k8s 系列之 CoreDNS
CoreDNS工作原理
kuberntes 中的 pod 基于 service 域名解析后,再负载均衡分发到 service 后端的各个 pod 服务中,如果没有 DNS 解析,则无法查到各个服务对应的 service 服务
在 Kubernetes 中,服务发现有几种方式:
基于环境变量的方式
基于内部域名的方式
从 K8S 1.11 开始,K8S 已经使用 CoreDNS,替换 KubeDNS 来充当其 DNS 解析, DNS 如何解析,依赖容器内 resolv 文件的配置
# cat /etc/resolv.conf
nameserver 10.200.254.254
search default.svc.cluster.local. svc.cluster.local. cluster.local.
options ndots:5
ndots:5:如果查询的域名包含的点 “.” 不到 5 个,那么进行 DNS 查找,将使用非完全限定名称(或者叫绝对域名),如果你查询的域名包含点数大于等于 5,那么 DNS 查询,默认会使用绝对域名进行查询。
Kubernetes 域名的全称,必须是 service-name.namespace.svc.cluster.local 这种模式,服务名
# nslookup kubernetes.default.svc.cluster.local
Server: 10.200.254.254
Address: 10.200.254.254:53
Name: kubernetes.default.svc.cluster.local
Address: 10.200.0.1
DNS策略,在Pod,Deployment RC等资源设置 dnsPolicy
None
用于想要自定义 DNS 配置的场景,而且需要和 dnsConfig 配合一起使用
Default
让 kubelet 来决定使用何种 DNS 策略。而 kubelet 默认使用宿主机的 /etc/resolv.conf(使用宿主机的DNS策略)
但 kubelet 可以配置使用什么文件来进行 DNS 策略,使用 kubelet 的参数:–resolv-conf=/etc/resolv.conf 来决定 DNS 解析文件地址
ClusterFirst
表示 POD 内的 DNS 使用集群中配置的 DNS 服务,使用 Kubernetes 中 kubedns 或 coredns 服务进行域名解析。如果解析不成功,才会使用宿主机的 DNS 进行解析
ClusterFirstWithHostNet
POD 是用 HOST 模式启动的(HOST模式),用 HOST 模式表示 POD 中的所有容器,都使用宿主机的 /etc/resolv.conf 进行 DNS 查询,但如果使用了 HOST 模式,还继续使用 Kubernetes 的 DNS 服务,那就将 dnsPolicy 设置为 ClusterFirstWithHostNet
配置文件使用 configmap
health:CoreDNS 健康检查为 http://$IP:8080/health,返回为 OK
kubernetes:CoreDNS 将根据 Kubernetes 服务和 pod 的 IP 回复 DNS 查询
prometheus:CoreDNS 度量 http://$IP:9153/metrics
proxy:不在 Kubernetes 集群域内的查询都将转发到预定义的解析器(/etc/resolv.conf),可以配置多个upstream 域名服务器,也可以用于延迟查找 /etc/resolv.conf 中定义的域名服务器
cache:启用缓存,30 秒 TTL
loop:检测简单的转发循环,如果找到循环则停止 CoreDNS 进程
reload:允许自动重新加载已更改的 Corefile
loadbalance:DNS 负载均衡器,默认round_robin
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: namespace-test
data:
Corefile: |
.:53 {
errors
health
ready
kubernetes cluster.local 10.200.0.0/16 {
pods insecure
upstream 114.114.114.114
fallthrough in-addr.arpa ip6.arpa
namespaces namespace-test
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
Coredns 规定协议
当前 CoreDNS 接受4种协议: DNS, DNS over TLS (DoT), DNS over HTTP/2 (DoH)
and DNS over gRPC。可以通过在服务器配置文件,在zone 前加个前缀来指定服务器接收哪种协议。
dns:// for plain DNS (the default if no scheme is specified).
tls:// for DNS over TLS, see RFC 7858.
https:// for DNS over HTTPS, see RFC 8484.
grpc:// for DNS over gRPC.
UDP非标准端口只在某些地区某些运营商有用,DoT,即DNS over TLS,支持DoT的公共DNS服务有Quad9的9.9.9.9,Google的8.8.8.8以及Cloudflare的1.1.1.1,可以这么使用:
.:5301 {
forward . tls://9.9.9.9 {
tls_servername dns.quad9.net
}
cache
}
.:5302 {
forward . tls://1.1.1.1 tls://1.0.0.1 {
tls_servername 1dot1dot1dot1.cloudflare-dns.com
}
cache
}
.:5303 {
forward . tls://8.8.8.8 tls://8.8.4.4 {
tls_servername dns.google
}
cache
}
由于proxy插件新版本已经移除,作为external plugin,需要自己编译CoreDNS。
git clone https://github.com/coredns/coredns.git
cd coredns
make
CoreDNS使用了go modules机制,所以在make过程中会自动下载依赖的package。可以通过HTTP_PROXY环境变量指定,或者使用国内的一些镜像(如果你信得过的话)通过GOPROXY环境变量指定。
则在make前,要修改plugin.cfg文件,加入以下:
proxy:github.com/coredns/proxy
再make,就会把插件编译进去。如果发现没有编译进去,可以先执行一下go generate coredns.go再make
coredns 安装部署
下载:https://github.com/coredns/deployment/tree/master/kubernetes
deploy.sh 用于生成用于 kube-dns 的集群上运行 CoreDNS 的 yaml 文件
coredns.yaml.sed 文件作为模板,它创建一个 ConfigMap 和一个 CoreDNS deployment 的yaml 文件
./deploy.sh 172.18.0.0/24 cluster.local 生成 yaml 文件,在使用 kubectl apply 部署在 k8s 中
官方性能
计算表达式: MB required (default settings) = (Pods + Services) / 1000 + 54
cache 需要 30 MB,大约缓存 10000 条记录
操作 buffer 需要 5 MB,用于处理查询,大约可以承受 30 K QPS 量
CoreDNS 的性能优化
概述
CoreDNS 作为 Kubernetes 集群的域名解析组件,如果性能不够可能会影响业务,本文介绍几种 CoreDNS 的性能优化手段。
合理控制 CoreDNS 副本数
考虑以下几种方式:
根据集群规模预估 coredns 需要的副本数,直接调整 coredns deployment 的副本数:
kubectl -n kube-system scale --replicas=10 deployment/coredns
为 coredns 定义 HPA 自动扩缩容。
安装 cluster-proportional-autoscaler 以实现更精确的扩缩容(推荐)。
禁用 ipv6
如果 K8S 节点没有禁用 IPV6 的话,容器内进程请求 coredns 时的默认行为是同时发起 IPV4 和 IPV6 解析,而通常我们只需要用到 IPV4,当容器请求某个域名时,coredns 解析不到 IPV6 记录,就会 forward 到 upstream 去解析,如果到 upstream 需要经过较长时间(比如跨公网,跨机房专线),就会拖慢整个解析流程的速度,业务层面就会感知 DNS 解析慢。
CoreDNS 有一个 template 的插件,可以用它来禁用 IPV6 的解析,只需要给 CoreDNS 加上如下的配置:
template ANY AAAA {
rcode NXDOMAIN
}
这个配置的含义是:给所有 IPV6 的解析请求都响应空记录,即无此域名的 IPV6 记录。
优化 ndots
默认情况下,Kubernetes 集群中的域名解析往往需要经过多次请求才能解析到。查看 pod 内 的 /etc/resolv.conf 可以知道 ndots 选项默认为 5:
意思是: 如果域名中 . 的数量小于 5,就依次遍历 search 中的后缀并拼接上进行 DNS 查询。
举个例子,在 debug 命名空间查询 kubernetes.default.svc.cluster.local 这个 service:
域名中有 4 个 .,小于 5,尝试拼接上第一个 search 进行查询,即 kubernetes.default.svc.cluster.local.debug.svc.cluster.local,查不到该域名。
继续尝试 kubernetes.default.svc.cluster.local.svc.cluster.local,查不到该域名。
继续尝试 kubernetes.default.svc.cluster.local.cluster.local,仍然查不到该域名。
尝试不加后缀,即 kubernetes.default.svc.cluster.local,查询成功,返回响应的 ClusterIP。
可以看到一个简单的 service 域名解析需要经过 4 轮解析才能成功,集群中充斥着大量无用的 DNS 请求。
怎么办呢?我们可以设置较小的 ndots,在 Pod 的 dnsConfig 中可以设置:
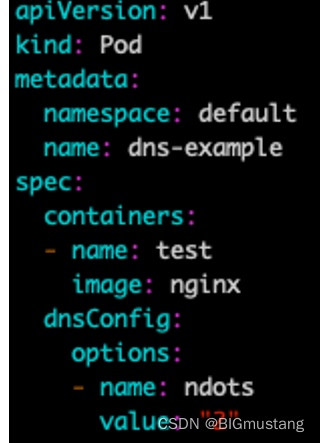
然后业务发请求时尽量将 service 域名拼完整,这样就不会经过 search 拼接造成大量多余的 DNS 请求。
不过这样会比较麻烦,有没有更好的办法呢?有的!请看下面的 autopath 方式。
启用 autopath
启用 CoreDNS 的 autopath 插件可以避免每次域名解析经过多次请求才能解析到,原理是 CoreDNS 智能识别拼接过 search 的 DNS 解析,直接响应 CNAME 并附上相应的 ClusterIP,一步到位,可以极大减少集群内 DNS 请求数量。
启用方法是修改 CoreDNS 配置:
kubectl -n kube-system edit configmap coredns
修改红框中圈出来的配置:
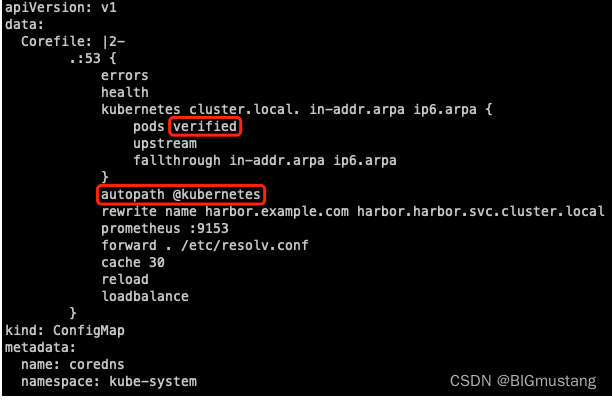
加上 autopath @kubernetes。
默认的 pods insecure 改成 pods verified。
需要注意的是,启用 autopath 后,由于 coredns 需要 watch 所有的 pod,会增加 coredns 的内存消耗,根据情况适当调节 coredns 的 memory request 和 limit。
CoreDNS 的排障
报错:***********************dns: overflowing header size

此时需修改参数:
#kubectl describe configmap coredns -n kube-system
Name: coredns
Namespace: kube-system
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","data":{"Corefile":".:53 {\n errors\n health {\n lameduck 5s\n }\n ready\n kubernetes cluster.local...
Data
====
Corefile:
----
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
fallthrough in-addr.arpa ip6.arpa
}
template ANY AAAA {
rcode NXDOMAIN
}
prometheus :9153
forward . /etc/resolv.conf
bufsize 2048 ##调大此参数 或增加此参数
cache 30
loop
reload
loadbalance
}