目录
RF概念
RF算法流程
RF算法的优缺点
RF算法使用实现
RF应用
RF概念
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器 决策树的详解见链接决策树---ID3算法、C4.5算法、CART算法_xiaoming1999的博客-CSDN博客
RF = 决策树+bagging+随机属性选择
RF算法流程
- 样本的随机:从样本集中用bagging的方式,随机选择n个样本。
- 特征的随机:从所有属性d中随机选择k个属性(k<d),然后从k个属性中选择最佳分割属性作为节点建立CART决策树。
- 重复以上两个步骤m次,建立m棵CART决策树。
- 这m棵CART决策树形成随机森林,通过投票表决结果,决定数据属于哪一类。
RF算法的优缺点
优点:
- 不用做特征选择
- 它可以判断特征的重要程度
- 可以判断出不同特征之间的相互影响
- 对于不平衡的数据集来说,它可以平衡误差。
- 如果有很大一部分的特征遗失,仍可以维持准确度。
缺点:
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
RF算法使用实现
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#载入数据
data = np.genfromtxt("LR-testSet2.txt",delimiter=',')
x_data = data[:,:-1]
y_data = data[:,-1]
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
#划分数据
x_train,x_test,y_train,y_test = train_test_split(x_data,y_data,test_size = 0.5)
#画图函数
def plot(model):
#获取数据值所在的范围
x_min,x_max = x_data[:,0].min()-1,x_data[:,0].max()+1
y_min,y_max = x_data[:,1].min()-1,x_data[:,1].max()+1
#生成网格矩阵
xx,yy = np.meshgrid(np.arange(x_min,x_max,0.02),
np.arange(y_min,y_max,0.02))
z = model.predict(np.c_[xx.ravel(),yy.ravel()])
z = z.reshape(xx.shape)
#等高线图
cs = plt.contourf(xx,yy,z)
#画散点图
plt.scatter(x_test[:,0],x_test[:,1],c=y_test)
plt.show()
#只用决策树
dtree = tree.DecisionTreeClassifier()
dtree.fit(x_train,y_train)
plot(dtree)
#用随机森林
RF = RandomForestClassifier(n_estimators = 100)
RF.fit(x_train,y_train)
plot(RF)
RF.score(x_test,y_test)
dtree.score(x_test,y_test)
结果显示如下
决策树结果: 随机森林结果:
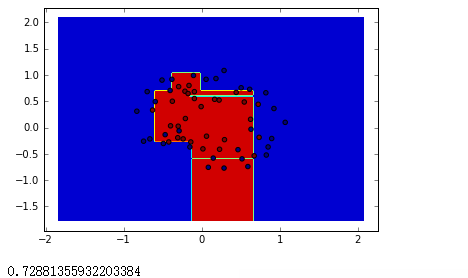

在一般情况下随机森林一般准确性比较高一些,但也不排除其他情况,随机森林的结果可能很差。
RF应用
- 对离散值的分类
- 对连续值的回归
- 无监督学习聚类
- 异常点检测