1.1Tensor
Tensor,又名张量,读者可能对这个名词似曾相识,因它不仅在PyTorch中出现过,它也是Theano、TensorFlow、 Torch和MxNet中重要的数据结构。关于张量的本质不乏深度的剖析,但从工程角度来讲,可简单地认为它就是一个数组,且支持高效的科学计算。它可以是一个数(标量)、一维数组(向量)、二维数组(矩阵)和更高维的数组(高阶数据)。Tensor和Numpy的ndarrays类似,但PyTorch的tensor支持GPU加速。
1.1.1 基础操作
从接口的角度来讲,对tensor的操作可分为两类:
1.torch.function,如torch.save等。
2.另一类是tensor.function,如tensor.view等。
为方便使用,对tensor的大部分操作同时支持这两类接口,如torch.sum (torch.sum(a, b))与tensor.sum (a.sum(b))功能等价。
而从存储的角度来讲,对tensor的操作又可分为两类:
不会修改自身的数据,如 a.add(b), 加法的结果会返回一个新的tensor。
会修改自身的数据,如 a.add_(b), 加法的结果仍存储在a中,a被修改了。
函数名以_结尾的都是inplace方式, 即会修改调用者自己的数据,在实际应用中需加以区分
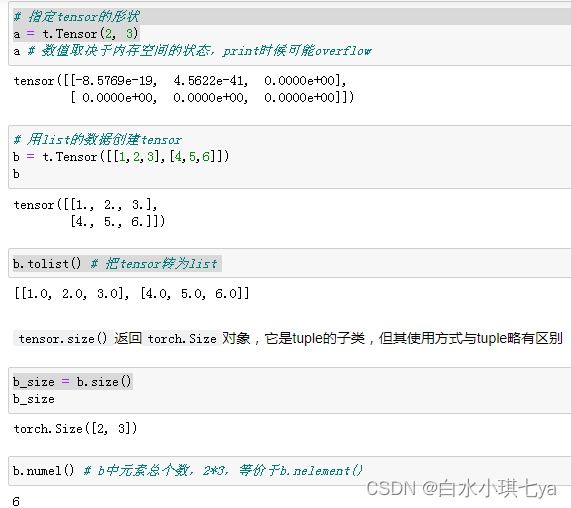
创建tensor
其中使用Tensor函数新建tensor是最复杂多变的方式,它既可以接收一个list,并根据list的数据新建tensor,也能根据指定的形状新建tensor,还能传入其他的tensor
| 函数 |
功能 |
| Tensor(*sizes) |
基础构造函数 |
| tensor(data,) |
类似np.array的构造函数 |
| ones(*sizes) |
全1Tensor |
| zeros(*sizes) |
全0Tensor |
| eye(*sizes) |
对角线为1,其他为0 |
| arange(s,e,step |
从s到e,步长为step |
| linspace(s,e,steps) |
从s到e,均匀切分成steps份 |
| rand/randn(*sizes) |
均匀/标准分布 |
| normal(mean,std)/uniform(from,to) |
正态分布/均匀分布 |
| randperm(m) |
随机排列 |

# 除了tensor.size(),还可以利用tensor.shape直接查看tensor的形状,tensor.shape等价于tensor.size()
c.shape # 输出 torch.Size([2, 3])
常用的创建tensor的方法
t.ones(2, 3)
t.zeros(2, 3)
t.arange(1, 6, 2)
t.linspace(1, 10, 3)
t.randn(2, 3, device=t.device('cpu'))
t.randperm(5) # 长度为5的随机排列
t.eye(2, 3, dtype=t.int) # 对角线为1, 不要求行列数一致




常见tensor操作
通过tensor.view方法可以调整tensor的形状,但必须保证调整前后元素总数一致。view不会修改自身的数据,返回的新tensor与源tensor共享内存,也即更改其中的一个,另外一个也会跟着改变。在实际应用中可能经常需要添加或减少某一维度,这时候squeeze和unsqueeze两个函数就派上用场了。


resize是另一种可用来调整size的方法,但与view不同,它可以修改tensor的大小。如果新大小超过了原大小,会自动分配新的内存空间,而如果新大小小于原大小,则之前的数据依旧会被保存,看一个例子

索引操作
a = t.randn(3, 4)
a
# 打印出来的a tensor([[ 1.1741, 1.4335, -0.8156, 0.7622],
# [-0.6334, -1.4628, -0.7428, 0.0410],
# [-0.6551, 1.0258, 2.0572, 0.3923]]
a[0] # 第0行(下标从0开始)
a[:, 0] # 第0列
a[0][2] # 第0行第2个元素,等价于a[0, 2]
a[0, -1] # 第0行最后一个元素
a[:2] # 前两行
a[:2, 0:2] # 前两行,第0,1列
a > 1 # 返回一个ByteTensor
# tensor([[1, 1, 0, 0],
# [0, 0, 0, 0],
# [0, 1, 1, 0]], dtype=torch.uint8
a[a>1] # 等价于a.masked_select(a>1)
# 选择结果与原tensor不共享内存空间
# 打印:tensor([1.1741, 1.4335, 1.0258, 2.0572]
常见的选择函数
| 函数 |
功能 |
| index_select(input, dim, index) |
在指定维度dim上选取,比如选取某些行、某些列 |
| masked_select(input, mask) |
例子如上,a[a>0],使用ByteTensor进行选取 |
| non_zero(input) |
非0元素的下标 |
| gather(input, dim, index) |
根据index,在dim维度上选取数据,输出的size与index一样 |
gather是一个比较复杂的操作,对一个2维tensor,输出的每个元素如下:
out[i][j] = input[index[i][j]][j] # dim=0
out[i][j] = input[i][index[i][j]] # dim=1
函数gather的例子


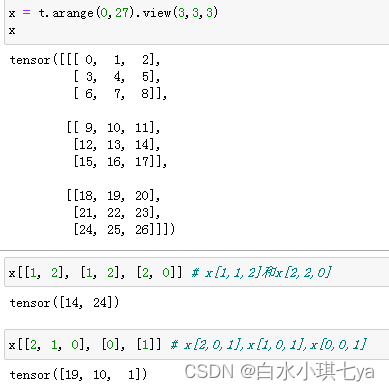
高级索引
高级索引可以看成是普通索引操作的扩展,但是高级索引操作的结果一般不和原始的Tensor共享内存

Tensor类型
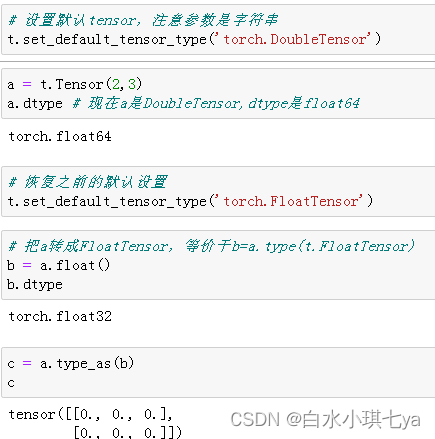
Tensor有不同的数据类型,如表3-3所示,每种类型分别对应有CPU和GPU版本(HalfTensor除外)。默认的tensor是FloatTensor,可通过t.set_default_tensor_type 来修改默认tensor类型(如果默认类型为GPU tensor,则所有操作都将在GPU上进行)。Tensor的类型对分析内存占用很有帮助。例如对于一个size为(1000, 1000, 1000)的FloatTensor,它有100010001000=10^9个元素,每个元素占32bit/8 = 4Byte内存,所以共占大约4GB内存/显存。HalfTensor是专门为GPU版本设计的,同样的元素个数,显存占用只有FloatTensor的一半,所以可以极大缓解GPU显存不足的问题,但由于HalfTensor所能表示的数值大小和精度有限^2,所以可能出现溢出等问题。
| Data type |
dtype |
CPU tensor |
GPU tensor |
| 32-bit floating point |
torch.float32 or torch.float
|
torch.FloatTensor |
torch.cuda.FloatTensor |
| 64-bit floating point |
torch.float64 or torch.double
|
torch.DoubleTensor |
torch.cuda.DoubleTensor |
| 16-bit floating point |
torch.float16 or torch.half
|
torch.HalfTensor |
torch.cuda.HalfTensor |
| 8-bit integer (unsigned) |
torch.uint8 |
torch.ByteTensor |
torch.cuda.ByteTensor |
| 8-bit integer (signed) |
torch.int8 |
torch.CharTensor |
torch.cuda.CharTensor |
| 16-bit integer (signed) |
torch.int16 or torch.short
|
torch.ShortTensor |
torch.cuda.ShortTensor |
| 32-bit integer (signed) |
torch.int32 or torch.int
|
torch.IntTensor |
torch.cuda.IntTensor |
| 64-bit integer (signed) |
torch.int64 or torch.long
|
torch.LongTensor |
torch.cuda.LongTensor |
各数据类型之间可以互相转换,type(new_type)是通用的做法,同时还有float、long、half等快捷方法。CPU tensor与GPU tensor之间的互相转换通过tensor.cuda和tensor.cpu方法实现,此外还可以使用tensor.to(device)。Tensor还有一个new方法,用法与t.Tensor一样,会调用该tensor对应类型的构造函数,生成与当前tensor类型一致的tensor。torch.like(tensora) 可以生成和tensora拥有同样属性(类型,形状,cpu/gpu)的新tensor。 tensor.new(new_shape) 新建一个不同形状的tensor。


逐元素操作
| 函数 |
功能 |
| abs/sqrt/div/exp/fmod/log/pow… |
绝对值/平方根/除法/指数/求余/求幂… |
| cos/sin/asin/atan2/cosh… |
相关三角函数 |
| ceil/round/floor/trunc |
上取整/四舍五入/下取整/只保留整数部分 |
| clamp(input, min, max) |
超过min和max部分截断 |
| sigmod/tanh… |
激活函数 |
例如:a ** 2 等价于torch.pow(a,2), a * 2等价于torch.mul(a,2)
其中clamp(x, min, max)的输出满足以下公式:
y
i
=
{
m
i
n
,
if
x
i
<
m
i
n
x
i
,
if
m
i
n
≤
x
i
≤
m
a
x
m
a
x
,
if
x
i
>
m
a
x
y_i = \begin{cases} min, & \text{if } x_i \lt min \\ x_i, & \text{if } min \le x_i \le max \\ max, & \text{if } x_i \gt max\\ \end{cases}
yi=⎩⎪⎨⎪⎧min,xi,max,if xi<minif min≤xi≤maxif xi>max
clamp常用在某些需要比较大小的地方,如取一个tensor的每个元素与另一个数的较大值。

归并操作
| 函数 |
功能 |
| mean/sum/median/mode |
均值/和/中位数/众数 |
| norm/dist |
范数/距离 |
| std/var |
标准差/方差 |
| cumsum/cumprod |
累加/累乘 |
假设输入的形状是(m, n, k)
如果指定dim=0,输出的形状就是(1, n, k)或者(n, k)
如果指定dim=1,输出的形状就是(m, 1, k)或者(m, k)
如果指定dim=2,输出的形状就是(m, n, 1)或者(m, n)
以上大多数函数都有一个参数dim,用来指定这些操作是在哪个维度上执行的。
from __future__ import print_function
import torch as t
t.__version__
b = t.ones(2,3)
b
b.sum(dim=0)#沿着列(y轴)的方向累加
b.sum(dim=1)#沿着行(X轴)的方向累加,不保留一维
b.sum(dim=1,keepdim = True)#沿着行(X轴)的方向累加,保留一维
b.cumsum(dim=1)#沿着行累加
# out
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([2., 2., 2.])
tensor([3., 3.])
tensor([[3.],
[3.]]
tensor([[1., 2., 3.],
[1., 2., 3.]])
比较
比较函数中有一些是逐元素比较,操作类似于逐元素操作,还有一些则类似于归并操作。
常用比较函数
| 函数 |
功能 |
| gt/lt/ge/le/eq/ne |
大于/小于/大于等于/小于等于/等于/不等 |
| topk |
最大的k个数 |
| sort |
排序 |
| max/min |
比较两个tensor最大最小值 |
表中第一行的比较操作已经实现了运算符重载,因此可以使用a>=b、a>b、a!=b、a==b,其返回结果是一个
- t.max(tensor):返回tensor中最大的一个数
- t.max(tensor,dim):指定维上最大的数,返回tensor和下标
- t.max(tensor1, tensor2): 比较两个tensor相比较大的元素


线性代数
| 函数 |
功能 |
| trace |
对角线元素之和(矩阵的迹) |
| diag |
对角线元素 |
| triu/tril |
矩阵的上三角/下三角,可指定偏移量 |
| mm/bmm |
矩阵乘法,batch的矩阵乘法 |
| addmm/addbmm/addmv/addr/badbmm… |
矩阵运算 |
| t |
转置 |
| dot/cross |
内积/外积 |
| inverse |
求逆矩阵 |
| svd |
奇异值分解 |
b = a.t()
b.is_contiguous()
#out
False
# 因为矩阵的转置会导致存储空间不连续,需要调用它的contiguous方法将其转为连续
b.contiguous()
# out
tensor([[ 0., 9.],
[ 3., 12.],
[ 6., 15.]])