基础算法
结巴分词的原理
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的HMM 模型,使用了Viterbi 算法
Word2vec的两种训练目标是什么 其中skip-gram训练的loss function是什么
CBOW和Skip-Gram模型的训练目标:

skip-gram训练的 loss function:
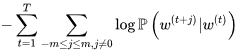
更多细节参考浅谈word2vec。
NER相关
命名实体识别 评价指标 是什么?
命名实体识别 本质有两个任务组成:
1)精确匹配评估

注:其中 #TP 表示识别出的实体且是正确实体的数量(被正确检测的实体), #FP 表示识别出的实体却是不存在实体的数量(被错误检测的实体), #FN 表示是正确的实体却没被识别出的数量(漏检)。当然,除此之外,像macro-f1、micro-f1也会用来作评估。
2)宽松匹配评估
- 特点:降低了匹配正确的要求
- 类别:
- 类别正确:一个实体被正确识别到类别,而边界与正确边界有重叠即可;
- 边界正确:一个实体被正确识别到边界,而不管类别是什么;
介绍下基于深度学习的命名实体识别怎么做
1. 基于深度学习的命名实体识别方法 相比于 基于机器学习的命名实体识别方法的优点?
- 受益于深度学习的非线性转换,可以从数据中学到更复杂的特征;
- 避免大量的人工特征的构建;
- 可以设计为端到端的结构。
2 基于深度学习的命名实体识别方法 的 结构是怎么样?
- 介绍:基于深度学习的命名实体识别方法 由 分布式输入层、文本编码器、解码层 组成;

3 分布式输入层 是什么,有哪些方法?
- 介绍:将 句子 转化为 词粒度、字符粒度、混合的表示方法作为模型输入;
- 类别:
-
词粒度的表示:像word2vec、fasttext、glove或者SENNA等算法可以通过大规模的无监督语料学习词粒度的表示,作为NER模型的输入,在训练过程中既可以固定不变也可以微调。
-
字符粒度的表示:除了仅考虑词向量作为输入之外,也融合了字符粒度的表示作为模型的输入。字符级别的表示,相对于词向量,能够提取出子词的特征,比如前缀后缀等,也能够缓解oov的问题。如下图所示,最常用的两种提取结构分别基于CNN与RNN模型。
-
混合表示:除了词粒度和字符粒度的表示之外,还融合了一些额外信息,比如地点信息、词汇相似度、视觉信息等等。像FLAT、BERT、XLNET等模型也被本文划分为混合表示,因为输入的时候还包含有位置等信息。
介绍下 BiLSTM-CRF?
1. 什么是 BiLSTM-CRF?网络结构?

- step 1:利用 字粒度表示层 将 句子中每个字 编码成一个字向量;
- step 2:然后利用 BiLSTM 编码层 对句子中每个字的字向量,以捕获 句子中每个字的信息;
- step 3:在 BiLSTM 后接一个 CRF 解码层,对 编码的向量进行解码,以解码出 句子最优的标注序列;
2. 为什么要用 BiLSTM?
由于 BiLSTM 能够捕获句子的长距离依赖信息。
介绍下标签解码器有哪些,优缺点?
1. 标签解码器是什么?
标签解码器是NER模型的最后一个阶段。它接受上下文相关的表示作为输入,并基于输入产生相关的序列标签。
2 MLP+softmax层 介绍?
- 介绍:使用多层感知器+Softmax层作为标签解码器层,则将序列标注任务转化为一个多分类问题。每个单词的标签都是根据上下文相关的表示独立预测的,而不考虑它的邻居标签结果。
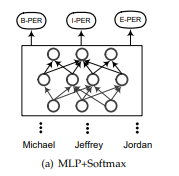
3. 条件随机场CRF层 介绍?
- 介绍:使用一个以观测序列为全局条件的随机场。CRF已被广泛应用于基于特征的监督学习方法。许多基于深度学习的NER模型使用CRF层作为标签解码器,并取得了很好的精度。
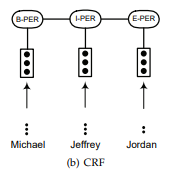
4. 循环神经网络RNN层 介绍?
- 介绍:RNN解码是个贪婪的过程,先计算出第一个位置的标签,然后后面每一个位置的标签都是基于前面的状态计算出标签,在标签数量比较多的时候,可以比CRF更加快速。
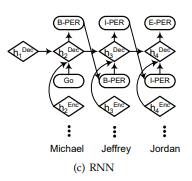
5. 指针网路层 介绍?
- 介绍:将序列标注问题转化为两个子问题:先分块再分类。指针网络会贪婪地从头开始找下一个块结束的位置(开始的位置很显然,第一个块的开始位置是起始点,后面的开始位置都是前面一块的结束位置的后继位置)如上图d所示,在起始块"<\s>“后一块的结束块位置是"Jordan”,这样就得到块"Michael Jeffrey Jordan",然后将这个块进行分类确定类别,之后再继续找下一个块的结束位置,找到"was",这样就得到一个新的块"was",再将这个块进行分类,然后这样循环下去直到序列结束。指针网络主要就起到确定块起始位置的作用(通过预测该位置是实体起始位置的概率来确定)。

对比CNN-CRF vs BiLSTM-CRF vs IDCNN-CRF?
- CNN-CRF:对于序列标注来讲,普通CNN有一个不足,就是卷积之后,末层神经元可能只是得到了原始输入数据中一小块的信息。而对NER来讲,整个输入句子中每个字都有可能对当前位置的标注产生影响,即所谓的长距离依赖问题。为了覆盖到全部的输入信息就需要加入更多的卷积层,导致层数越来越深,参数越来越多。而为了防止过拟合又要加入更多的Dropout之类的正则化,带来更多的超参数,整个模型变得庞大且难以训练。
- BiLSTM-CRF:因为CNN这样的劣势,对于大部分序列标注问题人们还是选择BiLSTM之类的网络结构,尽可能利用网络的记忆力记住全句的信息来对当前字做标注。但这又带来另外一个问题,BiLSTM本质是一个序列模型,在对GPU并行计算的利用上不如CNN那么强大。
- IDCNN-CRF:
- 如何解决 CNN-CRF 问题:通过堆叠不同扩张大小的空洞卷积层,有效扩展输入宽度的大小,使其在仅使用几个空洞卷积层的情况下,学习序列的整个长度信息;
- 如何解决 BiLSTM-CRF 问题:因为 IDCNN 本身是一个 CNN ,所以可以像 CNN 一样进行并行化计算;
为什么 DNN 后面要加 CRF?
- DNN 做 序列标注 的 机制
- 做法:NN 对每个 token 打标签的过程是独立进行的,不能直接利用上文已预测的标签(只能靠隐含状态传递上下文信息),进而导致预测出的标签序列可能无效
- 存在问题:
- CRF 做 序列标注 的 机制
- 方法:CRF是全局范围内统计归一化的条件状态转移概率矩阵,再预测出一条指定的sample的每个token的label
- 介绍:因为CRF的特征函数的存在就是为了对given序列观察学习各种特征(n-gram,窗口),这些特征就是在限定窗口size下的各种词之间的关系。然后一般都会学到这样的一条规律(特征):B后面接E,不会出现B。这个限定特征会使得CRF的预测结果不出现上述例子的错误。
- DNN-CRF
- 做法:把CRF接到LSTM后面,把LSTM在timestep上把每一个hidden state的tensor输入给CRF,进行句子级别的标签预测,使得标注过程中不再是对各个 token 单独分类
NER Trick
词向量选取:词向量 or 字向量?
- 词向量
- 方式:首先对句子进行分词,然后训练 所有词语 的 向量表示,最后利用 这些 词向量 训练模型;
- 优点:
- 缺点:
-
OOV 问题(Out of vocabulary,超出词表外的词);
-
维护成本高;
-
如果分词效果不好,那么词向量的质量 将受影响;
- 字向量
- 方式:首先对句子按字切分,然后训练 所有字的 向量表示,最后利用 这些 字向量 训练模型;
- 优点:
-
解决了 词向量的 OOV 问题;
-
减少人工维护成本;
-
不用分词;
- 在训练数据质量较差的时候(比如口语化较多,错别字较多,简称缩写较多等),采用字向量的效果好于词向量;
- 缺点:
- 解决方法:
-
利用 具有 双向 的 特征提取器 能够 缓解 该功能,eg: bilstm、bert 等;
专有名称 怎么 处理?
- 场景:#1机组1A锅炉磨煤机故障,#2机组2C炉磨煤机故障。 实体是磨煤机。
- 方法:在训练ner模型时,可以将一类专业名词改写成一个符号表示
- 具体操作:
- #1机组、#2机组、#3机组…是一类机组名词,可用符号表示;
- 1A锅炉,1A炉,1B炉,1C锅炉…是一类锅炉专业名词,可用符号表示;
- 转化后:
标注数据 不足怎么处理?
- 问题介绍:随着模型的愈发精细复杂,需要训练的参数日益庞大,但其训练所需的人工标注数据却因为标注成本的问题难以得到相应地增长。
- 方法一:远程监督标注数据
- 思路:使用远程监督的方法来得到大量的远程监督标注数据
- 问题:有限覆盖问题(Limited Coverage)。由于用于远程监督的知识库规模有限,大量的实体存在于文本中而未出现在知识库中,导致在远程监督时,将这些未出现在知识库中的实体标注为非实体,从而产生大量的假负例;
- 方法二:优化模型
- 思路:限制参数量,从而使得模型能够在较小的标注数据集上也能够完成训练;
- 方法三:采用主动学习方法
- 思路:
- step 1:先标注一小部分数据,利用这部分标注数据训练模型;
- step 2:利用模型去标注 未标记数据;
- step 3: 利用 查询函数 筛选 信息量最大的数据;(方法:信息熵计算不确定样本法、多模型投票选取争议性最高样本法);
- step 4:由人工进行标注,并加入到 标注数据中,回到 step 1,直到 样本足够大,或者 模型预测值 趋于平衡;
- 优点:
-
减少标注成本。由于 选取的数据 所包含的信息量较高,所以减少数据 标注成本(本人之前做过一个小实验,发现采用主动学习方法筛选出的总样本的30%左右,训练出的命名实体识别模型性能与全量训练效果相近);
-
数据质量高;
- 缺点:
- 如果 查询函数 选取 不对,可能吃力不讨好,也就是 选取的样本存在偏差,比如选到了 离群点。
- 方法四:迁移学习 【这种方法也蛮常见,问题就是风险太高】
- 方法五:预训练+自训练 【Self-training Improves Pre-training for Natural Language Understanding】
- 背景知识:
- 方法:
-
预训练(Pre-training)从广义上来讲,是指先在较大规模的数据上对模型训练一波,然后再在具体的下游任务数据中微调。大多数情况下,预训练的含义都比较狭窄:在大规模无标注语料上,用自监督的方式训练模型。这里的自监督方法一般指的是语言模型;
-
自训练是说有一个Teacher模型Ft和一个Student模型Fs,首先在标注数据上训练Ft,然后用它对大规模无标注数据进行标注,把得到的结果当做伪标注数据去训练Fs。
- 相同点:用到了大规模无标注的数据
- 区别:
- 预训练始终对针对一个模型进行操作,而自训练却用到了两个模型;
- 预训练是直接从无标注数据中学习,而自训练是间接地从数据中学习;
- 思路:
- 将一个预训练模型(本文使用RoBERTa_Large)在标注数据上训练,作为教师模型Ft;
- 使用Ft从海量通用语料中提取相关领域的数据,一般是 抽取出 置信度较高的样本;
- 用Ft对提取的数据作标注;
- 用伪标注语料训练学生模型Fs。
- 方法六:实体词典+BERT相结合
- 利用实体词典+BERT相结合,进行半监督自训练**【注:参考 资料11】 **
嵌套命名实体识别怎么处理
1. 什么是实体嵌套?
实体嵌套是指在一句文本中出现的实体,存在某个较短实体完全包含在另外一个较长实体内部的情况,如“南京市长”中地名“南京”就嵌套在职务名“南京市长”中。
2. 与 传统命名实体识别任务的区别
传统的命名实体识别任务关注的都是平坦实体(Flat entities),即文本中的实体之间不交叉、不嵌套。
3. 解决方法
3.1 方法一:序列标注
-
多标签分类
- 思路:命名实体识别本来属于基于字的多分类问题,嵌套实体需要将其转化为 多标签问题(即每个字有多种标签,如下图所示)
- 问题:
- 学习难度较大
- 容易导致label之间依赖关系的缺失

-
合并标签层
- 思路:采用CRF,但设置多个标签层,对于每一个token给出其所有的label,然后将所有标签层合并
- 问题:
- 指数级增加了标签;
- 对于多层嵌套,稀疏问题较为棘手;

3.2 方法二:指针标注
-
层叠式指针标注
- 思路:设置 C 个指针网络
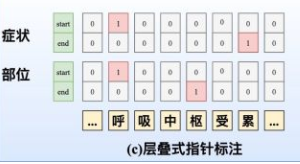
-
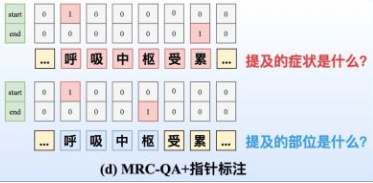
MRC-QA+指针标注
- 思路:构建query问题指代所要抽取的实体类型,同时也引入了先验语义知识,如下图(d)所示。在文献中就对不同实体类型构建query,并采取指针标注,此外也构建了 **1 矩阵来判断span是否构成一个实体mention。
3.3 方法三:多头标注
-
构建 span 矩阵
- 思路:构建一个 ** 的Span矩阵
- 说明:如图,Span{呼}{枢}=1,代表「呼吸中枢」是一个部位实体;Span{呼}{累}=2,代表「呼吸中枢受累」是一个症状实体;
- 问题:
- 如何构造Span矩阵问题
- 如何解决0-1标签稀疏问题

- 嵌套实体的2篇SOTA之作:
- ACL20的《Named Entity Recognition as Dependency Parsing》采取Biaffine机制构造Span矩阵 【注:具体可以参考 资料12】;
- EMNLP20的HIT【 注:具体可以参考 资料13】则通过Biaffine机制专门捕获边界信息,并采取传统的序列标注任务强化嵌套结构的内部信息交互,同时采取focal loss来解决0-1标签不平衡问题。
3.4 方法四:片段排列
十分直接,如下图(f)所示。对于含T个token的文本,理论上共有 = (+1)/2 种片段排列。如果文本过长,会产生大量的负样本,在实际中需要限制span长度并合理削减负样本。

为什么说 「词汇增强」 方法对于中文 NER 任务有效?
- 动机:虽然基于字符的NER系统通常好于基于词汇(经过分词)的方法,但基于字符的NER没有利用词汇信息,而词汇边界对于实体边界通常起着至关重要的作用。
- 目标:如何在基于字符的NER系统中引入词汇信息
- 思路:
- 方法一:设计一个动态框架,能够兼容词汇输入 【注:具体可以参考 资料6-10】
- 方法二:采用多种分词工具和多种句法短语⼯具进行融合来提取候选实体,并结合词典进行NER
NER实体span过长怎么办?
- 动机:如果NER任务中某一类实体span比较长(⽐如医疗NER中的⼿术名称是很长的),直接采取CRF解码可能会导致很多连续的实体span断裂;
- 解决方法:
- 加入规则进行修正
-
引入指针网络+CRF构建多任务学习。指针网络会更容易捕捉较长的span,不过指针网络的收敛是较慢的,可以对CRF和指针网络设置不同学习率,或者设置不同的loss权重。
NER 标注数据噪声问题?
- 动机:NER 标注数据存在噪声问题,导致模型训练效果差
- 方法:
- 方法一:对训练集进行交叉验证,然后人工去清洗这些“脏数据”
- 方法二:将noisy label learning应用于NER任务,惩罚那些噪音大的样本loss权重【注:具体可以参考 资料12】
给定两个命名实体识别任务,一个任务数据量足够,另外一个数据量很少,可以怎么做?
- 动机:NER 标注数据 有些类别 标注数据量 较少;
- 方法:
- 重采样
- loss惩罚
- Dice loss
- 若 该类实体属于 长尾实体(填充率低),可以挖掘相关规则模板、构建词典库
NER 标注数据不均衡问题?
-
迁移学习
- 假设:数据量足够任务为 T1,数据量很少任务为 T2。
- 思路
- 首先在任务T1中训练模型,然后模型利用之前学习任务所得的知识,应用于任务T2。也就是说模型在任务T1学习知识(特征、权重),然后推广这一知识(特征、权重)至任务T2(明显数据更少)。
-
半监督策略,即引入虚拟对抗;
- 思路:随机生成一个扰动,然后进行导数,L2规范化等处理,生成当前所需要的扰动,将其加入到model原始input embedding,再次求损失;模型最终优化loss + loss(带扰动);使得模型鲁棒性更强,准确率更高
Common Trick
交叉验证的目的
Cross Validation:简言之,就是进行多次train_test_split划分;每次划分时,在不同的数据集上进行训练、测试评估,从而得出一个评价结果。
- 从有限的学习数据中获取尽可能多的有效信息;
- 交叉验证从多个方向开始学习样本的,可以有效地避免陷入局部最小值;
- 可以在一定程度上避免过拟合问题;
早停的作用
模型训练过程中,训练 loss 和 验证 loss 在训练初期都是 呈下降趋势;当训练到达一定程度之后, 验证 loss 并非继续随 训练 loss 一样下降,而是 出现上升的趋势,此时,如果继续往下训练,容易出现 模型性能下降问题,也就是我们所说的过拟合问题。
早停法 就是在训练中计算模型在验证集上的表现,当模型在验证集上的表现开始下降的时候,停止训练,这样就能避免模型由于继续训练而导致过拟合的问题。所以说 早停法 结合交叉验证法可以防止模型过拟合。
标签平滑法
标签平滑法是一种正则化策略,主要是通过soft one-hot来加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。推荐阅读:标签平滑Label Smoothing
类别不平衡问题
1. 类别不平衡场景
-
数据均衡场景:
- 方法:准确率(accuracy)
- 前提:“数据是平衡的,正例与反例的重要性一样,二分类器的阈值是0.5。”
-
数据不均衡场景:
- 动机:准确率(accuracy)容易出现迷惑性(eg:正例有99条,负例1条,那么acc = 99%,然而这种结果是没有意义的)
- 主流的评估方法:
- ROC是一种常见的替代方法,全名receiver operating curve,计算ROC曲线下的面积是一种主流方法
- Precision-recall curve和ROC有相似的地方,但定义不同,计算此曲线下的面积也是一种方法
- Precision@n是另一种方法,特制将分类阈值设定得到恰好n个正例时分类器的precision
- Average precision也叫做平均精度,主要描述了precision的一般表现,在异常检测中有时候会用
- 直接使用Precision也是一种想法,但此时的假设是分类器的阈值是0.5,因此意义不大
- 如何选择:至于哪种方法更好,一般来看我们在极端类别不平衡中更在意“少数的类别”,因此ROC不像precision-recall curve那样更具有吸引力。在这种情况下,Precision-recall curve不失为一种好的评估标准,相关的分析可以参考[2]。还有一种做法是,仅分析ROC曲线左边的一小部分,从这个角度看和precision-recall curve有很高的相似性。
注:precision 使用 注意点:
没有特殊情况,不要用准确率(accuracy),一般都没什么帮助
如果使用precision,请注意调整分类阈值,precision@n更有意义
2. 解决类别不平衡中的“奇淫巧技”有什么?
-
SMOTE算法:对数据进行采用的过程中通过相似性同时生成并插样“少数类别数据”,叫做SMOTE算法
-
聚类算法做欠采样:对数据先进行聚类,再将大的簇进行随机欠采样或者小的簇进行数据生成
-
阈值调整(threshold moving),将原本默认为0.5的阈值调整到 较少类别/(较少类别+较多类别)即可
- 介绍:简单的调整阈值,不对数据进行任何处理。此处特指将分类阈值从0.5调整到正例比例
-
无监督学习问题:把监督学习变为无监督学习,舍弃掉标签把问题转化为一个无监督问题,如异常检测
-
集成学习: 先对多数类别进行随机的欠采样,并结合boosting算法进行集成学习
- 重构分类器角度
- 将大类压缩为小类;
- 使用 One Class 分类器(将小类作为异常点);
- 使用集成方式,训练多个分类器,联合这些分类器进行分类;
- 将二分类改为多分类问题;
- 使用其他 Loss 函数
- Focal Loss: 对 CE Loss 增加了一个调制系数来降低容易样本的权值,使其训练过程更加关注困难样本
注:第一种和第二种方法都会明显的改变数据分布,我们的训练数据假设不再是真实数据的无偏表述。在第一种方法中,我们浪费了很多数据。而第二类方法中有无中生有或者重复使用了数据,会导致过拟合的发生。
Warm Up
1. 什么是 Warm up?
Warmup 是在 ResNet 论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些 epoches 或者 steps (比如 4 个 epoches,10000steps),再修改为预先设置的学习来进行训练。
2. 为什么需要 Warm up?
-
在训练的开始阶段,模型权重迅速改变。 刚开始模型对数据的“分布”理解为零,或者是说“均匀分布”(当然这取决于你的初始化);在第一轮训练的时候,每个数据点对模型来说都是新的,模型会很快地进行数据分布修正,如果这时候学习率就很大,极有可能导致开始的时候就对该数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。当训练了一段时间(比如两轮、三轮)后,模型已经对每个数据点看过几遍了,或者说对当前的batch而言有了一些正确的先验,较大的学习率就不那么容易会使模型学偏,所以可以适当调大学习率。这个过程就可以看做是warmup。那么为什么之后还要decay呢?当模型训到一定阶段后(比如十个epoch),模型的分布就已经比较固定了,或者说能学到的新东西就比较少了。如果还沿用较大的学习率,就会破坏这种稳定性,用我们通常的话说,就是已经接近loss的local optimal了,为了靠近这个point,我们就要慢慢来。
-
mini-batch size较小,样本方差较大。第二种情况其实和第一种情况是紧密联系的。在训练的过程中,如果有mini-batch内的数据分布方差特别大,这就会导致模型学习剧烈波动,使其学得的权重很不稳定,这在训练初期最为明显,最后期较为缓解(所以我们要对数据进行scale也是这个道理)。
知识表示
知识表示相对于one-hot表示的优势是什么
1. 知识表示学习的基本概念
知识表示学习的目标是通过机器学习将研究对象的语义信息表示为稠密低维实值向量。以知识库中的实体
e
e
e和关系
r
r
r为例,我们将学校得到的模型表示为
l
e
l_e
le 和
l
r
l_r
lr。在该向量空间中,我们可以通过欧氏距离或余弦距离等方式,计算任意两个对象之间的语义相似度。像我们常说的词向量就属于知识表示学习。
2. 知识表示的理论基础
知识表示学习得到的低维向量表示是一种分布式表示(distributed representation),之所以这么命名,是因为孤立地看向量中的每一维,都没有明确对应的含义;而综合各维形成一个向量,则能够表示对象的语义信息。这种表示方案并非凭空而来,而是受到人脑的工作机制启发而来
3. 知识表示相对于one-hot表示的优势
独热表示的问题在于,需要设计专门的图算法计算实体键的语义和推理关系,计算复杂度高、可扩展性差,同时在大规模语料的建模中,会出现数据稀疏的问题。
而知识表示学习实现了对实体和关系的分布式表示,它具有以下主要优点:
-
显著提升计算效率:知识表示学习得到的分布式表示,则能够高效地实现语义相似度计算等操作,显著提升计算效率。
-
有效缓解数据稀疏:由于表示学习将对象投影到统一的低维空间中,使每个对象均对应一个稠密向量,从而有效缓解数据稀疏问题,这主要体现在2个方面。一方面,每个对象的向量均为稠密有值的,因此可以度量任意对象之间的语义相似程度。**而基于独热表示的图算法,由于受到大规模知识图谱稀疏特性的影响,往往无法有效计算很多对象之间的语义相似度。**另一方面,将大量对象投影到统一空间的过程,也能够将高频对象的语义信息用于帮助低频对象的语义表示,提高低频对象的语义表示准确性。
-
实现异质信息融合:不同来源的异质信息需要融合为整体,才能够得到有效应用。大量实体和关系在不同知识库中的名称不同,如何实现多知识库的有机融合,对知识库应用具有重要意义。如果基于独热表示和网络表示,该任务只能通过设计合理的表示学习模型,将不同来源的对象投影到同一个语义空间中,就能够建立统一的表示空间,实现多知识库的信息融合。此外,当我们在信息检索或自然语言处理中应用知识库时,往往需要计算查询词、句子、文档和知识库实体之间的复杂语义关联。由于这些对象的异质性,计算它们的语义关联往往是棘手问题。而表示学习亦能为异质对象提供统一表示空间,轻而易举实现异质 对象之间的语义关联计算。
有哪些文本表示模型?它们各有什么优缺点?
(1)词袋模型和N-gram模型
最基础的文本表示模型是词袋模型。顾名思义,就是将每篇文章看成一袋子词,并忽略每个词出现的顺序。具体地说,就是将整段文本以词为单位切分开, 然后每篇文章可以表示成一个长向量,向量中的每一维代表一个单词,而该维对应的权重则反映了这个词在原文章中的重要程度。常用TF-IDF来计算权重,公式为
T
F
−
I
D
F
(
t
,
d
)
=
T
F
(
t
,
d
)
×
I
D
F
(
t
)
TF-IDF(t, d) = TF(t, d) \times IDF(t)
TF−IDF(t,d)=TF(t,d)×IDF(t)
其中TF(t,d)为单词t在文档d中出现的频率,IDF(t)是逆文档频率,用来衡量单词t对表达语义所起的重要性,表示为
I
D
F
(
t
)
=
l
o
g
(
文
章
总
数
包
含
单
词
t
的
文
章
总
数
+
1
)
IDF(t) = log(\frac{文章总数}{包含单词t的文章总数+1})
IDF(t)=log(包含单词t的文章总数+1文章总数)
直观的解释是,如果一个单词在非常多的文章里面都出现,那么它可能是一个比较通用的词汇,对于区分某篇文章特殊语义的贡献较小,因此对权重做一定惩罚。
将文章进行单词级别的划分有时候并不是一种好的做法,比如英文中的natural language processing(自然语言处理)一词,如果将natural,language,processing这 3个词拆分开来,所表达的含义与三个词连续出现时大相径庭。通常,可以将连续 出现的n个词(n≤N)组成的词组(N-gram)也作为一个单独的特征放到向量表示 中去,构成N-gram模型。另外,同一个词可能有多种词性变化,却具有相似的含义。在实际应用中,一般会对单词进行词干抽取(Word Stemming)处理,即将不 同词性的单词统一成为同一词干的形式。
(2)主题模型
基于词袋模型或N-gram模型的文本表示模型有一个明显的缺陷,就是无法识别出两个不同的词或词组具有相同的主题。因此,需要一种技术能够将具有相同 主题的词或词组映射到同一维度上去,于是产生了主题模型。主题模型是一种特殊的概率图模型。想象一下我们如何判定两个不同的词具有相同的主题呢?这两个词可能有更高的概率同时出现在同一篇文档中;换句话说,给定某一主题,这 两个词的产生概率都是比较高的,而另一些不太相关的词汇产生的概率则是较低的。假设有K个主题,我们就把任意文章表示成一个K维的主题向量,其中向量的 每一维代表一个主题,权重代表这篇文章属于这个特定主题的概率。主题模型所 解决的事情,就是从文本库中发现有代表性的主题(得到每个主题上面词的分 布),并且计算出每篇文章对应着哪些主题。常见的主题模型有:pLSA(Probabilistic Latent Semantic Analysis),LDA(Latent Dirichlet Allocation)。
(3)词嵌入与深度学习模型
词嵌入是一类将词向量化的模型的统称,核心思想是将每个词都映射成低维 空间(通常K=50~300维)上的一个稠密向量(Dense Vector)。K维空间的每一维也可以看作一个隐含的主题,只不过不像主题模型中的主题那样直观。
由于词嵌入将每个词映射成一个K维的向量,如果一篇文档有N个词,就可以用一个N×K维的矩阵来表示这篇文档,但是这样的表示过于底层。在实际应用中,如果仅仅把这个矩阵作为原文本的表示特征输入到机器学习模型中,通常很 难得到令人满意的结果。因此,还需要在此基础之上加工出更高层的特征。在传统的浅层机器学习模型中,一个好的特征工程往往可以带来算法效果的显著提升。而深度学习模型正好为我们提供了一种自动地进行特征工程的方式,模型中的每个隐层都可以认为对应着不同抽象层次的特征。从这个角度来讲,深度学习模型能够打败浅层模型也就顺理成章了。卷积神经网络和循环神经网络的结构在文本表示中取得了很好的效果,主要是由于它们能够更好地对文本进行建模,抽取出一些高层的语义特征。与全连接的网络结构相比,卷积神经网络和循环神经网络一方面很好地抓住了文本的特性,另一方面又减少了网络中待学习的参数, 提高了训练速度,并且降低了过拟合的风险。
word2vec与LDA模型之间的区别和联系?
- 首先,LDA是利用文档中单词的共现关系来对单词按主题聚类,也可以理解为对“文档-单词”矩阵进行分解,得到“文档-主题”和“主题-单词”两个概率分布。而Word2Vec其实是对“上下文-单词”矩阵进行 学习,其中上下文由周围的几个单词组成,由此得到的词向量表示更多地融入了 上下文共现的特征。也就是说,如果两个单词所对应的Word2Vec向量相似度较高,那么它们很可能经常在同样的上下文中出现。需要说明的是,上述分析的是 LDA与Word2Vec的不同,不应该作为主题模型和词嵌入两类方法的主要差异。主题模型通过一定的结构调整可以基于“上下文-单词”矩阵进行主题推理。同样地,词嵌入方法也可以根据“文档-单词”矩阵学习出词的隐含向量表示。
-
主题模型和词嵌入两类方法最大的不同其实在于模型本身,主题模型是一种基于概率图模型的生成式模型,其似然函数可以写成若干条件概率连乘的形式,其中包括需要推测的隐含变量(即主题);而词嵌入模型一般表达为神经网络的形式,似然函数定义在网络的输出之上,需要通过学习网络的权重以得到单词的稠密向量表示。
介绍下词向量空间中的平移不变现象?
表示学习在自然语言处理领域受到广泛关注起源于Mikolov等人与2013年提出的word2vec词表示学习模型和工具包,利用该模型,Mikolov等人发现词向量空间中的平移不变现象,例如:
C
(
K
I
N
G
)
−
C
(
Q
U
E
E
N
)
≈
C
(
M
A
N
)
−
C
(
W
O
M
A
N
)
C(KING)-C(QUEEN) \approx C(MAN)-C(WOMAN)
C(KING)−C(QUEEN)≈C(MAN)−C(WOMAN)
这里的
c
(
w
)
c(w)
c(w)表示利用word2vec学习得到的单词
w
w
w的词向量。也就是说,词向量能够捕捉到单词KING和QUEEN之间、MAN和WOMAN之间的某种相同的隐含语义关系。Mikolov等人通过类比推理实验【4, 5】发现,这种平移不变现象普遍存在于词汇的语义关系和句法关系中。
简述deepwalk和node2vec模型的思想及其优点
DeepWalk算法借鉴了word2vec算法的思想,word2vec是NLP中一种常用的word embedding方法,word2vec通过语料库中的句子序列来描述词与词的共现关系,进而学习到词语的向量表示。DeepWalk算法与word2vec类似,使用图中节点与节点的共现关系来学习节点的向量表示。在DeepWalk中通过使用随机游走(RandomWalk)的方式在图中进行节点采样来模拟语料库中的语料,进而使用word2vec的方式学习出节点的共现关系。
具体来说,DeepWalk 通过将节点视为单词并生成短随机游走作为句子来弥补网络嵌入和单词嵌入之间的差距。然后,可以将诸如 Skip-gram 之类的神经语言模型应用于这些随机游走以获得网络嵌入。其优点是首先其可以按需生成随机游走。由于 Skip-gram 模型也针对每个样本进行了优化,因此随机游走和 Skip-gram 的组合使 DeepWalk 成为在线算法。其次,DeepWalk 是可扩展的,生成随机游走和优化 Skip-gram 模型的过程都是高效且平凡的并行化。最重要的是,DeepWalk 引入了深度学习图形的范例。
node2vec模型是在DeepWalk的架构上,优化了随机游走的序列抽取策略。node2vec采用有偏随机游走,在广度优先(bfs)和深度优先(dfs)图搜索之间进行权衡,从而产生比DeepWalk更高质量和更多信息量的嵌入。
预训练模型
transformer里面每一层的主要构成有哪些
Transformer本身是一个典型的encoder-decoder模型,Encoder端和Decoder端均有6个Block,Encoder端的Block包括两个模块,多头self-attention模块以及一个前馈神经网络模块;Decoder端的Block包括三个模块,多头self-attention模块,多头Encoder-Decoder attention交互模块,以及一个前馈神经网络模块;需要注意:Encoder端和Decoder端中的每个模块都有残差层和Layer Normalization层。
Bert模型中激活函数GELU
GELU函数是RELU的变种,形式如下:
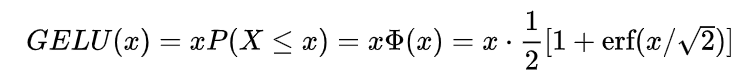
bert的架构是什么 目标是什么 输入包括了什么 三个embedding输入是怎么综合的?
Bert的结构主要是Transformer的encoder部分,其中Bert_base有12层,输出维度为768,参数量为110M,Bert_large有24层,输出维度为1024,参数总量为340M。
Bert的目标是利用大规模无标注语料训练,获得文本包含丰富语义信息的表征。
Bert的输入:token embedding,segment embedding,position embeddimg,三个向量相加作为模型的输入。
bert有什么可以改进的地方
问题:中文BERT是以汉字为单位训练模型的,而单个汉字是不能表达像词语或者短语具有的丰富语义。
改进:ERNIE模型,给模型输入知识实体,在进行mask的时候将某一个实体的汉字全都mask掉,从而让模型学习知识实体。
BERT-WWM:短语级别遮盖(phrase-level masking)训练。
问题:NSP任务会破坏原本词向量的性能。
改进:RoBERTa,移除了NSP任务,同时使用了动态Mask来代替Bert的静态mask。
bert的mask策略
随机mask每一个句子中15%的词,用其上下文来做预测,其中,
80%的是采用[mask],my dog is hairy → my dog is [MASK]
10%的是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
10%的保持不变,my dog is hairy -> my dog is hairy
参考文章