PyTorch——开源的Python机器学习库
一、前言
用了Matlab搭建神经网络才愈发感觉"人生苦短,我用PyTorch“是多么正确。毕竟新的神经网络架构还是得自己一点点敲,现在是一点都笑不出来了,指望Matlab提供的老框架和训练算法也做不出什么算法方法的突破,顶多就是在实现功能上方便点罢了。
本博文要求读者有一定的Python编程基础!,对机器学习和神经网络有一定的了解!。如果是零基础学习人群,请参看我之前的Python基础语法博文和人工智能相关博文。读完它们不会花费你太多的时间,并且如果你能做到简单地阅览完这些博文,就完全有足够的知识储备来彻底搞懂这篇博文的全部内容了。
以下贴上我之前写的关于神经网络相关的博文,Python相关的也可以去我的博客主页去找。
[深度学习入门]基于Python的理论与实现[感知机、神经网络、误差反向传播法及相关技巧]
[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数]
二、深度学习框架——PyTorch
2.1 PyTorch介绍
PyTorch是 Facebook 发布的一款深度学习框架,和Tensorflow,Keras,Theano等其他深度学习框架都不同。作为动态计算图模式,其应用模型支持在运行过程中根据运行参数动态改变,而其他几种框架都是静态计算图模式,其模型在运行之前就已经确定。
Python模块可以通过pip安装,临时使用时可以使用下述命令:
pip install pythonModuleName -i
https://pypi.douban.com/simple
也可以永久更改:/root/.pip/pip.conf:
[global]
index-url = https://pypi.douban.com/simple
2.2 Python安装详解
安装Python就略去不写了,都是可视化界面也没什么可说的。安装后查看当前版本:
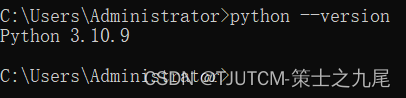
[root@iZ25ix41uc3Z ~]# python --version
Python 3.10.9
下载 setuptools:
wget --no-check-certificate
http://pypi.python.org/packages/source/s/setuptools/setuptools-
解压之后进入目录setuptools-0.6c11
安装python setup.py install
安装 pip,和 setuptools 过程类似:
wget --no-check-certificate
https://github.com/pypa/pip/archive/1.5.5.tar.gz
解压之后进入目录pip-1.5.5
安装python setup.py install
看看 pip 安装是否成功,执行:
pip list
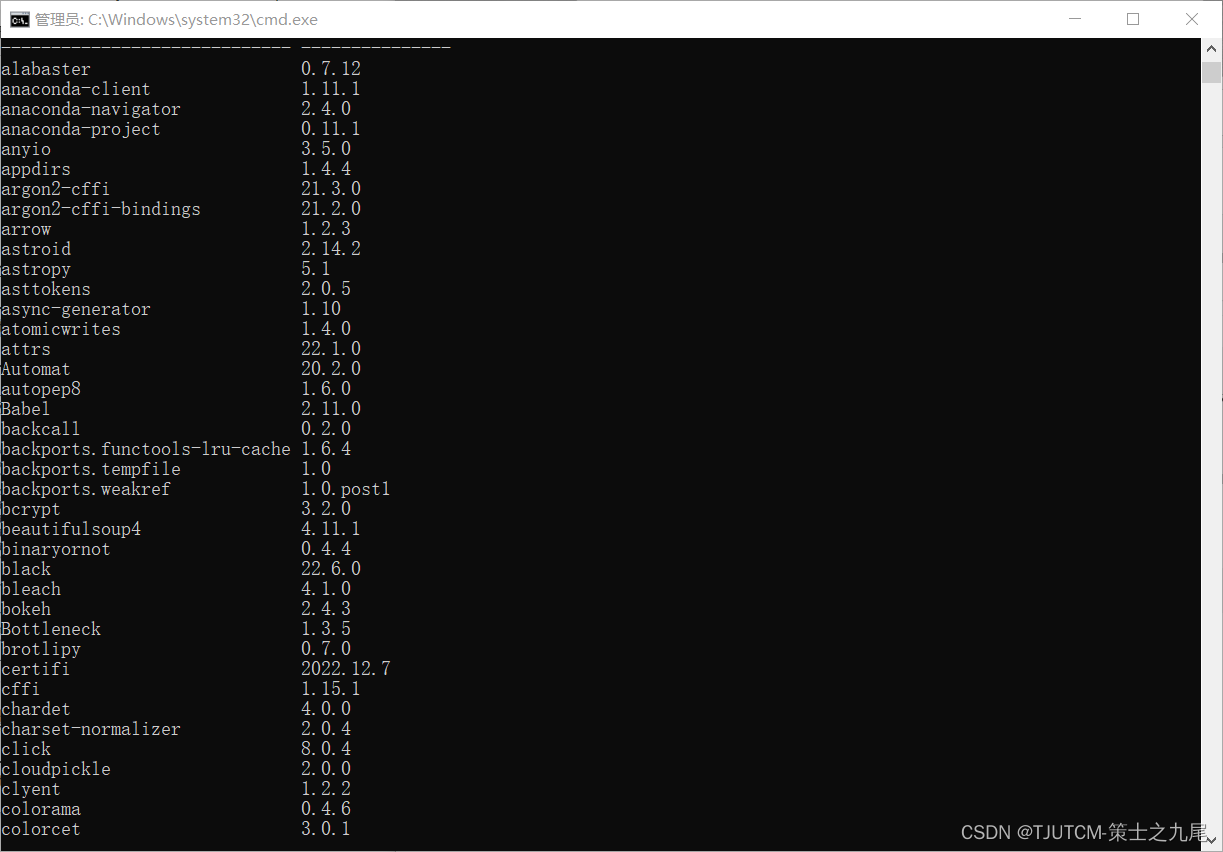
如果显示的不是上方的画面,则我们先安装 openssl:
yum install openssl openssl-devel -y
然后再重新安装 python,别的不用重新安装了。
[root@iZ25ix41uc3Z Python-3.10.9]# pip list
pip (1.5.4)
setuptools (27.3.0)
wsgiref (0.1.2)
最后我们就可以安装 numpy,scipy 等科学计算库了。
pip install numpy
pip install scipy

最后验证一下 numpy:

大功告成,如此一来我们已经成功安装 numpy。
2.3 PyTorch安装详解
先试试看 pip 安装能不能成功。输入命令 pip install pytorch,显示结果如下:

看来PyTorch不支持pip安装,这里提示到 pytorch.org 下载安装,同时,浏览器自动打开网址:
http://pytorch.org/#pip-install-pytorch
跟着上面的安装步骤安装就是了,这里也可以去网上找找安装教程。因为这里不是我们的重点,讲多了也没什么意思。
安装完成后,我们输入命令 python,进入 python 交互环境,写一段 pytorch 程序验证一下是不是安装成功了,这段代码调用 torch 的ones 方法,看看能不能正常显示结果:

看来没什么问题,安装成功了。下面,我们来一步步学习 pytorch 吧。
三、变量
先看看 Tensor,pytorch 中的数据都是封装成 Tensor 来引用的,Tensor实际上就类似于 numpy 中的数组,两者可以自由转换。
我们先生成一个3*4维的数组:
import torch
x = torch.Tensor(3,4)
print("x Tensor: ",x)
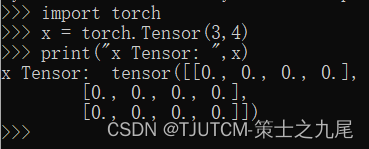
可以看到 torch.Tensor() 方法生成制定维度的随机数。
下面看看 Variable 的基本操作,引用 Variable:
import torch
from torch.autograd import Variable
x=Variable(torch.Tensor(2,2))
print("x variable: ",x)

Variable 不光包含了数据,还包含了其他东西,那么,还包含什么东西呢?
默认 Variable 是有导数 grad 的,x.data 是数据,这里 x.data 就是 Tensor。x.grad 是计算过程中动态变化的导数。
print ("x.data: ",x.data, ",x.grad: ",x.grad)
此时 Variable 还未进行计算,因此 x.grad 为 None。
四、求导
神经网络中的求导的作用是用导数对神经网络的权重参数进行调整。
Pytorch 中为求导提供了专门的包,包名叫autograd。如果用autograd.Variable 来定义参数,则 Variable 自动定义了两个变量:data代表原始权重数据;而 grad 代表求导后的数据,也就是梯度。每次迭代过程就用这个 grad 对权重数据进行修正。

import torch
from torch.autograd import Variable
x = Variable(torch.ones(2, 2), requires_grad=True)
print(x)
输出为:

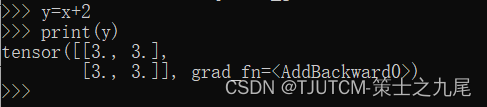
y=x+2
print(y)
输出为:
z = y * y * 3
out = z.mean()
print(z, out)
输出为:

out.backward()
反向传播,也就是求导数的意思。输出 out 对 x 求导:
print(x.grad)
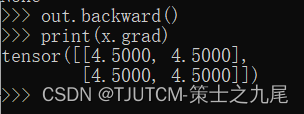
4.5 是怎么算出来的呢,从前面的公式可以看出 z=(x+2) * (x+2) * 3,它的导数是 3 * (x+2) / 2,当 x=1 时导数的值就是 3 * (1+2) / 2=4.5,和 pytorch 计算得出的结果是一致的。
权值更新方法:
weight = weight + learning_rate * gradient
learning_rate = 0.01
for f in model.parameters():
f.data.sub_(f.grad.data * learning_rate)
learning_rate 是学习速率,多数时候就叫做 lr,是学习步长,用步长 * 导数就是每次权重修正的 delta 值,lr 越大表示学习的速度越快,相应的精度就会降低。
五、损失函数
损失函数,又叫目标函数,是编译一个神经网络模型必须的两个参数之一。另一个必不可少的参数是优化器。
损失函数是指用于计算标签值和预测值之间差异的函数,在机器学习过程中,有多种损失函数可供选择,典型的有距离向量,绝对值向量等。
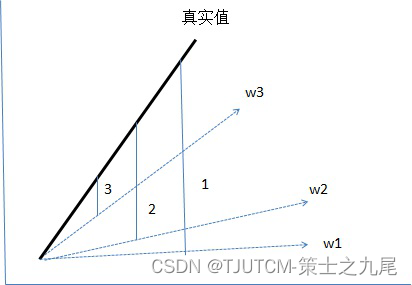
上图是一个用来模拟线性方程自动学习的示意图。粗线是真实的线性方程,虚线是迭代过程的示意,w1 是第一次迭代的权重,w2 是第二次迭代的权重,w3 是第三次迭代的权重。随着迭代次数的增加,我们的目标是使得 wn 无限接近真实值。
那么怎么让 w 无限接近真实值呢?其实这就是损失函数和优化器的作用了。图中 1/2/3 这三个标签分别是 3 次迭代过程中预测 Y 值和真实 Y 值之间的差值(这里差值就是损失函数的意思了,当然了,实际应用中存在多种差值计算的公式),这里的差值示意图上是用绝对差来表示的,那么在多维空间时还有平方差,均方差等多种不同的距离计算公式,也就是损失函数了。
这里示意的是一维度方程的情况,扩展到多维度,就是深度学习的本质了。
下面介绍几种常见的损失函数的计算方法,pytorch 中定义了很多类型的预定义损失函数,需要用到的时候再学习其公式也不迟。
我们先定义两个二维数组,然后用不同的损失函数计算其损失值。
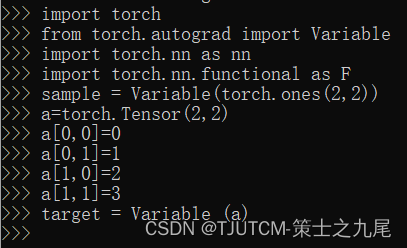
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
sample = Variable(torch.ones(2,2))
a=torch.Tensor(2,2)
a[0,0]=0
a[0,1]=1
a[1,0]=2
a[1,1]=3
target = Variable (a)
sample 的值为:[[1,1],[1,1]]。
target 的值为:[[0,1],[2,3]]。
5.1 nn.L1Loss
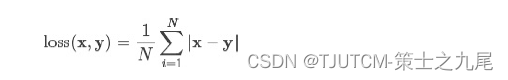
L1Loss 计算方法很简单,取预测值和真实值的绝对误差的平均数即可。
criterion = nn.L1Loss()
loss = criterion(sample, target)
print(loss)

最后的结果为1,计算步骤为:
先计算绝对差总和:|0-1|+|1-1|+|2-1|+|3-1|=4;
然后再平均:4/4=1。
5.2 nn.SmoothL1Loss
SmoothL1Loss 也叫作 Huber Loss,误差在 (-1,1) 上是平方损失,其他情况是 L1 损失。
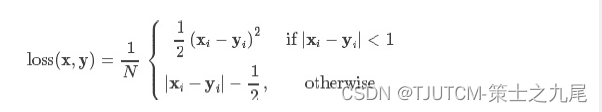
criterion = nn.SmoothL1Loss()
loss = criterion(sample, target)
print(loss)

最后结果是:0.625。
5.3 nn.MSELoss
平方损失函数。其计算公式是预测值和真实值之间的平方和的平均数。

criterion = nn.MSELoss()
loss = criterion(sample, target)
print(loss)

最后结果是:1.5。
5.4 nn.BCELoss
二分类用的交叉熵,其计算公式较复杂,这里主要是有个概念即可,一般情况下不会用到。
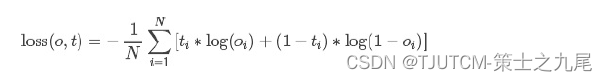
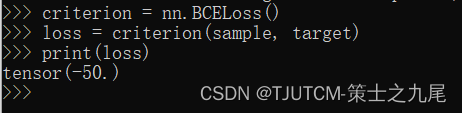
criterion = nn.BCELoss()
loss = criterion(sample, target)
print(loss)
最后结果是:-50。
5.5 nn.CrossEntropyLoss
交叉熵损失函数
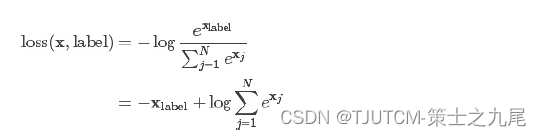
该公式用的也较多,比如在图像分类神经网络模型中就常常用到该公式。
criterion = nn.CrossEntropyLoss()
loss = criterion(sample, target)
print(loss)
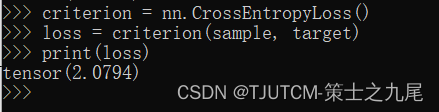
最后结果是:2.0794。
看文档我们知道 nn.CrossEntropyLoss 损失函数是用于图像识别验证的,对输入参数有各式要求,这里有这个概念就可以了,在后续的图像识别方向中会有正确的使用方法。
5.6 nn.NLLLoss
负对数似然损失函数(Negative Log Likelihood)

在前面接上一个 LogSoftMax 层就等价于交叉熵损失了。注意这里的xlabel 和上个交叉熵损失里的不一样,这里是经过 log 运算后的数值。
这个损失函数一般也是用在图像识别模型上。
criterion = F.nll_loss()
loss = criterion(sample, target)
print(loss)
loss=F.nll_loss(sample,target)
最后结果为报错,看来不能直接调用。
Nn.NLLLoss 和 nn.CrossEntropyLoss 的功能是非常相似的。通常都是用在多分类模型中,实际应用中我们一般用 NLLLoss 比较多。

5.7 nn.NLLLoss2d
和上面类似,但是多了几个维度,一般用在图片上。
input, (N, C, H, W)
target, (N, H, W)
比如用全卷积网络做分类时,最后图片的每个点都会预测一个类别标签。

最后结果报错,看来不能直接这么用。
六、优化器Optim
优化器用通俗的话来说就是一种算法,是一种计算导数的算法。
各种优化器的目的和发明它们的初衷其实就是能让用户选择一种适合自己场景的优化器。
优化器的最主要的衡量指标就是优化曲线的平稳度,最好的优化器就是每一轮样本数据的优化都让权重参数匀速的接近目标值,而不是忽上忽下跳跃的变化。因此损失值的平稳下降对于一个深度学习模型来说是一个非常重要的衡量指标。
pytorch 的优化器都放在 torch.optim 包中。常见的优化器有:SGD,Adam,Adadelta,Adagrad,Adamax 等。如果需要定制特殊的优化器,pytorch 也提供了定制化的手段,不过这里我们就不去深究了,毕竟预留的优化器的功能已经足够强大了。
6.1 SGD
SGD 指stochastic gradient descent,即随机梯度下降,随机的意思是随机选取部分数据集参与计算,是梯度下降的 batch 版本。SGD 支持动量参数,支持学习衰减率。SGD 优化器也是最常见的一种优化器,实现简单,容易理解。
6.1.1 用法
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
6.1.2 参数
lr:大于 0 的浮点数,学习率。
momentum:大于 0 的浮点数,动量参数。
parameters:Variable 参数,要优化的对象。
对于训练数据集,我们首先将其分成 n 个 batch,每个 batch 包含 m 个样本。我们每次更新都利用一个 batch 的数据 ,而非整个训练集,即:
xt+1=xt+Δxt
Δxt=-ηgt
其中,η 为学习率,gt 为 x 在 t 时刻的梯度。
6.1.3 好处
这么做的好处在于:
(1)当训练数据太多时,利用整个数据集更新往往时间上不现实。batch的方法可以减少机器的压力,并且可以更快地收敛。
(2)当训练集有很多冗余时(类似的样本出现多次),batch 方法收敛更快。以一个极端情况为例,若训练集前一半和后一半梯度相同,那么如果前一半作为一个 batch,后一半作为另一个 batch,那么在一次遍历训练集时,batch 的方法向最优解前进两个 step,而整体的方法只前进一个 step。
6.2 RMSprop
RMSProp 通过引入一个衰减系数,让 r 每回合都衰减一定比例,类似于Momentum 中的做法,该优化器通常是面对递归神经网络时的一个良好选择。
6.2.1 具体实现
需要:全局学习速率 ϵ,初始参数 θ,数值稳定量 δ,衰减速率 ρ。
中间变量:梯度累计量 r(初始化为 0)。
6.2.2 每步迭代过程
(1)从训练集中的随机抽取一批容量为 m 的样本 {x1,…,xm} 以及相关的输出 yi 。
(2)计算梯度和误差,更新 r,再根据 r 和梯度计算参数更新量 。
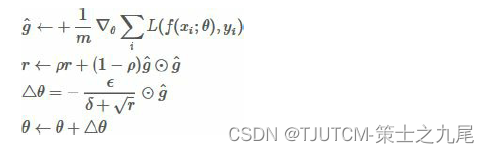
6.2.3 用法
keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-06)
6.2.4 参数
lr:大于 0 的浮点数,学习率。
rho:大于 0 的浮点数。
epsilon:大于 0 的小浮点数,防止除 0 错误。
6.3 Adagrad
AdaGrad 可以自动变更学习速率,只是需要设定一个全局的学习速率 ϵ,但是这并非是实际学习速率,实际的速率是与以往参数的模之和的开方成反比的。也许说起来有点绕口,不过用公式来表示就直白的多:

其中 δ 是一个很小的常量,大概在 10-7,防止出现除以 0 的情况.。
6.3.1 具体实现
需要:全局学习速率 ϵ,初始参数 θ,数值稳定量 δ 。
中间变量:梯度累计量 r(初始化为 0) 。
6.3.2 每步迭代过程
(1) 从训练集中的随机抽取一批容量为 m 的样本 {x1,…,xm} 以及相关。
(2)计算梯度和误差,更新r,再根据 r 和梯度计算参数更新量 。

6.3.3 优点
能够实现学习率的自动更改。如果这次梯度大,那么学习速率衰减的就快一些;如果这次梯度小,那么学习速率衰减的就慢一些。
6.3.4 缺点
仍然要设置一个变量 ϵ 。
经验表明,在普通算法中也许效果不错,但在深度学习中,深度过深时会造成训练提前结束。
6.3.5 用法
keras.optimizers.Adagrad(lr=0.01, epsilon=1e-06)
6.3.6 参数
lr:大于 0 的浮点数,学习率。
epsilon:大于 0 的小浮点数,防止除 0 错误。
6.4 Adadelta
Adagrad 算法存在三个问题:
(1)其学习率是单调递减的,训练后期学习率非常小。
(2)其需要手工设置一个全局的初始学习率。
(3)更新 xt 时,左右两边的单位不统一。
Adadelta 针对上述三个问题提出了比较漂亮的解决方案。
首先,针对第一个问题,我们可以只使用 adagrad 的分母中的累计项离当前时间点比较近的项,如下式:
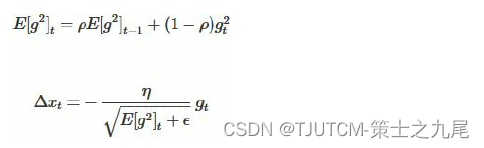
这里ρ 是衰减系数 ,通过这个衰减系数,我们令每一个时刻的 gt 随时间按照 ρ 指数衰减,这样就相当于我们仅使用离当前时刻比较近的gt信息,从而使得还很长时间之后,参数仍然可以得到更新。
针对第三个问题,其实 sgd 跟 momentum 系列的方法也有单位不统一的问题。sgd、momentum 系列方法中:

类似的,adagrad 中,用于更新 Δx 的单位也不是 x 的单位,而是 1。
而对于牛顿迭代法:

其中 H 为 Hessian 矩阵,由于其计算量巨大,因而实际中不常使用。其单位为:

注意,这里f 无单位 。因而,牛顿迭代法的单位是正确的。
所以,我们可以模拟牛顿迭代法来得到正确的单位。注意到:

这里,在解决学习率单调递减的问题的方案中,分母已经是 ∂f/∂x 的一个近似了。这里我们可以构造 Δx 的近似,来模拟得到 H-1 的近似,从而得到近似的牛顿迭代法。具体做法如下:

可以看到,如此一来adagrad 中分子部分需要人工设置的初始学习率也消失了 ,从而顺带解决了上述的第二个问题。
6.4.1 用法
keras.optimizers.Adadelta(lr=1.0, rho=0.95, epsilon=1e-06)
建议保持优化器的默认参数不变。
6.4.2 参数
lr:大于 0 的浮点数,学习率。
rho:大于 0 的浮点数。
epsilon:大于 0 的小浮点数,防止除 0 错误。
6.5 Adam
Adam 是一种基于一阶梯度来优化随机目标函数的算法。
Adam 这个名字来源于 adaptive moment estimation,自适应矩估计。概率论中矩的含义是:如果一个随机变量 X 服从某个分布,X 的一阶矩是E(X),也就是样本平均值,X 的二阶矩就是 E(X^2),也就是样本平方的平均值。
Adam 算法根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率。Adam 也是基于梯度下降的方法,但是每次迭代参数的学习步长都有一个确定的范围,不会因为很大的梯度导致很大的学习步长,参数的值比较稳定。
Adam(Adaptive Moment Estimation)本质上是带有动量项的 RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam 的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
6.5.1 具体实现
需要:步进值 ϵ,初始参数 θ,数值稳定量 δ,一阶动量衰减系数 ρ1,二阶动量衰减系数 ρ2 。
其中几个取值一般为:δ=10-8,ρ1=0.9,ρ2=0.999 。
中间变量:一阶动量 s,二阶动量 r,都初始化为 0 。
6.5.2 每步迭代过程
(1)从训练集中的随机抽取一批容量为 m 的样本 {x1,…,xm} 以及相关的输出 yi 。
(2)计算梯度和误差,更新 r 和 s,再根据 r 和 s 以及梯度计算参数更新量 。

6.5.3 用法
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
6.5.4 参数
lr:大于 0 的浮点数,学习率。
beta_1/beta_2:浮点数, 0<beta<1,通常很接近 1。
epsilon:大于 0 的小浮点数,防止除0错误。
6.6 Adamax
keras.optimizers.Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
Adamax 优化器的方法是基于无穷范数的 Adam 方法的变体。
6.6.1 参数
lr:大于 0 的浮点数,学习率。
beta_1/beta_2:浮点数, 0<beta<1,通常很接近 1。
epsilon:大于 0 的小浮点数,防止除 0 错误。