(一)DenseNet
DenseNet作为另一种拥有较深层数的卷积神经网络,具有如下优点:
(1) 相比ResNet拥有更少的参数数量.
(2) 旁路加强了特征(feature)的重用.
(3) 网络更易于训练,并具有一定的正则效果.
(4) 缓解了gradient vanishing(梯度消失)和model degradation(模型退化)的问题
梯度消失问题在网络深度越深的时候越容易出现,原因就是输入信息和梯度信息在很多层之间传递导致的,而现在这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题。
这种dense connection有正则化的效果,因此对于过拟合有一定的抑制作用,可能是因为参数减少了,所以过拟合现象减轻。
(二)DenseNet网络结构
(1)dense block
对比于ResNet的Residual Block,创新性地提出Dense Block,在每一个Dense Block中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。通过密集连接,缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量。
如下图:
[x0,x1,…,xl-1]表示将 0 到 l-1 层的输出feature map做concatenation。concatenation是做通道的合并,就像Inception那样。即将 X_{0} 到 X_{l-1} 层的所有输出feature map按Channel组合在一起。这里所用到的非线性变换H为BN+ReLU+ Conv(3×3)的组合。
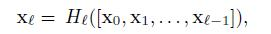

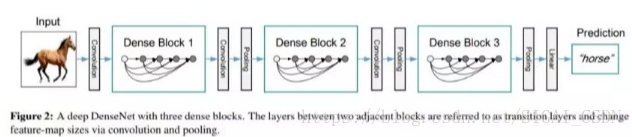
(2)DenseNet的结构图
在这个结构图中包含了3个dense block。将DenseNet分成多个dense block,原因是希望各个dense block内的feature map的size统一,这样在做concatenation就不会有size的问题。
在处理特征图数量或尺寸不匹配的问题上,ResNet采用零填充或者使用1x1的Conv来扩充特征图数量,而DenseNet是在两个Dense Block之间使用Batch+1x1Conv+2x2AvgPool作为transition layer的方式来匹配特征图的尺寸。 这样就充分利用了学习的特征图,而不会使用零填充来增加不必要的外在噪声,或者使用1x1Conv+stride=2来采样已学习到的特征(stride=2会丢失部分学习的特征)。
 (3)DenseNet效率更高
(3)DenseNet效率更高
如果每个 Hl 输出k个特征图,那么 l 层就有k0+k×(l−1)输入特征图,k0为输入层的通道数。由于每一层都包含之前所有层的输出信息,因此其只需要很少的特征图就够了(DenseNet与其他的网络架构有一个重要的不同之处在于可以通过修改k的大小,让DenseNet的网络变得非常窄小),这也是为什么DneseNet的参数量较其他模型大大减少的原因。这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题。
(三)DenseNet的简单实现
(1)稠密块
import d2lzh as d2l
from mxnet import gluon, init, nd
from mxnet.gluon import nn
def conv_block(num_channels): # DenseBlock块内组成
blk = nn.Sequential()
blk.add(nn.BatchNorm(), nn.Activation('relu'),
nn.Conv2D(num_channels, kernel_size=3, padding=1)) # BN+ReLU+Conv(3×3)模式
return blk
class DenseBlock(nn.Block): # 定义一个DenseBlock块
def __init__(self, num_convs, num_channels, **kwargs): #手动设计通道数和模块内的卷积块数目
super(DenseBlock, self).__init__(**kwargs)
self.net = nn.Sequential()
for _ in range(num_convs):
self.net.add(conv_block(num_channels))
def forward(self, X):
for blk in self.net:
Y = blk(X)
X = nd.concat(X, Y, dim=1) # 在通道维上将输入和输出连结
return X
如何计算输出通道呢?
blk = DenseBlock(2, 10) # 定义输入的通道数为10,定义一个denseblock里面有两个卷积块
blk.initialize()
X = nd.random.uniform(shape=(4, 3, 8, 8)) #输入的X通道数为3,图像大小为8×8
Y = blk(X) #Y为最后DenseBlock的输出
Y.shape
我们由这张图直观来看,这张图示一个DenseBlock,有四个卷积块,每个卷积块里面包括(BN+ReLU+Conv)三种层,到最后输出的通道数目,其实等于(Conv卷积层的输出通道数×卷积块个数)+输入通道数,
所以3+2×10=23。
所以输出为(4,23,8,8)
卷积块的通道数控制了输出通道数相对于输入通道数的增长,因此也被称为增长率(growth rate)。
(2)过渡层
由于每个稠密块都会带来通道数的增加,使用过多则会带来过于复杂的模型。过渡层用来控制模型复杂度。它通过1×1卷积层来减小通道数,并使用步幅为2的平均池化层减半高和宽,从而进一步降低模型复杂度。
def transition_block(num_channels): # 定义DenseBlock之间的transition layer
blk = nn.Sequential()
blk.add(nn.BatchNorm(), nn.Activation('relu'),
nn.Conv2D(num_channels, kernel_size=1),
nn.AvgPool2D(pool_size=2, strides=2)) # BN+ReLU+Conv(1×1)+AvgPool(2×2)
# 当map的信息都应该有所贡献的时候用avgpool,因为网络深层的高级语义信息一般来说都能帮助分类器分类。
return blk
如何理解这个过程呢?
blk = transition_block(10)
blk.initialize()
blk(Y).shape
比如之前DenseBlock的输出为(4,23,8,8),经过Conv2D(10×1×1)得到(4×10×8×8),经过AvgPool2D得到(4×10×4×4)
(3)DenseNet模型
DenseNet首先使用同ResNet一样的单卷积层和最大池化层。
net = nn.Sequential()
net.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3),
nn.BatchNorm(), nn.Activation('relu'),
nn.MaxPool2D(pool_size=3, strides=2, padding=1)) # 刚开始的时候为了减少无用信息选择MaxPooling(网络浅层)
类似于ResNet接下来使用的4个残差块,DenseNet使用的是4个稠密块。同ResNet一样,我们可以设置每个稠密块使用多少个卷积层。
num_channels, growth_rate = 64, 32 # num_channels为当前的通道数,growth_rate为卷积块的通道数
num_convs_in_dense_blocks = [4, 4, 4, 4] # 4个DenseBlock,每个里面有4个卷积块
for i, num_convs in enumerate(num_convs_in_dense_blocks):
# 利用enumerate可以同时迭代序列的索引和元素
net.add(DenseBlock(num_convs, growth_rate))
# 根据更新的num_convs添加DenseBlock
num_channels += num_convs * growth_rate # 上一个稠密块的输出通道数
if i != len(num_convs_in_dense_blocks) - 1:
num_channels //= 2 # 在稠密块之间加入通道数减半的过渡层
net.add(transition_block(num_channels))
同ResNet一样,最后接上全局池化层和全连接层来输出。
net.add(nn.BatchNorm(), nn.Activation('relu'), nn.GlobalAvgPool2D(),
nn.Dense(10))
#利用全局平均池化层可以降低模型的参数数量来最小化过拟合效应。GAP层通过取平均值映射每个h×w的特征映射至单个数字。

(4)获取数据并训练模型
lr, num_epochs, batch_size, ctx = 0.1, 5, 256, d2l.try_gpu()
net.initialize(ctx=ctx, init=init.Xavier())
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx,
num_epochs)