目录
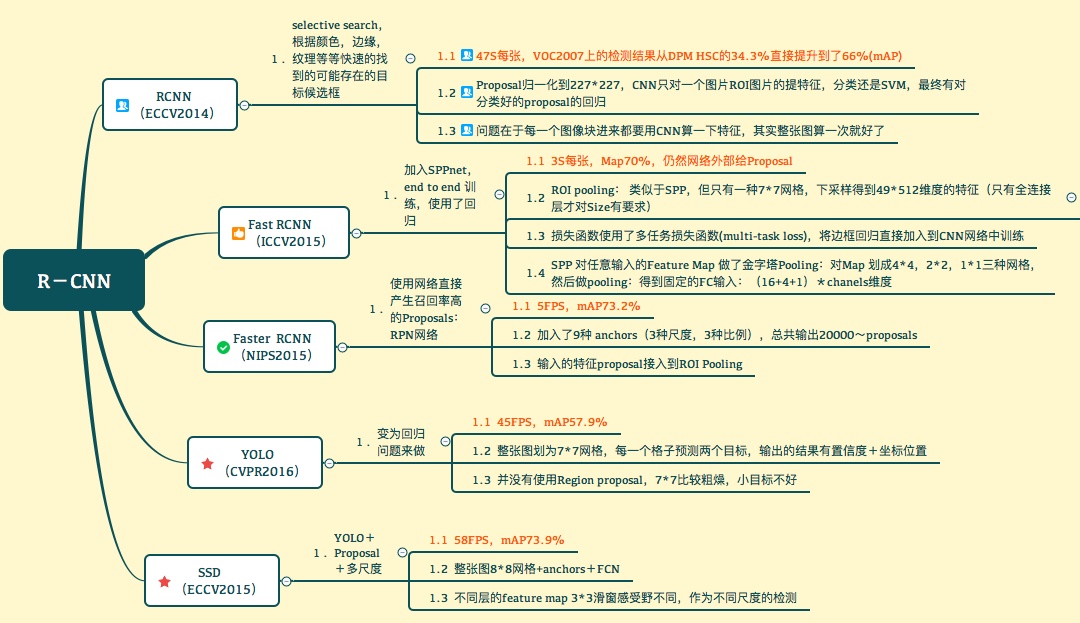
R-CNN
1.1提取候选区域
1.1.1合并规则
1.1.2多样化与后处理
1.2特征提取
1.2.1预处理
2.Fast RCNN
2.1RoI Pooling Layer
Faster RCNN
结构
RPN
anchor(目标框)
分类和定位
Mask RCNN
框架
算法
RoIAlign
Mask branch
SSD
FCOS

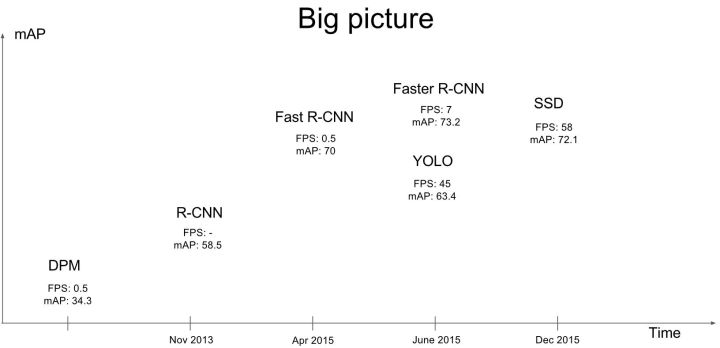
基于深度学习的目标检测算法主要分为两类:Two stage和One stage。
1)Tow Stage:基于Region Proposal的R-CNN系算法
先进行区域生成,该区域称之为region proposal(简称RP,一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
任务流程:特征提取 --> 生成RP --> 分类/定位回归。
常见tow stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等。
先算法产生目标候选框,然后再对候选框做分类与回归, 慢,准确性较高
2)One Stage
不用RP,直接在网络中提取特征来预测物体分类和位置。
任务流程:特征提取–> 分类/定位回归。
常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等。
卷积神经网络CNN直接预测不同目标的类别与位置,快,准确性稍低

| 目标检测 (分类+定位) |
R-CNN |
Fast RCNN |
Faster RCNN |
Mask RCNN |
| 目标候选框 |
Selective Search |
共享CNN 对全图提取特征 |
ResNeXt 获取特征 |
| 提取特征向量 |
CNN, 用AlexNet对候选区域 特征提取 |
CNN 对全图特征提取 RoI Pooling Layer 摘取Roi特征 |
RPN生成Roi 并修正 RoI Pooling Layer 摘取Roi特征 |
生成Roi RPN二值分类 BB回归 RoIAlign |
| 分类 |
SVM分类 |
|
FC 分类 二次修正 |
N类别分类、 BB回归、MASK生成 |
| 边框修正 |
BB回归 |
|
R-CNN
Region CNN解决目标检测中的两个关键问题:
1.速度:滑动窗法依次判断所有可能的区域->候选区域
2.训练集:提取人工设定的特征->训练深度网络进行特征提取
一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万图像,1000类。
一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置。一万图像,20类。
本文使用识别库进行预训练,而后用检测库调优参数。最后在检测库上评测。
目标检测有两个主要任务:物体分类和定位,
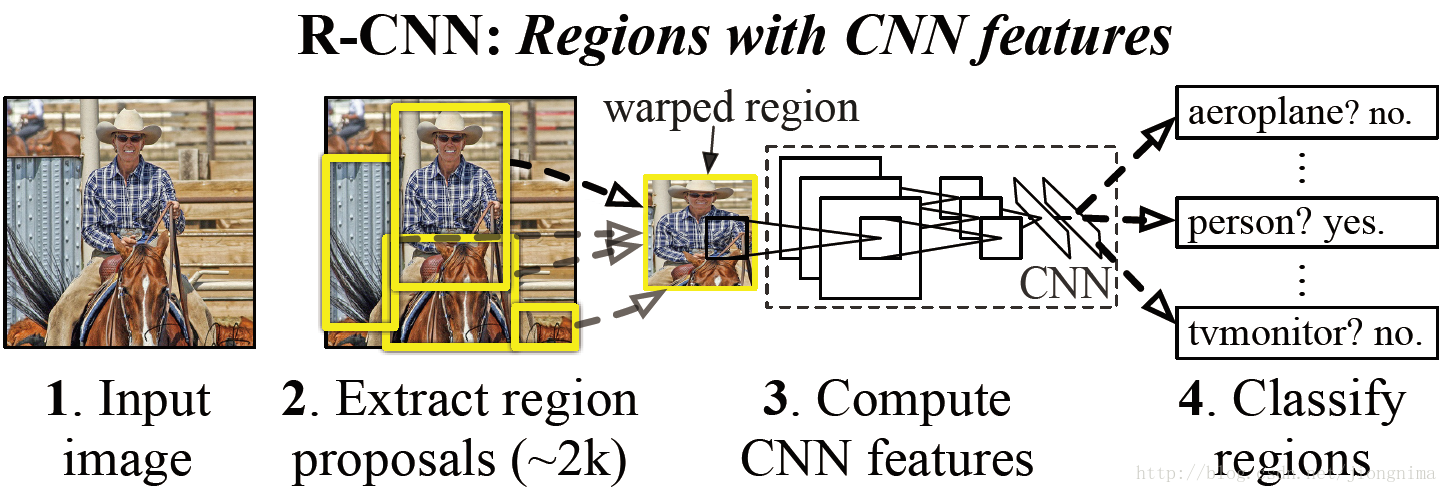
R-CNN借鉴了滑动窗口思想, 采用对区域进行识别的方案,
具体是:
1.一张图像,生成1K~2K个类别独立的候选区域(可能目标区域)
2.对于每个候选区域,利用卷积神经网络来获取一个特征向量
3.对于每个区域相应的特征向量,利用支持向量机SVM 进行分类,判别是否属于该类
4.通过一个bounding box regression回归器调整目标包围框的大小
1.1提取候选区域
R-CNN 采用的是 Selective Search 算法。
1.将图像分成很多小尺寸区域,
2.根据其特征合并合并可能性最高的得到大尺寸区域,
3.重复直到整张图像合并成一个区域位置,
4.输出所有曾经存在过的区域,所谓候选区域
1.1.1合并规则
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 面积,合并后小的(保证合并操作的尺度较为均匀,避免大区域“吃掉”其他小区域。)
- 位置,总面积在其BBOX中所占比例大的(保证合并后形状规则)
合并后的区域特征可以直接由子区域特征计算而来,速度较快。
1.1.2多样化与后处理
为尽可能不遗漏候选区域,上述操作在多个颜色空间中同时进行(RGB,HSV,Lab等)。
在一个颜色空间中,使用上述四条规则的不同组合进行合并。
所有颜色空间与所有规则的全部结果,在去除重复后,都作为候选区域输出。
1.2特征提取
1.2.1预处理
用CNN提取对应的特征向量,用模型AlexNet (2012)。
(Alexnet 的输入图像大小是 227x227,而通过 Selective Search 产生的候选区域大小不一,
为了与 Alexnet 兼容,R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,归一化为 227x227 的尺寸)
外扩的尺寸大小,形变时是否保持原比例,对框外区域直接截取还是补灰。会轻微影响性能。
2.Fast RCNN
1.首先还是采用selective search提取2000个候选框RoI
2.使CNN直接特征提取全图的特征图
3.使用一个RoI Pooling Layer在特征图上摘取每一个候选框RoI的特征
4.分别经过为21和84维的全连接层(并列的,前者是分类输出,后者是回归输出)
避免了R-CNN中的对每个候选框串行进行卷积(耗时较长)。
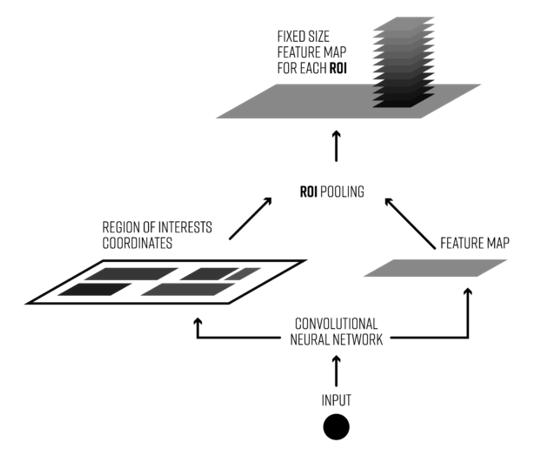
2.1RoI Pooling Layer
RoI Pooling:
1.将每个RoI映射到特征图对应位置,获取对应特征
2.将每个RoI对应的特征的维度转化成某个定值。
(每一个RoI的尺度各不相同,所以提取出来的特征向量region proposal维度也不尽相同,以满足全连接层的输入需求)
-
将region proposal划分为目标H×W大小的分块
-
对每一个分块中做MaxPooling(每个分块中含有多个网格,每个分块获取一个特征值)
-
将所有输出值组合起来便形成固定大小为H×W的feature map
-




pooling主要作用是减少运算量,但会降低performance

Fast R-CNN的贡献可以主要分为两个方面:
取代R-CNN的串行特征提取方式,直接采用一个CNN对全图提取特征(这也是为什么需要RoI Pooling的原因)。
除了selective search,其他部分都可以合在一起训练。
Fast R-CNN也有缺点,体现在耗时的selective search还是依旧存在。
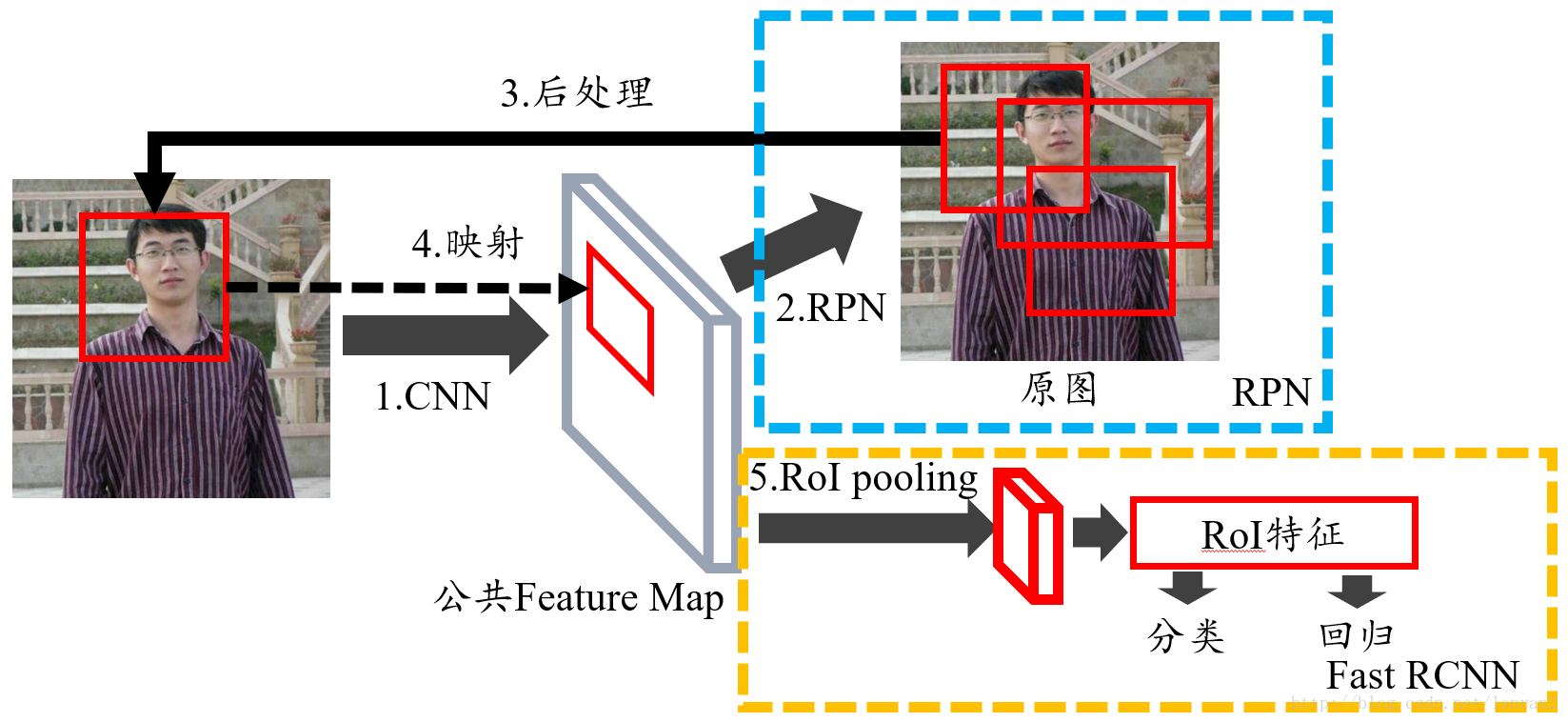
Faster RCNN
Faster R-CNN 取代selective search,直接通过Region Proposal Network (RPN)生成待检测区域
结构
Faster RCNN = RPN + Fast RCNN
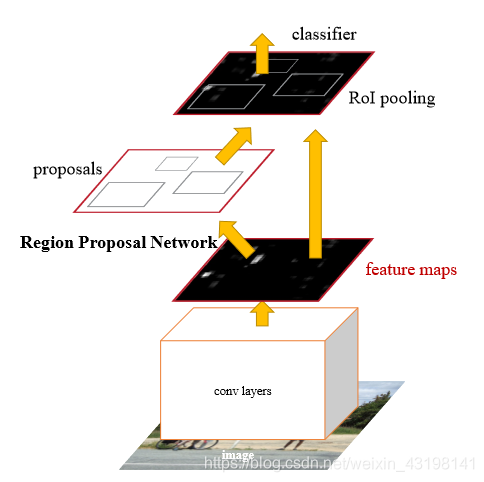
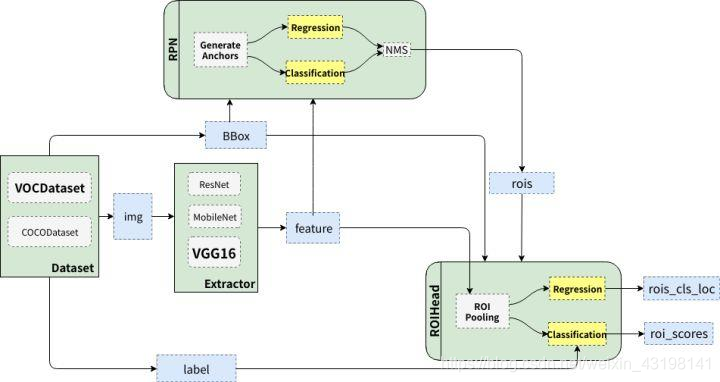
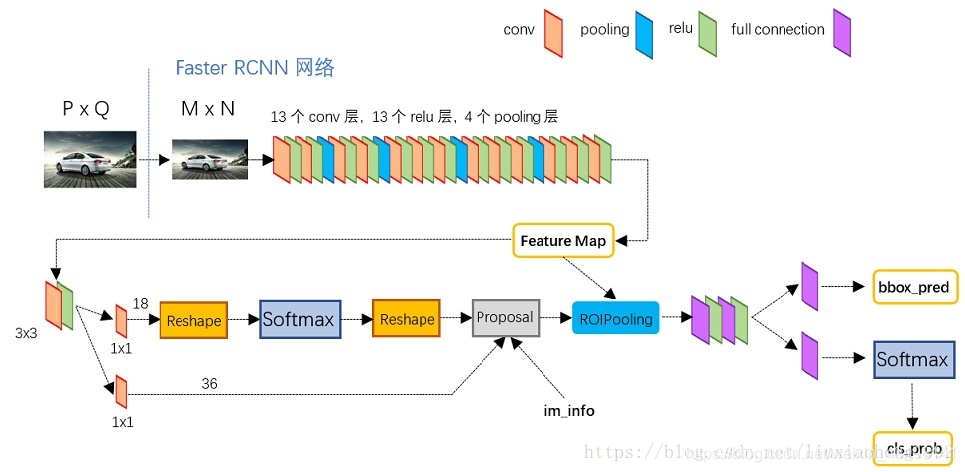 1.共享卷积层为全图提取特征feature maps
1.共享卷积层为全图提取特征feature maps
2.将feature maps送入RPN,RPN生成待检测框(指定RoI的位置),并对RoI的包围框进行第一次修正
3.RoI Pooling Layer根据RPN的输出在feature map上面选取每个RoI对应的特征,将维度置为定值
4.使用全连接层(FC Layer)对框进行分类,并且进行目标包围框的第二次修正。
Faster R-CNN真正实现了端到端的训练(end-to-end training)。
最大特色是使用了RPN取代了SS(selective search)算法来获取RoI
RPN
Region Proposal Network,Region Proposal“区域选取”,提取候选框的网络;
RCNN和Fast RCNN等物体检测架构中,用来提取候选框的方法通常是Selective Search

目标定位:
上面一条通过softmax来分类anchors获得前景foreground(检测目标)和背景background
下面一条计算anchors边框偏移量,获得精确的proposals
proposal层则负责综合foreground anchors和偏移量获取proposals,
同时剔除太小和超出边界的proposals。
anchor(目标框)
RPN依靠一个在共享特征图上滑动的窗口,为每个位置生成9种预先设置好长宽比与面积的目标框这9种初始anchor包含三种面积(128×128,256×256,512×512),
每种面积又包含三种长宽比(1:1,1:2,2:1)

共享特征图的大小约为40×60,RPN生成的初始anchor的总数约为20000个(40×60×9)。
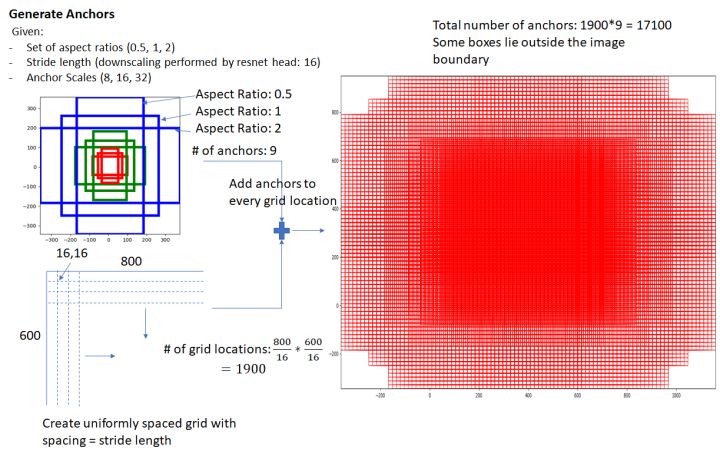
RPN最终就是在原图尺度上,设置了密密麻麻的候选anchor。
1.判断anchor到底是前景还是背景,就是判断这个anchor到底有没有覆盖目标
(SoftmaxLoss直接训练,在训练的时候排除掉了超越图像边界的anchor;
anchor与ground truth的IoU在0.7以上,那这个anchor就算前景(positive)
anchor与ground truth的IoU在0.3以下,那这个anchor就算背景(negative)
Intersection over Union(IoU)检测相应物体准确度的一个标准)
2.前景的anchor进行第一次坐标修正。
绿色表示的是飞机的实际框标签(ground truth),
红色的表示的其中一个候选区域(foreground anchor),即被分类器识别为飞机的区域,

对于目标框一般使用四维向量来表示(x,y,w,h)(x,y,w,h) ,分别表示目标框的中心点坐标、宽、高,
AA 表示原始的foreground anchor,GG 表示目标的ground truth,

寻找变换FF ,使得输入原始的Anchor AA 经过映射到一个和真实框GG 更接近的回归窗口G′G′


BB回归Bounding-box regression边框回归,回归分析”是指分析因变量和自变量之间关系

平移
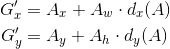
缩放

需要学习四个参数
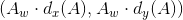 两个框中心距离的偏移量
两个框中心距离的偏移量
当输入的anchor A与G相差较小时,可以认为这种变换是一种线性变换

一个1×1的卷积层输出了18个值,每一个点对应9个anchor,
每个anchor有一个前景分数和一个背景分数,所以9×2=18

另一个1×1的卷积层输出了36个值,每一个点对应9个anchor,
每个anchor对应了4个修正坐标的值,所以9×4=36。
分类和定位
训练分类器和RoI边框修正:
1.通过RPN生成约20000个anchor(40×60×9)。
2.对20000个anchor进行第一次边框修正,得到修订边框后的proposal。
3.对超过图像边界的proposal的边进行clip,使得该proposal不超过图像范围。
4.忽略掉长或者宽太小的proposal。
5.将所有proposal按照前景分数从高到低排序,选取前12000个proposal。
6.使用阈值为0.7的NMS算法排除掉重叠的proposal。
7.针对上一步剩下的proposal,选取前2000个proposal进行分类和第二次边框修正。
Faster R-CNN的loss分两大块,
第一大块是训练RPN的loss(包含一个SoftmaxLoss和SmoothL1Loss),
第二大块是训练Faster R-CNN中分类器的loss(包含一个SoftmaxLoss和SmoothL1Loss)
Mask RCNN
- Mask RCNN可以看做是一个通用实例分割架构。
- Mask RCNN以Faster RCNN原型,增加了一个分支用于分割任务。
- Mask RCNN比Faster RCNN速度慢一些,达到了5fps。
- 可用于人的姿态估计等其他任务;
框架
模块:Faster-RCNN、RoI Align和Mask
算法
1.将预处理好的图片输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
2.对这个feature map中的每一点设定预定一个的RoI,从而获得多个候选RoI;
3.将候选RoI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
4.对这些剩下的RoI进行RoIAlign操作
(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
5.对这些RoI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)。
Mask R-CNN可以增加不同的分支完成不同的任务,
可以完成目标分类、目标检测(object dection)、语义分割(semantic segmentation)、
实例分割(Instance Segmentation=object dection+semantic segmentation)、人体姿势识别等多种任务,如下图所示。

RoIAlign
取代了Faster RCNN中的RoIPooling
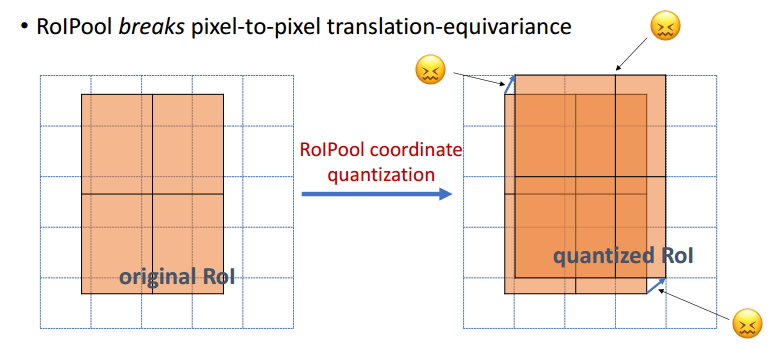
RoI Pooling使用了两次量化操作(即取整操作)
RoIAlign使用了线性插值算法

为了得到固定大小(7X7)的feature map,需要做两次量化操作:
1)图像坐标 — feature map坐标,
2)feature map坐标 — RoI feature坐标。
1)输入的是一张800x800的图像,在图像中有两个目标(猫和狗),狗的BB大小为665x665,
经过VGG16网络后,可以获得对应的feature map,
对卷积层进行Padding操作,图片经过卷积层后保持原来的大小,
feature map经过池化层,会比原图缩小一定的比例,这和Pooling层的个数和大小有关。
在该VGG16中,我们使用了5个池化操作,每个池化操作都是2x2Pooling,
因此最终获得feature map的大小为800/32 x 800/32 = 25x25(是整数),
但是将狗的BB对应到feature map上面,我们得到的结果是665/32 x 665/32 = 20.78 x 20.78,
结果是浮点数,含有小数,但是我们的像素值可没有小数,
对其进行了量化操作(即取整操作),即其结果变为20 x 20,在这里引入了第一次的量化误差;
2)feature map中有不同大小的ROI,但是后面的网络却要求有固定的输入,
需要将不同大小的ROI转化为固定的ROI feature,在这里使用的是7x7的ROI feature,
那么需要将20 x 20的ROI映射成7 x 7的ROI feature,其结果是 20 /7 x 20/7 = 2.86 x 2.86,
在这里引入了第二次量化误差(即取整操作)
这里引入的误差会导致图像中的像素和特征中的像素的偏差,
即将feature空间的ROI对应到原图上面会出现很大的偏差。
feature空间和图像空间是有比例关系的,在这里是1:32,那么对应到原图上面的差距就是0.86 x 32 = 27.52这会大大影响整个检测算法的性能,因此是一个严重的问题。

双线性插值是一种比较好的图像缩放算法,
它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)
四周的四个真实存在的像素值来共同决定目标图中的一个像素值,
即可以将20.56这个虚拟的位置点对应的像素值估计出来。
蓝框表示卷积后获得的feature map,黑框表示ROI feature,最后需要输出的大小是2x2,
用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值,
蓝点是2x2Cell中的随机采样的普通点,这些采样点的个数和位置不会对性能产生很大的影响,
在每一个橘红色的区域里面进行max pooling或者average pooling操作,获得最终2x2的输出结果。
原图中的像素和feature map中的像素是完全对齐的,没有偏差,
这不仅会提高检测的精度,同时也会有利于实例分割。

Mask branch

mask分支只做语义分割
RoI Align后有一个"head"部分,主要作用将RoI Align的输出维度扩大,在预测Mask时会更加精确。
在Mask Branch的训练环节,输出了K个Mask预测图(为每一个类都输出一张),
并采用average binary cross-entropy loss训练,
训练Mask branch时,输出的K个特征图中,只对应ground truth类别的特征图对Mask loss有贡献。
SSD
(SSD: Single Shot MultiBox Detector)
上面分析了YOLO存在的问题,使用整图特征在7*7的粗糙网格内回归对目标的定位并不是很精准。那是不是可以结合Region Proposal的思想实现精准一些的定位?SSD结合YOLO的回归思想以及Faster R-CNN的anchor机制做到了这点。
上图是SSD的一个框架图,首先SSD获取目标位置和类别的方法跟YOLO一样,都是使用回归,但是YOLO预测某个位置使用的是全图的特征,SSD预测某个位置使用的是这个位置周围的特征(感觉更合理一些)。
那么如何建立某个位置和其特征的对应关系呢?可能你已经想到了,使用Faster R-CNN的anchor机制。如SSD的框架图所示,假如某一层特征图(图b)大小是8*8,那么就使用3*3的滑窗提取每个位置的特征,然后这个特征回归得到目标的坐标信息和类别信息(图c)。
不同于Faster R-CNN,这个anchor是在多个feature map上,这样可以利用多层的特征并且自然的达到多尺度(不同层的feature map 3*3滑窗感受野不同)。
小结:SSD结合了YOLO中的回归思想和Faster R-CNN中的anchor机制,使用全图各个位置的多尺度区域特征进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster R-CNN一样比较精准。SSD在VOC2007上mAP可以达到72.1%,速度在GPU上达到58帧每秒。
FCOS
论文名称:FCOS: Fully Convolutional One-Stage Object Detection
论文下载地址:
https://arxiv.org/abs/1904.01355
https://arxiv.org/abs/2006.09214 (注:2020年更新后的版本,比如center-ness分支有些小改动)
在bilibili上的视频讲解:https://www.bilibili.com/video/BV1G5411X7jw
单阶段的anchor-free
参考链接:目标检测综述_计算机视觉life的博客-CSDN博客_目标检测
【目标检测】RCNN算法详解_shenxiaolu1984的博客-CSDN博客_rcnn算法
Faster RCNN详解_小白的深度学习之路的博客-CSDN博客_faster r-cnn
RPN 解析_懒人元的博客-CSDN博客_rpn
【Mask RCNN】论文详解(真的很详细)_咖啡味儿的咖啡的博客-CSDN博客_mask rcnn论文
目标检测(Object Detection)_图像算法AI的博客-CSDN博客_目标检测
一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD_v_JULY_v的博客-CSDN博客_r-ssdFCOS网络解析_太阳花的小绿豆的博客-CSDN博客_fcos网络
FCOS算法详解_技术挖掘者的博客-CSDN博客_fcos算法