第1章 实验基本信息
1.1 实验目的
熟练掌握计算机系统的数据表示与数据运算;
通过C程序深入理解计算机运算器的底层实现与优化;
掌握VS/CB/GCC等工具的使用技巧与注意事项。
1.2 实验环境与工具
1.2.1 硬件环境
x64 CPU;1.60GHz;8G RAM;256GHD Disk。
1.2.2 软件环境
Windows10 64位。
1.2.3 开发工具
VM VirtualBox 6.1;Ubuntu 20.04 LTS 64位;
Visual Studio 2019 64位;CodeBlocks 17.12 64位;vi/vim/gedit+gcc。
1.3 实验预习
上实验课前,必须认真预习实验指导书(PPT或PDF)
了解实验的目的、实验环境与软硬件工具、实验操作步骤,复习与实验有关的理论知识。
采用sizeof在Windows的VS/CB以及Linux的CB/GCC下获得C语言每一类型在32/64位模式下的空间大小。
Char /short int/int/long/float/double/long long/long double/指针。




编写C程序,计算斐波那契数列在int/long/unsigned int/unsigned long类型时,n为多少时会出错 (linux-x64)。
Int:47;long:47;unsigned int:48;unsigned long:48。
先用递归程序实现,会出现什么问题?程序执行速度较慢,n较大时需要很长时间才能计算出来,程序好像停止一样。
再用循环方式实现。见6.1、6.2
写出float/double类型最小的正数、最大的正数(非无穷)。
float最大正数:0 11111110 11111111111111111111111,
即(2-2^-(23))*2^(254-127)= 3.4028234663852886*10^38.
float最小正数:0 00000001 00000000000000000000000,
即1*2^(1-127)=1.18*10^(-38).
同理,
double最大正数:1.79769*10^(308);
double最小正数:2.22507*10^(-308).
按步骤写出float数-10.1在内存从低到高地址的字节值-16进制。
9a 99 21 c1
按照阶码区域写出float的最大密度区域范围及其密度,最小密度区域及其密度(表示的浮点数个数/区域长度)。
-(2-2^-23)*2^-126~(2-2^-23)*2^-126 ,
2*(1-2^(-23))*2^(-126)/2*2^23;
-(2-2^-23)*2^127~2^127 和 2^127~(2-2^-23)*2^127 ,
2*(2-2^(-23)*2^(127)/2*(2^8-1)*2^23.
第2章 实验环境建立
2.1 Ubuntu下CodeBlocks安装
CodeBlocks运行界面截图:编译、运行hellolinux.c
 图2-1 Ubuntu下CodeBlocks截图
图2-1 Ubuntu下CodeBlocks截图
2.2 64位Ubuntu下32位运行环境建立
在终端下,用gcc的32位模式编译生成hellolinux.c。执行此文件。
Linux及终端的截图。
 图2-2 Ubuntu与Windows共享目录截图
图2-2 Ubuntu与Windows共享目录截图
第3章 C语言的数据类型与存储
3.1 类型本质
|
Win/VS/x86 |
Win/VS/x64 |
Win/CB/32 |
Win/CB/64 |
Linux/CB/32 |
Linux/CB/64 |
| char |
1 |
1 |
1 |
1 |
1 |
1 |
| short |
2 |
2 |
2 |
2 |
2 |
2 |
| int |
4 |
4 |
4 |
4 |
4 |
4 |
| long |
4 |
4 |
4 |
4 |
4 |
8 |
| long long |
8 |
8 |
8 |
8 |
8 |
8 |
| float |
4 |
4 |
4 |
4 |
4 |
4 |
| double |
8 |
8 |
8 |
8 |
8 |
8 |
| long double |
8 |
8 |
12 |
16 |
12 |
16 |
| 指针 |
4 |
8 |
4 |
8 |
4 |
8 |
C编译器对sizeof的实现方式:____sizeof是一个宏,而非函数,编译阶段编译器将其替换掉______
3.2 数据的位置-地址
打印x、y、z输出的值:截图1
反汇编查看x、y、z的地址,每字节的内容:截图2,标注说明
反汇编查看x、y、z在代码段的表示形式。截图3,标注说明
x与y在__汇编__阶段转换成补码与ieee754编码。
数值型常量与变量在存储空间上的区别是:_____全局变量和静态局部变量储存在数据段,局部变量储存在堆栈段_______
字符串常量与变量在存储空间上的区别是:___字符串常量储存在代码段,全局变量和静态局部变量储存在数据段,局部变量储存在堆栈段_______
常量表达式在计算机中处理方法是:_______在编译阶段求值并储存________



3.3 main的参数分析
反汇编查看x、y、z的地址,argc的地址,argv的地址与内容,截图4


3.4 指针与字符串的区别
cstr的地址与内容截图,pstr的内容与截图,截图5
pstr修改内容会出现什么问题_____出现段错误,因为ptsr指向的字符串储存在常量区,不可进行修改_________

第4章 深入分析UTF-8编码
4.1 提交utf8len.c子程序
见附件
4.2 C语言的strcmp函数分析
分析论述:strcmp到底按照什么顺序对汉字排序
(1)猜测


可以看出“一”和“丁”的unicode编码非常接近,虽然两个汉字拼音相差较多。所以可以猜测unicode对汉字的编码按照部首偏旁排序。
(2)采用控制变量法进行验证



从图中可以看出,“范”和“茄”部首偏旁相近,拼音不同,但是编码只差1;“范”与“饭”拼音相同但部首偏旁不同,但编码相差较大。因此unicode对汉字编码按照部首排序。
4.3讨论:按照姓氏笔画排序的方法实现
分析论述:应该怎么实现呢?
- 将所有姓氏按笔画从小到大排序,将笔画相同的姓汉字归为一类,得到笔画从少到多的姓氏汉字类,每个类中汉字笔画数相同。
- 对每个类内的汉字进行排序。按照康熙字典中笔画先后对笔画的优先级排序,先比较两个字的第一个笔画,再比较下一个,以此类推。
- 若两个字笔画种类、数量及顺序都相同,按照汉字本身unicode编码的优先级排序。
构造此编码后使其与unicode的汉字编码一一对应,将此排序映射到unicode编码上,使用按姓氏笔画排序完毕后,将其转换为unicode编码。
第5章 数据变换与输入输出
5.1 提交cs_atoi.c
见附件
5.2 提交cs_atof.c
见附件
5.3 提交cs_itoa.c
见附件
5.4 提交cs_ftoa.c
见附件
5.5 讨论分析OS的函数对输入输出的数据有类型要求吗
论述如下:
OS使用read/write函数输入输出,在头文件#include<unistd.h>中,从打开的文件或设备读取/写入数据。
ssize_t read(int fd ,void *buf ,size_t count)
fd:文件描述符 ,buf:读出数据缓冲区 ,count:读取字节数
返回:成功返回读取字节数,失败返回-1,错误代码存入errno,提前读完数
据返回0.
ssize_t write(int fd ,void *buf ,size_t count)
fd:文件描述符 ,buf:读出数据缓冲区 ,count:写入字节数
返回:成功返回写入字节数,失败返回-1,错误代码存入errno.
利用write/read进行输入输出时,文件描述符使用已经打开的文件描述符:标准输入0、标准输出1、标准错误2。
write/read函数需要程序员管理数据缓冲区,缓冲区一般为字符数组,将输入输出转化为字符串进行读和写。故write/read函数对输入和输出的数据类型没有要求。
第6章 整数表示与运算
6.1 提交fib_dg.c
见附件
6.2 提交fib_loop.c
见附件
6.3 fib溢出验证
int 时从n=__47___时溢出,long时n=___47__时溢出。
unsigned int 时从n=___48___时溢出,unsigned long时n=___48___时溢出。
6.4 除以0验证:
除以0:截图1

除以极小浮点数,截图:

6.5 万年虫验证
你的机器到9999年12月31日23:59:59后,时钟怎么显示的?Windows/Linux下分别截图:
1.Windows:不允许更改,只能改到2099年

2.Linux:无效的操作,不允许更改

6.6 2038虫验证
2038年1月19日中午11:14:07后你的计算机时间是多少,Windows/Linux下分别截图
1.Windows10:系统出错,闪烁黑屏,任务栏等消失,但控制面板时间更改界面不变化,将时间改回后逐渐恢复正常,但任务栏有部分信息显示错乱
2.Linux:无变化

第7章 浮点数据的表示与运算
7.1手动float编码:
按步骤写出float数-10.1在内存从低到高地址的字节值(16进制)。
编写程序在内存验证手动编码的正确性,截图。
9a 99 21 c1

7.2特殊float数据的处理
提交子程序floatx.c,要求:
构造多float变量,分别存储+0-0,最小浮点正数,最大浮点正数、最小正的规格化浮点数、正无穷大、Nan,并打印最可能的精确结果输出(十进制/16进制)。截图。

7.3验证浮点运算的溢出
提交子程序float0.c
编写C程序,验证C语言中float除以0/极小浮点数后果,截图
除以0,截图:

除以极小浮点数,截图:

7.4 类型转换的坑
实验指导PPT第5步骤的x变量,执行 x=(int)(float)x 后结果为多少?
原x=____1190201308_____,现x=______1190201344_________
7.5 讨论1:有多少个int可以用float精确表示
有____1769996287____个int数据可以用float精确表示。
是哪些数据呢?____绝对值小于2^(24)的整数或绝对值大于2^(24)但尾数在23位之后全为0的数据_________
7.6 讨论2:怎么验证float采用的向偶数舍入呢
基于上个讨论,开发程序或举几个特例用C验证即可!
截图与标注说明!
构造两个整数,其需要用24位尾数表示,而由于浮点数只能表示23位尾数,需要进行舍入。如下构造两个二进制整数,令其从左数23位分别为0和1,并令其从左数24位为1(1即00),即为舍入可能结果的中间值,方便进行舍入验证。
构造时计算其十进制和十六进制的值,十进制方便进行赋值,十六进制方便进行比较验证,对于十六进制我们只关心最低的字节的变化,因为其他高字节可能影响十六进制的值。
1101010101010101010101011


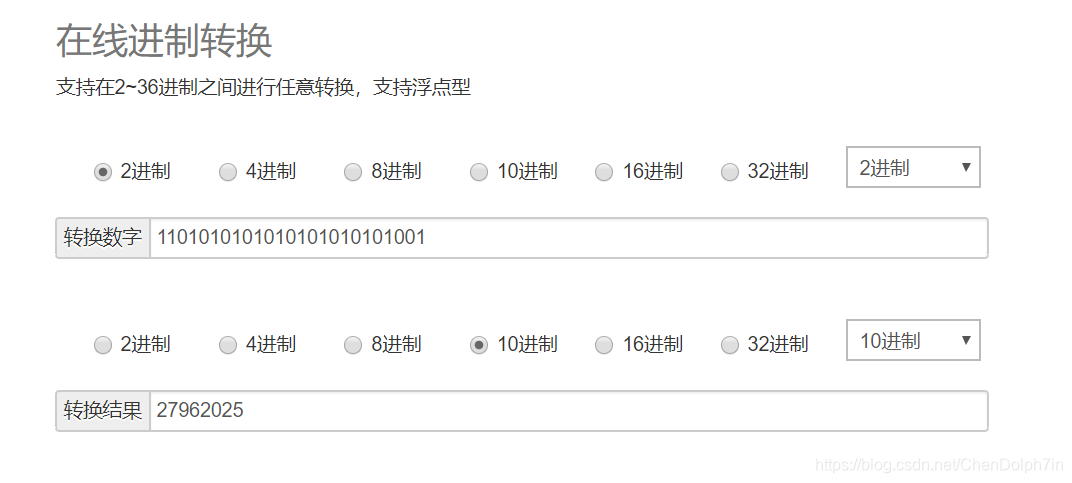


对于第一个数即图中的a,其最低字节为0101 0101 (100),舍入时100进位变为0101 0110,即图中的最低为变为56,而不是上面图中转换的55,即可排除向下舍入。

对于第二个数即图中的b,其最低字节为0101 0100 (100),由于舍入变为0101 0100,即图中54,没变,而不是十六进制转换过来的55,可以排除向上舍入。 综上可以推断出浮点数使用的舍入原则是向偶舍入。
7.7 讨论3:float能精确表示几个1元内的钱呢
人民币0.01-0.99元之间的十进制数,有多少个可用float精确表示?是哪些呢?
83个,0.01~0.83之间的数字,包括0.01和0.83。
7.8 Float的微观与宏观世界
按照阶码区域写出float的最大密度区域的范围及其密度,最小密度区域及其密度(区域长度/表示的浮点个数):__-(1-2^(-23))*2^(-126)~(1-2^(-23))*2^(-126)________、__2*(1-2^(-23))*2^(-126)/2*2^23_________、___-(2-2^(-23))*2^(127)~(2-2^(-23))*2^(127)_________、__2*(2-2^(-23)*2^(127)/2*(2^8-1)*2^23______
微观世界:能够区别最小的变化__2^(-149)___,其10进制科学记数法为__1.401298464325*10^(-45)_______
宏观世界:不能区别最大的变化___2^(150)_____,其10进制科学记数法为____1.427247692706*10(45)_____
7.9 讨论:浮点数的比较方法
从键盘输入或运算后得到的任意两个浮点数,论述其比较方法以及理由。
先确定二者是否在精度范围内相等:使用两者差值的绝对值与精度限制(较小的常数)比较,差值的绝对值小于精度限制则认为二者相等。若由上一步得出二者不相等并需要进一步比较二者绝对大小关系,则简单通过差值的符号确定。
理由:浮点数的二进制表示往往不是精确值,则用浮点数进行比较时,不能简单地使用==进行比较,因为可能出现由于极小误差而导致判断失误的情况出现。这种情况下使用精度限制限制误差的范围,能减小判断错误的情况。
第8章 舍尾平衡的讨论
8.1 描述可能出现的问题
报表时,数字由于单位转换需要进行舍位,而大量数据经过舍位运算后舍去数字的积累可能会导致较大误差的出现。这就需要舍位平衡进行数据平衡关系的调整,减小误差。
8.2 给出完美的解决方案
1.单向舍位平衡
处理数据统计时,每个数据只用于一次合计,则在处理舍位平衡时,只需要根据合计值得误差调整各项数据,下面有几种舍位平衡规则:
(1)将平衡差整理到第一个数据中:先计算数据的平衡差(舍位后数据合计与原数据合计的差的绝对值,即误差),然后将平衡差加到第一个数据上。
(2)将平衡差按照“最小调整值”,对绝对值较大的数据进行分担调整:最小调整值即舍位后最小精度的单位值,例如在取整时,最小精度单位是1,最小调整值就是1或-1。
先计算最小调整个数,使用平衡差除以最小调整值的绝对值,得到调整个数。然后将数据按绝对值大小排序,找到数据绝对值中的最大的需要调整的个数的数。然后在计算数据时将这些数加上最小调整值再计算合计值(如果舍位后合计值比原数据合计值小,则需要将数据调大,最小调整值取1;如果舍位后合计值比原数据合计值大,则需要将数据调小,最小调整值取-1)。
(3)将平衡差按照最小调整值,由不为0的数依次分担。为了提高舍位平衡的效率,尽量少使用花费较多时间的排序过程,故取消按照绝对值大小分配分担,而采用随机采用顺序前n个数据进行分担操作。由于0不会进行舍位运算且对0进行分配会对原数据造成较大影响故跳过0数据的分配操作。
即(2)中舍去排序过程,从数据中取出前n个(最小调整个数)数据进行最小调整值分配。
2.双向舍位平衡
处理数据统计时,数据需要在行方向和列方向进行两次运算合计值,且需要计算总数据合计值。这时当我们修改一个数据的值,在行和列方向的合计值都会受到影响,我们不仅要求总数据合计值准确还要保证行列两个方向的合计值对应准确。这种情况下需要用到双向舍位平衡。
在数据合计过程中,只与合计值相关的平衡差,叫做合计平衡差;而其他的平衡差都与具体数据有关,叫做非合计平衡差。
下面从简单的情况研究双向平衡差:
(1)横向与纵向的非合计平衡差符号相同。不需要调整总合计值,只需要调整合计不平衡行列的交叉点处的数据,根据平衡差加减调整最小值。
(2)同向的两个非合计平衡差符号相反。不需要调整总合计值,若两列的非合计平衡差符号相反,选择一个平衡差为0的行,将这行上的两列的数据进行加减最小调整值;若两行的非合计平衡差符号相反,选择一个平衡差为0的列,将这列上的两行的数据进行加减最小调整值。
(3)某个合计平衡差与另一方向的非合计平衡差符号相反。调整交叉处的合计数据,根据合计平衡差的符号加减最小调整值。
(4)某个合计平衡差与同方向的非合计平衡差符号相同。若两列某个合计平衡差与同方向的非合计平衡差符号相同,任选一平衡差为0的行,同时将行上两个列的数据进行加减最小调整值;若两行某个合计平衡差与同方向的非合计平衡差符号相同,任选一平衡差为0的列,同时将列上两个行的数据进行加减最小调整值。
(5)两个方向合计平衡差的符号相同。任选一个非合计值,根据合计平衡差的符号加减最小调整值,同样调整这个数据的纵向和横向合计值。
代码、附件github地址
https://github.com/ChenDolph7in/HITICS-LABS-in-21-Spring/tree/master/Lab2