无监督问题,将相似的样本分到一组,难点是如何评估和调参
注意!!!!!!!:对输入数据进行标准化很重要!!!!
it is important to scale the input features.虽然不能保证所有的cluster被聚类的很好,但是通常会改善一些。
一、基本概念
工作原理:
- 选取k个点作为初始的类中心点,这些点一开始都是从数据集中随机抽取的
- 将每个点分配到最近的类中心点,这样就形成了k个类,然后重新计算每个类的中心点
- 重复第二步,直到类不发生变化,或者设置最大迭代数,只要达到最大迭代次数就会结束聚类
质心:centroid,均值,即向量各维取平均值,中心点
距离的度量: 常用欧几里得距离和余弦相似度(要先标准化操作)
优化目标:对所有的K簇进行优化(每个簇里要优化每个样本点x到中心点c的距离越小越好)
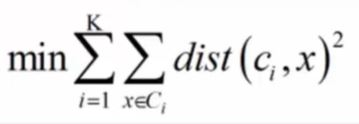
Kmeans算法做出来的分类结果很大程度上由起始centroid决定。如果起始中心点设置不好,最终的结果也只能是局部最优。
二、Centroid Initialization Methods
- 可以试着将大概的各个cluster的中心点,输入到算法中。(比如说之前用了其他的聚类算法得到的中心点)
- 可以多跑几次,使用不同的随机起始中心点。然后选取最优的。在sklearn中由
n_init控制
如何衡量聚类结果是最优的呢?叫做inertia [ɪˈnɜːrʃə] :mean squared distance between each instance and its closest centroid
通过Kmeans.inertia_ 调用或者Kmeans.score(x) 会得到负的inertia值(great is better)
- 通常初始中心点生成使用 K-Means++ 方法。不需要改成random。
三、Mini-Batch K-Means
K-Means算法在Sklearn中默认采用accelerated K-Means:避免不必要地距离计算
如果要用最原始地K-Means算法可以将 algorithm参数调成'full'
Mini-batch:
不用所有的数据集进行迭代,而是使用小批量的数据。每轮使用小批量数据迭代后,centroid只移动一点点
from sklearn.cluster import MiniBatchKMeans
minibatch_kmeans = MiniBatchKMeans(n_clusters=5)
minibatch_kmeans.fit(X)
Mini-Batch 比原版的运算更快,但inertia(一种聚类的评估指标)会更差一些,尤其当clusters增多时

四、找寻最优的聚类数量
4.1 拐点
一般来说我们并不知道有多少个聚类K。如果只用inertia单纯的衡量聚类的好坏,是不够的!!
因为随着K聚类的不断地增加,inertia必定减少
The inertia is not a good performance metric when trying to choose k since it keeps getting lower as we increase k. Indeed, the more clusters there are, the closer each instance will be to its closest centroid, and therefore the lower the inertia will be.

可以看出k=4 是一个拐点,尽管k=5是最优解,但很靠近了。拐点左边的K值没必要在测试了,可以测拐点右边的K值。(这个方法来选择最优的K值是很粗糙的)
4.2 silhouette score 轮廓分数
[ˌsɪluˈet]
silhouette score = (b – a) / max(a, b)
ai:计算样本i到同簇其他样本的平均距离。ai越小,说明样本i越应该被聚类到该簇。将ai称为样本i的簇内不相似度
bi: 计算样本i到其他簇的所有样本的平均距离,bi是这些平均距离中的最小值!!!bi =min{b1, b2, bik}

s值越接近1越好,取值是[-1,1] ,接近于0,说明此时的样本靠近聚类边界,-1说明很可能被分错了
from sklearn.metrics import silhouette_score
silhouette_score(X, kmeans.labels_)
一种更具有信息的可视化方法是,将每个样本的silhouette 系数画出来,并按照所分配的cluster进行排序

红色的虚线代表所有cluster的silhouette score的平均值,当在一个cluster中的大部分样本的silhouette score低于这个红线值时,那么这个cluster聚类是相当差的,这意味着它的样本要更接近于其他的cluster。
上图可以看出当k=3和k=6时,有坏的cluster。
k=4,和k=5时的cluster看起来不错:大部分的样本silhouette score超过了红线。
然而仔细看k=4时,index=1,那个橙色的cluster里有更多的样本,显得很粗,而k=5的各个簇的样本数量看上去更平均。所以尽管总体silhouette score,k=4要超过k=5,我们更愿意选择k=5.
https://blog.csdn.net/sinat_29957455/article/details/80113972
五、Kmeans的优缺点
优点是:简单,运算速度快和可扩展,适合常规数据集,然而K-means并不是完美的。
缺点:K值很难确定!它必须跑很多次来避免局部最优。复杂度与样本数量呈线性关系
而且当clusters的形状很怪异时,各个cluster的大小不一时,密度不同时,K-Means的效果并不好。如果初始值中心点生成不好,结果会很差!
六、利用Kmeans做preprocessing
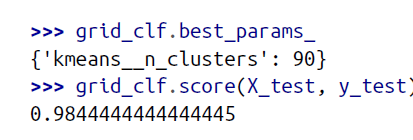
在特征工程时加入一列Kmeans聚类得来的聚类标签,利用GridSearchCV找到最优的K值,来看看通过Kmean聚类后是否会比原始的数据更好
from sklearn.model_selection import GridSearchCV
param_grid = dict(kmeans__n_clusters=range(2, 100))
grid_clf = GridSearchCV(pipeline, param_grid, cv=3, verbose=2)
grid_clf.fit(X_train, y_train)
七、利用K-Means进行图像压缩。
对数据分析无用,可以省略,在网易云课堂里有教。
八、代码
8.1 聚类
#标准化,要尝试min-max和zscore两种
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data_zscore = scaler.fit_transform(data)
#from sklearn.preprocessing import MinMaxScaler
#minmax = MinMaxScaler()
#data_minmax = minmax.fit_transform(data)
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3,random_state=0)
kmeans.fit(data_zscore)
cluster_labels = kmeans.predict(data_zscore)
#将得到的聚类标签粘到原数据上
data['Cluster'] = cluster_labels
8.2 inertia拐点评估聚类的好坏
#https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
#用来存放设置不同簇数时的SSE值
distortions = []
for i in range(1,8):
km = KMeans(n_clusters=i,init="k-means++",n_init=10,max_iter=300,tol=1e-4,random_state=0)
km.fit(data_zscore)
#获取K-means算法的SSE
distortions.append(km.inertia_)
#绘制曲线
plt.plot(range(1,8),distortions,marker="o")
plt.xlabel("Number of Cluster")
plt.ylabel("Inertia(SSE)")
plt.show()

8.3 轮廓曲线判断聚类的好坏
kmeans = KMeans(n_clusters=2,init="k-means++",n_init=10,max_iter=300,tol=1e-4,random_state=0)
from sklearn.metrics import silhouette_samples
cluster_label = kmeans.fit_predict(data_zscore) #获取每个样本的cluster标签
from matplotlib import cm
#获取簇的标号
unique_label = np.unique(cluster_label)
#获取簇的个数
n_clusters = unique_label.shape[0]
#基于欧式距离计算轮廓系数
silhoutte_vals = silhouette_samples(data_zscore,cluster_label,metric="euclidean")
y_ax_lower,y_ax_upper=0,0
yticks=[]
for i,c in enumerate(unique_label):
#获取不同簇的轮廓系数
c_silhouette_vals = silhoutte_vals[cluster_label == c]
#对簇中样本的轮廓系数由小到大进行排序
c_silhouette_vals.sort()
#获取到簇中轮廓系数的个数
y_ax_upper += len(c_silhouette_vals)
#获取不同颜色
color = cm.jet(i / n_clusters)
#绘制水平直方图
plt.barh(range(y_ax_lower,y_ax_upper),c_silhouette_vals,height=1.0,edgecolor="none",color=color)
#获取显示y轴刻度的位置
yticks.append((y_ax_lower+y_ax_upper) / 2)
#下一个y轴的起点位置
y_ax_lower += len(c_silhouette_vals)
#获取轮廓系数的平均值
silhouette_avg = np.mean(silhoutte_vals)
#绘制一条平行y轴的轮廓系数平均值的虚线
plt.axvline(silhouette_avg,color="red",linestyle="--")
#设置y轴显示的刻度
plt.yticks(yticks,cluster_labels+1)
plt.ylabel("Cluster")
plt.xlabel("Silhouette Score")
plt.show()
