非递归的算法主要采用的是循环出栈入栈来实现对二叉树的遍历,下面是过程分析
以下列二叉树为例:(图片来自懒猫老师《数据结构》课程相关内容)
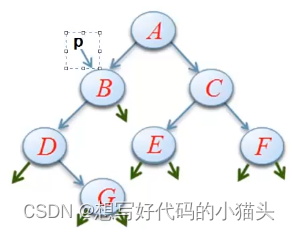
1.前序遍历
前序遍历的顺序为:根结点->左子树->右子树
基本过程:
(1)访问根结点,将根结点入栈
(2)循环逐个访问左子树,执行(1)中步骤;当访问到没有左子树的结点时,跳出循环
(3)栈不为空,根结点出栈,访问右子树
这里以A的左子树为例进行栈的变化过程说明:
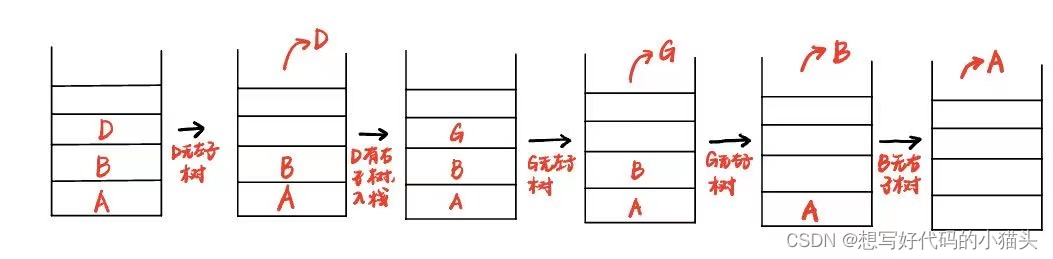
可以总结成,没有左子树->出栈+右子树入栈;没有右子树->出栈
代码实现:
void PreOrder(BiNode *bt) { //树的前序遍历
SqStack s;
s = InitStack();
BiNode *p = bt;
while (p != NULL || StackEmpty(&s) != 1) { //当p为空,栈也为空时退出循环
while (p != NULL) {
visit(p->data);//访问根结点
Push(&s, p); //将指针p的节点压入栈中
p = p->Lchild; //遍历左子树
}
if (StackEmpty(&s) != 1) { //栈不为空
p = Pop(&s); //根结点出栈,相当于回退
p = p->rchild; //遍历右子树
}
}
DestroyStack(&s);
}
2.中序遍历
中序遍历的顺序为:左子树->根结点>右子树
基本过程:
(1)将根结点入栈
(2)循环逐个访问左子树,执行(1)中步骤;当访问到没有左子树的结点时,跳出循环
(3)栈不为空,根结点出栈,访问根结点,再访问右子树
其实就是将访问根结点的位置换了
代码实现:
void MidOrder(BiNode *bt) { //树的中序遍历
SqStack s;
s = InitStack();
BiNode *p = bt;
while (p != NULL || StackEmpty(&s) != 1) { //当p为空,栈也为空时退出循环
while (p != NULL) {
Push(&s, p); //将指针p的节点压入栈中
p = p->Lchild; //遍历左子树
}
if (StackEmpty(&s) != 1) { //栈不为空
p = Pop(&s); //根结点出栈,相当于回退
visit(p->data);//访问根结点
p = p->rchild; //遍历右子树
}
}
DestroyStack(&s);
}
3.后序遍历
前两种遍历的栈数据类型都是BiNode *,但后序遍历的栈的数据类型要进行重新定义,因为后序遍历的顺序是左子树->右子树>根结点,结点要进入两次栈,出两次栈,为什么会有两次呢?
(1)第一次出栈:只遍历完左子树,该结点不能出栈,需要第二次入栈;找到右子树并遍历
(2)第二次出栈:遍历完左右子树,该结点出栈,并访问
需要注意的是,第二次出栈并访问之后,需要将p指针置空,这样才能在下一次循环的时候,重新从栈中取到一个元素(或者理解成二叉树中的回退操作)
这里设置一个flag标志来区分两次出入栈,并进行不同的操作
栈元素类型定义如下:
typedef struct element {
BiNode *ptr;
int flag;
} element;
代码实现:
(因为后序遍历和前两种数据类型不一样,这里定义了两套栈函数分别来用,用_1下标区分)
void PostOrder(BiNode *bt) { //树的后序遍历
SqStack s;
s = InitStack_1();
BiNode *p = bt;
element elem;
while (p != NULL || StackEmpty_1(&s) != 1) { //当p为空,栈也为空时退出循环
if (p != NULL) {//第一次入栈,访问左子树
elem.ptr = p;
elem.flag = 1; //标记flag为1,表示即将第一次入栈
Push_1(&s, elem); //将指针p的结点第一次压入栈中
p = p->Lchild;
} else {
elem = Pop_1(&s); //出栈
p = elem.ptr; //p指向当前要处理的结点
if (elem.flag == 1) {
//flag==1时,说明只访问过左子树,还要访问右子树
elem.flag = 2;
Push_1(&s, elem); //结点第二次压入栈中
p = p->rchild;
} else {
//flag==2时,左右子树都已经访问过了
visit(p->data);
p = NULL; //访问后,p赋为空,确保下次循环时继续出栈(相当于回退)
}
}
}
DestroyStack_1(&s);
}
4. 完整代码
分为三个文件包,一个是存放栈的操作函数,一个是存放二叉树的非递归遍历函数,一个是对二叉树的非递归遍历功能进行的测试,第三个文件调用前两个头文件就可以测试完整功能
(1)数组堆栈_二叉树非递归.h
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define STACK_INIT_SIZE 100
#define STACKINCREMENT 10
typedef char Datatype;
typedef struct BiNode {
Datatype data;//数据内容
struct BiNode *Lchild;//指向左孩子结点
struct BiNode *rchild;//指向右孩子结点
} BiNode;
typedef BiNode *Elemtype;
typedef struct element {
BiNode *ptr;
int flag;
} element;
typedef element Elemtype_1;
typedef struct {
Elemtype *data;//用于前序和中序遍历
Elemtype_1 *data_1;//用于后序遍历
int top;//栈顶指针,这里用int类型表示指针的下标
int stacksize;
} SqStack;
Elemtype Pop(SqStack *s);
SqStack InitStack() {//空栈构造函数
SqStack s;
s.data = (Elemtype *)malloc(STACK_INIT_SIZE * sizeof(Elemtype));
s.top = -1; //表示栈空
s.stacksize = STACK_INIT_SIZE;
if (s.data != NULL)
{}
else
printf("Init error!\n");
return s;
}
void DestroyStack(SqStack *s) {//销毁栈函数
free(s->data);
}
int StackEmpty(SqStack *s) {//判断是否为空栈,是返回1,否 返回0
if (s->top == -1)
return 1;
else
return 0;
}
void Push(SqStack *s, Elemtype e) {//添加元素入栈
if (s->top >= s->stacksize) {
s->data = (Elemtype *)malloc((STACK_INIT_SIZE + STACKINCREMENT) * sizeof(Elemtype));
s->stacksize += STACKINCREMENT;
if (s->data != NULL) {}
else
printf("Push error!\n");
} else {
s->top++;
s->data[s->top] = e;
}
}
Elemtype Pop(SqStack *s) {
if (StackEmpty(s) != 1 && s->top >= 0) {
Elemtype e = s->data[s->top];
s->top--;
return e;
}
printf("Pop error!\n");
}
SqStack InitStack_1() {//空栈构造函数
SqStack s;
s.data_1 = (Elemtype_1 *)malloc(STACK_INIT_SIZE * sizeof(Elemtype_1));
s.top = -1; //表示栈空
s.stacksize = STACK_INIT_SIZE;
if (s.data != NULL)
{}
else
printf("Init error!\n");
return s;
}
void DestroyStack_1(SqStack *s) {//销毁栈函数
free(s->data_1);
}
int StackEmpty_1(SqStack *s) {//判断是否为空栈,是返回1,否 返回0
if (s->top == -1)
return 1;
else
return 0;
}
void Push_1(SqStack *s, Elemtype_1 e) {//添加元素入栈
if (s->top >= s->stacksize) {
s->data_1 = (Elemtype_1 *)malloc((STACK_INIT_SIZE + STACKINCREMENT) * sizeof(Elemtype_1));
s->stacksize += STACKINCREMENT;
if (s->data_1 != NULL) {}
else
printf("Push error!\n");
} else {
s->top++;
s->data_1[s->top] = e;
}
}
Elemtype_1 Pop_1(SqStack *s) {
if (StackEmpty(s) != 1 && s->top >= 0) {
Elemtype_1 e = s->data_1[s->top];
s->top--;
return e;
}
printf("Pop error!\n");
}
(2)二叉树遍历(非递归).h
#include "数组堆栈_二叉树非递归.h"
BiNode *Creat(char *str, int *i, int len) { //树的创建
struct BiNode *bt = NULL;
char ch = str[(*i)++];
if (ch == '#' || *i >= len) {
bt = NULL;
} else {
bt = (struct BiNode *)malloc(sizeof(BiNode));
if (bt != NULL) {
bt->data = ch;
bt->Lchild = Creat(str, i, len); //这里的递归要赋值,这样才能建立不同域中的连接关系
bt->rchild = Creat(str, i, len);
}
}
return bt;//返回的一直是根结点
}
void visit(Datatype e) {
printf("%c ", e);
}
void PreOrder(BiNode *bt) { //树的前序遍历
SqStack s;
s = InitStack();
BiNode *p = bt;
while (p != NULL || StackEmpty(&s) != 1) { //当p为空,栈也为空时退出循环
while (p != NULL) {
visit(p->data);//访问根结点
Push(&s, p); //将指针p的节点压入栈中
p = p->Lchild; //遍历左子树
}
if (StackEmpty(&s) != 1) { //栈不为空
p = Pop(&s); //根结点出栈,相当于回退
p = p->rchild; //遍历右子树
}
}
DestroyStack(&s);
}
void MidOrder(BiNode *bt) { //树的中序遍历
SqStack s;
s = InitStack();
BiNode *p = bt;
while (p != NULL || StackEmpty(&s) != 1) { //当p为空,栈也为空时退出循环
while (p != NULL) {
Push(&s, p); //将指针p的节点压入栈中
p = p->Lchild; //遍历左子树
}
if (StackEmpty(&s) != 1) { //栈不为空
p = Pop(&s); //根结点出栈,相当于回退
visit(p->data);//访问根结点
p = p->rchild; //遍历右子树
}
}
DestroyStack(&s);
}
void PostOrder(BiNode *bt) { //树的后序遍历
SqStack s;
s = InitStack_1();
BiNode *p = bt;
element elem;
while (p != NULL || StackEmpty_1(&s) != 1) { //当p为空,栈也为空时退出循环
if (p != NULL) {//第一次入栈,访问左子树
elem.ptr = p;
elem.flag = 1; //标记flag为1,表示即将第一次入栈
Push_1(&s, elem); //将指针p的结点第一次压入栈中
p = p->Lchild;
} else {
elem = Pop_1(&s); //出栈
p = elem.ptr; //p指向当前要处理的结点
if (elem.flag == 1) {
//flag==1时,说明只访问过左子树,还要访问右子树
elem.flag = 2;
Push_1(&s, elem); //结点第二次压入栈中
p = p->rchild;
} else {
//flag==2时,左右子树都已经访问过了
visit(p->data);
p = NULL; //访问后,p赋为空,确保下次循环时继续出栈(相当于回退)
}
}
}
DestroyStack_1(&s);
}
(3)二叉树遍历(非递归).c
#include "二叉树遍历(非递归).h"
main() {
printf("测试二叉树遍历(非递归)算法\n");
printf("建立一个二叉树-->");
BiNode *bt;
int i = 0, len;
char str[50];
printf("输入一个字符串用于建立二叉树:");
scanf("%s", str);
len = strlen(str);
bt = Creat(str, &i, len);
printf("测试遍历操作:\n");
printf("测试树的前序遍历:");
PreOrder(bt);
printf("\n");
printf("测试树的中序遍历:");
MidOrder(bt);
printf("\n");
printf("测试树的后序遍历:");
PostOrder(bt);
printf("\n");
}
5.测试输出
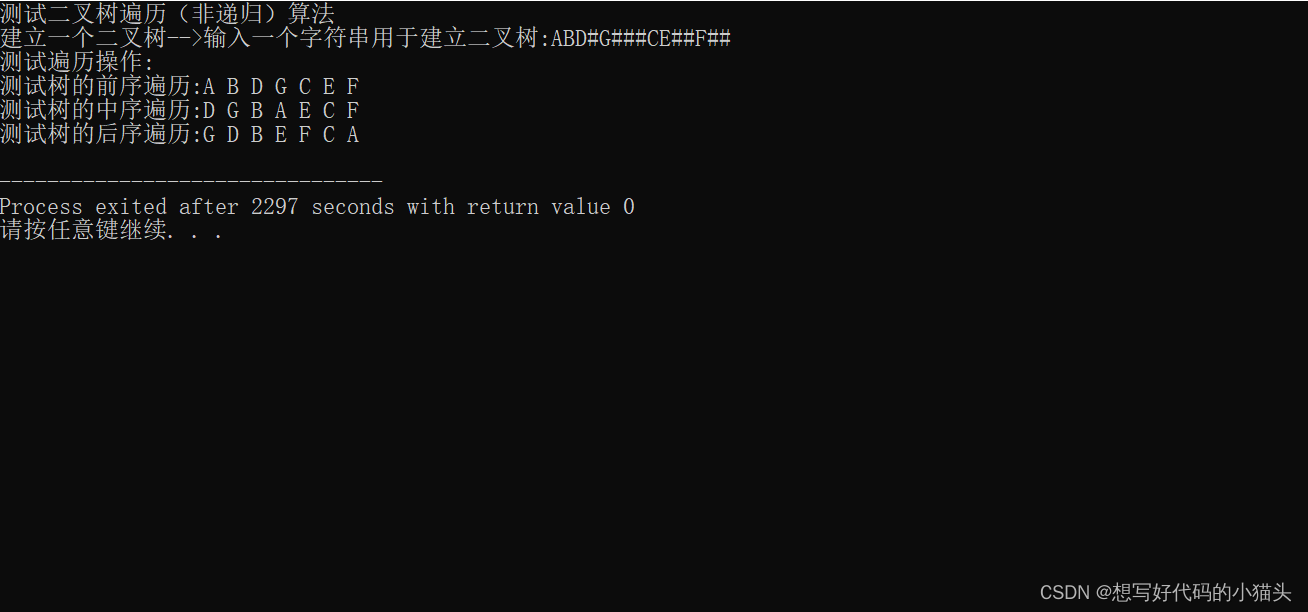
初学小白,有错误的话欢迎指正喔!~