目录
1、逻辑回归简要介绍
2、statsmodels中实现逻辑回归
3、sklearn实现逻辑回归
3.1 基础案例代码
3.2 样本不平衡问题处理
3.3 LogisticRegression模型参数说明
3.4 模型调优方法
1、逻辑回归简要介绍
逻辑回归是名为“回归”实为分类的一个算法,在金融行业应用广泛,常被用来预测用户是否违约、是否流失等。逻辑回归是通过概率进行分类预测的,其预测区间是0到1的连续值,这与线性回归有相似之处,线形回归预测值是负无穷到正无穷。逻辑回归和线性回归之间的联系通过连接函数来转化。
(1)逻辑回归的预测值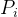 可通过 logit函数,将其映射为取值在负无穷到正无穷数,可表示为如下的线性回归函数:
可通过 logit函数,将其映射为取值在负无穷到正无穷数,可表示为如下的线性回归函数:


(2)线性回归的预测值z 可通过sigmoid函数,将其映射为取值在0到1之间的概率:


逻辑回归的求解和线性回归类似,都是求解参数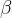 使预测值接近因变量,在求解参数的过程中也需要注意变量选择和多重共线性这两个问题,其中多重共线性在逻辑回归中的影响并不是很大,可根据实际情况考虑是否进行处理。
使预测值接近因变量,在求解参数的过程中也需要注意变量选择和多重共线性这两个问题,其中多重共线性在逻辑回归中的影响并不是很大,可根据实际情况考虑是否进行处理。
2、statsmodels中实现逻辑回归
代码案例付有数据集,可点击进行下载~~~逻辑回归介绍及statsmodels、sklearn实操数据集--accepts.csv-数据挖掘文档类资源-CSDN下载
%matplotlib inline
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.api as sm
import statsmodels.formula.api as smf
accepts = pd.read_csv('./data/accepts.csv')
# axis = 0, 把包含nan值的行删除掉; axis = 1, 把包含nan值的列删除掉
accepts = accepts.dropna(axis = 0, how = 'any')
# 创建测试集和训练集
train = accepts.sample(frac = 0.7, random_state = 101)
test = accepts[~accepts.index.isin(train.index)]
# 逻辑回归建模
formula = 'bad_ind ~ fico_score + bankruptcy_ind + age_oldest_tr + tot_derog + rev_util + ltv + veh_mileage'
lg = smf.glm(formula = formula, data = train
, family = sm.families.Binomial(sm.families.links.logit())).fit()
lg.summary()

可以看到有些参数是不显著的,可以进一步考虑用向前筛选、向后筛选、逐步法等进行变量筛选,在此不在赘述,一般会用sklearn中的LogisticRegression进行更方便的处理。
3、sklearn实现逻辑回归
3.1 基础案例代码
from sklearn.linear_model import LogisticRegression as LR
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_auc_score
X = accepts[['fico_score', 'bankruptcy_ind', 'age_oldest_tr', 'tot_derog', 'rev_util', 'veh_mileage']]
X['bankruptcy_ind'] = [0 if i == 'N' else 1 for i in X['bankruptcy_ind']] # 处理分类变量bankruptcy_ind
Y = accepts['bad_ind']
# 划分训练集与测试
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size = 0.3, random_state = 101)
penalty = ['l1', 'l2'] # 正则化参数
rocaucscore = [] # auc分数
accuracyscore = [] # 准确率
coefs = [] # 参数列表
for i in penalty:
lr = LR(penalty = i, solver = 'saga', C = 0.7, max_iter = 1000).fit(x_train, y_train)
y_pred = lr.predict(x_test)
rocaucscore.append(roc_auc_score(y_test, y_pred))
accuracyscore.append(accuracy_score(y_test, y_pred))
coefs.append(lr.coef_)
print('roc_auc_score', rocaucscore)
print('accuracy_score', accuracyscore)
print('l1 coef {} \nl2 coef {}'.format(*coefs))

3.2 样本不平衡问题处理
该案例中由于样本分布不平衡(目标变量1的数量为786,为0的数量为3319),模型预测较难将正样本预测出来,auc过低,对于样本分布不平衡的数据集,一般先进行上采样,然后再建模。
from imblearn.over_sampling import SMOTE
smo = SMOTE(random_state = 50)
x_train_smo, y_train_smo = smo.fit_resample(x_train, y_train) # smote上采样
print('y_train 中 分布\n', y_train.value_counts())
print('\ny_train_smo 中 分布\n', y_train_smo.value_counts())

接下来再进行建模,看预测指标是否有提升
lr = LR(C = 0.8).fit(x_train_smo, y_train_smo)
y_pred = lr.predict(x_test)
print('accuracy_score', accuracy_score(y_test, y_pred))
print('roc_auc_score', roc_auc_score(y_test, y_pred))

可以看到测试集上auc有所提升。
3.3 LogisticRegression模型参数说明
LogisticRegression参数详解
| 求解器sovler |
liblinear |
lbfgs |
newton-cg |
sag |
saga |
| 求解方式 |
坐标下降法 |
拟牛顿法的一种,利用损失函数二阶导数矩阵(海森矩阵)来迭代优化损失函数 |
牛顿法的一种,利用损失函数二阶导数矩阵(海森矩阵)来迭代优化损失函数 |
随机平均梯度下降,与普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度 |
随机平均梯度下降的进化,稀疏多项逻辑回归的首选 |
| 支持的惩罚项 penalty |
L1, L2 |
L2 |
L2 |
L2 |
L1,L2 |
| L1正则化能将系数收缩为0,而L2只能将系数无限接近于0 |
| 惩罚项 C |
C越小,惩罚力度越强 |
| 求解器收敛的最大迭代次数max_iter |
默认为100,仅适用于newton-cg,sag,lbfgs求解器。过小会错过最优解,过大计算会变大。 |
| 回归类型multi_class |
ovr 二分类 auto |
ovr 一对多 multinomial 多对多 auto |
| 求解器效果 |
|
在大型数据集上运行更快 |
| 对未标准化的数据集很有用 |
|
3.4 模型调优方法
模型调优一般会通过画学习曲线的方式进行,以正则化参数C的调优为例,可通过模型在测试集上的交叉验证结果来,也可以通过训练集和测试集上的auc等指标趋势来进行判断,如下为参考代码
c = np.arange(0.05, 1, 0.05) # 参数C的搜索范围
accu_score_test = [] # 测试集上的准确率得分
auc_score_test = [] # 测试集上的auc得分
accu_score_train = [] # 训练集上的准确率得分
auc_score_train = [] # 训练集上的auc得分
cross_value_scores = [] # 交叉验证结果
for i in c:
# 创建分类器
lr = LR(C = i, max_iter = 1000, solver = 'liblinear', penalty = 'l2')
# 交叉验证结果, 这里通过scoring参数指定交叉验证结果为auc
cross_value_scores.append(cross_val_score(lr
, x_train_smo, y_train_smo
, cv = 5
, scoring = 'roc_auc').mean())
lr = lr.fit(x_train_smo, y_train_smo)
y_pred = lr.predict(x_test)
y_pred_train = lr.predict(x_train_smo)
accu_score_train.append(accuracy_score(y_train_smo, y_pred_train)) # 训练集上的准确率
auc_score_train.append(roc_auc_score(y_train_smo, y_pred_train)) # 训练集上的auc
accu_score_test.append(accuracy_score(y_test, y_pred)) # 测试集上的准确率
auc_score_test.append(roc_auc_score(y_test, y_pred)) # 测试集上的auc
fig = plt.figure(figsize = (16, 12))
ax0 = fig.add_subplot(211)
ax0.plot(c, cross_value_scores)
ax0.set_title('auc score of cross value validition')
ax1 = fig.add_subplot(223)
ax1.plot(c, accu_score_test, label = 'accu_score_test', color = 'darkorange')
ax1.plot(c, accu_score_train, label = 'accu_score_train', color = 'royalblue')
ax1.set_title('accu_score of train and test')
ax1.legend()
ax2 = fig.add_subplot(224)
ax2.plot(c, auc_score_test, label = 'auc_score_test', color = 'darkorange')
ax2.plot(c, auc_score_train, label = 'auc_score_train', color = 'royalblue')
ax2.set_title('auc_score of train and test')
ax2.legend()
