1. 什么是选择排序?(摘抄自百度百科)
选择排序(Selection sort)是一种简单直观的排序算法。
它的工作原理是:
第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。
以此类推,直到全部待排序的数据元素的个数为零。
选择排序是不稳定的排序方法。
2.选择排序算法实现(摘抄自百度百科(C语言版伪代码))
void selectionsort(int n, keytype S[])
{
index i, j, smallest;
for (i = 1; i <= n - 1; i++) {
smallest = i;
for (j = i + 1; j <= n; j++)
if (S[j] < S[smallest])
smallest = j;
exchange S[i] and S[smallest];
}
}
下面进行讲解上面的程序:
1. 定义索引变量:i(外循环索引变量),j(内循环索引变量),smallest(最小值索引变量)
2. 通过for进行数组的外循环,遍历次数为整个数组的长度
3. 初始化最小值索引变量(smallest)为当前外循环索引值(i)
4. 通过for进行数组的内循环,起始索引为当前外循环索引值
5. 比较内循环索引变量(j)和最小值索引变量(smallest)的数值元素的值,选出最小值的索引,然后保存索引到最小值索引变量(smallest)
6. 每次内循环结束后,将最小值索引(smallest)和当前外循环索引(i)的元素进行交换,确保当前外循环索引(i)后面的元素都比自身小
动画解释

图解:
第一次循环
当前外循环索引(i)为0
初始化最小值索引(smallest)为当前外循环索引(i) 为 0
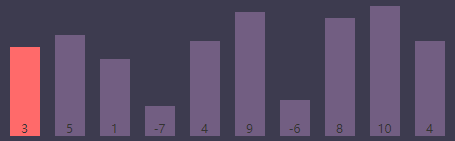
进入内循环,内循环索引(j)为当前外循环索引(i) + 1,当前内循环索引为 i + 1 => 0 + 1 => 1
内循环索引(j)为1, 最小值索引(smallest)为0
进行条件判断,if (S[j] < S[smallest]) => if (S[j(1)] < S[smallest(0)]) => if (5 < 3),条件为 false,继续执行
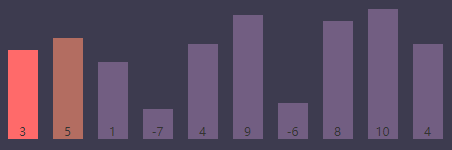
内循环索引(j)为2, 最小值索引(smallest)为0
进行条件判断,if (S[j] < S[smallest]) => if (S[j(2)] < S[smallest(0)]) => if (1 < 3),条件为 true,执行索引交换
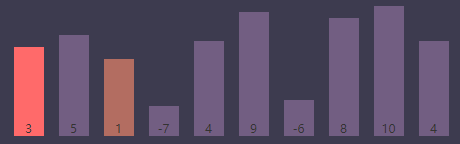
交换后,最小值索引(smallest)为当前内循环索引(j),最小值索引(smallest)为2
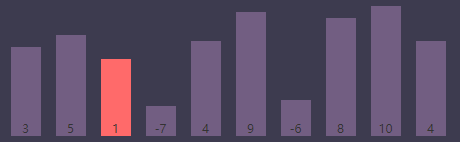
内循环索引(j)为3, 最小值索引(smallest)为2
进行条件判断,if (S[j] < S[smallest]) => if (S[j(3)] < S[smallest(2)]) => if (-7 < 1),条件为 true,执行索引交换
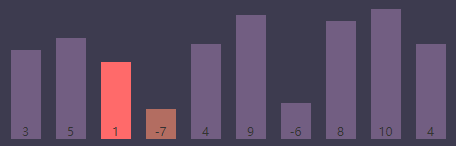
交换后,最小值索引(smallest)为当前内循环索引(j),最小值索引(smallest)为3
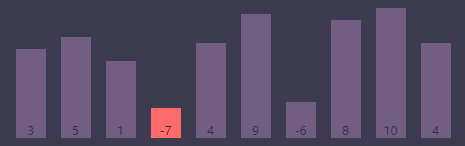
内循环索引(j)为4, 最小值索引(smallest)为3
进行条件判断,if (S[j] < S[smallest]) => if (S[j(4)] < S[smallest(3)]) => if (4 < -7),条件为 false,继续执行
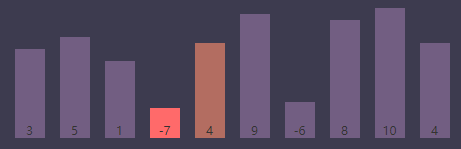
内循环索引(j)为5, 最小值索引(smallest)为3
进行条件判断,if (S[j] < S[smallest]) => if (S[j(5)] < S[smallest(3)]) => if (9 < -7),条件为 false,继续执行
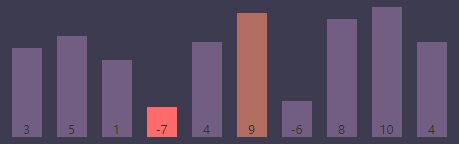
内循环索引(j)为6, 最小值索引(smallest)为3
进行条件判断,if (S[j] < S[smallest]) => if (S[j(6)] < S[smallest(3)]) => if (-6 < -7),条件为 false,继续执行
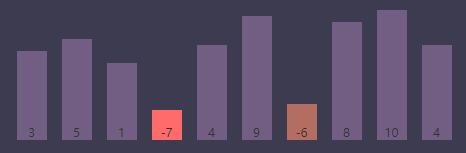
内循环索引(j)为7, 最小值索引(smallest)为3
进行条件判断,if (S[j] < S[smallest]) => if (S[j(7)] < S[smallest(3)]) => if (8 < -7),条件为 false,继续执行
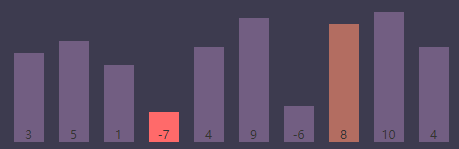
内循环索引(j)为8, 最小值索引(smallest)为3
进行条件判断,if (S[j] < S[smallest]) => if (S[j(8)] < S[smallest(3)]) => if (10 < -7),条件为 false,继续执行
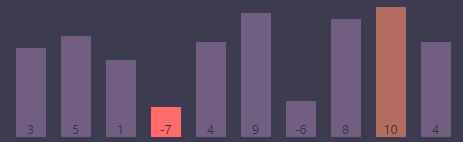
内循环索引(j)为9, 最小值索引(smallest)为3
进行条件判断,if (S[j] < S[smallest]) => if (S[j(9)] < S[smallest(3)]) => if (4 < -7),条件为 false,继续执行
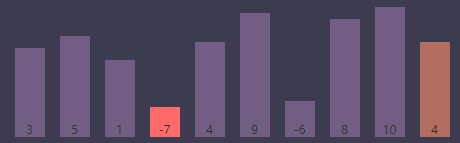
内循环结束,进行交换元素,exchange S[i] and S[smallest];
当前外循环索引(i)为0,最小值索引(smallest)为3
进行交换数组中0和3的元素,交换后的数组
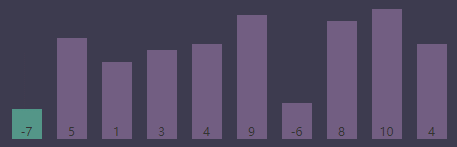
下一次循环
外循环索引(i)为1,最小值索引(smallest)为1,内循环索引(j)为当前外循环索引(i) + 1,当前内循环索引为 i + 1 => 1 + 1 => 2
继续内循环查找最小值索引,然后与外循环索引(i)元素互换,以达到升序排序数组
如需降序排序数组则查找最大值进行交换
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)