = aN^2 + bN + C
因此得出简单选择排序时间复杂度为 O(N^2)
算法实现:
public static void insertSort(int[] arr){
if(arr == null || arr.length < 2)
return;
for(int i = 0 ; i < arr.length - 1 ; i ++){
int minIndex = i;
for(int j = i + 1 ; j <= arr.length - 1; j ++){
minIndex = arr[j] < arr[minIndex] ? j : minIndex;
}
// if(i != minIndex) {
// swap(arr, i, minIndex);
// }
swap(arr,i,minIndex);
}
}
递归函数时间复杂度估计
子规模一致
T(n) = a * T(N/b) + O(N^d)
l
o
g
b
a
<
d
=
>
O
(
N
d
)
logb^a < d => O(N^d)
logba<d=>O(Nd)
l
o
g
b
a
>
d
=
>
O
(
N
l
o
g
b
a
)
logb^a > d => O(Nlogb^a)
logba>d=>O(Nlogba)
l
o
g
b
a
=
d
=
>
(
N
d
l
o
g
N
)
logb^a = d =>(N^dlogN)
logba=d=>(NdlogN)
常见的时间复杂度量级有:
- 常数阶O(1)
- 对数阶O(logN)
- 线性阶O(n)
- 线性对数阶O(nlogN)
- 平方阶O(n²)
- 立方阶O(n³)
- K次方阶O(n^k)
- 指数阶(2^n)
评估算法优劣:
1.时间复杂度(流程决定)
2.额外空间复杂度(流程决定)
3.常数项时间
三、额外空间复杂度
完成流程,需要的额外空间。
如果是有限几个变量,O(1)
四、常见数据结构
1.单向链表
public class Node{
public T value;
public Node Next;
}

查找需要遍历时间复杂度为O(N)
插入删除某一个节点操作时间复杂度为O(1)
2.双向链表
单向链表无法知道前置节点,双向链表针对这个新增了一个前置节点的指针。
B+树的叶子节点 利用了双向链表的结构,可以方便进行范围查询
public class DoubleNode {
public T value;
public DoubleNode pre;
public DoubleNode next;
}


3.栈和队列
是逻辑结构
栈:先进后出
队列:先进先出
可以使用数组/链表实现栈和队列

如何使用数组完成一个队列结构:
public class Class01_MyListQueue {
public static class MyListQueue {
private int[] arr;
private int pushi;
private int polli;
private int size;
private final int limit;
public MyListQueue(int limit){
arr = new int[limit];
pushi = 0;
polli = 0;
size = 0;
this.limit = limit;
}
public void push(int value){
if( size == limit){
throw new RuntimeException("队列满了,无法入队");
}
size ++;
arr[pushi] = value;
pushi = nextIndex(pushi);
}
public int polli(){
if( size == 0){
throw new RuntimeException("队列为空,无法出对");
}
size --;
int result = arr[polli];
polli = nextIndex(polli);
return result;
}
public boolean isEmpty(){
return size == 0;
}
public int nextIndex(int index){
return index < limit - 1?index+1:0;
}
}
}
上述过程和Mysql的redolog的设计思想优点类似,一个指针写入(入队),一个指针擦除(出队)。

4.数组
5.Hash表,有序表
put 时间复杂度 O(1)
删除、查询key对应的value、是否包含key 时间复杂度都为O(1)
// 有序表
可以通过 红黑树、avl树、sb树、跳表实现
Redis中关于跳跃表
6.树
树是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
7.堆
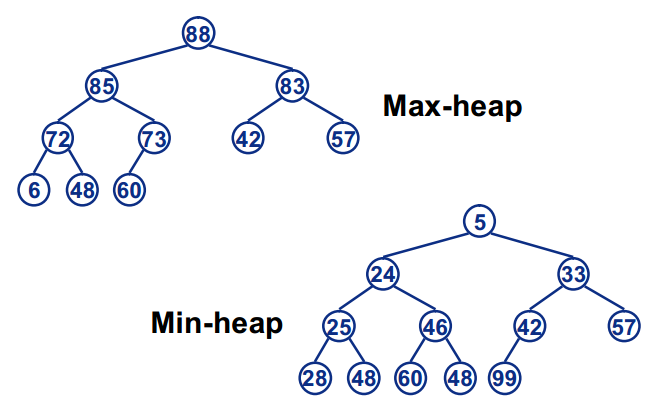
堆是一种比较特殊的数据结构,可以被看做一棵树的数组对象,具有以下的性质:堆中某个节点的值总是不大于或不小于其父节点的值;堆总是一棵完全二叉树。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。可以用堆来做TopN的计算
8.图
https://blog.csdn.net/yjw123456/article/details/90211563
常见数据结构的时间复杂度分析:
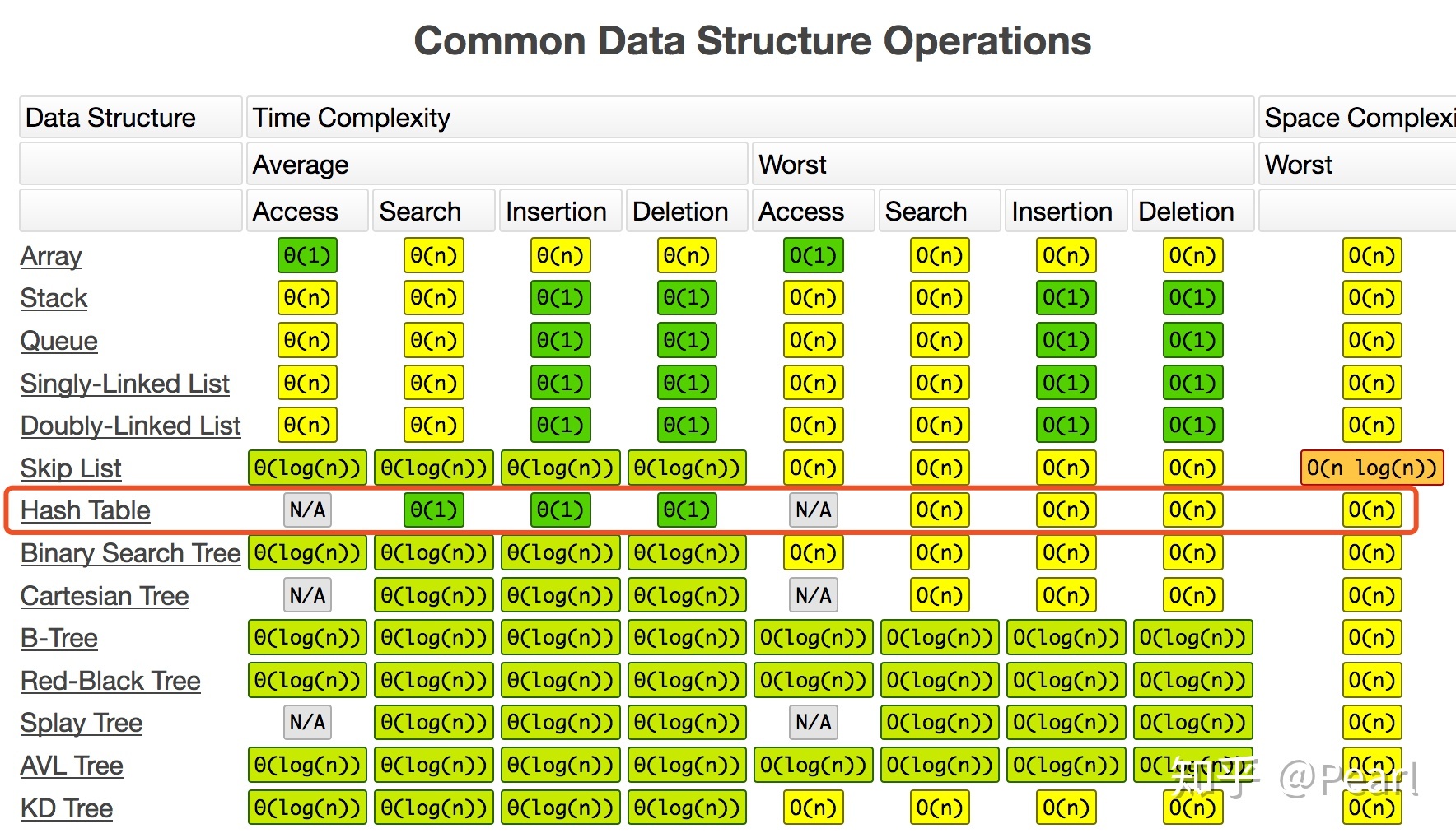
https://www.bigocheatsheet.com/