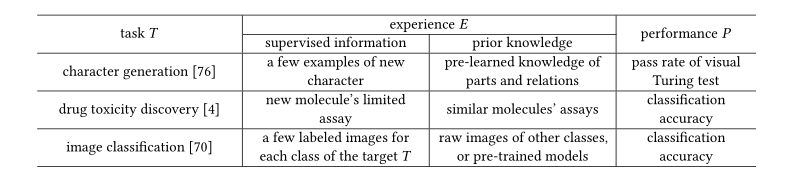
机器学习定义:A computer program is said to learn from experience E with respect to some classes of task T and performance measure P if its performance can improve with E on T measured by P.
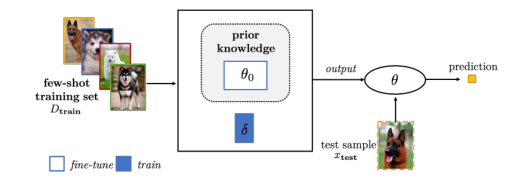
小样本学习:Few-Shot Learning(FSL) is a type of machine learning problems (specified by E, T and P), where E contains only a limited number of examples with supervised information for the target T.
Remark 1.When there is only one example with supervised information inE, FSL is calledone-shot learning[14,35,138]. When E does not contain any example with supervised information for the targetT, FSL becomes azero-shot learningproblem (ZSL). As the target class does not contain examples with supervised information, ZSL requires E to contain information from other modalities (such as attributes, WordNet, and word embeddings used in rare object recognition tasks), so as to transfer some supervised information and make learning possible.
假设一个任务h,我们想最小化他的风险R,损失函数用
p
(
x
,
y
)
p(x,y)
p(x,y)进行计算。得到如下公式
R
(
h
)
=
∫
ℓ
(
h
(
x
)
,
y
)
d
p
(
x
,
y
)
=
E
[
ℓ
(
h
(
x
)
,
y
)
]
R(h)=\int \ell(h(x),y)dp(x,y)=\mathbb{E}[\ell(h(x),y)]
R(h)=∫ℓ(h(x),y)dp(x,y)=E[ℓ(h(x),y)]
因为
p
(
x
,
y
)
是
未
知
的
,
经
验
风
险
在
有
I
个
样
本
的
训
练
集
上
的
平
均
值
p(x,y)是未知的,经验风险在有I个样本的训练集上的平均值
p(x,y)是未知的,经验风险在有I个样本的训练集上的平均值来代理经验风险值
R
I
(
h
)
R_I(h)
RI(h)
R
I
(
h
)
=
1
I
∑
i
=
1
i
ℓ
(
h
(
x
i
)
,
y
i
)
R_I(h)= \frac{1}I\sum_{i=1}^i \ell(h(x_i),y_i)
RI(h)=I1i=1∑iℓ(h(xi),yi)
为方便说明做以下三种假设,
h
^
=
a
r
g
m
i
n
h
(
R
(
h
)
)
\hat{h} = arg {\ } min_h(R(h))
h^=argminh(R(h))期望最小值函数
h
∗
=
a
r
g
m
i
n
h
∈
H
R
(
h
)
h^* = arg{\ }min_{h \in \mathcal{H}}R(h)
h∗=argminh∈HR(h)在
H
\mathcal{H}
H中期望最小值函数
h
I
=
a
r
g
m
i
n
h
∈
H
R
I
(
h
)
h_I=arg {\ }min_{h\in\mathcal{H}}R_I(h)
hI=argminh∈HRI(h)在
H
\mathcal{H}
H中经验最小值函数
因为
h
^
\hat{h}
h^是未知的,但是在
H
\mathcal{H}
H中
h
∗
h^*
h∗是
h
^
\hat{h}
h^最好的近似值,所以可以得到误差为
E
[
R
(
h
I
)
−
R
(
h
^
)
]
=
E
[
R
(
h
∗
)
−
R
(
h
^
)
]
⏟
ξ
a
p
p
(
H
)
+
E
[
R
(
h
I
)
−
R
(
h
∗
)
]
⏟
ξ
e
s
t
(
H
,
I
)
\mathbb{E}[R(h_I)-R(\hat h)]=\underbrace{\mathbb{E}[R(h^*)-R(\hat h)]}_{\xi_{app}(\mathcal H)}+\underbrace{\mathbb{E}[R(h_I)-R( h^*)]}_{\xi_{est}(\mathcal H,I)}
E[R(hI)−R(h^)]=ξapp(H)E[R(h∗)−R(h^)]+ξest(H,I)E[R(hI)−R(h∗)]
ξ
a
p
p
(
H
)
\xi_{app}(\mathcal H)
ξapp(H)计算的是在
H
\mathcal H
H能多接近期望最小是
h
^
,
ξ
e
s
t
(
H
,
I
)
\hat h, \xi_{est}(\mathcal H,I)
h^,ξest(H,I)计算的是经验风险可以多接近在
H
\mathcal H
H上的期望风险。
不可靠的经验风险最小化(Unreliable Empirical Risk Minimizer)
h
^
,
ξ
e
s
t
(
H
,
I
)
\hat h, \xi_{est}(\mathcal H,I)
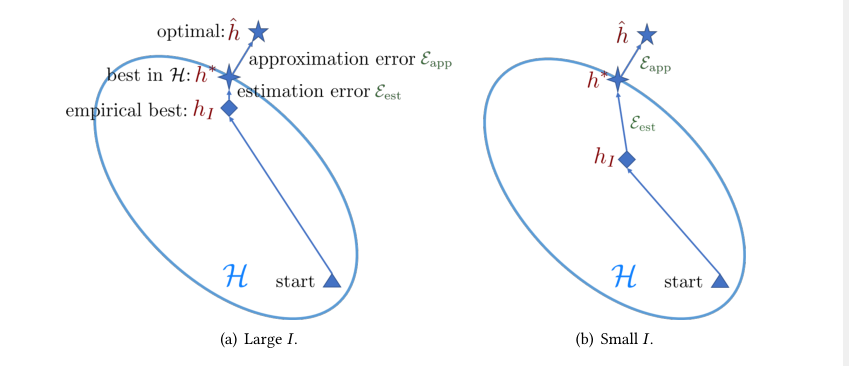
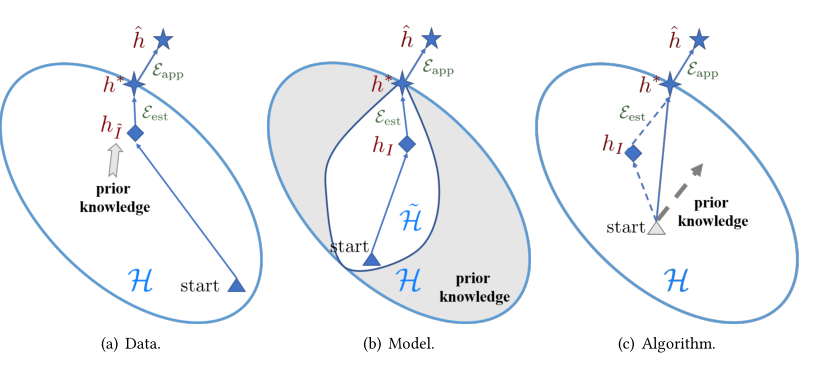
h^,ξest(H,I)可以通过增大I来进行减少,但是在小样本学习中I很小,所以经验风险离期望风险很远,这就是小样本学习中的核心问题,用下图进行表示。
解决方法
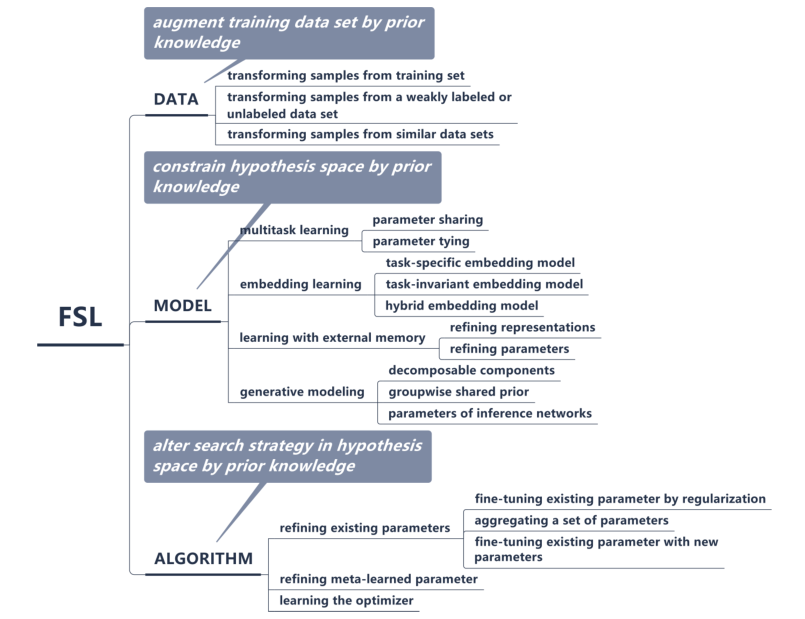
根据上面的误差计算公式,我们可以发现,减少误差有三种方法
增大I样本数量
改善模型,缩小
H
\mathcal H
H的范围
改进算法,使搜索
h
I
∈
H
h_I \in \mathcal H
hI∈H更优,初始化
h
∗
h^*
h∗更接近
h
^
\hat h
h^
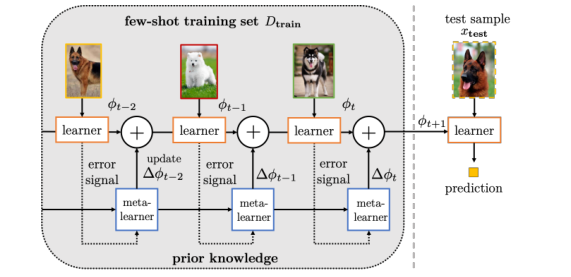
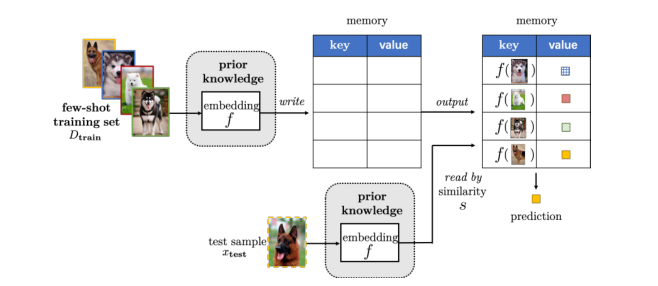
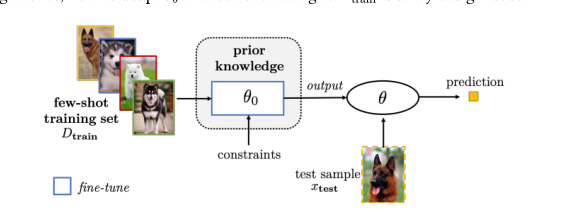
嵌入学习:将每一个例子embed(嵌入)一个低维,这样相似的样本靠的很近,而不同的样本则更容易区分。同时可以构造更小的假设空间KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲H。嵌入学习主要从先验知识中学习。

![(img-Ko80GD2k-1637941610952)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20211126233009988.png)]](https://img-blog.csdnimg.cn/9f7e4efe58564a8292be977d4887765e.png?x-oss-process=,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5LqR5rqq6b6Z,size_20,color_FFFFFF,t_70,g_se,x_16)