本文主要分享文本数据的拆分,提取合并,为下一步可视化分析做好准备。
数据来源于boss与拉勾网数据分析岗位的招聘信息。
拉勾网的爬取方法见我的:
《Python selenium+beautifulsoup 登录爬取拉勾网》
《登录爬取拉勾网2.0 Python selenium》
环境配置
# Jupyter Notebook
%matplotlib inline
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
原始数据如下:

【job_link】与【company_link】不需要,删掉
【company_describe】与【job_skills】使用jieba与wordcloud,本文不涉及。若对词云感兴趣,请见我博客:《Python jieba+wordcloud制作词云》
本文主要展示【experience】与【city】这两列的处理方法,其他列大同小异,不再赘述。
数据准备
bs=pd.read_csv('boss.csv',encoding='gbk')
lg=pd.read_csv('lagou.csv',encoding='gbk')
#合并数据,查看是否存在缺失值
all_data=pd.concat([bs,lg],ignore_index=True)
all_data.info()
#删除掉不需要的信息
del all_data['job_link']
del all_data['company_link']
#填充缺失值
all_data['company_describe']=all_data['company_describe'].fillna('暂无')
experience列的处理
这一列的文本其实是杂糅了经验及学历要求。但是如果只观察前几列,很容易忽略了一些异常数据。
使用【all_data.tail( )】观察发现有的数据是【\n10k-20k\n经验1-3年 / 本科\n】,呈现【薪资+经验+学历】这种形态,这需要我们将其分割处理成【经验+学历】,统一这一列的数据形式。
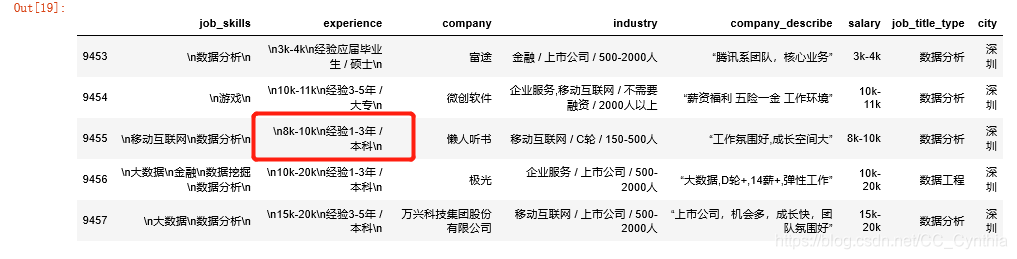
split的使用
pandas中使用split需要先将需要split的数据集转化为字符串。split( a,b)中的第一个参数【a】代表以某字符串作为分割点,第二个参数【b】代表分割次数,即分成【b+1】个元素。分割完成后会返回一个列表。提取列表中元素必须再次转化为字符串来进行。
#新建一列“e1”用来装切割好的,形式为“经验+学历”的文本
all_data['e1']=all_data.experience.str.split("k",2).str[2]
拆开来看,以字符串‘k’作为分割点,数据被分为了2类:不含有薪资的只有1个元素k的列表;含有薪资的有3个元素的列表。选取该列中所有列表的第三个元素,只有一个元素的列表会在【‘e1’】列中显示为NaN,而另一类就是我们想要的信息。

此时提取出来的【‘e1’】列存在很多的NaN:
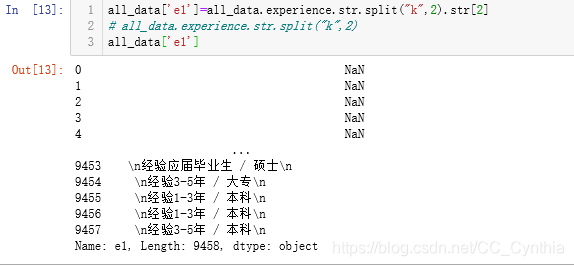
fillna填充数据
以experience列的数据填充e1列的NaN数据,最终实现整列数据统一为【经验+学历】的形式。
all_data['e1']=all_data['e1'].fillna(all_data.experience)
all_data.tail(10)
处理好的e1为这个样子:
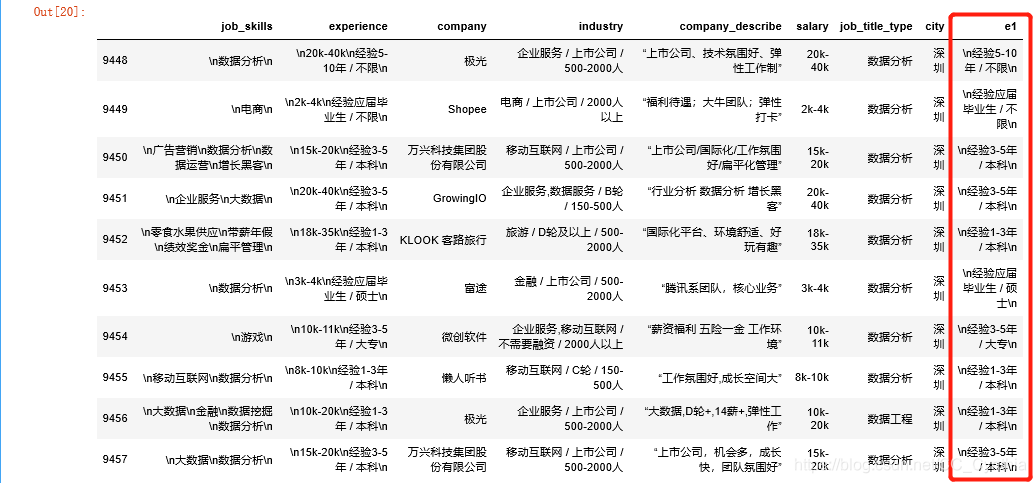
extract+正则表达
当文本数据出现字母与数字混合的这种形式就需要我们使用str.extract+正则表达式来进行提取。参数【expand=Fales】代表返回dataframe数据,若为True即为数据框。
extract中的正则表达式需要用引号包住
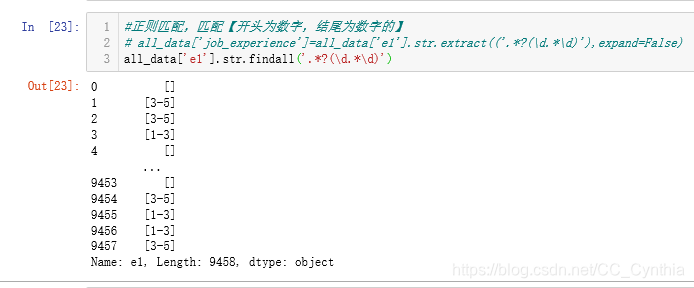
#正则匹配,匹配【开头为数字,结尾为数字的】
all_data['job_experience']=all_data['e1'].str.extract(('.*?(\d.*\d)'),expand=False)

findall 多条件匹配
上面的处理结果显示,有NaN存在,这是因为有的经验类别为【应届毕业生】,【不限】,【1年以下】。
findall与extract最直观的区别有二:findall会匹配多次,所有符合条件的元素返回一个group,而extract只匹配一次,直接返回数值;findall可以多条件匹配,而extract不可以。
例如,与上面同一个例子,函数换为extract( ),得到的是列表,见下图。
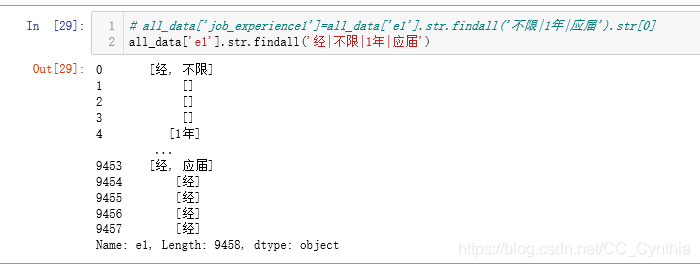
findall的多条件匹配,条件使用【“ ”】双引号包住,条件之间使用【|】隔开,匹配多次成功就会出现多个元素。
all_data['e1'].str.findall('经|不限|1年|应届')
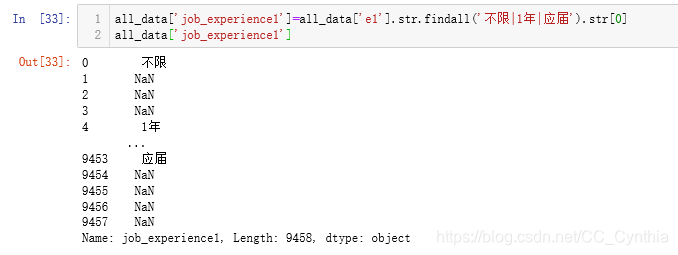
当然,我们不需要这么做。
all_data['job_experience1']=all_data['e1'].str.findall('不限|1年|应届').str[0]
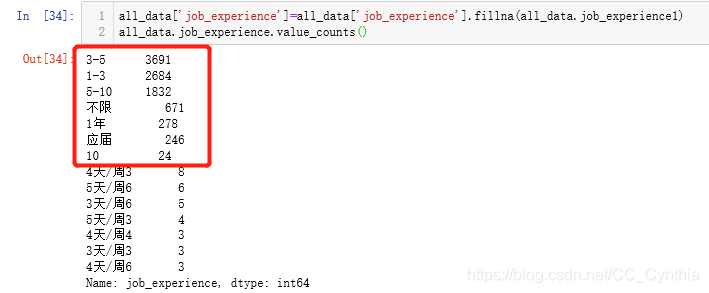
跟上面的fillna的例子相同
all_data['job_experience']=all_data['job_experience'].fillna(all_data.job_experience1)
all_data.job_experience.value_counts()
使用loc[ ]替换(一)
从上面的标签来看,表达得不够完整,我们使用loc[ ]来替换掉内容。
df.loc[df [‘需要替换的列名’] ==‘被替换的内容’,‘替换好以后存在那一列名下’] = ‘替换成的内容’
all_data.loc[all_data['job_experience']=='1年','job_experience']='1年以下'
all_data.loc[all_data['job_experience']=='应届','job_experience']='1年以下'
all_data.loc[all_data['job_experience']=='3-5','job_experience']='3-5年'
all_data.loc[all_data['job_experience']=='1-3','job_experience']='1-3年'
all_data.loc[all_data['job_experience']=='5-10','job_experience']='5-10年'
all_data.loc[all_data['job_experience']=='10','job_experience']='10年以上'
all_data.job_experience.value_counts()

替换当然不局限于原来的那一列,后文在以城市列为例。
删除筛选出来的数据
可以看出来,有奇怪的数据混进来了,应该是临时工或者兼职,删掉。
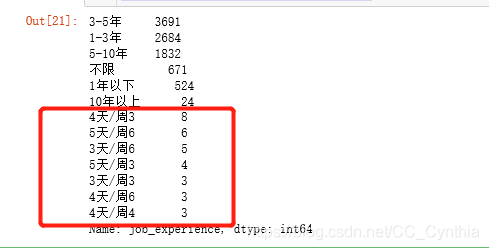
#删除job_experience列中带“/”的文本
all_data=all_data.drop(all_data[all_data['job_experience'].str.contains('/')].index)
这条代码一共三层,从里到外的含义分别是:
选取all_data里【job_experience】这一列中含有【/】的数据;
all_data[ ].index是得到所需数据的索引;
使用all_data.drop( )删除数据
最后,分离学历
degree='大专|本科|硕士|博士'
all_data['degree']=(all_data['e1'].str.findall(degree).str[0])
all_data['degree']=all_data['degree'].fillna('不限')
del all_data['e1']
del all_data['experience']
del all_data['job_experience1']

city 列的处理
先观察一下:
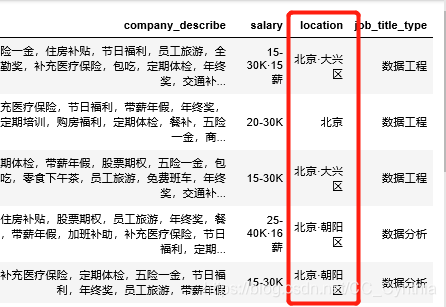
contains与loc[ ]提换(二)
我爬取的城市为北上广深,但原始数据多了区,需要替换,这里展示使用contains( )与loc替换的另一种方法。
使用contains之前需要先转化数据为字符串。contains会返回布尔值,含有所需寻找的字符串的数据为True。
这个方法可以大繁化简,锁定一些列中的特殊符号,比如上文使用的删除方法。
all_data.location.str.contains('北京')
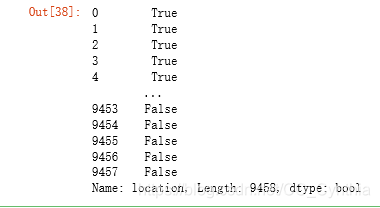
all_data['bj']=all_data.location.str.contains('北京')
all_data['sh']=all_data.location.str.contains('上海')
all_data['gz']=all_data.location.str.contains('广州')
all_data['sz']=all_data.location.str.contains('深圳')
all_data.loc[all_data['bj']==True,'city']='北京'
all_data.loc[all_data['sh']==True,'city']='上海'
all_data.loc[all_data['gz']==True,'city']='广州'
all_data.loc[all_data['sz']==True,'city']='深圳'
#删除多余的数据
del all_data['bj']
del all_data['sh']
del all_data['sz']
del all_data['gz']
del all_data['location']
可以看到这里的loc[ ] 选取的数据是【bj】这一列的,但替换的却是【city】这一列的。
完