目录
前言
思路
代码实现
第一步,先获取页面源代码
第二步,交给XPath的HTML解释器进行解析
第三步,通过源代码检查并获取XPath路径
第四步,创建csv文件,准备写入数据
第五步,遍历所有的div,获取我们需要的信息
完整代码
运行结果
总结
前言
我们通过前面小节的学习已经了解了XPath的基本语法,这一节我们将以一个比较复杂的网站来试水,它的标签嵌套十分多而且复杂,足够让我们来练习。
思路
1. 拿到页面源代码
2. 提取和解析数据
3. 把数据保存为csv文件
代码实现
第一步,先获取页面源代码
url = "见评论区"
resp = requests.get(url)
# print(resp.text)
第二步,交给XPath的HTML解释器进行解析
# 解析
html = etree.HTML(resp.text)
第三步,通过源代码检查并获取XPath路径
注意,这一步很有可能出现问题,因为这个网站是一直在动态变化的,所以不能直接用绝对路径,而要用一些唯一的属性来标定才能精准定位。当然,我们也可以先检查源代码并复制XPath路径,再进行微调。

右击查询到的服务商板块,单击检查,即可跳转到源代码对应的代码段中,并且移动鼠标可以观察到每个标签包裹的板块。
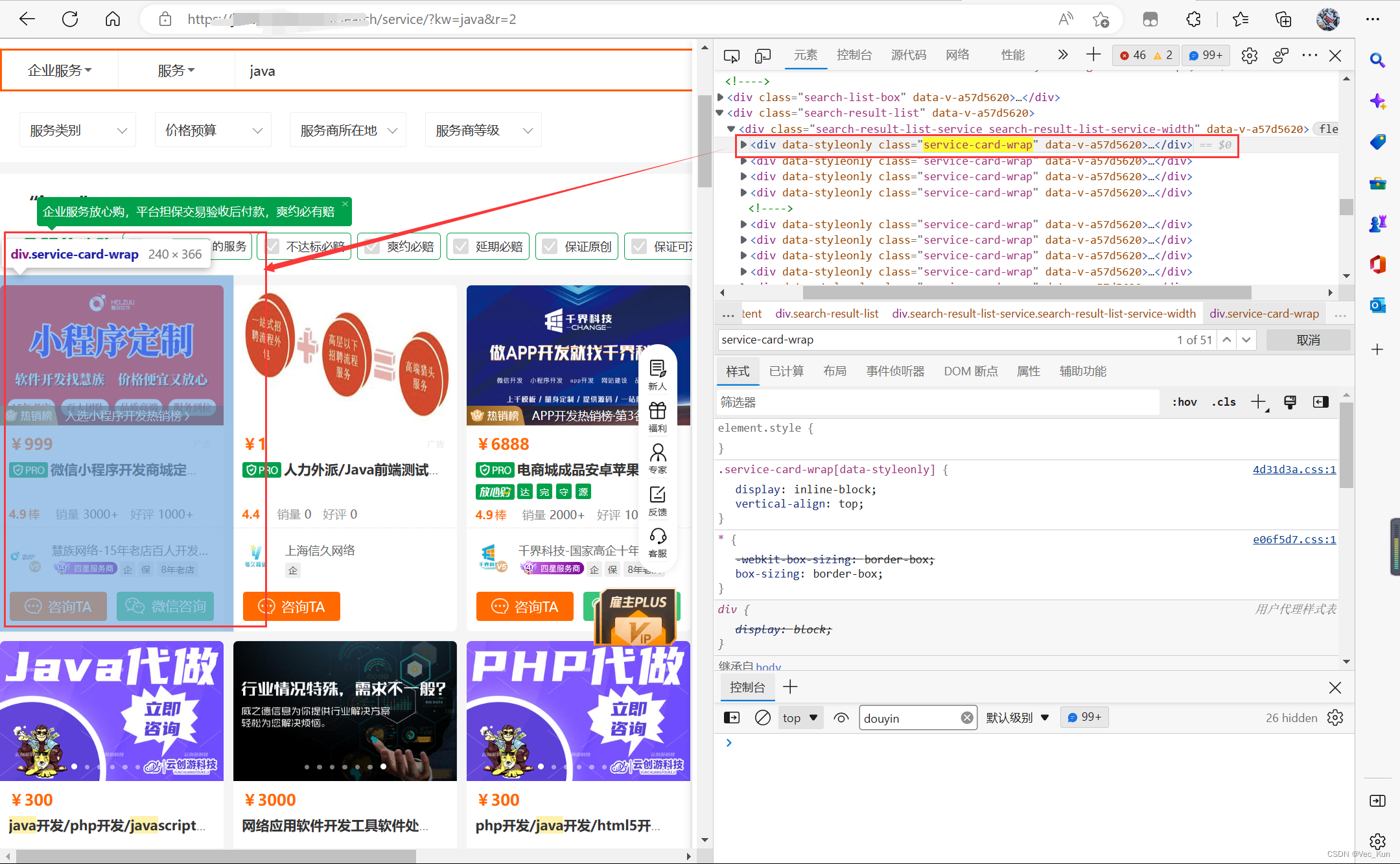
通过观察发现这里是我们需要的标签,所以复制绝对路径后再把最后一个标签的[1]删掉,就可以获取本页面上所有类似的服务商板块了,也就是所有的查询结果。但是根据实际我们需要修改一些前置标签的属性值来定位,否则很有可能抓到空列表。
最后拿到的效果是这样的:
# 拿到每一个服务商的div
divs = html.xpath("/html/body/div[@id='__nuxt']/div[@id='__layout']/div[@class='app-page-layout']/div[3]/div[@class='s50-search-list-page']/div[4]/div[4]/div[1]/div[@class='service-card-wrap']")
# print(len(divs))
打印列表长度是为了debug,在源代码中查找最后的属性值为51个,除去我们查找范围外的一个正好为50个,而我们打印出来的列表长度也是50,说明找到了50个子项,是对应的。
第四步,创建csv文件,准备写入数据
with open("猪八戒Java.csv", mode="a+", newline='', encoding="utf-8") as f:
csvwriter = csv.writer(f)
第五步,遍历所有的div,获取我们需要的信息
for div in divs: # 每一个服务商信息
price = div.xpath("./div/div[@class='bot-content']/div/span/text()")[0].strip("¥")
title = "Java".join(div.xpath("./div/div[@class='bot-content']/div[2]/a/text()"))
score = div.xpath("./div/div[@class='bot-content']/div[4]/div[@class='fraction']/span[1]/text()")[0]
sales = div.xpath("./div/div[@class='bot-content']/div[4]/div[@class='sales']/div/span[2]/text()")[0]
evaluate = div.xpath("./div/div[@class='bot-content']/div[4]/div[@class='evaluate']/div/span[2]/text()")[0]
company_name = div.xpath("./div/a/div[2]/div[1]/div/text()")[0]
csvwriter.writerow([title, price, score, sales, evaluate, company_name])
f.close()
print("Over!")
同理,需要一层一层去找,配合网页开发工具的高亮提示对应模块快速找到,或者在网页中将鼠标移动到对应元素上右击检查找到目标。此时我们要用相对路径来找,否则太长了。注意这里也要适当的修改一些属性值来精准定位,但不是每一条都要修改属性值,这就需要经验和试错了。
当然,最后别忘记关闭文件和关闭网络请求。
完整代码
# Created at UESTC
# Author: Vector Kun
# Time: 2023/1/2 23:55
# 拿到页面源代码
# 提取和解析数据
import requests
from lxml import etree
import csv
url = "见评论区"
resp = requests.get(url)
# print(resp.text)
# 解析
html = etree.HTML(resp.text)
# 拿到每一个服务商的div
divs = html.xpath("/html/body/div[@id='__nuxt']/div[@id='__layout']/div[@class='app-page-layout']/div[3]/div[@class='s50-search-list-page']/div[4]/div[4]/div[1]/div[@class='service-card-wrap']")
# print(len(divs))
with open("猪八戒Java.csv", mode="a+", newline='', encoding="utf-8") as f:
csvwriter = csv.writer(f)
for div in divs: # 每一个服务商信息
price = div.xpath("./div/div[@class='bot-content']/div/span/text()")[0].strip("¥")
title = "Java".join(div.xpath("./div/div[@class='bot-content']/div[2]/a/text()"))
score = div.xpath("./div/div[@class='bot-content']/div[4]/div[@class='fraction']/span[1]/text()")[0]
sales = div.xpath("./div/div[@class='bot-content']/div[4]/div[@class='sales']/div/span[2]/text()")[0]
evaluate = div.xpath("./div/div[@class='bot-content']/div[4]/div[@class='evaluate']/div/span[2]/text()")[0]
company_name = div.xpath("./div/a/div[2]/div[1]/div/text()")[0]
csvwriter.writerow([title, price, score, sales, evaluate, company_name])
f.close()
print("Over!")
resp.close()
运行结果

可以看到我们成功抓取了50条结果,结果十分准确。
总结
XPath解析方法可以和文件路径与bs4作类比,我个人觉得它特别像两者的结合体,把他们的优点集合到一起,取长补短进行互补。我们本节通过一个比较复杂的实战案例实现外包网站报价等信息的获取,巩固了XPath解析的知识和运用能力。下一节开始我们将对requests模块进行进阶学习。