什么是图的遍历
图的遍历是对一张图中所有节点进行访问的过程。在图遍历中,我们从图中的某个节点开始,沿着边一直访问其他节点,直到访问完所有与该节点有连通关系的节点。遍历过程中需要遵循一定的遍历规则,常见的有深度优先遍历和广度优先遍历。深度优先遍历是从某个节点开始,尽可能深地访问其他节点,直到到达图的最底层,然后再回溯到上一级节点继续遍历。广度优先遍历则是逐层访问节点,先访问与当前节点相邻的所有节点,然后再访问与这些节点相邻的节点,以此类推,直到访问完所有节点为止。
图的深度优先遍历
代码
#include <bits/stdc++.h>
#define MAX 100
using namespace std;
int Visited[MAX];
typedef struct{
char vexs[MAX]; //顶点向量
int arcs[MAX][MAX]; //邻接矩阵
int vexnum,arcnum; //顶点数,边数
}AMGraph;
int Location(AMGraph G, char c) {
int i = 0;
for(; i < G.vexnum; i ++) {
if(G.vexs[i] == c) {
return i;
}
}
return -1;
}
void CreateUDG(AMGraph &G) {
scanf("%d %d", &G.vexnum, &G.arcnum);
int i = 0;
getchar();
for(i = 0; i < G.vexnum; i ++) {
scanf("%c", &G.vexs[i]);
}
int j = 0;
// 初始化
for(i = 0; i < G.vexnum; i ++) {
for(j = 0; j < G.vexnum; j ++) {
G.arcs[i][j] = 0;
}
}
char c1, c2;
int k = 0;
getchar();
for(i = 0; i < G.arcnum; i ++) {
scanf("%c %c", &c1, &c2);
getchar();
j = Location(G, c1);
k = Location(G, c2);
G.arcs[j][k] = 1;
G.arcs[k][j] = 1;
}
}
void DFS(AMGraph G, int v) {
int i = 0;
cout << G.vexs[v] << ' ';
Visited[v] = 1;
for(; i < G.vexnum; i ++) {
if(!Visited[i] && G.arcs[v][i] != 0) {
DFS(G, i);
}
}
}
int main() {
AMGraph G;
CreateUDG(G); // 创建图
int v; // 从v开始遍历
cin >> v;
DFS(G, v); // 深度优先搜索
return 0;
}
运行结果
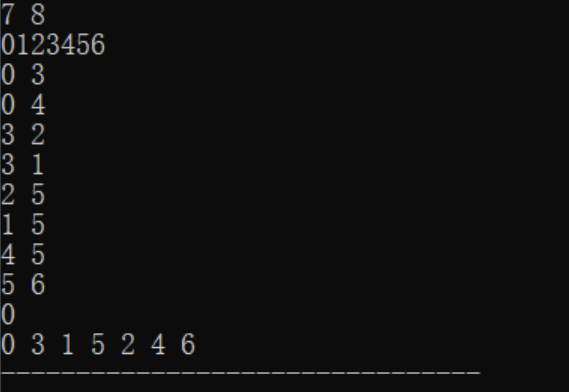
分析
图的深度优先搜索(DFS)是从图中一个开始节点出发,沿着一条路径访问到不能再访问为止,然后回溯到该节点的上一个节点,继续搜索下一条路径,直到访问完所有与该节点连通的节点。DFS通常使用递归的方式实现,其基本思路如下:
- 访问该节点,并标记该节点为已访问。
- 对该节点的所有未被访问过的相邻节点,递归调用DFS。
- 回溯到上一个节点,重复第2步,直到所有节点都被访问过。
DFS算法的时间复杂度为O(|V|+|E|),其中|V|为节点数,|E|为边数。在实际应用中,DFS常用于有向图、无向图的连通性判断、拓扑排序、MST等问题。
值得注意的是,DFS可能会陷入死循环,因此需要在遍历过程中通过标记节点来避免重复访问。此外,DFS的搜索路径具有单向性,很可能并不是最短路径,因此适用于要求不需要最短路径的问题。如果需要求最短路径,可以使用广度优先搜索。
图的广度优先遍历
代码
#include <bits/stdc++.h>
#define MAX 100
using namespace std;
int Visited[MAX];
typedef struct{
char vexs[MAX]; //顶点向量
int arcs[MAX][MAX]; //邻接矩阵
int vexnum,arcnum; //顶点数,边数
}AMGraph;
int Location(AMGraph G, char c) {
int i = 0;
for(; i < G.vexnum; i ++) {
if(G.vexs[i] == c) {
return i;
}
}
return -1;
}
void CreateUDG(AMGraph &G) {
scanf("%d %d", &G.vexnum, &G.arcnum);
int i = 0;
getchar();
for(i = 0; i < G.vexnum; i ++) {
scanf("%c", &G.vexs[i]);
}
int j = 0;
// 初始化
for(i = 0; i < G.vexnum; i ++) {
for(j = 0; j < G.vexnum; j ++) {
G.arcs[i][j] = 0;
}
}
char c1, c2;
int k = 0;
getchar();
for(i = 0; i < G.arcnum; i ++) {
scanf("%c %c", &c1, &c2);
getchar();
j = Location(G, c1);
k = Location(G, c2);
G.arcs[j][k] = 1;
G.arcs[k][j] = 1;
}
}
void BFS(AMGraph G, int v) {
printf("BFS from %d: ", v);
int line[MAX] = {0};
int front = 0;
int rear = 0;
int j = 0;
printf("%c ", G.vexs[v]);
Visited[v] = 1;
line[rear ++] = v;
while(rear != front) {
int i = line[front ++];
for(j = 0; j < G.vexnum; j ++) {
if(!Visited[j] && G.arcs[i][j]) {
printf("%c ", G.vexs[j]);
Visited[j] = 1;
line[rear ++] = j;
}
}
}
}
int main() {
AMGraph G;
CreateUDG(G); // 创建图
int v; // 从v开始遍历
cin >> v;
BFS(G, v); // 广度优先遍历
return 0;
}
运行结果
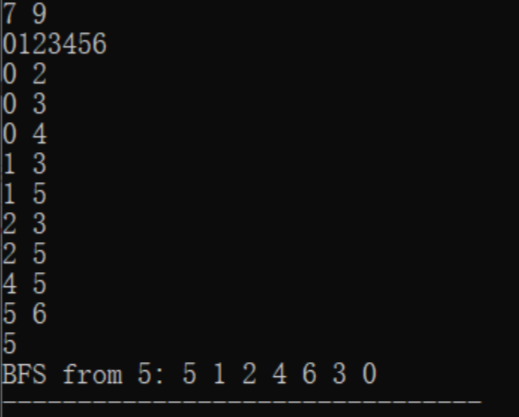
分析
图的广度优先搜索(BFS)是从指定的起点开始,沿着每条连接路径依次访问相邻的节点,直到所有节点都被访问。BFS使用队列来进行实现,其基本思路如下:
- 将起点加入队列,并标记该节点为已访问。
- 取出队列头部节点,对该节点的所有未被访问过的相邻节点,标记为已访问,并加入队列尾部。
- 重复第2步,直到队列为空。
BFS算法的时间复杂度同样为O(|V|+|E|),其中|V|为节点数,|E|为边数。BFS通常应用于计算最短路径、查找一组节点、遍历树等问题。
BFS搜索的路径具有层级性,最先访问到该节点的路径一定是最短的,因此适用于求解最短路径问题。此外,BFS的缺点是空间复杂度较高,需要使用队列进行存储,因此如果图的节点数比较大时,会占用较多的内存,可能导致程序执行缓慢。