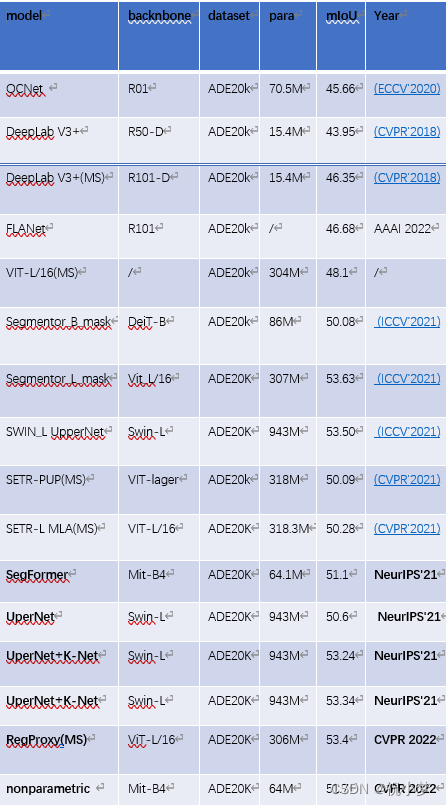
MMSegmentation
MMSegmentation:标准统一的语义分割框架
非常好的分割开源集成框架:
https://link.zhihu.com/?target=https%3A//github.com/open-mmlab/mmsegmentation
研究现状
受到阈值分割方法的启发,在早期图像分割常用传统的阈值分割方法结合具体的使用场景
手动设计特征并调参进行场景分割,基于阈值的二值分割的算法得到广泛应用。这一系列基
于传统图像处理技术的分割方法有着较大的局限性,适用的分割场景也较为简单,容易受到光照环境变化干扰,泛化能力不足。因此阈值分割算法逐渐被基于聚类的方法取代。虽然基于聚类的无监督方法可以获得一定的场景泛化能力来应对光线变化,但仅使用二维图像对复杂场景分割的精度依旧有限且难以进行场景感知,亦存在较多局限性。针对室内场景目标多种多样,各目标之间差异较大,比如有靠椅、有凳子等,传统图像算法难以完整的分割出目标,且难以获得类别标签等更多的信息。近年来,随着GPU 算力的增长以及数据集的完善,基于深度学习的语义分割算法飞速发展,图像分割技术水平大幅提高,可以实现图像像素级分类,目标分割完整度得到大大 提升,进而分割精度得到大大提升Long等人于 2014 年提出了全卷积网络进行语义分割,该网络实现了端到端的逐像素分类,是深度学习语义分割方法的基石。而后,Unet、Deeplab、Pspnet等深度学习相关方法层出不穷。
具体可分为以下几类:完全卷积网络、深度卷积编码-解码架构、采用膨胀(空洞)卷积的多尺度背景分割、用于高分辨率语义分割的多路径细化网络、金字塔场景解析网络。近年来,近一年来,Transformer 在计算机视觉领域所带来的革命性提升,引起了学术界的广泛关注,有越来越多的研究人员投入其中,基于Transfomer的分割方法也在各个数据集上取得了具有强竞争力的实验结果。
SegFormer
论文地址: https://arxiv.org/pdf/2105.15203.pdf
代码: https://github.com/NVlabs/SegFormer
1. 背景
有效感受野:对于语义分割来说最重要的问题就是如何增大感受野,首先对于CNN encoder来说,有效感受野是比较小且局部的,所以需要一些decoder 的设计来增大有效感受野,比如ASPP里利用了不同大小的空洞卷积来实现这一目的。但是对于Transformer encoder来说,由于 self-attention这一牛逼的操作,有效感受野变得非常大,因此decoder 不需要更多操作来提高感受野
2. 模型
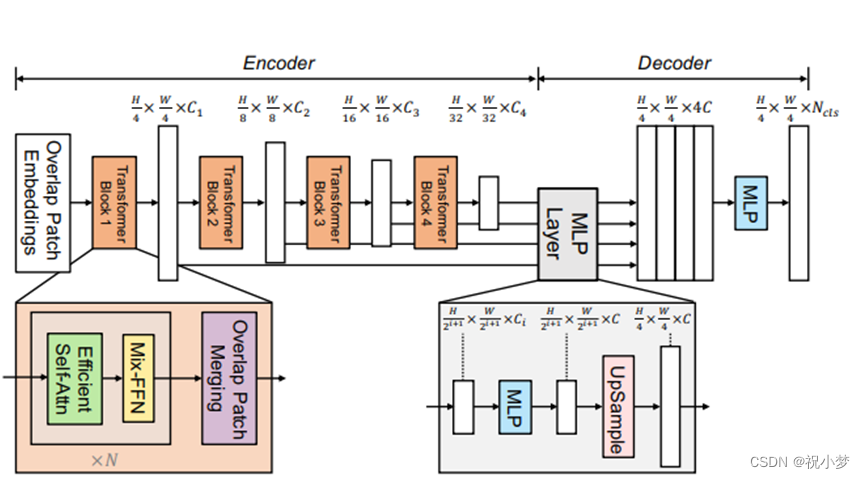
1.使用分层次的encoder结构,输出多尺度的特征,并在decoder中将其融合在一起。这类似于CNN里面将浅层特征图与深层特征图融合的做法,目的是使得高分辨率粗粒度的特征和低分辨率细粒度的特征能一起被捕捉到并优化分割结果
2.设计更加适合语义分割的Transformer Encoder
(1)patch设计成有overlap的,这样可以保证局部连续性
(2)彻底去掉了Positional Embedding, 取而代之的是Mix FFN。
Mix-FFN假设zero padding操作会汇入位置信息, , 即在feed forward network中引入3x3 deepwise conv传递位置信息
3.没有像SETR中那样复杂的decoder
设计简单轻量级的的MLP Decoder
仅有几个MLP 层。首先我们会对不同层的Feature分别过一个linear层确保他们的channel维度一样,其次都上采样到1/4分辨率并concat起来,再用一个linear层融合,最后一个linear层预测结果
3. 实验结果:
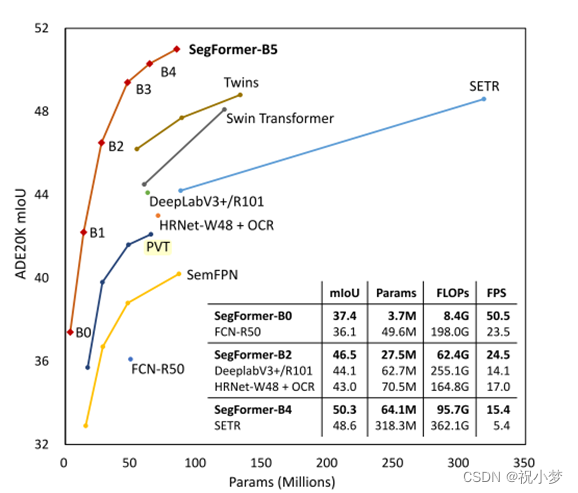
SegFormer不仅在经典语义分割数据集(如:ADE20K, Cityscapes, Coco Stuff)上取得了SOTA的精度同时速度也不错(见图1),而且在Cityscapes-C(对测试图像加各种噪声)上大幅度超过之前的方法(如:DeeplabV3+),反映出其良好的鲁棒性。
此外,作者验证了Segformer对于大型模型和小patch sizes而言,性能更好。分割器在语义分割上取得了极好的效果。
segmentor:Transformer for Semantic Segmentation
代码:https://github.com/rstrudel/segmenter
论文:https://arxiv.org/abs/2105.0563
1. 背景
根据设计,transformer 可以捕获场景元素之间的全局交互,并且没有内置的感应先验,然而,全局交互的建模需要二次方成本,这使得这些方法在应用于原始图像像素时非常昂贵。继 Vision Transformers (ViT) 的最新研究之后,将图像分割成小块,并将线性小块嵌入作为 Transformers 编码器的输入 tokens。然后由 transformer 解码器将编码器产生的上下文化 tokens 序列上采样为逐像素类分数。对于解码,本文考虑一个简单的逐点线性映射的 patch 嵌入到类分数,或者一个基于 transformer 的解码方案,其中可学习的类嵌入与 patch tokens 一起处理以生成类 mask。
2.模型
Segmenter 基于一个完全基于转换器的编码器-解码器架构,它将一系列 patch 嵌入映射到像素级的类注释。模型的概览如图所示。patch 序列由变压器编码器编码,并由mask Transformer 解码。本文的模型采用逐像素交叉熵损失的端到端训练。在推理时,上采样后应用 argmax,获得每个像素单类。解码阶段采用了联合处理图像块和类嵌入的简单方法,解码器Mask Transformer可以通过用对象嵌入代替类嵌入来直接进行全景分割。

3.结果
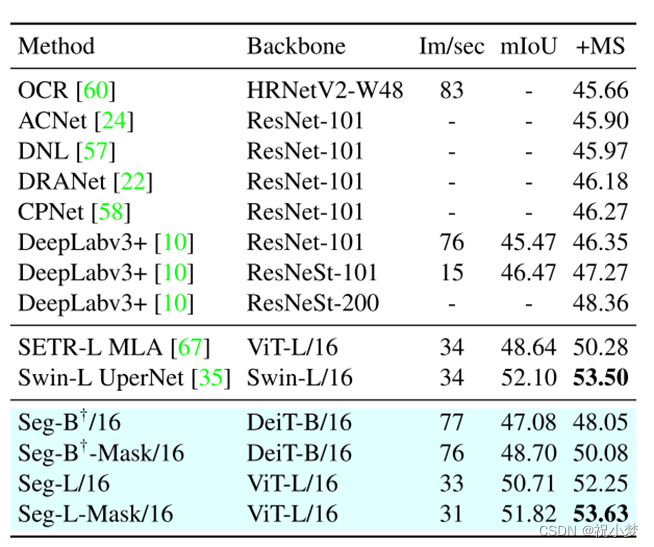
广泛的消融研究了不同参数的影响,特别是性能更好的大模型和小 patch 尺寸。分割器获得了良好的语义分割效果。它在具有挑战性的 ADE20K 数据集上的性能优于现有水平,在Pascal Context 和 Cityscapes 上的性能与现有水平相当。
Maskformer
1.背景
现在的方法通常将语义分割制定为per-pixel classification任务,而实例分割则使用mask classification来处理。
本文作者的观点是:mask classification完全可以通用,即可以使用完全相同的模型、损失和训练程序以统一的方式解决语义和实例级别的分割任务。
提出了一个简单的mask classification模型——MaskFormer,预测一组二进制掩码,每个掩码都与单个全局类标签预测相关联,并且可以将任何现有的per-pixel classification模型无缝转换为mask classification。
掩码分类将分割任务拆分为
1)将图像划分/分组为N个区域(N不需要等于K),用二值掩码表示;
2)将每个区域作为一个整体与 K 个类别的分布相关联。
2. 模型
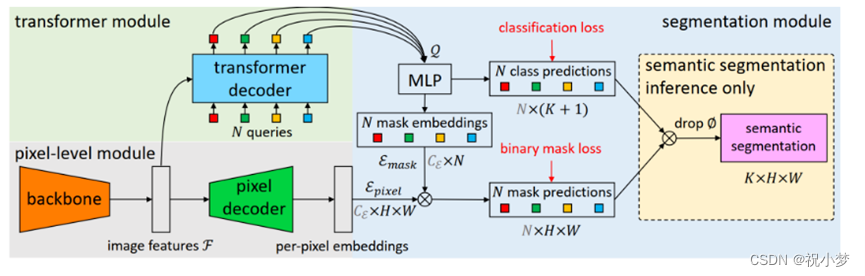
MaskFormer包含三个模块:
1) 像素级模块:用于提取图像特征的backbone和用于生成per-pixel嵌入的像素级解码器;
Backbone可采用 FPN等,经过Backbone之后,对解码器中的低分辨率特征图进行 2× 上采样,并将其与来自主干的相应分辨率的投影特征图(投影是为了与特征图维度匹配,通过1×1 卷积层+GroupNorm实现)相加。 接下来,通过一个额外的 3×3 卷积层+GN+ReLU将串联特征融合。 重复这个过程,直到获得最终特征图。最后,应用单个 1×1 卷积层来获得peri-pixel嵌入。
2) Transformer模块:使用堆叠的Transformer解码器层计算N个per-segment嵌入;
使用标准 Transformer 解码器(与 DETR 相同) 从图像特征 F 和 N 个可学习的位置嵌入(即查询)计算输出N 个per-segments嵌入 Q ,它编码了 MaskFormer 预测的每个段的全局信息。 与 DETR 类似,解码器并行生成所有预测。N 个查询嵌入初始化为零向量且各与一个可学习的位置编码相关联。本文使用 6 个 Transformer 解码器层和 100 个查询,并且在每个解码器之后应用 DETR 相同的损失。实验中,作者观察到 MaskFormer 在使用单个解码器层进行语义分割也相当有竞争力,但在实例分割中多个层对于从最终预测中删除重复项是必要的。
3)分割模块:从上述两个embeddings生成预测结果的概率-掩码对。
使用一个带softmax 激活的线性分类器,在per-segments嵌入 Q 上产生类概率预测。且预测一个额外的“无对象”类别 (∅) 来防止嵌入不对应任何区域。
对于Mask预测,使用包含 2 个隐藏层的多层感知器 (MLP) 将per-segments嵌入 Q 转换为 N 个Mask嵌入 Emask。
最后,通过计算的第 i 个Mask嵌入和per-pixel嵌入之间的点积获得对应的二值掩码预测 mi(点积后使用 sigmoid 激活)
3.实验结果
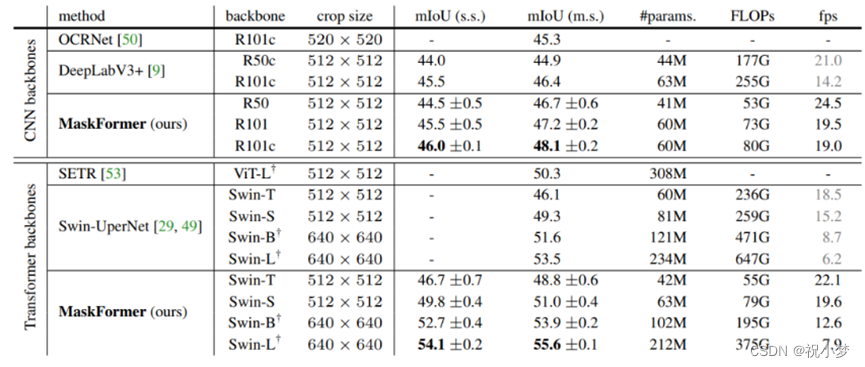
MaskFormer 的性能优于SOTA的语义分割模型(ADE20K 上的 55.6 mIoU)和全景分割模型(COCO 上的 52.7 PQ),特别是类别数量很大时, MaskFormer不仅结果更好,而且速度更快参数更少。
总结