文章目录
- 前言
- 一、安装依赖环境
- 二、导入依赖包
- 三、导入数据集
-
- 四、处理丢失数据
-
- 五、解析分类数据
-
- 六、拆分数据集为训练集合和测试集合
- 七、特征缩放
- 总结
前言


一、安装依赖环境
开始之前,要确保Anaconda、Python和sklearn已经成功安装在你的电脑上,具体可以参照上一期教程。
二、导入依赖包
使用import导入我们安装的几个依赖包:
import numpy as np #导入numpy包,简写为np
import pandas as pd #导入pandas包,简写为pd
三、导入数据集
这一步将通过pandas导入我们的数据集,请注意数据集文件要在运行python的当前目录下:
dataset = pd.read_csv('Day 1 Data.csv') #读取csv文件
X = dataset.iloc[ : , :-1].values # 选择X数据集是第几行第几列 .iloc[行,列]
Y = dataset.iloc[ : , 3].values # : 表示全部行 or 列;[a]第a行 or 列
print("Step 2: Importing dataset")
print("X")
print(X)
print("Y")
print(Y)
保姆级操作演示:
1、打开spyder,设置默认的工作路径(也就是你的数据集存在在哪里),比如我的就是:E:\ML\100-Days-Of-ML-Code-master\datasets。
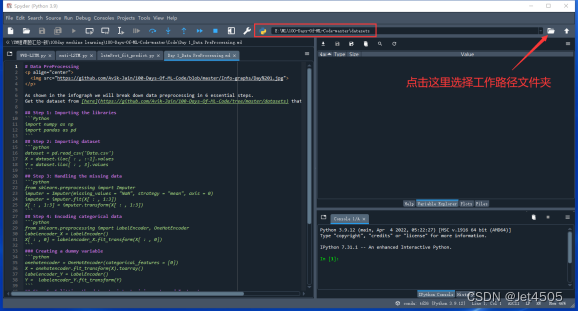
2、输入代码dataset = pd.read_csv(‘Day 1 Data.csv’)读取csv文件数据,按F9逐步运行每一行,导入数据,导入的数据叫做dataset。
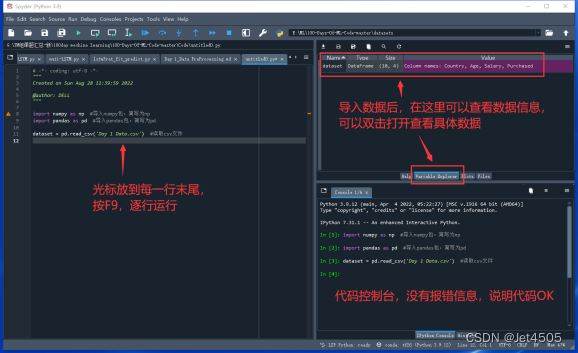

3、接下来要选择X和Y,也就是自变量和应变量;在这个例子中,X是前三列(Country、Age、Salary),Y是最后一列或者说第四列(Purchased)。
我们来看代码:X = dataset.iloc[ : , :-1].values。iloc是一个函数,功能是根据标签的所在位置,从0开始计数,先选取行再选取列。比如dataset.iloc[1,1]就是取第二行,第二列,也就是27(python的行从0开始计数)。
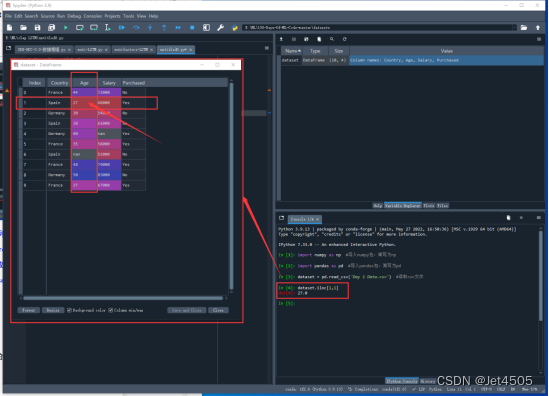
现在X是前三列,准确来说是第一列(python的第0列)到第三列(python的第2列),每一列要所有的行,代码就是dataset.iloc[:,0:2],其中,0:2表示第一列到第三列(python从0开始计数),单独一个:表示所有行。运行发现有问题,怎么第三列(python的第2列)没有读取?当我们使用dataset.iloc[:,0:3],第三列(python的第2列)出来了。看出端倪来了么?这个[:,0:n]中的n是不算的,只读取到第n-1列,这样是不是清晰了。
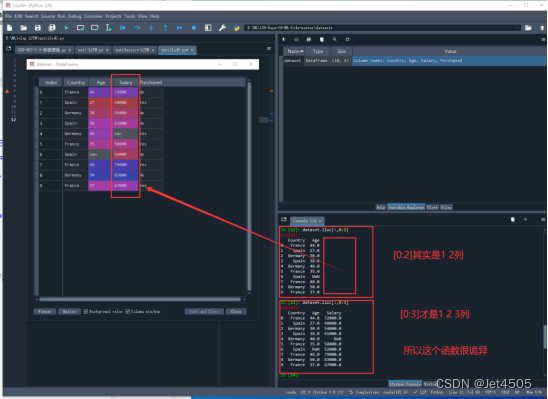
有同学发现了吧,代码怎么是dataset.iloc[ : , :-1]。在这个例子中,dataset.iloc[ : , :-1]和dataset.iloc[:,0:3]是等效的, :-1表示从第一列(python的第0列)到倒数第二列(python的第二列),至于这个-1嘛,就是从右往左数第一列(python从右往左又是从1开始计数,根据上面提到的n-1原则,此时python只读取到倒数第二列,也就是-2列)。没错!那个0是可以省略的。在这个例子中,倒数第二列不就是正数第三列(python的第二列)么。综上,dataset.iloc[ : , :-1] = dataset.iloc[ : , :3] = dataset.iloc[ : , 0:3],到这里迷糊了吧,不清楚就一个一个做测试就好。最后,加上一个.values ,转化成python认的数值型,最后在赋值到X和Y,进行后续的运算。
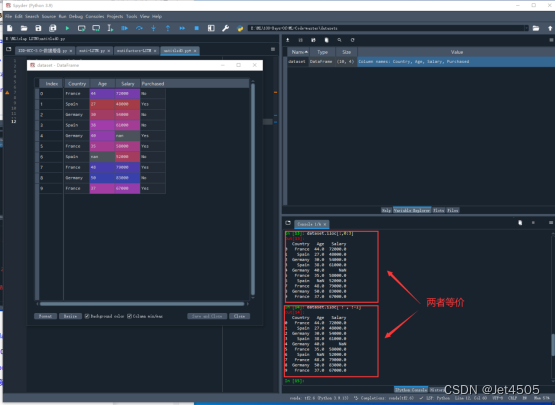
最后就是打印了,print(“Step 2: Importing dataset”)、print(“X”)这种带有双引号的,说明打印的是双引号包含的文字,属于字符型;而print(X)、print(Y)属于打印具体的内容,X和Y不就是我们之前划分出来的自变量和应变量么。
四、处理丢失数据
使用sklearn的内置方法Imputer,可以将丢失的数据用特定的方法补全。
这里我们使用整列的平均值来替换:
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan,strategy='mean')
X[:,1:3] = imputer.fit_transform(X[:,1:3])
print("---------------------")
print("Step 3: Handling the missing data")
print("step2")
print("X")
print(X)
保姆级操作演示
1、1、from sklearn.impute import SimpleImputer,这一类from XXX import XXX是常用的语句,表示的是从sklearn这个大函数包,里面的impute这个小函数包,调用具体的函数,SimpleImputer。看出来了吧,这三个函数是逐一被包含的。简单介绍一下python包的构成,python的包都安装在site-packages中,sklearn包就是site-packages下的子文件夹,同理,impute是sklearn下的一个子文件夹,打开impute下的__init__.py文件,就可以看到SimpleImputer了。
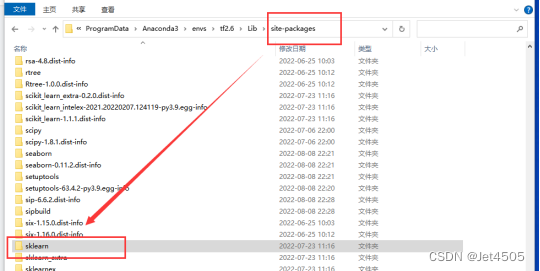
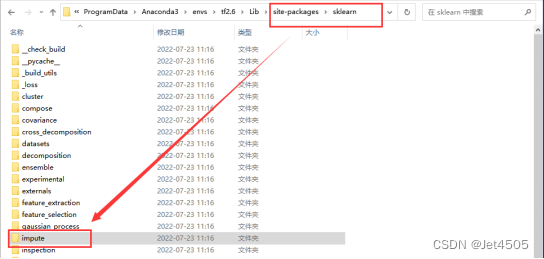
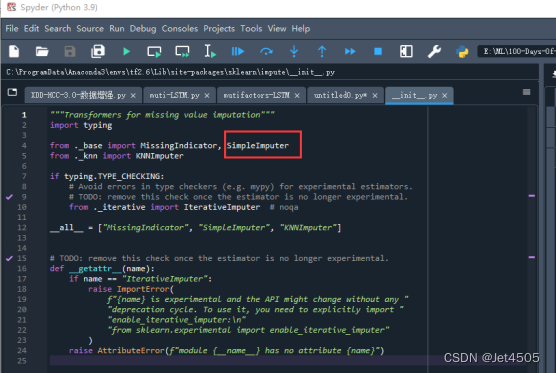
说这么多,就是为了让大家了解python包的调用逻辑,因为随着版本更新,不少包或者函数会有位置变动,这时候就需要根据位置来重新修改调用语句。
SimpleImputer参数详解:
class sklearn.impute.SimpleImputer(*, missing_values=nan, strategy=‘mean’, fill_value=None, verbose=0, copy=True, add_indicator=False)
参数含义:
missing_values:int, float, str, (默认)np.nan或是None, 即缺失值是什么。
strategy:空值填充的策略,共四种选择(默认)mean、median、most_frequent、constant。mean表示该列的缺失值由该列的均值填充。median为中位数,most_frequent为众数。constant表示将空值填充为自定义的值,但这个自定义的值要通过fill_value来定义。
常用方法:还需配合fit_transform(X)使用:
imputer = SimpleImputer(missing_values=np.nan,strategy=‘mean’)
X[:,1:3] = imputer.fit_transform(X[:,1:3])
这里只需要对X的第二列和第三列做缺失值处理X[:,1:3]
五、解析分类数据
从第3步的输出结果中我们可以看到分类数据Y中有很多"Yes"/“No"之类的字符标签,X中有很多国家的字符名称比如"France” , “Spain”,这些字符Python是不认识的,因此需要将其解析成数字:
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
onehotencoder = ColumnTransformer([('encoder', OneHotEncoder(), [0])], remainder='passthrough')
X = onehotencoder.fit_transform(X)
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
print("---------------------")
print("Step 4: Encoding categorical data")
print("X")
print(X)
print("Y")
print(Y)
保姆级操作演示
1、标签编码(LabelEncoder)知识点解析:
顾名思义,将红,蓝,绿转化为0,1,2就是标签编码,将转换成连续的数值型变量。即是对不连续的数字或者文本进行编号。
2、独热编码(OneHotEncoder)知识点解析:
对于离散型数据,比如一个特征为颜色,他一共有三个值,分别为红,蓝,绿,按照正常想法,我们可能认为,令红色=0,蓝色=1,绿色=2,这样对数据进行了编码,但是,如果把这些数据放到需要计算距离的或者其他模型中,模型会认为重要性是绿色>蓝色>红色。但这并不是我们的让机器学习的本意,只是想让机器区分它们,并无大小比较之意。所以这时标签编码是不够的,需要进一步转换。我们可以设置,这个特征有三个取值,我们可以设置三列,分别是红,蓝,绿,对于红色,它的取值是1,0,0,对于蓝色,它的取值是0,1,0,而对于绿色,它的取值是0,0,1。如此一来每两个向量之间的距离都是根号2,在向量空间距离都相等,所以这样不会出现偏序性,基本不会影响基于向量空间度量算法的效果。
3、ColumnTransformer()函数知识点解析:
ColumnTransformer()在Python的机器学习库scikit-learn中,可以选择地进行数据转换。要使用ColumnTransformer,必须指定一个转换器列表。每个转换器是一个三元素元组,用于定义转换器的名称,要应用的转换以及要应用于其的列索引,例如:(名称,对象,列)。
六、拆分数据集为训练集合和测试集合
我们知道,为了让机器学习到分类的特征,我们需要先“训练”机器,这时候就需要训练集。训练结束后需要测试刚训练得到的模型的效果,因此又需要测试集。
为了实现这个目的,将刚获得的数据集进行拆分,其中20%为测试集,80%为训练集。使用sklearn的train_test_split可以很容易做到:
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
七、特征缩放
如第5步的结果显示,数据集中存在一些值比如[4000, 6000, 10000, 100], 这样会导致一个问题:越大的值,权重越大,但实际上不论这个值多大,它的权重都应该是相同的,这时候就需要引入StandardScaler进行数据标准化了:
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
总结
做完数据上述步骤后,就可以进行模型的训练了。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)