1 最优化(Optimization)
定义:最优化是寻找能使得损失函数值最小化的参数
W
W
W的过程
- 注:给的是损失优化问题的一个简单定义,并不是完整的最优化数学定义
方法:
-
问题陈述: 这节的核心问题是:给定函数
f
(
x
)
f(x)
f(x) ,其中
x
x
x是输入数据的向量,需要计算函数
f
f
f相对于
x
x
x的梯度,也就是
Δ
f
(
x
)
\Delta f(x)
Δf(x)
- 1、找到一个目标函数
- 2、找到一个能让目标函数最优化的方法
- 3、利用这个方法进行求解
过程描述:
因为在神经网络中
f
f
f对应的是损失函
L
L
L,输入
x
x
x里面包含训练数据和神经网络的权重。比如说,损失函数可以是Softmax的损失函数,输入则包含了训练数据
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi)、权重
W
W
W和偏差
b
b
b。注意训练集是给定的对于监督学习来说,而权重是可以控制的变量。因此,即使能用反向传播计算输入数据
x
i
x_i
xi上的梯度,但在实践为了进行参数更新,通常也只计算参数
W
W
W,
b
b
b的梯度。当然
x
i
x_i
xi的梯度有时仍然是有用的:比如将神经网络所做的事情可视化便于直观理解的时候,就能用上。
1.1 梯度下降算法过程(复习)
目的:使损失函数的值找到最小值
方式:梯度下降
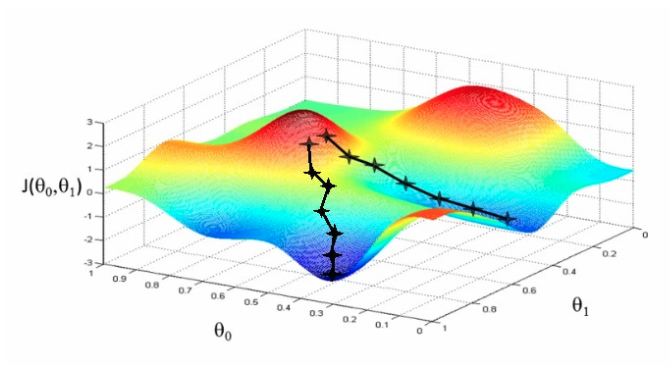
函数的 梯度(gradient) 指出了函数的最陡增长方向。梯度的方向走,函数增长得就越快。那么按梯度的负方向走,函数值自然就降低得最快了。模型的训练目标即是寻找合适的 w 与 b 以最小化代价函数值。假设 w 与 b 都是一维实数,那么可以得到如下的 J 关于 w 与 b 的图:
参数w和b的更新公式为:
w
:
=
w
−
α
d
J
(
w
,
b
)
d
w
,
b
:
=
b
−
α
d
J
(
w
,
b
)
d
b
w:=w−\alpha\frac{dJ(w, b)}{dw},b := b - \alpha\frac{dJ(w, b)}{db}
w:=w−αdwdJ(w,b),b:=b−αdbdJ(w,b)
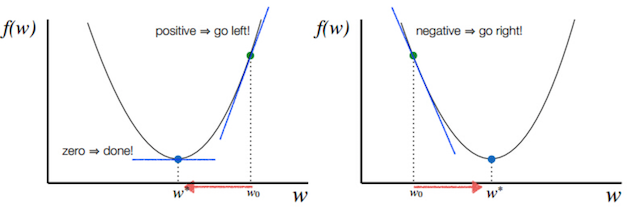
注:其中 α 表示学习速率,即每次更新的 w 的步伐长度。当 w 大于最优解 w′ 时,导数大于 0,那么 w 就会向更小的方向更新。反之当 w 小于最优解 w′ 时,导数小于 0,那么 w 就会向更大的方向更新。迭代直到收敛。
通过二维平面来理解梯度下降过程:
可能根据简单的RMSE损失函数的是一个凸函数。但是一旦我们将函数扩展到神经网络,目标函数就就不再是凸函数了,图像也不会像上面那样是个碗状,而是凹凸不平的复杂地形形状。

注:在一篇论文中:Visualizing the Loss Landscape of Neural Nets,就专门做了将高位参数空间投影到二维或者三维的样子,这样投影之后的样子对神经网络的损失函数有个直观的认识,后面还会分析针对于这样的情况的优化问题。
2 神经网络的链式法则与反向传播算法
反向传播是训练神经网络最重要的算法,可以这么说,没有反向传播算法就没有深度学习的今天。但是反向传播算法设计一大堆数据公式概念。所以我们先复习回顾一下之前导数计算过程以及要介绍的新的复合函数多层求导计算过程。
- 导数、导数计算图
- 链式法则、逻辑回归的梯度下降优化、向量化编程
2.1 导数(复习)
这里就不在赘述导数到底如何去进行计算了,相信大家都会,不会的可以看一看我前面机器学习专栏的文章,在讲线性回归的时候有导数的讲解
这里仅强调一下sigmoid函数的求导,之后会用到
σ
(
x
)
=
1
1
+
e
−
x
→
d
σ
(
x
)
d
x
=
e
−
x
(
1
+
e
−
x
)
2
=
(
1
+
e
−
x
−
1
1
+
e
−
x
)
(
1
1
+
e
−
x
)
=
(
1
−
σ
(
x
)
)
σ
(
x
)
\sigma(x) = \frac{1}{1+e^{-x}} \rightarrow \frac{d\sigma(x)}{dx} = \frac{e^{-x}}{(1+e^{-x})^2} = \left( \frac{1 + e^{-x} - 1}{1 + e^{-x}} \right) \left( \frac{1}{1+e^{-x}} \right) = \left( 1 - \sigma(x) \right) \sigma(x)
σ(x)=1+e−x1→dxdσ(x)=(1+e−x)2e−x=(1+e−x1+e−x−1)(1+e−x1)=(1−σ(x))σ(x)
2.3 导数计算图
那么接下来我们来看看含有多个变量的到导数流程图,假设
J
(
a
,
b
,
c
)
=
3
(
a
+
b
c
)
J(a,b,c) = 3{(a + bc)}
J(a,b,c)=3(a+bc),虽然这个表达足够简单,可以直接微分,但是在此使用一种有助于读者直观理解反向传播的方法。
我们以下面的流程图代替
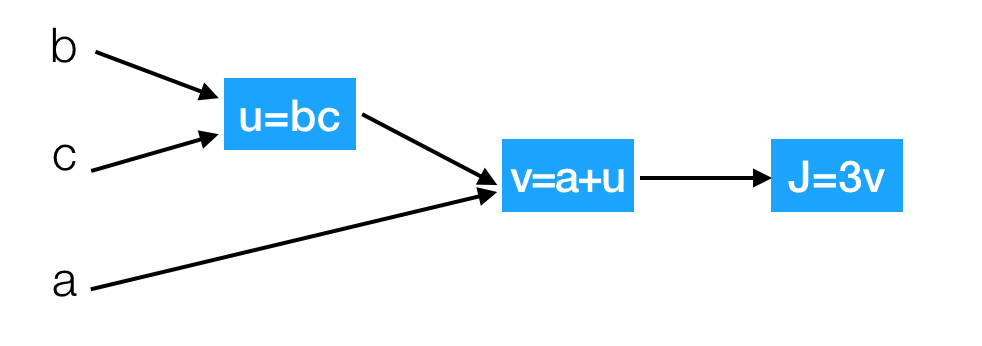
这样就相当于从左到右计算出结果,然后从后往前计算出导数dv以及da,如果用前面的变化量计算J相对于三个变量a,b,c的导数?假设b=4,c=2,a=7,u=8,v=15,j=45
-
d
J
d
v
=
3
\frac{dJ}{dv}=3
dvdJ=3
增加v从15到15.001,那么
J
≈
45.003
J\approx45.003
J≈45.003
-
d
J
d
a
=
3
\frac{dJ}{da}=3
dadJ=3
增加a从7到7.001,那么
v
≈
15.001
v\approx15.001
v≈15.001,
J
≈
45.003
J\approx45.003
J≈45.003
2.4 使用链式法则计算复合表达式
对于上面的例子,如果考虑更复杂的包含多个函数的复合函数,那么我们需要用到链式法则,指出将这些梯度表达式链接起来相乘。
-
d
J
d
a
=
d
J
d
v
d
v
d
a
=
3
∗
1
=
3
\frac{dJ}{da} = \frac{dJ}{dv}\frac{dv}{da} =3*1=3
dadJ=dvdJdadv=3∗1=3
J
J
J相对于
a
a
a增加的量可以理解为
J
J
J相对于
v
v
v相对于
a
a
a增加的量
接下来计算
-
d
J
d
b
=
d
J
d
u
d
u
d
b
=
3
∗
2
=
6
\frac{dJ}{db}=\frac{dJ}{du}\frac{du}{db}=3*2=6
dbdJ=dudJdbdu=3∗2=6
-
d
J
d
c
=
d
J
d
u
d
u
d
c
=
3
∗
4
=
12
\frac{dJ}{dc}=\frac{dJ}{du}\frac{du}{dc}=3 * 4=12
dcdJ=dudJdcdu=3∗4=12
这次计算可以被可视化为如下计算线路图像:

那么整个计算图展示的就是计算过程,神经网络提到的前向传播就是从输入计算到输出(红色部分),反向传播从尾部开始,根据链式法则递归地向前计算梯度(显示为绿色),一直到网络的输入端。
反向传播总结:
在反向传播的过程中,门单元将最终获得整个网络的最终输出值在自己的输出值上的梯度。链式法则指出,门单元应该将回传的梯度乘以它对其的输入的局部梯度,从而得到整个网络的输出对该门单元的每个输入值的梯度。
2.5 案例:逻辑回归的链式法则推导过程
逻辑回归的梯度下降过程计算图,首先从前往后的计算图得出如下。
-
z
=
w
T
x
+
b
z=w^Tx+b
z=wTx+b
-
y
^
=
a
=
σ
(
z
)
\hat{y} =a= \sigma(z)
y^=a=σ(z)
-
L
(
y
^
,
y
)
=
−
(
y
log
a
)
−
(
1
−
y
)
log
(
1
−
a
)
L(\hat{y},y) = -(y\log{a})-(1-y)\log(1-a)
L(y^,y)=−(yloga)−(1−y)log(1−a)
那么计算图从前向过程为,假设样本有两个特征
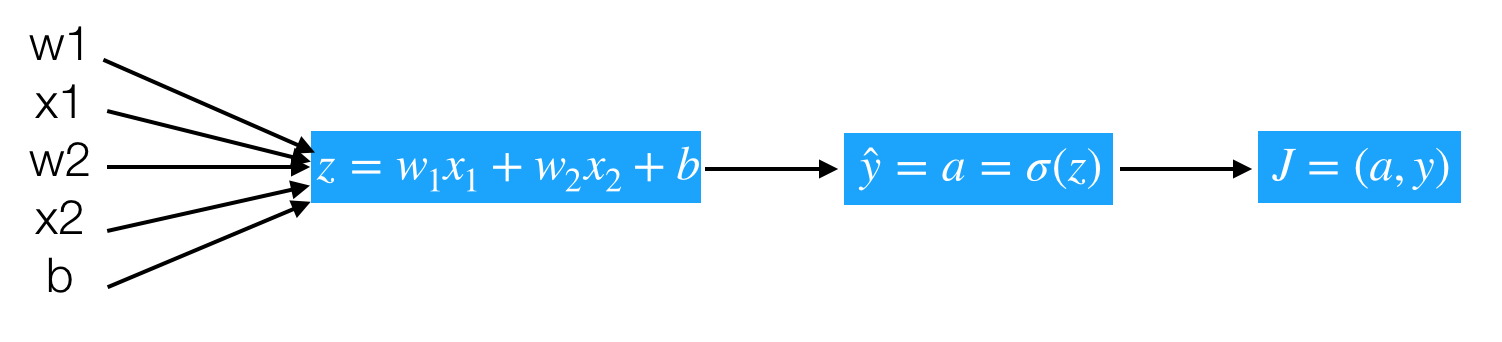
问题:计算出
J
J
J关于
z
z
z的导数的计算公式(
d
J
d
z
\frac{dJ}{dz}
dzdJ 记为
d
z
dz
dz):
-
d
z
=
d
J
d
a
d
a
d
z
=
a
−
y
dz = \frac{dJ}{da}\frac{da}{dz} = a-y
dz=dadJdzda=a−y
-
d
J
d
a
=
−
y
a
+
1
−
y
1
−
a
\frac{dJ}{da} = -\frac{y}{a} + \frac{1-y}{1-a}
dadJ=−ay+1−a1−y
-
d
a
d
z
=
a
(
1
−
a
)
\frac{da}{dz} = a(1-a)
dzda=a(1−a)
(
−
y
a
+
1
−
y
1
−
a
)
(
a
(
1
−
a
)
)
=
(
−
y
+
a
y
)
+
(
a
−
a
y
)
=
a
−
y
(-\frac{y}{a} + \frac{1-y}{1-a})(a(1-a)) = (-y+ay)+(a-ay)=a-y
(−ay+1−a1−y)(a(1−a))=(−y+ay)+(a−ay)=a−y
所以我们这样可以求出总损失相对于
w
1
,
w
2
,
b
w_1,w_2,b
w1,w2,b 参数的某一点导数,从而可以更新参数
-
d
J
d
w
1
=
d
J
d
z
d
z
d
w
1
=
d
z
∗
x
1
=
(
a
−
y
)
x
1
\frac{dJ}{dw_1} = \frac{dJ}{dz}\frac{dz}{dw_1}=dz * x1=(a-y)x_1
dw1dJ=dzdJdw1dz=dz∗x1=(a−y)x1
-
d
J
d
w
2
=
d
J
d
z
d
z
d
w
2
=
d
z
∗
x
2
=
(
a
−
y
)
x
2
\frac{dJ}{dw_2} = \frac{dJ}{dz}\frac{dz}{dw_2}=dz * x2=(a-y)x_2
dw2dJ=dzdJdw2dz=dz∗x2=(a−y)x2
-
d
J
d
b
=
d
z
∗
1
=
a
−
y
\frac{dJ}{db}=dz * 1=a-y
dbdJ=dz∗1=a−y
2.6 案例:逻辑回归前向与反向传播简单计算
假设简单的模型为
y
=
s
i
g
m
o
i
d
(
w
1
x
1
+
w
2
x
2
+
b
)
y =sigmoid(w1x1+w2x2+b)
y=sigmoid(w1x1+w2x2+b), 我们在这里给几个随机的输入的值和权重,带入来计算一遍,其中在点
x
1
,
x
2
=
(
−
1
−
2
)
x1,x2 = (-1 -2)
x1,x2=(−1−2),目标值为1,假设给一个初始化
w
1
,
w
2
,
b
=
(
2
,
−
3
,
−
3
)
w1,w2,b=(2, -3, -3)
w1,w2,b=(2,−3,−3),由于中间有
s
i
g
m
o
i
d
sigmoid
sigmoid的计算过程,所以我们用代码来呈现刚才的过程。
# 假设一些随机数据和权重,以及目标结果1
w = [2,-3,-3]
x = [-1, -2]
y = 1
# 前向传播
z = w[0]*x[0] + w[1]*x[1] + w[2]
a = 1.0 / (1 + np.exp(-z))
cost = -np.sum(y * np.log(a) + (1 - y) * np.log(1 - a))
# 对神经元反向传播
# 点积变量的梯度, 使用sigmoid函数求导
dz = a - y
# 回传计算x梯度
dx = [w[0] * dz, w[1] * dz]
# #回传计算w梯度
dw = [x[0] * dz, x[1] * dz, 1.0 * dz]
我们可以看出来
w
1
,
w
2
,
b
w_1,w_2,b
w1,w2,b 在这次更新是受到
x
x
x的输入的影响计算梯度的。
3 反向传播的向量化编程实现
每更新一次梯度时候,在训练期间我们会拥有m个样本,那么这样每个样本提供进去都可以做一个梯度下降计算。所以我们要去做在所有样本上的计算结果、梯度等操作
J
(
w
,
b
)
=
1
m
∑
i
=
1
m
L
(
a
(
i
)
,
y
(
i
)
)
J(w,b) = \frac{1}{m}\sum_{i=1}^mL(a^{(i)},y^{(i)})
J(w,b)=m1i=1∑mL(a(i),y(i))
计算参数的梯度为:
d
(
w
1
)
i
,
d
(
w
2
)
i
,
d
(
b
)
i
d(w_1)^{i}, d(w_2)^{i},d(b)^{i}
d(w1)i,d(w2)i,d(b)i,这样,我们想要得到最终的
d
w
1
,
d
w
2
,
d
b
d{w_1},d{w_2},d{b}
dw1,dw2,db,如何去设计一个算法计算?伪代码实现:
初始化,假设
J
=
0
,
d
w
1
=
0
,
d
w
2
=
0
,
d
b
=
0
{J} = 0, dw_1=0, dw_2=0, db={0}
J=0,dw1=0,dw2=0,db=0
for i in m:
z
i
=
w
T
x
i
+
b
z^i = w^Tx^i+{b}
zi=wTxi+b
a
i
=
σ
(
z
i
)
a^i = \sigma(z^i)
ai=σ(zi)
J
+
=
−
[
y
i
l
o
g
(
a
i
)
+
(
1
−
y
i
)
l
o
g
(
1
−
a
i
)
]
J +=-[y^ilog(a^i)+(1-y^i)log(1-a^i)]
J+=−[yilog(ai)+(1−yi)log(1−ai)]
每个梯度计算结果相加
d
z
i
=
a
i
−
y
i
dz^i = a^i-y^{i}
dzi=ai−yi
d
w
1
+
=
x
1
i
d
z
i
dw_1 += x_1^idz^i
dw1+=x1idzi
d
w
2
+
=
x
2
i
d
z
i
dw_2 +=x_2^idz^i
dw2+=x2idzi
d
b
+
=
d
z
i
db+=dz^i
db+=dzi
最后求出平均梯度
J
/
=
m
J /=m
J/=m
d
w
1
/
=
m
dw_1 /= m
dw1/=m
d
w
2
/
=
m
dw_2 /= m
dw2/=m
d
b
/
=
m
db /= m
db/=m
3.1 向量化优势
由于在进行计算的时候,最好不要使用for循环去进行计算,因为有Numpy可以进行更加快速的向量化计算。
在公式
z
=
w
T
x
+
b
z = w^Tx+b
z=wTx+b 中
w
,
x
w,x
w,x 都可能是多个值,也就是
w
ˉ
=
(
w
1
⋮
w
n
)
x
ˉ
=
(
x
1
⋮
x
n
)
\bar w = \left( \begin{array}{c}w_{1} \\ \vdots \\w_{n}\end{array}\right) \bar x= \left(\begin{array}{c}x_{1} \\\vdots \\x_{n} \end{array}\right)
wˉ=⎝⎜⎛w1⋮wn⎠⎟⎞xˉ=⎝⎜⎛x1⋮xn⎠⎟⎞
import numpy as np
import time
a = np.random.rand(100000)
b = np.random.rand(100000)
# 第一种for 循环
c = 0
start = time.time()
for i in range(100000):
c += a[i]*b[i]
end = time.time()
print("计算所用时间%s " % str(1000*(end-start)) + "ms")
计算所用时间78.79066467285156 ms
# 向量化运算
start = time.time()
c = np.dot(a, b)
end = time.time()
print("计算所用时间%s " % str(1000*(end-start)) + "ms")
计算所用时间0.9977817535400391 ms
Numpy能够充分的利用并行化,Numpy当中提供了很多函数使用
| 函数 |
作用 |
| np.ones or np.zeros |
全为1或者0的矩阵 |
| np.exp |
指数计算 |
| np.log |
对数计算 |
| np.abs |
绝对值计算 |
所以上述的m个样本的梯度更新过程,就是去除掉for循环。原本这样的计算
3.2 向量化反向传播实现伪代码
思路:
|
z
1
=
w
T
x
1
+
b
z^1 = w^Tx^1+b
z1=wTx1+b |
z
2
=
w
T
x
2
+
b
z^2 = w^Tx^2+b
z2=wTx2+b |
z
3
=
w
T
x
3
+
b
z^3 = w^Tx^3+b
z3=wTx3+b |
|
a
1
=
σ
(
z
1
)
a^1 = \sigma(z^1)
a1=σ(z1) |
a
2
=
σ
(
z
2
)
a^2 = \sigma(z^2)
a2=σ(z2) |
a
3
=
σ
(
z
3
)
a^3 = \sigma(z^3)
a3=σ(z3) |
可以变成这样的计算
w
ˉ
=
(
w
1
⋮
w
n
)
\bar w = \left( \begin{array}{c}w_{1} \\ \vdots \\w_{n}\end{array}\right)
wˉ=⎝⎜⎛w1⋮wn⎠⎟⎞
x
ˉ
=
(
⋮
x
1
⋮
⋮
x
2
⋮
⋮
x
3
⋮
…
⋮
x
m
⋮
)
\bar x = \left( \begin{array}{c}\vdots \\x^1\\ \vdots \end{array} \begin{array}{c}\vdots \\x^2\\ \vdots \end{array} \begin{array}{c}\vdots \\x^3\\ \vdots \end{array} \begin{array}{c}\dots \end{array} \begin{array}{c}\vdots \\x^m\\ \vdots \end{array}\right)
xˉ=⎝⎜⎜⎛⋮x1⋮⋮x2⋮⋮x3⋮…⋮xm⋮⎠⎟⎟⎞
注:w的形状为(n,1), x的形状为(n, m),其中n为特征数量,m为样本数量
我们可以让
Z
=
W
T
X
+
b
=
(
z
1
,
z
2
,
z
3
⋯
z
m
)
+
b
=
n
p
.
d
o
t
(
W
T
,
X
)
+
b
Z= {W^T}X + b=\left(z^1, z^2,z^3\cdots z^m \right)+b=np.dot(W^T,X)+b
Z=WTX+b=(z1,z2,z3⋯zm)+b=np.dot(WT,X)+b,得出的结果为
[
1
,
n
]
×
[
n
,
m
]
=
[
1
,
m
]
[1, n]\times[n, m] = [1, m]
[1,n]×[n,m]=[1,m]大小的矩阵 注:大写的
W
,
X
W,X
W,X为多个样本表示
初始化,假设n个特征,m个样本
J
=
0
,
W
=
n
p
.
z
e
r
o
s
(
[
n
,
1
]
)
,
b
=
0
J = 0, W=np.zeros([n,1]), b={0}
J=0,W=np.zeros([n,1]),b=0
Z
=
n
p
.
d
o
t
(
W
T
,
X
)
+
b
Z= np.dot(W^T,X)+{b}
Z=np.dot(WT,X)+b
A
=
σ
(
Z
)
A = \sigma(Z)
A=σ(Z)
L
=
−
(
1
/
m
)
n
p
.
s
u
m
(
Y
∗
n
p
.
l
o
g
(
A
)
+
(
1
−
Y
)
∗
n
p
.
l
o
g
(
1
−
A
)
)
L = -(1/m)np.sum(Y*np.log(A)+(1-Y)*np.log(1-A))
L=−(1/m)np.sum(Y∗np.log(A)+(1−Y)∗np.log(1−A))
每个样本梯度计算过程为:
d
Z
=
A
−
Y
dZ = {A}-{Y}
dZ=A−Y
d
W
=
1
m
X
d
Z
T
dW = \frac{1}{m}X{dZ}^{T}
dW=m1XdZT
d
b
=
1
m
n
p
.
s
u
m
(
d
Z
)
db=\frac{1}{m}np.sum(dZ)
db=m1np.sum(dZ)
更新
W
:
=
W
−
α
d
W
W := W - \alpha{dW}
W:=W−αdW
b
:
=
b
−
α
d
b
b := b - \alpha{db}
b:=b−αdb
这相当于一次使用了M个样本的所有特征值与目标值,那我们知道如果想多次迭代,使得这M个样本重复若干次计算。
代码实现过程, 这里假设有10个样本,每个样本两个特征
# 随机初始化权重
# w1,w2
W = np.random.random([2, 1])
X = np.random.random([2, 10])
b = 0.0
Y = np.array([0, 1, 1, 0, 1, 1, 0, 1, 0, 0])
Z = np.dot(W.T, X) + b
A = 1.0 / (1 + np.exp(-Z))
cost = -1 / 10 * np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A))
# 形状:A:[1, 10] , Y:[1, 10]
dZ = A - Y
# [2, 10] * ([1, 10].T) = [2, 1]
dW = (1.0 / 10) * np.dot(X, dZ.T)
db = (1.0 / 10) * np.sum(dZ)
4 案例:实现单神经元神经网络
4.1 目的
读取猫狗的图片矩阵数据,自实现单神经元神经网络进行二分类
4.2 步骤
- 1、读取数据集
- 2、实现前向传播与反向传播过程
- 3、模型预测函数实现
4.3 代码实现
代码模块安排如下图

1、读取数据集以及主函数逻辑
import numpy as np
import h5py
def load_dataset():
train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
这部分直接复制即可,可以暂时不用懂数据是如何读取进来的
主体函数
导入相关包
import numpy as np
from data import load_dataset
主体逻辑
def main():
# 1、读取样本数据
train_x, train_y, test_x, test_y, classes = load_dataset()
print("训练集的样本数: ", train_x.shape[0])
print("测试集的样本数: ", test_x.shape[0])
print("train_x形状: ", train_x.shape)
print("train_y形状: ", train_y.shape)
print("test_x形状: ", test_x.shape)
print("test_x形状: ", test_y.shape)
# 输入数据的形状修改以及归一化
train_x = train_x.reshape(train_x.shape[0], -1).T
test_x = test_x.reshape(test_x.shape[0], -1).T
train_x = train_x / 255.
test_x = test_x / 255.
# 2、模型训练以及预测
d = model(train_x, train_y, test_x, test_y, num_iterations=2000, learning_rate=0.005)
2、模型预测函数实现
模型函数
def model(X_train, Y_train, X_test, Y_test, num_iterations=2000, learning_rate=0.5):
"""
"""
# 初始化参数
w, b = initialize_with_zeros(X_train.shape[0])
# 梯度下降
# params:更新后的网络参数
# grads:最后一次梯度
# costs:每次更新的损失列表
params, grads, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate)
# 获取训练的参数
# 预测结果
w = params['w']
b = params['b']
Y_prediction_train = predict(w, b, X_train)
Y_prediction_test = predict(w, b, X_test)
# 打印准确率
print("训练集准确率: {} ".format(100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100))
print("测试集准确率: {} ".format(100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100))
d = {"costs": costs,
"Y_prediction_test": Y_prediction_test,
"Y_prediction_train": Y_prediction_train,
"w": w,
"b": b,
"learning_rate": learning_rate,
"num_iterations": num_iterations}
return d
其中涉及两个函数一个是sigmoid另一个是初始化函数:
def basic_sigmoid(x):
"""
计算sigmoid函数
"""
s = 1 / (1 + np.exp(-x))
return s
def initialize_with_zeros(shape):
"""
创建一个形状为 (shape, 1) 的w参数和b=0.
return:w, b
"""
w = np.zeros((shape, 1))
b = 0
return w, b
3、前向传播与反向传播实现
def optimize(w, b, X, Y, num_iterations, learning_rate):
"""
参数:
w:权重,b:偏置,X特征,Y目标值,num_iterations总迭代次数,learning_rate学习率
Returns:
params:更新后的参数字典
grads:梯度
costs:损失结果
"""
costs = []
for i in range(num_iterations):
# 梯度更新计算函数
grads, cost = propagate(w, b, X, Y)
# 取出两个部分参数的梯度
dw = grads['dw']
db = grads['db']
# 按照梯度下降公式去计算
w = w - learning_rate * dw
b = b - learning_rate * db
if i % 100 == 0:
costs.append(cost)
if i % 100 == 0:
print("损失结果 %i: %f" % (i, cost))
print(b)
params = {"w": w,
"b": b}
grads = {"dw": dw,
"db": db}
return params, grads, costs
def propagate(w, b, X, Y):
"""
参数:w,b,X,Y:网络参数和数据
Return:
损失cost、参数W的梯度dw、参数b的梯度db
"""
m = X.shape[1]
# 前向传播
# w (n,1), x (n, m)
A = basic_sigmoid(np.dot(w.T, X) + b)
# 计算损失
cost = -1 / m * np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A))
# 反向传播
dz = A - Y
dw = 1 / m * np.dot(X, dz.T)
db = 1 / m * np.sum(dz)
grads = {"dw": dw,
"db": db}
return grads, cost
预测函数为:
def predict(w, b, X):
'''
利用训练好的参数预测
return:预测结果
'''
m = X.shape[1]
Y_prediction = np.zeros((1, m))
w = w.reshape(X.shape[0], 1)
# 计算结果
A = basic_sigmoid(np.dot(w.T, X) + b)
for i in range(A.shape[1]):
if A[0, i] <= 0.5:
Y_prediction[0, i] = 0
else:
Y_prediction[0, i] = 1
assert (Y_prediction.shape == (1, m))
return Y_prediction
运行结果显示:
训练集的样本数: 209
测试集的样本数: 50
train_x形状: (209, 64, 64, 3)
train_y形状: (1, 209)
test_x形状: (50, 64, 64, 3)
test_x形状: (1, 50)
===== 12288
损失结果第 0 次, 值为:0.693147
损失结果第 100 次, 值为:0.584508
损失结果第 200 次, 值为:0.466949
损失结果第 300 次, 值为:0.376007
损失结果第 400 次, 值为:0.331463
损失结果第 500 次, 值为:0.303273
损失结果第 600 次, 值为:0.279880
损失结果第 700 次, 值为:0.260042
损失结果第 800 次, 值为:0.242941
损失结果第 900 次, 值为:0.228004
损失结果第 1000 次, 值为:0.214820
损失结果第 1100 次, 值为:0.203078
损失结果第 1200 次, 值为:0.192544
损失结果第 1300 次, 值为:0.183033
损失结果第 1400 次, 值为:0.174399
损失结果第 1500 次, 值为:0.166521
损失结果第 1600 次, 值为:0.159305
损失结果第 1700 次, 值为:0.152667
损失结果第 1800 次, 值为:0.146542
损失结果第 1900 次, 值为:0.140872
训练集准确率: 99.04306220095694
测试集准确率: 70.0