在很多场合中,没有必要从头开始训练整个卷积网络(随机初始化参数),因为没有足够丰富的数据集,而且训练也是非常耗时、耗资源的过程。通常,采用pretrain a ConvNet的方式,然后用ConvNet作为初始化或特征提取器。有两种迁移学习,对应着不同的应用场景。
- 微调ConvNet:使用已有的model参数代替随机初始化参数进行训练。
- ConvNet做为特征提取器:我们需要冻结所有的网络权重的更新,最后一层(全连接层)除外。通常,最后一个全连接层是需要根据需求进行修改,并使用一个新的随机权重进行训练。显然,整个网络只有这个层被训练。
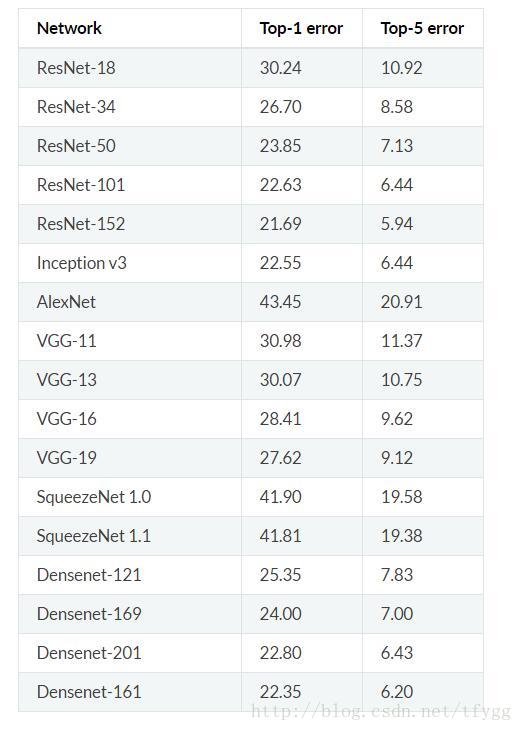
pytorch提供了很多pre-trained models,如下:
下面以cifar10为例,cifar10有10类图像 ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')。我们将采用采用第二种方式,修改resnet-18的全连层,以达到cifar10识别目的。
加载数据
print('==> Preparing data..')
transform_train = transforms.Compose([
#transforms.RandomCrop(224, padding=4),
transforms.Scale(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.Scale(224),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='../data/cifar', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=args.batch_size, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='../data/cifar', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=args.test_batch_size, shuffle=False, num_workers=2)
加载并修改模型
# ConvNet
model_ft = models.resnet18(pretrained=True)
print(model_ft)
for i, param in enumerate(model_ft.parameters()):
param.requires_grad = False # 冻结参数的更新
num_ftrs = model_ft.fc.in_features #重新定义fc层,此时,会进行参数的更新。
model_ft.fc = nn.Linear(num_ftrs, 10)
print(model_ft)
训练
def train(epoch):
model_ft.train()
for batch_idx, (data, target) in enumerate(trainloader):
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model_ft(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(trainloader.dataset),
100. * batch_idx / len(trainloader), loss.data[0]))
完整代码可以查看:
tfygg/pytorch-tutorials