目录
前言
AlexNet搭建
模型架构
卷积神经网络输出
层设置
模型代码
数据集定义加载
自定义数据集
数据集定义代码
读取txt文件
处理加载数据集
数据集加载代码
训练测试
训练过程
测试过程
前言
AlexNet模型是2012由Alex等人在ImageNet竞赛中提出,很优秀的机器学习分类的算法。也由此深度学习开始迅速发展,更多更深的神经网络被提出。在对一个简单图像分类任务下手时,我们要考虑到数据集的定义加载,然后搭建模型并对数据集进行训练测试。本文将讲一下其过程和遇到的一些问题。
AlexNet搭建
模型架构
在模型最初被提出时,其结构如下图所示:

该模型主要有以下几个优点:
(1)首次利用GPU进行网络加速训练;
(2)使用了Relu激活函数(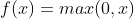 ),而不是传统的sigmoid和tanh函数,训练速度有了较大提升;
),而不是传统的sigmoid和tanh函数,训练速度有了较大提升;
(3)提出了LRN(局部响应归一化)层,抑制了反馈较小的神经元,增强了模型的泛化能力;
(4)使用了Dropout和数据增强进而有效减少过拟合发生。
卷积神经网络输出

- 输入图片大小 W×W(一般情况下Width=Height)
- Filter大小F×F
- 步长 S
- padding的像素数 P
下面以AlexNet第一层卷积层、池化层为例:
#卷积层1
nn.Conv2d(in_channels=3, out_channels=48, kernel_size=11, stride=4,padding=0), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True), # 直接修改覆盖原值,节省运算内存
#池化层1
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
#全连接层1
nn.Dropout(p=0.5), # Dropout 随机失活神经元,默认比例为0.5
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
卷积层1的几个参数:
in_channels=3:表示的是输入的通道数,由于是RGB型的,所以通道数是3
out_channels=96:表示的是输出的通道数,设定输出通道数的96(这个是可以根据自己的需要来设置的)
kernel_size=11:表示卷积核的大小是11x11的,也就是上面的 “F”, F=11
stride=4:表示的是步长为4,也就是上面的S, S=4
padding=0:表示的是填充值的大小为2,也就是上面的P, P=2
假定图像输入大小为224*224,根据计算公式可以算得Output=55,那么输出的size即为55*55。通道数则为自己设定的数值。
通过全连接层我们看到里面使用了Dropout。该层包含权重向量和激活函数,将一个图片先拉伸为一向量作为输入,与权重向量点乘后再通过激活函数进一步输出。
层设置
cove1d:用于文本数据,只对宽度进行卷积,对高度不进行卷积
cove2d:用于图像数据,对宽度和高度都进行卷积
maxpool意为最大池化层,MaxPoold即为二维最大池化操作。池化层用于特征融合和降维。
模型代码
def __init__(self, num_classes=63, init_weights=False):
super(AlexNet, self).__init__()
# 用nn.Sequential()将网络打包成一个模块,精简代码
self.features = nn.Sequential( # 卷积层提取图像特征
#卷积层1
nn.Conv2d(3, 48, kernel_size=11, stride=4), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True), # 直接修改覆盖原值,节省运算内存
#池化层1
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
#卷积层2
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
#池化层2
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
#卷积层3
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
#卷积层4
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
#卷积层5
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
#池化层3
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential( # 全连接层对图像分类
#全连接层1
nn.Dropout(p=0.5), # Dropout 随机失活神经元,默认比例为0.5
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
#全连接层2
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
#全连接层3
nn.Linear(2048, num_classes),
)
# if init_weights:
# self._initialize_weights()
# 前向传播过程
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1) # 展平后再传入全连接层
x = self.classifier(x)
return x
数据集定义加载
自定义数据集
untils.data包括Dataset和Dataloader,前者为一抽象类。自己定义的数据集需要继承抽象类class torch.utils.data.Dataset,并且需要重载两个重要的函数:__len__ 和__getitem__。
def getitem(self, index):
def len(self):
其中__len__应该返回数据集的大小,而__getitem__应该编写支持数据集索引的函数
这里重点看 getitem函数,getitem接收一个index,然后返回图片数据和标签,这个index通常指的是一个list的index,这个list的每个元素就包含了图片数据的路径和标签信息。
数据集中包括两个文件夹,一个是图片(image),一个是标签(label)。我们需要将其一一对应,那这时就有两种方法。一种是读取标签信息所在的txt,对于图片名称加上路径再和label拼接组成一个txt;另一种方法则是读取图片所在的文件夹,读取图片路径后然后根据图片名称在标签信息txt中筛选找到对应的label然后组成一个新的txt。新的txt就可以作为数据集被读取加载。
数据集定义代码
# *************************************数据集的设置****************************************************************************
root = os.getcwd() + '/data/' # 数据集的地址
# 定义读取文件的格式
def default_loader(path):
return Image.open(path).convert('RGB') #对于彩色图像返回RGB,对于灰度图像模式为L
class MyDataset(Dataset):
# 创建自己的类: MyDataset,这个类是继承的torch.utils.data.Dataset
# ********************************** #使用__init__()初始化一些需要传入的参数及数据集的调用**********************
def __init__(self, txt,mulu, transform=None, target_transform=None, loader=default_loader):
super(MyDataset, self).__init__()
# 对继承自父类的属性进行初始化
fh = open(txt,'r')
imgs = []
# 按照传入的路径和txt文本参数,以只读的方式打开这个文本
for line in fh: # 迭代该列表#按行循环txt文本中的内
line = line.strip('\n')
line = line.rstrip('\n')
# 删除 本行string 字符串末尾的指定字符,这个方法的详细介绍自己查询python
words = line.split()
words[0] = './data/'+str(mulu)+'/'+str(words[0]) + '.JPG'
# 用split将该行分割成列表 split的默认参数是空格,所以不传递任何参数时分割空格
imgs.append((words[0], int(words[4])))
#根据原本txt的内容,words[0]是图片信息,words[4]是lable
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index): # 这个方法是必须要有的,用于按照索引读取每个元素的具体内容
fn, label = self.imgs[index] # fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[4]的信息
# print(fn)
# img = Image.open(fn)
img = self.loader(fn) # 按照路径读取图片
if self.transform is not None:
img = self.transform(img) # 数据标签转换为Tensor
return img, label # return回哪些内容,那么我们在训练时循环读取每个batch时,就能获得哪些内容
def __len__(self): # 这个函数它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分
return len(self.imgs)
读取txt文件
open函数使用:open(name[, mode[, buffering]])
-
name : 一个包含了你要访问的文件名称的字符串值。
-
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
-
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
fh=oprn(txt,'r')其中r代表以只读的方式打开文件。读取的时候逐行读取,删除首尾的换行符,由于原txt第一列是图片名称,第五列是label,所以在给第一列加上路径信息后即可和第五列进行拼接。输出的imgs即为我们想要得到的信息。
处理加载数据集
在导入数据集时我们要对其进行预处理,然后进一步加载。 处理过程有很多种方法,包括裁剪、翻转、加入噪声等方法。通过调用untils.data.Dataloader可以加载数据集。关于Dataloader的使用还涉及到下面几个参数:
batch_size:可以分批次读取
shuffle=True可以对数据进行随机读取,可以对数据进行洗牌操作(shuffling),打乱数据集内数据分布的顺序
num_workers=0 可以并行加载数据(利用多核处理器加快载入数据的效率
数据集加载代码
#数据预处理
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(227), # 随机裁剪,再缩放成 224×224
transforms.RandomHorizontalFlip(p=0.5), # 水平方向随机翻转,概率为 0.5, 即一半的概率翻转, 一半的概率不翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"test": transforms.Compose([transforms.Resize((227, 227)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
#导入训练集并进行预处理
train_data = MyDataset(txt=root+'IR1_05-17.txt',mulu='img_05-17', transform=data_transform["train"])
train_num = len(train_data)
print(train_num)
#导入测试集并进行预处理
test_data = MyDataset(txt=root+'IR1_18.txt',mulu='img_2018', transform=data_transform["test"])
test_num = len(test_data)
print(test_num)
#print(test_data[1])
#加载训练集
train_loader = DataLoader(train_data, # 导入的训练集
batch_size=64, # 每批训练的样本数
shuffle=True, # 是否打乱训练集
num_workers=0) # 使用线程数,在windows下设置为0
#加载测试集
test_loader = DataLoader(test_data, # 导入的测试集
batch_size=64, # 每批测试的样本数
shuffle=True, # 是否打乱测试集
num_workers=0) # 使用线程数,在windows下设置为0
训练测试
在这个过程中,要注意以下两点:
-
net.train():训练过程中开启 Dropout
-
net.eval(): 测试过程关闭 Dropout
训练过程
神经网络模型训练是经过前向传播计算Loss,根据其值进行反向推导,然后调整优化参数。下面损失函数选用了交叉熵误差。同时还保存了模型,以便在测试过程中加载模型,这样就可以将训练和测试独立,方便测试。
net = AlexNet(num_classes) # 实例化网络(输出类型)
net.to(device) # 分配网络到指定的设备(GPU/CPU)训练
loss_function = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.Adam(net.parameters(), lr) # 优化器(训练参数,学习率)
s_path = './lunwen.pkl'
best_acc = 0.0
for epoch in range(63):
########################################## train ###############################################
net.train() # 训练过程中开启 Dropout
running_loss = 0.0 # 每个 epoch 都会对 running_loss 清零
time_start = time.perf_counter() # 对训练一个 epoch 计时
for step, data in enumerate(train_loader, start=0): # 遍历训练集,step从0开始计算
images, labels = data # 获取训练集的图像和标签
#print(images.size())
optimizer.zero_grad() # 清除历史梯度
outputs = net(images.to(device)) # 正向传播
loss = loss_function(outputs, labels.to(device)) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
running_loss += loss.item()
# 打印训练进度(使训练过程可视化)
rate = (step + 1) / len(train_loader) # 当前进度 = 当前step / 训练一轮epoch所需总step
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
print('%f s' % (time.perf_counter() - time_start))
torch.save(net, s_path)
测试过程
当图片经过模型输出outputs是一个不同类别对应的概率矩阵,假定类别为63类,那么outputs第一行就代表第一张图的被预测成0-62类的概率 ,可经过softmax进一步确定。torch.max()输出值最大的位置,假使它和原标签一致,那么便预测准确,再比上总数即可得到准确率。
其性能可看MAE和RMSE,在sklearn中均有相应函数,当然注释中也根据其定义写了一段代码。
#加载模型
net=torch.load('./lunwen.pth')
net.to(device) # 分配网络到指定的设备(GPU/CPU)训练
net.eval() # 验证过程中关闭 Dropout
best_acc = 0.0
pre=[]
lab=[]
acc = 0.0
with torch.no_grad():
for test_data in test_loader:
test_images, test_labels = test_data
#print(test_labels)
num_test = test_labels.cpu().numpy()
#print(num_test)
lab.extend(num_test)
#print(test_labels.item())
outputs = net(test_images.to(device))
#print(outputs.size())
#print(outputs)
predict_y = torch.max(outputs, dim=1)[1] # 以output中值最大位置对应的索引(标签)作为预测输出
#print(predict_y.size())
#print(predict_y)
num_y = predict_y.cpu().numpy()
#print(num_y)
pre.extend(num_y)
#y = torch.max(outputs, dim=1)[0]
#mse = mean_squared_error(test_labels, predict_y)
#print("MSE: %.4f" % mse)
#print(y,predict_y,test_labels)
acc += (predict_y == test_labels.to(device)).sum().item()
print(acc)
test_accurate = acc / test_num
# 保存准确率最高的那次网络参数
if test_accurate > best_acc:
best_acc = test_accurate
print(lab)
print(pre)
# error = []
# for i in range(len(lab)):
# error.append(lab[i] - pre[i])
# squaredError = []
# absError = []
# for val in error:
# squaredError.append(val * val) # target-prediction之差平方
# absError.append(abs(val)) # 误差绝对值
# print("1MSE = ", sum(squaredError) / len(squaredError)) # 均方误差MSE
# print("1RMSE = ", sqrt(sum(squaredError) / len(squaredError))) # 均方根误差RMSE
# print("1MAE = ", sum(absError) / len(absError)) # 平均绝对误差MAE
mae = mean_absolute_error(lab,pre)
mse = mean_squared_error(lab, pre)
rmse = math.sqrt(mse)
print("MAE: %.2f MSE: %.2f RMSE:%.2f" %(mae,mse,rmse) )
print(' test_accuracy: %.3f \n' %test_accurate)