所需软件
Linux所需软件包括:
- JavaTM1.5.x,必须安装,建议选择Sun公司发行的Java版本(以前安装过)。
- ssh 必须安装并且保证 sshd一直运行,以便用Hadoop 脚本管理远端Hadoop守护进程。(一般默认CentOS已经安装了OpenSSH,即使你是最小化安装也是如此,所以不用安装。)
为了能够方便复制,主要是vmware tools时灵时不灵的情况(主要是Install 的时候不方便),我这里使用XShell。
集群网络配置
本文中的集群网络环境配置如下:
master内网IP:192.168.235.131
slave1内网IP:192.168235.132
slave2内网IP:192.168.235.133
另外主机和虚拟机Ping不通的原因如下:
https://blog.csdn.net/qqxyy99/article/details/80864862
克隆虚拟机的问题,克隆后需要先修改mac地址,再开机修改ip。否则很麻烦,别问我怎么知道的,不然这篇文章在昨天就更了。
通过虚拟机文件复制,在VMware改名快速创建slave1和slave2后,可能会产生网卡MAC地址重复的问题,需要在VMware网卡设置中重新生成MAC,在虚拟机复制后需要更改内网网卡的IP。
集群SSH免密登陆设置
目的:创建一个可以ssh免密登陆的集群
为了不直接使用IP,可以通过设置hosts文件达到ssh slave1这样的的效果(三个节点设置相同)
$sudo vim /etc/hosts
在文件尾部添加如下行,保存后退出:
192.168.235.131 master
192.168.235.132 slave1
192.168.235.133 slave2
centos7默认的hostname是localhost,为了方便将每个节点hostname分别修改为master、slave1、slave2(以下以master节点为例)。
$sudo hostnamectl set-hostname master
重启terminal,然后查看:$hostname

设置master节点和两个slave节点之间的双向ssh免密通信,下面以master节点ssh免密登陆slave节点设置为例,进行ssh设置介绍(以下操作均在master机器上操作):
首先生成master的rsa密钥:$ssh-keygen -t rsa
设置全部采用默认值进行回车
将生成的rsa追加写入授权文件:$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
给授权文件权限:$chmod 600 ~/.ssh/authorized_keys
进行本机ssh测试:$ssh master正常免密登陆后所有的ssh第一次都需要密码,此后都不需要密码
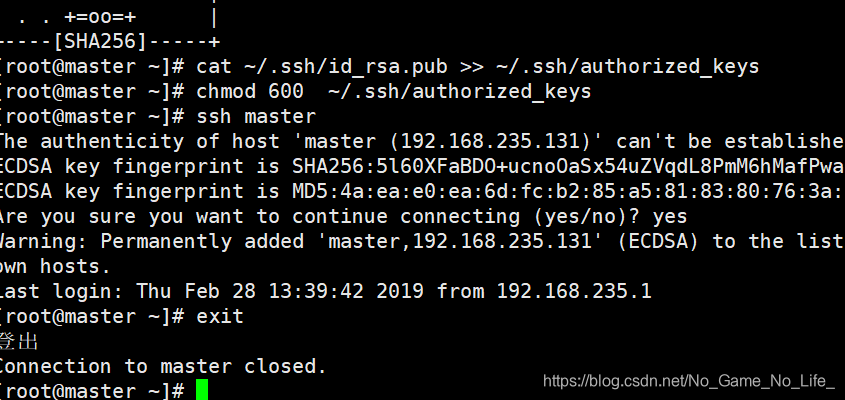
将master上的authorized_keys传到slave1
sudo scp ~/.ssh/id_rsa.pub root@slave1:~/
登陆到slave1操作:$ssh slave1输入密码登陆
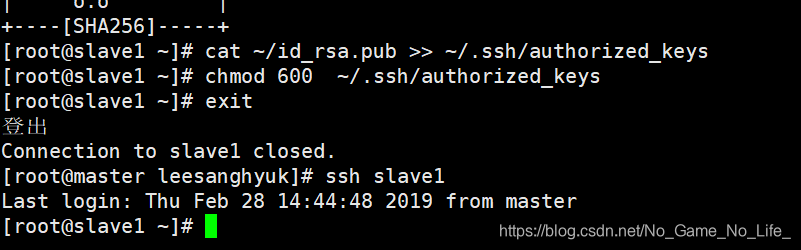
$cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
如果slave上没有这个文件夹,最好先执行一遍$ssh-keygen -t rsa
修改authorized_keys权限:$chmod 600 ~/.ssh/authorized_keys
退出slave1:$exit
进行免密ssh登陆测试:$ssh slave1
Hadoop安装配置
目的:获得正确配置的完全分布式Hadoop集群(以下操作均在master主机下操作)
安装前三台节点都需要需要关闭防火墙和selinux:
$sudo systemctl stop firewalld.service
$sudo systemctl disable firewalld.service

将SELinux status参数设定为关闭状态:
$sudo vim /usr/sbin/sestatus
SELinux status: disabled
首先在master节点进行hadoop安装配置,之后使用scp传到slave1和slave2。
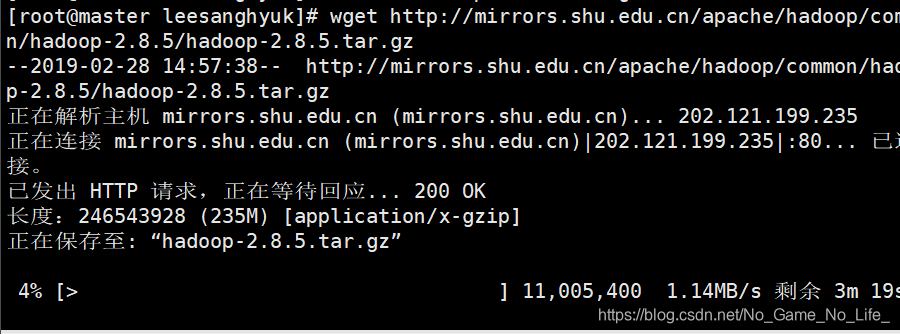
下载Hadoop 二进制源码 至master,我们这里使用wget下载如下地址。
http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
好了,安装后解压。
$tar -zxvf hadoop-2.8.5.tar.gz
配置hadoop的配置文件core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves(都在~/hadoop-2.8.5/etc/hadoop文件夹下)
$cd ~/hadoop/etc/hadoop
$vim core-site.xml其他文件相同,以下为配置文件内容:
1.core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/leesanghyuk/hadoop-2.8.5/hadoop/tmp</value>
</property>
</configuration>
2.hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/leesanghyuk/hadoop-2.8.5/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/leesanghyuk/hadoop-2.8.5/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
</configuration>
3.mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
5.slaves
slave1
slave2
6.hadoop-env.sh
export JAVA_HOME=/home/Java/jdk1.6

此步骤的所有操作仍然是在master节点上操作,以master节点在slave1节点上配置为例:
复制hadoop文件至slave1:$scp -r ~/hadoop root@slave1:~/
然后,复制到slave2。
配置环境变量,修改vi /etc/profile文件使其永久性生效,添加行(每个节点都需要此步操作,以master节点为例):
#hadoop environment vars
export HADOOP_HOME=/home/leesanghyuk/hadoop-2.8.5
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
执行 命令source /etc/profile或 执行点命令./profile使其修改生效,执行完可通过echo $PATH命令查看是否添加成功。
格式化namenode:$hadoop namenode -format
启动hadoop:$start-all.sh
云服务器启动不成功解决方案:https://blog.csdn.net/dongdong9223/article/details/81255713
master节点查看启动情况:$jps

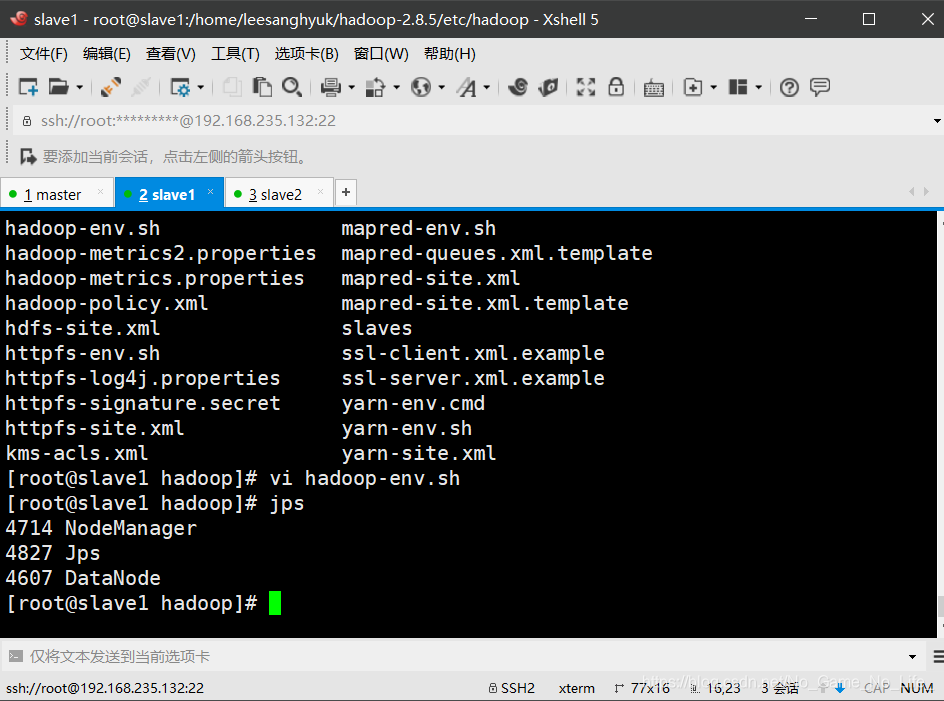
目的:验证当前hadoop集群正确安装配置
本次测试用例为利用MapReduce实现wordcount程序
生成文件testWordCount:$echo "My name is LeesangHyuk. This is a example program called WordCount, run by LeesangHyuk " >> testWordCount
创建hadoop文件夹wordCountInput:$hadoop fs -mkdir /wordCountInput
将文件testWordCount上传至wordCountInput文件夹:$hadoop fs -put testWordCount /wordCountInput
执行wordcount程序,并将结果放入wordCountOutput文件夹:$hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /wordCountInput /wordCountOutput
注意事项:/wordCountOutput文件夹必须是没有创建过的文件夹
查看生成文件夹下的文件:$hadoop fs -ls /wordCountOutput

在output/part-r-00000可以看到程序执行结果:$hadoop fs -cat /wordCountOutpart-r-00000