文章目录
- 1
-
- 部门表
-
- 用户列表
-
- 用户增加
-
- 用户编辑
-
- 靓号管理
-
- 优化代码结构
-
- 管理员管理
-
- 用户登录
-
- 用户注销
- 显示登录用户
- 生成随机验证码
-
- Ajax介绍
-
- 任务表单
-
- 订单表单
-
- 图表
- 关于文件上传
-
- Cookie 和session 介绍 (图解 Http)
-
- Excel格式文件
-
- 3. 默认打开的sheet
- 4. 拷贝sheet
- 5.删除sheet
- 1. 获取某个单元格,修改值
- 2. 获取某个单元格,修改值
- 3. 获取某些单元格,修改值
- 4. 对齐方式
- horizontal,水平方向对齐方式:"general", "left", "center", "right", "fill", "justify", "centerContinuous", "distributed"
- vertical,垂直方向对齐方式:"top", "center", "bottom", "justify", "distributed"
- text_rotation,旋转角度。
- wrap_text,是否自动换行。
- 5. 边框
- side的style有如下:dashDot','dashDotDot', 'dashed','dotted','double','hair', 'medium', 'mediumDashDot', 'mediumDashDotDot','mediumDashed', 'slantDashDot', 'thick', 'thin'
- 6.字体
- 7.背景色
- 8.渐变背景色
- 9.宽高(索引从1开始)
- 10.合并单元格
- 11.写入公式
- 12.删除
- idx,要删除的索引位置
- amount,从索引位置开始要删除的个数(默认为1)
- 13.插入
- 14.循环写内容
- 15.移动
- 将H2:J10范围的数据,向右移动15个位置、向上移动1个位置
- 16.打印区域
- 17.打印时,每个页面的固定表头
1
框架MVC 介绍


Django 框架的介绍
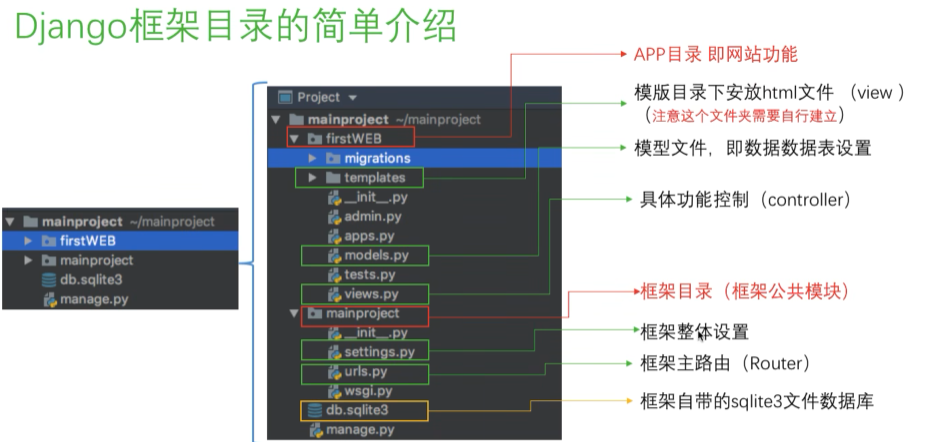
基础命令

Django处理浏览器的请求的流程

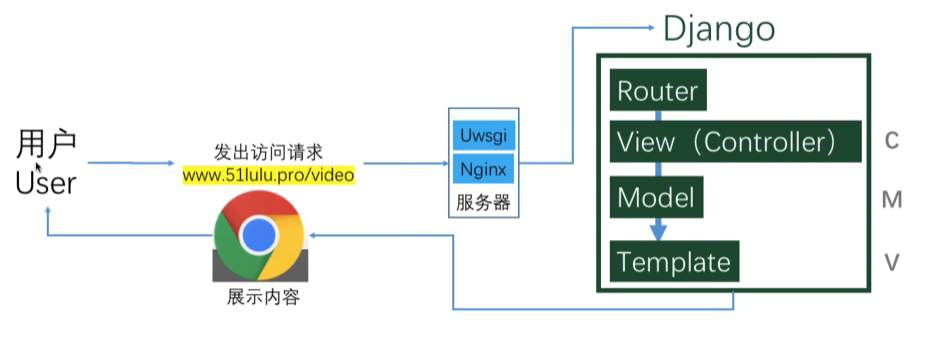
1 当对 http://127.0.0.1:8000/depart/list/ , 发出访问请求时,
2 请求发送到了wsgi (WSGI是一套接口标准协议/规范;),wsgi 封装请求的相关数据(request)
3 django去匹配路径,根据路径判断要执行哪个函数
在 urls .py中 匹配 即 Router
4 执行函数,函数中处理具体的业务逻辑
在每个 app 的 view.py 中执行相应函数, 即 Controller
函数体中可以对数据库进行交互 即 Model
5 函数返回响应,django按照 HTTP 协议的响应的格式进行返回
即通过 render 或者 HttpResponse 返回 网页 或者 JSON 数据 , 期间还可以传值 (对模板上下文(模板变量)赋值,以字典格式表示,默认情况下是一个空字典。),
返回前端 即 Template
部门表
部门表显示
{% extends 'layout.html' %}
{% block content %}
<div class="container">
<div style="margin-bottom: 10px">
<a class="btn btn-success" href="/depart/add/">
<span class="glyphicon glyphicon-plus-sign" aria-hidden="true"></span>
新建部门
</a>
</div>
<div class="panel panel-default">
<!-- Default panel contents -->
<div class="panel-heading">
<span class="glyphicon glyphicon-th-list" aria-hidden="true"></span>
部门列表
</div>
<!-- Table -->
<table class="table table-bordered">
<thead>
<tr>
<th>ID</th>
<th>名称</th>
<th>操作</th>
</tr>
</thead>
<tbody>
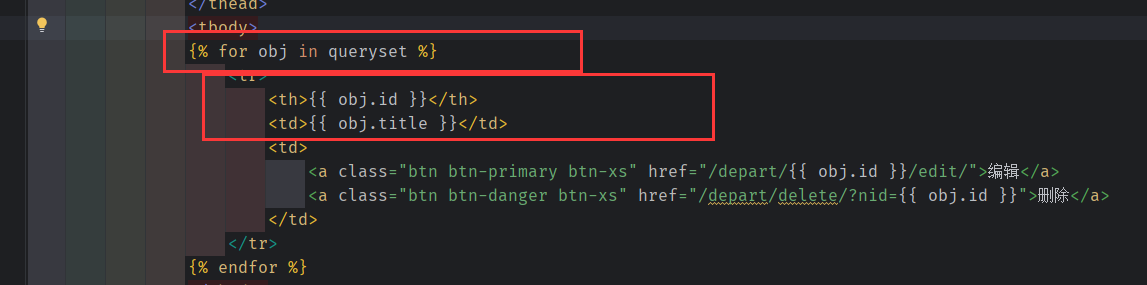
{% for obj in queryset %}
<tr>
<th>{{ obj.id }}</th>
<td>{{ obj.title }}</td>
<td>
<a class="btn btn-primary btn-xs" href="/depart/{{ obj.id }}/edit/">编辑</a>
<a class="btn btn-danger btn-xs" href="/depart/delete/?nid={{ obj.id }}">删除</a>
</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</div>
{% endblock %}
当用户 访问 http://127.0.0.1:8000/depart/list/ 时, 1 先 匹配路径和执行函数 2 交互数据库获取部门表。3在render 中 以 字典的形式返回
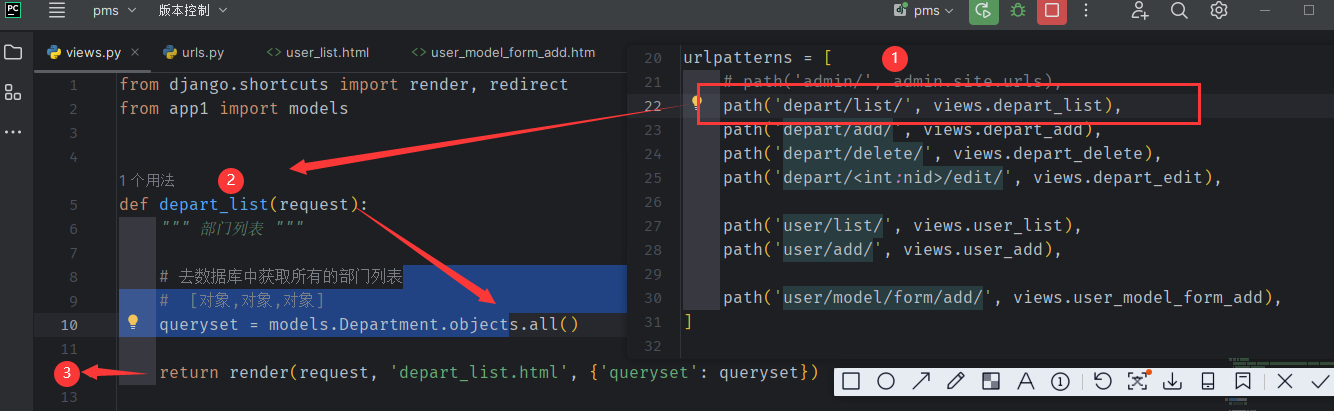
上下文的命名必须与变量 queryset 的数据命名(字典的key)相同,这样 Django 内置的模板引擎才能将参数context(变量querset)的数据与模板上下文进行配对,从而将参数 context 的数据转换成网页内容
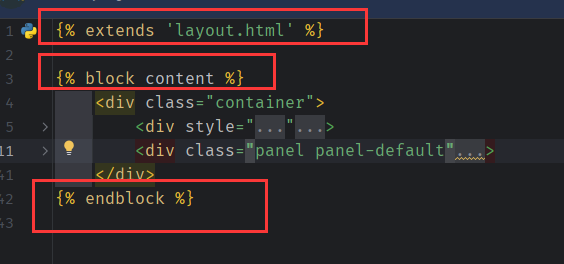
HTML提供了一个block块功能,可以实现HTML模板的继承,从而可以减少代码的重复量。
在Django模板继承中最常用了标签就是 {% block %} 与 {% extends %} 标签,其中 {% block% } 标签与 {% endblock %} 标签成对出现,而 {% extends %} 放在子模板的第一行且必须是模板中的第一个标签,标志着此模板继承自父模板,
7.模板的继承
定义目版:layout.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="{% static 'plugin...min.css' %}">
{% block css %}{% endblock %}
</head>
<body>
<h1>标题</h1>
<div>
{% block content %}{% endblock %}
</div>
<h1>底部</h1>
<script src="{% static 'js/jquery-3.6.0.min.js' %}"></script>
{% block js %}{% endblock %}
</body>
</html>
继承母版:
{% extends 'layout.html' %}
{% block css %}
<link rel="stylesheet" href="{% static 'pluxxx.css' %}">
<style>
...
</style>
{% endblock %}
{% block content %}
<h1>首页</h1>
{% endblock %}
{% block js %}
<script src="{% static 'js/jqxxxin.js' %}"></script>
{% endblock %}
部门表的添加

通过 a 标签 进行 发送 get 请求 ,
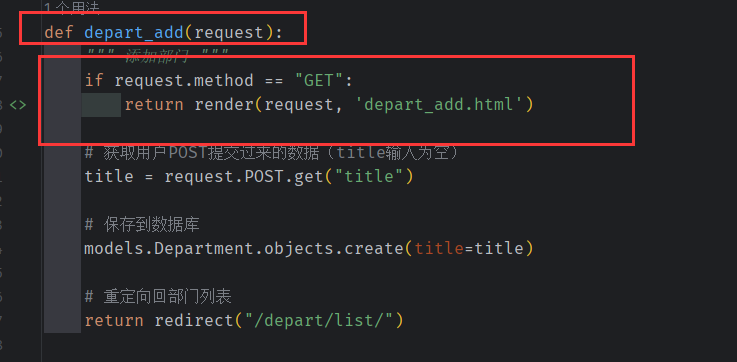
控制器被 上层 Router 的 匹配路径后,如果是get请求就 转到 depart_add 网页。
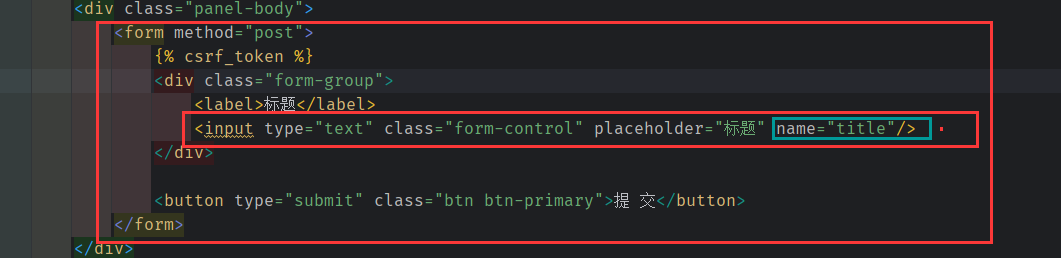
通过 用户在此表单上填写的数据 , 表单 发出 post 请求, 将 title 作为 key 传出
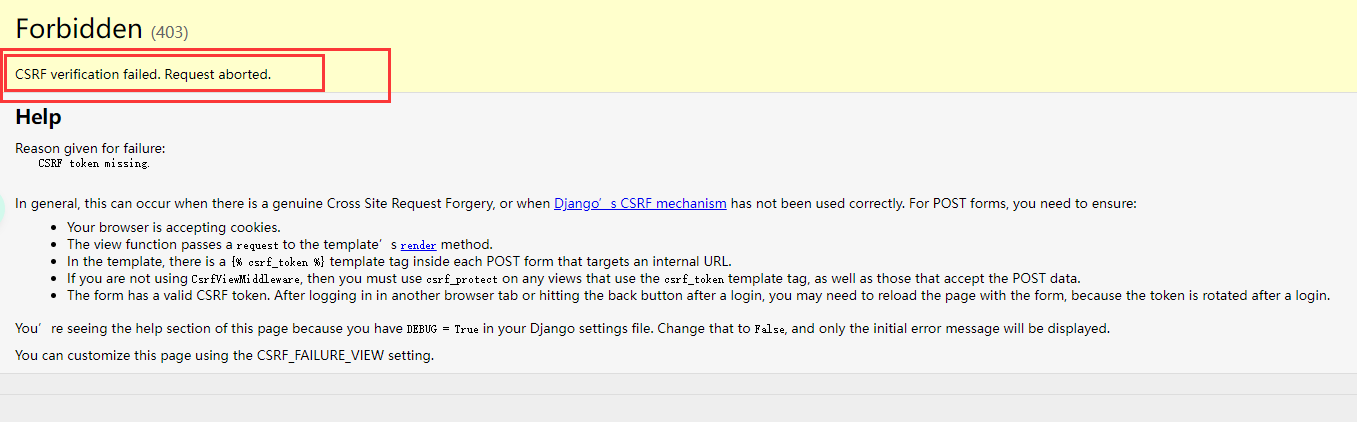
浏览器在发送请求的时候,会自动带上当前域名对应的cookie内容,发送给服务端,不管这个请求是来源A网站还是其它网站,只要请求的是A网站的链接,就会带上A网站的cookie。浏览器的同源策略并不能阻止CSRF攻击,因为浏览器不会停止js发送请求到服务端,只是在必要的时候拦截了响应的内容。或者说浏览器收到响应之前它不知道该不该拒绝。
为了防止跨域访问。直接发出 post ,Django 将会阻止
解决方法

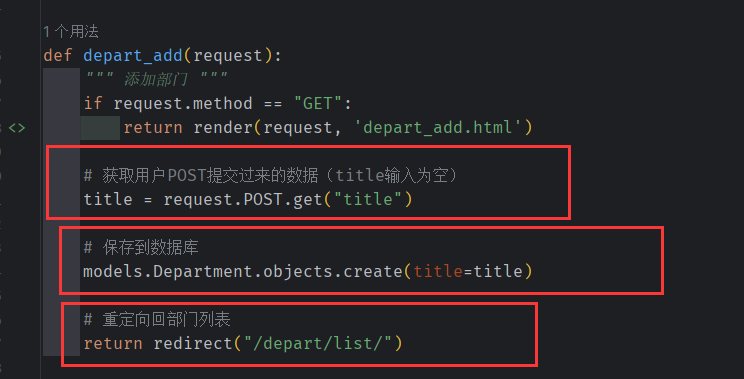
接收到 来自 dapart_add 的post 请求后, 将 titile (部门名) 。 同时和数据库 进行 交互 新增一条记录,并选择重定向到
部门列表 depart_list
部门表的删除
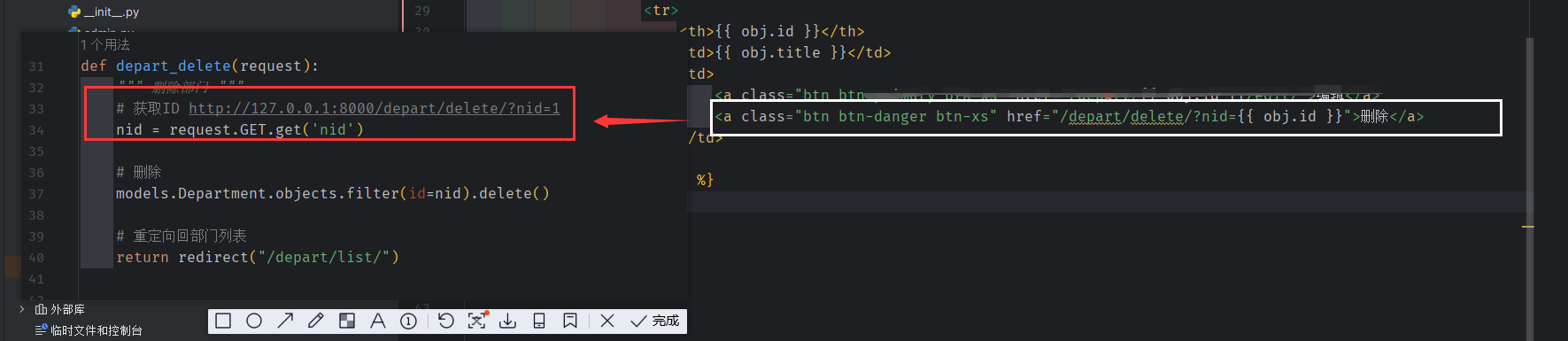
a 标签传值 将 id 传给 depart_delete
a 标签传值的三种方式


request.POST.get(‘key’) 、 request.GET.get(‘key’, ‘’)
request.POST是用来接受从前端表单中传过来的数据,比如用户登录过程中传递过来的username、passwrod等字段。返回类型是字典;
在后台进行数据获取时,有两种方法(以username为例):request.POST[‘username’]与request.POST.get(‘username’),那么这两者有什么不同之处呢?
如果传递过来的数值不为空,那么这两种方法都没有错误,可以得到相同的结果。但是如果传递过来的数值为空,那么request.POST[‘username’]则会提示Keyerror错误,而request.POST.get(‘username’)则不会报错,而是返回一个None。举例来说:
try:
x = request.POST[‘sth’]
except KeyError:
x = None
1
2
3
4
x = request.POST.get(‘sth’)
1
以上两种写法是等价的。
如果数值不存在的话,我们可以指定显示的默认值:
x = request.POST.get(‘sth’, ‘default_value’)
1
这里我们可以拿字典对象来进行理解:
list_test = {‘a’: 1, ‘b’: 2}
list_test.get(‘a’) # 得到结果1
list_test.get(‘c’) # 得到结果none
list_test.get(‘c’, 3) # 得到设定的默认值3
list_test[‘b’] # 得到结果 2
list_test[‘c’] # 返回一个Keyvalue 错误类型
-------------------------------
GET一样:
query = request.GET.get(‘q’, ‘’)
寻找名为 q 的GET参数,而且如果参数没有提交,返回一个空的字符串。
注意在 request.GET 中使用了 get() 方法,这可能让大家不好理解。这里的 get() 是每个python的的字典数据类型都有的方法。使用的时候要小心:假设 request.GET 包含一个 ‘q’ 的key是不安全的,所以我们使用 get(‘q’, ‘’) 提供一个缺省的返回值’’ (一个空字符串)。如果只是使用 request.GET[‘q’] 访问变量,在Get数据时 q 不可得,可能引发 KeyError .
部门表的编辑
url.py
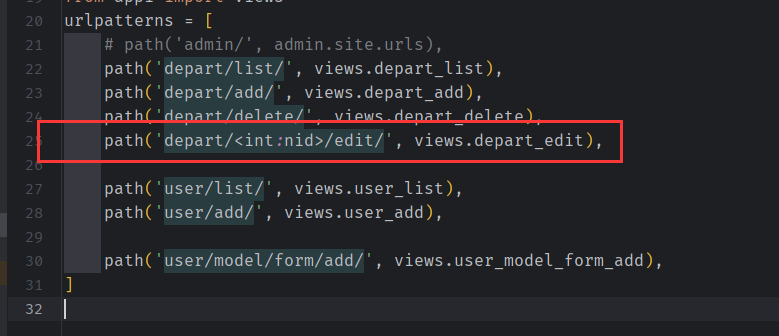
#http://127.0.0.1:8000/depart/10/edit/
#http://127.0.0.1:8000/depart/4/edit/
#http://127.0.0.1:8000/depart/1/edit/
只有在 django 3 中才能 使用 < int:nid > 使得传入的数据 只能如上面一样 中间的数字由 depart_list 传入,即 传入 id
depart_list:

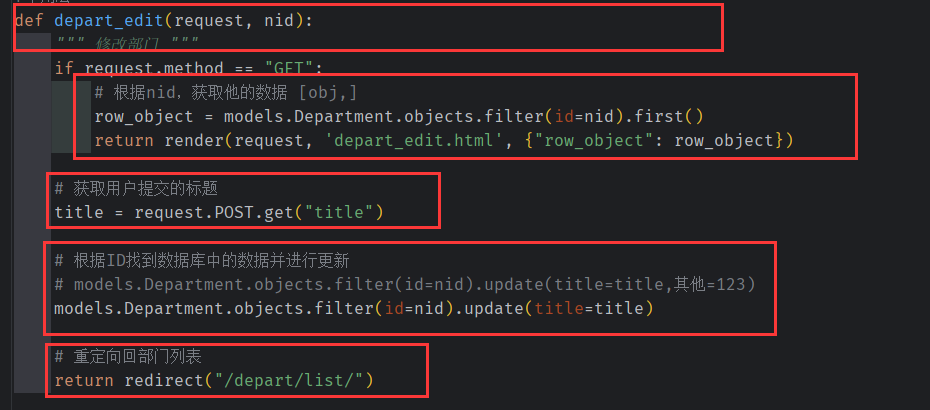
这里的first()的功能是将 queryset 转化为 字典,以便于 render 返回字典

filter() 得到可迭代的QuerySet对象,支持for循环取容器内的元素
#filter其实就是 筛选功能,相当于你原生sql语句里面的where关键字,返回的结果queryset对象
res=models.Books.objects.filter(pk=1,title='张三丰') #支持多个参数,and关系
print(res) #<QuerySet [<Books: 张三丰>]>
print('************************')
# 3.get() 在django中不推荐使用
# 筛选,获取的是数据对象本身,条件不存在的数据直接报错,并且查询条件必须是唯一的
res=models.Books.objects.get(title='西游记')
print(type(res)) #如果是数据库中不存在的数据进行查询的话,会报错,因为数据库中没有该数据
print('//')
-----------------------------------------------------------------------------------------------------------------------------------
打印结果如下:
<QuerySet [<Books: 张三丰>]>
************************
<class 'app01.models.Books'>
//////////////////////////
(0.001) SELECT `app01_books`.`id`, `app01_books`.`title`, `app01_books`.`price`, `app01_books`.`kucun`, `app01_books`.`maichu` FROM `app01_books` WHERE `app01_books`.`price` = 766 LIMIT 21; args=(Decimal('766'),)
<QuerySet [<Books: 西游记>, <Books: 西游记2>]>
<class 'django.db.models.query.QuerySet'>
************************
西游记
1000
<class 'app01.models.Books'>
(0.001) SELECT `app01_books`.`id`, `app01_books`.`title`, `app01_books`.`price`, `app01_books`.`kucun`, `app01_books`.`maichu` FROM `app01_books` WHERE `app01_books`.`price` = 766 ORDER BY `app01_books`.`id` ASC LIMIT 1; args=(Decimal('766'),)
first()
#功能一, 取queryset 相同数据中的第一个数据对象,
# id=3,title='西游记' id=5,title='西游记2',加上.first()会优先取id=3的数据
res = models.Books.objects.filter(price='766')
print(res)
print(type(res))
打印结果如下:
<QuerySet [<Books: 西游记>, <Books: 西游记2>]>
如果上面加上.first()就会只取到第一个值 <QuerySet [<Books: 西游记>]>
<class 'django.db.models.query.QuerySet'>
重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点重点
特殊功能如下:
# .first()特殊的功能可以把QuerySet对象转换为字典对象,方便字典对象的属性取值------------88颗星的重点
res = models.Books.objects.filter(price='766').first()
print(res)
print(res.kucun) 通过字典对象,拿到该书的库存
print(type(res))
打印结果如下:
西游记
1000
<class 'app01.models.Books'>
用户列表
1 choices 参数
choices参数:
针对表中某个可能列举完全的字段,采用choices参数
例如:性别可以列举完全为男女,其他
- choice参数使用
sex_choices = (
(1, '男'),
(0, '女'),
(2, '其他'),
)
sex = models.IntegerField(choices=sex_choices)
- 查询
from app01 import models
# 录入
# models.User.objects.create(name='q', sex=0)
# models.User.objects.create(name='w', sex=1)
# models.User.objects.create(name='e', sex=2)
# models.User.objects.create(name='r', sex=3)
# 当查询的sex字段值在我们定义的choice参数中时
# user_obj = models.User.objects.filter(pk=1).first()
# print(user_obj.sex) # 这里返回的是0, 并非是0对应的女
# print(user_obj.get_sex_display()) # 这里返回的是0对应的女
# 当查询的sex字段值不在在我们定义的choice参数中时
# user_obj = models.User.objects.filter(pk=4).first()
# print(user_obj.sex) # 这里返回的是3,虽然超出范围,但并没报错
# print(user_obj.get_sex_display()) # 这里返回的也是3, 当查询的值不在定义的choices中, 返回的是我们录入的值
原因:对于设置了choice的字段,Django会自动帮我们提供一个方法(注意是方法), 用来获取这个字段对应的要展示的值。
而admin中,展示带有choice属性的字段时,django会自动帮我们调用get_xxx_display(xxx为字段名,如本文的get_status_display)方法,所以不用配置。而在我们自己写的模板中,这需要自己来写。并且为了简化模板的使用,默认只支持无参数的方法调用,你只需要写方法名称即可,后面的括号不能写,Django会自行帮你调用(如果是方法的话)。
2 表的关联查找
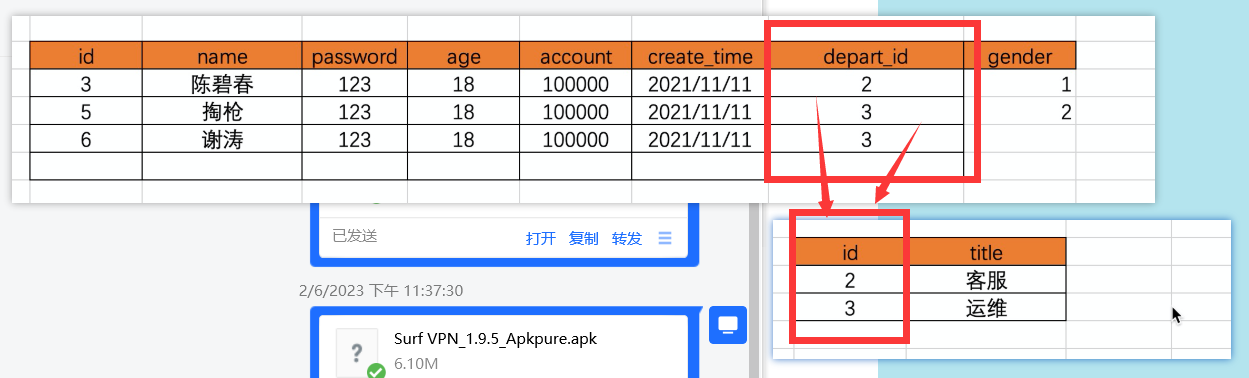
关联取值的方法
sql 提供的方式
xx =models.Department.objects.filter(id=obj.depart_id).first()
xx.title
而depart_id则是第一个表的外键,于是Django为我们提供了一种比较方便的方式,还得我们之前明明是depart时foreignkey但生成的字段却是depart_id,那么depart有啥用呢,其实对于这种我们只要depart.title,它会自动帮我们读取depart_id对应过去的id然后去找到title。
而depart_id则是第一个表的外键,于是Django为我们提供了一种比较方便的方式,还得我们之前明明是depart时foreignkey但生成的字段却是depart_id,那么depart有啥用呢,其实对于这种我们只要depart.title,它会自动帮我们读取depart_id对应过去的id然后去找到title。
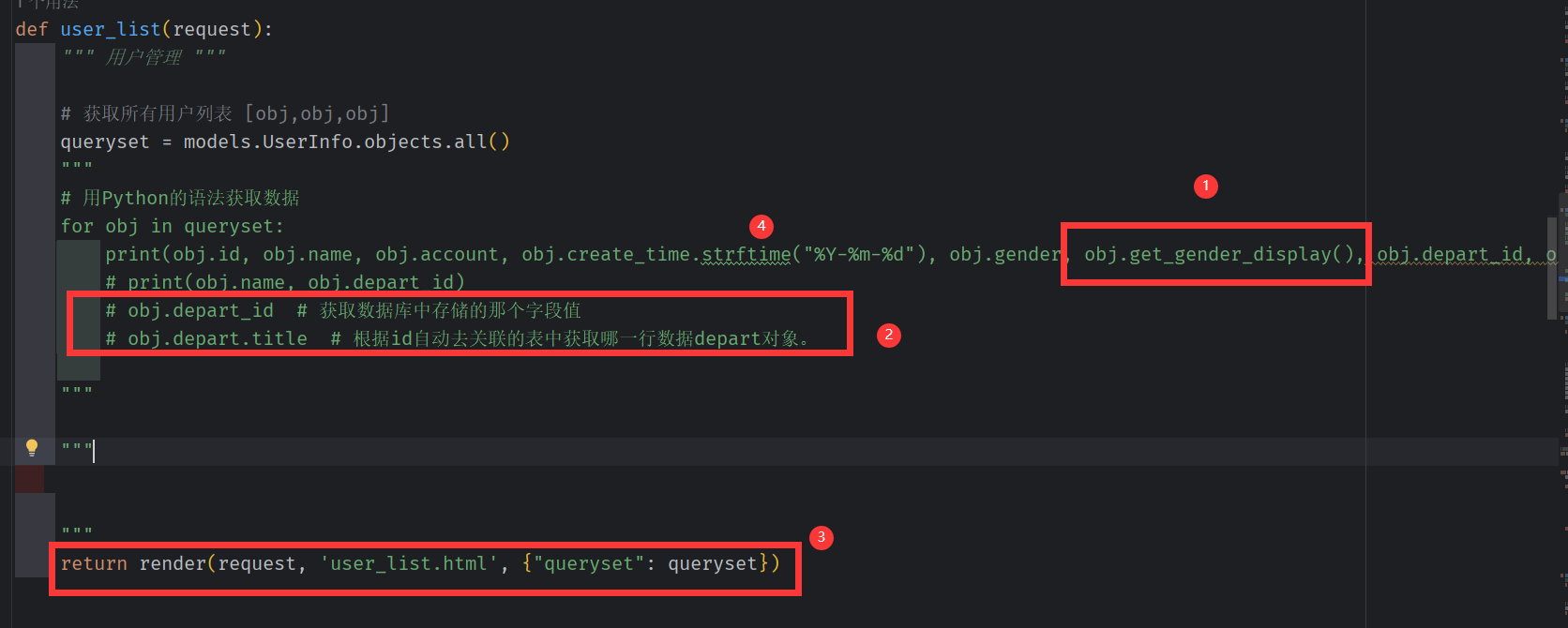
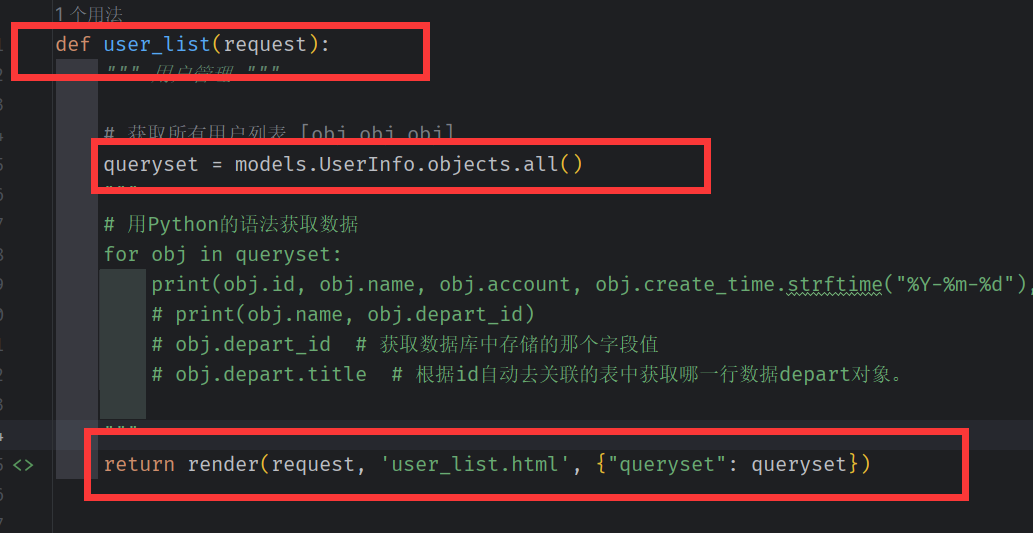
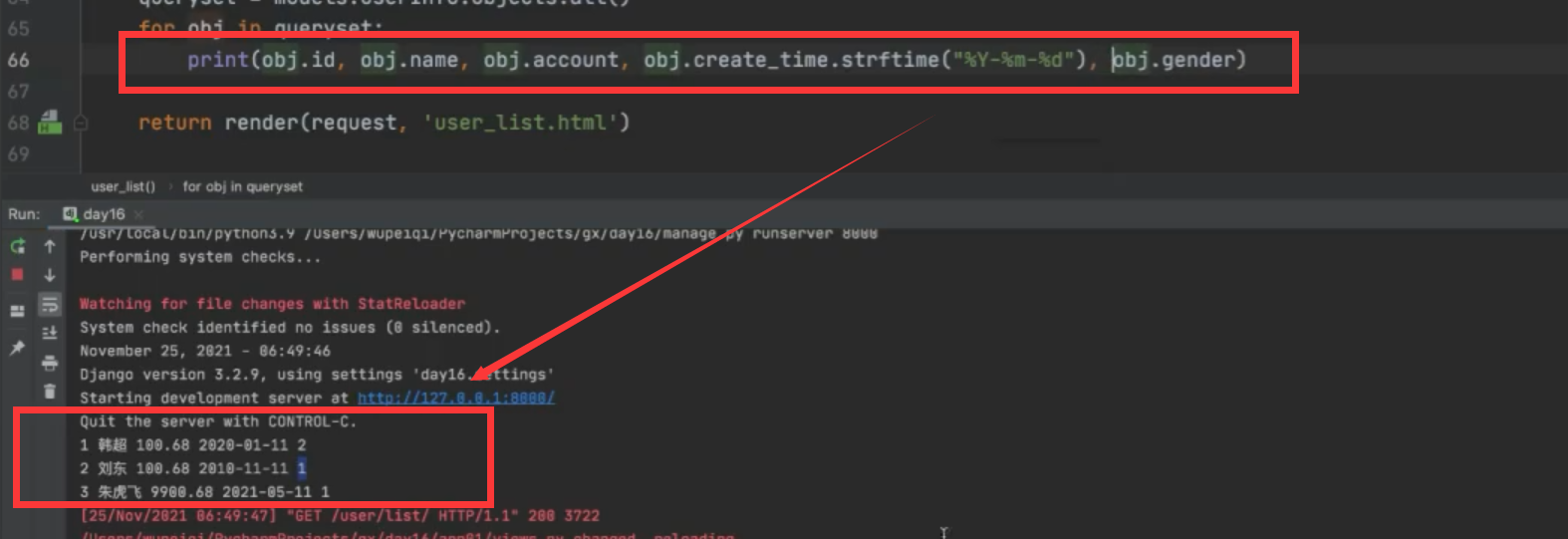
用Django的语法获取数据
for obj in queryset:
print(obj.id, obj.name, obj.account, obj.create_time.strftime("%Y-%m-%d"), obj.gender, obj.get_gender_display(), obj.depart_id, obj.depart.title)
# print(obj.name, obj.depart_id)
# obj.depart_id # 获取数据库中存储的那个字段值
# obj.depart.title # 根据id自动去关联的表中获取哪一行数据depart对象。
使用前端语法
也可以通过前端模板语法,我们直接把queryset传过去通过前端模板语法来处理
3 数据类型转换
参见:
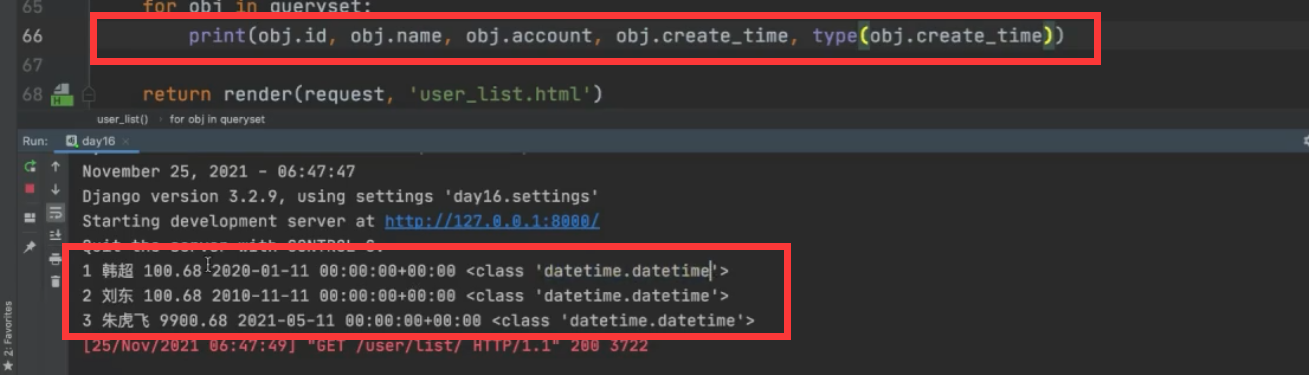
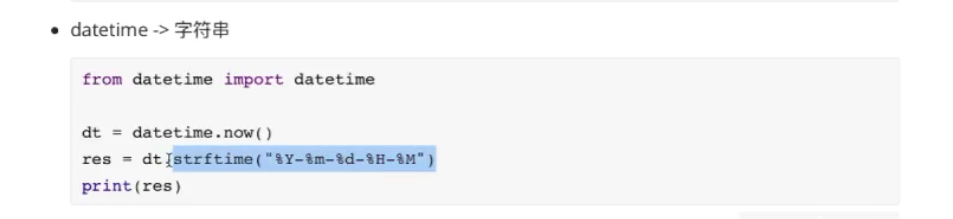
datetime 转为字符串
4 模板语法
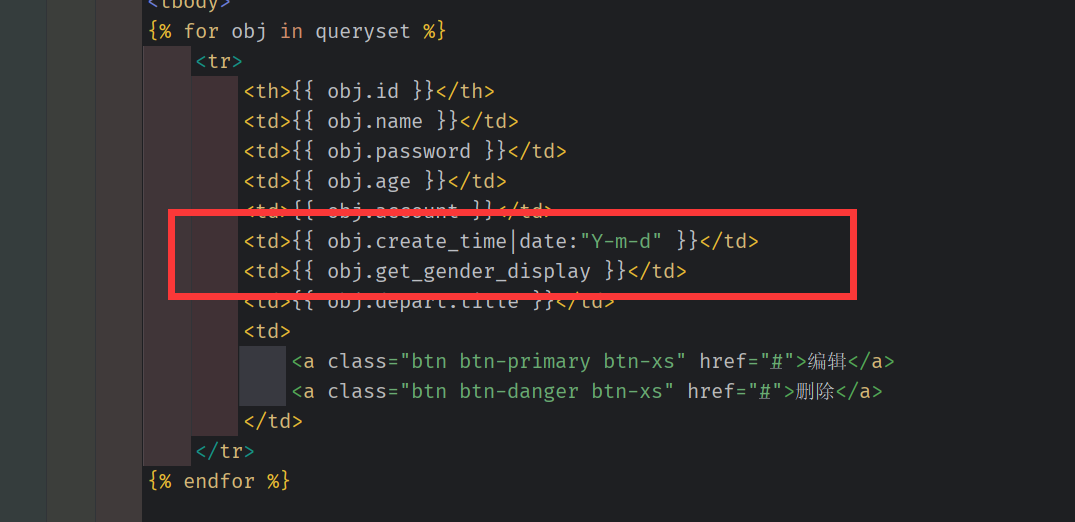
在 中 不允许出现括号(除非它自动添加的),且 时间日期格式 和python (没有 %)不同。

更多参见
用户增加
0 用户请求前端信息《 a 标签 》
1 前端页面提供部门和 性别信息, 供用户选择。
2 前端(html ) post 信息 id name password age account create time gender depart id
3 后端 (view )接受 信息
4 model 存储信息
(一)前端提供信息供用户选择
常规方式
1 Views.py
def user_add(request):
""" 添加用户(原始方式) """
""" 只将部门和性别 数据加载到user_add 页面"""
if request.method == "GET":
context = {
'gender_choices': models.UserInfo.gender_choices,
"depart_list": models.Department.objects.all()
}
return render(request, 'user_add.html', context)
# 获取用户提交的数据
user = request.POST.get('user')
pwd = request.POST.get('pwd')
age = request.POST.get('age')
account = request.POST.get('ac')
ctime = request.POST.get('ctime')
gender = request.POST.get('gd')
depart_id = request.POST.get('dp')
# 添加到数据库中
models.UserInfo.objects.create(name=user, password=pwd, age=age,
account=account, create_time=ctime,
gender=gender, depart_id=depart_id)
# 返回到用户列表页面
return redirect("/user/list/")
2 user_add.html
{% extends 'layout.html' %}
{% block content %}
<div class="container">
<div class="panel panel-default">
<div class="panel-heading">
<h3 class="panel-title"> 新建用户 </h3>
</div>
<div class="panel-body">
<form method="post">
{% csrf_token %}
<div class="form-group">
<label>姓名</label>
<input type="text" class="form-control" placeholder="姓名" name="user" />
</div>
<div class="form-group">
<label>密码</label>
<input type="text" class="form-control" placeholder="密码" name="pwd"/>
</div>
<div class="form-group">
<label>年龄</label>
<input type="text" class="form-control" placeholder="年龄" name="age"/>
</div>
<div class="form-group">
<label>余额</label>
<input type="text" class="form-control" placeholder="余额" name="ac"/>
</div>
<div class="form-group">
<label>入职时间</label>
<input type="text" class="form-control" placeholder="入职时间" name="ctime"/>
</div>
<div class="form-group">
<label>性别</label>
<select class="form-control" name="gd">
{% for item in gender_choices %}
<option value="{{ item.0 }}">{{ item.1 }}</option>
{% endfor %}
</select>
</div>
<div class="form-group">
<label>部门</label>
<select class="form-control" name="dp">
{% for item in depart_list %}
<option value="{{ item.id }}">{{ item.title }}</option>
{% endfor %}
</select>
</div>
<button type="submit" class="btn btn-primary">提 交</button>
</form>
</div>
</div>
</div>
{% endblock %}
- 用户提交数据没有校验。
- 错误,页面上应该有错误提示。
- 页面上,没一个字段都需要我们重新写一遍。
- 关联的数据,手动去获取并展示循环展示在页面。
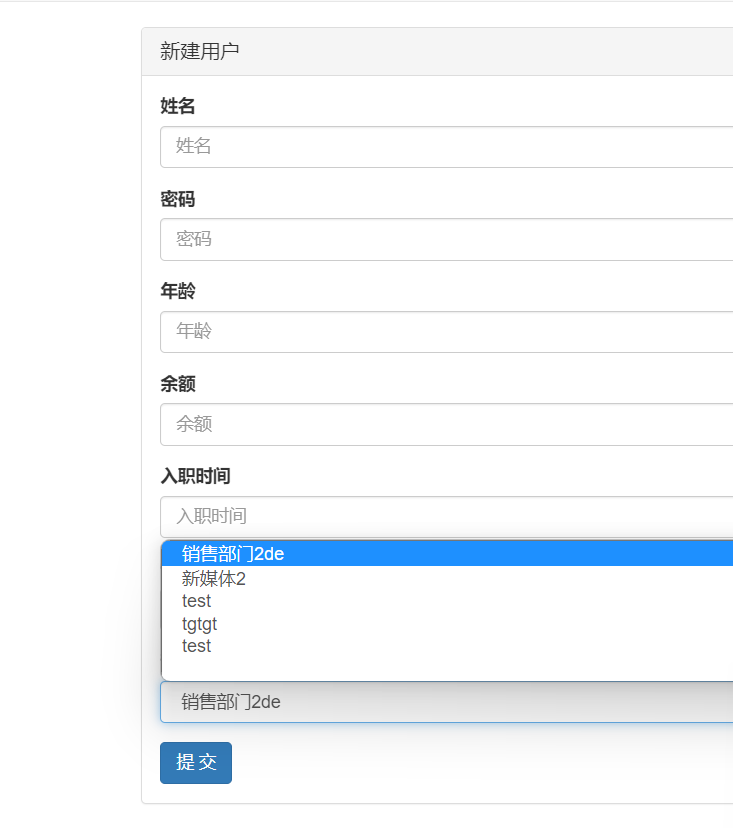
Form
用法参见
1. views.py
class MyForm(Form):
user = Form.CharField(widget=forms.Input)
pwd = Form.CharFiled(widget=forms.Input)
email = Form.CharFiled(widget=forms.Input)
account = Form.CharFiled(widget=forms.Input)
create_time = Form.CharFiled(widget=forms.Input)
depart = Form.CharFiled(widget=forms.Input)
gender = Form.CharFiled(widget=forms.Input)
def user_add(request):
if request.method == "GET":
form = MyForm()
return render(request, 'user_add.html',{"form":form})
2.user_add.html
可以循环去拿到值
<form method="post">
{% for field in form%}
{{ field }}
{% endfor %}
<!-- <input type="text" placeholder="姓名" name="user" /> -->
</form>
或者一行行拿值
<form method="post">
{{ form.user }}
{{ form.pwd }}
{{ form.email }}
<!-- <input type="text" placeholder="姓名" name="user" /> -->
</form>
ModelForm
modelForm 的用法
modelForm
0. models.py
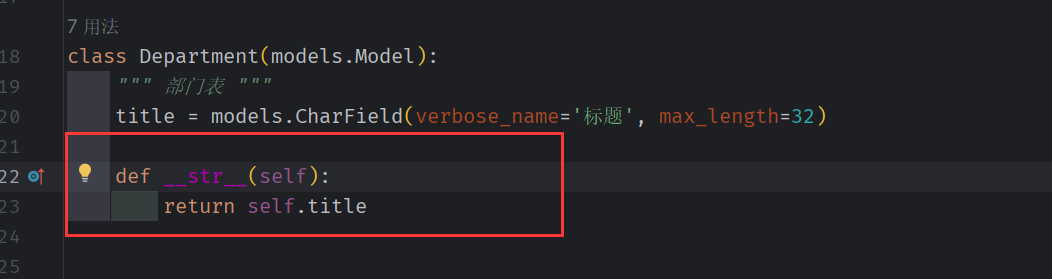
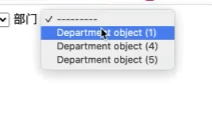
在 user_model_form.html 下拉框中 ModelForm 对于 部门这个字段的处理是 循环取出集合对象(如图)打印
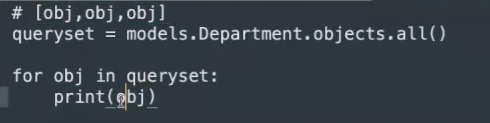
如果直接打印,结果如下图,打印全为对象
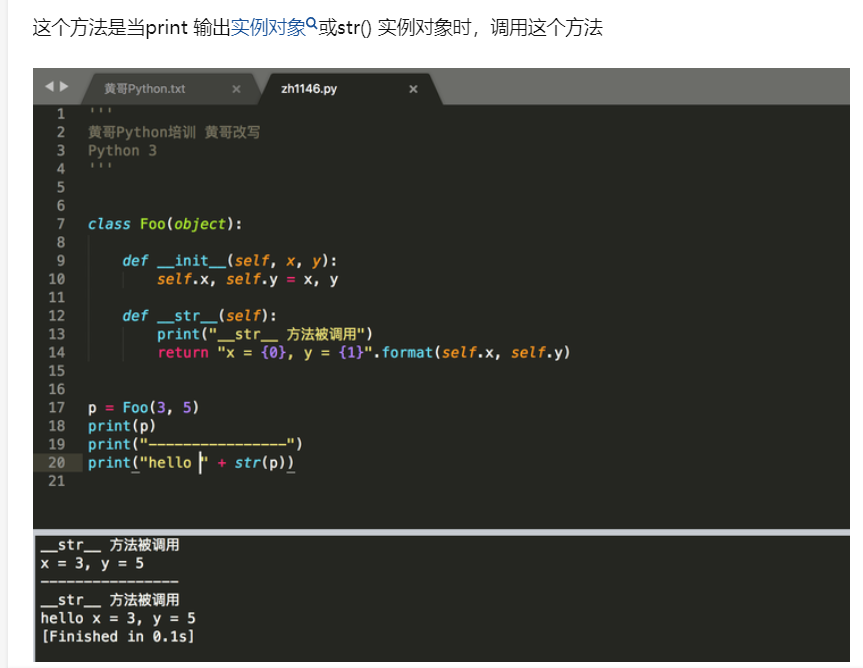
1. views.py
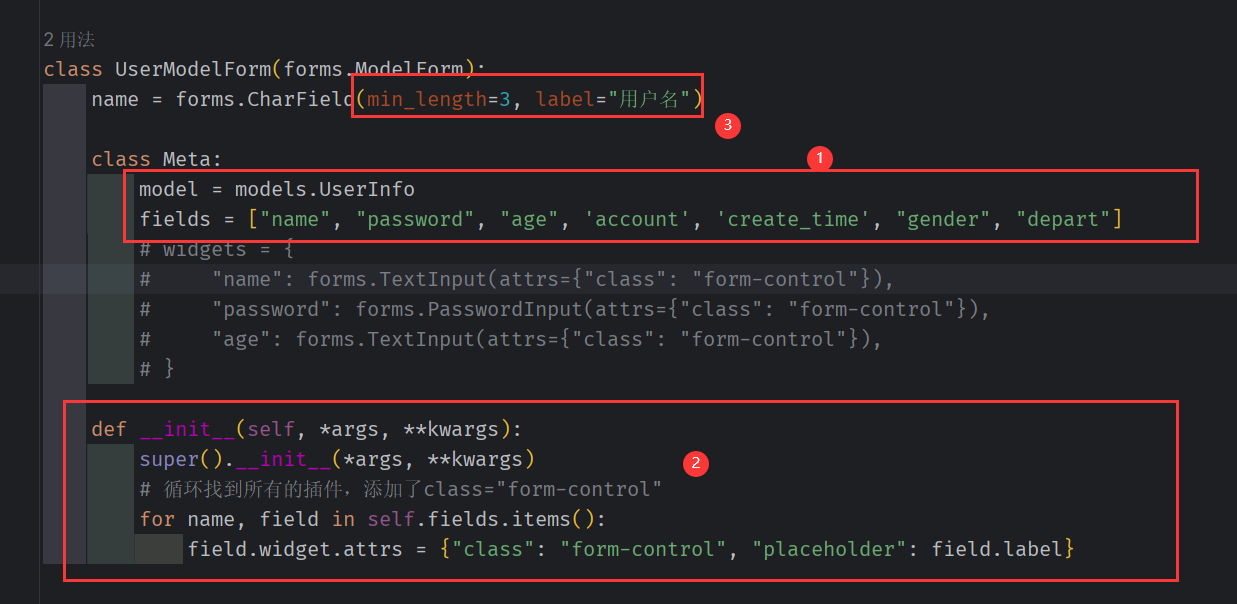
对于 ModelForm 里的 fields model widget(插件)属性 ,参见modelForm ,widget 会提供一个输入框,样式来自这里指定的 bootstrap
对于在 modelForm 添加 widget 有两种方式:
一是像 这样,直接在 views.py 中添加,但 有多少个字段就要添加多少个,

二 是 使用如下代码,自动循环添加
原理可分析源码

2.user_add.html
可以循环去拿到值
<form method="post">
{% for field in form%}
{{ field }}
{% endfor %}
</form>
或者一行行拿值
<form method="post">
{{ form.user }}
{{ form.pwd }}
{{ form.email }}
<!-- <input type="text" placeholder="姓名" name="user" /> -->
</form>
(二)用户填写信息 与提交
views.py
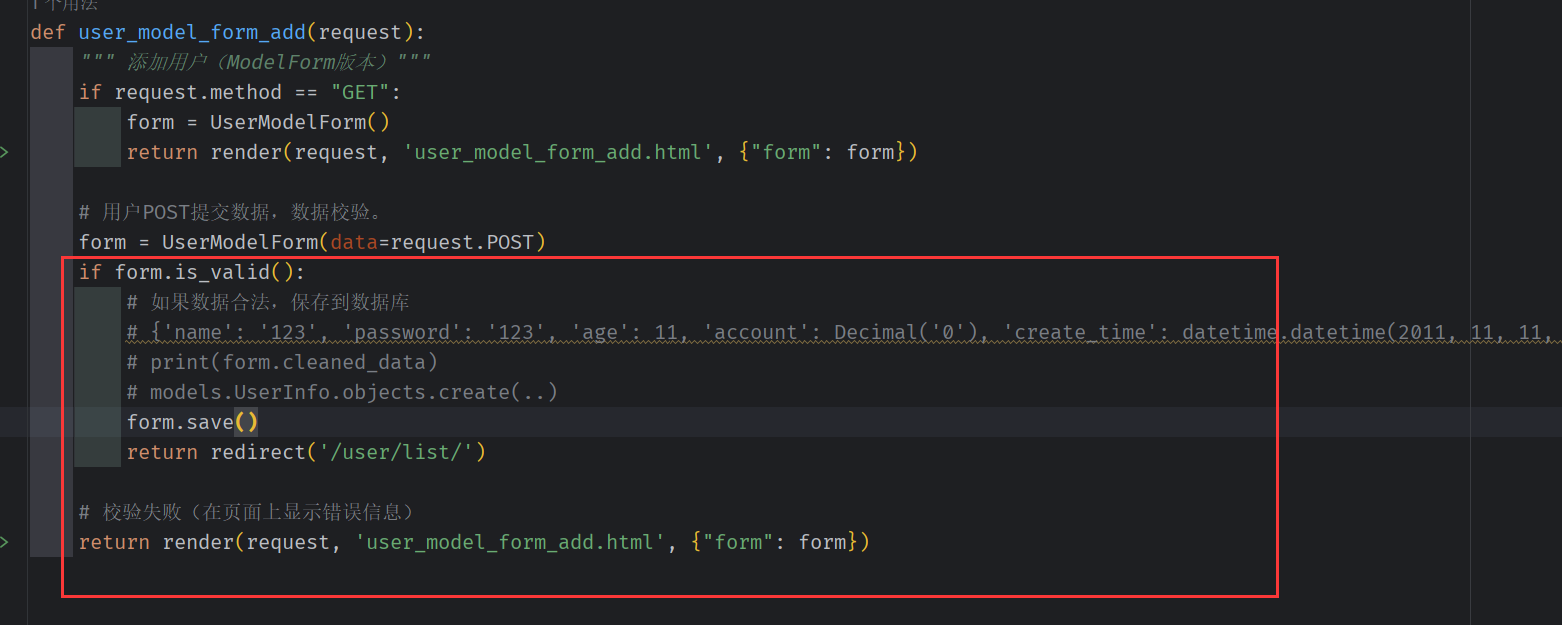
使用 Django 自带的校验 和 数据库保存(save)
user_model_form_add.html

关闭浏览器自带的校验提示
时间插件
<link rel="stylesheet" href="static/plugins/bootstrap-3.4.1/css/bootstrap.css">
<link rel="stylesheet" href="static/plugins/bootstrap-datepicker/css/bootstrap-datepicker.css">
<input type="text" id="dt" class="form-control" placeholder="入职日期">
<script src="static/js/jquery-3.6.0.min.js"></script>
<script src="static/plugins/bootstrap-3.4.1/js/bootstrap.js"></script>
<script src="static/plugins/bootstrap-datepicker/js/bootstrap-datepicker.js"></script>
<script src="static/plugins/bootstrap-datepicker/locales/bootstrap-datepicker.zh-CN.min.js"></script>
<script>
$(function () {
$('#dt').datepicker({
format: 'yyyy-mm-dd',
startDate: '0',
language: "zh-CN",
autoclose: true
});
})
</script>
用户编辑
url 匹配 仿照 部门编辑,
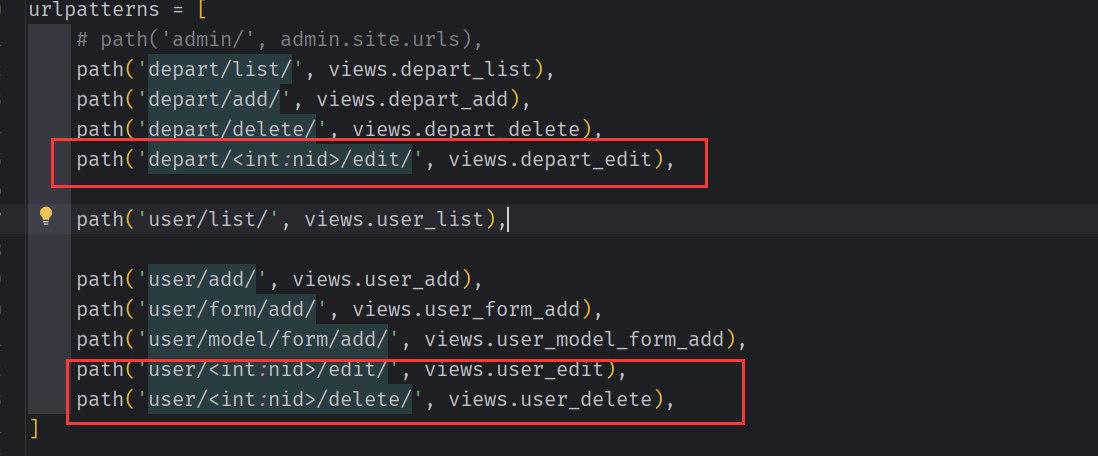
前端提供用户信息给用户编辑
views.py
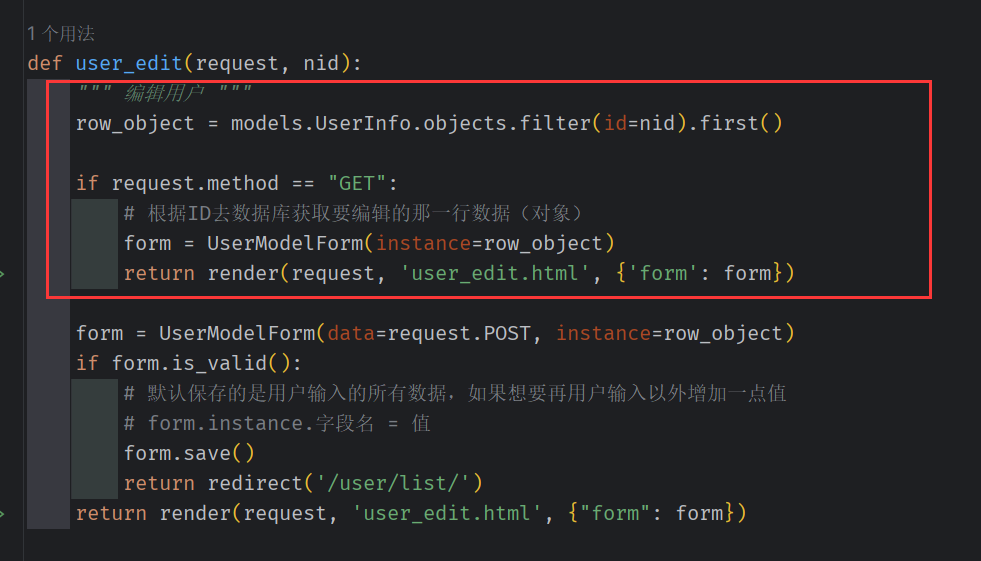
收到网址请求后,开始数据库交互。 Django 自带的特性就能很简单进行编辑
user_edit.html
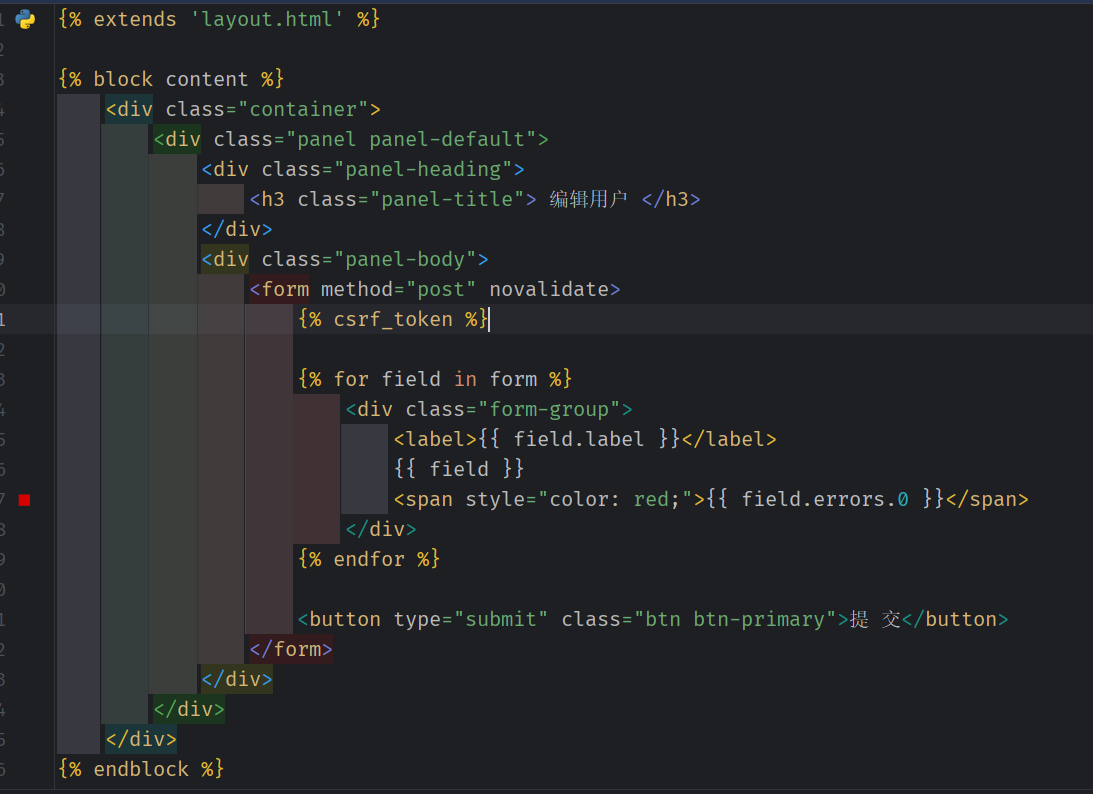
前端拿到信息 开始渲染
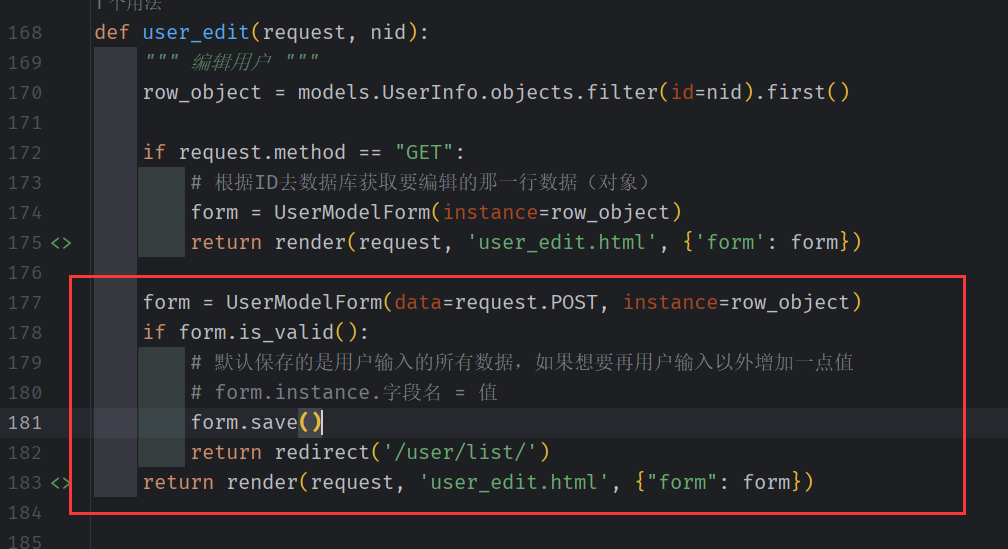
用户提交,Django 提供的方法进行保存
靓号管理
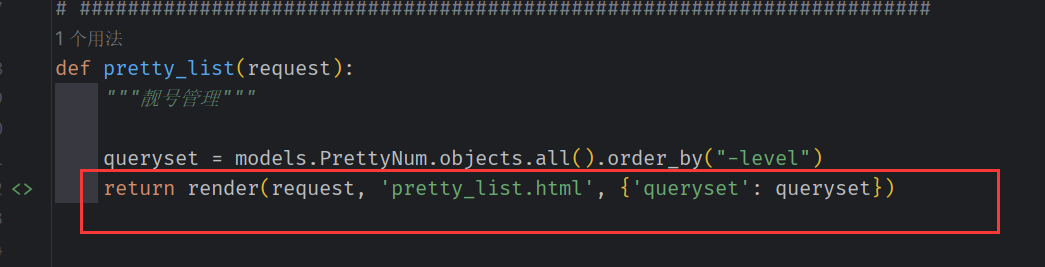
靓号前端显示
同 部门列表显示
靓号的增加
同用户的增加
增加验证方式
方式一
使用正则
from django.forms import Form
from django.forms import widgets
from django.forms import fields
from django.core.validators import RegexValidator
class MyForm(Form):
user = fields.CharField(
validators=[RegexValidator(r'^[0-9]+$', '请输入数字'), RegexValidator(r'^159[0-9]+$', '数字必须以159开头')],
)
方式二
自定义 钩子方法
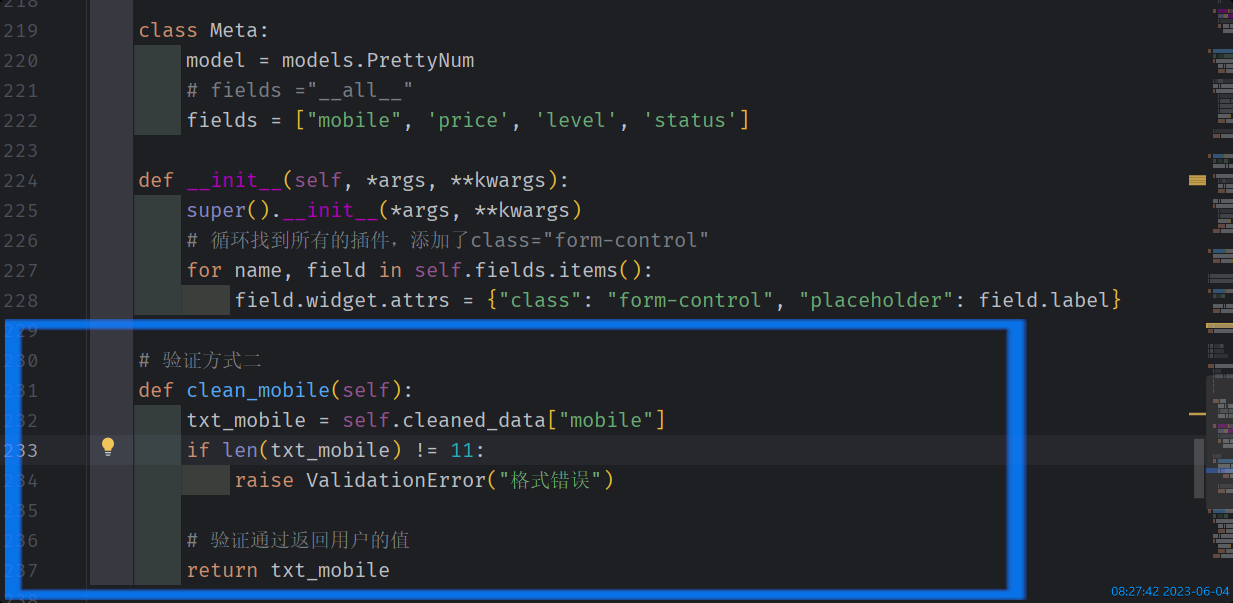
方式三
自定义验证规则
import re
from django.forms import Form
from django.forms import widgets
from django.forms import fields
from django.core.exceptions import ValidationError
# 自定义验证规则
def mobile_validate(value):
mobile_re = re.compile(r'^(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])[0-9]{8}$')
if not mobile_re.match(value):
raise ValidationError('手机号码格式错误')
class PublishForm(Form):
title = fields.CharField(max_length=20,
min_length=5,
error_messages={'required': '标题不能为空',
'min_length': '标题最少为5个字符',
'max_length': '标题最多为20个字符'},
widget=widgets.TextInput(attrs={'class': "form-control",
'placeholder': '标题5-20个字符'}))
# 使用自定义验证规则
phone = fields.CharField(validators=[mobile_validate, ],
error_messages={'required': '手机不能为空'},
widget=widgets.TextInput(attrs={'class': "form-control",
'placeholder': u'手机号码'}))
email = fields.EmailField(required=False,
error_messages={'required': u'邮箱不能为空','invalid': u'邮箱格式错误'},
widget=widgets.TextInput(attrs={'class': "form-control", 'placeholder': u'邮箱'}))
方法四
同时生成多个标签进行验证
from django.forms import Form
from django.forms import widgets
from django.forms import fields
from django.core.validators import RegexValidator
############## 自定义字段 ##############
class PhoneField(fields.MultiValueField):
def __init__(self, *args, **kwargs):
# Define one message for all fields.
error_messages = {
'incomplete': 'Enter a country calling code and a phone number.',
}
# Or define a different message for each field.
f = (
fields.CharField(
error_messages={'incomplete': 'Enter a country calling code.'},
validators=[
RegexValidator(r'^[0-9]+$', 'Enter a valid country calling code.'),
],
),
fields.CharField(
error_messages={'incomplete': 'Enter a phone number.'},
validators=[RegexValidator(r'^[0-9]+$', 'Enter a valid phone number.')],
),
fields.CharField(
validators=[RegexValidator(r'^[0-9]+$', 'Enter a valid extension.')],
required=False,
),
)
super(PhoneField, self).__init__(error_messages=error_messages, fields=f, require_all_fields=False, *args,
**kwargs)
def compress(self, data_list):
"""
当用户验证都通过后,该值返回给用户
:param data_list:
:return:
"""
return data_list
############## 自定义插件 ##############
class SplitPhoneWidget(widgets.MultiWidget):
def __init__(self):
ws = (
widgets.TextInput(),
widgets.TextInput(),
widgets.TextInput(),
)
super(SplitPhoneWidget, self).__init__(ws)
def decompress(self, value):
"""
处理初始值,当初始值initial不是列表时,调用该方法
:param value:
:return:
"""
if value:
return value.split(',')
return [None, None, None]
手机号不允许重复
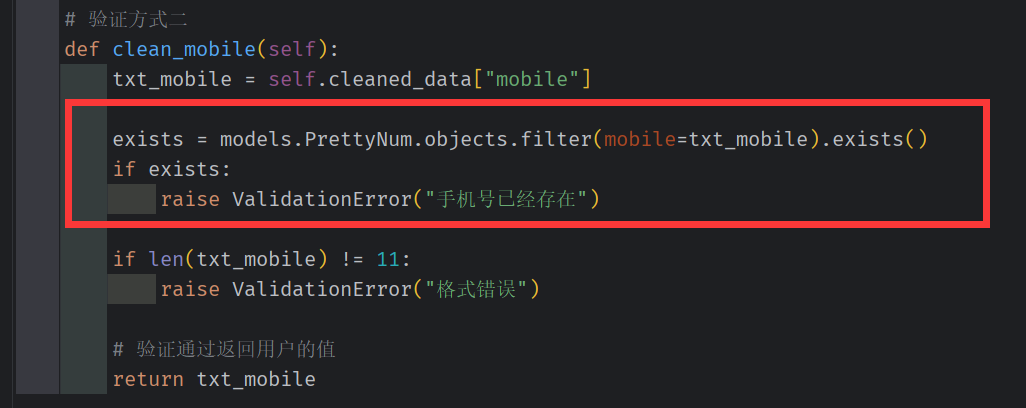
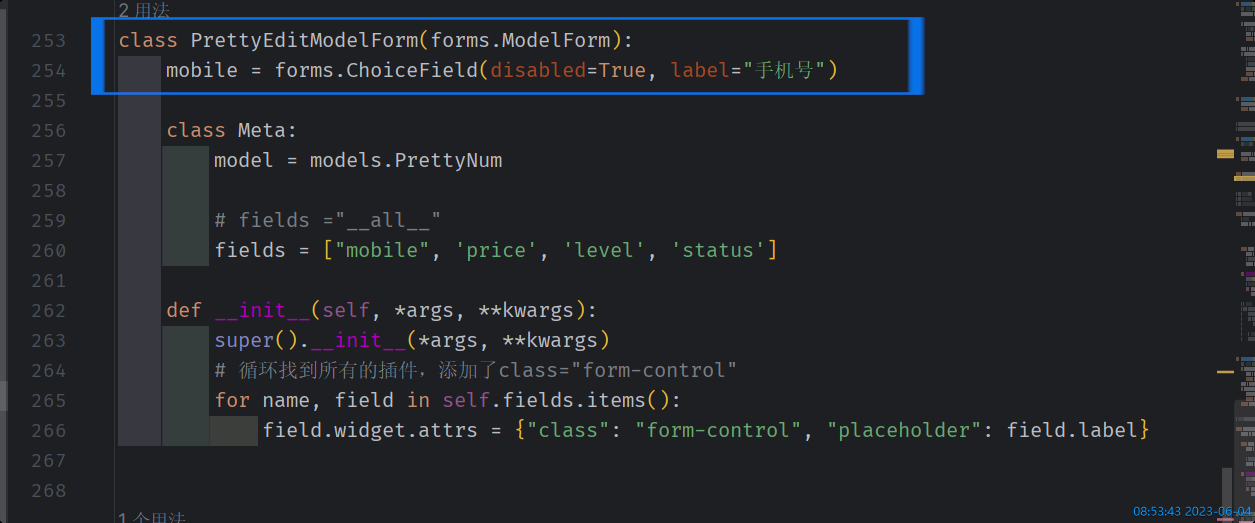
编辑靓号
同用户编辑
只是额外 加了一个modelForm,使得手机号不可编辑,
不允许手机号重复 (在手机号设置可编辑的话)
排除当前手机号的前提下,不允许手机号重复
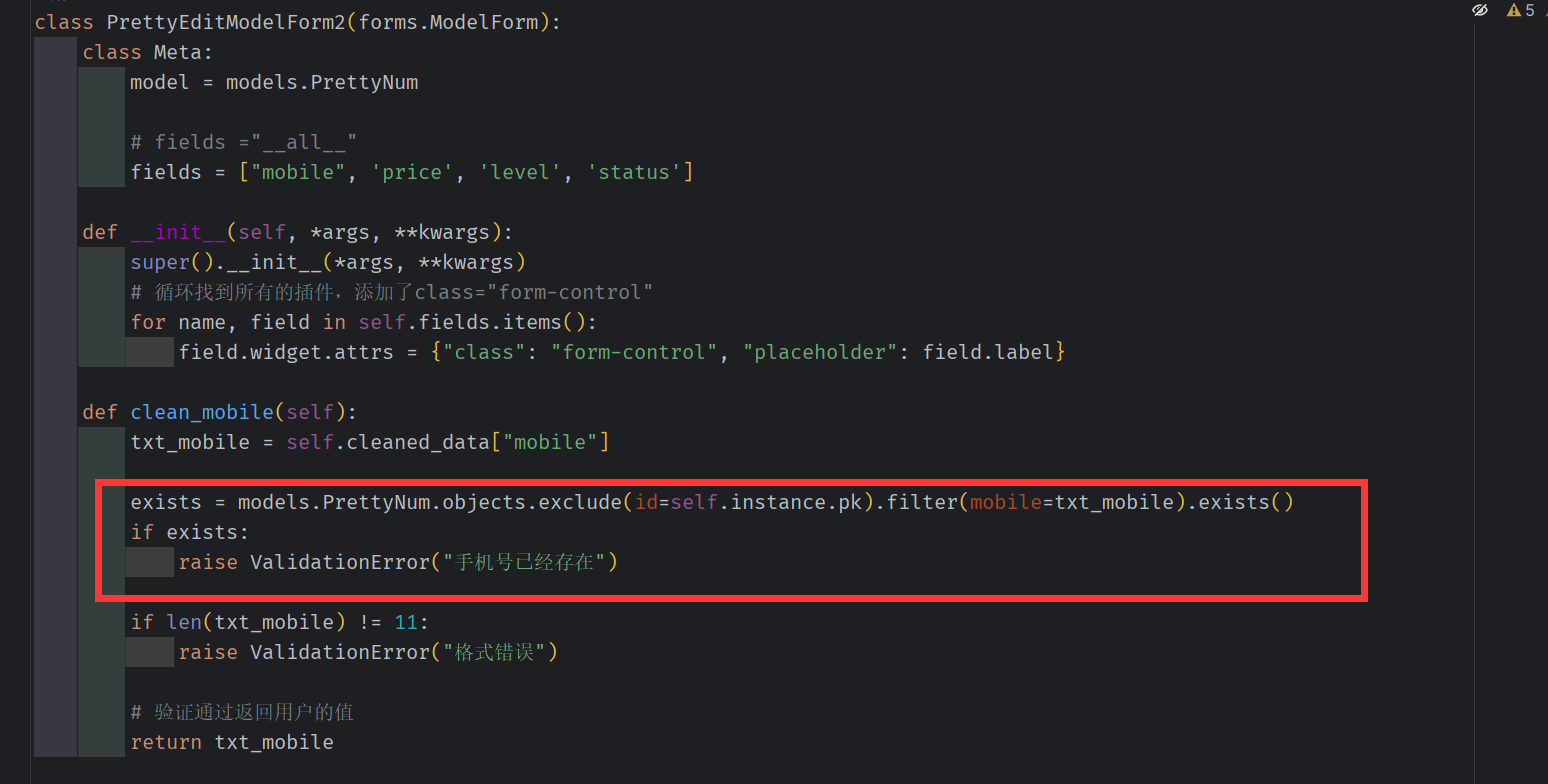
self.instance是modelform对象的实例化,包含了对象中的内容,我们可以通过self.instance访问并获取到对象的数据进行操作。
pk就是primary key的缩写,也就是任何model中都有的主键,那么id呢,大部分时候也是model的主键,所以在这个时候我们可以认为pk和id是完全一样的。
参见
参见二
靓号搜索
我们只要控制链接的q=…, 就能让modelForm过滤出来 q=…了
改造view 中的 pretty_list
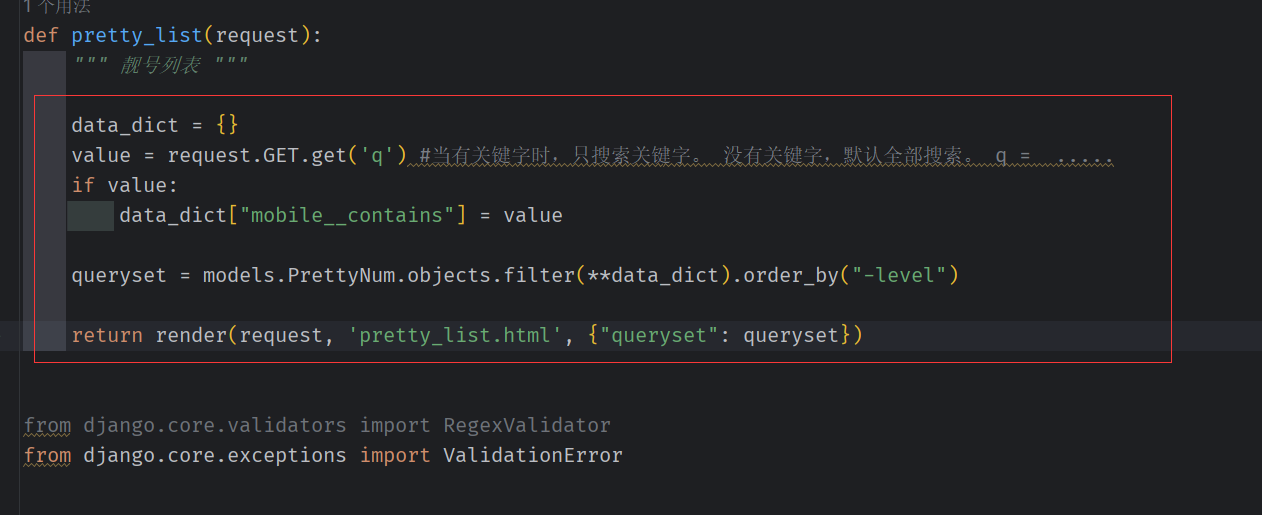
下面这样中过滤写法都可行

Django 的一些过滤条件扩展
models.PrettyNum.objects.filter(id=12) # 等于12
models.PrettyNum.objects.filter(id__gt=12) # 大于12
models.PrettyNum.objects.filter(id__gte=12) # 大于等于12
models.PrettyNum.objects.filter(id__lt=12) # 小于12
models.PrettyNum.objects.filter(id__lte=12) # 小于等于12
data_dict = {"id__lte":12}
models.PrettyNum.objects.filter(**data_dict)
models.PrettyNum.objects.filter(mobile="999") # 等于
models.PrettyNum.objects.filter(mobile__startswith="1999") # 筛选出以1999开头
models.PrettyNum.objects.filter(mobile__endswith="999") # 筛选出以999结尾
models.PrettyNum.objects.filter(mobile__contains="999") # 筛选出包含999
data_dict = {"mobile__contains":"999"}
models.PrettyNum.objects.filter(**data_dict)
改造pretty_list.html
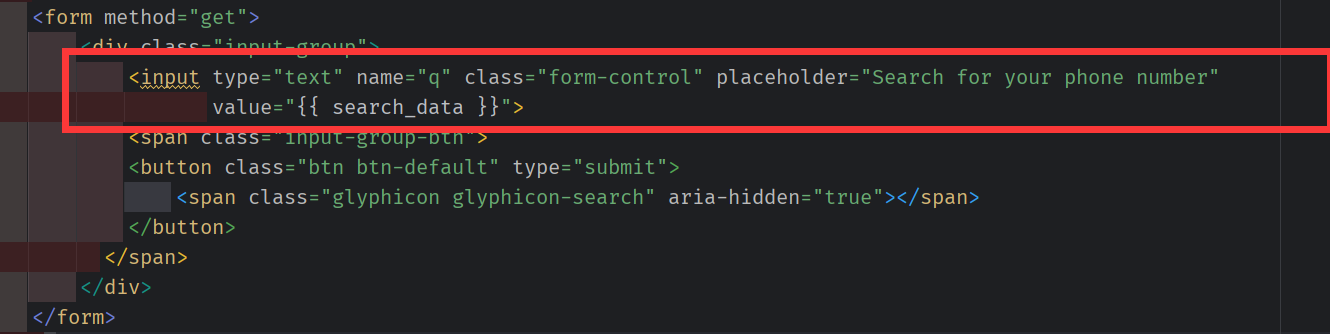
增加搜索框和 提交方法
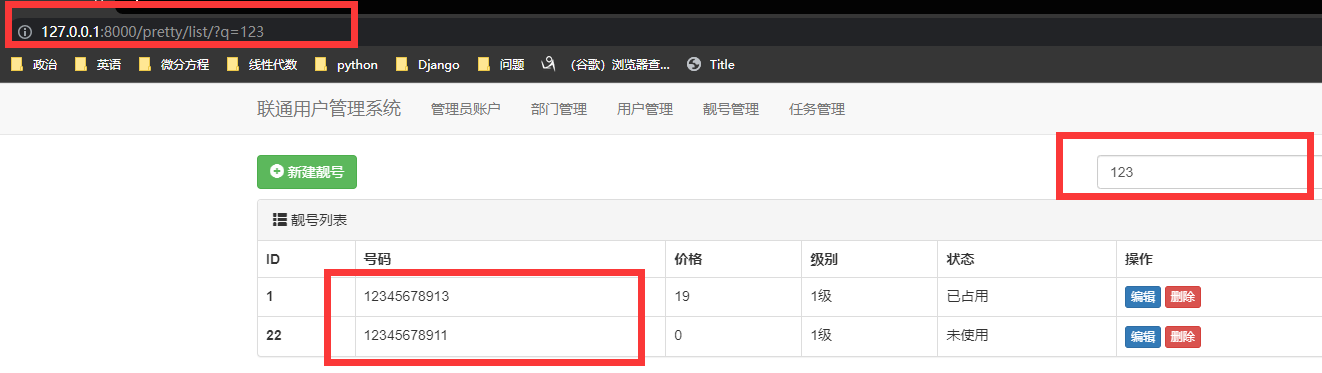
靓号分页
Django 的分页
queryset = models.PrettyNum.objects.all()
#查询出所有手机号的集合
queryset = models.PrettyNum.objects.filter(id=1)[0:10]
#查询出所有符合条件的手机号的集合,并进行切片,每次取出10个
# 第1页
queryset = models.PrettyNum.objects.all()[0:10]
#查询出所有手机号的集合,并进行切片。每次取10个
# 第2页
queryset = models.PrettyNum.objects.all()[10:20]
# 第3页
queryset = models.PrettyNum.objects.all()[20:30]
data = models.PrettyNum.objects.all().count()
查询出所有手机号的集合的数量,
data = models.PrettyNum.objects.filter(id=1).count()
#查询出所有符合条件的手机号的数量。
每页展示数目
1.根据用户像访问的页码,计算出起止位置
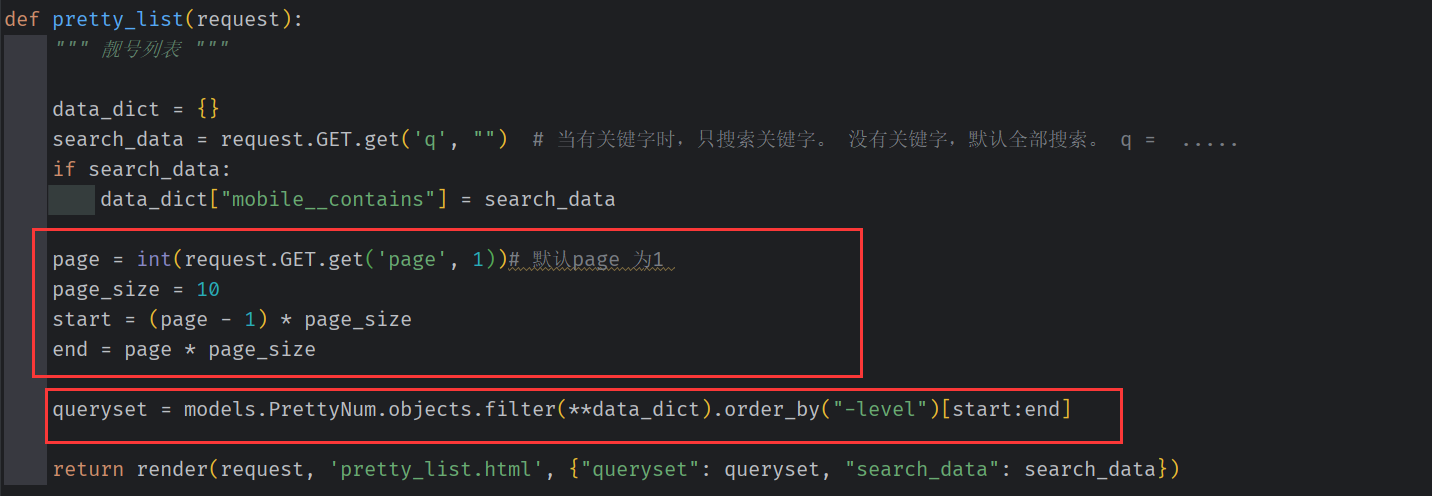
page 当前页 page_size 每页显示10条。 start 切片开始页码,end 切片结束页码
关于 request.GET.get() 参见
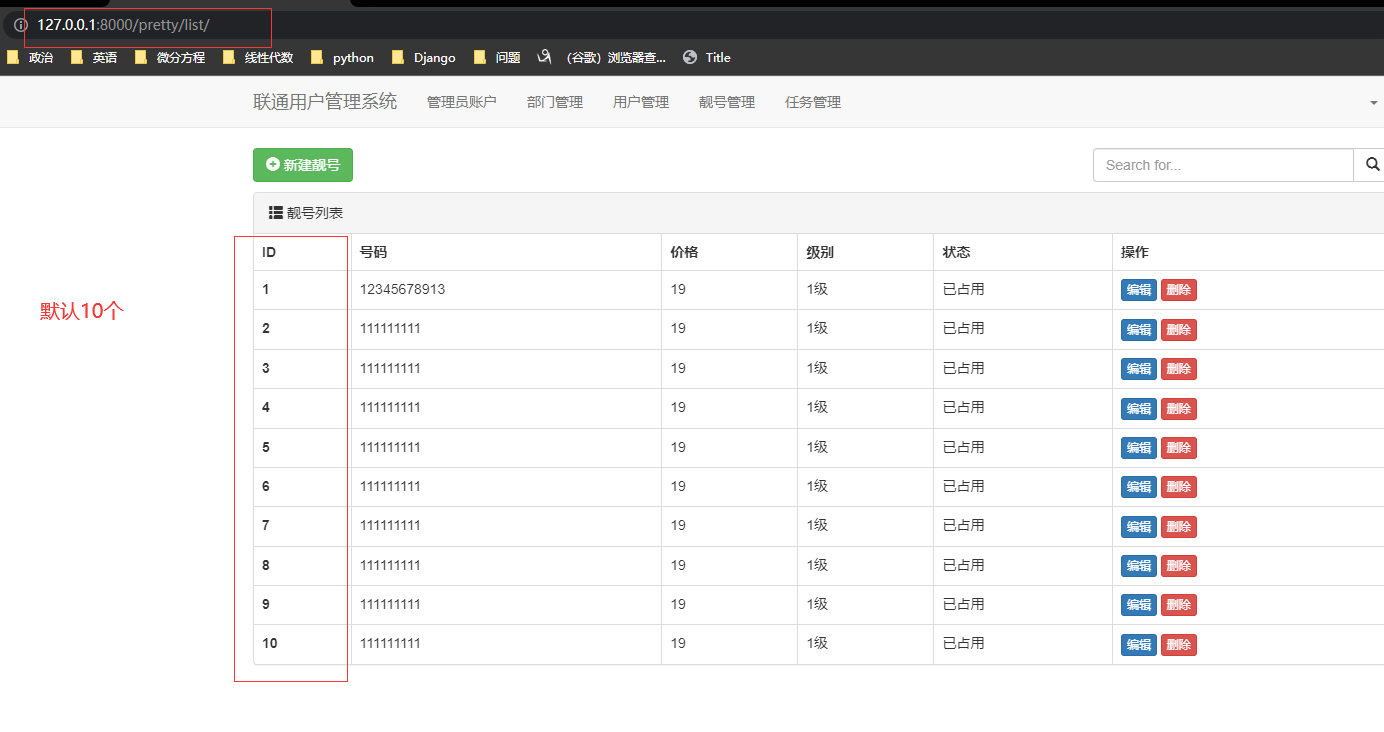
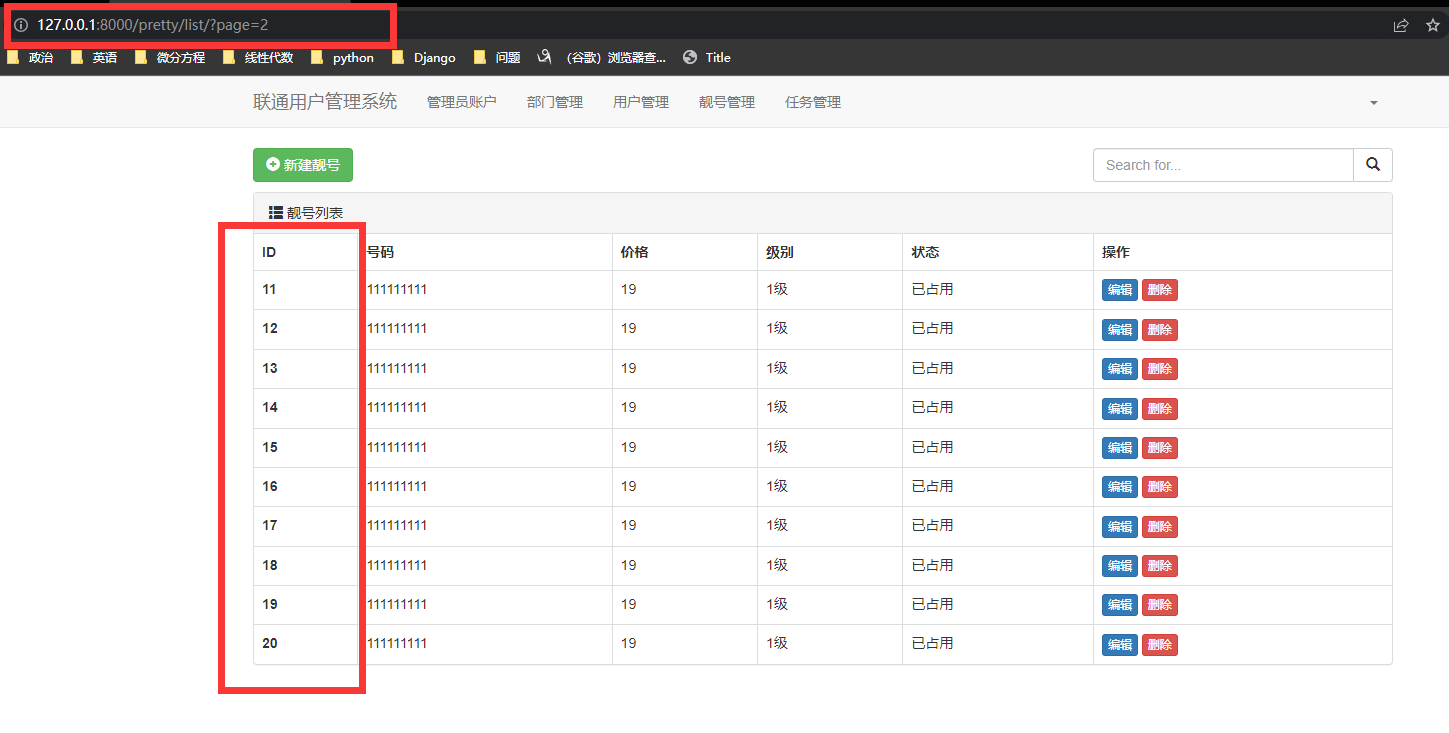
静态页码
增加前端页面的页码
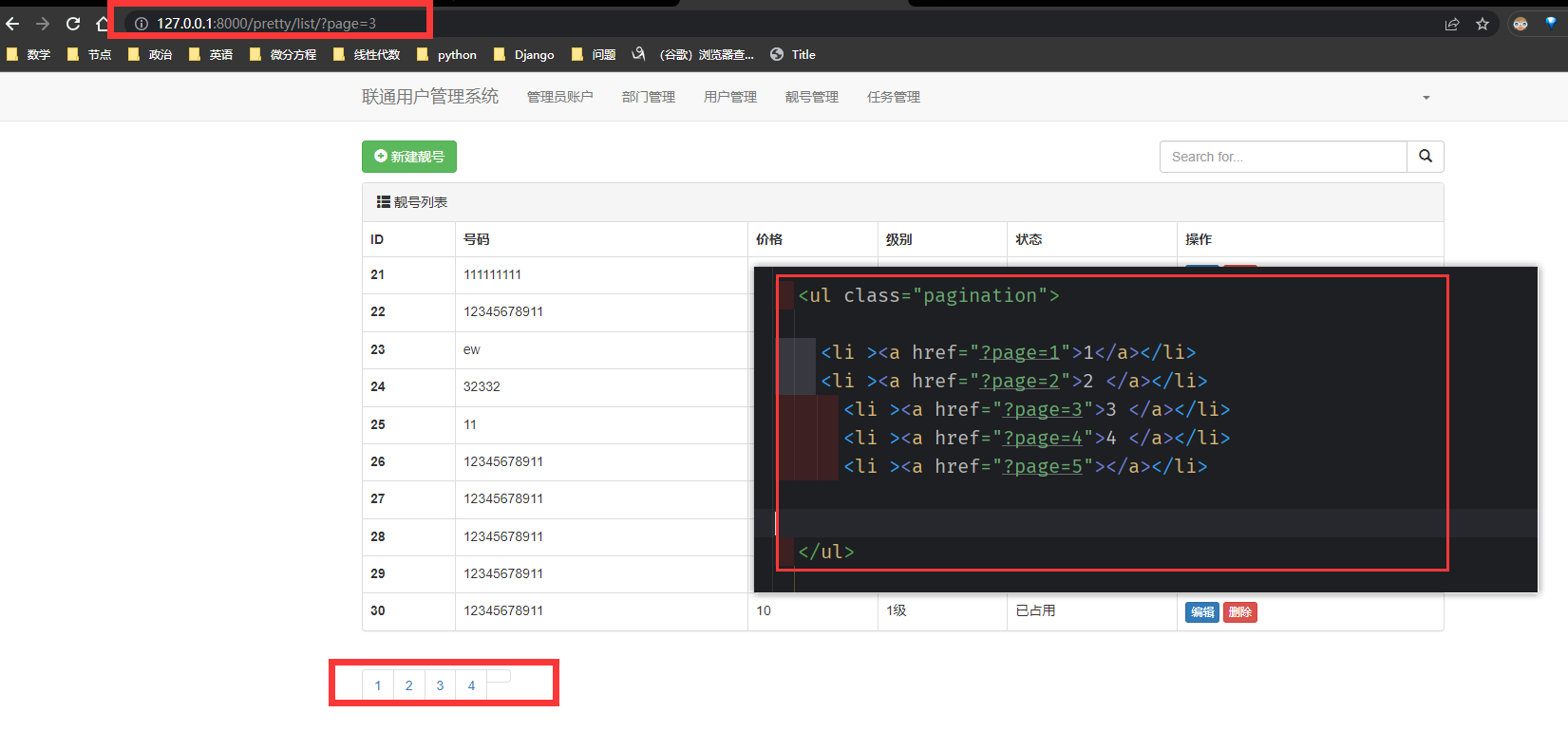
通过 a标签跳转网址
后台生成页码
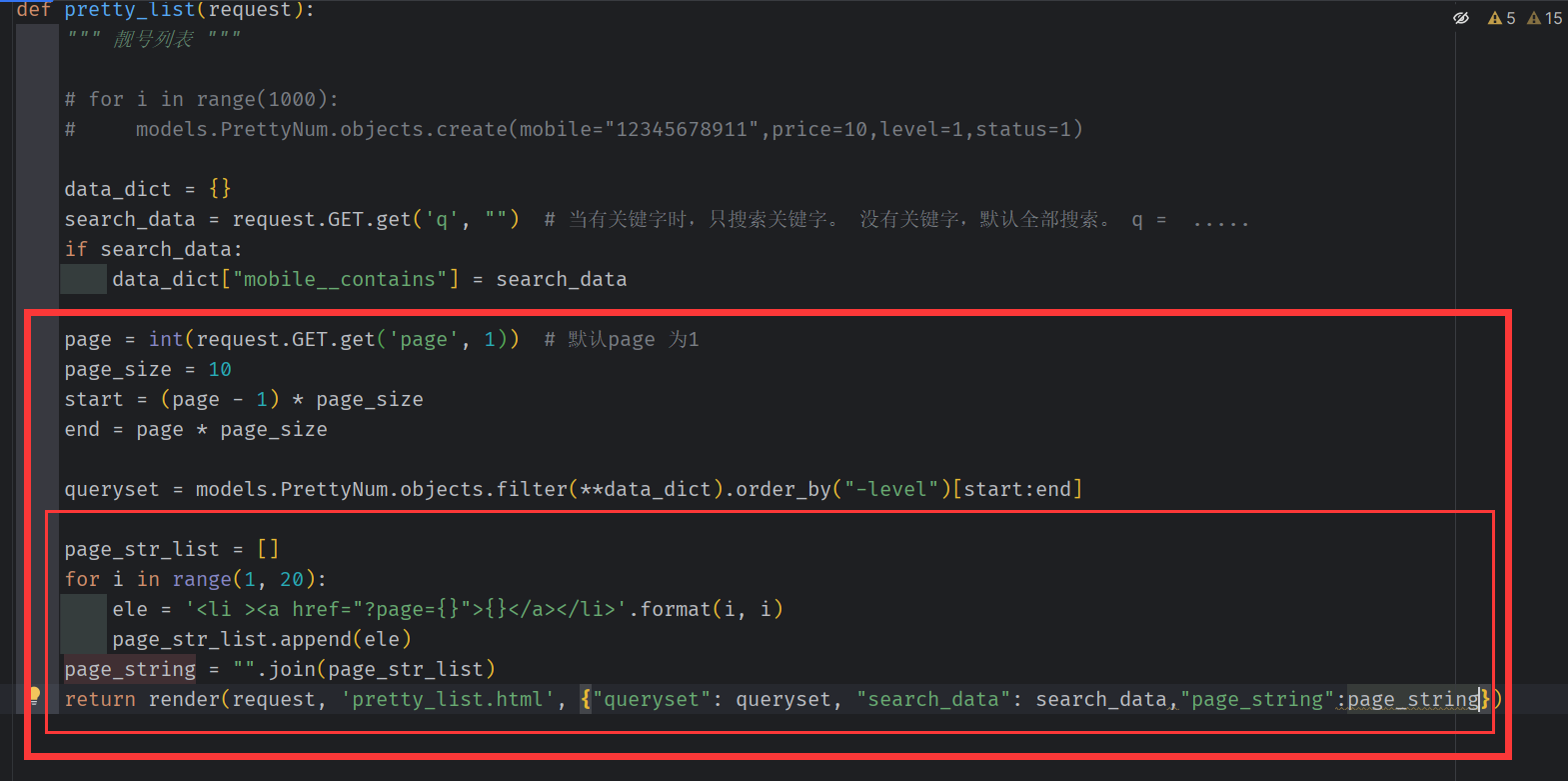
page 当前页 page_size 每页显示10条。 start 切片开始页码,end 切片结束页码
for 循环 模拟生成 20条页码

加上mark_safe,才会在前台生成html
用数据库的数据条数/分页大小,计算得到 页码数替换之前模拟显示的20个页码
处理分页过多的情况

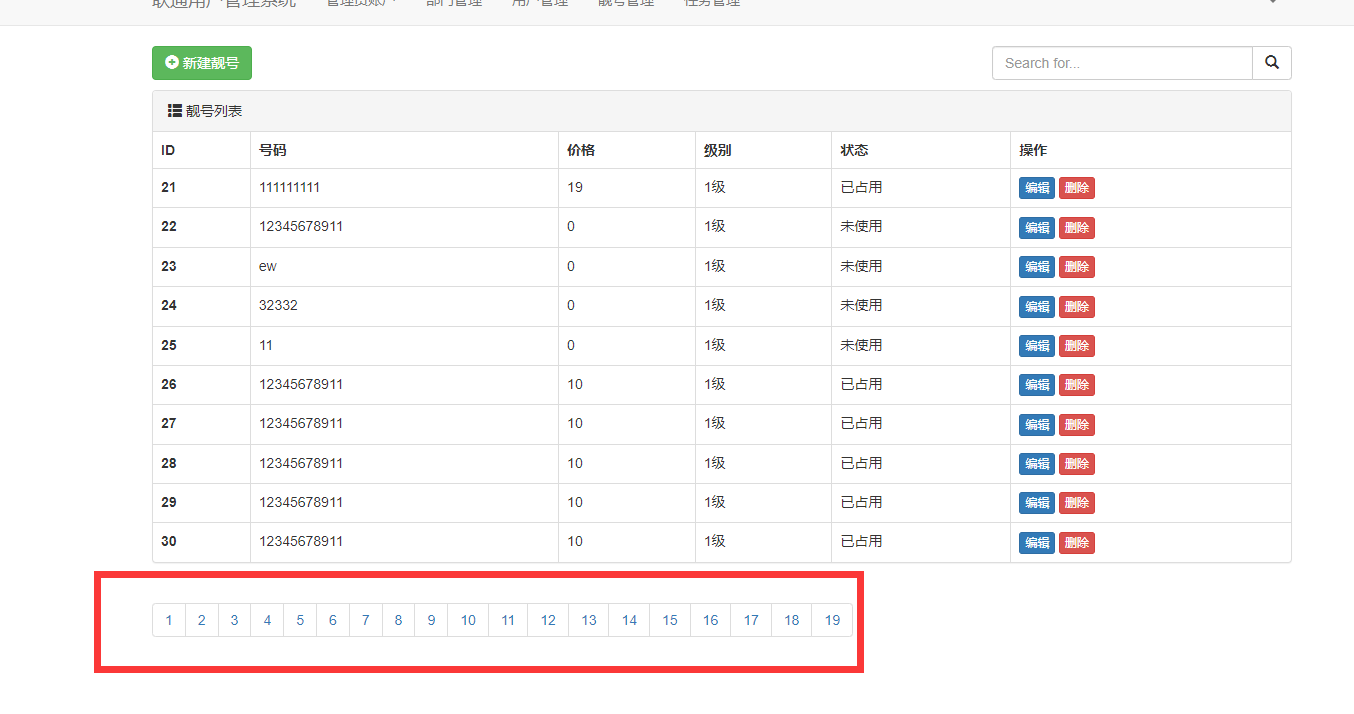
当 数据过多,页码将妨碍使用
只显示当前页面 页码的前九页, 后九页。 同时加上当前页面标记
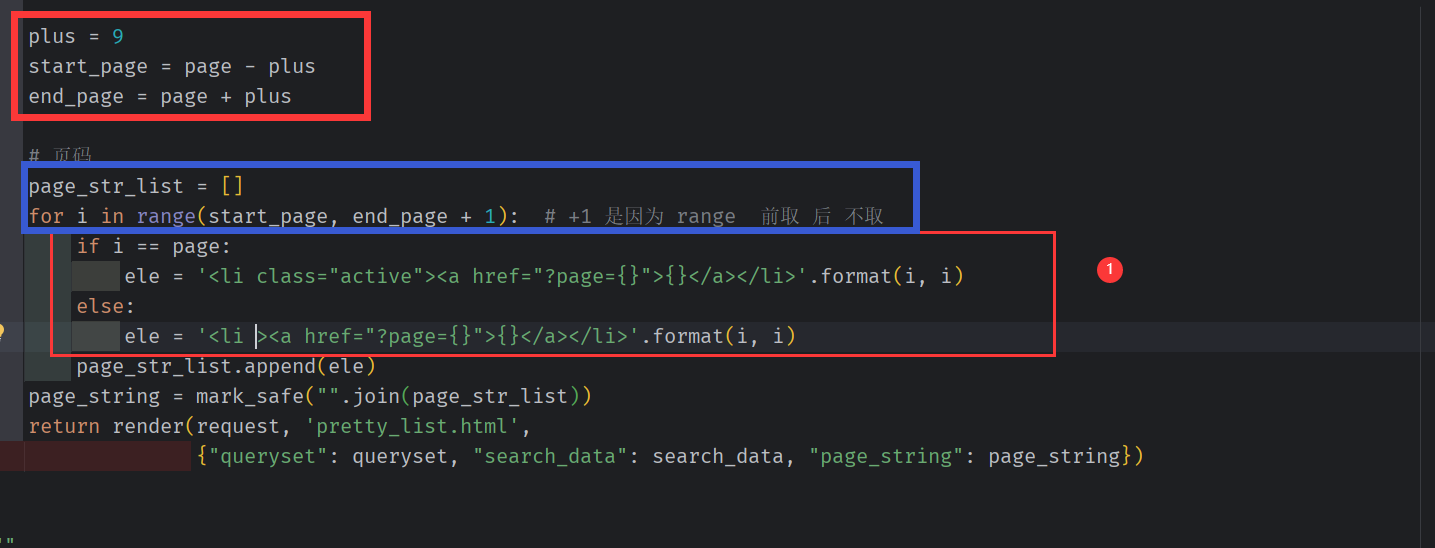
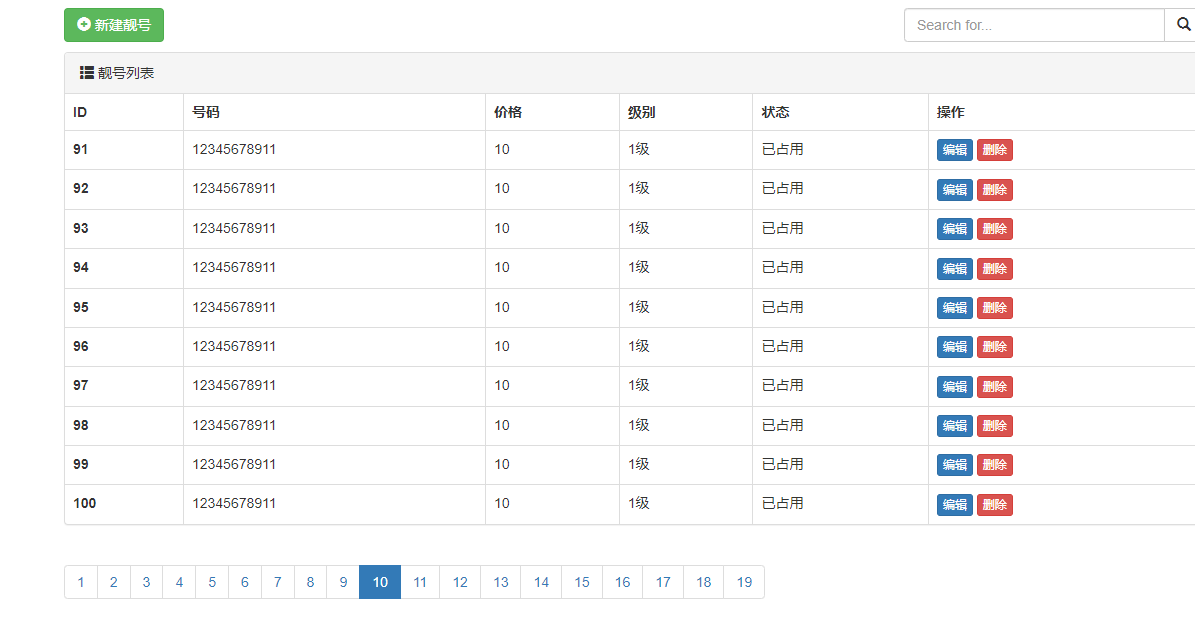
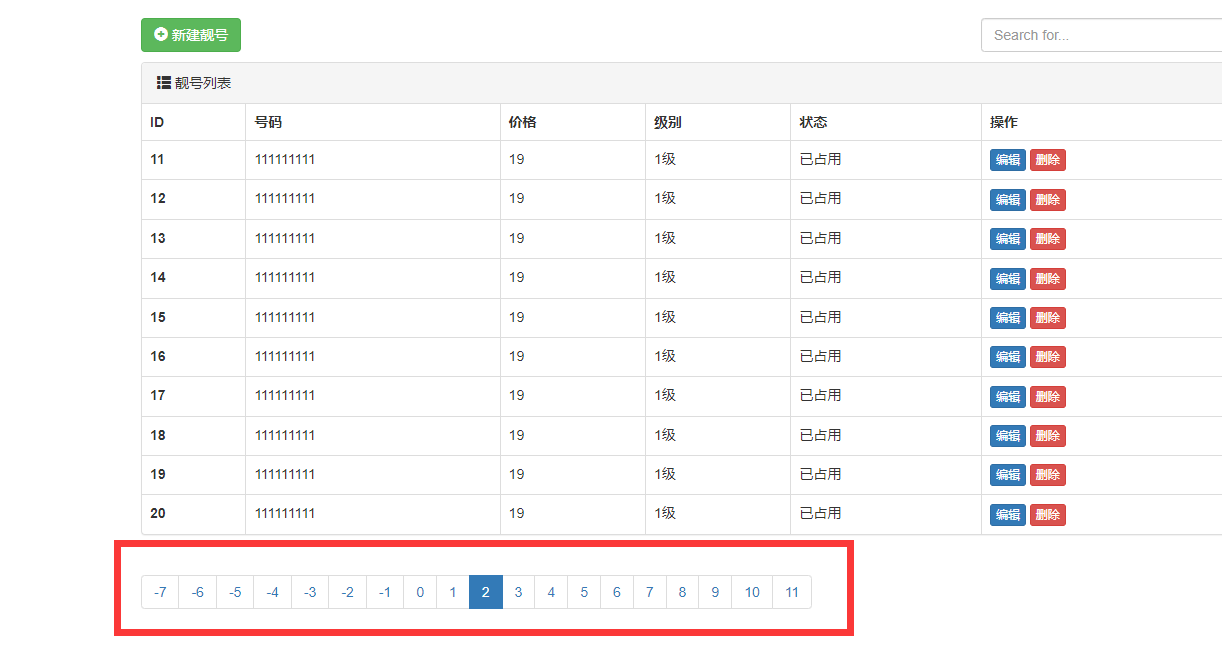
解决出现 极值问题
情况1: 页码数出现负值
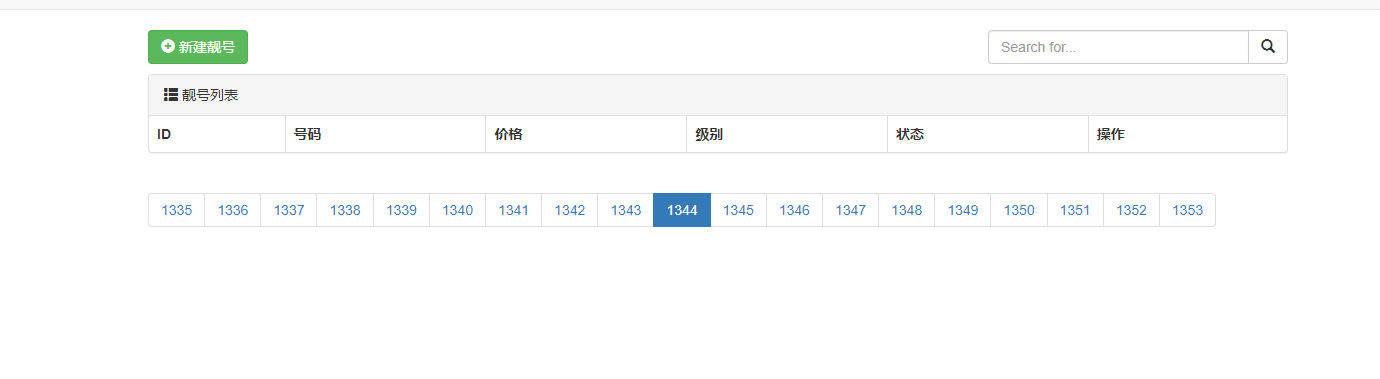
情况二 :页码总数大于实际的页码总数
data_dict = {}
search_data = request.GET.get('q', "") # 当有关键字时,只搜索关键字。 没有关键字,默认全部搜索。 q = .....
if search_data:
data_dict["mobile__contains"] = search_data
page = int(request.GET.get('page', 1)) # 默认page 为1
page_size = 10
start = (page - 1) * page_size
end = page * page_size
queryset = models.PrettyNum.objects.filter(**data_dict).order_by("-level")[start:end]
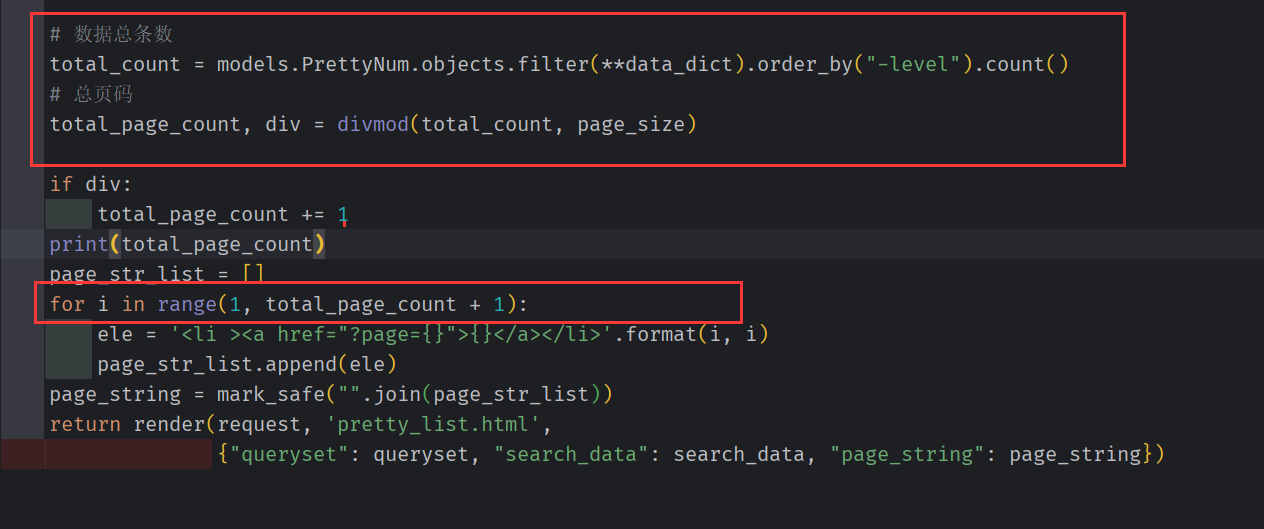
# 数据总条数
total_count = models.PrettyNum.objects.filter(**data_dict).order_by("-level").count()
# 总页码
total_page_count, div = divmod(total_count, page_size)
if div:
total_page_count += 1
plus = 9
if total_page_count <= 2 * plus + 1:
# 如果数据库当前数据比较少,都没有达到19页, start_page 就始终为 1 ,end_page 该是多少就是多少。
start_page = 1
end_page = total_page_count
else:
# 当前数据库中数据比较多 >20
if page <= plus: # 小极值,当当前页小于 9 时, 开始页就要固定为1,
start_page = 1
end_page = 2 * plus + 1
else:
if (page + plus) > total_page_count: # 大极值, 如果 当前页面+5 大于 总页面, 则开始页码 = 总页面 -2*plus .
# 结束页码 = 总页码
start_page = total_page_count - 2 * plus
end_page = total_page_count
else:
start_page = page - plus
end_page = page + plus + 1
# 循环生成中间页
for i in range(start_page, end_page):
if i == page:
ele = '<li class="active"><a href="?page={}">{}</a></li>'.format(i, i)
else:
ele = '<li ><a href="?page={}">{}</a></li>'.format(i, i)
page_str_list.append(ele)
增加上一页 下一页,首页尾页 ,跳转某页
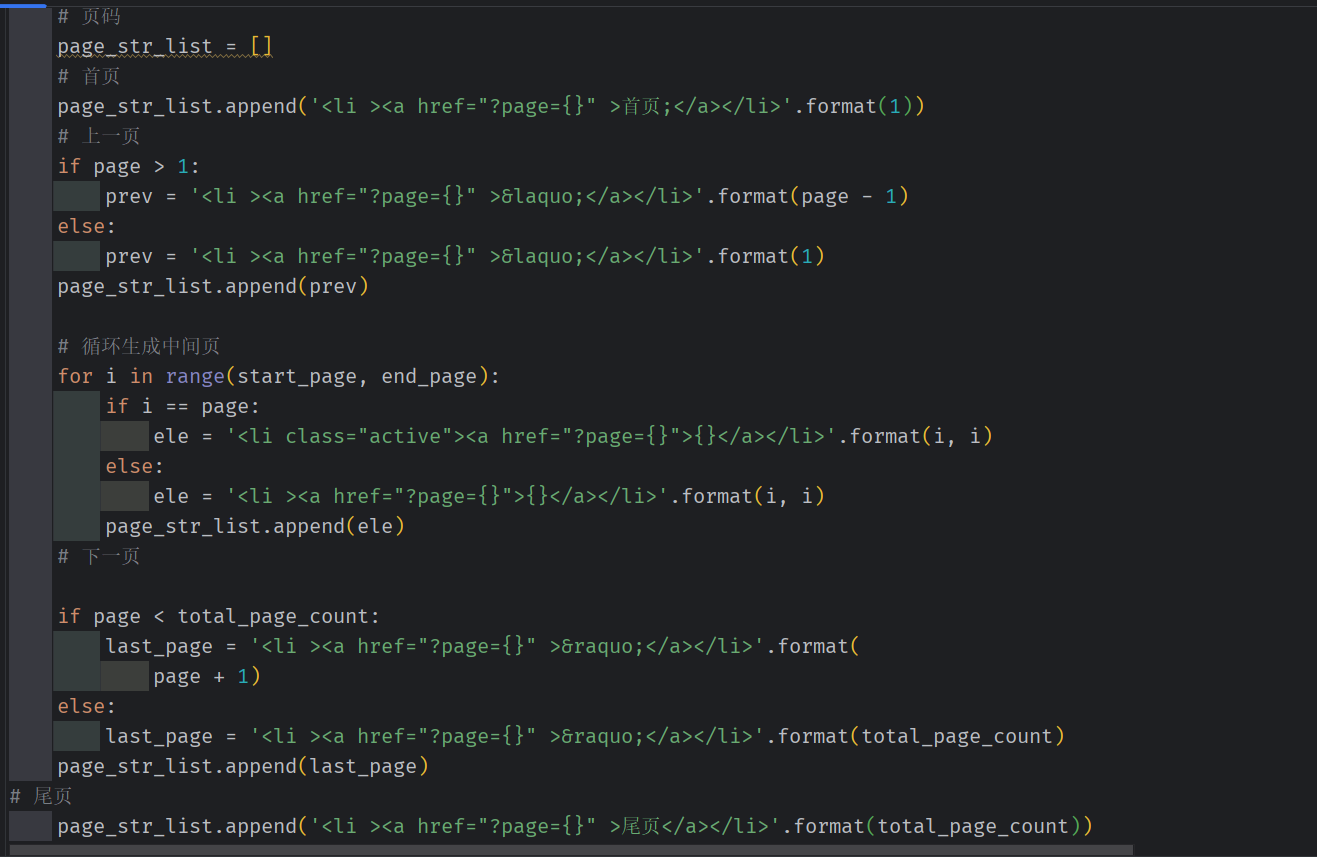
代码总览
# ###################################################靓号管理
# #######################################################################
# def pretty_list(request):
# """靓号管理"""
#
# queryset = models.PrettyNum.objects.all().order_by("-level")
# return render(request, 'pretty_list.html', {'queryset': queryset})
#
def pretty_list(request):
""" 靓号列表 """
# for i in range(1000):
# models.PrettyNum.objects.create(mobile="12345678911",price=10,level=1,status=1)
data_dict = {}
search_data = request.GET.get('q', "") # 当有关键字时,只搜索关键字。 没有关键字,默认全部搜索。 q = .....
if search_data:
data_dict["mobile__contains"] = search_data
page = int(request.GET.get('page', 1)) # 默认page 为1
page_size = 10
start = (page - 1) * page_size
end = page * page_size
queryset = models.PrettyNum.objects.filter(**data_dict).order_by("-level")[start:end]
# 数据总条数
total_count = models.PrettyNum.objects.filter(**data_dict).order_by("-level").count()
# 总页码
total_page_count, div = divmod(total_count, page_size)
if div:
total_page_count += 1
plus = 5
if total_page_count <= 2 * plus + 1:
# 如果数据库当前数据比较少,都没有达到 11页, start_page 就始终为 1 ,end_page 该是多少就是多少。
start_page = 1
end_page = total_page_count
else:
# 当前数据库中数据比较多 >11
if page <= plus: # 小极值,当当前页小于 5 时, 开始页就要固定为1,
start_page = 1
end_page = 2 * plus + 1
else:
if (page + plus) > total_page_count: # 大极值, 如果 当前页面+5 大于 总页面, 则开始页码 = 总页面 -2*plus .
# 结束页码 = 总页码
start_page = total_page_count - 2 * plus
end_page = total_page_count
else:
start_page = page - plus
end_page = page + plus + 1
# 页码
page_str_list = []
# 首页
page_str_list.append('<li ><a href="?page={}" >首页</a></li>'.format(1))
# 上一页
if page > 1:
prev = '<li ><a href="?page={}" >«</a></li>'.format(page - 1)
else:
prev = '<li ><a href="?page={}" >«</a></li>'.format(1)
page_str_list.append(prev)
# 循环生成中间页
for i in range(start_page, end_page):
if i == page:
ele = '<li class="active"><a href="?page={}">{}</a></li>'.format(i, i)
else:
ele = '<li ><a href="?page={}">{}</a></li>'.format(i, i)
page_str_list.append(ele)
# 下一页
if page < total_page_count:
last_page = '<li ><a href="?page={}" >»</a></li>'.format(
page + 1)
else:
last_page = '<li ><a href="?page={}" >»</a></li>'.format(total_page_count)
page_str_list.append(last_page)
# 尾页
page_str_list.append('<li ><a href="?page={}" >尾页</a></li>'.format(total_page_count))
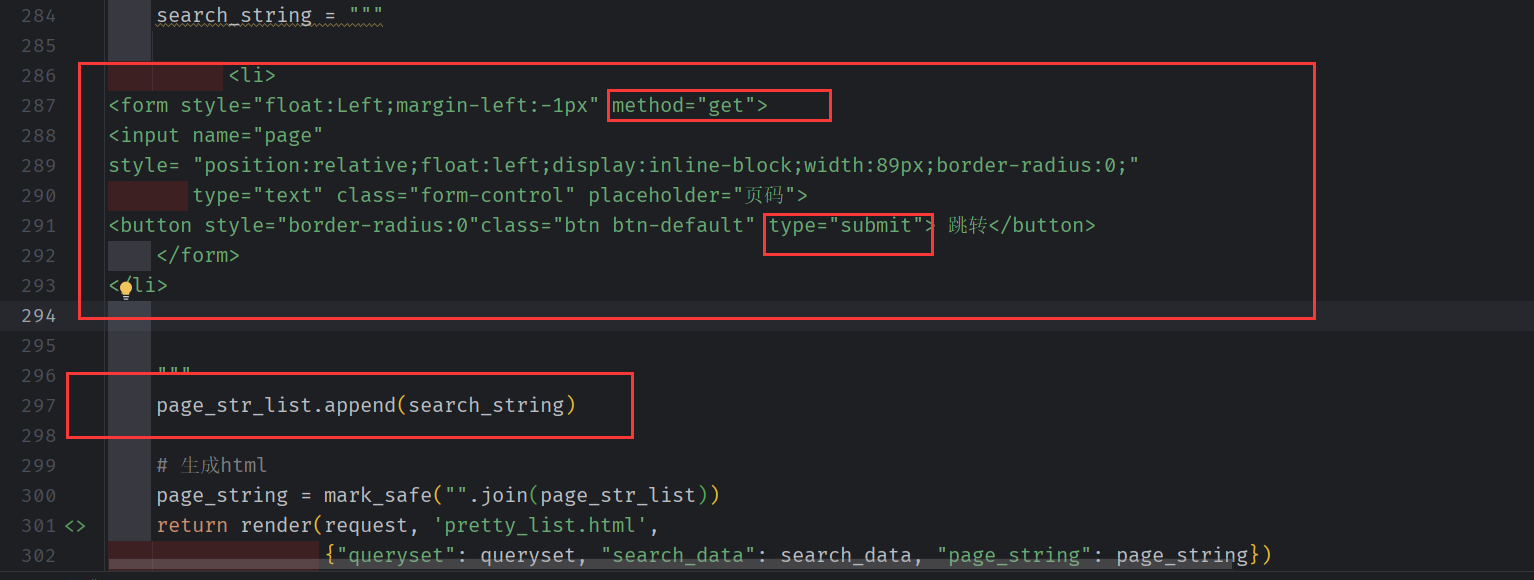
#搜索框
search_string = """
<li>
<form style="float:Left;margin-left:-1px" method="get">
<input name="page"
style= "position:relative;float:left;display:inline-block;width:89px;border-radius:0;"
type="text" class="form-control" placeholder="页码">
<button style="border-radius:0"class="btn btn-default" type="submit"> 跳转</button>
</form>
</li>
"""
page_str_list.append(search_string)
# 生成html
page_string = mark_safe("".join(page_str_list))
return render(request, 'pretty_list.html',
{"queryset": queryset, "search_data": search_data, "page_string": page_string})
"""
# <li ><a href="?page=1">1</a></li>
# <li ><a href="?page=2">2 </a></li>
# <li ><a href="?page=3">3 </a></li>
# <li ><a href="?page=4">4 </a></li>
# <li ><a href="?page=5"></a></li>
"""
request.GET 是preety_list 传递过来的所有参数

print(request.GET.urlencode()) 可以将传递的参数拼接为url

当我们要将 分页条件(page)和 搜索条件 (q) 合并时 , 就要 修改request. 但 request 是 不可修改的。
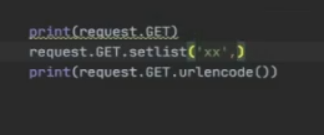

因此就要使用深拷贝,
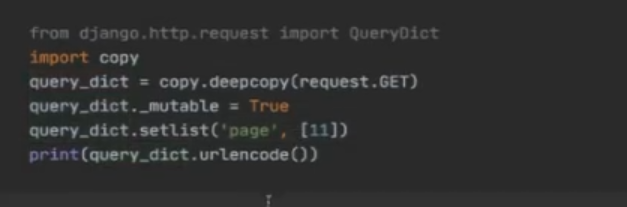
使用 setlist 就能合并page 和 q 的搜索条件,再使用 urlencode 就能拼接为 url

处理Django请求.GET和多个变量相同的参数名称 使用 getlist, 不同的变量使用setlist
请求url:http://127.0.0.1:8000/?param=a¶m=b
获取param参数所有的值:request.GET.getlist('param')
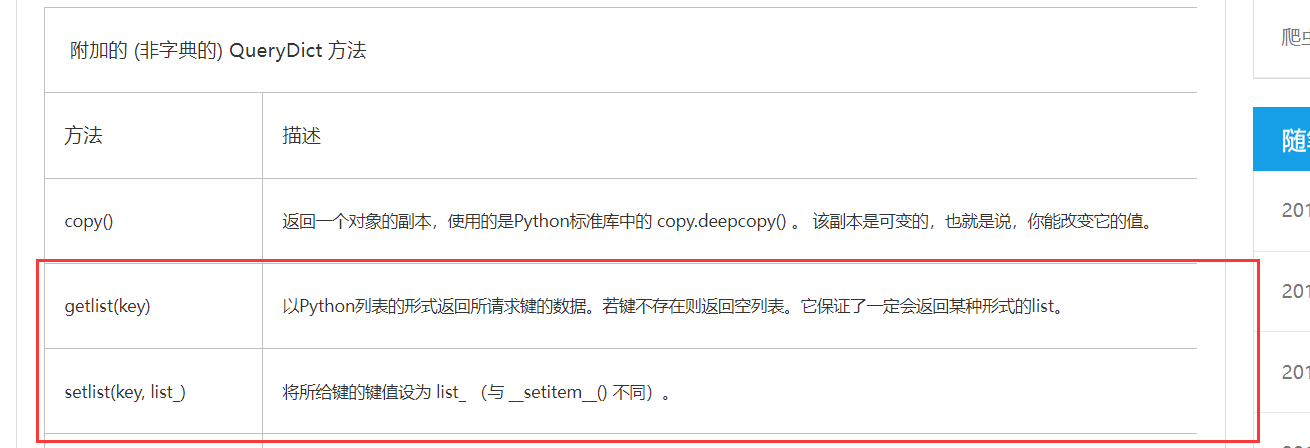
参见 django.http.request中QueryDict 对象
再每次需要 结合 page 和 q 进行搜索的时候 ,都使用 setlist 进行 拼接,(见代码封装)

代码封装
app1 中新建文件夹 utils,
pagination.py
"""
自定义的分页组件,以后如果想要使用这个分页组件,你需要做如下几件事:
在视图函数中:
def pretty_list(request):
# 1.根据自己的情况去筛选自己的数据
queryset = models.PrettyNum.objects.all()
# 2.实例化分页对象
page_object = Pagination(request, queryset)
context = {
"queryset": page_object.page_queryset, # 分完页的数据
"page_string": page_object.html() # 生成页码
}
return render(request, 'pretty_list.html', context)
在HTML页面中
{% for obj in queryset %}
{{obj.xx}}
{% endfor %}
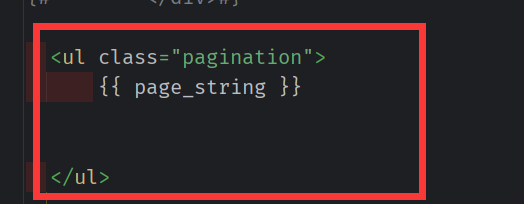
<ul class="pagination">
{{ page_string }}
</ul>
"""
from django.utils.safestring import mark_safe
class Pagination(object):
def __init__(self, request, queryset, page_size=10, page_param="page", plus=5):
"""
:param request: 请求的对象
:param queryset: 符合条件的数据(根据这个数据给他进行分页处理)
:param page_size: 每页显示多少条数据
:param page_param: 在URL中传递的获取分页的参数,例如:/etty/list/?page=12
:param plus: 显示当前页的 前或后几页(页码)
"""
from django.http.request import QueryDict
import copy
query_dict = copy.deepcopy(request.GET)
query_dict._mutable = True
self.query_dict = query_dict
self.page_param = page_param
page = request.GET.get(page_param, "1")
if page.isdecimal():
page = int(page)
else:
page = 1
self.page = page
self.page_size = page_size
self.start = (page - 1) * page_size
self.end = page * page_size
self.page_queryset = queryset[self.start:self.end]
total_count = queryset.count()
total_page_count, div = divmod(total_count, page_size)
if div:
total_page_count += 1
self.total_page_count = total_page_count
self.plus = plus
def html(self):
# 计算出,显示当前页的前5页、后5页
if self.total_page_count <= 2 * self.plus + 1:
# 数据库中的数据比较少,都没有达到11页。
start_page = 1
end_page = self.total_page_count
else:
# 数据库中的数据比较多 > 11页。
# 当前页<5时(小极值)
if self.page <= self.plus:
start_page = 1
end_page = 2 * self.plus + 1
else:
# 当前页 > 5
# 当前页+5 > 总页面
if (self.page + self.plus) > self.total_page_count:
start_page = self.total_page_count - 2 * self.plus
end_page = self.total_page_count
else:
start_page = self.page - self.plus
end_page = self.page + self.plus
# 页码
page_str_list = []
self.query_dict.setlist(self.page_param, [1])
page_str_list.append('<li><a href="?{}">首页</a></li>'.format(self.query_dict.urlencode()))
# 上一页
if self.page > 1:
self.query_dict.setlist(self.page_param, [self.page - 1])
prev = '<li><a href="?{}">上一页</a></li>'.format(self.query_dict.urlencode())
else:
self.query_dict.setlist(self.page_param, [1])
prev = '<li><a href="?{}">上一页</a></li>'.format(self.query_dict.urlencode())
page_str_list.append(prev)
# 页面
for i in range(start_page, end_page + 1):
self.query_dict.setlist(self.page_param, [i])
if i == self.page:
ele = '<li class="active"><a href="?{}">{}</a></li>'.format(self.query_dict.urlencode(), i)
else:
ele = '<li><a href="?{}">{}</a></li>'.format(self.query_dict.urlencode(), i)
page_str_list.append(ele)
# 下一页
if self.page < self.total_page_count:
self.query_dict.setlist(self.page_param, [self.page + 1])
prev = '<li><a href="?{}">下一页</a></li>'.format(self.query_dict.urlencode())
else:
self.query_dict.setlist(self.page_param, [self.total_page_count])
prev = '<li><a href="?{}">下一页</a></li>'.format(self.query_dict.urlencode())
page_str_list.append(prev)
# 尾页
self.query_dict.setlist(self.page_param, [self.total_page_count])
page_str_list.append('<li><a href="?{}">尾页</a></li>'.format(self.query_dict.urlencode()))
search_string = """
<li>
<form style="float: left;margin-left: -1px" method="get">
<input name="page"
style="position: relative;float:left;display: inline-block;width: 80px;border-radius: 0;"
type="text" class="form-control" placeholder="页码">
<button style="border-radius: 0" class="btn btn-default" type="submit">跳转</button>
</form>
</li>
"""
page_str_list.append(search_string)
page_string = mark_safe("".join(page_str_list))
return page_string
调用接口
为其他页面加上 分页组件
优化代码结构
ModelForm和BootStrap
-
ModelForm可以帮助我们生成HTML标签。但这种生成方式不会携带样式
class UserModelForm(forms.ModelForm):
class Meta:
model = models.UserInfo
fields = ["name", "password",]
form = UserModelForm()
{{form.name}} 普通的input框
{{form.password}} 普通的input框
-
定义插件 每个单独的字段都要设置,繁琐
方式一
class UserModelForm(forms.ModelForm):
class Meta:
model = models.UserInfo
fields = ["name", "password",]
widgets = {
"name": forms.TextInput(attrs={"class": "form-control"}),
"password": forms.PasswordInput(attrs={"class": "form-control"}),
"age": forms.TextInput(attrs={"class": "form-control"}),
}
方式二
class UserModelForm(forms.ModelForm):
name = forms.CharField(
min_length=3,
label="用户名",
widget=forms.TextInput(attrs={"class": "form-control"})
)
class Meta:
model = models.UserInfo
fields = ["name", "password", "age"]
{{form.name}} BootStrap的input框
{{form.password}} BootStrap的input框
-
重新定义的init方法,批量设置
class UserModelForm(forms.ModelForm):
class Meta:
model = models.UserInfo
fields = ["name", "password", "age",]
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 循环ModelForm中的所有字段,给每个字段的插件设置
for name, field in self.fields.items():
field.widget.attrs = {
"class": "form-control",
"placeholder": field.label
}
class UserModelForm(forms.ModelForm):
class Meta:
model = models.UserInfo
fields = ["name", "password", "age",]
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 循环ModelForm中的所有字段,给每个字段的插件设置
for name, field in self.fields.items():
# 字段中有属性,保留原来的属性,没有属性,才增加。
if field.widget.attrs:
field.widget.attrs["class"] = "form-control"
field.widget.attrs["placeholder"] = field.label
else:
field.widget.attrs = {
"class": "form-control",
"placeholder": field.label
}
class UserEditModelForm(forms.ModelForm):
class Meta:
model = models.UserInfo
fields = ["name", "password", "age",]
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 循环ModelForm中的所有字段,给每个字段的插件设置
for name, field in self.fields.items():
# 字段中有属性,保留原来的属性,没有属性,才增加。
if field.widget.attrs:
field.widget.attrs["class"] = "form-control"
field.widget.attrs["placeholder"] = field.label
else:
field.widget.attrs = {
"class": "form-control",
"placeholder": field.label
}
-
自定义类
class BootStrapModelForm(forms.ModelForm):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 循环ModelForm中的所有字段,给每个字段的插件设置
for name, field in self.fields.items():
# 字段中有属性,保留原来的属性,没有属性,才增加。
if field.widget.attrs:
field.widget.attrs["class"] = "form-control"
field.widget.attrs["placeholder"] = field.label
else:
field.widget.attrs = {
"class": "form-control",
"placeholder": field.label
}
让要使用bootstrap 的类继承自这个类
class UserEditModelForm(BootStrapModelForm):
class Meta:
model = models.UserInfo
fields = ["name", "password", "age",]
控制器分离
之前的view.py
操作
-
提取公共的类
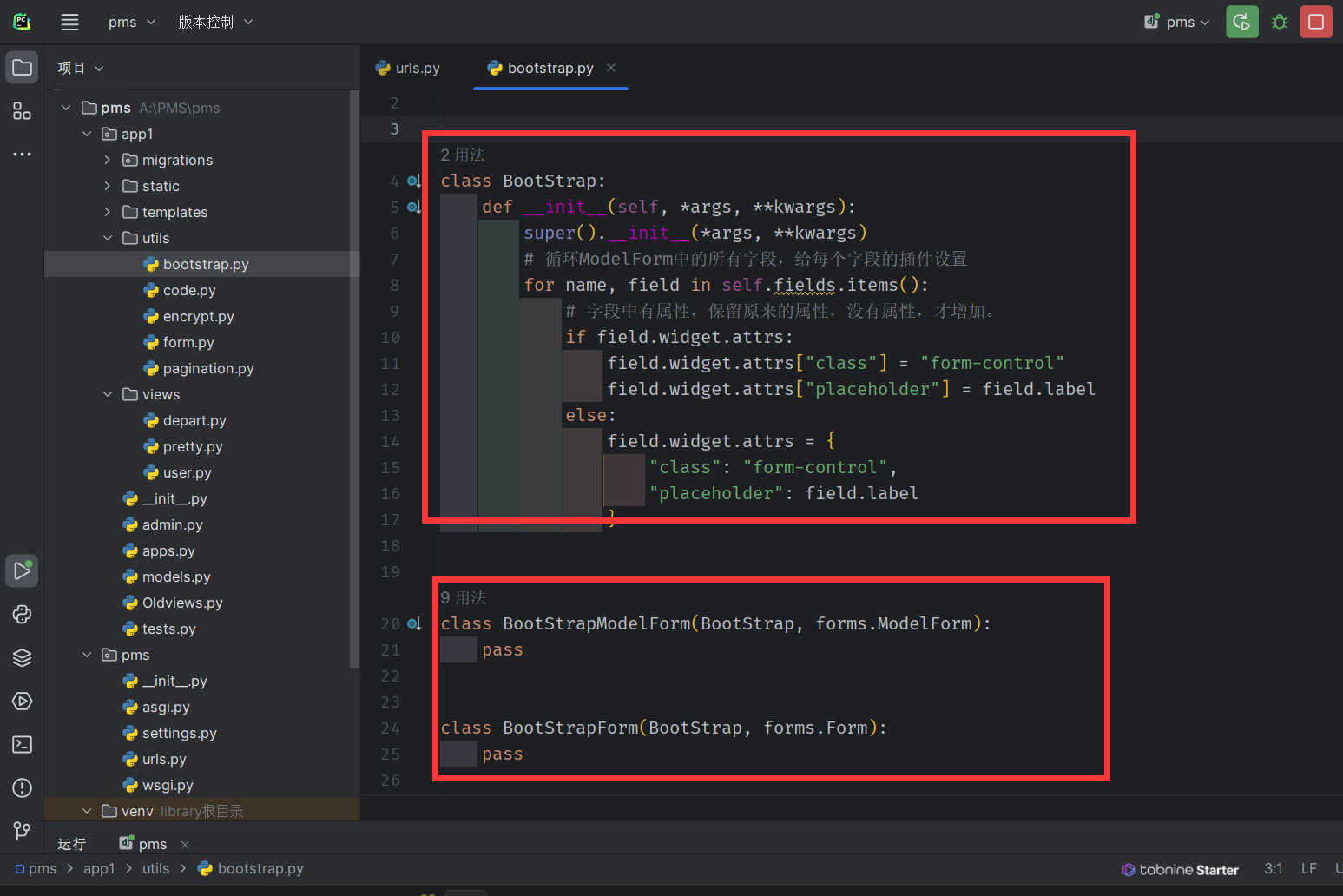
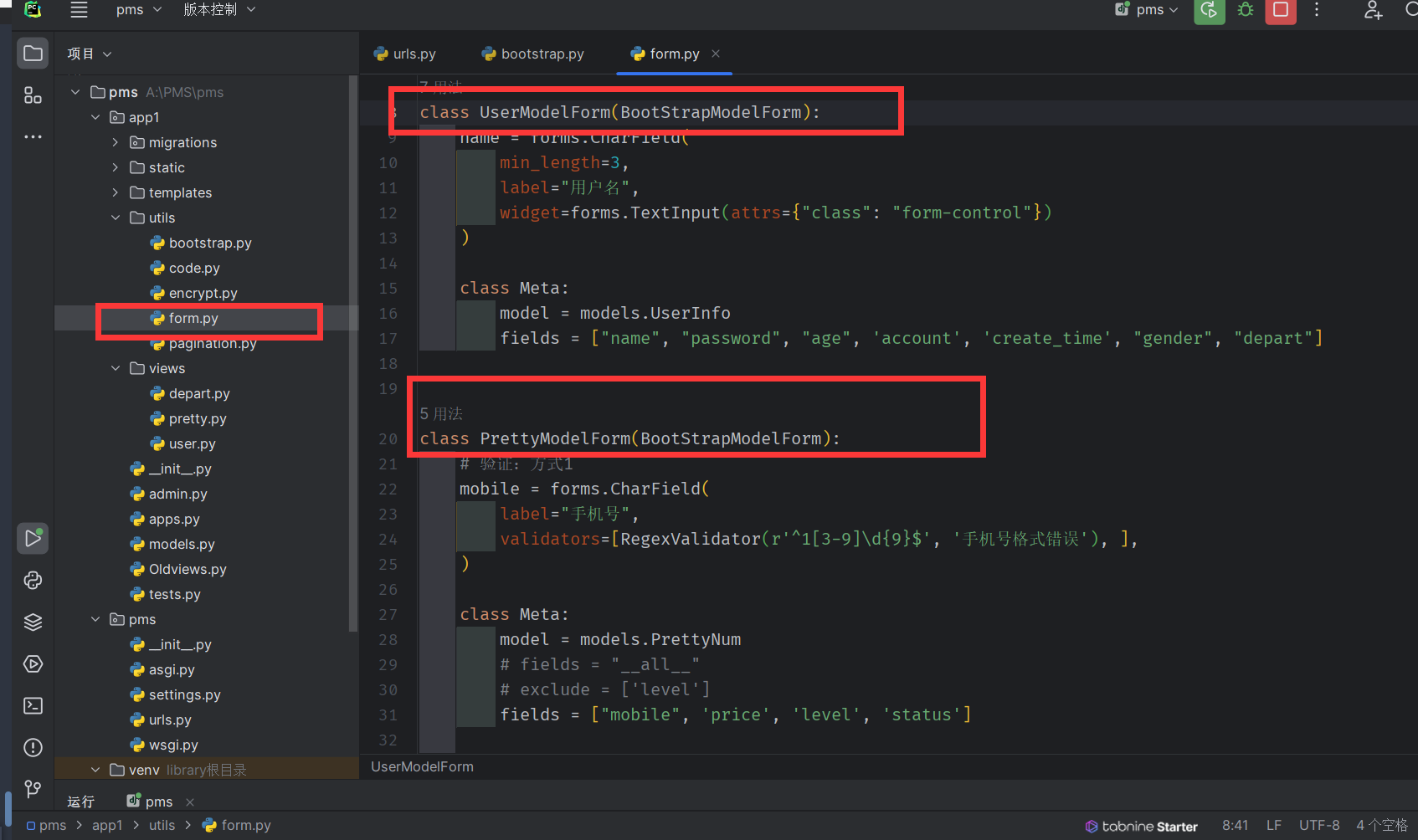
-
ModelForm拆分出来
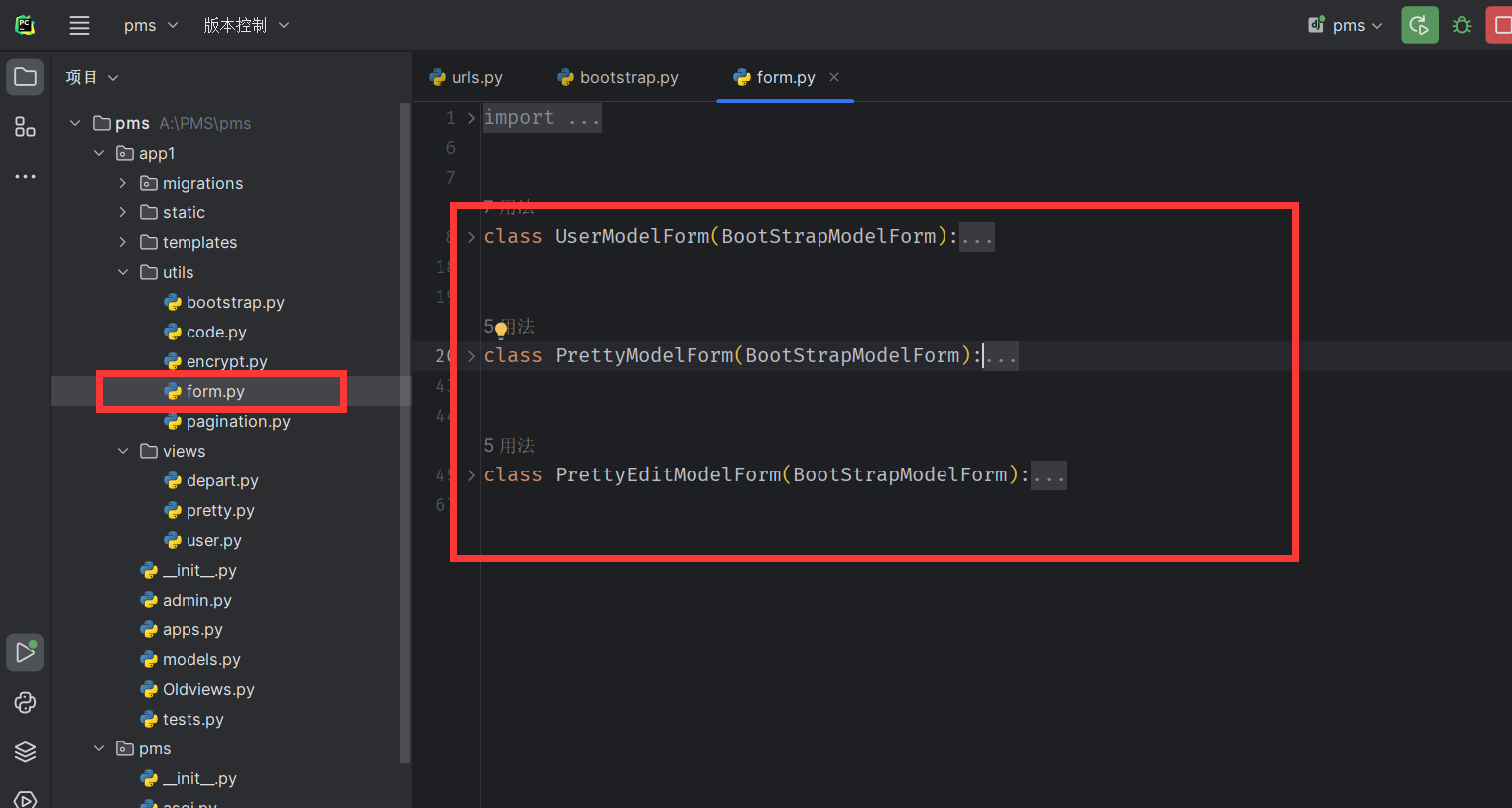
- 视图函数的归类 (将之前的view.py 删除或者重命名,防止冲突)
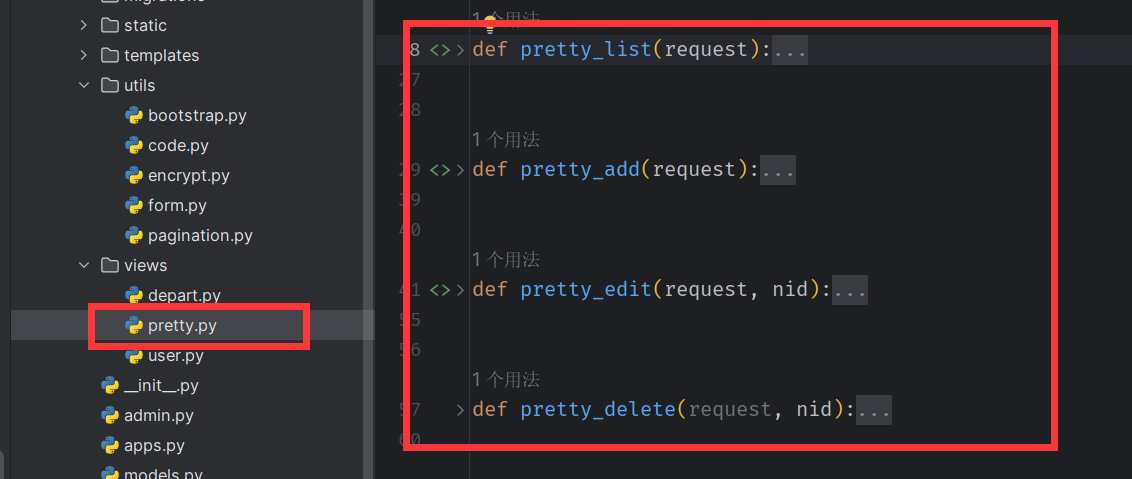
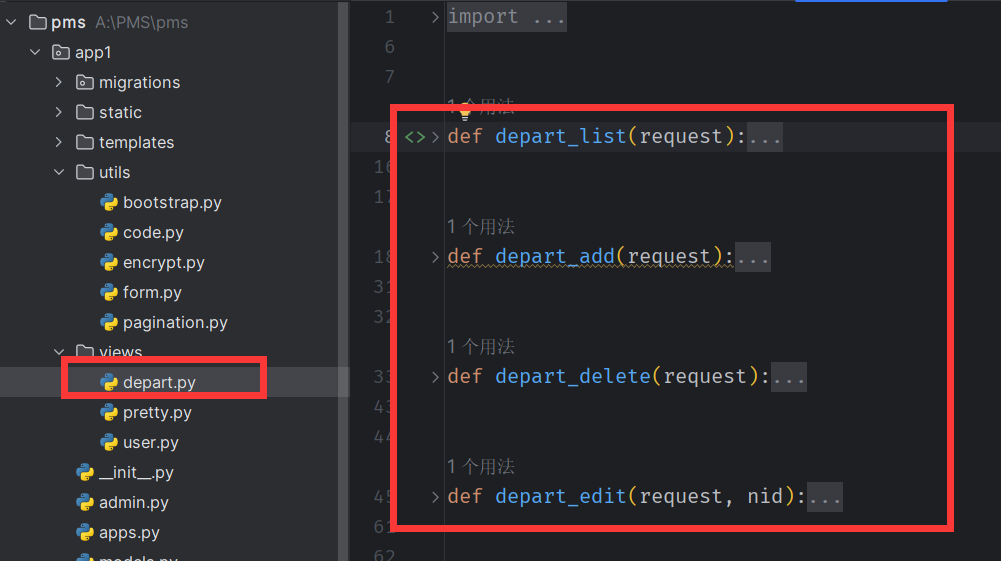

- 更改url 文件
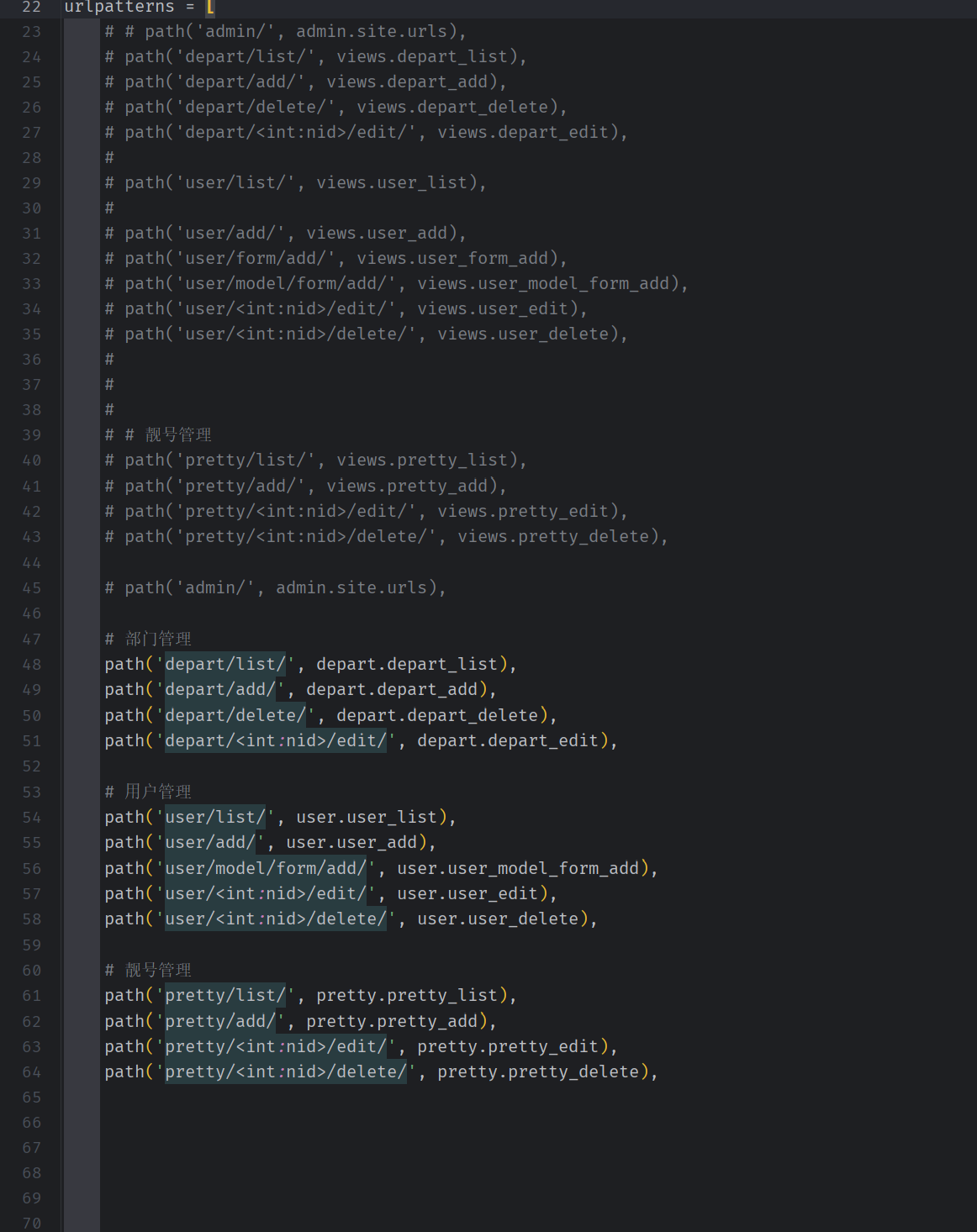
管理员管理
管理员列表
同 部门列表展示
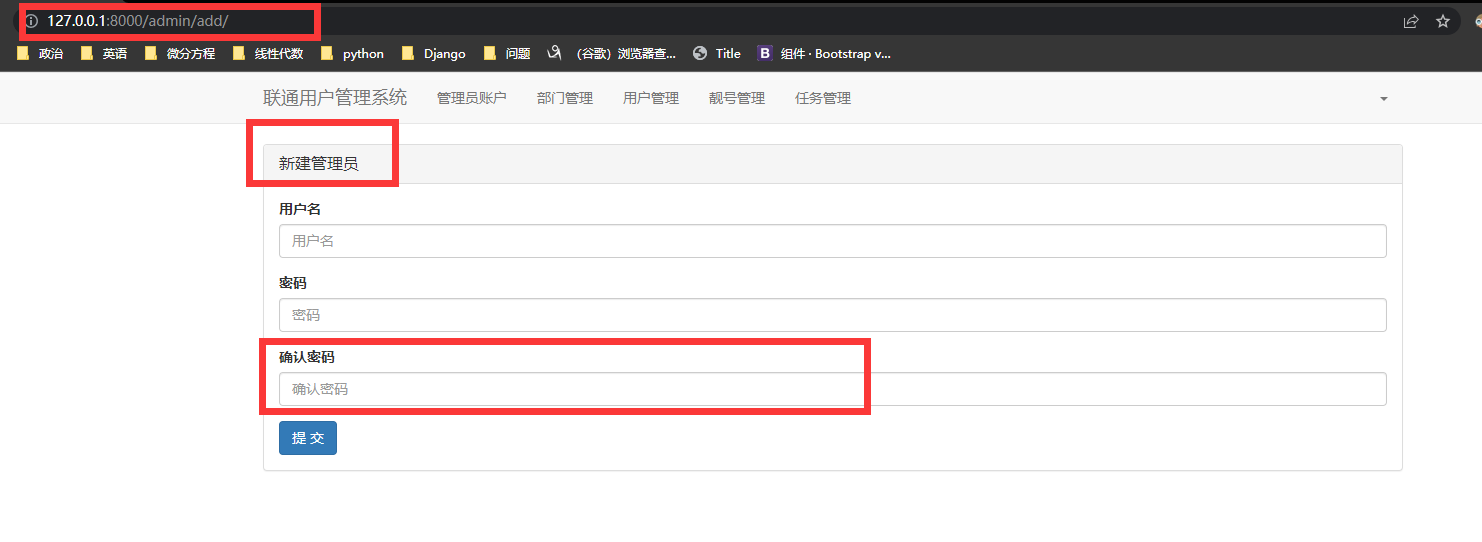
管理员添加
实际上和新增靓号的界面代码相同,只是在管理员编辑的页面也重用了这个。 因此 写成一个模板页, 只需要传入名字
{% extends 'layout.html' %}
{% block content %}
<div class="container">
<div class="panel panel-default">
<div class="panel-heading">
<h3 class="panel-title"> {{ title }} </h3> # 界面的名字由后端传入
</div>
<div class="panel-body">
<form method="post" novalidate>
{% csrf_token %}
{% for field in form %}
<div class="form-group">
<label>{{ field.label }}</label>
{{ field }}
<span style="color: red;">{{ field.errors.0 }}</span>
</div>
{% endfor %}
<button type="submit" class="btn btn-primary">提 交</button>
</form>
</div>
</div>
</div>
{% endblock %}
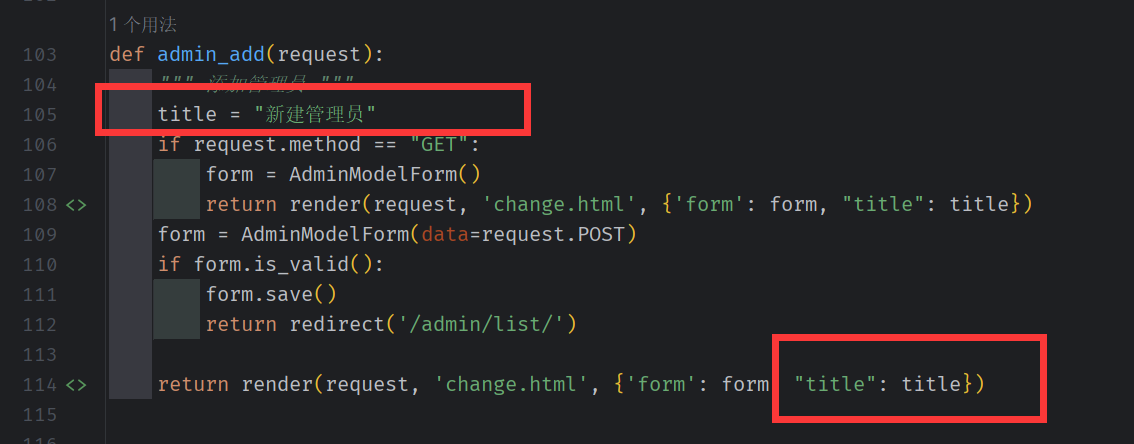
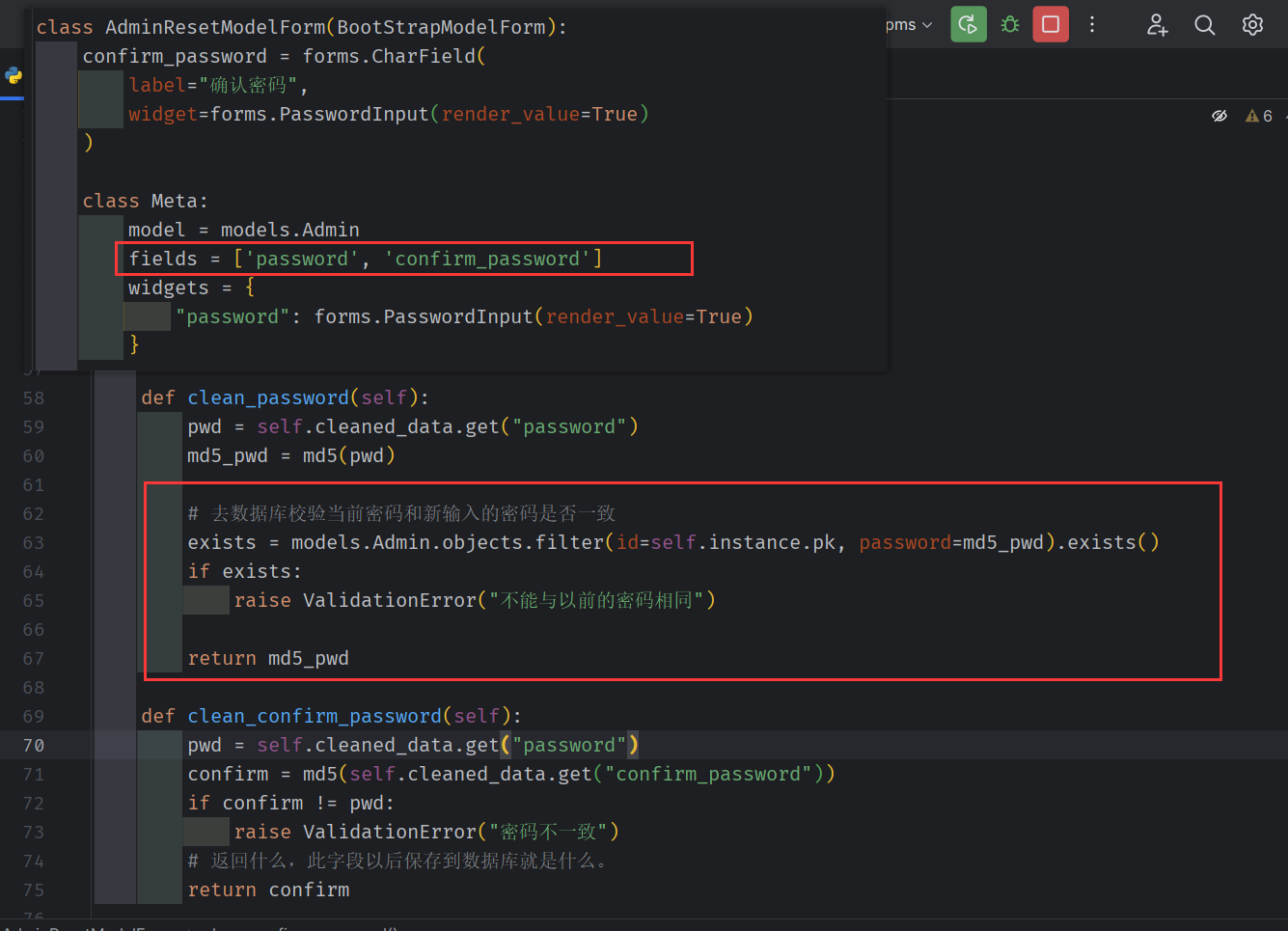
增加密码的重复校验
在 不添加重复校验和 密码加密的情况下, 如果数据 是有效的(form.is_valid==true), 则所有有效的数据将会存储到 clean_data中
进而存储到数据库中
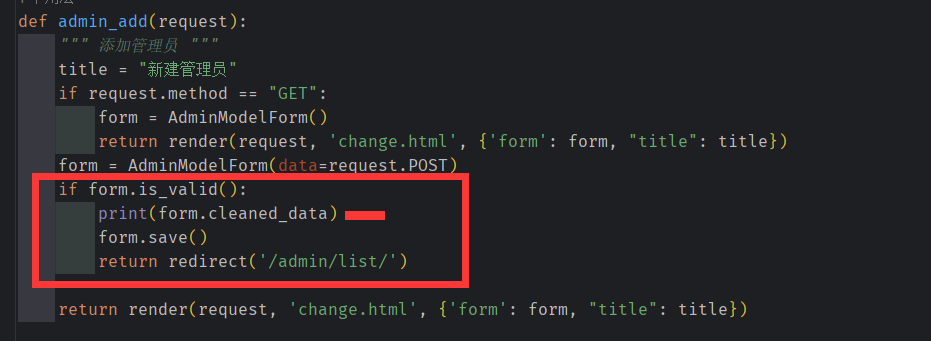

我们可以使用钩子函数, 比较 clean_data 中的 password 和 confirm_password 是否一致。
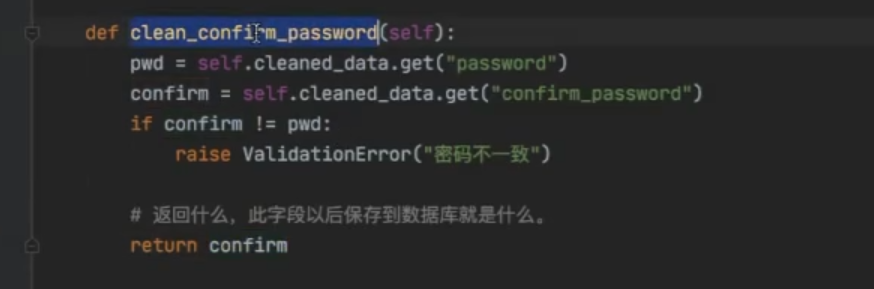
同时为了,在输入错误的情况下,不至于清空输入框。添加 render_value=True
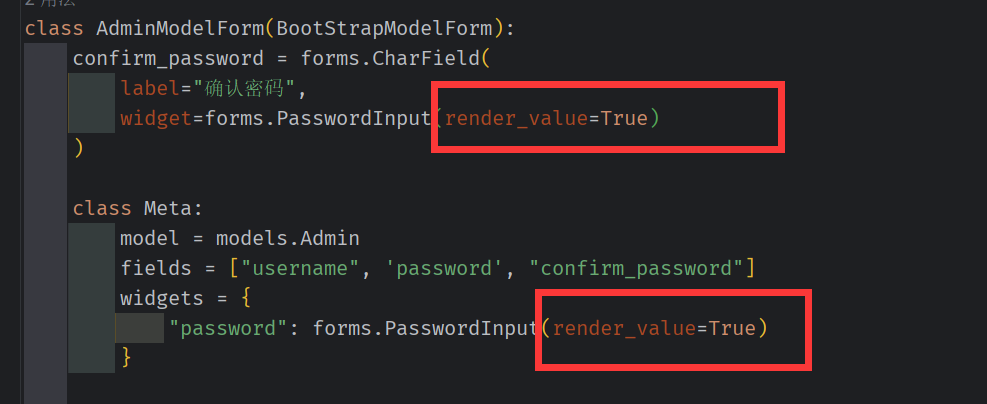
这里的 confirm_password 是不会存储到数据库中的(因为它不是数据库的字段), modelForm 允许 定义数据库中不存在的字段生成组件。
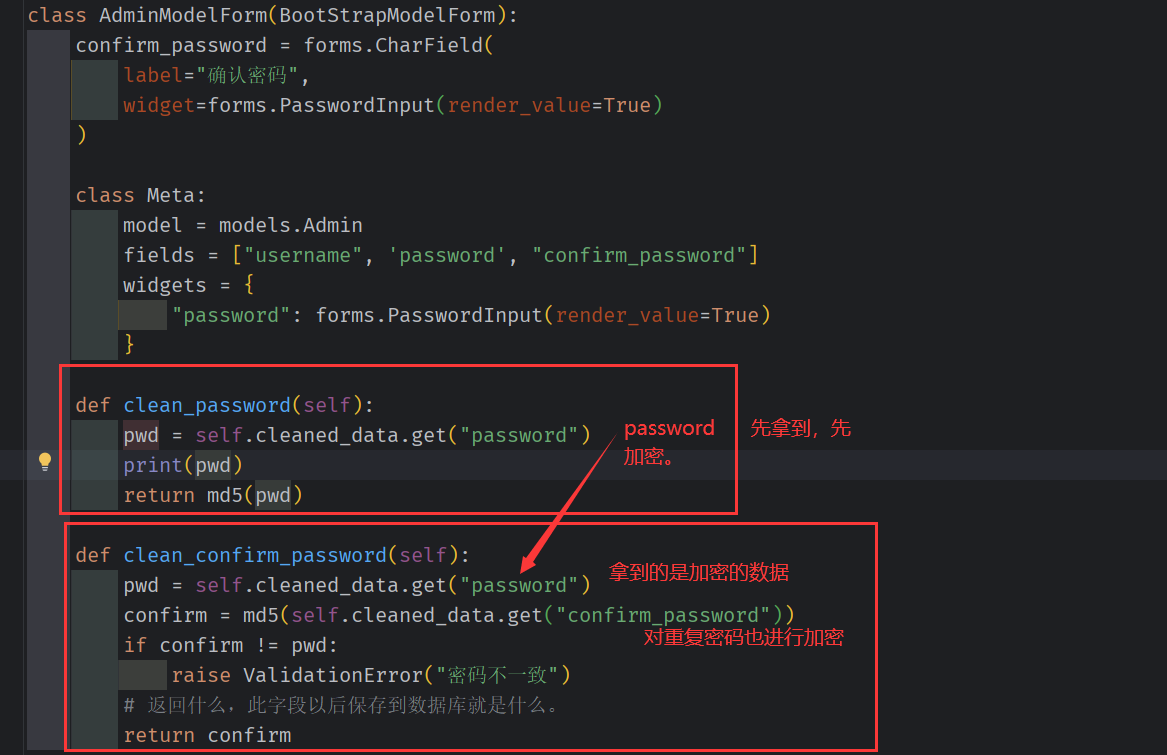
增加 md5 加盐算法,不存储明文数据
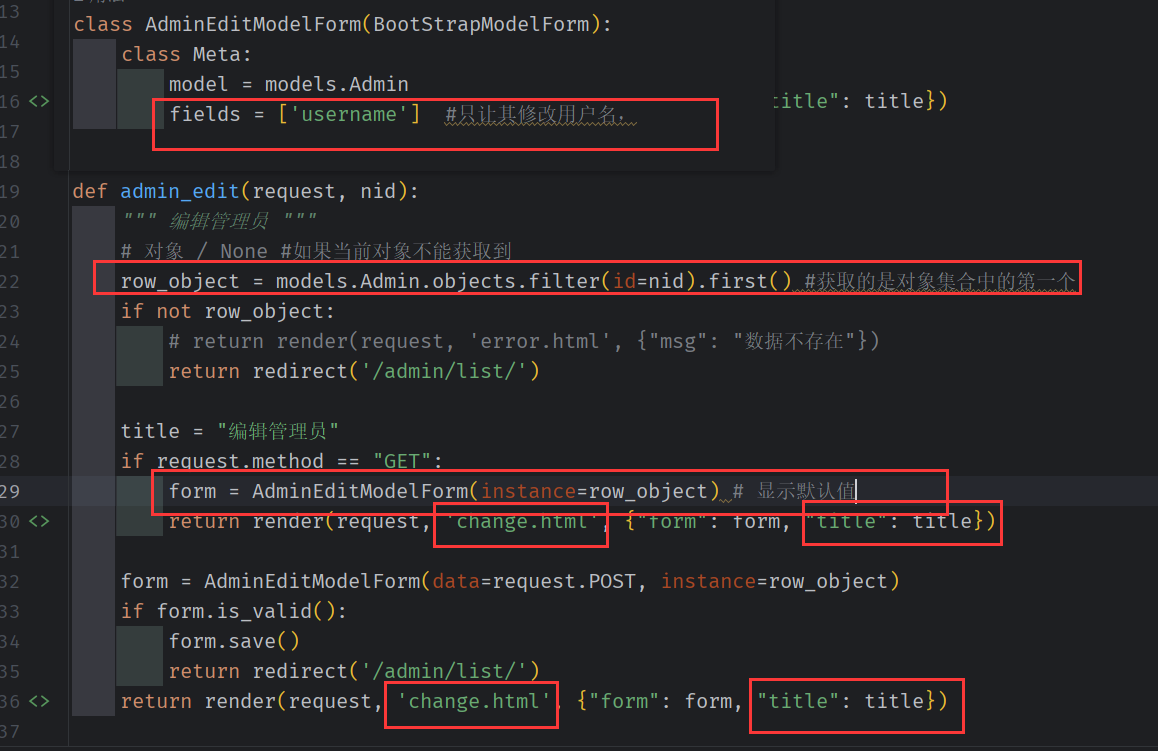
管理员编辑
和管理员添加共用一个页面模板(change.html),传入title(管理员编辑的页面名字) ,
只允许其修改用户名,一旦密码忘记,只能重置密码
.xxx.obhect.first()
永远取第一个值,是一个对象。 filter取到的是n个对象的合集
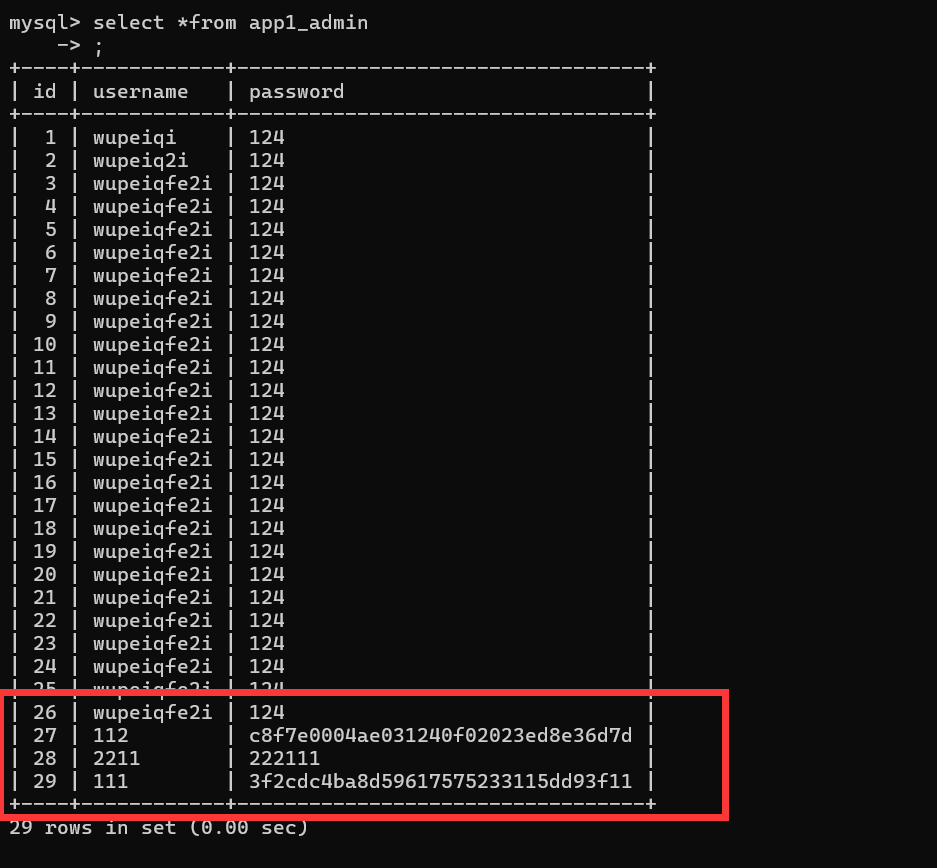
管理员密码重置
用户登录
account,py
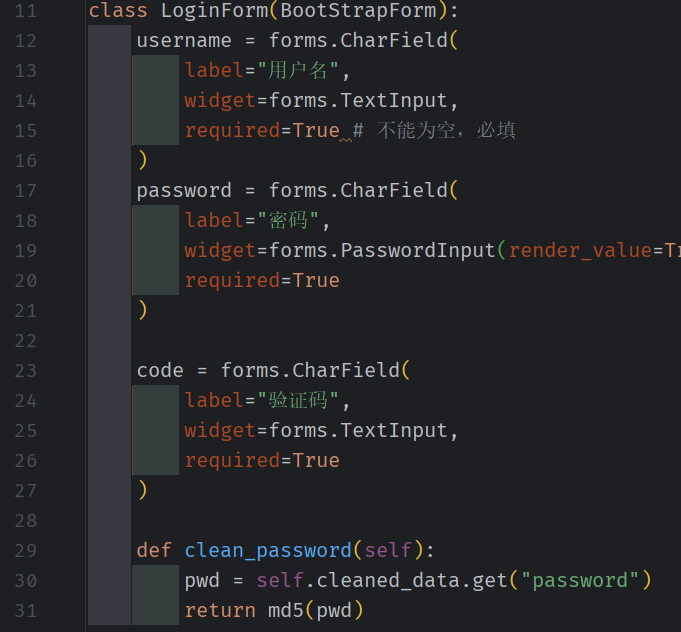
使用 Form 生成前台 输入框 。 同时使用 钩子函数 ,使得 前台输入 且经过检验有效的密码(clean_password) 进行加密,
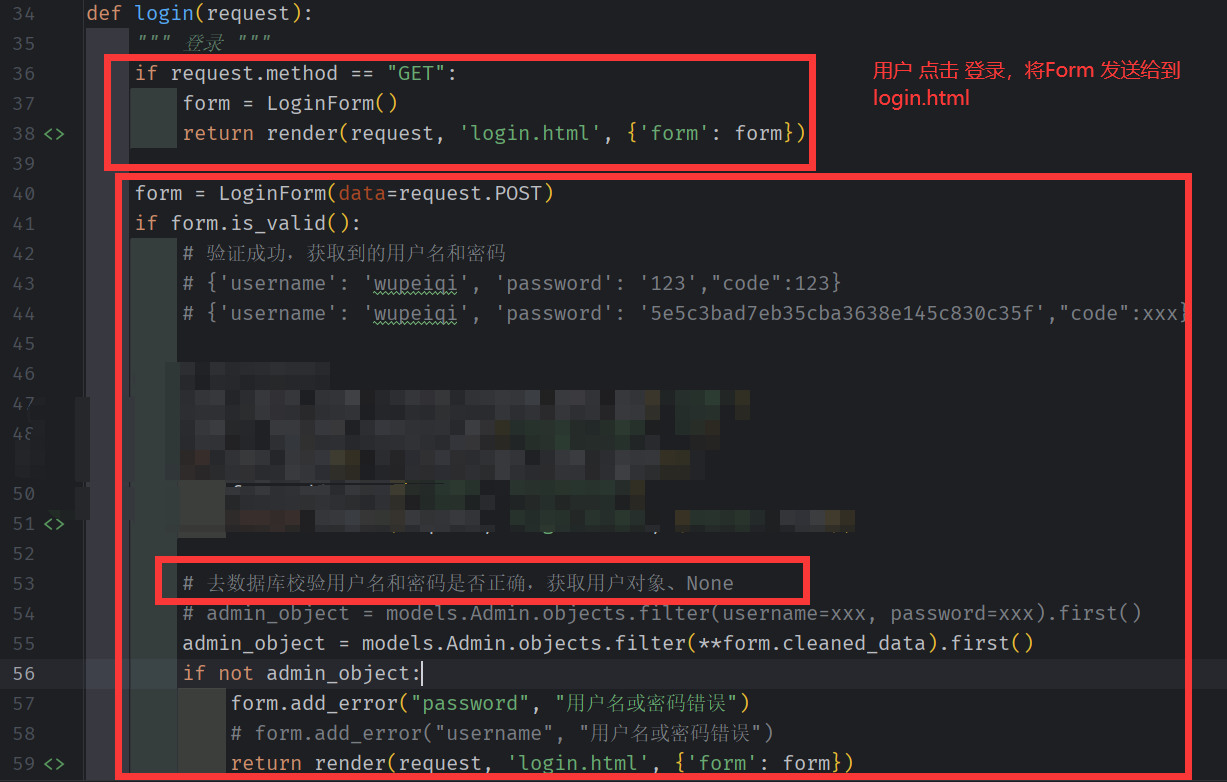
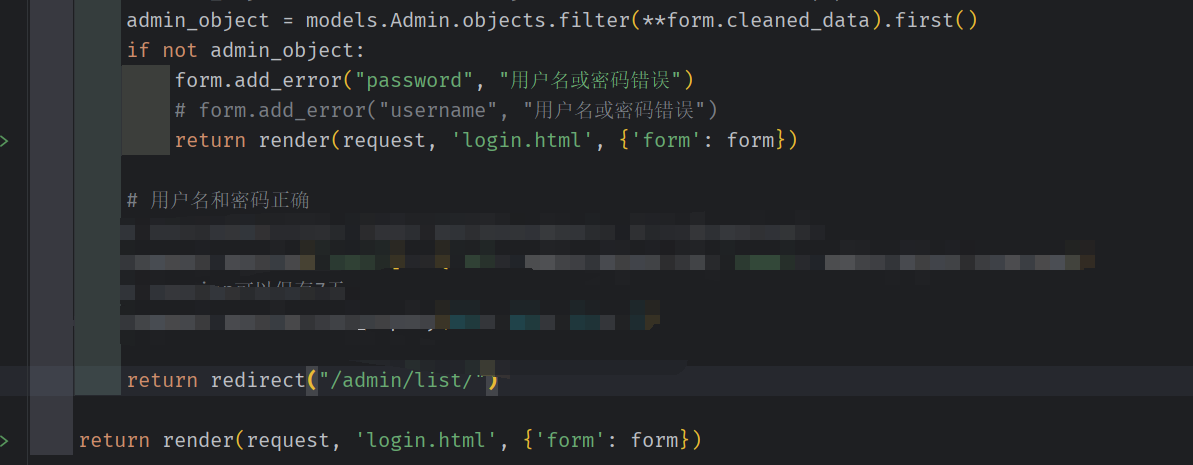
如果 输入无效数据 或者有效数据(但 数据库校验 失败) 则 重定向回登录页面
如果登录成功 ,则重定向为管理员列表
Login.html
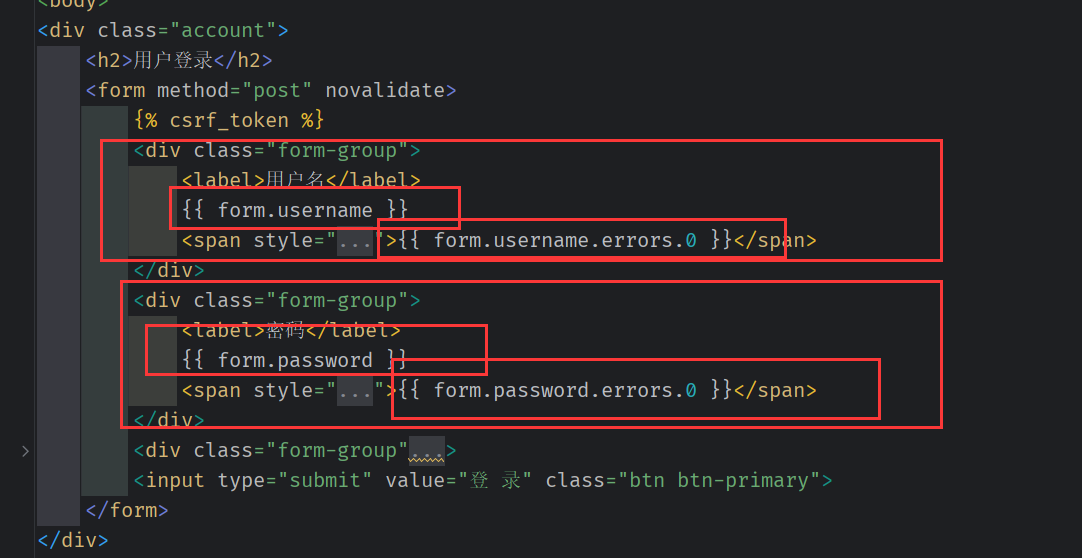
Form 或者 modelForm 可以直接添加 error 的信息,
实现登录的两种方式
方式一:存储在客户端
将用户数据加密,然后存储在cookie中。这种专业术语叫做client side session。flask采用的就是这种方式,但是也可以替换成其他形式。
优点:cookie 保存在客户端,不占用服务器资源
缺点:存在安全问题,如果你的加密方式泄露,别人就可以模拟用户登录
方式二:存储在服务端
通过 session 得到一个 session_id 存储在 cookie 中,然后具体的数据则是保存在服务器 session 中。如果用户登录完成,则服务器会在 cookie 中保存一个session_id,下次再次请求的时候,会把该session_id携带上来,服务器根据session_id在session库中获取用户的session数据。就能知道该用户到底是谁,以及之前保存的一些状态信息。这种专业术语叫做server side session。
优点:安全性高
缺点:session 是保存在服务端的,每个用户都会产生一个session,并发访问多的话,每个用户都会生成session,消耗内存
当用户数据库交互成功后(用户名和密码正确), 应该把用户信息保存。
第一次登录

第二次用户登录时

有了cookie为什么需要session?
-
用session只需要在客户端保存一个id,实际上大量数据都是保存在服务端。如果全部用cookie,数据量大的时候客户端是没有那么多空间的。
cookie只是实现session的其中一种方案。虽然是最常用的,但并不是唯一的方法。
全部在客户端保存,服务端无法验证,这样伪造和仿冒会更加容易。(伪造一个随机的id很难,但伪造另一个用户名是很容易的)
全部保存在客户端,那么一旦被劫持,全部信息都会泄露
客户端数据量变大,网络传输的数据量也会变大
通过Cookie来管理Session


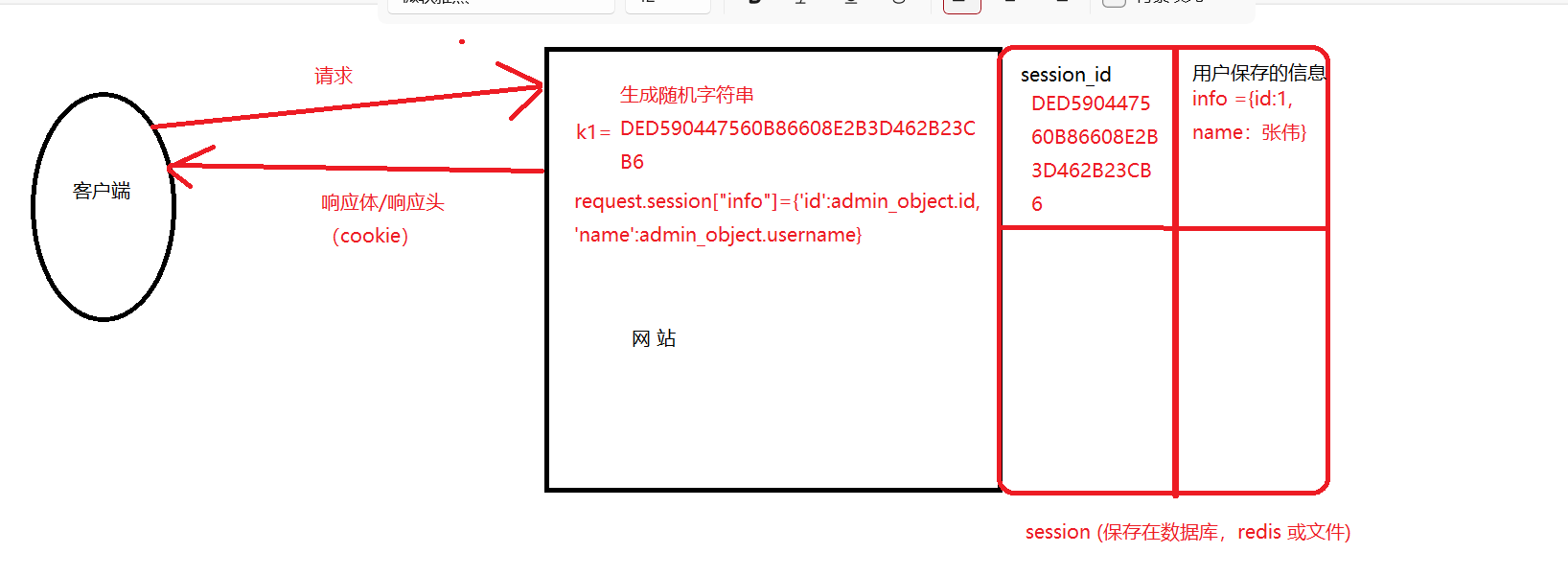
代码实现
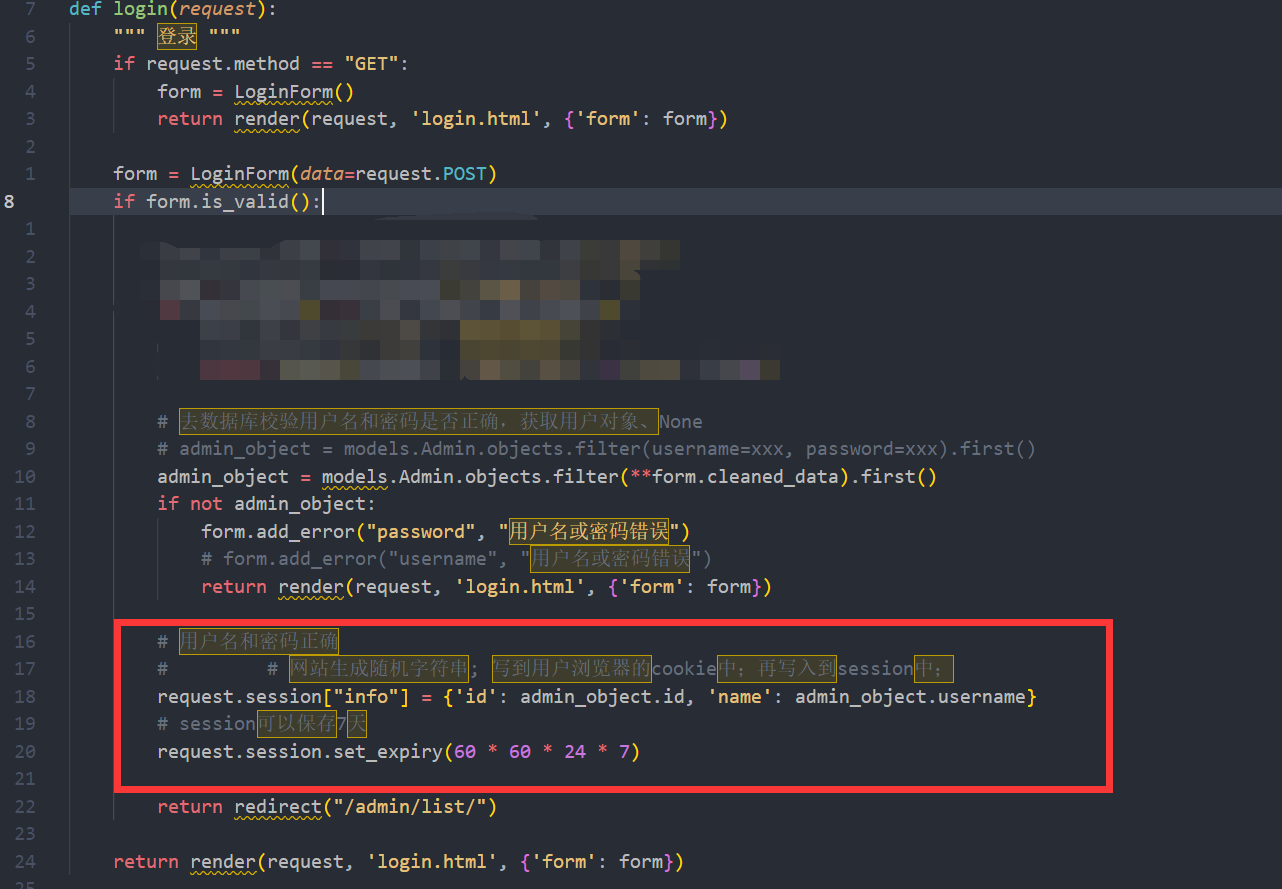
request.session[“iffo”]={‘id’:admin_object.id,‘name’:admin_object.username}
这行代码实现了三个功能
# 网站生成随机字符串; 写到用户浏览器的cookie中;再写入到session中;
查看保存的信息
获取用户登录时保存的 信息
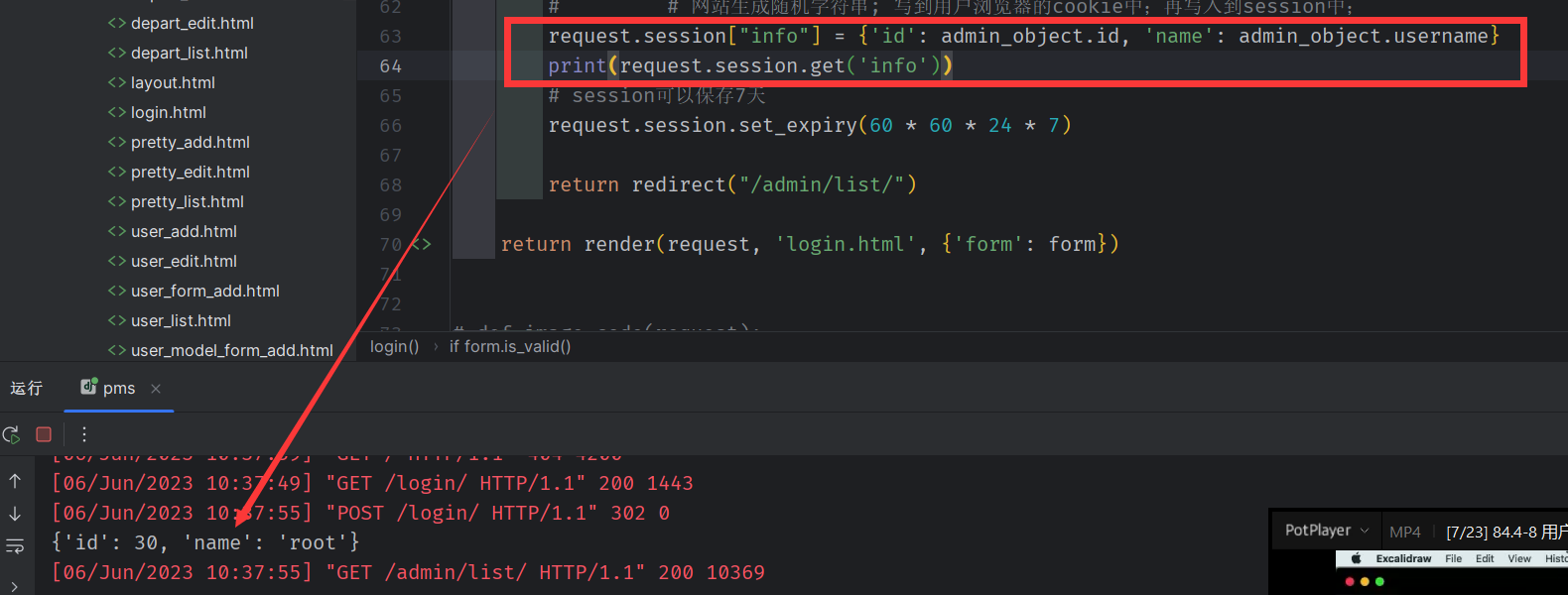
如果用户未登录,则该值为 none
因此就可以在每个 需要用户登录才能访问的页面上加上以下代码
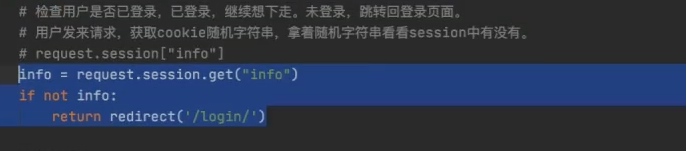
在其他需要登录才能访问的页面中,都需要加入:
def index(request):
info = request.session.get("info")
if not info:
return redirect('/login/')
...
目标:在18个视图函数前面统一加入判断。
info = request.session.get("info")
if not info:
return redirect('/login/')
但 页面总数过多,不可能一个一个加。因此可以使用中间件
补充:实际上session id 也会存储在数据库中,Django 默认生成的表 django_session
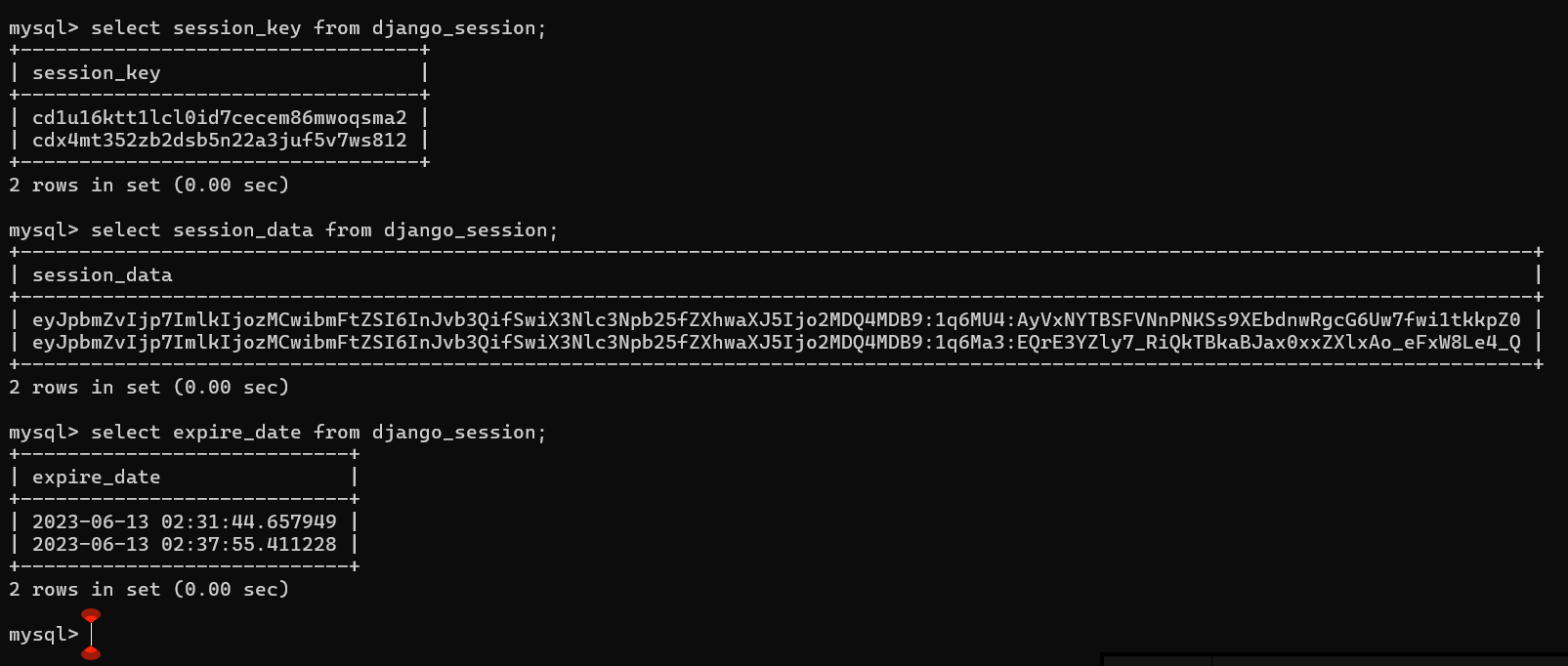
中间件
Django 中间件详解
无论访问哪个页面都必须经过中间件,都会执行中间件(类)的方法
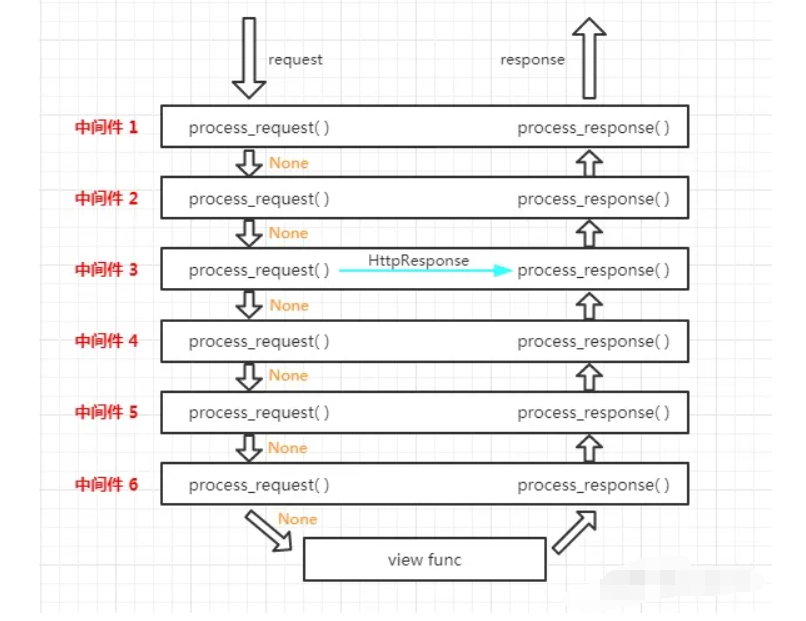
一旦任何一个中间件返回了一个HttpResponse对象,立刻进入响应流程!要注意,未被执行的中间件,其响应钩子方法也不会被执行,这是一个短路,或者说剥洋葱的过程。
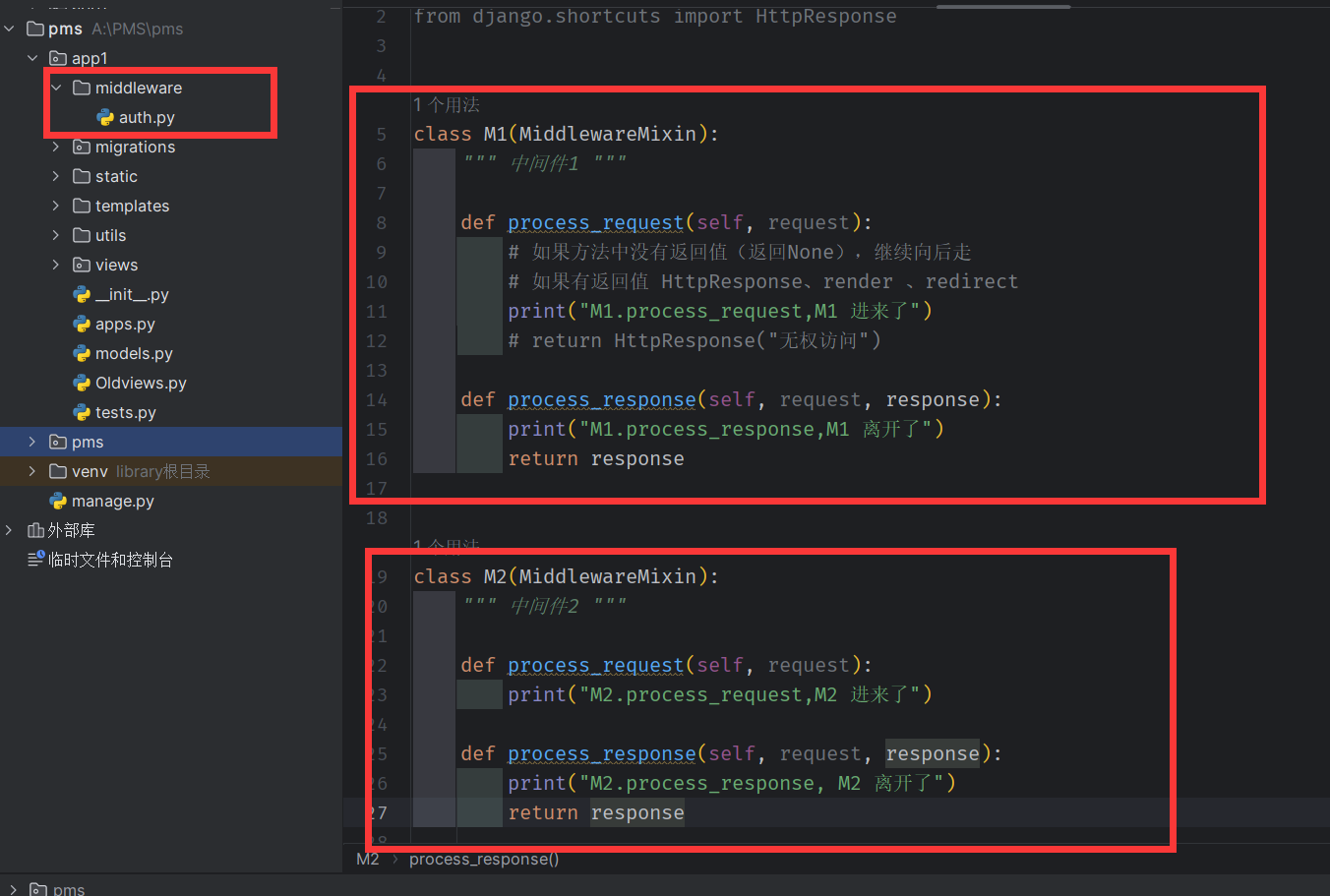
演示中间件
定义中间件
from django.utils.deprecation import MiddlewareMixin
from django.shortcuts import HttpResponse
应用中间件 setings.py
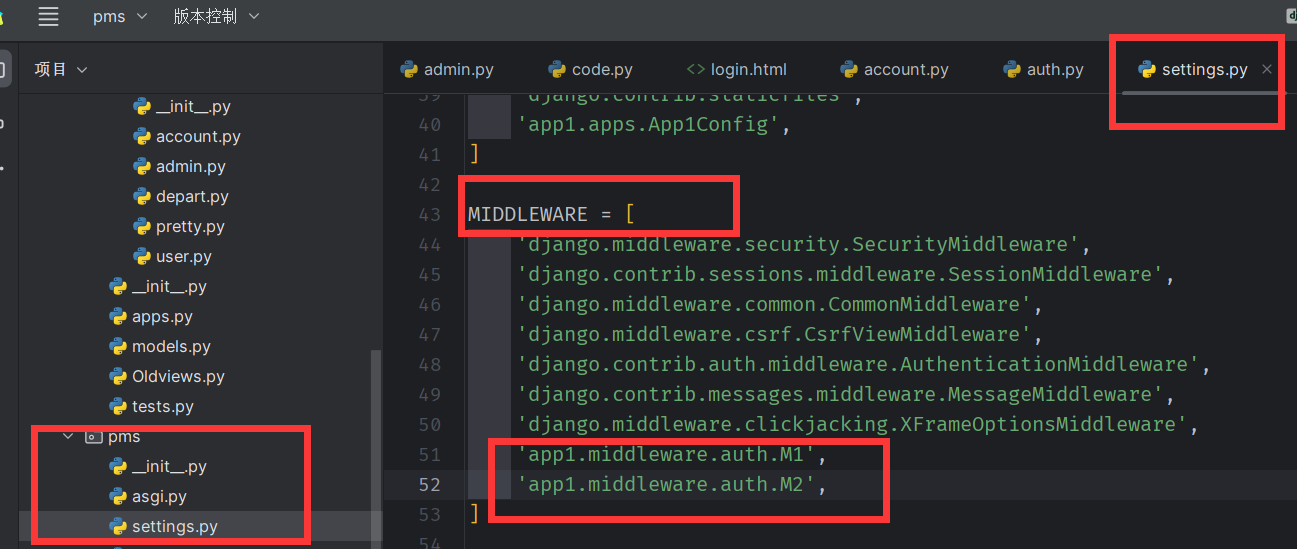
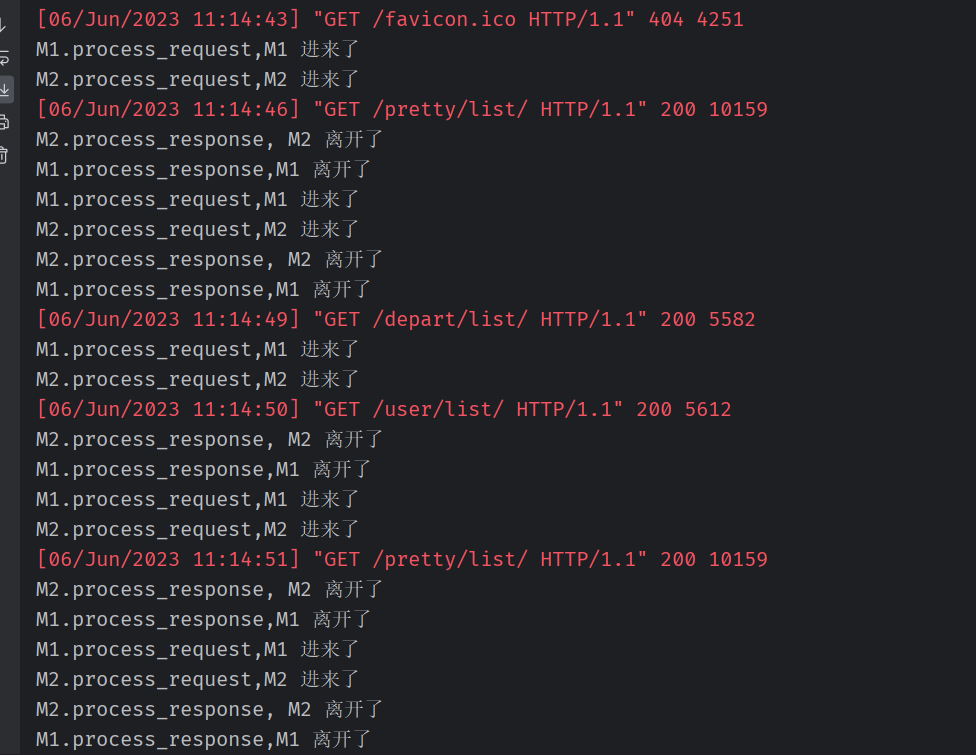
无论访问哪个页面都必须经过中间件,都会执行中间件(类)的方法
一旦任何一个中间件返回了一个HttpResponse对象,立刻进入响应流程!要注意,未被执行的中间件,其响应钩子方法也不会被执行.
修改 中间件的代码,让其返回 HttpResponse
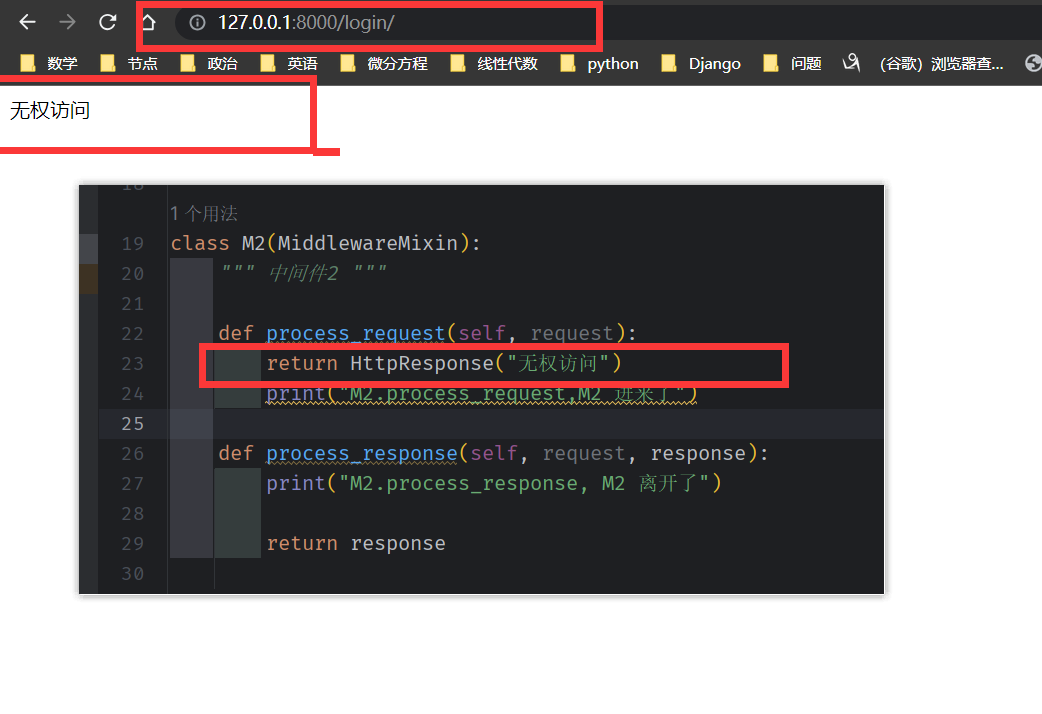
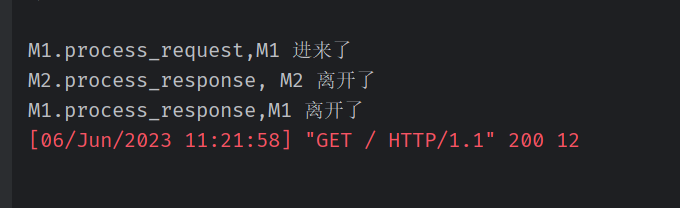
M2 没有进来
应用中间件用于登录校验
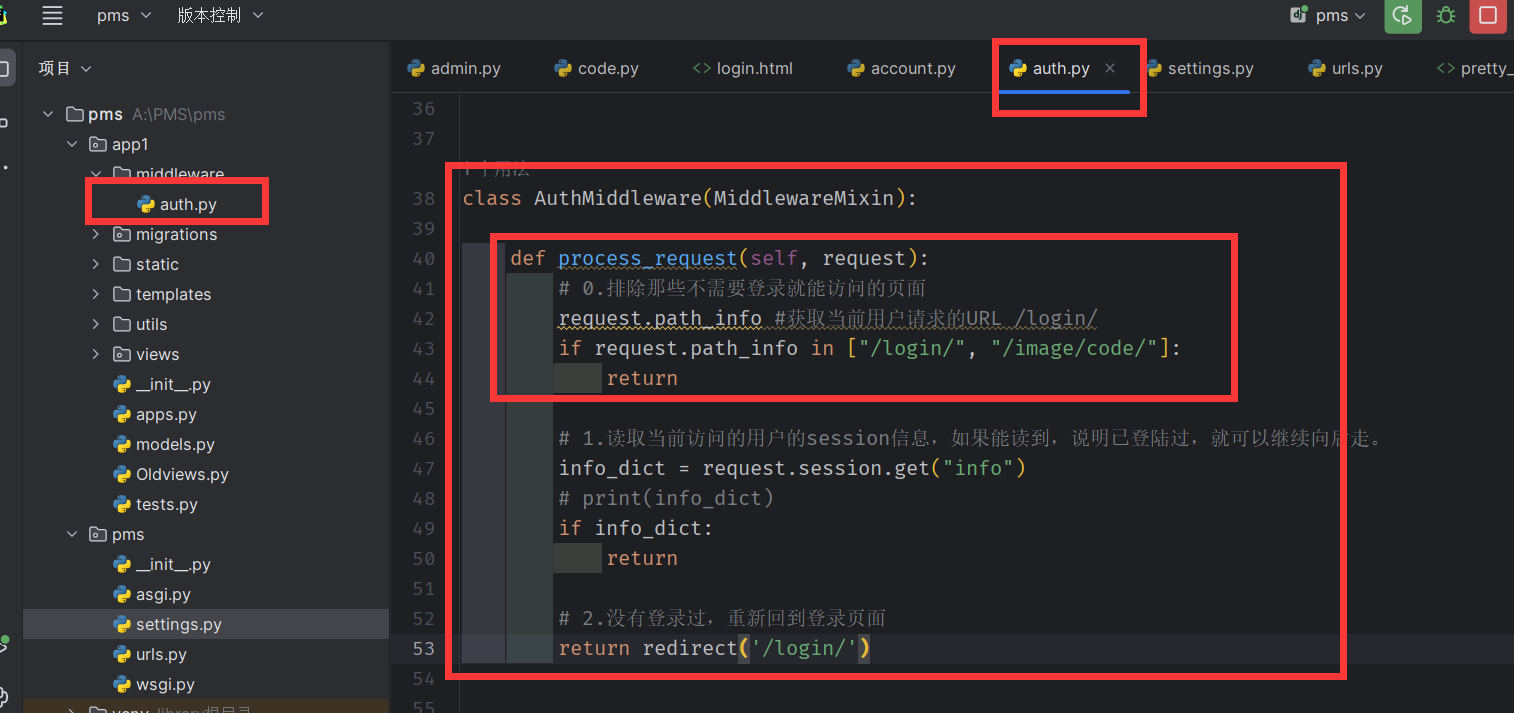
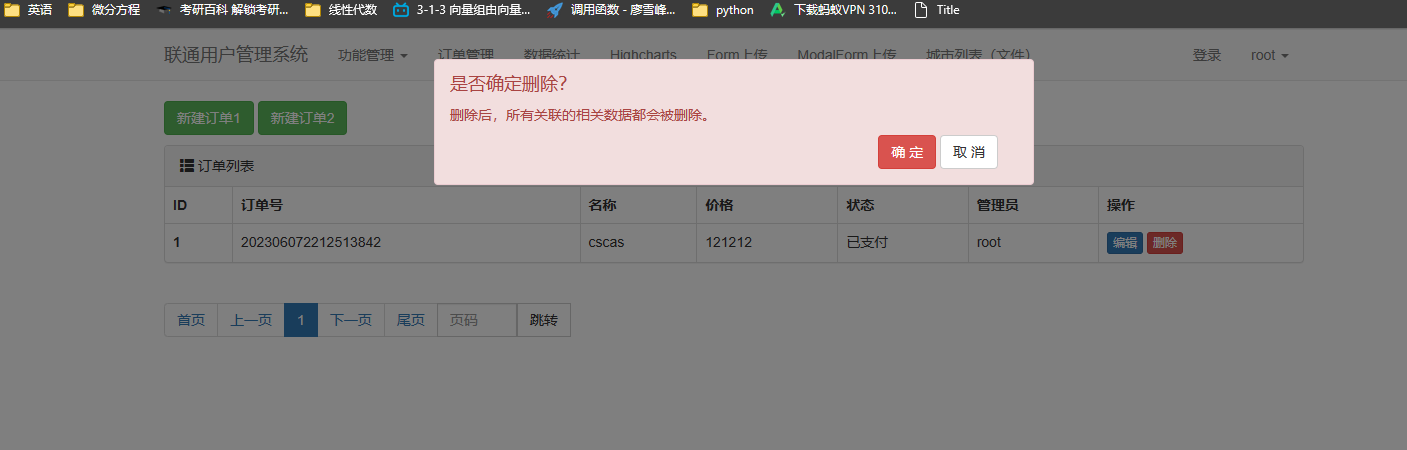
必须排除掉在登录页面的 登录校验 ,否则,将不断重定向到登录页面,如下图
用户注销
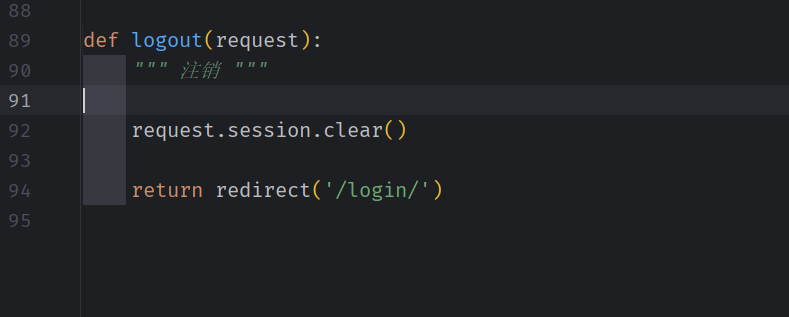
清除 session ,重定向到登录页面
显示登录用户

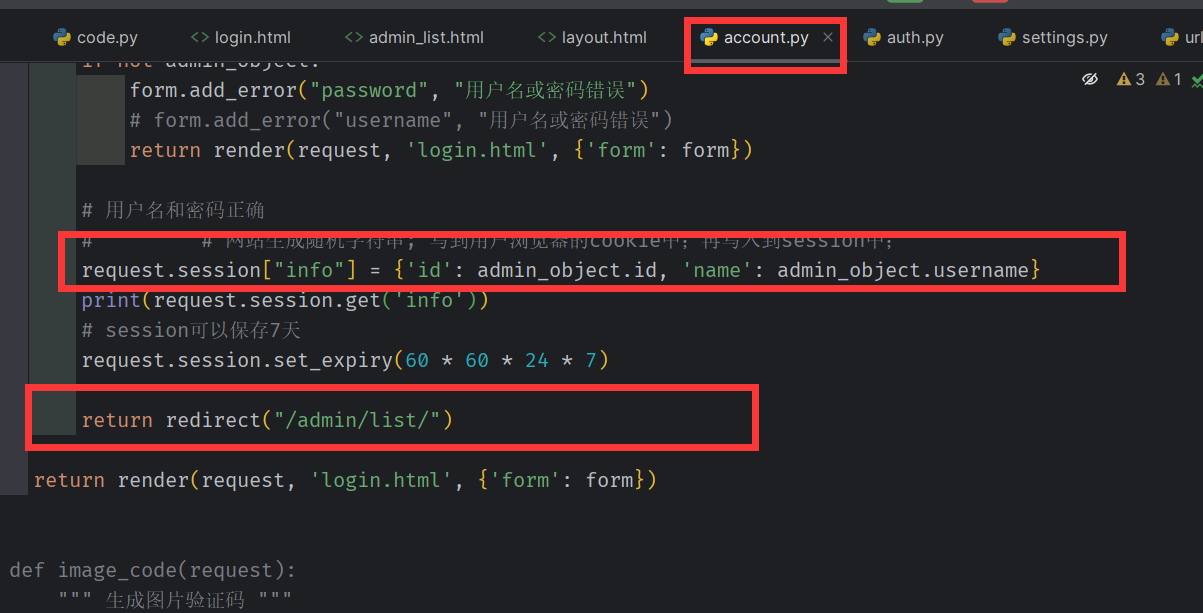
将 登录成功后的 保存在session 中的 id 和name 取出 即可
生成随机验证码
Python生成随机验证码参考链接
显示
login.html


让图片去访问一个链接,(以便于每次刷新页面验证码会刷新)
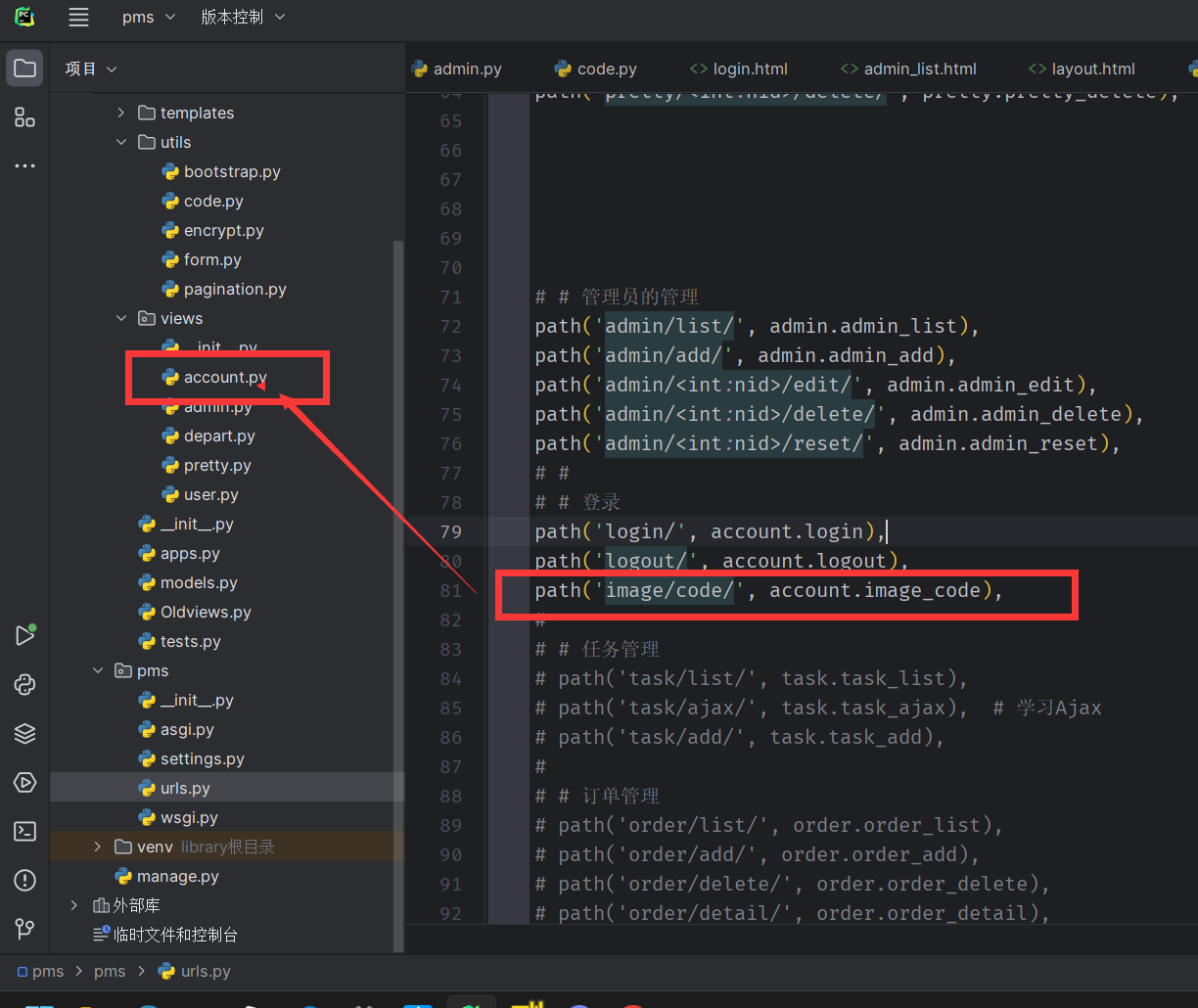
执行对应的函数
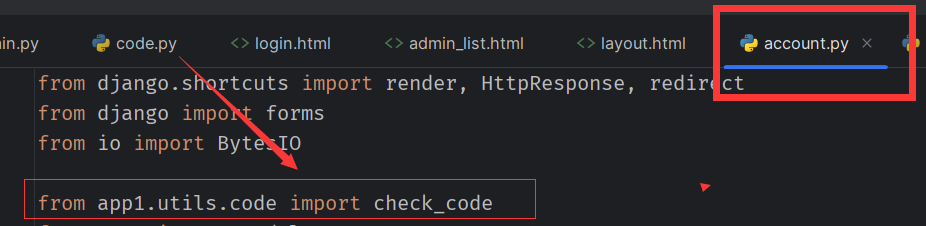
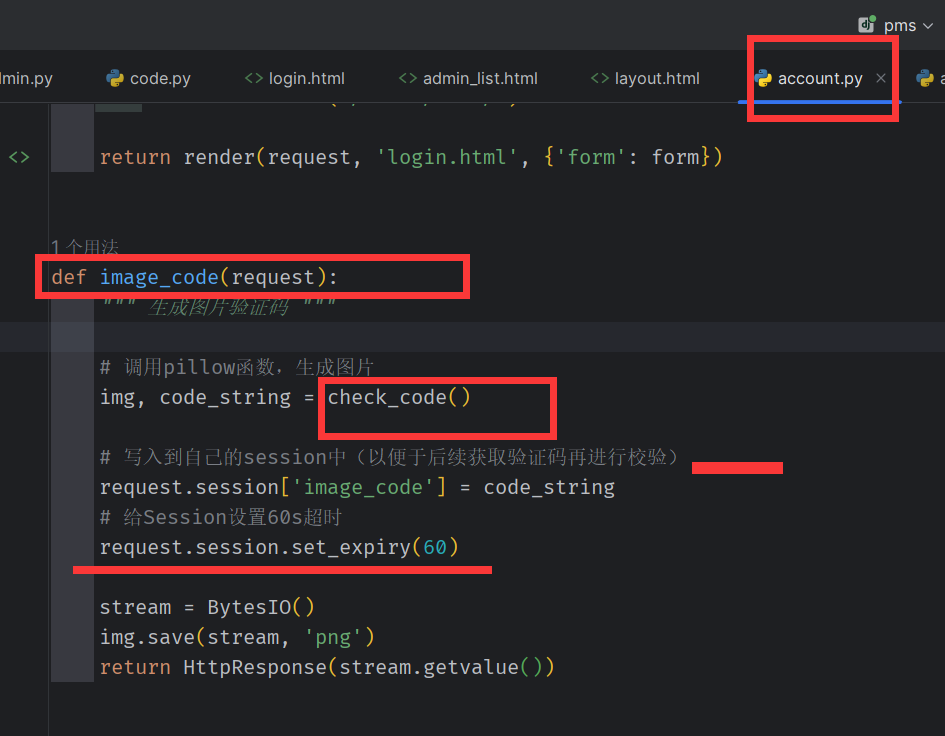
check_code 返回 生成的验证码图片,和图片上的文字
stream= ByteIO 相当于创建文件,这个文件是存在内存中的
img.save(stream,png) 将此图像以指定的格式保存到指定的流中。
url = stream , 即能显示验证码图片
code.py
生成随机验证码
pip install pillow
import random
from PIL import Image, ImageDraw, ImageFont, ImageFilter
def check_code(width=120, height=30, char_length=5, font_file='Monaco.ttf', font_size=28):
code = []
img = Image.new(mode='RGB', size=(width, height), color=(255, 255, 255))
draw = ImageDraw.Draw(img, mode='RGB')
def rndChar():
"""
生成随机字母
:return:
"""
return chr(random.randint(65, 90))
def rndColor():
"""
生成随机颜色
:return:
"""
return (random.randint(0, 255), random.randint(10, 255), random.randint(64, 255))
# 写文字
font = ImageFont.truetype(font_file, font_size)
for i in range(char_length):
char = rndChar()
code.append(char)
h = random.randint(0, 4)
draw.text([i * width / char_length, h], char, font=font, fill=rndColor())
# 写干扰点
for i in range(40):
draw.point([random.randint(0, width), random.randint(0, height)], fill=rndColor())
# 写干扰圆圈
for i in range(40):
draw.point([random.randint(0, width), random.randint(0, height)], fill=rndColor())
x = random.randint(0, width)
y = random.randint(0, height)
draw.arc((x, y, x + 4, y + 4), 0, 90, fill=rndColor())
# 画干扰线
for i in range(5):
x1 = random.randint(0, width)
y1 = random.randint(0, height)
x2 = random.randint(0, width)
y2 = random.randint(0, height)
draw.line((x1, y1, x2, y2), fill=rndColor())
img = img.filter(ImageFilter.EDGE_ENHANCE_MORE)
return img, ''.join(code)
if __name__ == '__main__':
img, code_str = check_code()
print(code_str)
with open('code.png', 'wb') as f:
img.save(f, format='png')
校验
account.py
生成 验证码的输入框
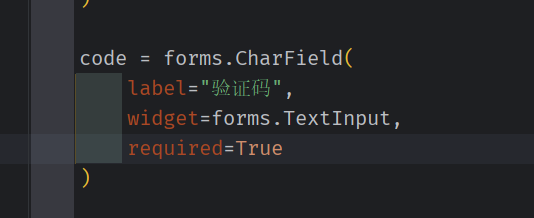
account.py
之前 生成并 保留在session 中的验证码
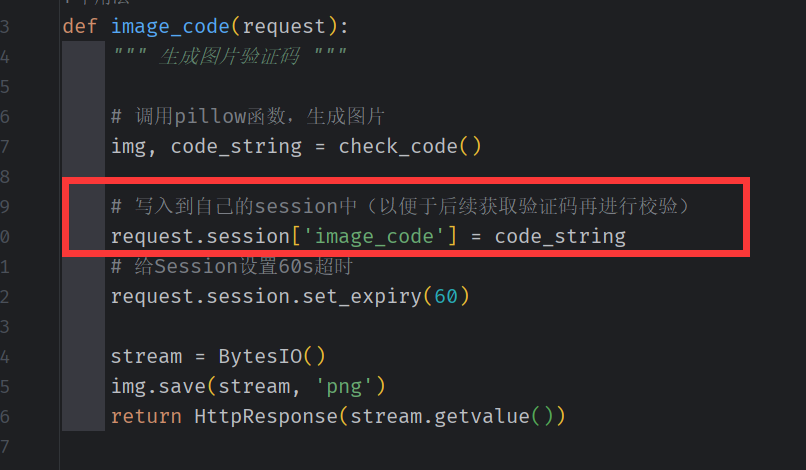
将用户输入的验证码和 session中的验证码进行比较
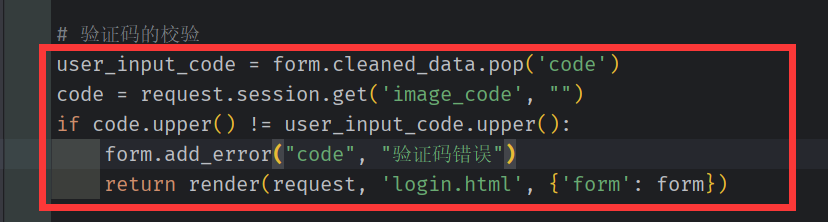
cleaned_data 是经过modelForm (正则或输入) 校验 但未经过数据库校验的数据。
pop 既可以返回 code ,又能避免将 code 交付数据库进行校验(因为数据库没有此字段)
Ajax介绍
内容参见
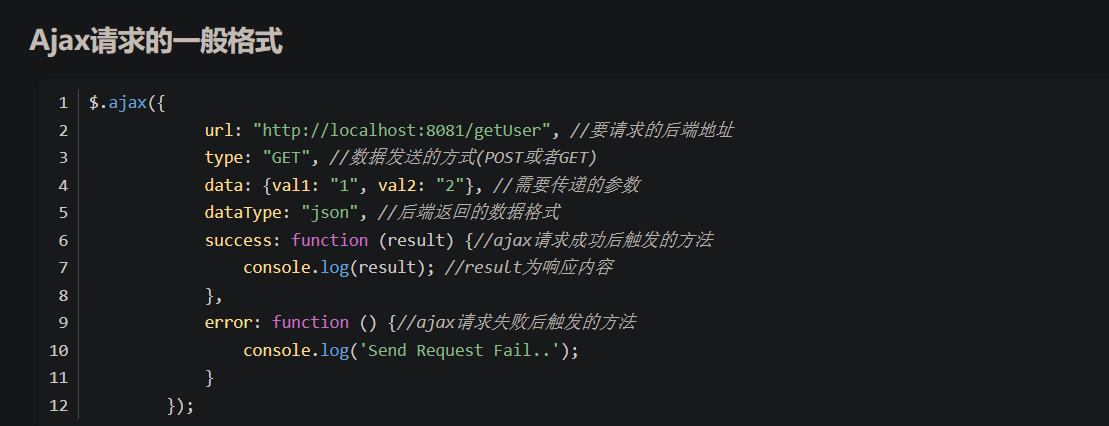
ajax 流程介绍
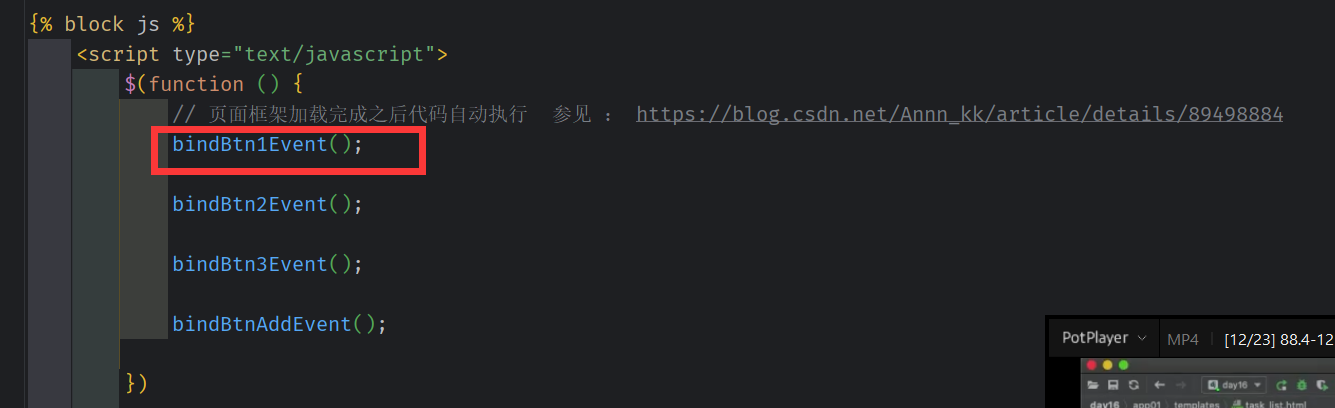
以bindBtn1Event();为例
task_list.html
绑定事件,JS,两种在页面加载完成后自动执行的方法

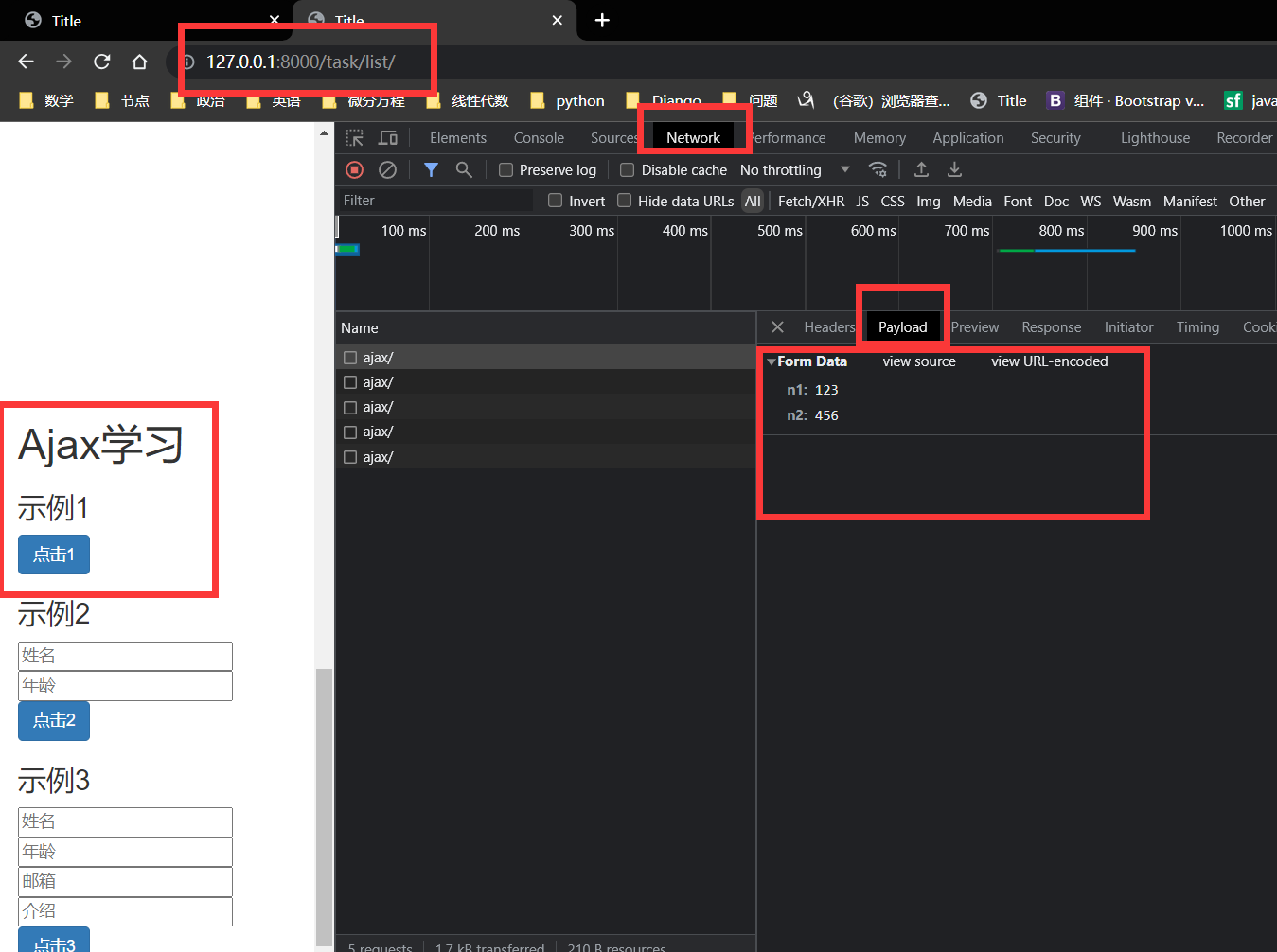
注册点击事件 , data 是传给 task/ajax 的数据 , res 成功访问后url 后 接受 task/ajax 网址返回的数据,。
task_list.html
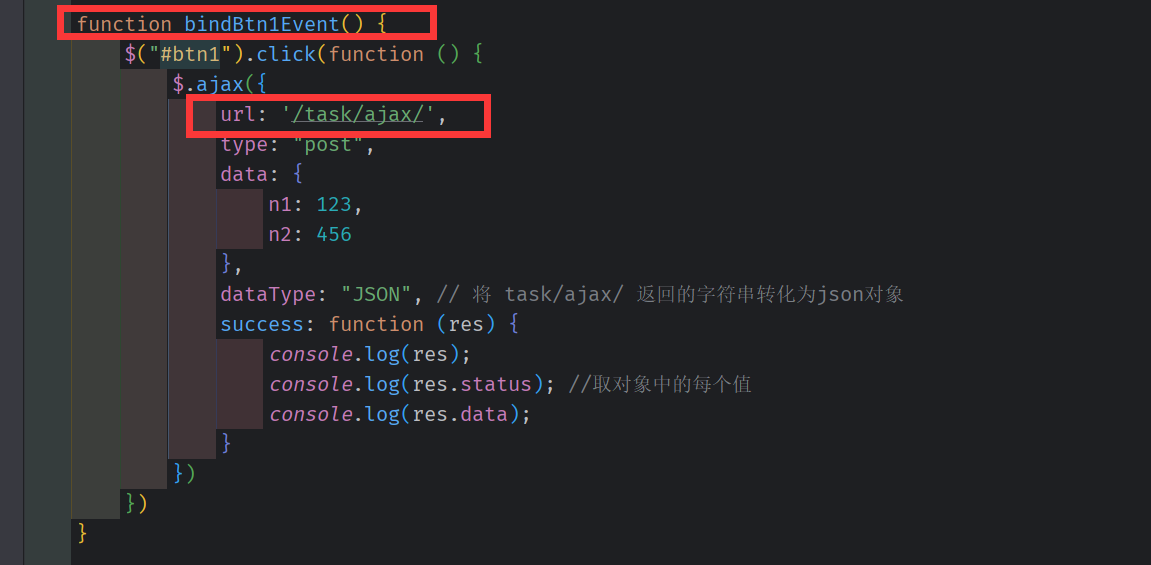
前端请求的网址
url.py

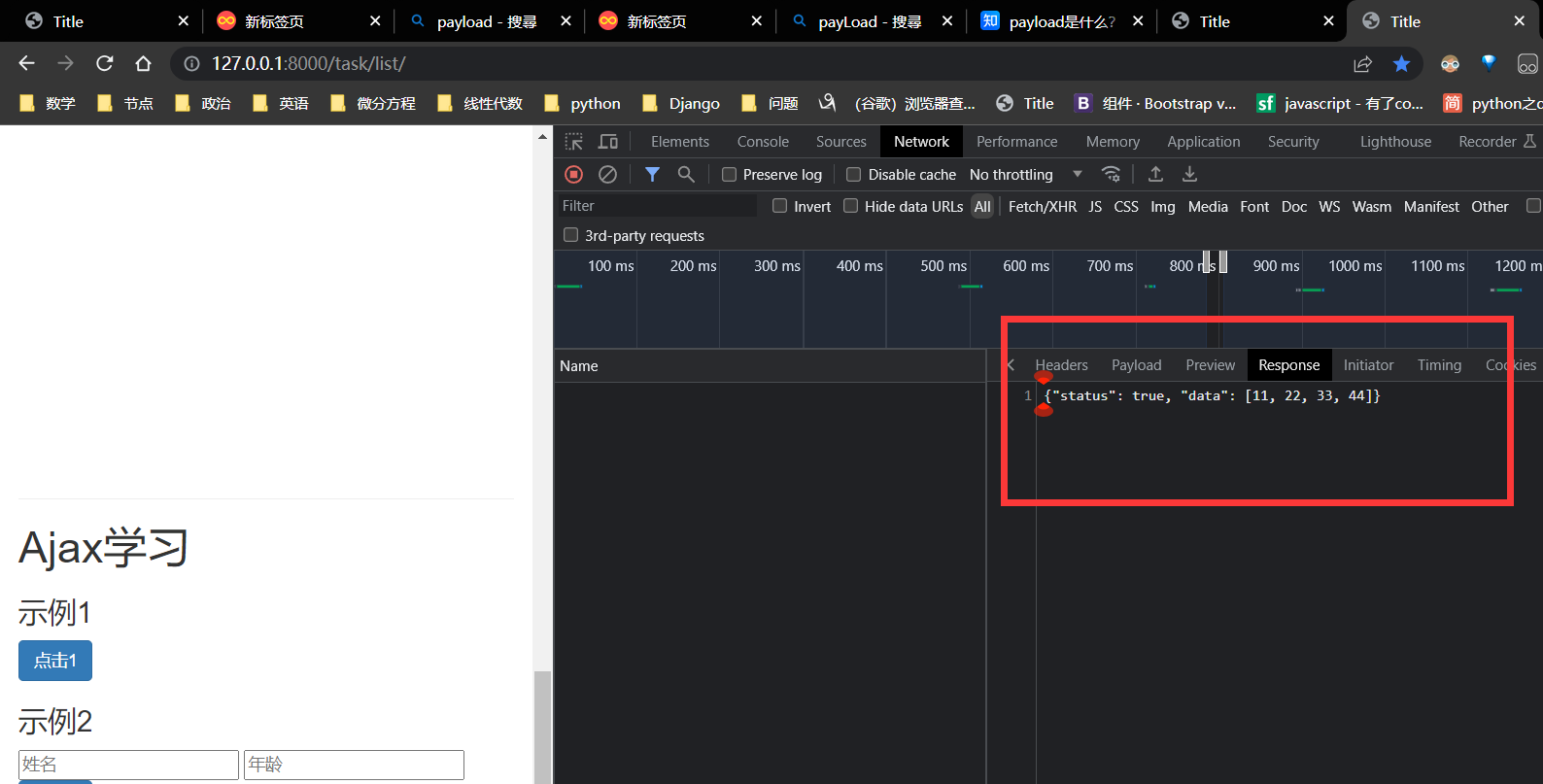
请求后执行的函数, 该函数返回的数据为 json 对象 被 task_list.html 的bindBtn1Event(); 的res 捕获。
同时 task_list.html 的bindBtn1Event(); 传递过来的值被 request 的 get (或者 post 捕获)
task.py

注意 当task_list 对 网址 task_ajax 请求方式为 POST 时, 被请求 网址 task_ajax 应当啊 加上 @csrf_exempt 在post请求时,免除csrf认证. 或者其他方法也可。
Post 请求时
task_ajax 返回 的 HttpResponse 被task_list 的 bindBtn1Event 的 Function接收
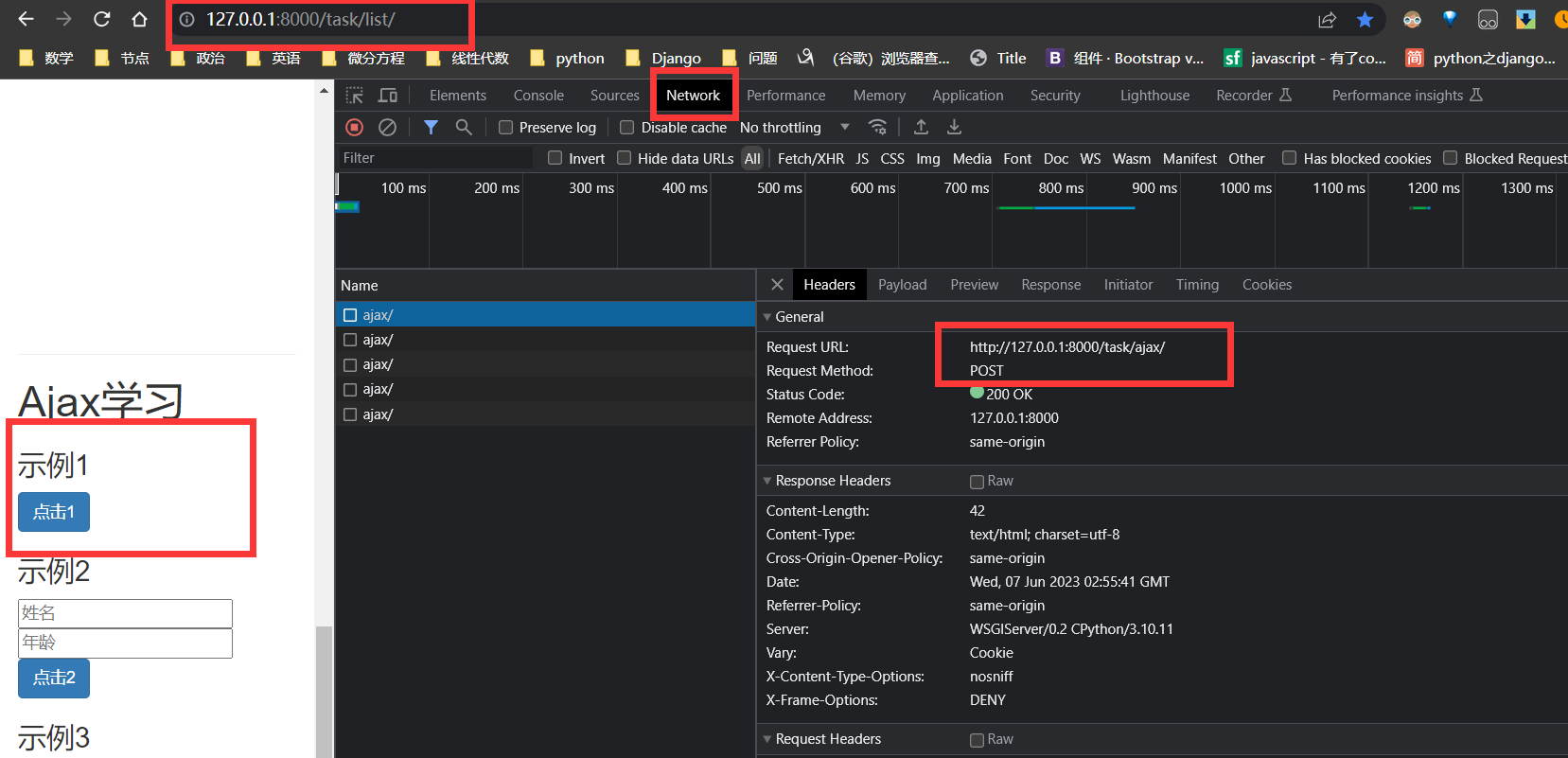
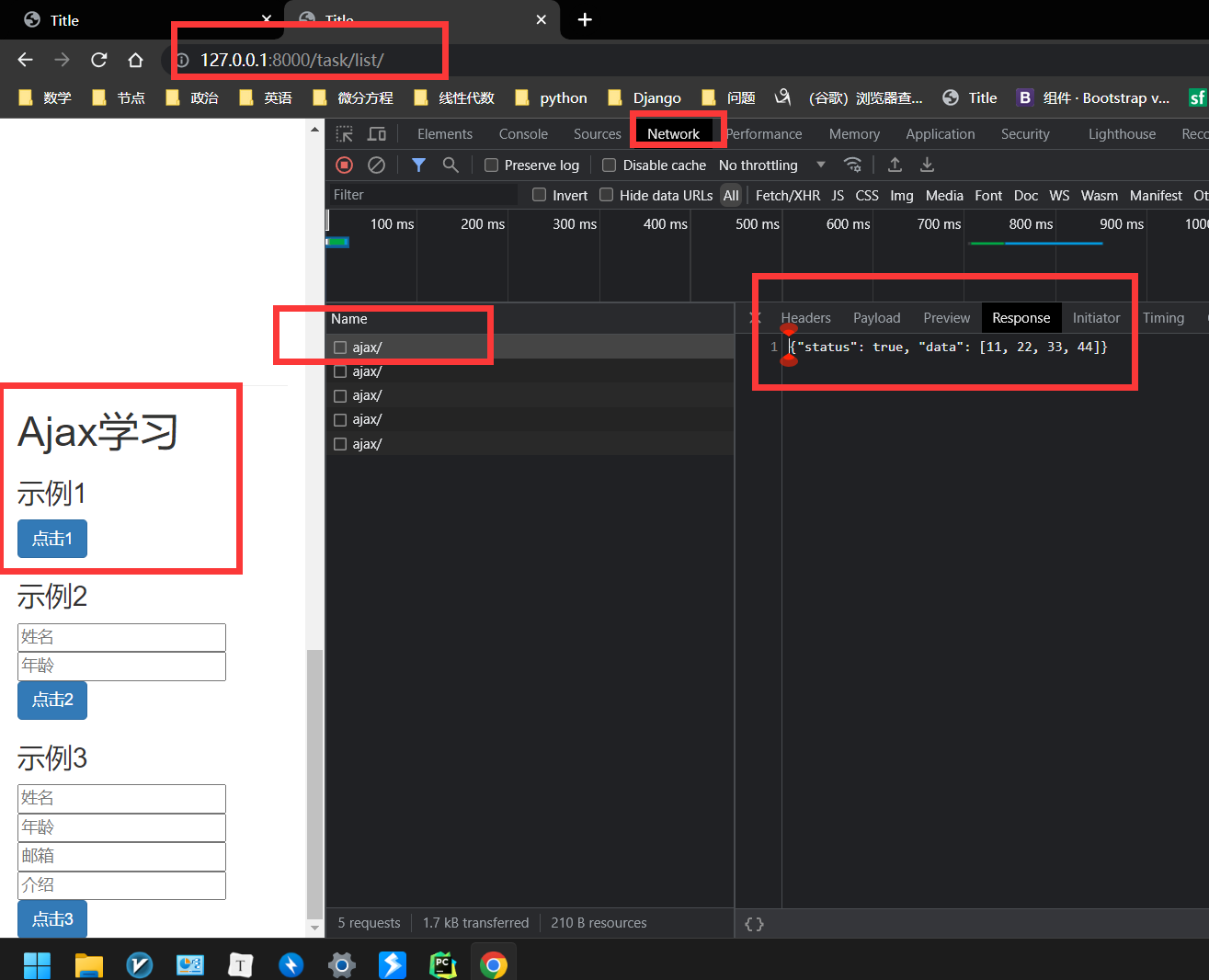
task_list.html 对 task_ajax 发出 post 请求时,task_list 的 bindBtn1Event 将 data (n1,n2)中的数据 发送给 task_ajax
get 请求
task_list.html 对 task_ajax 发出 post 请求时,task_list 的 bindBtn1Event 将 data (n1,n2)中的数据 发送给 task_ajax
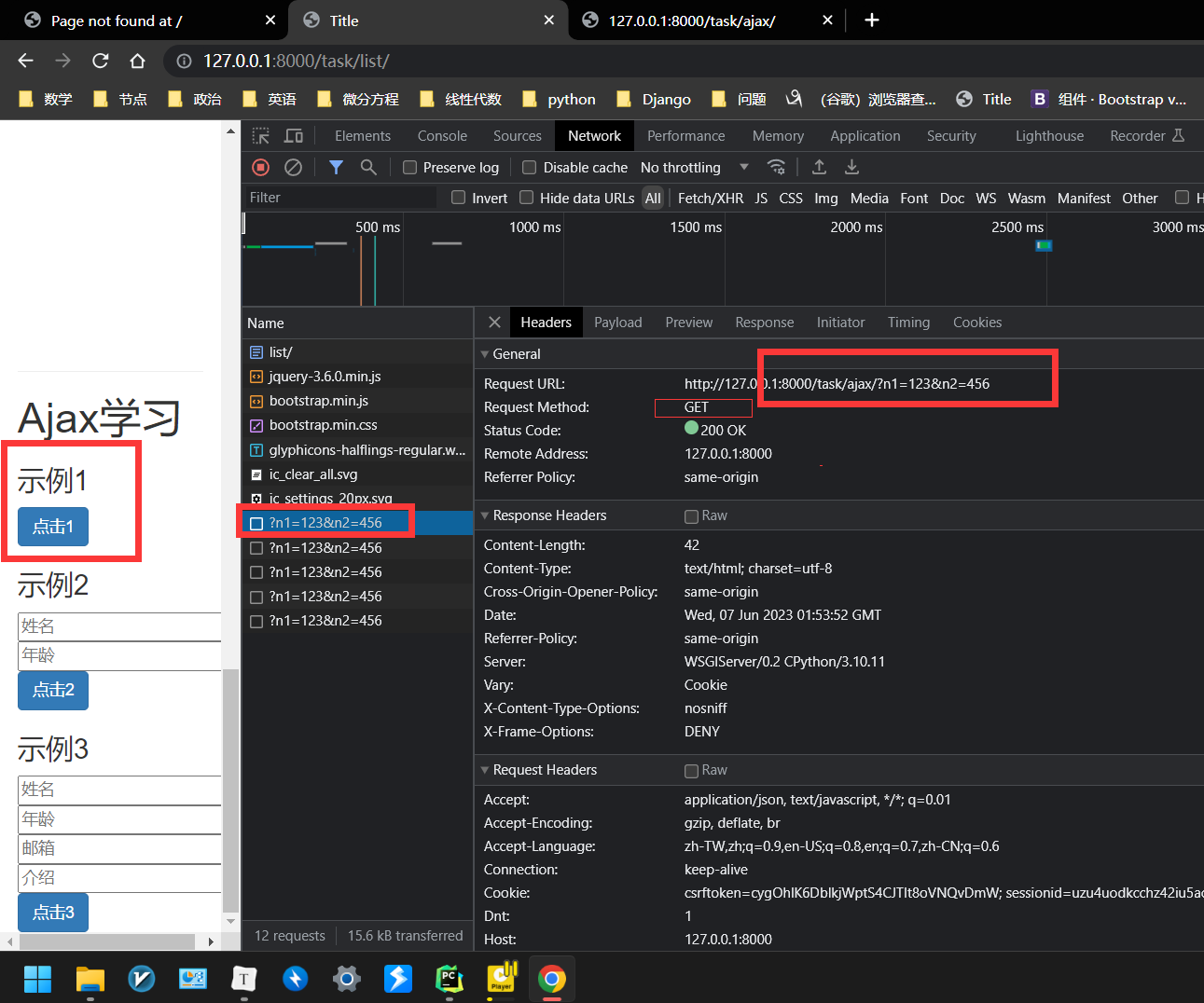
task_ajax 返回 的 HttpResponse 被task_list 的 bindBtn1Event 的 Function接收
差别
get 和 post
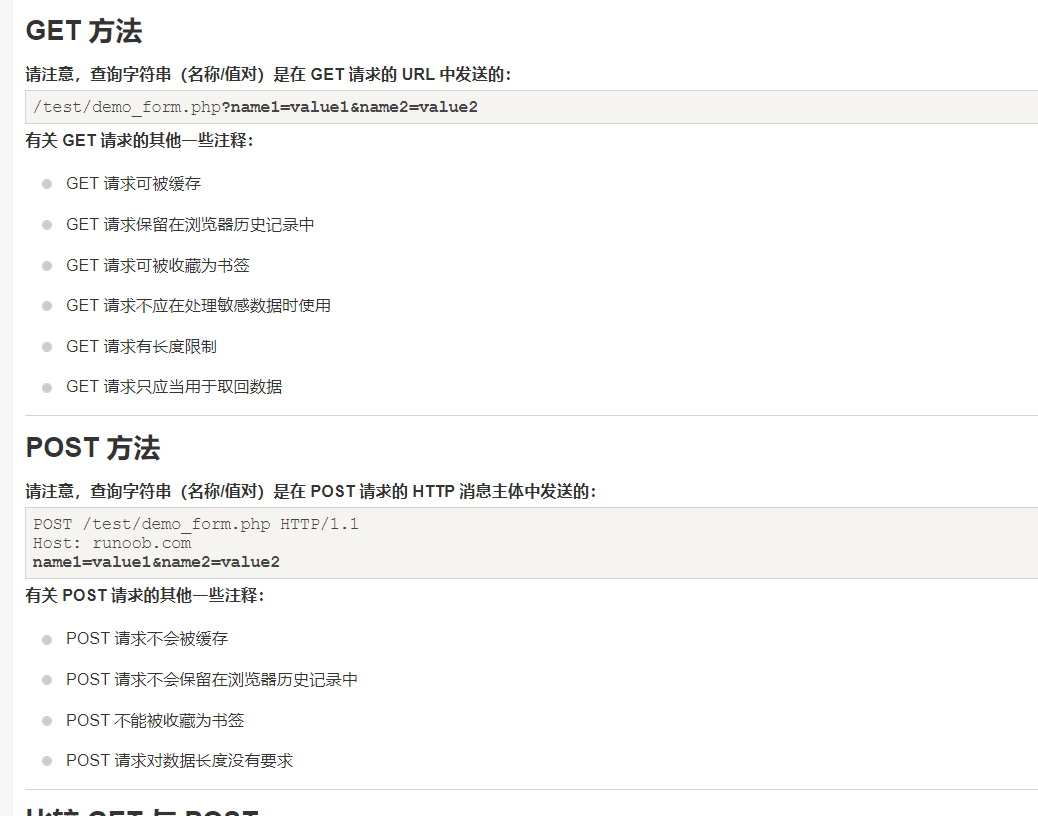
post用于修改和写入数据,get一般用于搜索排序和筛选之类的操作(淘宝,支付宝的搜索查询都是get提交),目的是资源的获取,读取数据
form表单提交和ajax异步请求的优缺点

任务表单
任务表单界面
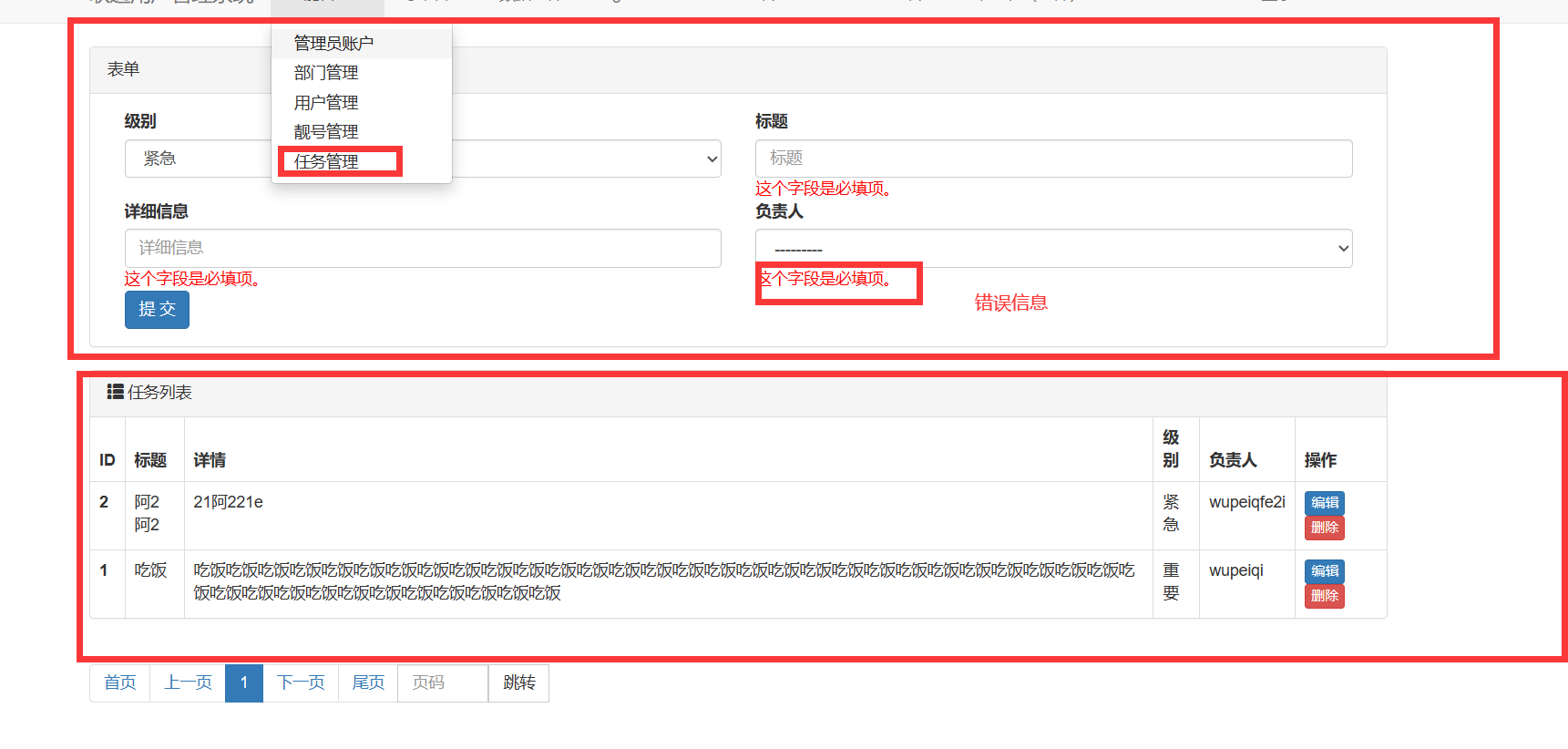
task.py
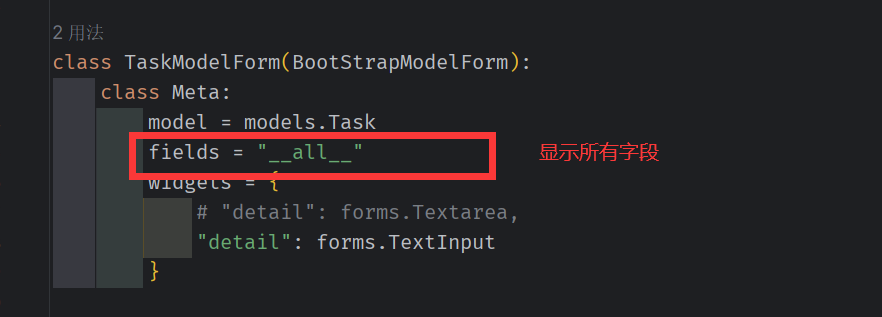
表单的前端代码(栅格布局)

使用Ajax 提交表单数据
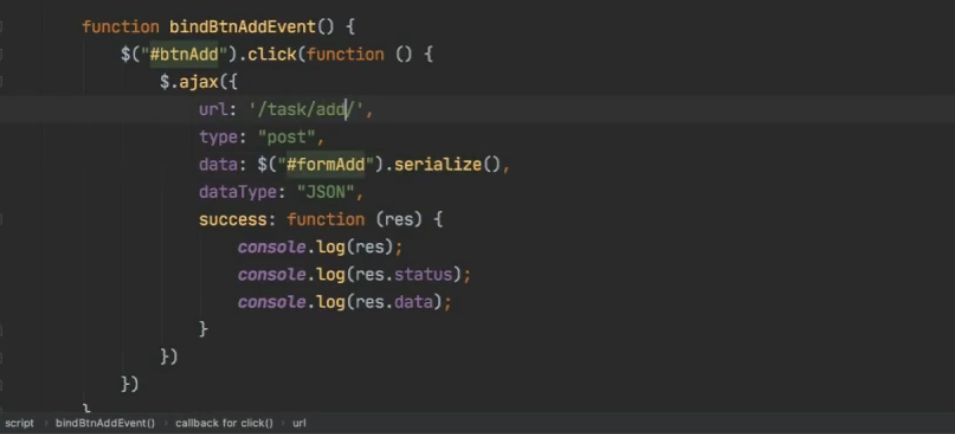
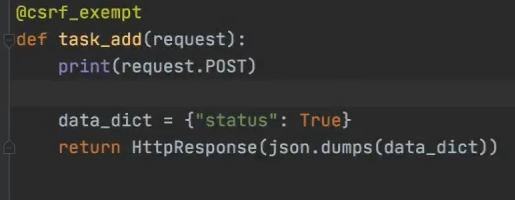
错误提示的校验
将错误信息以json 格式传到前端,
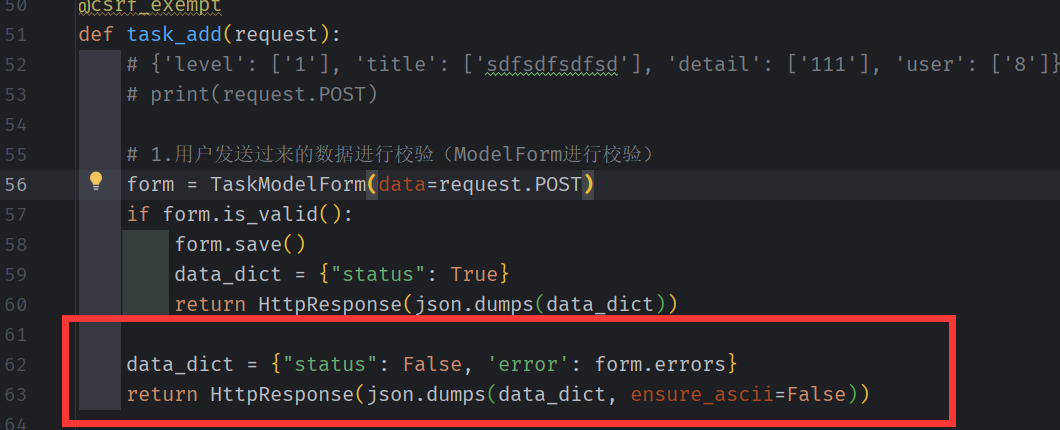
前端接收到的错误信息是一个 字典类型
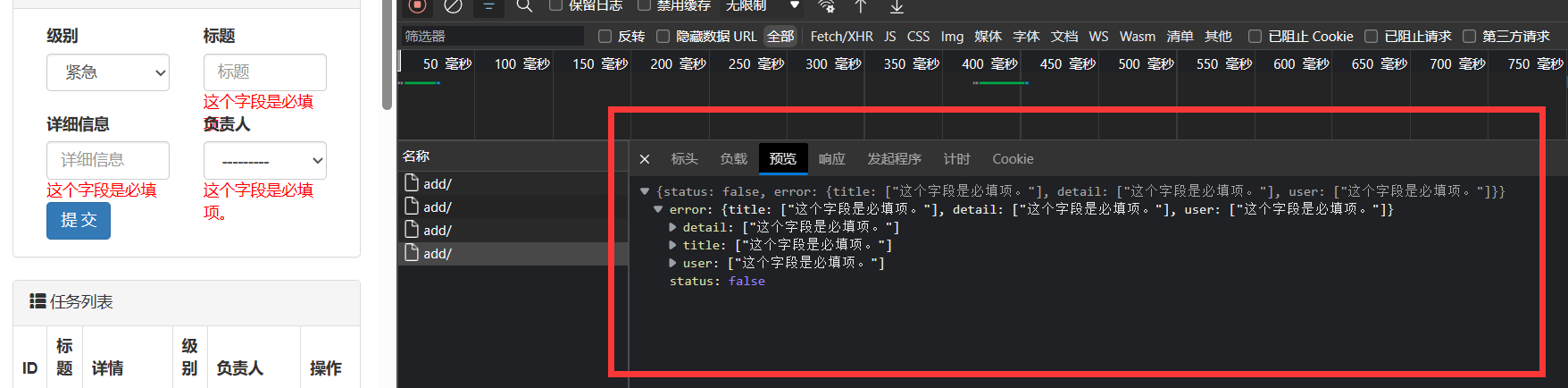
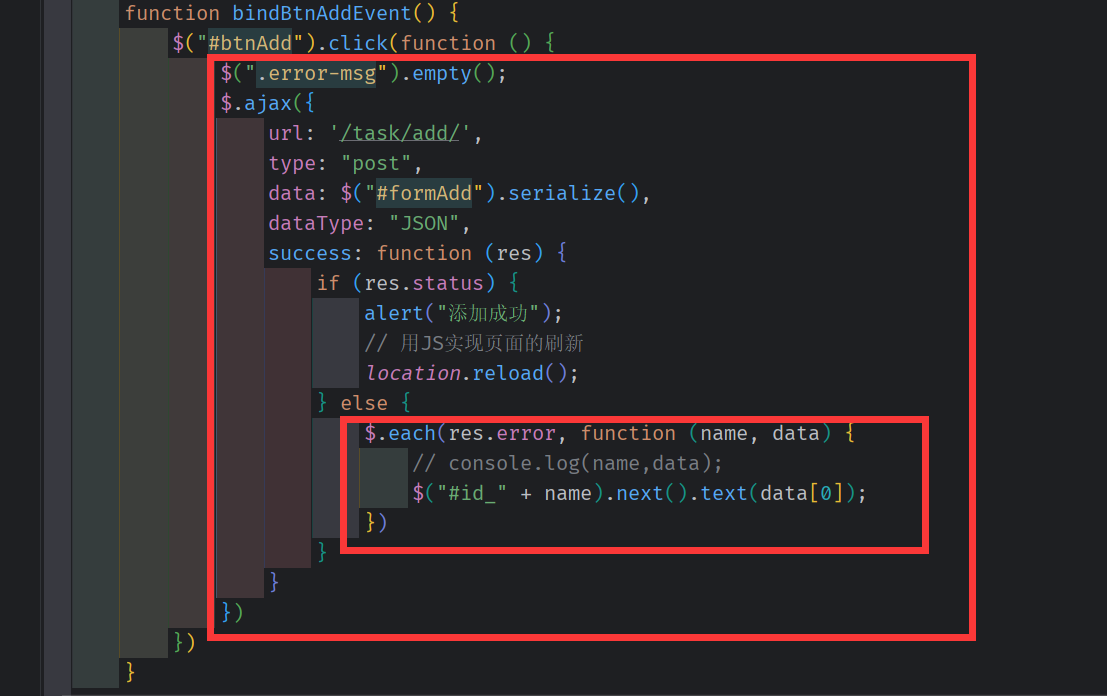
Ajax js 实现对 错误信息(字典)的遍历
因为 model_Form 生成的表单元素的 字段信息的id格式是 id + 下划线 + 字段名。
我们在错误信息字典中能定位到哪个 表单元素出错,就能将错误信息拼接到元素的next()处
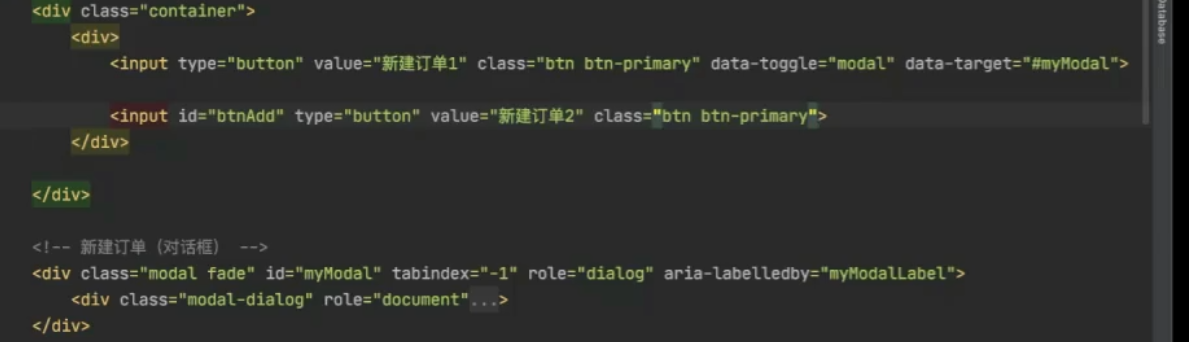
订单表单
弹出添加订单的对话框
order_list.html
使用bootstrap 提供的javaScript 插件
使用自定义的 js
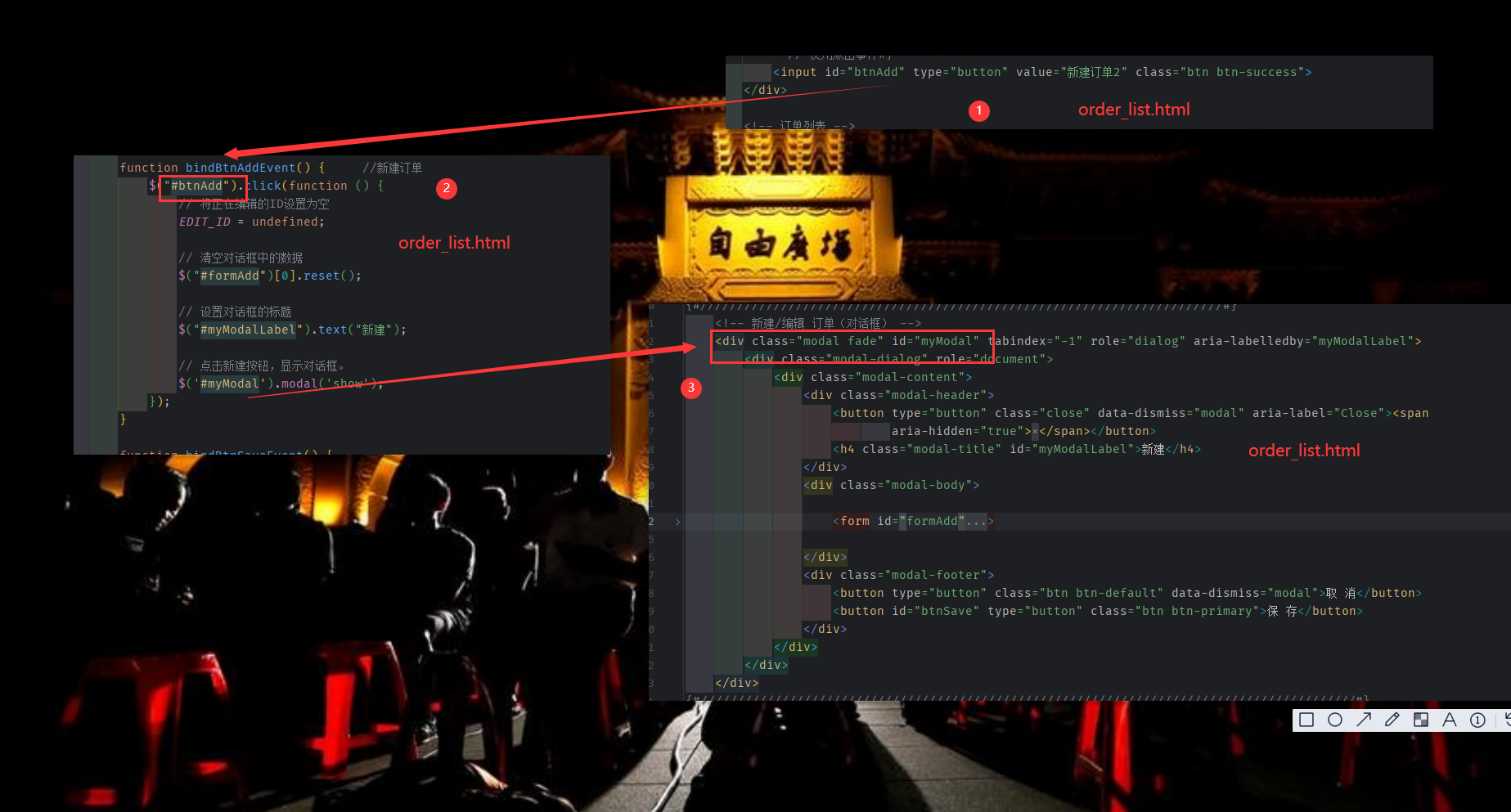
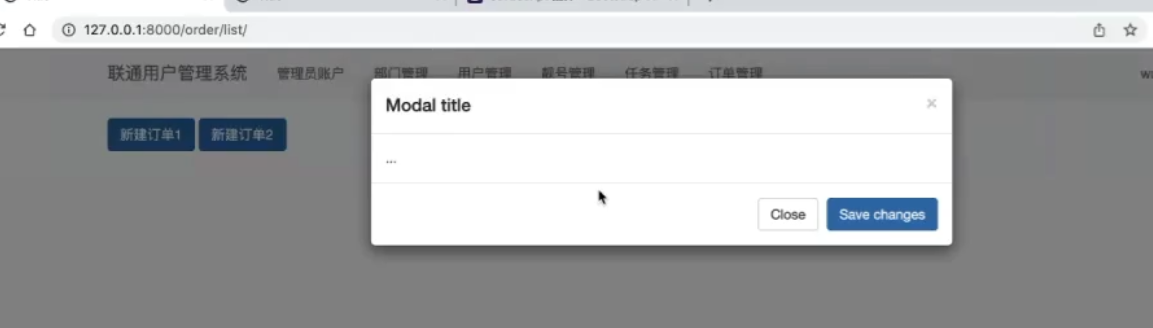
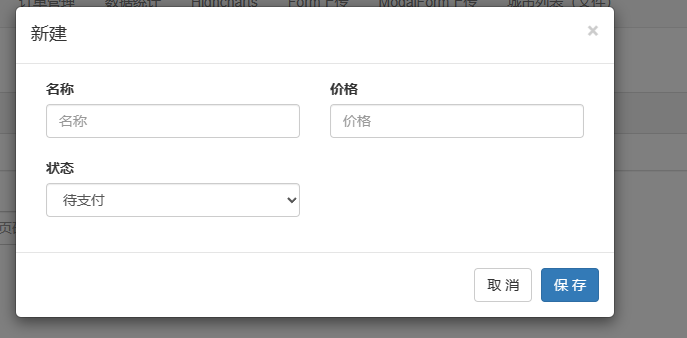
在对话框中添加 表单
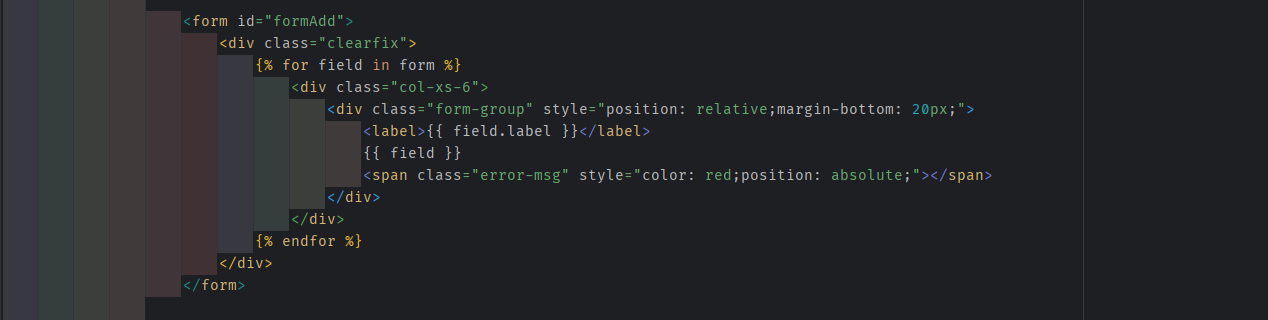
通过 modelForm 自动生成
model.py 和 order_list.html

生成的 表单里排除了让用户选择 订单的 管理员。 而 是让登录用户 作为 订单的管理员
ajax 提交表单
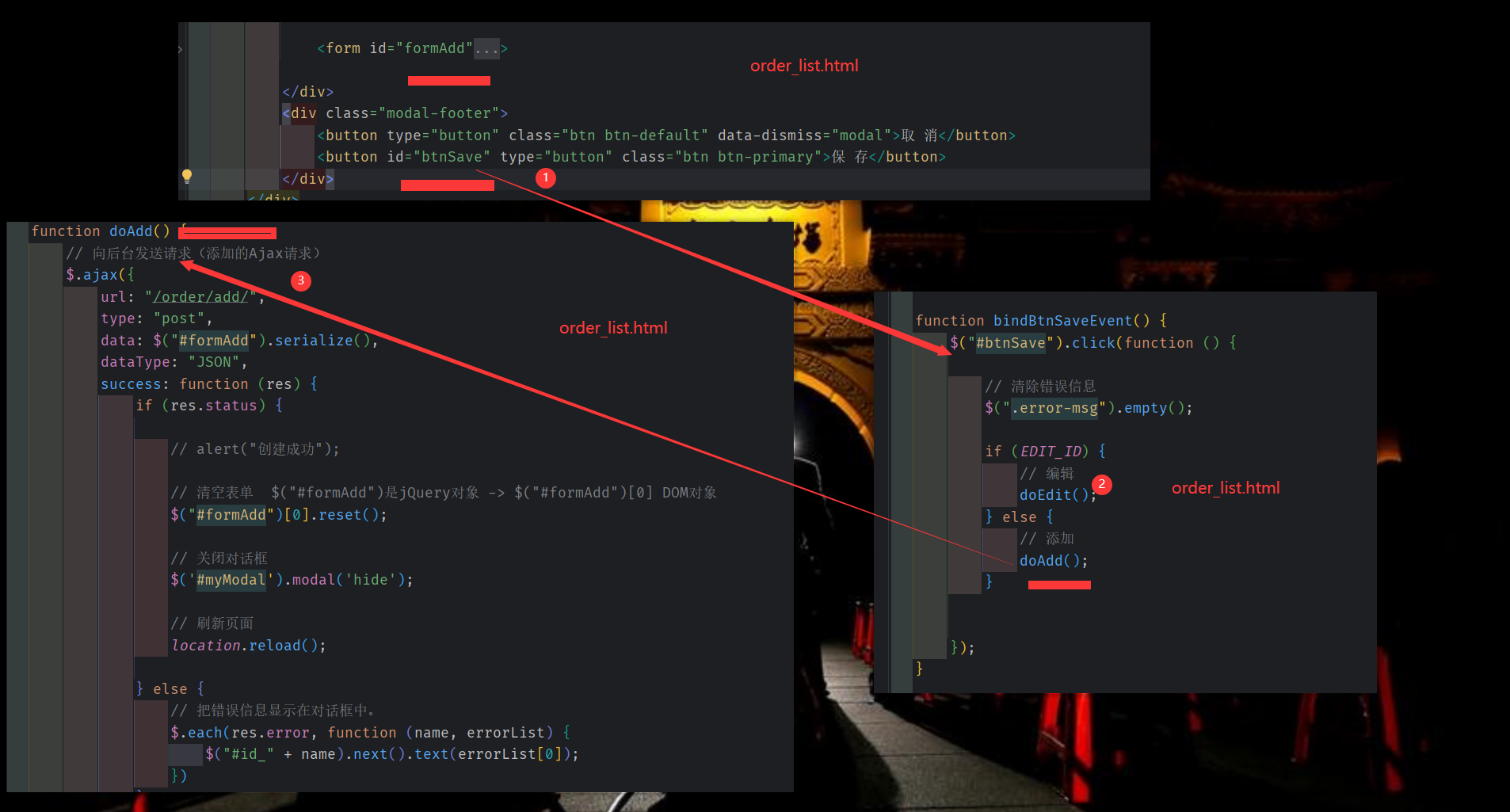
管理员的 id 和 名字被保存在 session 中 , 订单号 随机生成。 均不需要 用户在 订单页面提交
订单列表
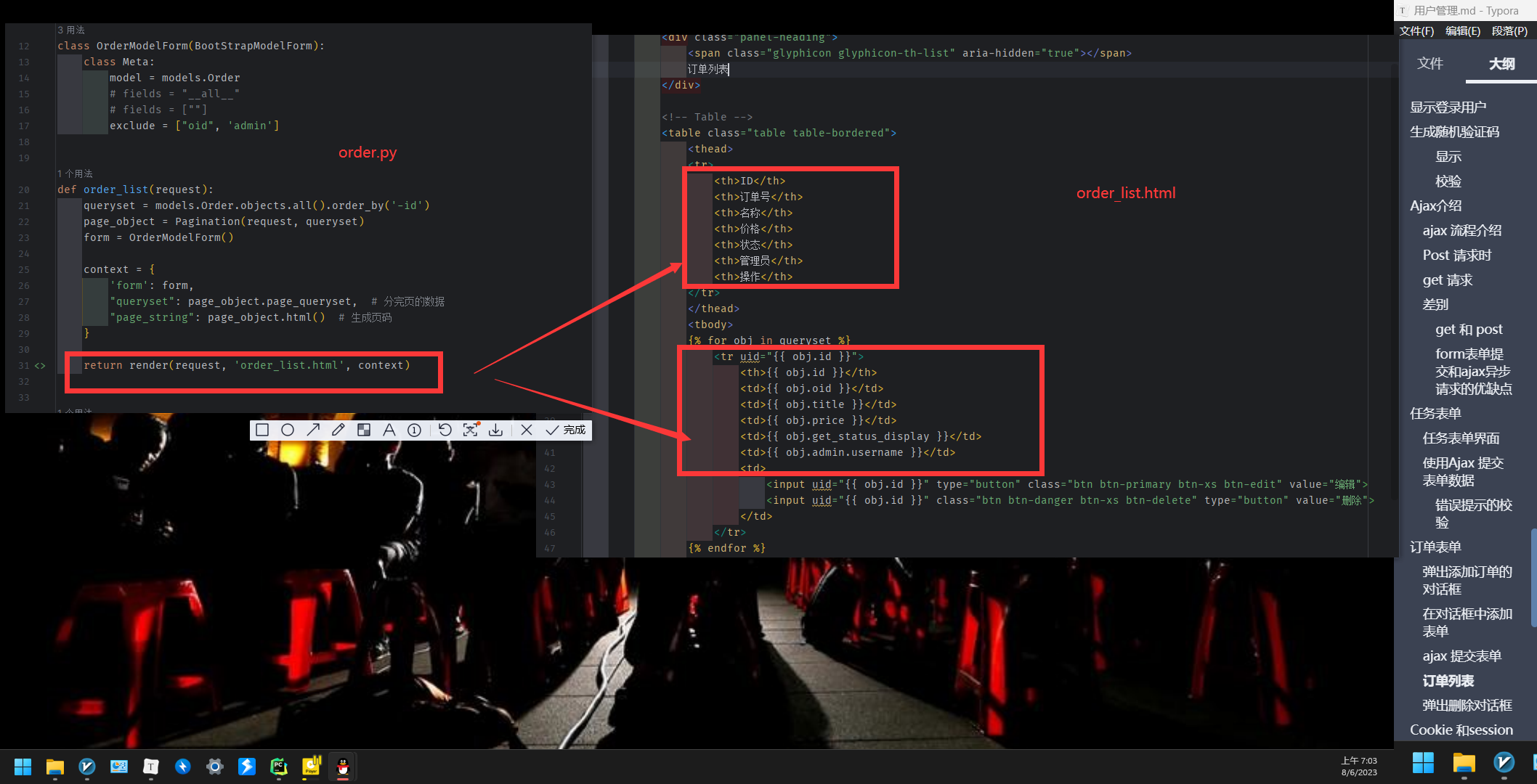

这一步 拿到的 uid (也就是当前编辑对象)将 提供给 全局变量 DELETE_ID
弹出删除对话框 (js)
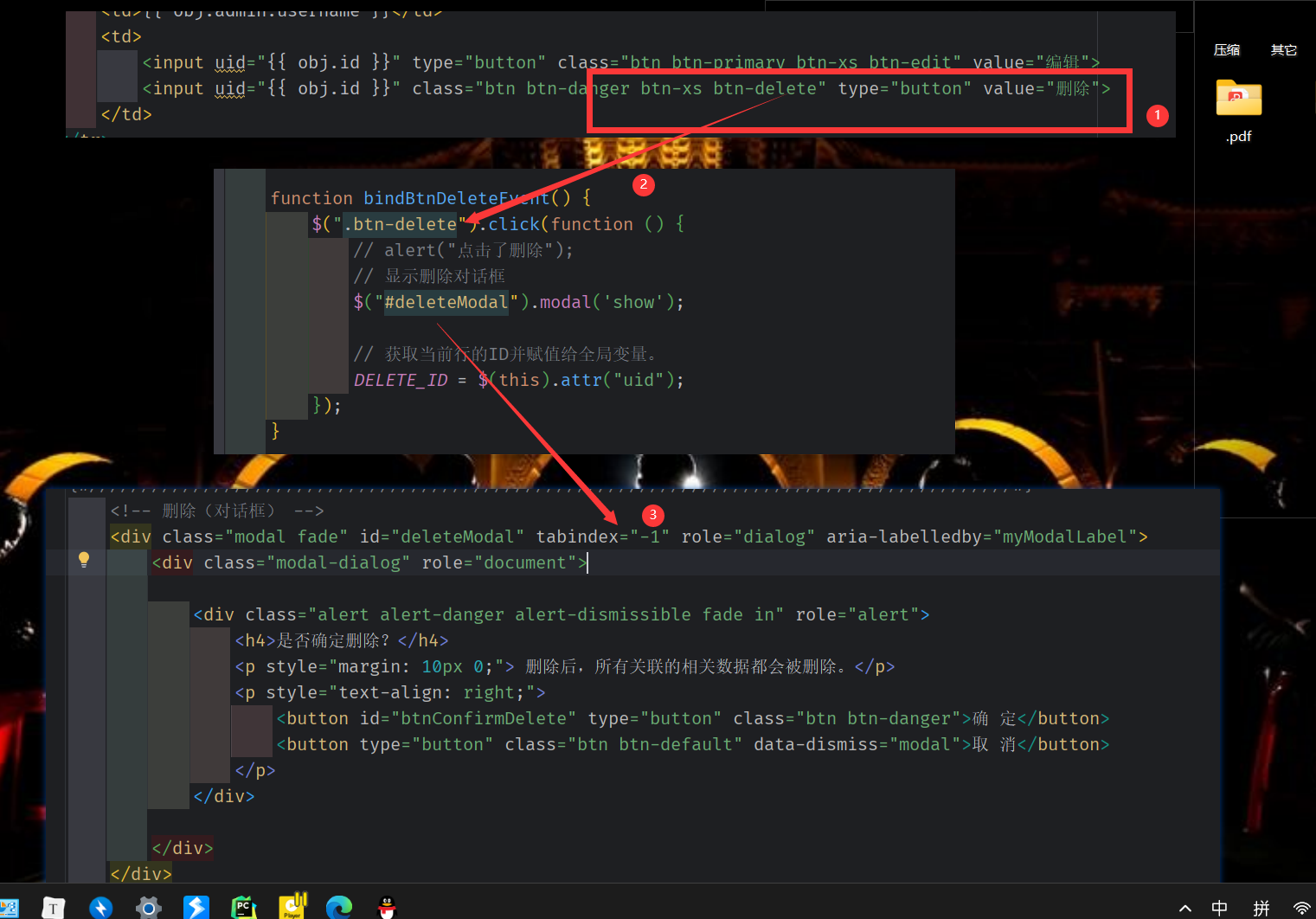
具体删除功能 (ajax)
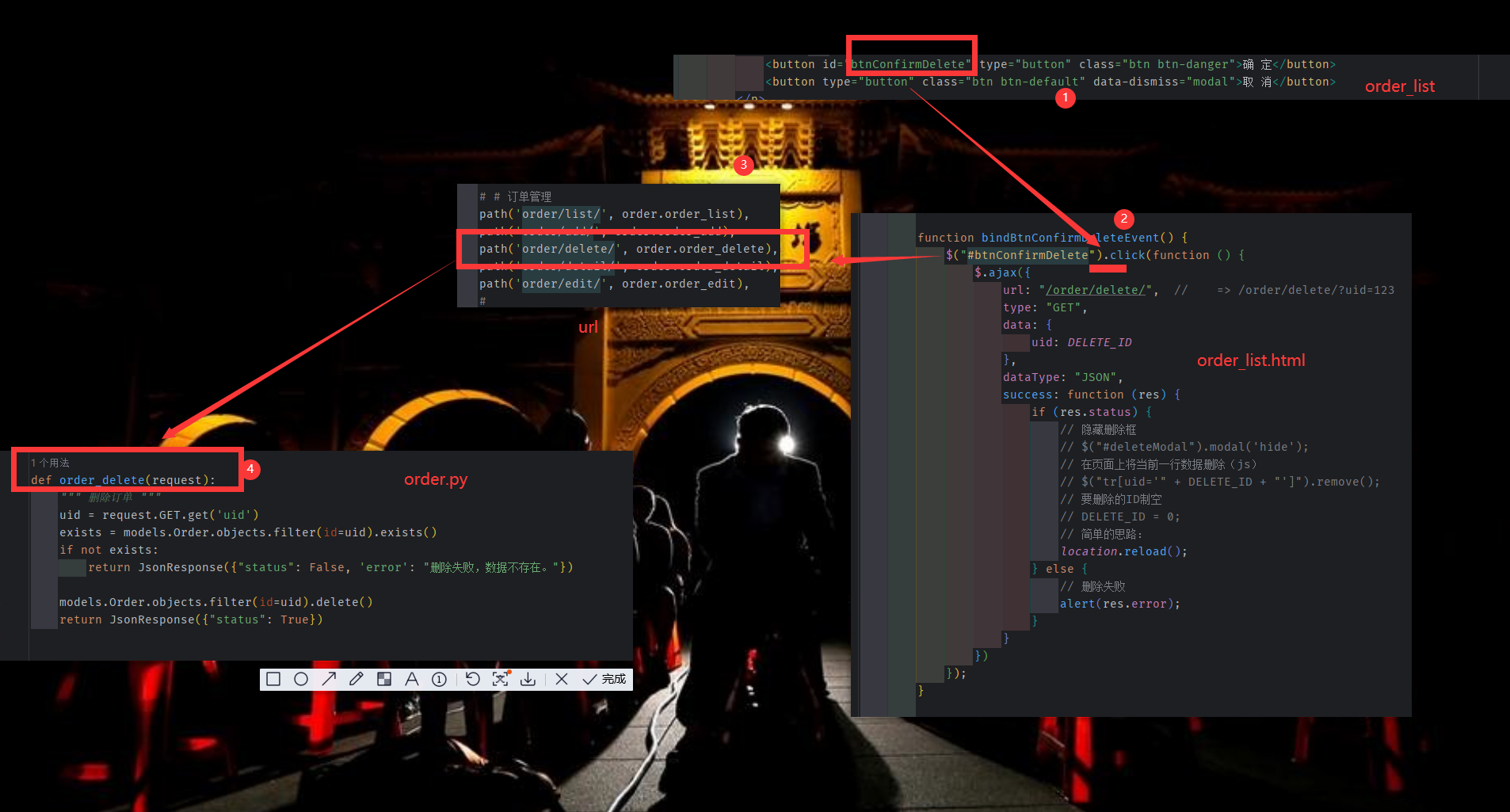
获取删除行的 uid , ajax传到后台,删除成功后自动刷新。
获取要编辑的那一行的数据
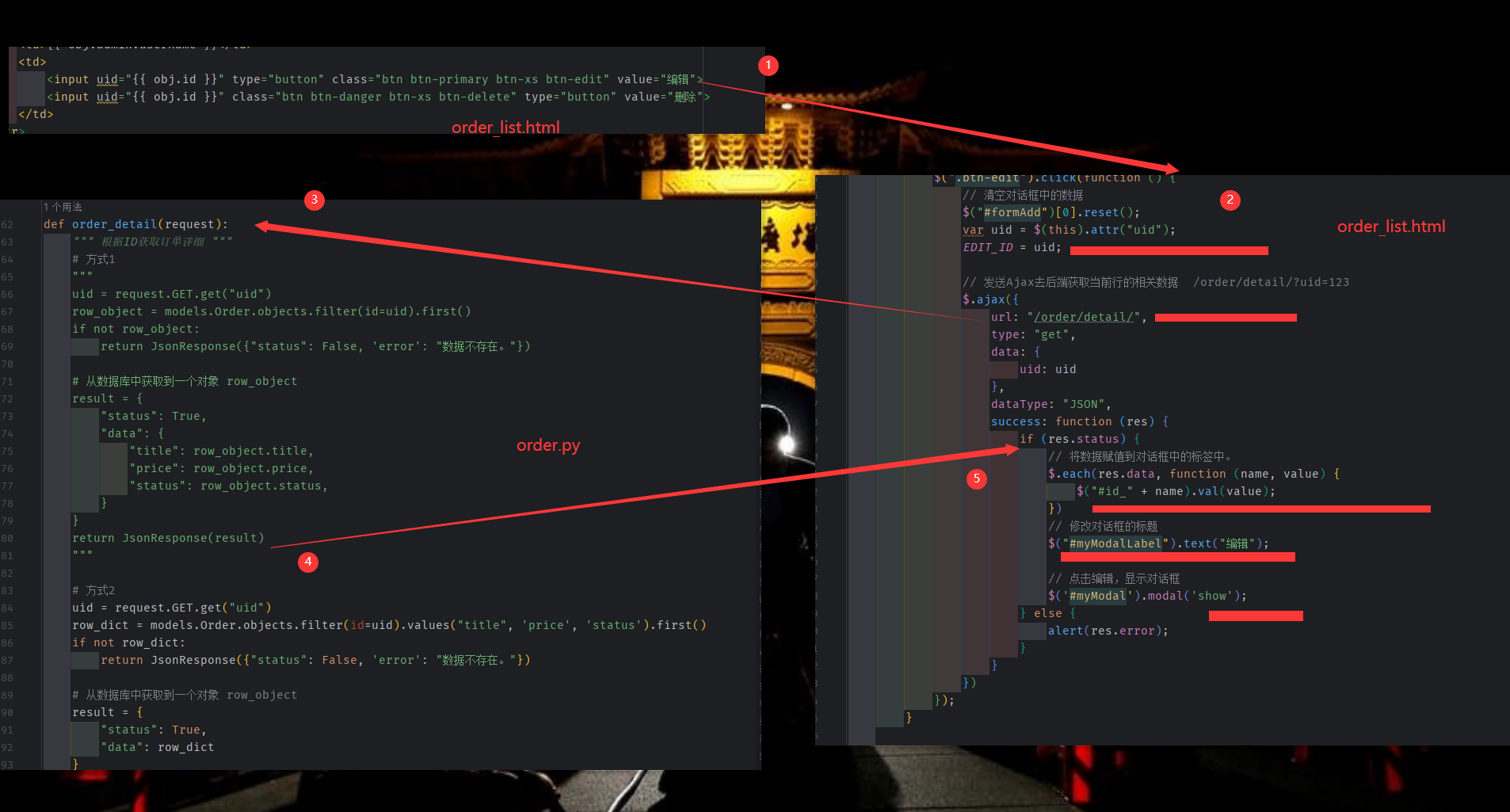
Django 支持三种从数据库 获取 数据的方式
想要去数据库中获取数据时:对象/字典
# 对象,当前行的所有数据。
row_object = models.Order.objects.filter(id=uid).first()
row_object.id
row_object.title
# 字典,{"id":1,"title":"xx"}
row_dict = models.Order.objects.filter(id=uid).values("id","title").first()
# queryset = [obj,obj,obj,]
queryset = models.Order.objects.all()
# queryset = [ {'id':1,'title':"xx"},{'id':2,'title':"xx"}, ]
queryset = models.Order.objects.all().values("id","title")
# queryset = [ (1,"xx"),(2,"xxx"), ]
queryset = models.Order.objects.all().values_list("id","title")
提交编辑的数据
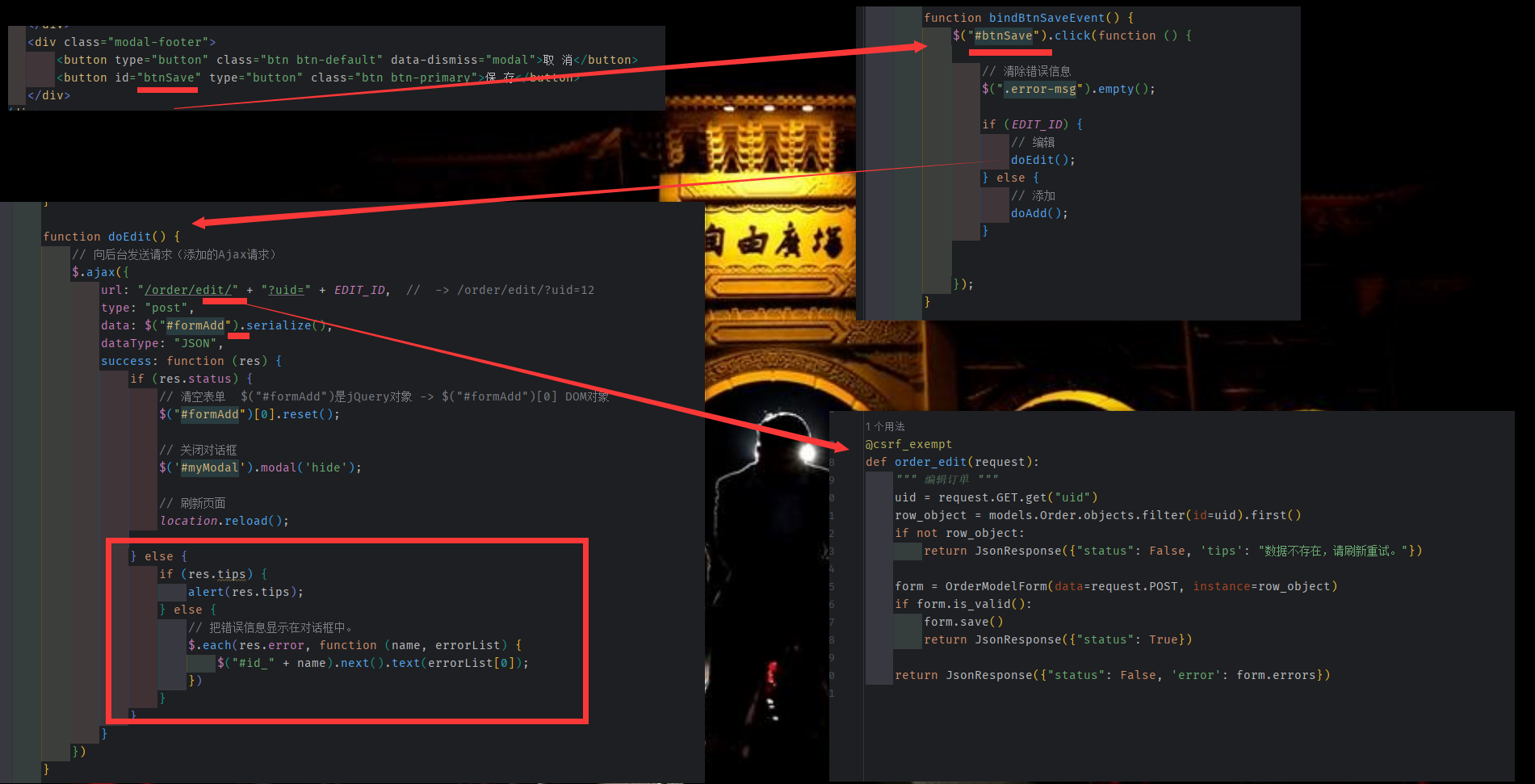
当点击编辑时,给 全局变量 Edit_ID 赋值, 由于复用了编辑框 和添加框, 需要使用全局变量 EDIT_ID 判断 此时为编辑状态,(在点击新建时,将EDIT_ID 置为 undefined, 在 点击 编辑时(获取数据时),将 选中行 的id 赋值给 EDIT_ID 。 )
如果 EDIT_ID 不为空(undefined), 则判断为编辑 在进行确认(上传表单)时, 会执行 doEdit 将数据上传,并进行错误校验。若EDIT_ID 为空 ,则 执行 doAdd();
图表
- highchart,国外。
- echarts,国内。
更多参考文档:https://echarts.apache.org/handbook/zh/get-started
关于文件上传
1 基本操作
upload_list.html
<form method="post" enctype="multipart/form-data"> // 必须是post
{% csrf_token %}
<input type="text" name="username">
<input type="file" name="avatar">
<input type="submit" value="提交">
</form>
upload.py
from django.shortcuts import render, HttpResponse
def upload_list(request):
if request.method == "GET":
return render(request, 'upload_list.html')
# # 'username': ['big666']
# print(request.POST) # 请求体中数据
# # {'avatar': [<InMemoryUploadedFile: 图片 1.png (image/png)>]}>
# print(request.FILES) # 请求发过来的文件 {}
file_object = request.FILES.get("avatar")
# print(file_object.name) # 文件名:WX20211117-222041@2x.png
f = open(file_object.name, mode='wb')
for chunk in file_object.chunks():
f.write(chunk)
f.close()
return HttpResponse("...")
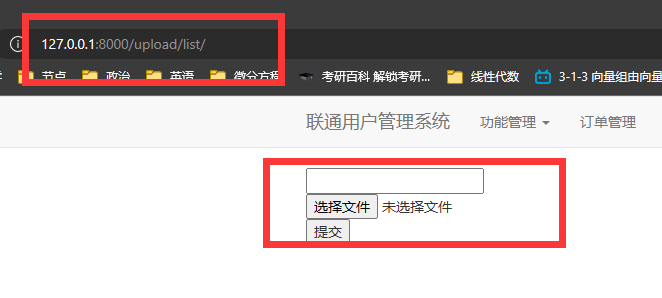
2 批量上传 (excel)
excel 上传参见
批量上传部门
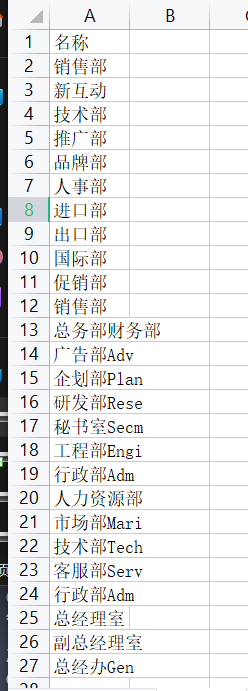
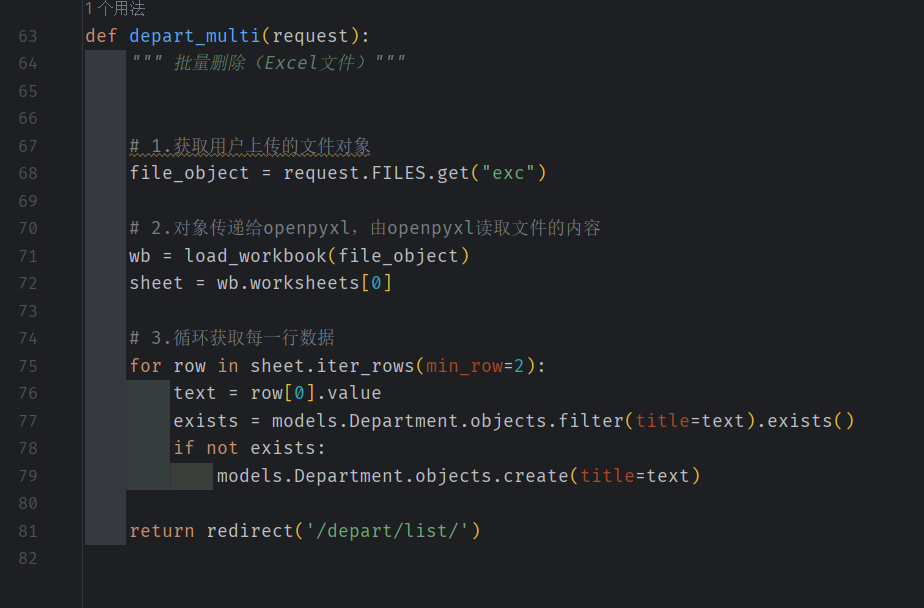
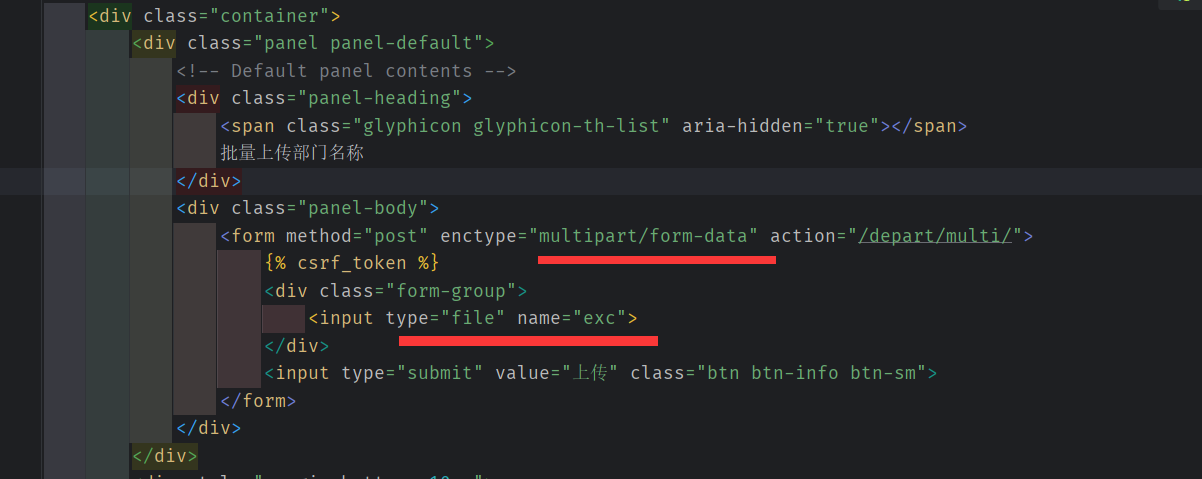
部门名称不重复,则可以导入数据库
案例:混合数据(Form)
提交页面时:用户输入数据 + 文件(输入不能为空、报错)。
- Form生成HTML标签:type=file
- 表单的验证
- form.cleaned_data 获取 数据 + 文件对象
参见
Cookie 和session 介绍 (图解 Http)
1. 使用Cookie来管理状态
HTTP 是无状态协议,说明它不能以状态来区分和管理请求和响应。也就是说,无法根据之前的状态进行本次的请求处理。
不可否认,无状态协议当然也有它的优点。由于不必保存状态,自然可减少服务器的CPU 及内存资源的消耗。从另一侧面来说,也正是因为HTTP 协议本身是非常简单的,所以才会被应用在各种场景里。

我们登录淘宝的时候首先要登录,我们看到了一个商品点进去,进行了页面跳转/刷新,按照HTTP的无状态协议岂不是又要登录一次?
所以为了解决这个问题,Cookie诞生了,在保留无状态协议这个特征的同时又要解决类似记录状态的矛盾问题。Cookie 技术通过在请求和响应报文中写入Cookie 信息来控制客户端的状态。
Cookie 会根据从服务器端发送的响应报文内的一个叫做Set-Cookie的首部字段信息,通知客户端保存Cookie。当下次客户端再往该服务器发送请求时,客户端会自动在请求报文中加入Cookie 值后发送出去。
服务器端发现客户端发送过来的Cookie 后,会去检查究竟是从哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。
-
没有Cookie信息状态下的请求

-
第2次以后(存有Cookie信息状态)的请求

上图很清晰地展示了发生Cookie 交互的情景。
HTTP 请求报文和响应报文的内容如下(数字和图中对应)。
①请求报文(没有Cookie 信息的状态)
GET /reader/ HTTP/1.1
Host: hackr.jp
*首部字段内没有Cookie的相关信息
②响应报文(服务器端生成Cookie 信息)
HTTP/1.1 200 OK
Date: Thu, 12 Jul 2012 07:12:20 GMT
Server: Apache
<Set-Cookie: sid=1342077140226724; path=/; expires=Wed,10-Oct-12 07:12:20 GMT>
Content-Type: text/plain; charset=UTF-8
③请求报文(自动发送保存着的Cookie 信息)
GET /image/ HTTP/1.1
Host: hackr.jp
Cookie: sid=1342077140226724
2. 关于Cookie 的首部字段


2.1 Set-Cookie
Set-Cookie: status=enable; expires=Tue, 05 Jul 2011 07:26:31 GMT; ⇒
path=/; domain=.hackr.jp;
当服务器准备开始管理客户端的状态时,会事先告知各种信息。下面的表格列举了Set-Cookie 的字段值。
2.1.1Set-Cookie 字段的属性

2.1.2 expires 属性
Cookie 的expires 属性指定浏览器可发送Cookie 的有效期。当省略expires 属性时,Cookie仅在浏览器关闭之前有效。
另外,一旦Cookie 从服务器端发送至客户端,服务器端就不存在可以显式删除Cookie 的方法。但可通过覆盖已过期的Cookie,实现对客户端Cookie 的实质性删除操作。
2.1.3 path 属性
Cookie 的path 属性可用于限制指定Cookie 的发送范围的文件目录。不过另有办法可避开这项限制,看来对其作为安全机制的效果不能抱有期待。
2.1.4 domain 属性
通过Cookie 的domain 属性指定的域名可做到与结尾匹配一致。比如, 当指定http://example.com 后, 除http://example.com 以外,Example Domain或www2.example.com 等都可以发送Cookie。因此,除了针对具体指定的多个域名发送Cookie 之外,不指定domain 属性显得更安全。
2.1.5 secure 属性
Cookie 的secure 属性用于限制Web 页面仅在HTTPS 安全连接时,才可以发送Cookie。发送Cookie 时,指定secure 属性的方法如下所示。
Set-Cookie: name=value; secure
以上例子仅当在https ://Example Domain(HTTPS)安全连接的情况下才会进行Cookie 的回收。也就是说,即使域名相同时http : //Example Domain(HTTP) 也不会发生Cookie 回收行为。当省略secure 属性时,不论HTTP 还是HTTPS,都会对Cookie 进行回收。
2.1.6 HttpOnly 属性
Cookie 的HttpOnly 属性是Cookie 的扩展功能,它使JavaScript 脚本无法获得Cookie。其主要目的为防止跨站脚本攻击(Cross-sitescripting,XSS)对Cookie 的信息窃取。
发送指定HttpOnly 属性的Cookie 的方法如下所示。
Set-Cookie: name=value; HttpOnly
通过上述设置,通常从Web 页面内还可以对Cookie 进行读取操作。但使用JavaScript 的document.cookie 就无法读取附加HttpOnly 属性后的Cookie 的内容了。因此,也就无法在XSS 中利用JavaScript 劫持Cookie 了。
虽然是独立的扩展功能,但Internet Explorer 6 SP1 以上版本等当下的主流浏览器都已经支持该扩展了。另外顺带一提,该扩展并非是为了防止XSS 而开发的。
2.2 Cookie
Cookie: status=enable
首部字段Cookie 会告知服务器,当客户端想获得HTTP 状态管理支持时,就会在请求中包含从服务器接收到的Cookie。接收到多个Cookie 时,同样可以以多个Cookie 形式发送。
3 Session 管理及Cookie 应用
3.1 什么是Session
在计算机中,尤其是在网络应用中,称为“会话控制”。Session 对象存储特定用户会话所需的属性及配置信息。这样,当用户在应用程序的 Web 页之间跳转时,存储在 Session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当用户请求来自应用程序的 Web 页时,如果该用户还没有会话,则 Web 服务器将自动创建一个 Session 对象。当会话过期或被放弃后,服务器将终止该会话。Session 对象最常见的一个用法就是存储用户的首选项。例如,如果用户指明不喜欢查看图形,就可以将该信息存储在 Session 对象中。
3.2 通过Cookie来管理Session
基于表单认证的标准规范尚未有定论,一般会使用Cookie 来管理Session(会话)。
基于表单认证本身是通过服务器端的Web 应用,将客户端发送过来的用户ID 和密码与之前登录过的信息做匹配来进行认证的。
但鉴于HTTP 是无状态协议,之前已认证成功的用户状态无法通过协议层面保存下来。即,无法实现状态管理,因此即使当该用户下一次继续访问,也无法区分他与其他的用户。于是我们会使用Cookie 来管理Session,以弥补HTTP 协议中不存在的状态管理功能。

Session 管理及Cookie 状态管理
- 步骤一:客户端把用户ID 和密码等登录信息放入报文的实体部分,通常是以POST 方法把请求发送给服务器。而这时,会使用HTTPS 通信来进行HTML 表单画面的显示和用户输入数据的发送。
- 步骤二:服务器会发放用以识别用户的Session ID。通过验证从客户端发送过来的登录信息进行身份认证,然后把用户的认证状态与Session ID 绑定后记录在服务器端。
向客户端返回响应时,会在首部字段Set-Cookie 内写入Session ID(如PHPSESSID=028a8c…)。
你可以把Session ID 想象成一种用以区分不同用户的等位号。然而,如果Session ID 被第三方盗走,对方就可以伪装成你的身份进行恶意操作了。因此必须防止Session ID 被盗,或被猜出。为了做到这点,Session ID 应使用难以推测的字符串,且服务器端也需要进行有效期的管理,保证其安全性。
另外,为减轻跨站脚本攻击(XSS)造成的损失,建议事先在Cookie 内加上httponly 属性。
- 步骤三:客户端接收到从服务器端发来的Session ID 后,会将其作为Cookie 保存在本地。下次向服务器发送请求时,浏览器会自动发送Cookie,所以Session ID 也随之发送到服务器。服务器端可通过验证接收到的Session ID 识别用户和其认证状态。
除了以上介绍的应用实例,还有应用其他不同方法的案例。
另外,不仅基于表单认证的登录信息及认证过程都无标准化的方法,服务器端应如何保存用户提交的密码等登录信息等也没有标准化。
通常,一种安全的保存方法是,先利用给密码加盐(salt)A 的方式增加额外信息,再使用散列(hash)函数计算出散列值后保存。但是我们也经常看到直接保存明文密码的做法,而这样的做法具有导致密码泄露的风险。
Excel格式文件
Python内部未提供处理Excel文件的功能,想要在Python中操作Excel需要按照第三方的模块。
pip install openpyxl
此模块中集成了Python操作Excel的相关功能,接下来我们就需要去学习该模块提供的相关功能即可。

5.1 读Excel#
-
读sheet
from openpyxl import load_workbook
wb = load_workbook("files/p1.xlsx")
# sheet相关操作
# 1.获取excel文件中的所有sheet名称
print(wb.sheetnames) # ['数据导出', '用户列表', 'Sheet1', 'Sheet2']
# 2.选择sheet,基于sheet名称
sheet = wb["数据导出"]
cell = sheet.cell(1, 2) # sheet名称是“数据导出”,第一行第二列的数据
print(cell.value) # 输出单元格的值
# 3.选择sheet,基于索引位置
sheet = wb.worksheets[0]
cell = sheet.cell(1,2)
print(cell.value)
# 4.循环所有的sheet
for name in wb.sheetnames:
sheet = wb[name]
cell = sheet.cell(1, 1)
print(cell.value)
for sheet in wb.worksheets:
cell = sheet.cell(1, 1)
print(cell.value)
for sheet in wb:
cell = sheet.cell(1, 1)
print(cell.value)
-
读sheet中单元格的数据
from openpyxl import load_workbook
wb = load_workbook("files/p1.xlsx")
sheet = wb.worksheets[0]
# 1.获取第N行第N列的单元格(位置是从1开始)
cell = sheet.cell(1, 1)
print(cell.value) # 获取单元格内容
print(cell.style) # 获取样式
print(cell.font) # 获取字体
print(cell.alignment) # 获取排列情况
# 2.获取某个单元格
c1 = sheet["A2"]
print(c1.value)
c2 = sheet['D4']
print(c2.value)
# 3.第N行所有的单元格
for cell in sheet[1]:
print(cell.value)
# 4.所有行的数据(获取某一列数据)
for row in sheet.rows:
print(row[0].value, row[1].value) # 获取第0列,和第1列
# 5.获取所有列的数据
for col in sheet.columns:
print(col[1].value) # 获取第一行数据
-
读合并的单元格(合并单元格的第一个位置的值为单元格内容,其他的为None)

from openpyxl import load_workbook
wb = load_workbook("files/p1.xlsx")
sheet = wb.worksheets[2]
# 获取第N行第N列的单元格(位置是从1开始)
c1 = sheet.cell(1, 1)
print(c1) # <Cell 'Sheet1'.A1>
print(c1.value) # 用户信息
c2 = sheet.cell(1, 2)
print(c2) # <MergedCell 'Sheet1'.B1>
print(c2.value) # None
from openpyxl import load_workbook
wb = load_workbook('files/p1.xlsx')
sheet = wb.worksheets[2]
for row in sheet.rows:
print(row)
>>> 输出结果
(<Cell 'Sheet1'.A1>, <MergedCell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>)
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>)
(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>)
(<MergedCell 'Sheet1'.A4>, <Cell 'Sheet1'.B4>, <Cell 'Sheet1'.C4>)
(<Cell 'Sheet1'.A5>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.C5>)
5.1 写Excel#
在Excel中想要写文件,大致要分为在:
-
原Excel文件基础上写内容。
from openpyxl import load_workbook
wb = load_workbook('files/p1.xlsx')
sheet = wb.worksheets[0]
# 找到单元格,并修改单元格的内容
cell = sheet.cell(1, 1)
cell.value = "新的开始"
# 将excel文件保存到p2.xlsx文件中
wb.save("files/p2.xlsx")
-
新创建Excel文件写内容。
from openpyxl import workbook
# 创建excel且默认会创建一个sheet(名称为Sheet)
wb = workbook.Workbook()
sheet = wb.worksheets[0] # 或 sheet = wb["Sheet"]
# 找到单元格,并修改单元格的内容
cell = sheet.cell(1, 1)
cell.value = "新的开始"
# 将excel文件保存到p2.xlsx文件中
wb.save("files/p2.xlsx")
在了解了如何读取Excel和创建Excel之后,后续对于Excel中的sheet和cell操作基本上都相同。
from openpyxl import workbook
wb = workbook.Workbook() # Sheet
# 1. 修改sheet名称
sheet = wb.worksheets[0]
sheet.title = "数据集"
wb.save("p2.xlsx")
# 2. 创建sheet并设置sheet颜色
sheet = wb.create_sheet("工作计划", 0)
sheet.sheet_properties.tabColor = "1072BA"
wb.save("p2.xlsx")
# 3. 默认打开的sheet
wb.active = 0
wb.save("p2.xlsx")
# 4. 拷贝sheet
sheet = wb.create_sheet("工作计划")
sheet.sheet_properties.tabColor = "1072BA"
new_sheet = wb.copy_worksheet(wb["Sheet"])
new_sheet.title = "新的计划"
wb.save("p2.xlsx")
# 5.删除sheet
del wb["用户列表"]
wb.save('files/p2.xlsx')
from openpyxl import load_workbook
from openpyxl.styles import Alignment, Border, Side, Font, PatternFill, GradientFill
wb = load_workbook('files/p1.xlsx')
sheet = wb.worksheets[1]
# 1. 获取某个单元格,修改值
cell = sheet.cell(1, 1)
cell.value = "开始"
wb.save("p2.xlsx")
# 2. 获取某个单元格,修改值
sheet["B3"] = "Alex"
wb.save("p2.xlsx")
# 3. 获取某些单元格,修改值
cell_list = sheet["B2":"C3"]
for row in cell_list:
for cell in row:
cell.value = "新的值"
wb.save("p2.xlsx")
# 4. 对齐方式
cell = sheet.cell(1, 1)
# horizontal,水平方向对齐方式:"general", "left", "center", "right", "fill", "justify", "centerContinuous", "distributed"
# vertical,垂直方向对齐方式:"top", "center", "bottom", "justify", "distributed"
# text_rotation,旋转角度。
# wrap_text,是否自动换行。
cell.alignment = Alignment(horizontal='center', vertical='distributed', text_rotation=45, wrap_text=True)
wb.save("p2.xlsx")
# 5. 边框
# side的style有如下:dashDot','dashDotDot', 'dashed','dotted','double','hair', 'medium', 'mediumDashDot', 'mediumDashDotDot','mediumDashed', 'slantDashDot', 'thick', 'thin'
cell = sheet.cell(9, 2)
cell.border = Border(
top=Side(style="thin", color="FFB6C1"),
bottom=Side(style="dashed", color="FFB6C1"),
left=Side(style="dashed", color="FFB6C1"),
right=Side(style="dashed", color="9932CC"),
diagonal=Side(style="thin", color="483D8B"), # 对角线
diagonalUp=True, # 左下 ~ 右上
diagonalDown=True # 左上 ~ 右下
)
wb.save("p2.xlsx")
# 6.字体
cell = sheet.cell(5, 1)
cell.font = Font(name="微软雅黑", size=45, color="ff0000", underline="single")
wb.save("p2.xlsx")
# 7.背景色
cell = sheet.cell(5, 3)
cell.fill = PatternFill("solid", fgColor="99ccff")
wb.save("p2.xlsx")
# 8.渐变背景色
cell = sheet.cell(5, 5)
cell.fill = GradientFill("linear", stop=("FFFFFF", "99ccff", "000000"))
wb.save("p2.xlsx")
# 9.宽高(索引从1开始)
sheet.row_dimensions[1].height = 50
sheet.column_dimensions["E"].width = 100
wb.save("p2.xlsx")
# 10.合并单元格
sheet.merge_cells("B2:D8")
sheet.merge_cells(start_row=15, start_column=3, end_row=18, end_column=8)
wb.save("p2.xlsx")
sheet.unmerge_cells("B2:D8")
wb.save("p2.xlsx")
# 11.写入公式
sheet = wb.worksheets[3]
sheet["D1"] = "合计"
sheet["D2"] = "=B2*C2"
wb.save("p2.xlsx")
sheet = wb.worksheets[3]
sheet["D3"] = "=SUM(B3,C3)"
wb.save("p2.xlsx")
# 12.删除
# idx,要删除的索引位置
# amount,从索引位置开始要删除的个数(默认为1)
sheet.delete_rows(idx=1, amount=20)
sheet.delete_cols(idx=1, amount=3)
wb.save("p2.xlsx")
# 13.插入
sheet.insert_rows(idx=5, amount=10)
sheet.insert_cols(idx=3, amount=2)
wb.save("p2.xlsx")
# 14.循环写内容
sheet = wb["Sheet"]
cell_range = sheet['A1:C2']
for row in cell_range:
for cell in row:
cell.value = "xx"
for row in sheet.iter_rows(min_row=5, min_col=1, max_col=7, max_row=10):
for cell in row:
cell.value = "oo"
wb.save("p2.xlsx")
# 15.移动
# 将H2:J10范围的数据,向右移动15个位置、向上移动1个位置
sheet.move_range("H2:J10",rows=-1, cols=15)
wb.save("p2.xlsx")
sheet = wb.worksheets[3]
sheet["D1"] = "合计"
sheet["D2"] = "=B2*C2"
sheet["D3"] = "=SUM(B3,C3)"
sheet.move_range("B1:D3",cols=10, translate=True) # 自动翻译公式(自动处理公式)
wb.save("p2.xlsx")
# 16.打印区域
sheet.print_area = "A1:D200"
wb.save("p2.xlsx")
# 17.打印时,每个页面的固定表头
sheet.print_title_cols = "A:D"
sheet.print_title_rows = "1:3"
wb.save("p2.xlsx")
", 0)
sheet.sheet_properties.tabColor = “1072BA”
wb.save(“p2.xlsx”)
3. 默认打开的sheet
wb.active = 0
wb.save(“p2.xlsx”)
4. 拷贝sheet
sheet = wb.create_sheet(“工作计划”)
sheet.sheet_properties.tabColor = “1072BA”
new_sheet = wb.copy_worksheet(wb[“Sheet”])
new_sheet.title = “新的计划”
wb.save(“p2.xlsx”)
5.删除sheet
del wb[“用户列表”]
wb.save(‘files/p2.xlsx’)
from openpyxl import load_workbook
from openpyxl.styles import Alignment, Border, Side, Font, PatternFill, GradientFill
wb = load_workbook(‘files/p1.xlsx’)
sheet = wb.worksheets[1]
1. 获取某个单元格,修改值
cell = sheet.cell(1, 1)
cell.value = “开始”
wb.save(“p2.xlsx”)
2. 获取某个单元格,修改值
sheet[“B3”] = “Alex”
wb.save(“p2.xlsx”)
3. 获取某些单元格,修改值
cell_list = sheet[“B2”:“C3”]
for row in cell_list:
for cell in row:
cell.value = “新的值”
wb.save(“p2.xlsx”)
4. 对齐方式
cell = sheet.cell(1, 1)
horizontal,水平方向对齐方式:“general”, “left”, “center”, “right”, “fill”, “justify”, “centerContinuous”, “distributed”
vertical,垂直方向对齐方式:“top”, “center”, “bottom”, “justify”, “distributed”
text_rotation,旋转角度。
wrap_text,是否自动换行。
cell.alignment = Alignment(horizontal=‘center’, vertical=‘distributed’, text_rotation=45, wrap_text=True)
wb.save(“p2.xlsx”)
5. 边框
side的style有如下:dashDot’,‘dashDotDot’, ‘dashed’,‘dotted’,‘double’,‘hair’, ‘medium’, ‘mediumDashDot’, ‘mediumDashDotDot’,‘mediumDashed’, ‘slantDashDot’, ‘thick’, ‘thin’
cell = sheet.cell(9, 2)
cell.border = Border(
top=Side(style=“thin”, color=“FFB6C1”),
bottom=Side(style=“dashed”, color=“FFB6C1”),
left=Side(style=“dashed”, color=“FFB6C1”),
right=Side(style=“dashed”, color=“9932CC”),
diagonal=Side(style="thin", color="483D8B"), # 对角线
diagonalUp=True, # 左下 ~ 右上
diagonalDown=True # 左上 ~ 右下
)
wb.save(“p2.xlsx”)
6.字体
cell = sheet.cell(5, 1)
cell.font = Font(name=“微软雅黑”, size=45, color=“ff0000”, underline=“single”)
wb.save(“p2.xlsx”)
7.背景色
cell = sheet.cell(5, 3)
cell.fill = PatternFill(“solid”, fgColor=“99ccff”)
wb.save(“p2.xlsx”)
8.渐变背景色
cell = sheet.cell(5, 5)
cell.fill = GradientFill(“linear”, stop=(“FFFFFF”, “99ccff”, “000000”))
wb.save(“p2.xlsx”)
9.宽高(索引从1开始)
sheet.row_dimensions[1].height = 50
sheet.column_dimensions[“E”].width = 100
wb.save(“p2.xlsx”)
10.合并单元格
sheet.merge_cells(“B2:D8”)
sheet.merge_cells(start_row=15, start_column=3, end_row=18, end_column=8)
wb.save(“p2.xlsx”)
sheet.unmerge_cells(“B2:D8”)
wb.save(“p2.xlsx”)
11.写入公式
sheet = wb.worksheets[3]
sheet[“D1”] = “合计”
sheet[“D2”] = “=B2*C2”
wb.save(“p2.xlsx”)
sheet = wb.worksheets[3]
sheet[“D3”] = “=SUM(B3,C3)”
wb.save(“p2.xlsx”)
12.删除
idx,要删除的索引位置
amount,从索引位置开始要删除的个数(默认为1)
sheet.delete_rows(idx=1, amount=20)
sheet.delete_cols(idx=1, amount=3)
wb.save(“p2.xlsx”)
13.插入
sheet.insert_rows(idx=5, amount=10)
sheet.insert_cols(idx=3, amount=2)
wb.save(“p2.xlsx”)
14.循环写内容
sheet = wb[“Sheet”]
cell_range = sheet[‘A1:C2’]
for row in cell_range:
for cell in row:
cell.value = “xx”
for row in sheet.iter_rows(min_row=5, min_col=1, max_col=7, max_row=10):
for cell in row:
cell.value = “oo”
wb.save(“p2.xlsx”)
15.移动
将H2:J10范围的数据,向右移动15个位置、向上移动1个位置
sheet.move_range(“H2:J10”,rows=-1, cols=15)
wb.save(“p2.xlsx”)
sheet = wb.worksheets[3]
sheet[“D1”] = “合计”
sheet[“D2”] = “=B2*C2”
sheet[“D3”] = “=SUM(B3,C3)”
sheet.move_range(“B1:D3”,cols=10, translate=True) # 自动翻译公式(自动处理公式)
wb.save(“p2.xlsx”)
16.打印区域
sheet.print_area = “A1:D200”
wb.save(“p2.xlsx”)
17.打印时,每个页面的固定表头
sheet.print_title_cols = “A:D”
sheet.print_title_rows = “1:3”
wb.save(“p2.xlsx”)

