写前一篇文章TCP的乱序和丢包判断(附Reordering更新算法)-理论的时候,我觉得我在一边拉一边吃,玩的都是排泄物,言之无味,不知所云,我想把一些能看得见摸得着的东西独立出来,就成了本文,如果有一天我忘掉了TCP的细节,我想我直接把本文的例子跑一遍,应该就能拾起个大概了。
声明
本文完全旨在解释上一篇文章里那些枯燥的理论,我实在是觉得自己文字功底差,一直以来都倾向于用例子来给出解释。花了点时间整理了几个用例,希望能把问题解释清楚。在用实例解释问题的时候,最忌讳的是把很多因素杂糅了一起,因为本来就是通过特例解释,并没有完备性支撑,所以我尽量把问题孤立化,加之以前也写了不少文章解释其它的方面,所以本文的所有用例均采用以下的配置:
net.ipv4.tcp_fack = 0
net.ipv4.tcp_sack = 1
net.ipv4.tcp_congestion_control = cubic
关于fack开启的情形,请自行分析。另外本文的主要目的是解释reordering相关的,不是拥塞算法,所以默认采用了cubic算法,至于其它的比如bbr算法(以及任何携带cong_control回调的拥塞控制算法)下是什么表现,本文不涉及。
另外,本文的所有实例均是packetdrill脚本,如果你不会的话就请自行谷歌百度packetdrill的使用方法并下载安装,本文并不负责介绍关于packetdrill的任何东西,给出一个链接算是比较厚道了:Packetdrill 简明使用手册。
case 1:认识乱序空洞左边缘确定
这个用例可以让你清晰看懂如何来确定乱序空洞的边缘在哪里以及如何确定。为此我准备了两个packetdrill脚本来进行对比性解释。首先看第一个,packetdrill代码如下:
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_SOCKET, SO_REUSEPORT, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 32792
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
// 确保已经确认到了1001
+.1 < . 1:1(0) ack 1001 win 32792
// 连续发送10个段
+0 write(4, ..., 10000) = 10000
+.0 %{ print tcpi_reordering }%
// 重复确认1001,同时携带一个6001-7001的SACK
+.1 < . 1:1(0) ack 1001 win 257 <sack 6001:7001,nop,nop>
// 随即重复确认1001,同时再携带两个SACK
+.0 < . 1:1(0) ack 1001 win 257 <sack 2001:3001 9001:10001,nop,nop>
+.0 %{ print tcpi_reordering }%
// 最终完全确认10个数据包
+5 < . 1:1(0) ack 10001 win 257
+.0 %{ print tcpi_reordering }%
以下是脚本的输出:
3
8
8
下面我给出一个解析,解释发生了什么。我把整个事情发生的过程整理成下图:
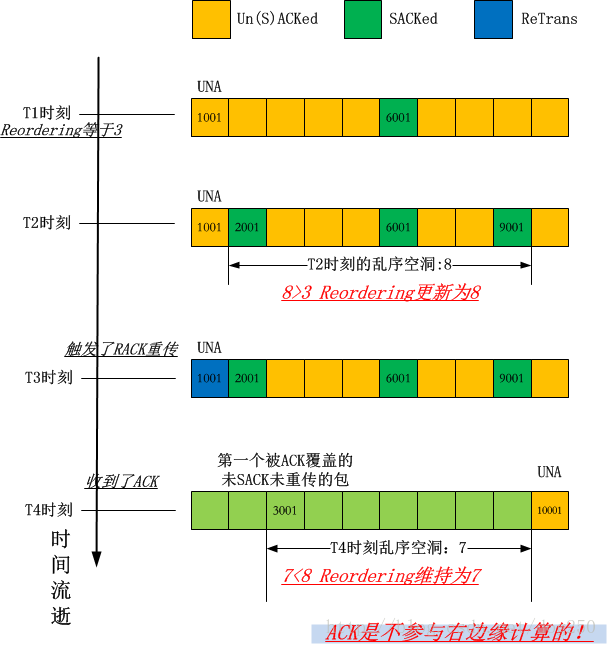
可见,虽然输出的是3,8,8,但事实上,由于reordering值的更新是单调递增的,所以reordering值经过的第二次8到7的更新是失败的,真实的reordering更新尝试应该是3,8,7.
最终我们来看一下以上脚本过程的抓包:
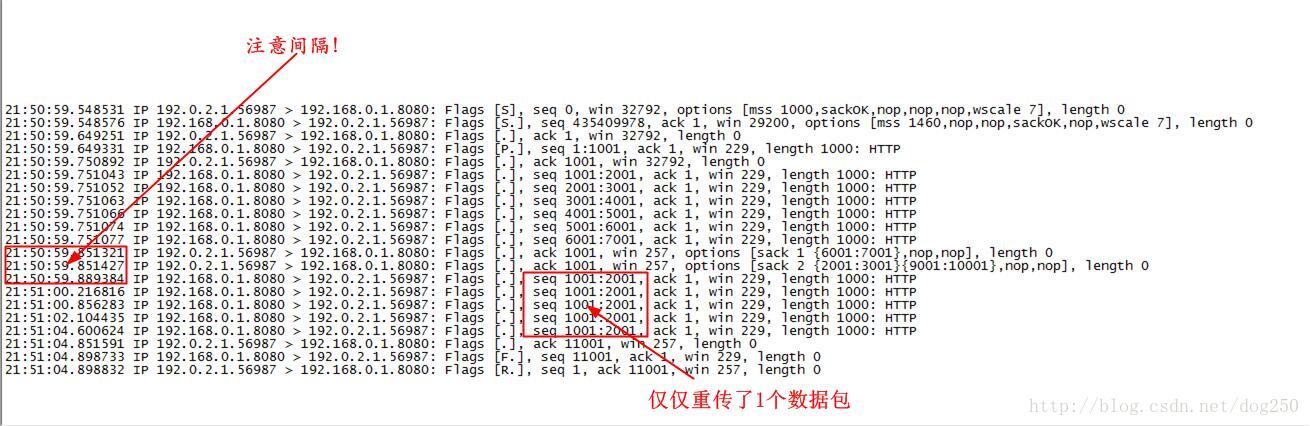
第一个脚本到此结束了。
接下来我们看下case 1的第二个例子,该例子说明了乱序空洞的右边缘如何确定。首先还是先给出packetdrill脚本的代码:
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_SOCKET, SO_REUSEPORT, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 32792
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 32792
+0 write(4, ..., 10000) = 10000
+.0 %{ print tcpi_reordering }%
+.1 < . 1:1(0) ack 1001 win 257 <sack 2001:3001 9001:10001,nop,nop>
+.0 < . 1:1(0) ack 1001 win 257 <sack 6001:7001,nop,nop>
+.0 %{ print tcpi_reordering }%
+5 < . 1:1(0) ack 10001 win 257
+.0 %{ print tcpi_reordering }%
它的输出是:
3
4
7
以下是关于该脚本运行时的图解:
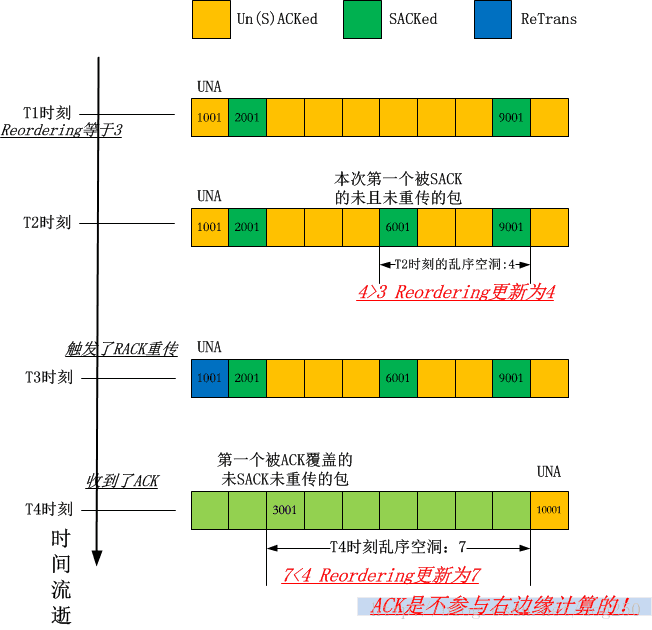
依然有抓包来确认:
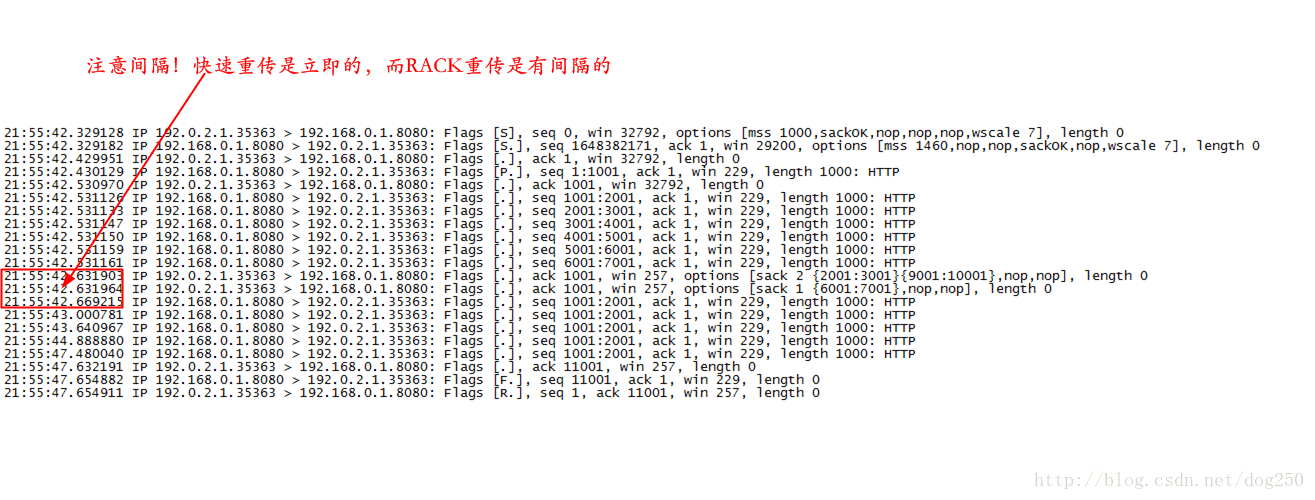
也许,到底为止,事情应该结束了,你也应该完全明白了乱序空洞左右边缘的确定方法以及reordering值的更新机制,但是且慢,还有一个更好的例子呢。该case的最后一个例子,旨在解释在收到携带SACK的ACK包时,遍历传输队列以求取乱序空洞左右边缘的过程。该例子的packetdrill代码如下:
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_SOCKET, SO_REUSEPORT, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 32792
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 32792
+0 write(4, ..., 10000) = 10000
+.0 %{ print tcpi_reordering }%
+.1 < . 1:1(0) ack 1001 win 257 <sack 3001:4001,nop,nop>
+.0 < . 1:1(0) ack 1001 win 257 <sack 4001:5001 9001:10001,nop,nop>
+.0 %{ print tcpi_reordering }%
+5 < . 1:1(0) ack 10001 win 257
+.0 %{ print tcpi_reordering }%
它的输出是:
3
3
3
为什么reordering值没有变化?这是一个问题。按照左边缘和右边缘的确定方法,右边缘显然是9001开始的数据包,而左边缘是4001开始的数据包,这样一来reordering的值应该更新为6才对啊!但事实证明,reordering值并没有变化,依然是3,这是为什么?因为后一个ACK包携带的第一个SACK包在之前的最右边的SACK包3001之后,这明显是一个按序的确认,何来乱序呢?
从常理上分析更容易理解,第一个SACK确认了3001开始的一个数据包,第二个SACK确认了从4001开始以及从9001开始的两个数据包,先发送的先被确认,这并不能表明出现了乱序啊,事实证明确实没有判定为乱序。确认了这一点之后,我们再来看收到SACK之后遍历TCP传输队列以确定乱序空洞左右边缘的算法:
for each skb in write-queue
if thisSACK contains skb && skb.SACKed == FALSE && skb.RETRANS == FALSE && skb < Hr
Hl = skb
if thisSACK contains skb
Hr = skb
skb.SACKed = TRUE
if Hr > Hl && (Hr - Hl + 1 > reordering)
reordering = Hr - Hl + 1
请注意skb < Hr这个判断条件,想要让一个最新被SACK的数据包成为左边缘,不仅仅要求它此前没有被SACK以及此前没有被重传,还要求它不超过此前的右边缘。有了这个判定,对于事情的理解就简单多了。有了这个理解,我们来猜一下下面脚本的结果:
...
+0 write(4, ..., 10000) = 10000
+.0 %{ print tcpi_reordering }%
+.1 < . 1:1(0) ack 1001 win 257 <sack 3001:4001 8001:9001,nop,nop>
+.0 < . 1:1(0) ack 1001 win 257 <sack 4001:5001 9001:10001,nop,nop>
+.0 %{ print tcpi_reordering }%
+5 < . 1:1(0) ack 10001 win 257
+.0 %{ print tcpi_reordering }%
显然,答案是:
3
6
8
好的,现在我们进入下一个更加简单些的用例。
case 2 认识RACK机制与reordering值的关系
依旧先看一个脚本:
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_SOCKET, SO_REUSEPORT, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 32792
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 32792
+0 write(4, ..., 10000) = 10000
+.0 %{ print tcpi_reordering }%
+.1 < . 1:1(0) ack 1001 win 257 <sack 2001:3001 9001:10001,nop,nop>
// 间隔一些时间再SACK新的数据包
+.1 < . 1:1(0) ack 1001 win 257 <sack 5001:6001,nop,nop>
+.0 %{ print tcpi_reordering }%
+5 < . 1:1(0) ack 10001 win 257
+.0 %{ print tcpi_reordering }%
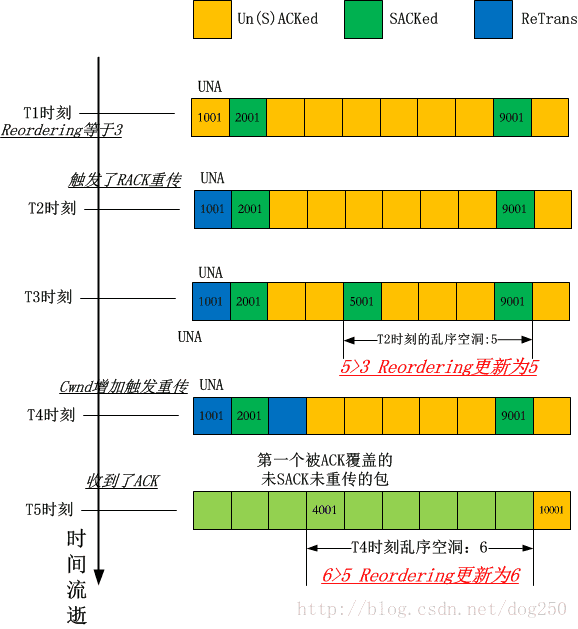
输出是:
3
5
6
以下给出一个图解,解释一下为什么:
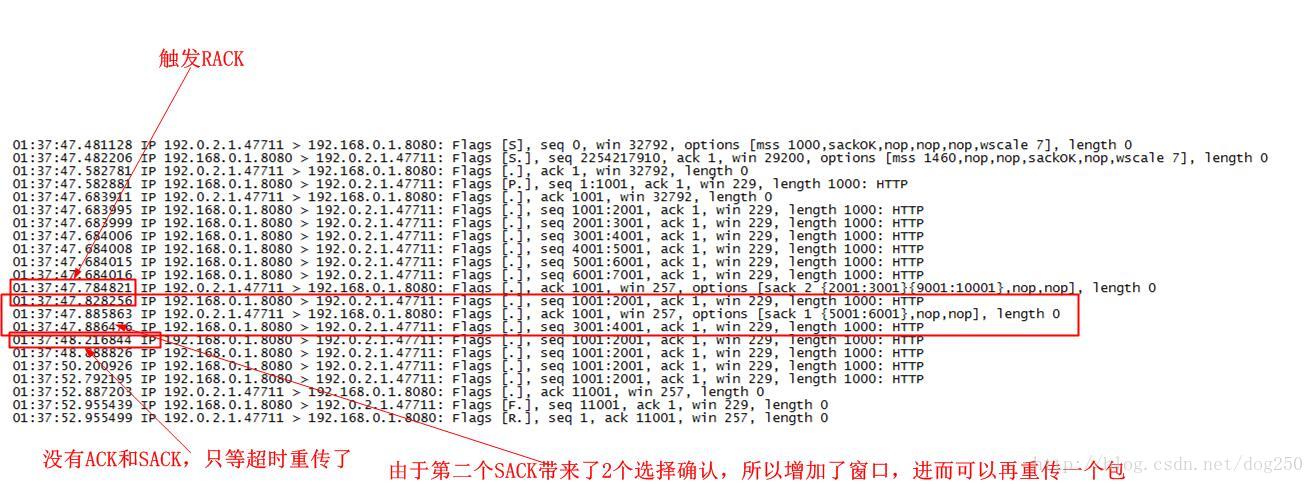
下面是抓包的分析确认:
如果我们连续发送两个SACK,不给RACK定时器超时的机会会怎样?下面我们就试一下,请运行下面的packetdrill脚本:
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_SOCKET, SO_REUSEPORT, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 32792
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 32792
+0 write(4, ..., 10000) = 10000
+.0 %{ print tcpi_reordering }%
+.1 < . 1:1(0) ack 1001 win 257 <sack 2001:3001 9001:10001,nop,nop>
// 立即SACK新的数据包
+.0 < . 1:1(0) ack 1001 win 257 <sack 5001:6001,nop,nop>
+.0 %{ print tcpi_reordering }%
+5 < . 1:1(0) ack 10001 win 257
+.0 %{ print tcpi_reordering }%
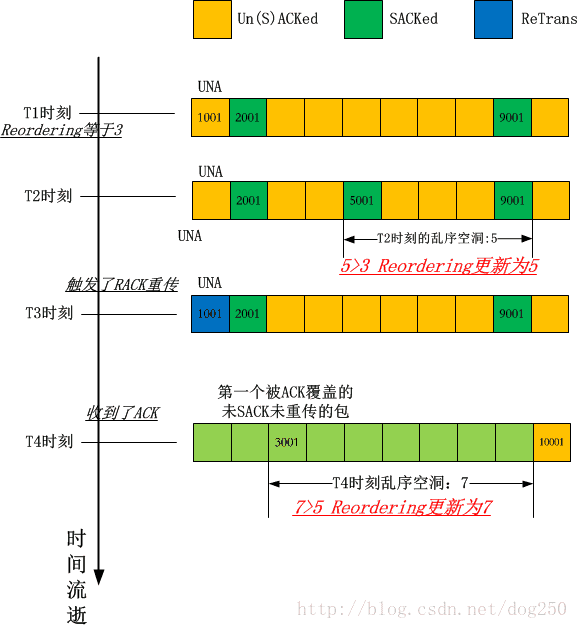
输出是:
3
5
7
下面是一个图解:
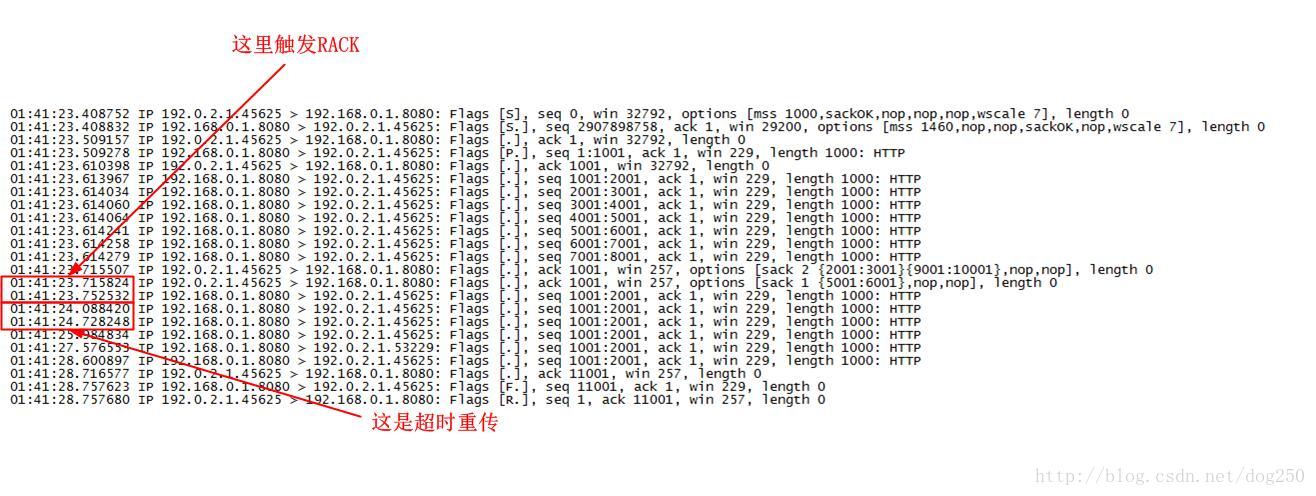
依然给出抓包分析:
看来,归根结底这并不是RACK的影响,而是RACK定时器的触发影响了TCP的拥塞窗口,导致两种情况下重传的数据包数量不同,进而造成了两种情况下乱序空洞的左边缘不同(左边缘不能被重传过),最终左右边缘的间距不同。
接下来,我们看个更简单的用例。
case 3 认识reordering更新与快速重传的先后顺序
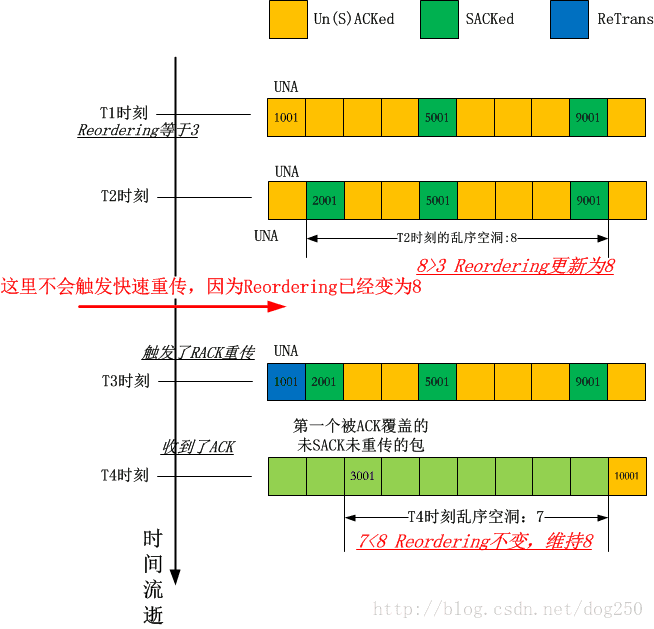
假设当前的reordering值是默认值3,开启SACK的情况下,有人会说,为什么已经有3个数据包被SACK,依然没有触发快速重传呢?比如下面的脚本所示:
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_SOCKET, SO_REUSEPORT, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 32792
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 32792
+0 write(4, ..., 10000) = 10000
+.0 %{ print tcpi_reordering }%
+.1 < . 1:1(0) ack 1001 win 257 <sack 5001:6001 9001:10001,nop,nop>
// 如果下面的这行不是随即确认,而是间隔一段时间(把+.0改成+.1),待RACK超时发生重传后,情况将会有大不同,请自行分析!
+.0 < . 1:1(0) ack 1001 win 257 <sack 2001:3001,nop,nop>
+.0 %{ print tcpi_reordering }%
+5 < . 1:1(0) ack 10001 win 257
+.0 %{ print tcpi_reordering }%
输出如下:
3
8
8
从输出上看,在收到第二个包含两个SACK段的包后,虽然被SACK的包量达到了3个,但是此时的reordering值已经更新,可见reordering值的更新在判断快速重传条件之前!
下面是一个图解:
下面给出抓包分析:

注意,虽然数据包被重传了,但不是快速重传所触发,而是RACK超时所触发!作为一个反过来的例子,下面的脚本可以印证上面的说法:
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_SOCKET, SO_REUSEPORT, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 32792
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 32792
+0 write(4, ..., 10000) = 10000
+.0 %{ print tcpi_reordering }%
+.1 < . 1:1(0) ack 1001 win 257 <sack 5001:6001 9001:10001,nop,nop>
+.0 < . 1:1(0) ack 1001 win 257 <sack 7001:8001,nop,nop>
+.0 %{ print tcpi_reordering }%
+5 < . 1:1(0) ack 10001 win 257
+.0 %{ print tcpi_reordering }%
输出如下:
3
3
6
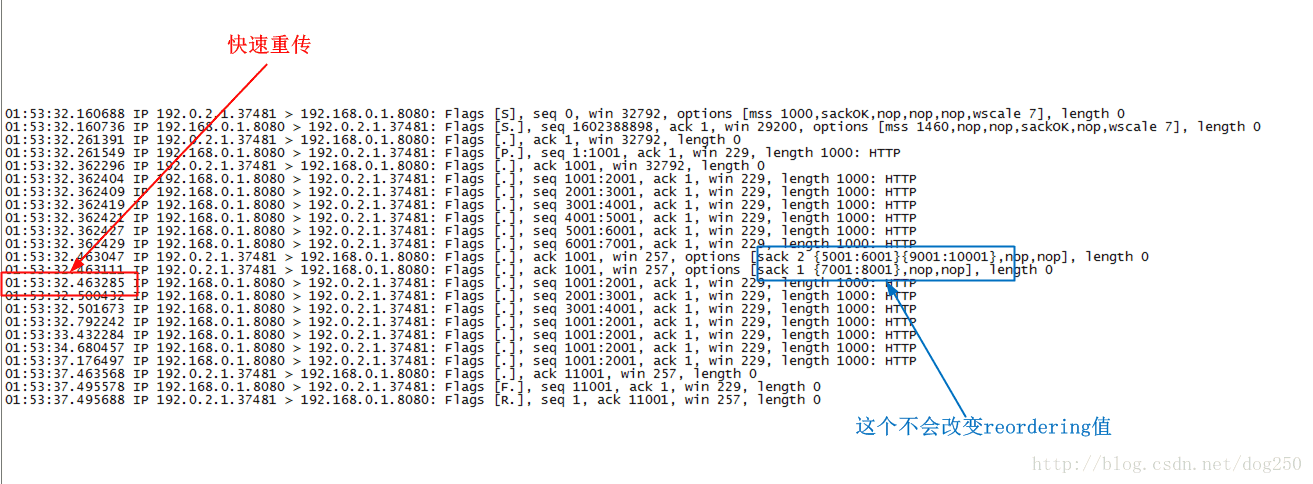
该脚本几乎和上面的脚本没有什么区别,只是把第3个SACK从2001开始的包改成了从7001开始的包,按照reordering值的更新算法,这次将不会引发reordering值的更新,进而在收到3个SACK后触发快速重传,从下面的抓包分析中能看出来确实触发了快速重传:
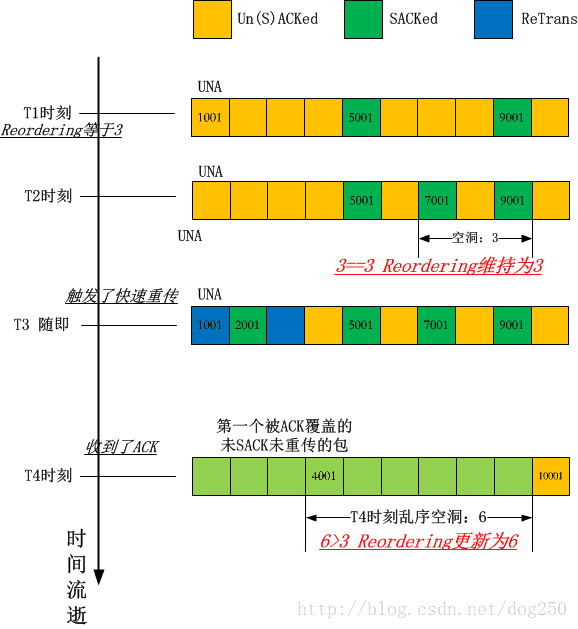
以下是针对上述脚本的图解:
我们来看最后一个用例。
case 4 理解TCP记分板Mark lost算法的自适应性
这块内容比较独立,理论上的东西请参考我此前的文章:关于TCP快速重传的细节-重传优先级与重传触发条件。本文给出两个实际的例子来解释枯燥的理论。首先看第一个例子,该例子中,被SACK的包聚集于后面:
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_SOCKET, SO_REUSEPORT, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 32792
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 32792
+0 write(4, ..., 10000) = 10000
// 被SACK的包量大于3,触发快速重传,快速重传前进行数据包的LOST标记
+.1 < . 1:1(0) ack 1001 win 257 <sack 5001:10001,nop,nop>
+5 < . 1:1(0) ack 10001 win 257
很显然,按照Mark LOST算法,在最后保留reordering个被SACK的数据包,本例中,前面所有的数据包均将被标记为LOST,事实也正是如此!在我的probe输出中,一共有4个包被标记为LOST:
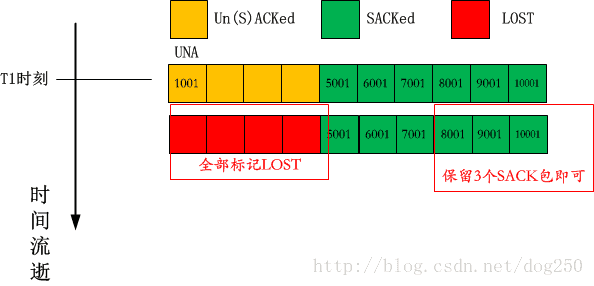
下面是此例的抓包分析:
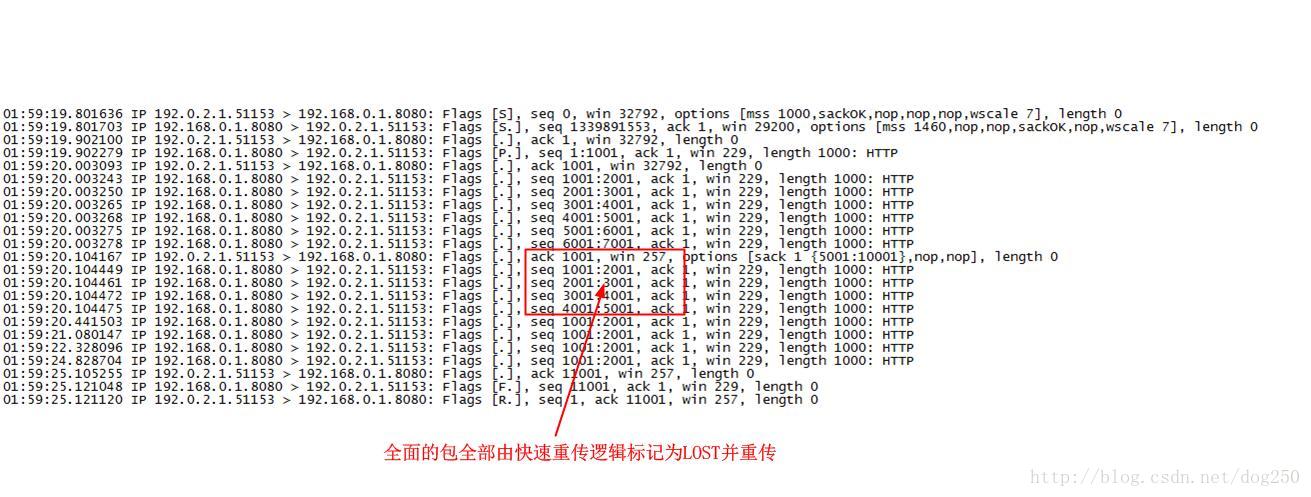
再看一个例子,该例子中,被SACK的数据包聚集于前面:
0 socket(..., SOCK_STREAM, IPPROTO_TCP) = 3
+0 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0 setsockopt(3, SOL_SOCKET, SO_REUSEPORT, [1], 4) = 0
+0 bind(3, ..., ...) = 0
+0 listen(3, 1) = 0
+0 < S 0:0(0) win 32792 <mss 1000,sackOK,nop,nop,nop,wscale 7>
+0 > S. 0:0(0) ack 1 <...>
+.1 < . 1:1(0) ack 1 win 32792
+0 accept(3, ..., ...) = 4
+0 write(4, ..., 1000) = 1000
+.1 < . 1:1(0) ack 1001 win 32792
+0 write(4, ..., 10000) = 10000
+.1 < . 1:1(0) ack 1001 win 257 <sack 2001:6001 9001:10001,nop,nop>
// 以下的打印不一定准确,因为存在一个异步的RACK定时器超时的过程,该过程同样会进行LOST标记,且与tcp_get_info的调用顺序不确定。
// 因此需要采用tcp_probe的方式,HOOK住tcp_xmit_recovery函数,然后打印tp->lost_out的值最为准确和实时。
+.0 %{ print tcpi_lost }%
+5 < . 1:1(0) ack 10001 win 257
依然用probe输出,被标记为LOST的包量仅为1!如下图所示:
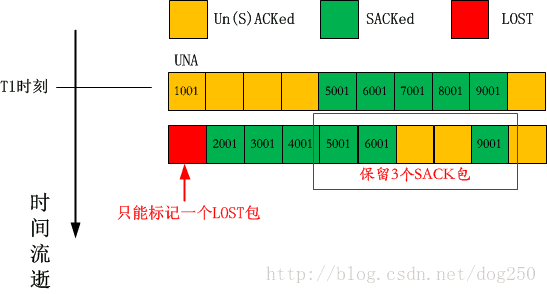
我们再看下抓包以确认上述分析:
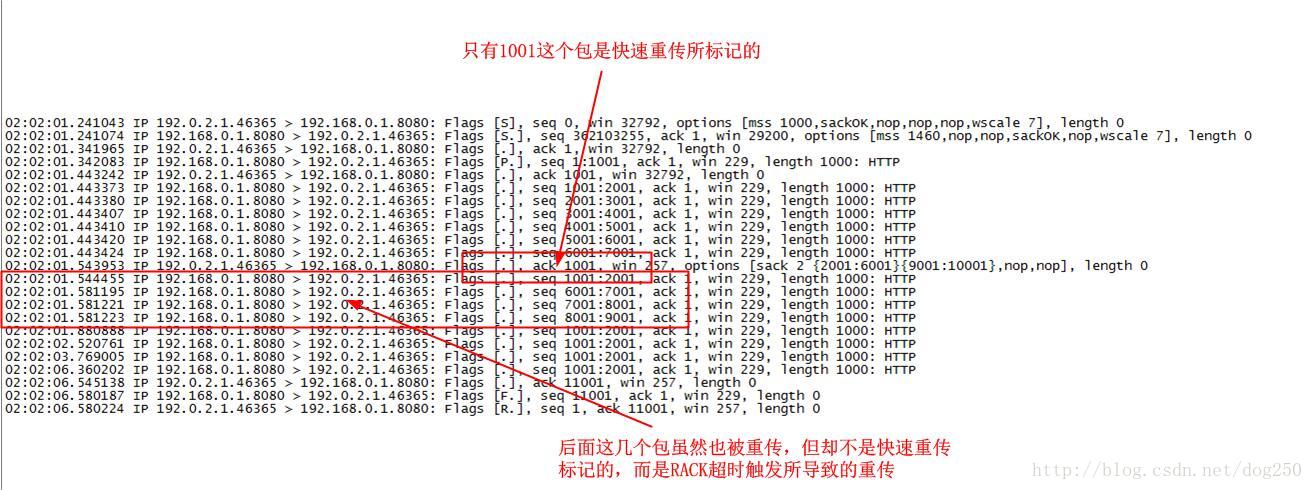
我们发现不止1个数据包被重传,然而仔细观察前面的时间戳后,发现从第二个重传包开始,便不再是快速重传所起的作用,而是RACK超时重传了,当RACK超时被触发后,有4个包被标记为LOST!在早期的内核中,RACK尚未文档化的时候,内核当然并没有引入RACK机制,没有RACK,就只能timeout了。引入了RACK,反而更加令人迷惑,然而正如抓包看到的那样,虽然没有触发快速重传,但不那么慢的间隔内,重传确实发生了,这就是RACK带来的东西。
遗留的问题
本文根本没有详述关于RACK的细节,但这并不意味着它不重要,RACK是作为时间序丢包判断最近才出现的,以下三类丢包判断是并列的:
- 空间序-dupthresh: 3 OOO packets delivered (packet count)
- 序列假定-FACK: sequence delta to highest sacked sequence (sequence space)
- 时间序-RACK: sent time delta to the latest delivered packet (time domain)
这些问题并没有在本文中进行论述,因为这个话题有点大,所以说就先略过了。