距离比赛结束已经过去两个多月了。
整个过程还是非常辛苦的,在前期整个团队都在进行学习铺垫,精力主要集中在全部数据给出后的建模
收到了答辩的通知,可惜评委问的问题太过离谱,没能展现出我们的创新点,最终没能获得特等奖,是个国一
因为感觉对我们的工作进行一个总结,对很多准备相关比赛的同学还是挺有帮助的,所以还是复盘一下
用Prophet一个个商品预测肯定是错误的,训练时间太长。先整合成结构化数据,再上机器学习才是合理的做法
题目
任务1:数据分析
针对提供的历史销售数据(order_train1.csv),需要进行深入的数据分析。分析主题包括但不限于:
1.1 产品的不同价格对需求量的影响
1.2 产品所在区域对需求量的影响,以及不同区域的产品需求量有何特性
1.3 不同销售方式(线上和线下)的产品需求量的特性
1.4 不同品类之间的产品需求量有何不同点和共同点
1.5 不同时间段(例如月头、月中、月末等)产品需求量有何特性
1.6 节假日对产品需求量的影响
1.7 促销(如618、双十一等)对产品需求量的影响
1.8 季节因素对产品需求量的影响
任务2:需求预测
基于上述分析,需要建立数学模型,对给出的产品(predict_sku1.csv)进行未来3个月(即2019年1月、2月、3月)的月需求量预测。预测结果需要按照给定格式保存为文件result1.xlsx。
请分别按照天、周、月的时间粒度进行预测,并尝试分析不同的预测粒度对预测精度可能产生的影响。
第一问
第一问就是数据探索性分析,没啥好说的,现在会调chatgpt并且进行简单的修改就能做出不错的图了。
虽然题目的意思可能是通过第一问的分析,对第二问的建模起到什么帮助,可能会在论文里看起来不错,但说实话屁用没有。第二问预测靠的还是特征工程等经验。所以第一问不是重点,展示几个图吧,不细讲了。


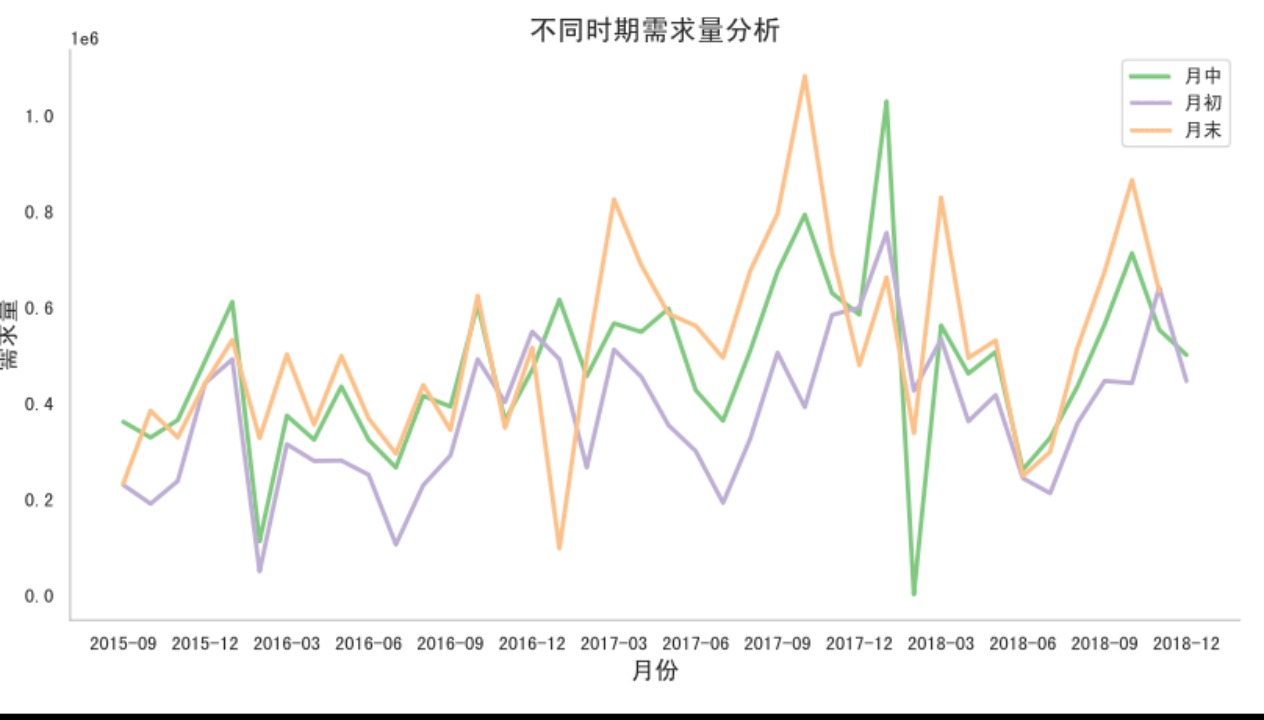

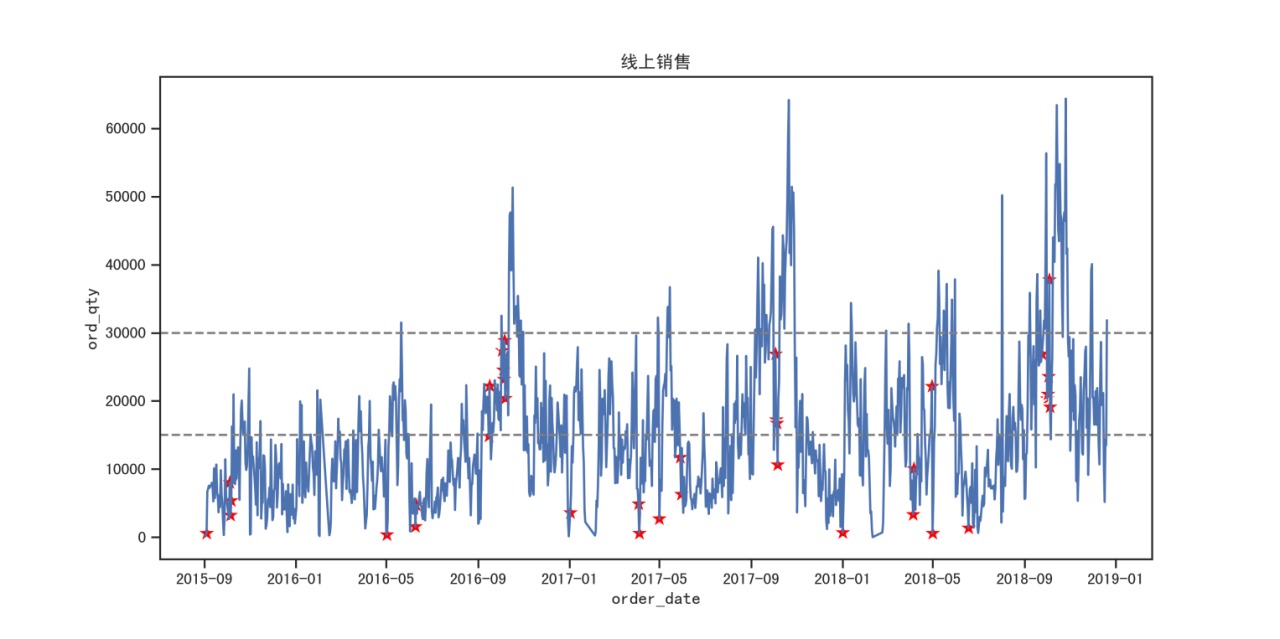
- “6.18”和“双十一”期间Top50促销产品所属细类双向柱状图

第二问
第二问要预测的精准,还是比较考验学习、代码能力的,当时是看了好几个销量预测的比赛代码,主要是kaggle上的,并且一步步自己改。搭出Baseline后,能先有一个预测的结果,再一步步的加上自己的想法。
以下内容都是先有Baseline后一步步试出来的,所以会有些跳跃性
一些链接(很多我找不到了):
详细的EDA和随机森林
1st place solution - Part 1 - “Hands on Data”
2.1 数据预处理
-
缺失值处理
-
异常值检测
- 对于检测出来有异常值的商品
- 在预测集中的商品单独建模(手动预测)
- 不再预测集中的商品直接删除
-
分类型数据转换成数值型
-
对于波动很大的销量数据,我们有两种指标。
- 标签平滑处理:取对数,用RMSE指标
- 不对数处理:使用Tweedie偏差(Tweedie deviance)
-
如果你不处理,就用RMSE评价销量预测的精确度肯定有问题。
比如一只5块钱的笔(一个月销量大约5000个),预测偏差100个。跟一块2000块钱的手表(一个月销量大约500个),预测偏差100个。用RMSE评价是一样的,但实际上肯定是手表预测的偏差带来的问题更大。Tweedie偏差就能解决这种问题
当然如果先对数处理,倒也可以用RMSE
二选一即可,最后我还是使用了后者
2.2 数据集分析
2.2.1 训练集
这里我们对数据进行了很详细的分析,我自己单独去看每一类别中的每个商品的趋势,就能发现很多特征。尽管大部分因为时间原因没有用上,但这在现实业务的预测中是很重要的一步。我们要对这个数据集有详细的了解,才能针对性处理。
稍微列举几点:
- 403/404/405:最初线上,2017年起增加线下
- 406:线下,小规模订单;2018.3从105区域迁到其他区域
- 407:销售趋势呈多个小高峰,具有季节性趋势
- 411:于2017年11月上市
- 自2017年起,地区104停止销售,104地区大部分产品转移到105地区,编写函数实现数据迁移
-
有些商品有线上引领线下的销售特征,如果某个商品线上涨了,那个这个商品下个月大概率线下也会涨
- 数据按月整合,才能做特征工程和机器学习
- 对每个产品的需求量按区域和月份进行整合
- 建立一个包含销售区域、销售月份和产品等组合信息的结构化数据集
- 然后我们提出了一个比较有用的策略-商品分层。思路来源于营销课广告,因为不同性质定位的产品,其销售规律肯定有所不同,所以分类
-
新品:直至第36个月(date_block_num)才开始出现在市场上的产品。
-
流星品:突然出现的商品;但销售时长不超过5个月,销量会急剧下降。
-
睡眠品:一直保持客观的销量,却在某个时间点之后销售量骤减,但究其原因并非季节性因素的产品。
-
常规品:总有销量的产品;销售时长达39周以上或至少存在于市场中一年以上。
- 其实应该还有季节性商品的,但是大部分商品其存在时间都没到两年,所以算法不太能判断的出来,遂放弃
2.2.2 预测集
- 然后我们编写了分类函数,对预测集中的商品进行分类,来看看要预测的都是哪些商品

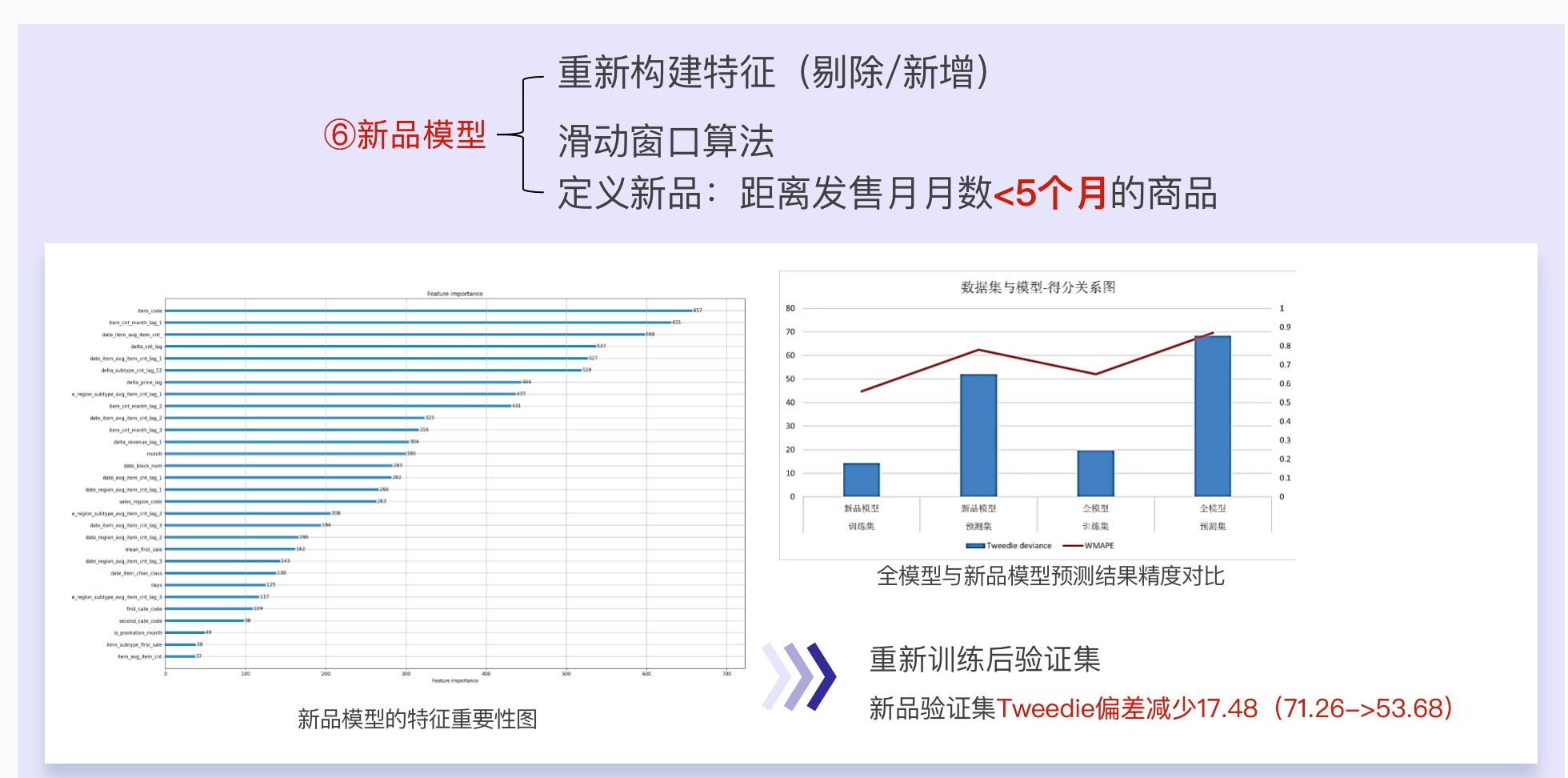
发现大部分是常规品,新品占比也不小。在搭出Baseline后我们进行了误差分析(后面会提,就是分析预测误差来源于哪里)。我们就发现很多的新品和一些波动大的商品,预测偏差很大,所以单独建立了新品模型。
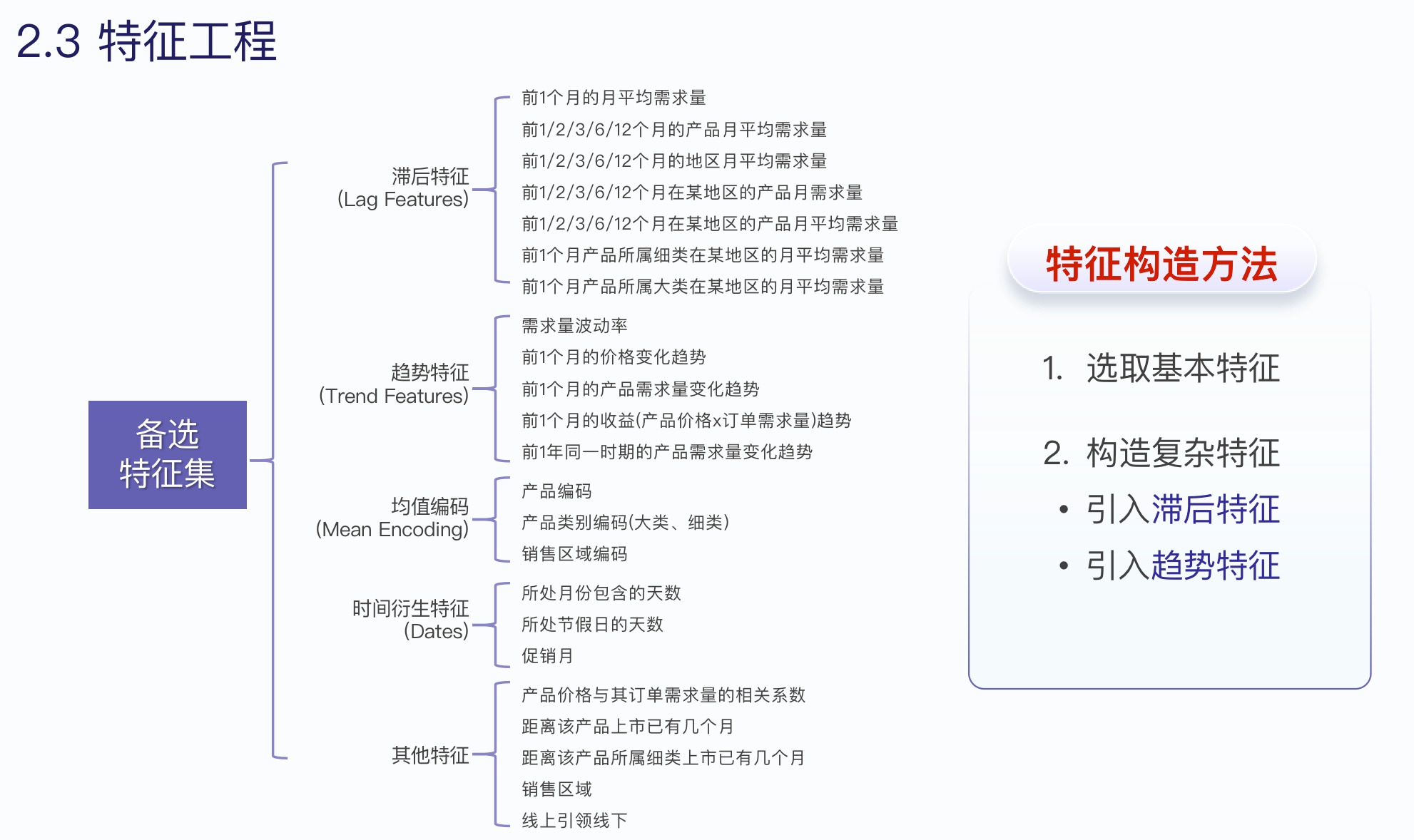
2.3 特征工程
特征工程是最重要的,也是决定模型最终预测精度的关键。常规的就是滞后特征、趋势特征等等。不断添加新特征,不断训练模型验证效果,最后没用的特征我们删除就好
- 切记不要数据泄漏,不要在做特征的时候引入未来的数据。比如趋势应该是上上个月->上个月的趋势,别是上个月->这个月的。这个月数据是要预测的
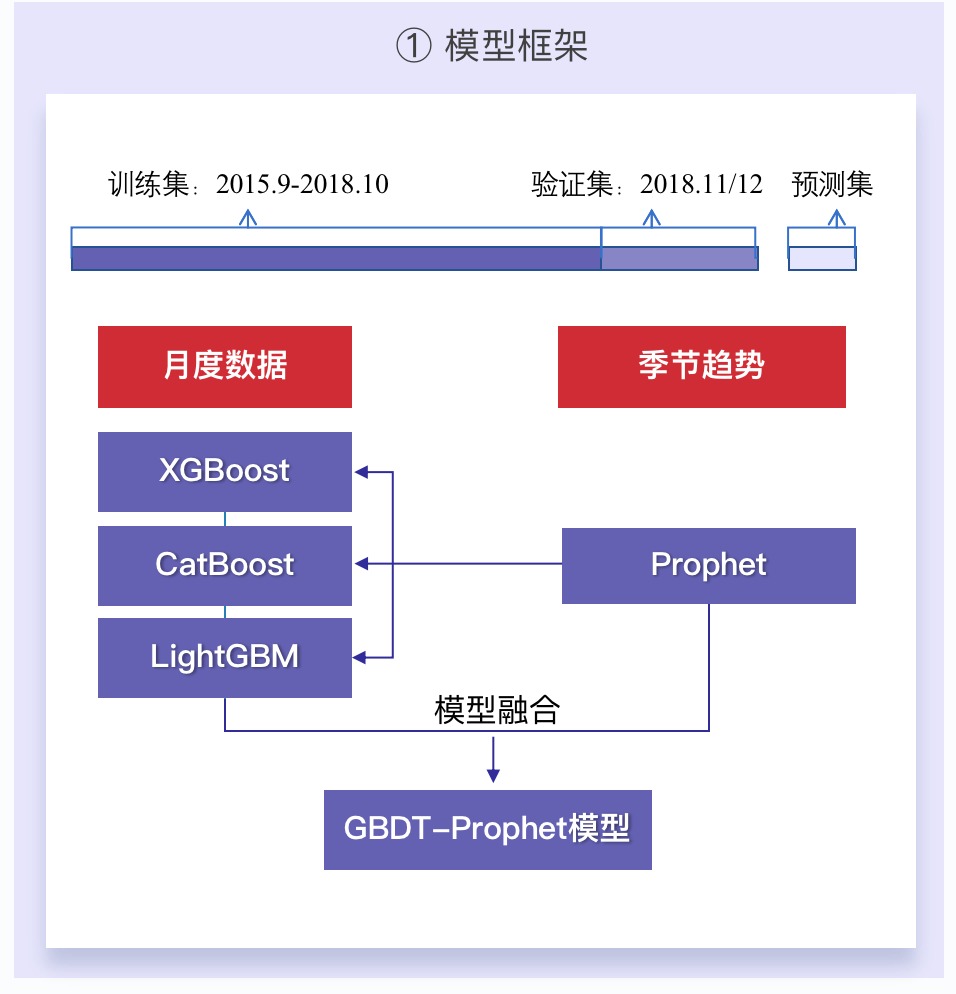
2.4 模型建立
2.4.1 模型框架和评价指标
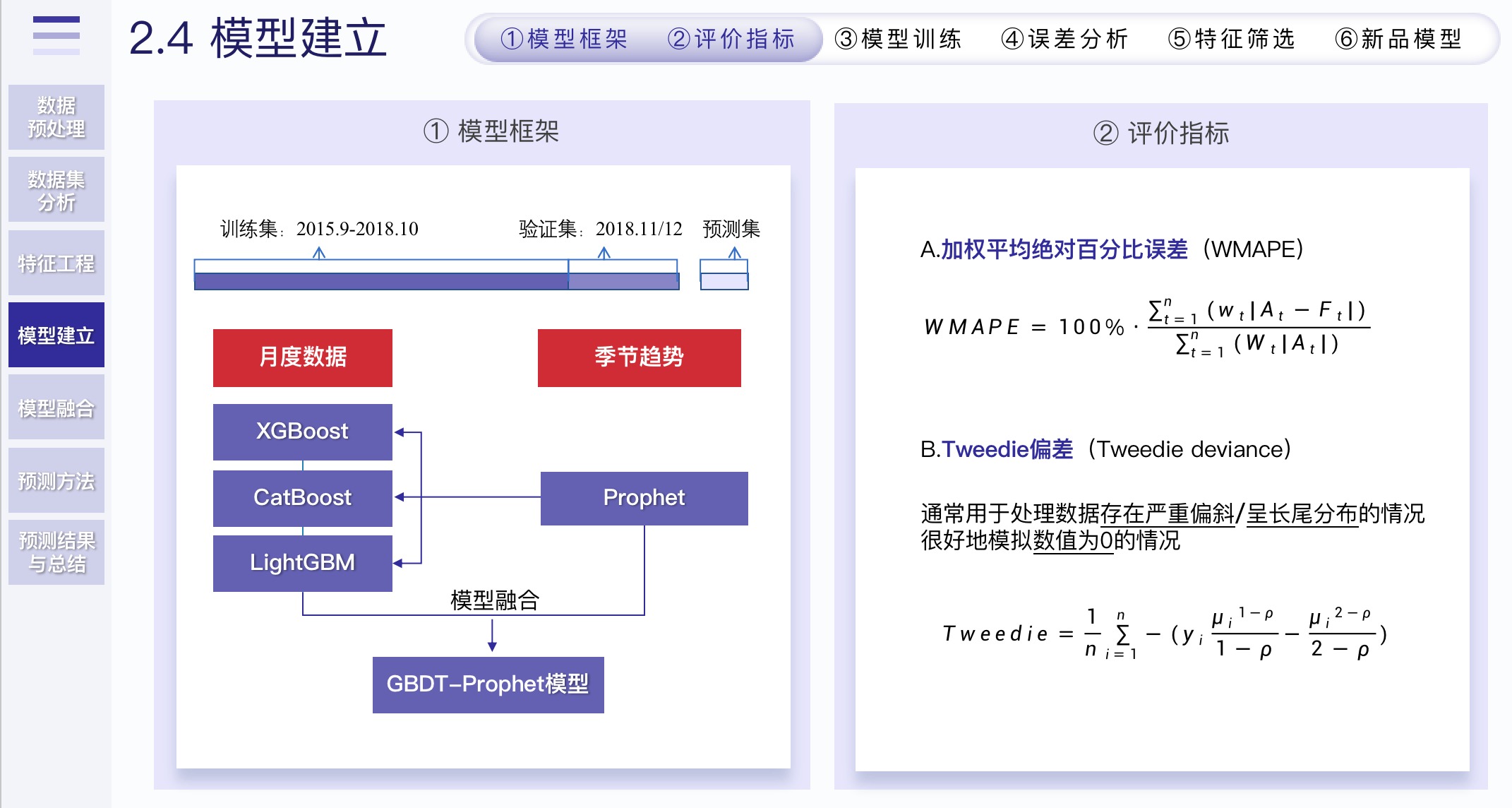
2.4.2 模型建立
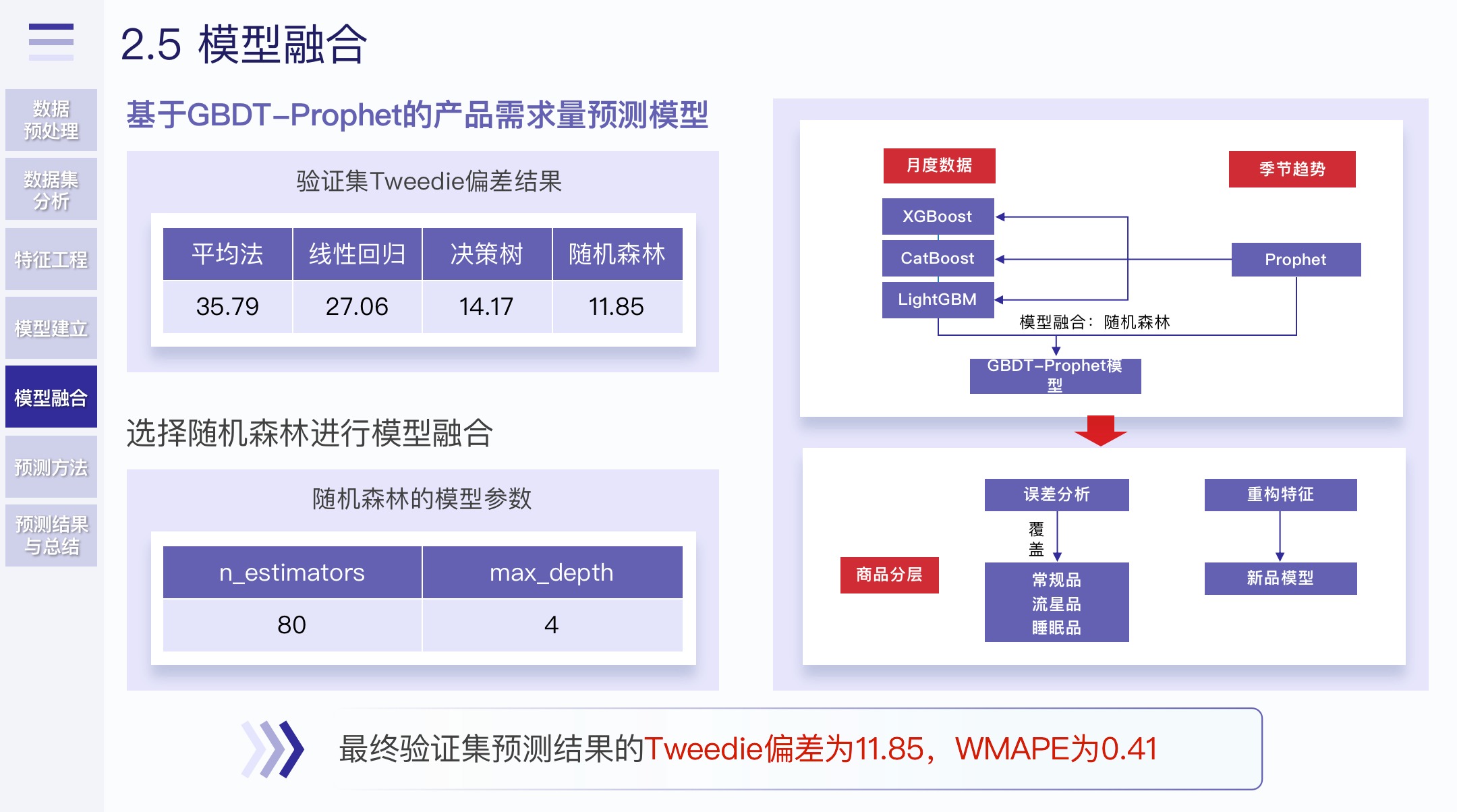
- 模型选择的话,我们Baseline使用LightGBM做的,因为其训练时间最快,方便我们不断优化
- 最后使用了三种梯度提升树算法(LightGBM、CatBoost、XGBoost)进行模型融合
- 该怎么说呢,效果肯定是很好的,但是这样也会带来过拟合。实际上,其实不用那么复杂,用一个模型也许效果最好

2.4.3 误差分析和特征筛选
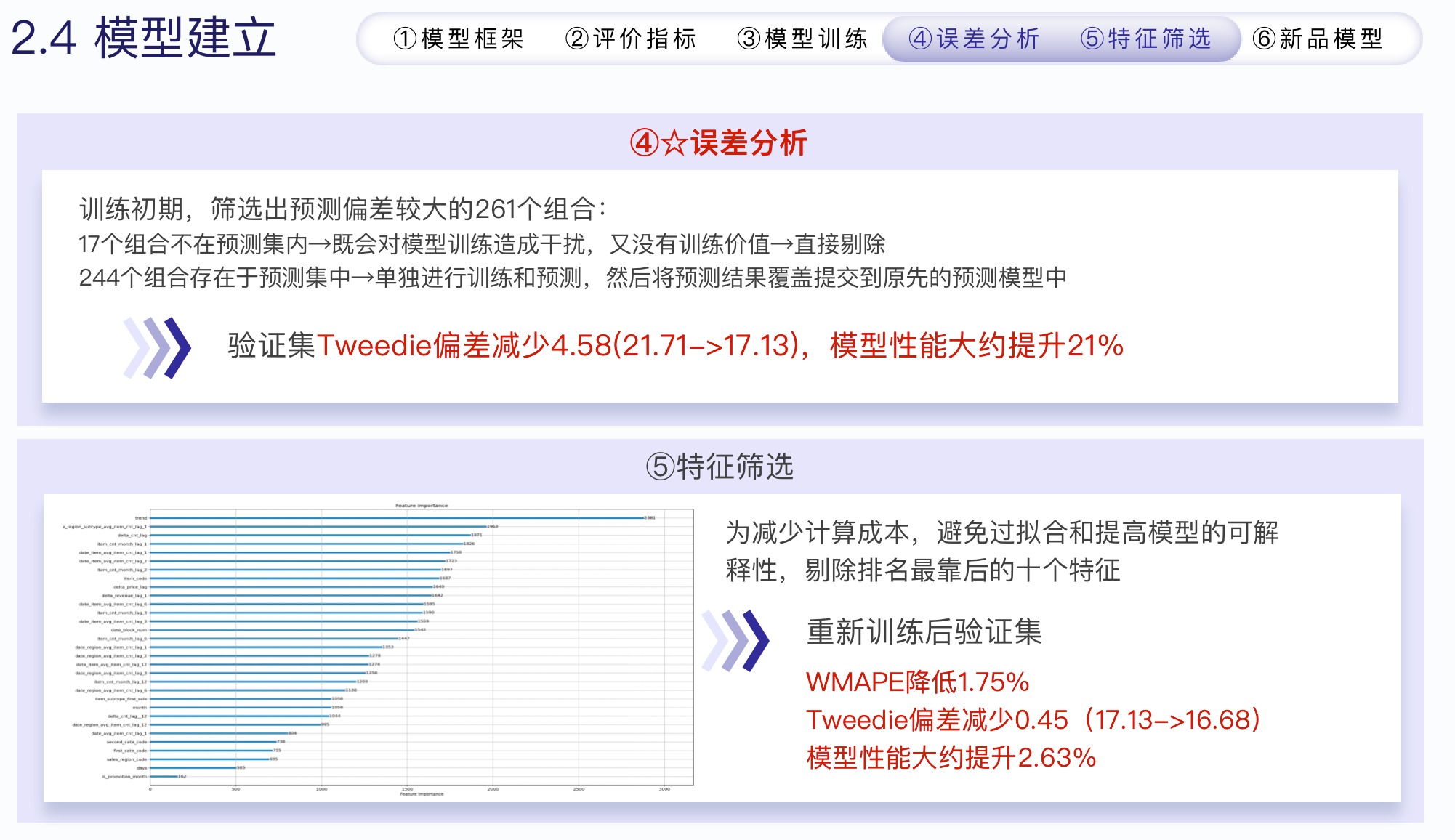
- 误差分析
- 在训练前期的帮助很大
- 重新预测误差大的商品,并将预测值覆盖提交到原先的模型中
- 特征筛选
2.4.4 新品模型
- 对于新品,我们使用滑动窗口提取出每个月的新品,来组成新品模型的训练集和预测集
- 并且重新进行特征工程,因为新品没啥历史数据,预测只能靠同类商品的一些信息,所以我们做的特征往这个方向靠
2.5 模型融合
比较了一下,选定了进行模型融合的方法
还是那句话,模型太复杂并不代表真正的预测效果越好。但是这些工作在论文的展现中是需要的。
2.6 预测方法
我们还测试了三种预测方法。因为题目要求预测往后三个月的数据。
直接预测、滚动预测应该比较好理解。
滞后预测需要重新做特征,比如预测M+2月的销售量。我们是不能用M+1月的数据做特征的

2.7 总结

结尾
先吐槽一下本次比赛的题目,题目的数据感觉质量不是太好,前期做起来很头疼,也许是销量数据的通病。第二问的按日/周/月精度分别预测让人很难理解。再吐槽一下评委,私以为能进入答辩的队伍应该都是用机器学习/深度学习对整个数据集一起训练的,评委应该focus我们工作的创新点。但是评委貌似无法理解,认为我们怎么能用到了Prophet但又不用一个个训练,好像很难理解用机器学习怎么对每个商品进行预测。我们达到的是全局最优而不是每个商品最优,这跟用不用Prophet无关(我们只是用了Prophet来一个个提取特征,总体的工作是用LGBM不断优化的)。
还有就是这个比赛需要先提交论文和预测数据(2019年1、2、3月的数据),提交的后一天又会给出1、2、3月的数据,要求在预测一遍4、5、6月的数据。当时都五一放假了喂,那天早上发现1月份的真实销售数据销量很高,总体大概是预测的2~3倍。然后我就发现5月的数据也有可能很高,就重新改代码,总结了每一类商品的每月销售特征,又预测了一天。最终相信效果应该是不错的。合理的运用Trick来提升预测精度也是获奖必不可少的部分!
最后致谢一下吧。感谢我的两位队友的努力,感谢npy的作图和比赛期间的理解、感谢学姐学长的帮助和答辩指导、感谢我的指导老师。希望这篇总结能帮助到别人。