使用MMEditing进行图像超分辨率
安装MMEditing
# 检查PyTorch版本
!pip list | grep torch

# 安装对应版本的mmcv-full
!pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.8.0/index.html
# 源码安装MMEditing(git clone命令)
%cd /content
!rm -rf mmediting
!git clone https://github.com/open-mmlab/mmediting.git
# 用pip安装
%cd mmediting
!pip install -e .

# 检查PytorchCheck Pytorch installation
import torch, torchvision
print(torch.__version__,torch.cuda.is_available())

import mmedit
print(mmedit.__version__)

使用预训练模型完成推理
查找并下载预训练模型
https://mmediting.readthedocs.io/en/latest/
# 下载SRCNN的预训练模型
!test -d checkpoint || mkdir checkpoint
!wget -c https://openmmlab.oos-accelerate.aliyuncs.com/mmediting/restorers/srcnn/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth\
-o ./checkpoint/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth
# 下载样例数据
!rm -rf data
!git clone https://github.com/kckchan-dev/Datasets.git data
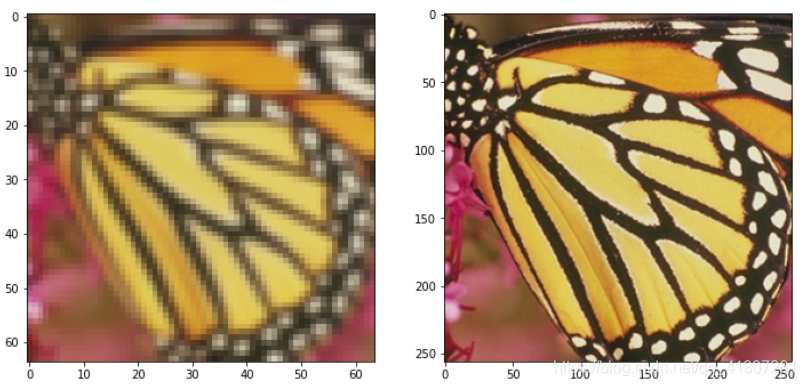
# 展示图像
import matplotlib.pyplot as plt
import mmcv
img_LR = mmcv.imread('./data/Set5/LR/butterfly.png',channel_order='rgb')
img_HR = mmcv.imread('./data/Set5/GT/butterfly.png',channel_order='rgb')
plt.figure(figsize=(12,8))
plt.subplot(1,2,1)
plt.imshow(img_LR)
plt.subplot(1,2,2)
plt.imshow(img_HR)
plt.show()
# 设置配置文件和与训练模型的路径
config_file = 'configs/restorers/srcnn/srcnn_x4k915_g1_1000k_div2k.py'
checkpoint_file = 'checkpoint/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth'
调用API构建模型
# 调用init_model初始化模型
from mmedit.apis import init_model
model = init_model(config_file,checkpoint_file,device='cuda:0')
# 展示model
model


SRCNN 双三次插值上采样 三层卷积 L1损失
调用API进行推理
调用restoration_inference推理
from mmedit.apis import restoration_inference
result = restoration_inference(model, 'data/Set5/LR/butterfly.png')
result

pytorch的tensor 四维
result = torch.clamp(result,0,1) # 像素值在0,1之间,用clamp进行截断,把小于1的置为0,大于1的置为1
img_SR = result.squeeze(0).permute(1,2,0).numpy()# (n,c,h,w)去掉n这一维度,把(c,h,w)转换为(h,w,c),再转换为numpy数组
分析图像恢复效果
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(15,12))
ax1 = fig.add_subplot(1,3,1)
plt.title('LR',fontsize=16)
ax1.axis('off')
ax2 = fig.add_subplot(1,3,2)
plt.title('SR',fontsize=16)
ax2.axis('off')
ax3 = fig.add_subplot(1,3,3)
plt.title('HR',fontsize=16)
ax3.axis('off')
ax1.imshow(img_LR)
ax2.imshow(img_SR)
ax3.imshow(img_HR)
plt.show()

从结果可以看到,输出仍然有些模糊,事实上是个正常现象
我们使用的数据再降采样前有高斯模糊滤波,
但预训练模型在训练时所使用的数据没有加入高斯模糊,
训练数据与测试数据的失陪产生了上述问题。
使用自定义的数据集微调模型
使用MMEditing完成模型的微调,需要三个步骤:
- 准备训练数据
- 修改配置文件
- 启动训练
准备训练数据
使用MMEditing训练超分辨率模型,需要将数据整理成如下格式:
- 将高分辨率图像和低分辨率图像放置在不同的文件夹下,对应的高低分辨率使用相同的文件名
- 生成一个标注文件(annotation file)是一个文件列表,每行包含高分辨率图像文件名,以及对应的高分辨率图像的分辨率
这里使用DIV2K数据集的一个子集,并在生成低分辨率图像时,使用高斯滤波(样例数据中已经处理好)
# 生成图像列表
import glob
gt_paths = sorted(glob.glob('./data/DIV2K/GT/*.png'))
with open('data/training_ann.txt','w')as f:
for gt_path in gt_paths:
filename = gt_path.split('/')[-1]
line = f'{filename} (480,480,3)\n'# 把图像的分辨率写入文件
f.write(line)
对应修改配置文件
# 加载原始SRCNN的配置文件
from mmcv import Config
cfg = Config.fromfile('configs/restorers/srcnn/srcnn_x4k915_g1_1000k_div2k.py')
print(f'Config:\n{cfg.pretty_text}')
# 原始配置文件基于完整的DIV2K数据集训练,我们需要做出对应修改
from mmcv.runner import set_random_seed
# 指定训练集的目录和标注文件
cfg.data.train.dataset.lq_folder='./data/DIV2K/LR'
cfg.data.train.dataset.gt_folder='./data/DIV2K/GT'
cfg.data.train.dataset.ann_file='./data/training_ann.txt'
# 指定验证集的目录
cfg.data.val.lq_folder='./data/Set5/LR'
cfg.data.val.gt_folder='./data/Set5/GT'
# 指定测试集的目录
cfg.data.test.lq_folder='./data/Set5/LR'
cfg.data.test.gt_folder='./data/Set5/GT'
# 指定预训练模型
cfg.load_from='./checkpoint/srcnn_x4k915_1x16_1000k_div2k_20200608-4186f232.pth'
# 设置工作目录
cfg.work_dir='./tutorial_exps/srcnn'
# 配置batch size
cfg.data.samples_per_gpu=4
cfg.data.workers_per_gpu=0
cfg.data.val_workers_per_gpu=0
# 设置总迭代次数
cfg.total_iters = 200
# 在100次迭代时降低学习率,按步长下降的策略
cfg.lr_config={}
cfg.lr_config.policy='Step'
cfg.lr_config.by_epoch=False
cfg.lr_config.step=[100]
cfg.lr_config.gamma=0.5
# 每20轮进行一次验证,并保存结果
if cfg.evaluation.get('gpu_collect',None):
cfg.evaluation.pop('gpu_collect')
cfg.evaluation.interval=200
cfg.checkpoint_config.interval=200
# 每N轮迭代打印日志
cfg.log_config.interval=40
# 设置种子,结果可重现
cfg.seed=0
set_random_seed(0,deterministic=False)
cfg.gpus=1
print(f'Configs:\n{cfg.pretty_text}')
启动训练
调用对应的Python API启动训练
import os.path as osp
from mmedit.datasets import build_dataset
from mmedit.models import build_model
from mmedit.apis import train_model
from mmcv.runner import init_dist
import mmcv
import os
# 构建数据集
datasets = [build_dataset(cfg.data.train)]
# 构建模型
model = build_model(cfg.model,train_cfg=cfg.train_cfg,test_cfg=cfg.test_cfg)
# 创建工作路径
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
# 额外信息
meta = dict()
if cfg.get('exp_name',None) is None:
cfg['exp_name']=osp.splitext(osp.basename(cfg.work_dir))[0]
meta['exp_name']=cfg.exp_name
meta['mmedit Version']=mmedit.__version__
meta['seed']=0
# 启动训练
train_model(model,datasets,cfg,distributed=False,validate=True,meta=meta)

PSNR和SSIM是像素级别的评估标准,可以看到在训练过程中,Loss下降,两个指标增加,符合预期
使用微调后的模型完成推理
微调模型存储在工作目录下,微调后的模型的恢复效果有所好转
from mmedit.apis import init_model
from mmedit.apis import restoration_inference
model = init_model(config_file, F'{cfg.work_dir}/latest.pth', device='cuda:0')
result = restoration_inference(model,'data/Set5/LR/butterfly.png')
result = torch.clamp(result,0,1)
img_SR_ft = result.squeeze(0).permute(1,2,0).numpy()
# 比较低分辨率超分辨率和高分辨率的结果
fig=plt.figure(figsize=(15,12))
ax1 = fig.add_subplot(1,3,1)
plt.title('Before finetune',fontsize=16)
ax1.axis('off')
ax2 = fig.add_subplot(1,3,2)
plt.title('After finetune',fontsize=16)
ax2.axis('off')
ax3 = fig.add_subplot(1,3,3)
plt.title('HR image',fontsize=16)
ax3.axis('off')
ax1.imshow(img_SR)
ax2.imshow(img_SR_ft)
ax3.imshow(img_HR)
plt.show()
