索引简介
索引(Index)可以用于提高数据库的查询性能;但是索引也需要进行读写,同时还会占用
更多的存储空间;因此了解并适当利用索引对于数据库的优化至关重要。本篇我们就来介绍如何
高效地使用 PostgreSQL 索引。
-- 创建表
CREATE TABLE test (
id integer,
name text
);
-- generate_series 产生序列
INSERT INTO test
SELECT v,'val:'||v FROM generate_series(1, 10000000) v;
SELECT name FROM test WHERE id = 10000;
如果没有索引,数据库需要扫描整个表才能找到相应的数据。利用 EXPLAIN 命令可以看到
数据库的执行计划,也就是 PostgreSQL 执行 SQL 语句的具体步骤
执行计划参考文档
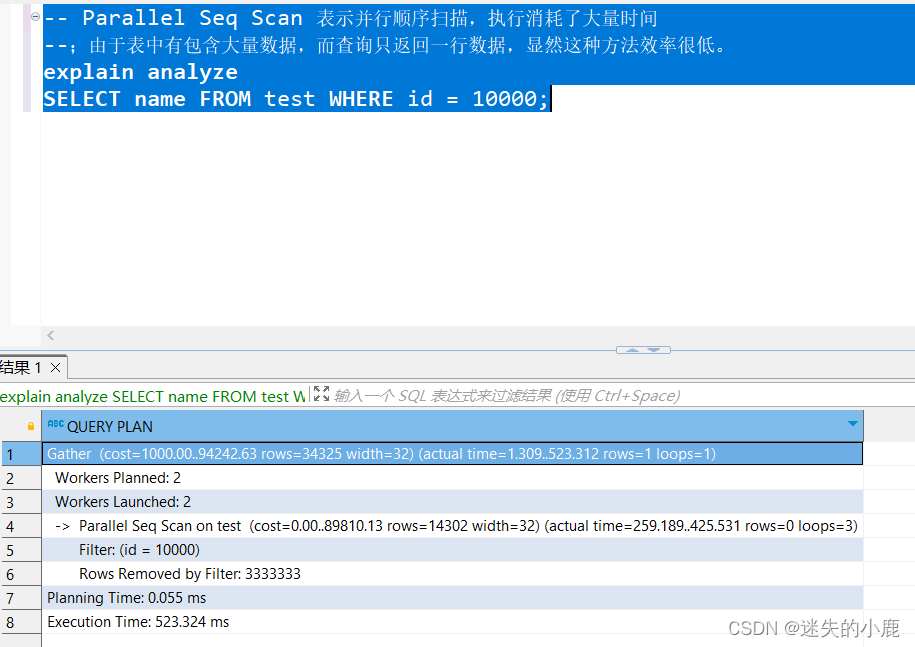
-- Parallel Seq Scan 表示并行顺序扫描,执行消耗了大量时间
--;由于表中有包含大量数据,而查询只返回一行数据,显然这种方法效率很低。
explain analyze
SELECT name FROM test WHERE id = 10000;
--如果在 id 列上存在索引,则可以通过索引快速找到匹配的结果。我们先创建一个索引:
CREATE INDEX test_id_index ON test (id);
-- 创建索引之后,再次查看数据库的执行计划
explain analyze
SELECT name FROM test WHERE id = 10000;
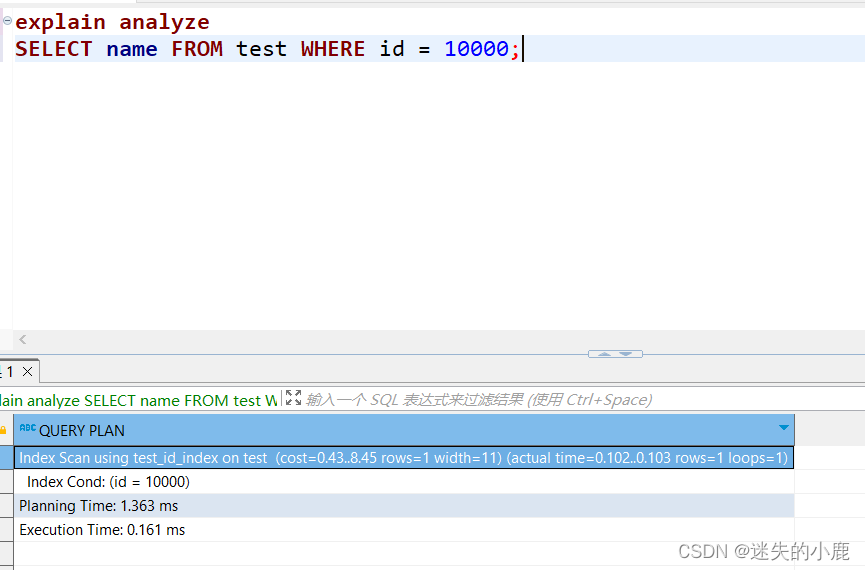
Index Scan 表示索引扫描,执行消耗了 1.3ms;这种方式类似于图书最后的关键字索引,读
者可以相对快速地浏览索引并翻到适当的页面,而不必阅读整本书来找到感兴趣的内容。
索引不仅仅能够优化查询语句,某些包含 WHERE 条件的 UPDATE、DELETE 语句也可以
利用索引提高性能,因为修改数据的前提是找到数据。
此外,索引也可以用于优化连接查询,基于连接条件中的字段创建索引可以提高连接查询的
性能。索引甚至还能优化分组或者排序操作,因为索引自身是按照顺序进行组织存储的。
另一方面,系统维护索引需要付出一定的代价,从而增加数据修改操作的负担。所以,我们
需要合理创建索引,一般只为经常使用到的字段创建索引。就像图书一样,不可能为书中的每个
关键字都创建一个索引
索引类型
PostgreSQL 提高了多种索引类型:B-树、哈希、GiST、SP-GiST、GIN 以及 BRIN 索引。每
种索引基于不同的存储结构和算法,用于优化不同类型的查询。默认情况下,PostgreSQL 创建
B-树索引,因为它适合大部分情况下的查询
B-树索引
B-树是一个自平衡树(self-balancing tree),按照顺序存储数据,支持对数时间复杂度(O(logN))
的搜索、插入、删除和顺序访问。
对于索引列上的以下比较运算符,PostgreSQL 优化器都会考虑使用 B-树索引:
• <
• <=
• =
• >=
• BETWEEN
• IN
• IS NULL
• IS NOT NULL
另外,如果模式匹配运算符 LIKE 和~中模式的开头不是通配符,优化器也可以使用 B-树索
引,例如:
col LIKE 'foo%'
col ~ '^foo'
对于不区分大小的的 ILIKE 和~*运算符,如果匹配的模式以非字母的字符(不受大小写转
换影响)开头,也可以使用 B-树索引。
B-树索引还可以用于优化排序操作,例如:
SELECT col1, col2
FROM t
WHERE col1 BETWEEN 100 AND 200
ORDER BY col1;
col1 上的索引不仅能够优化查询条件,也可以避免额外的排序操作;因为基于该索引访问时
本身就是按照排序返回结果
哈希索引
哈希索引(Hash index)只能用于简单的等值查找(=),也就是说索引字段被用于等号条
件判断。因为对数据进行哈希运算之后不再保留原来的大小关系。
创建哈希索引需要使用 HASH 关键字:
-- CREATE INDEX 语句用于创建索引,USING 子句指定索引的类型
CREATE INDEX index_name
ON table_name USING HASH (column_name);
GiST 索引
GiST 代表通用搜索树(Generalized Search Tree),GiST 索引单个索引类型,而是一种支持
不同索引策略的框架。GiST 索引常见的用途包括几何数据的索引和全文搜索。GiST 索引也可以
用于优化“最近邻”搜索,例如
-- 该语句用于查找距离某个目标地点最近的 10 个地方。
SELECT *
FROM places
ORDER BY location <-> point '(101,456)'
LIMIT 10;
SP-GiST 索引
SP-GiST 代表空间分区 GiST,主要用于 GIS、多媒体、电话路由以及 IP 路由等数据的索引。
与 GiST 类似,SP-GiST 也支持“最近邻”搜索
GIN 索引
GIN 代表广义倒排索引(generalized inverted indexes),主要用于单个字段中包含多个值的
数据,例如 hstore、array、jsonb 以及 range 数据类型。一个倒排索引为每个元素值都创建一个单
独的索引项,可以有效地查询某个特定元素值是否存在。Google、百度这种搜索引擎利用的就是
倒排索引。
BRIN 索引
BRIN 代表块区间索引(block range indexes),存储了连续物理范围区间内的数据摘要信息。
BRIN 也相比 B-树索引要小很多,维护也更容易。对于不进行水平分区就无法使用 B-树索引的
超大型表,可以考虑 BRIN。
BRIN 通常用于具有线性排序顺序的字段,例如订单表的创建日期
postgresql官网关于索引的介绍
创建索引
PostgreSQL 使用 CREATE INDEX 语句创建新的索引:
CREATE INDEX index_name ON table_name
[USING method]
(column_name [ASC | DESC] [NULLS FIRST | NULLS LAST]);
index_name 是索引的名称,table_name 是表的名称;
• method 表示索引的类型,例如 btree、hash、gist、spgist、gin 或者 brin。默认为 btree;
• column_name 是字段名,ASC 表示升序排序(默认值),DESC 表示降序索引;
• NULLS FIRST 和 NULLS LAST 表示索引中空值的排列顺序,升序索引时默认为 NULLS
LAST,降序索引时默认为 NULLS FIRST。

唯一索引
在创建索引时,可以使用 UNIQUE 关键字指定唯一索引:
CREATE UNIQUE INDEX index_name
ON table_name (column_name [ASC | DESC] [NULLS FIRST | NULLS LAST]);
唯一索引可以用于实现唯一约束,PostgreSQL 目前只支持 B-树类型的唯一索引。多个 NULL
被看作是不同的值,因此唯一索引字段可以存在多个空值
对于主键和唯一约束,PostgreSQL 会自动创建一个唯一索引,从而确保唯一性。
多列索引
CREATE [UNIQUE] INDEX index_name ON table_name
[USING method]
(column1 [ASC | DESC] [NULLS FIRST | NULLS LAST], ...);
对于多列索引,应该将最常作为查询条件使用的字段放在左边,较少使用的字段放在右边。
例如,基于(c1, c2, c3)创建的索引可以优化以下查询:
WHERE c1 = v1 and c2 = v2 and c3 = v3;
WHERE c1 = v1 and c2 = v2;
WHERE c1 = v1;
但是以下查询无法使用该索引:
WHERE c2 = v2;
WHERE c3 = v3;
WHERE c2 = v2 and c3 = v3;
对于多列唯一索引,字段的组合值不能重复;但是如果某个字段是空值,其他字段可以出现
重复值。
函数索引
函数索引,也叫表达式索引,是指基于某个函数或者表达式的值创建的索引。PostgreSQL
中创建函数索引的语法如下
CREATE [UNIQUE] INDEX index_name
ON table_name (expression);
expression 是基于字段的表达式或者函数。
以下查询在 name 字段上使用了 upper 函数:
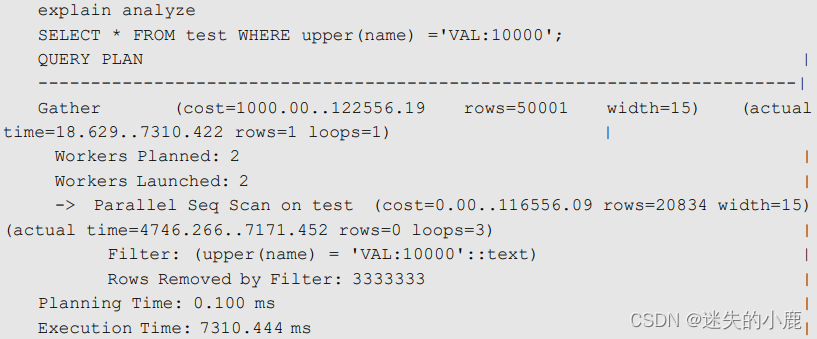
虽然 name 字段上存在索引 test_name_index,但是函数会导致优化器无法使用该索引。为了
优化这种不分区大小写的查询语句,可以基于 name 字段创建一个函数索引
drop index test_name_index;
create index test_name_index on test(upper(name));
再次查看该语句的执行计划:
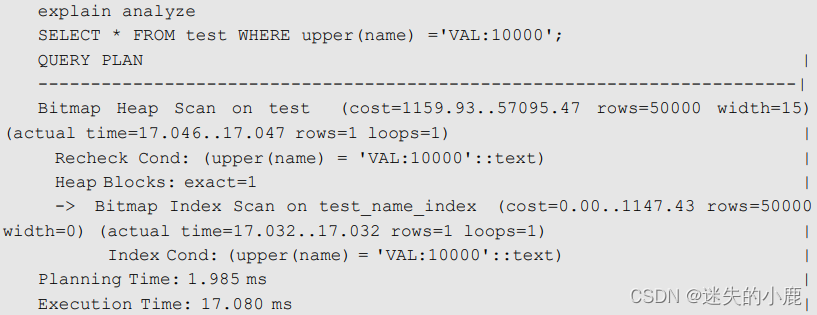
函数索引的维护成本比较高,因为插入和更新时都需要进行函数计算。
部分索引
部分索引(partial index)是只针对表中部分数据行创建的索引,通过一个 WHERE 子句指
定需要索引的行。例如,对于订单表 orders,绝大部的订单都处于完成状态;我们只需要针对未
完成的订单进行查询跟踪,可以创建一个部分索引
-- 创建表
create table orders(order_id int primary key, order_ts timestamp, finished
boolean);
-- 创建索引
create index orders_unfinished_index
on orders (order_id)
WHERE finished is not true;
该索引只包含了未完成的订单 id,比直接基于 finished 字段创建的索引小很多。它可以用于
优化未完成订单的查询:
explain analyze
select order_id
from orders
where finished is not true;

覆盖索引
PostgreSQL 中的索引都属于二级索引,意味着索引和数据是分开存储的。因此通过索引查
找数据即需要访问索引,又需要访问表,而表的访问是随机 I/O
为了解决这个性能问题,PostgreSQL 支持 Index-Only Scan,只需要访问索引的数据就能获
得需要的结果,而不需要再次访问表中的数据。例如
-- 创建表
create table t (a int, b int, c int);
-- 创建唯一索引
create unique index idx_t_ab on t using btree (a, b) include (c);
以上语句基于字段 a 和 b 创建了多列索引,同时利用 INCLUDE 在索引的叶子节点存储了字
段 c 的值。以下查询可以利用 Index-Only Scan:
explain analyze
select a, b, c
from t
where a = 100 and b = 200;
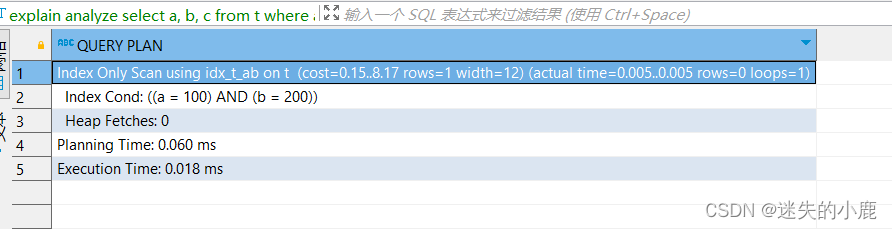
以上查询只返回索引字段(a、b)和覆盖的字段(c),可以仅通过扫描索引即可返回结果。
B-树索引支持 Index-Only Scan,GiST 和 SP-GiST 索引支持某些运算符的 Index-Only Scan,
其他索引不支持这种方式
查看索引
PostgreSQL 提供了一个关于索引的视图 pg_indexes,可以用于查看索引的信息:
-- 该视图包含的字段依次为:模式名、表名、索引名、表空间以及索引的定义语句。
select * from pg_indexes where tablename = 'test';

维护索引
PostgreSQL 提供了一些修改和重建索引的方法:
ALTER INDEX index_name RENAME TO new_name;
ALTER INDEX index_name SET TABLESPACE tablespace_name;
REINDEX [ ( VERBOSE ) ] { INDEX | TABLE | SCHEMA | DATABASE | SYSTEM } index_name;
两个 ALTER INDEX 语句分别用于重命名索引和移动索引到其他表空间;REINDEX 用于重
建索引数据,支持不同级别的索引重建
另外,索引被创建之后,系统会在修改数据的同时自动更新索引。不过,我们需要定期执行
ANALYZE 命令更新数据库的统计信息,以便优化器能够合理使用索引
删除索引
DROP INDEX index_name [ CASCADE | RESTRICT ];
CASCADE 表示级联删除其他依赖该索引的对象;RESTRICT 表示如果存在依赖于该索引 的对象,将会拒绝删除操作。默认为 RESTRICT
--可以使用以下语句删除 test 上的索引:
drop index test_id_index, test_name_index;