前言: 本文主要讲解MySQL中对表进行一些基本的查询操作,同时在讲一些对表的其他操作,所谓其他操作就是之前博客里面没有涉及到的。
1. 向表中插入数据
向表中插入数据再补充一下,如果插入的数据和主键或者唯一键冲突了的情况。
- 先创建
mysql> create table students (id int unsigned primary key auto_increment, sn int not null unique comment '学号', name varchar(20) not null, qq varchar(20))character set utf8;
Query OK, 0 rows affected (0.04 sec)
mysql> desc students;
+-------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| sn | int(11) | NO | UNI | NULL | |
| name | varchar(20) | NO | | NULL | |
| qq | varchar(20) | YES | | NULL | |
+-------+------------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
- 向表中插入数据,单行全列插入:
mysql> insert into students values(1,100,"张三",22222);
Query OK, 1 row affected (0.01 sec)
mysql> insert into students values(2,101,"李四",33333);
Query OK, 1 row affected (0.00 sec)
mysql> select * from students;
+----+-----+--------+-------+
| id | sn | name | qq |
+----+-----+--------+-------+
| 1 | 100 | 张三 | 22222 |
| 2 | 101 | 李四 | 33333 |
+----+-----+--------+-------+
2 rows in set (0.00 sec)
- 再向表中插入数据,多行全列插入:
mysql> insert into students values(11,111,"王五",4444),(12,222,"刘六",55555);
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from students;
+----+-----+--------+-------+
| id | sn | name | qq |
+----+-----+--------+-------+
| 1 | 100 | 张三 | 22222 |
| 2 | 101 | 李四 | 33333 |
| 11 | 111 | 王五 | 4444 |
| 12 | 222 | 刘六 | 55555 |
+----+-----+--------+-------+
4 rows in set (0.00 sec)
这里需要注意的就是,多行插入时,() () 之间用,隔开。
- 当然还可以指定列插入,现在来演示插入和主键,唯一键冲突了的情况:
mysql> insert into students values(2,101,"开心",33333);
ERROR 1062 (23000): Duplicate entry '2' for key 'PRIMARY'
很明显这是主键冲突,但是我如果就是想要更新一下name信息,但是发生冲突,导致无法完成插入操作,这就需要这样插入:
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ...
mysql> insert into students values(2,101,"开心",33333) on duplicate key update name="开心";
Query OK, 2 rows affected (0.01 sec)
mysql> select * from students;
+----+-----+--------+-------+
| id | sn | name | qq |
+----+-----+--------+-------+
| 1 | 100 | 张三 | 22222 |
| 2 | 101 | 开心 | 33333 |
| 11 | 111 | 王五 | 4444 |
| 12 | 222 | 刘六 | 55555 |
+----+-----+--------+-------+
4 rows in set (0.00 sec)
主键冲突,想要更新其余字段就是这样操作。唯一键冲突,和上面一样的操作。这里需要注意一点,那就是主键冲突,更新的字段不能包括主键,唯一键冲突,更新的字段不能包括唯一键。这是因为你更新了,就相当于不冲突了,那就可以直接插入了,而不是利用上面的更新操作。
- 上面发生冲突后,采取的是更新的方式,其实还有一种方式,那就是替换。
replace into students (sn, name) values (111, '王五');
- 如果发生了键冲突,那么就删除原来的,直接插入新的。这就是替换。
- 如果没有发生键冲突,就是直接插入。
2. 查询操作
我们先创建一个表,然后进行一些查询操作:
mysql> create table exam(id int unsigned primary key auto_increment, name varchar(20) not null comment '同学姓名', chinese float deefault 0.0 comment'语文成绩', math float default 0.0 comment'数学成绩', english float default 0.0 comment'英语成绩');
Query OK, 0 rows affected (0.05 sec)
mysql> desc exam;
+---------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| chinese | float | YES | | 0 | |
| math | float | YES | | 0 | |
| english | float | YES | | 0 | |
+---------+------------------+------+-----+---------+----------------+
5 rows in set (0.00 sec)
插入一批数据:
mysql> insert into exam values(1,'bob',88.5,75.4,98.5),(2,'xm',88,76,93),(3,'gg',76,77,98);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into exam values(4,'ss',82.5,72.4,98.5),(5,'ll',88,74,97),(6,'ff',75,72,93);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
2.1 全列查询
select * from 表名
全列查询,这个就是咱们实验用的比较多,一般情况下,很少用,因为全列显示,意味着需要传输的数据量越大,可能会影响到索引的使用。
比如:
mysql> select * from exam;
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 1 | bob | 88.5 | 75.4 | 98.5 |
| 2 | xm | 88 | 76 | 93 |
| 3 | gg | 76 | 77 | 98 |
| 4 | ss | 82.5 | 72.4 | 98.5 |
| 5 | ll | 88 | 74 | 97 |
| 6 | ff | 75 | 72 | 93 |
+----+------+---------+------+---------+
6 rows in set (0.00 sec)
2.2 指定列查询
就是指定部分列进行查询,不是全列查询,需要指定:
select 指定列 from exam:
mysql> select id,name,math from exam;
+----+------+------+
| id | name | math |
+----+------+------+
| 1 | bob | 75.4 |
| 2 | xm | 76 |
| 3 | gg | 77 |
| 4 | ss | 72.4 |
| 5 | ll | 74 |
| 6 | ff | 72 |
+----+------+------+
6 rows in set (0.00 sec)
2.3 查询字段带表达式
比如:现在要求 显示出来的math都加10:
select id,name,math+10 from exam:
mysql> select id,name,math+10 from exam;
+----+------+------------------+
| id | name | math+10 |
+----+------+------------------+
| 1 | bob | 85.4000015258789 |
| 2 | xm | 86 |
| 3 | gg | 87 |
| 4 | ss | 82.4000015258789 |
| 5 | ll | 84 |
| 6 | ff | 82 |
+----+------+------------------+
注意这个+10,只影响显示结果,不会影响 表中的原始数据。
现在要求显示出总分:
mysql> select id,name,math+chinese+english from exam;
+----+------+----------------------+
| id | name | math+chinese+english |
+----+------+----------------------+
| 1 | bob | 262.4000015258789 |
| 2 | xm | 257 |
| 3 | gg | 251 |
| 4 | ss | 253.4000015258789 |
| 5 | ll | 259 |
| 6 | ff | 240 |
+----+------+----------------------+
2.4 为查询结果指定别名
把上面的math+chinese+english,起别名为总分:
mysql> select id,name,math+chinese+english 总分 from exam ;
+----+------+-------------------+
| id | name | 总分 |
+----+------+-------------------+
| 1 | bob | 262.4000015258789 |
| 2 | xm | 257 |
| 3 | gg | 251 |
| 4 | ss | 253.4000015258789 |
| 5 | ll | 259 |
| 6 | ff | 240 |
+----+------+-------------------+
6 rows in set (0.00 sec)
2.5 去重操作
select distinct 字段名 from 表名;
mysql> select chinese from exam;
+---------+
| chinese |
+---------+
| 88.5 |
| 88 |
| 76 |
| 82.5 |
| 88 |
| 75 |
+---------+
可以看到里面有重复的情况,那就是88和88重复了,那么去重就是:
mysql> select distinct chinese from exam;
+---------+
| chinese |
+---------+
| 88.5 |
| 88 |
| 76 |
| 82.5 |
| 75 |
+---------+
3. where 条件
比较运算符:
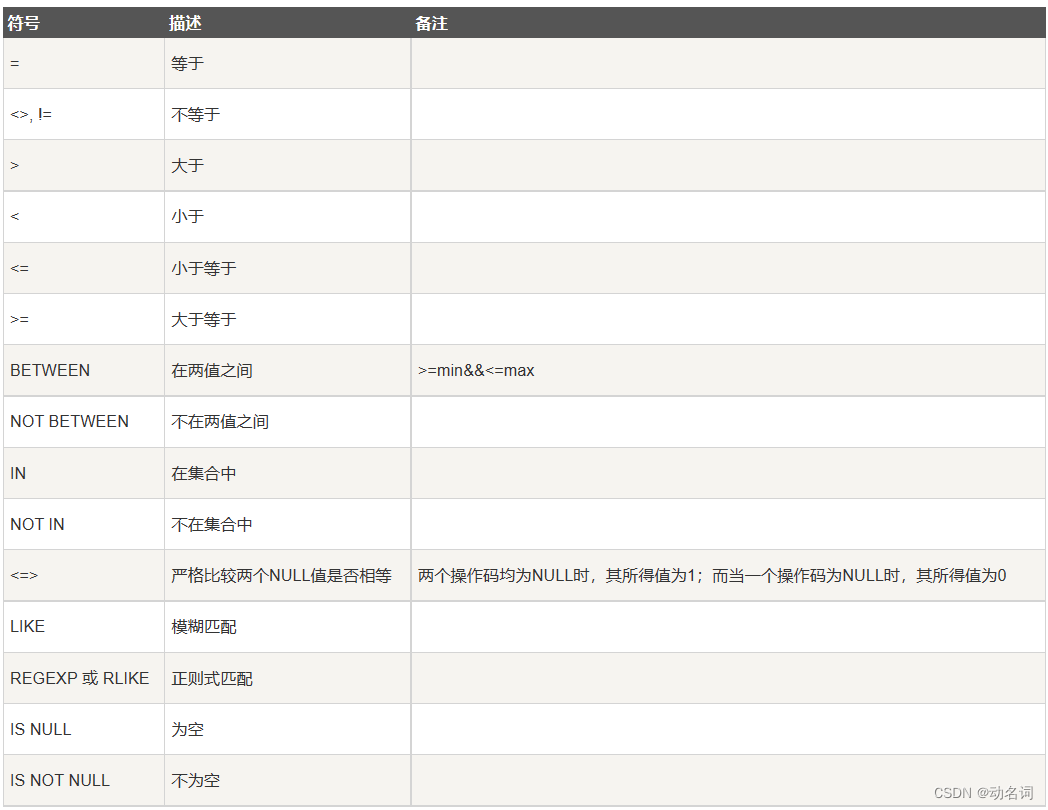
逻辑运算符:
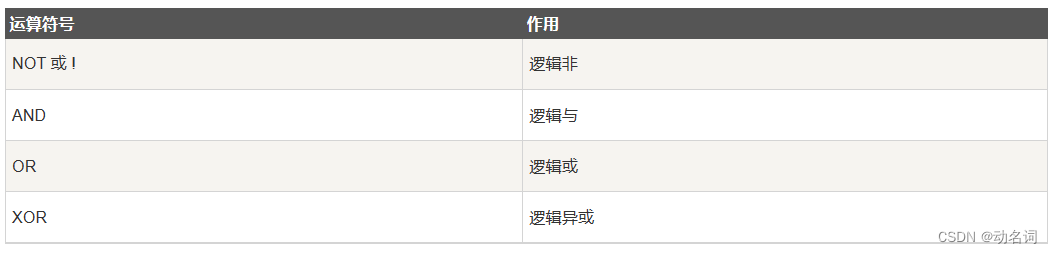
3.1 比较运算符和逻辑预算符的运用
假如:我要语文成绩在[80,90]之间的同学名单:
mysql> select name,chinese from exam where chinese>=80 and chinese<=90;
+------+---------+
| name | chinese |
+------+---------+
| bob | 88.5 |
| xm | 88 |
| ss | 82.5 |
| ll | 88 |
+------+---------+
4 rows in set (0.00 sec)
先在要求: 数学成绩大于75或者语文成绩大于85:
mysql> select name,chinese,math from exam where math>75 or chinese>=85;
+------+---------+------+
| name | chinese | math |
+------+---------+------+
| bob | 88.5 | 75.4 |
| xm | 88 | 76 |
| gg | 76 | 77 |
| ll | 88 | 74 |
+------+---------+------+
4 rows in set (0.00 sec)
3.2 like的细节
找出 名字为bob的同学:
mysql> select * from exam where name like 'bob';
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 1 | bob | 88.5 | 75.4 | 98.5 |
+----+------+---------+------+---------+
1 row in set (0.00 sec)
其实这里也可以用 name = ‘bob’ ,不过这里用like 。
关于like的两个细节:%,_。
比如我要搜索 b后面只有一个字母的人,bb之类的。如果不限制后面字母数 那就是 %:
mysql> select * from exam where name like 'b_';
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 7 | bb | 87 | 86 | 76 |
+----+------+---------+------+---------+
1 row in set (0.00 sec)
mysql> select * from exam where name like 'b%';
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 1 | bob | 88.5 | 75.4 | 98.5 |
| 7 | bb | 87 | 86 | 76 |
+----+------+---------+------+---------+
2 rows in set (0.00 sec)
3. 3 null查询
null不参与一般的运算,如果要让它参与比较运算,也是可以的,那就是用 is null和is not null,这样好用。如果非要用比较运算符的话,那就是<=>等于。
mysql> select * from students;
+----+-----+--------+-------+
| id | sn | name | qq |
+----+-----+--------+-------+
| 3 | 102 | 开学 | 33333 |
| 11 | 111 | 王五 | 4444 |
| 12 | 222 | 刘六 | 55555 |
| 13 | 100 | 发财 | NULL |
+----+-----+--------+-------+
比如:上面那个表,其中发财的qq是空。
mysql> select * from students where qq is not null;
+----+-----+--------+-------+
| id | sn | name | qq |
+----+-----+--------+-------+
| 3 | 102 | 开学 | 33333 |
| 11 | 111 | 王五 | 4444 |
| 12 | 222 | 刘六 | 55555 |
+----+-----+--------+-------+
3 rows in set (0.00 sec)
mysql> select * from students where qq is null;
+----+-----+--------+------+
| id | sn | name | qq |
+----+-----+--------+------+
| 13 | 100 | 发财 | NULL |
+----+-----+--------+------+
1 row in set (0.00 sec)
mysql> select * from students where qq <=> null;
+----+-----+--------+------+
| id | sn | name | qq |
+----+-----+--------+------+
| 13 | 100 | 发财 | NULL |
+----+-----+--------+------+
1 row in set (0.00 sec)
4. 对查询的结果进行排序
-- asc 为升序(从小到大)
-- desc 为降序(从大到小)
-- 默认为 asc
4.1 对单一字段进行排序
假如:对数学成绩进行排序:
mysql> select id,name,math from exam order by math;
+----+------+------+
| id | name | math |
+----+------+------+
| 6 | ff | 72 |
| 4 | ss | 72.4 |
| 5 | ll | 74 |
| 1 | bob | 75.4 |
| 2 | xm | 76 |
| 3 | gg | 77 |
| 7 | bb | 86 |
+----+------+------+
7 rows in set (0.00 sec)
对吧,很明显是升序,也就是默认asc。
那么如果要排降序呢,那就是选desc:
mysql> select id,name,math from exam order by math desc;
+----+------+------+
| id | name | math |
+----+------+------+
| 7 | bb | 86 |
| 3 | gg | 77 |
| 2 | xm | 76 |
| 1 | bob | 75.4 |
| 5 | ll | 74 |
| 4 | ss | 72.4 |
| 6 | ff | 72 |
+----+------+------+
7 rows in set (0.00 sec)
4.2 对多个字段排序
对多个字段进行排序:
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示:
注意其实多字段排序是不能完成的,你想想吧,有的数学高,有的英语高,这不能在一张表中排序,所以多字段排序其实就是你写的要排序的第一个字段:
mysql> select * from exam order by math desc,english,chinese;
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 7 | bb | 87 | 86 | 76 |
| 3 | gg | 76 | 77 | 98 |
| 2 | xm | 88 | 76 | 93 |
| 1 | bob | 88.5 | 75.4 | 98.5 |
| 5 | ll | 88 | 74 | 97 |
| 4 | ss | 82.5 | 72.4 | 98.5 |
| 6 | ff | 75 | 72 | 93 |
+----+------+---------+------+---------+
7 rows in set (0.00 sec)
这只对math进行了排序。
4.3 对字段排序结果进行分页
起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
比如:我只想看一些,数学的第一名:
mysql> select id,name,math from exam order by math desc limit 1 offset 0;
+----+------+------+
| id | name | math |
+----+------+------+
| 7 | bb | 86 |
+----+------+------+
1 row in set (0.00 sec)
我想看数学的前三名:
mysql> select id,name,math from exam order by math desc limit 3 offset 0;
+----+------+------+
| id | name | math |
+----+------+------+
| 7 | bb | 86 |
| 3 | gg | 77 |
| 2 | xm | 76 |
+----+------+------+
3 rows in set (0.00 sec)
我想看从[4,6]名:
mysql> select id,name,math from exam order by math desc limit 3 offset 3;
+----+------+------+
| id | name | math |
+----+------+------+
| 1 | bob | 75.4 |
| 5 | ll | 74 |
| 4 | ss | 72.4 |
+----+------+------+
3 rows in set (0.00 sec)
5. 更改表中的数据
UPDATE table_name SET column = expr [, column = expr ...][WHERE ...] [ORDER BY ...] [LIMIT ...]
5.1 更新单列数据
比如我想用更改bob的语文成绩:
mysql> select name,chinese from exam where name like'bob';
+------+---------+
| name | chinese |
+------+---------+
| bob | 88.5 |
+------+---------+
1 row in set (0.00 sec)
mysql> update exam set chinese=90 where name like'bob';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select name,chinese from exam where name like'bob';
+------+---------+
| name | chinese |
+------+---------+
| bob | 90 |
+------+---------+
1 row in set (0.00 sec)
mysql>
5.2 更新多列的数据
假如我要更新bob的语文和数学成绩:
mysql> update exam set chinese=84,math=90 where name like'bob';
Query OK, 1 row affected (0.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select name,chinese,math from exam where name like'bob';
+------+---------+------+
| name | chinese | math |
+------+---------+------+
| bob | 84 | 90 |
+------+---------+------+
1 row in set (0.00 sec)
更新表中数据,如果不加上 where条件句的限制,那就是全列更新。但是全列更新这个操作用的不多,要慎用。update操作当然不仅是简单的修改值,还可以:比如说要把某个人的语文成绩+30,update exam set chinese=chinese+30 where name like'bob';或者说语文成绩变成原来的2倍,update exam set chinese=chinese*2 where name like'bob。像上面的操作都是可以的,不过不支持什么 += ,*= 等复合操作。
6. 删除表中数据
6.1 删除表中一个数据或或者多个数据
要求删除bob的成绩:
mysql> select * from exam;
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 1 | bob | 84 | 90 | 98.5 |
| 2 | xm | 88 | 76 | 93 |
| 3 | gg | 76 | 77 | 98 |
| 4 | ss | 82.5 | 72.4 | 98.5 |
| 5 | ll | 88 | 74 | 97 |
| 6 | ff | 75 | 72 | 93 |
| 7 | bb | 87 | 86 | 76 |
+----+------+---------+------+---------+
7 rows in set (0.00 sec)
mysql> delete from exam where name='bob';
Query OK, 1 row affected (0.02 sec)
mysql> select * from exam;
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 2 | xm | 88 | 76 | 93 |
| 3 | gg | 76 | 77 | 98 |
| 4 | ss | 82.5 | 72.4 | 98.5 |
| 5 | ll | 88 | 74 | 97 |
| 6 | ff | 75 | 72 | 93 |
| 7 | bb | 87 | 86 | 76 |
+----+------+---------+------+---------+
6 rows in set (0.01 sec)
我现在要求删除xm和gg的成绩:
mysql> delete from exam where name='xm' or name='gg';
Query OK, 2 rows affected (0.00 sec)
mysql> select * from exam;
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 4 | ss | 82.5 | 72.4 | 98.5 |
| 5 | ll | 88 | 74 | 97 |
| 6 | ff | 75 | 72 | 93 |
| 7 | bb | 87 | 86 | 76 |
+----+------+---------+------+---------+
4 rows in set (0.00 sec)
6.2 删除全表的数据
这个操作要慎用:
delete from 表名。
这个操作就不演示了,不过会在下面进行讲解。
6.3 截断表,不可以恢复的删除
像是上面的delete操作,之后都是可以恢复数据的,这个可以通过MySQL的日志功能进行恢复。但是truncate操作之后,是不能恢复数据的。
我创建一个表test,专门用于实验这点:
mysql> CREATE TABLE for_delete (
-> id INT PRIMARY KEY AUTO_INCREMENT,
-> name VARCHAR(20));
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from for_delete;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)
mysql> delete from for_delete;
Query OK, 3 rows affected (0.01 sec)
mysql> select * from for_delete;
Empty set (0.00 sec)
mysql> insert into for_delete(name) values('W');
Query OK, 1 row affected (0.00 sec)
mysql> select * from for_delete;
+----+------+
| id | name |
+----+------+
| 4 | W |
+----+------+
1 row in set (0.00 sec)
mysql>
可以看到,delete全表后,继续插入数据,自增的id 是有记录的,它自动从id=3后进行增加。为什么?我们来查看表结构:
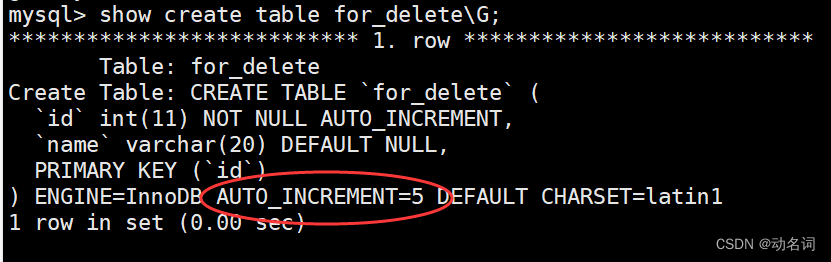
这里是有记录的,说明 下次 自增的话,id就会是5。
那么我们再来实验一下,truncate操作:
mysql> CREATE TABLE for_truncate( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20));
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO for_truncate (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)
mysql> truncate for_truncate;
Query OK, 0 rows affected (0.02 sec)
mysql> select * from for_truncate;
Empty set (0.00 sec)
mysql> show create table for_truncate\G;
*************************** 1. row ***************************
Table: for_truncate
Create Table: CREATE TABLE `for_truncate` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
ERROR:
No query specified
mysql> insert into for_truncate (name) values('W');
Query OK, 1 row affected (0.02 sec)
mysql> select * from for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | W |
+----+------+
1 row in set (0.00 sec)
mysql>
从这里就能看到,truncate是没有保留以前的自增长的。
7. 去重操作
我创建一个新的表,演示去重操作:
mysql> create table test (id int,name varchar(20));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into test values(1,'bb'),(2,'yy'),(3,'bb'),(1,'bb');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from test;
+------+------+
| id | name |
+------+------+
| 1 | bb |
| 2 | yy |
| 3 | bb |
| 1 | bb |
+------+------+
4 rows in set (0.00 sec)
mysql> select distinct * from test ;
+------+------+
| id | name |
+------+------+
| 1 | bb |
| 2 | yy |
| 3 | bb |
+------+------+
3 rows in set (0.00 sec)
用distinct修饰字段,就是去重操作。
mysql> select distinct name from test ;
+------+
| name |
+------+
| bb |
| yy |
+------+
8. 聚合函数
- count : 返回查询到的数据的数量总和
- sum: 返回查询到的数据的总和
- avg:返回查询到的数据的平均值
- max:返回查询到的数据的最大值
- min: 返回查询到的数据的最小值
注意:null不会加入聚合函数的计算。
比如:
我想看一下表中有多少数据:
mysql> select * from students;
+----+-----+--------+-------+
| id | sn | name | qq |
+----+-----+--------+-------+
| 3 | 102 | 开学 | 33333 |
| 11 | 111 | 王五 | 4444 |
| 12 | 222 | 刘六 | 55555 |
| 13 | 100 | 发财 | NULL |
+----+-----+--------+-------+
4 rows in set (0.00 sec)
mysql> select count(*) from students;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.00 sec)
mysql> select count(id) from students;
+-----------+
| count(id) |
+-----------+
| 4 |
+-----------+
1 row in set (0.00 sec
聚合函数中的sum使用,sum就是给一列进行求和:
mysql> select * from exam;
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 4 | ss | 82.5 | 72.4 | 98.5 |
| 5 | ll | 88 | 74 | 97 |
| 6 | ff | 75 | 72 | 93 |
| 7 | bb | 87 | 86 | 76 |
+----+------+---------+------+---------+
4 rows in set (0.00 sec)
mysql> select sum(math) from exam;
+-------------------+
| sum(math) |
+-------------------+
| 304.4000015258789 |
+-------------------+
1 row in set (0.00 sec)
mysql> select sum(math+chinese) from exam;
+-------------------+
| sum(math+chinese) |
+-------------------+
| 636.9000015258789 |
+-------------------+
1 row in set (0.00 sec)
mysql> select sum(math+chinese+english) from exam;
+---------------------------+
| sum(math+chinese+english) |
+---------------------------+
| 1001.4000015258789 |
+---------------------------+
1 row in set (0.00 sec)
mysql>
其实像上面math+chinese,math+chinese+english都可以看作一列。
统计平均分用avg:
mysql> select avg(math+chinese+english) from exam;
+---------------------------+
| avg(math+chinese+english) |
+---------------------------+
| 250.35000038146973 |
+---------------------------+
1 row in set (0.00 sec)
看一下数学最高分,上面也演示过看最高分,不过用的方法是order by + limit的方式:
mysql> select max(math) from exam;
+-----------+
| max(math) |
+-----------+
| 86 |
+-----------+
1 row in set (0.00 sec)
看一下最低数学成绩:
mysql> select min(math) from exam;
+-----------+
| min(math) |
+-----------+
| 72 |
+-----------+
1 row in set (0.00 sec)