大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群

为什么使用monorepo
什么是monorepo
简单来说就是,将多个项目或包文件放到一个git仓库来管理。 目前比较广泛应用的是yarn+lerna的方式实现monorepo的管理。 一个简单的monorepo的目录结构类似这样:
js
复制代码
├── packages
| ├── pkg1
| | ├── package.json
| ├── pkg2
| | ├── package.json
├── package.json
├── lerna.json
之所以应用monorepo,主要是解决以下问题:
pnpm的使用
为什么用pnpm
关于为什么越来越多的人推荐使用pnpm,可以参考这篇文章[1] 这里简单列一下pnpm相对于yarn/npm的优势:
安装速度最快(非扁平的包结构,没有yarn/npm的复杂的扁平算法,且只更新变化的文件)
节省磁盘空间 (统一安装包到磁盘的某个位置,项目中的node_modules通过hard-link的方式链接到实际的安装地址)
pnpm安装包有何不同
目前,使用npm/yarn安装包是扁平结构(以前是嵌套结构,npm3之后改为扁平结构)
扁平结构 就是安装一个包,那么这个包依赖的包将一起被安装到与这个包同级的目录下。比如安装一个express包,打开目录下的node_modules会发现除了express之外,多出很多其他的包。如图:
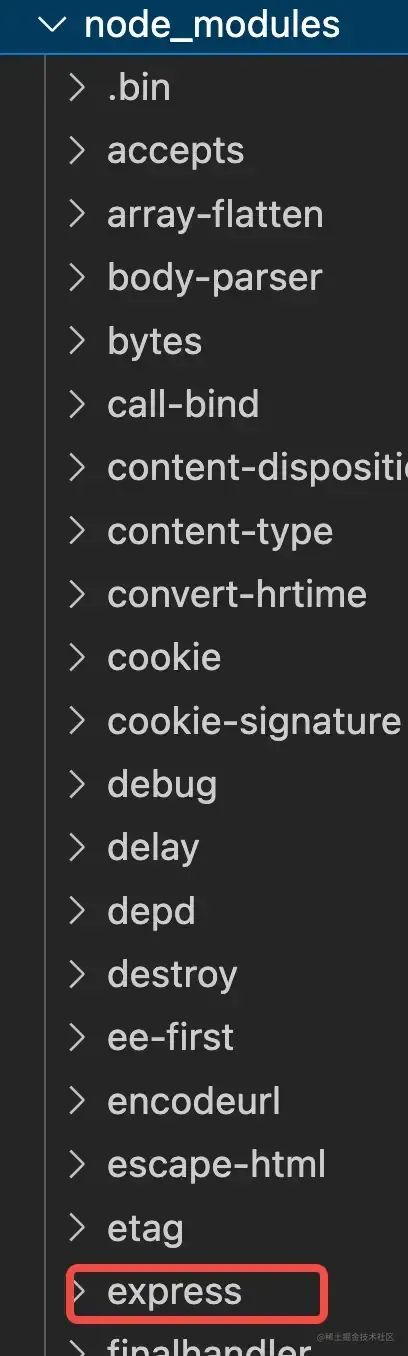 image.png
image.png
嵌套结构 就是一个包的依赖包会安装在这个包文件下的node_modules下,而依赖的依赖会安装到依赖包文件的node_modules下。依此类推。如下所示:
js
复制代码
node_modules
├─ foo
├─ node_modules
├─ bar
├─ index.js
└─ package.json
├─ index.js
└─ package.json
嵌套结构的问题在于:
包文件的目录可能会非常长
重复安装包
相同包的实例不能共享
而扁平结构也同样存在问题:
现在,我们使用pnpm来安装express,然后打开node_modules:
 image.png
image.png
从上图可以发现:
node_modules下只有express一个包,且这个被软链到了其他的地方。
.modlues.yaml包含了一些pnpm包管理的配置信息。如下图:
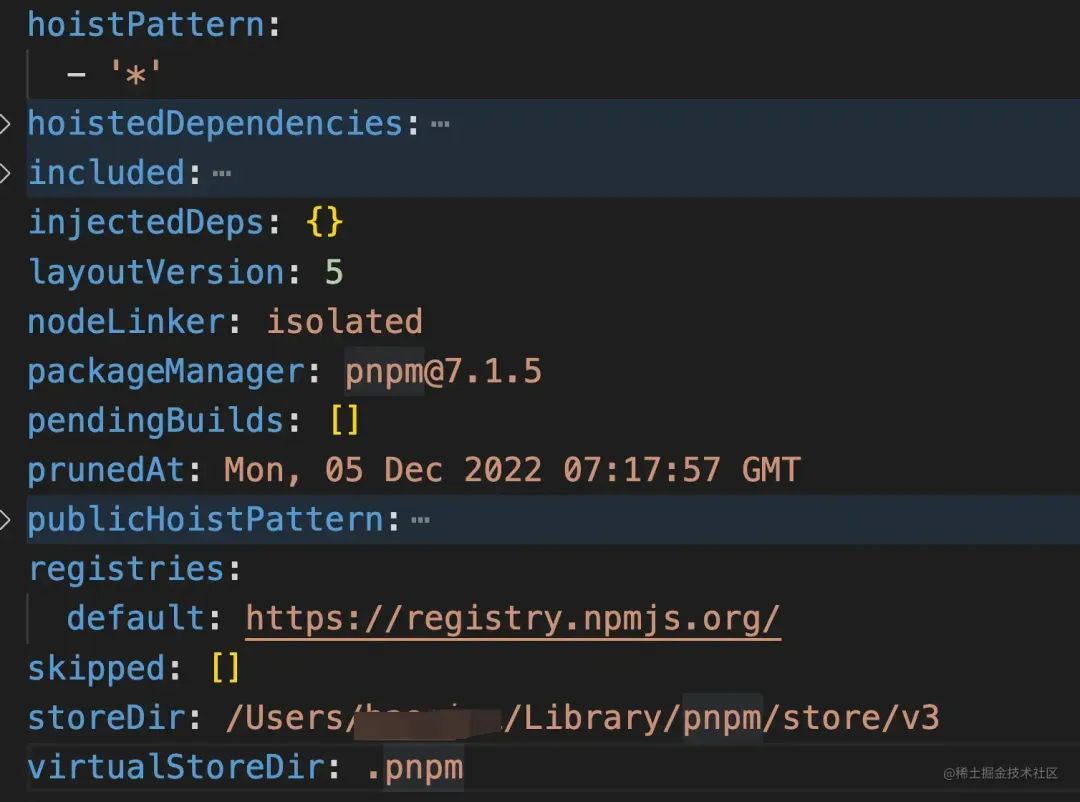 image.png
image.png
可以看到 .pnpm目录的实际指向的pnpm store的路径、pnpm包的版本等信息
.pnpm目录可以看到所有安装了的依赖包。如下图:
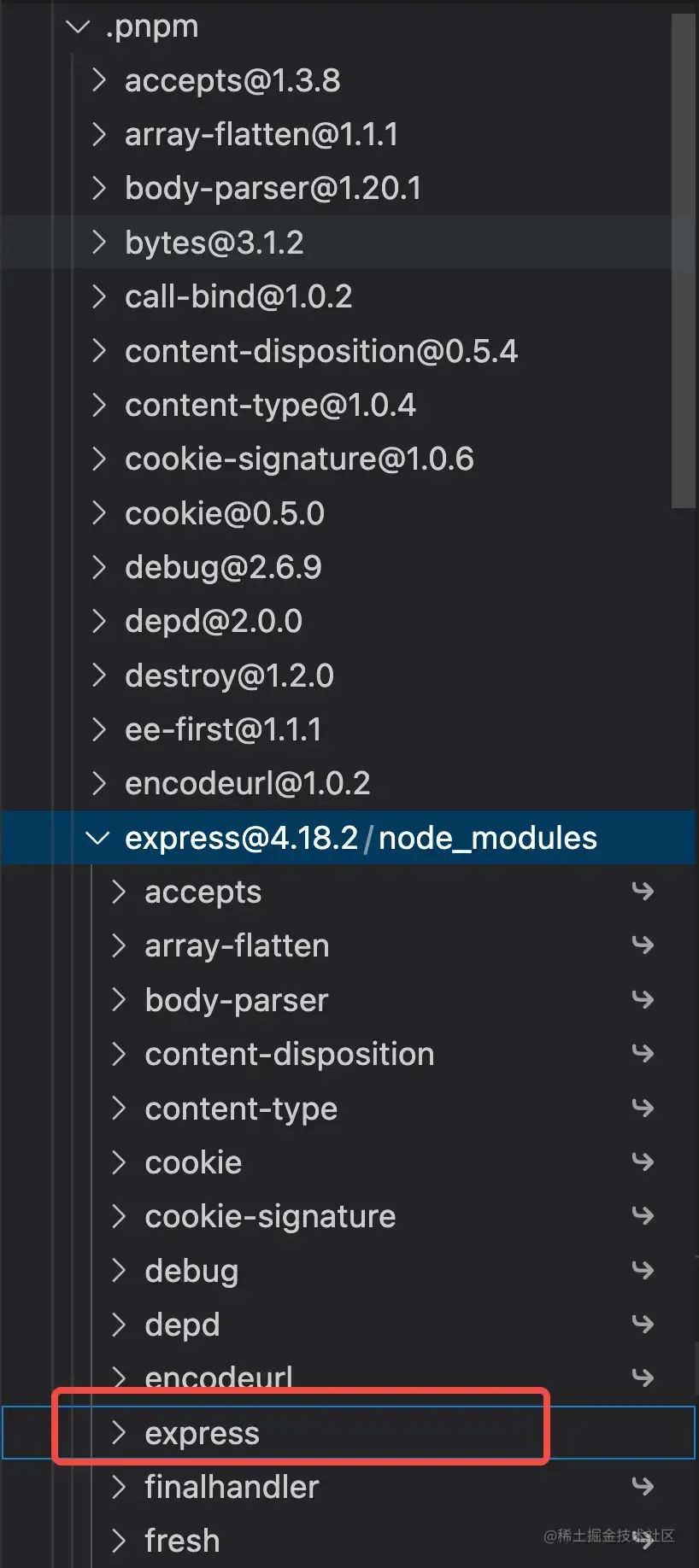 image.png
image.png
观察之后,发现安装结构和官方发布的图是完全一致的: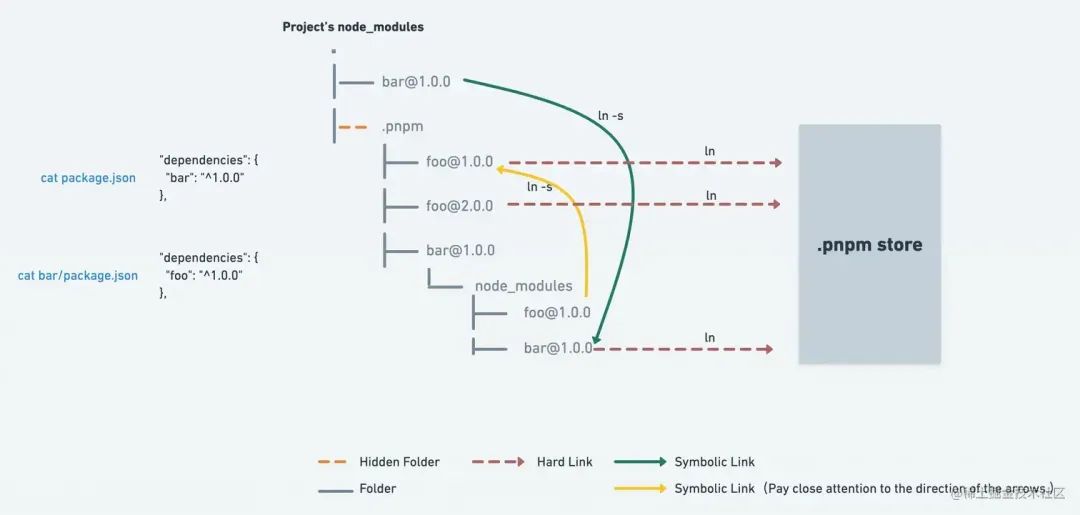
由官方图我们可以了解到:
当我们安装bar包时,根目录下只包含安装的包bar
而node_modules目录下的bar包会软链接到.pnpm/bar/node_modules/bar@*.*.*
bar的依赖包foo会被提升到.pnpm的根目录下,其他包依赖foo时也会软链接到这里
而bar和foo实际通过硬链接到.pnpm store中
软链接可以理解成快捷方式。 它和windows下的快捷方式的作用是一样的。 硬链接等于cp -p 加 同步更新。即文件大小和创建时间与源文件相同,源文件修改,硬链接的文件会同步更新。应用:可以防止别人误删你的源文件
软链接解决了磁盘空间占用的问题,而硬链接解决了包的同步更新和统一管理问题。 还有一个巧妙的设计就是:将安装包和依赖包放在同一级目录下,即.pnpm/依赖包/node_modules下。这个设计也就防止了 **依赖包间的非法访问**,根据Node模块路径解析规则[2]可知,不在安装包同级的依赖包无法被访问,即只能访问安装包依赖的包。
现在应该没理由不升级你的包管理工具了吧!
如果你还有使用npm/yarn的场景,那么,可以推荐使用 **ni**[3] 这个工具,它可以帮你自动识别项目使用的包管理工具,你只需要一行命名就搞定了。
比如: 执行命令ni安装依赖包,如果当前项目包含pnpm-lock.yaml,那么会使用 pnpm install执行安装命令,否则判断是否包含package-lock.json/yarn.lock/bun.lockb,来确定使用哪个包管理工具去执行安装命令。
pnpm workspace实践
1. 新建仓库并初始化
新建目录pnpm-workspace-demo,执行npm init / pnpm init初始化项目,生成 package.json
2. 指定项目运行的Node、pnpm版本
为了减少因node或pnpm的版本的差异而产生开发环境错误,我们在package.json中增加engines字段来限制版本。
js
复制代码
{
"engines": {
"node": ">=16",
"pnpm": ">=7"
}
}
3. 安全性设置
为了防止我们的根目录被当作包发布,我们需要在package.json加入如下设置:
js
复制代码
{
"private": true
}
pnpm本身支持monorepo,不用额外安装包,真是太棒了! 但是每个monorepo的根目录下必须包含pnpm-workspace.yaml文件。 目录下新建pnpm-workspace.yaml文件,内容如下:
yaml
复制代码
packages:
# all packages in direct subdirs of packages/
- 'packages/*'
4. 安装包
4.1 安装全局依赖包
有些依赖包需要全局安装,也就是安装到根目录,比如我们常用的编译依赖包rollup、execa、chalk、enquirer、fs-extra、minimist、npm-run-all、typescript等 运行如下命令:
-w 表示在workspace的根目录下安装而不是当前的目录
sql
复制代码
pnpm add rollup chalk minimist npm-run-all typescript -Dw
与安装命令pnpm add pkgname相反的的删除依赖包pnpm rm/remove pkgname或pnpm un/uninstall pkgname
4.2 安装子包的依赖
除了进入子包目录直接安装pnpm add pkgname之外,还可以通过过滤参数 --filter或-F指定命令作用范围。格式如下:
pnpm --filter/-F 具体包目录名/包的name/正则匹配包名/匹配目录 command
比如:我在packages目录下新建两个子包,分别为tools和mini-cli,假如我要在min-cli包下安装react,那么,我们可以执行以下命令:
js
复制代码
pnpm --filter mini-cli add react
更多的过滤配置可参考:www.pnpm.cn/filtering[4]
4.3 打包输出包内容
这里选用rollup[5]作为打包工具,由于其打包具有更小的体积及tree-shaking的特性,可以说是作为工具库打包的最佳选择。
先安装打包常用的一些插件:
sql
复制代码
pnpm add rollup-plugin-typescript2 @rollup/plugin-json @rollup/plugin-terser -Dw
基础编译配置
目录下新建rollup的配置文件rollup.config.mjs,考虑到多个包同时打包的情况,预留input为通过rollup通过参数传入。这里用process.env.TARGET表示不同包目录。
以下为编译的基础配置,主要包括:
js
复制代码
import { createRequire } from 'module'
import { fileURLToPath } from 'url'
import path from 'path'
import json from '@rollup/plugin-json'
import terser from '@rollup/plugin-terser'
const require = createRequire(import.meta.url)
const __dirname = fileURLToPath(new URL('.', import.meta.url))
const packagesDir = path.resolve(__dirname, 'packages')
const packageDir = path.resolve(packagesDir, process.env.TARGET)
const resolve = p => path.resolve(packageDir, p)
const pkg = require(resolve(`package.json`))
const packageOptions = pkg.buildOptions || {}
const name = packageOptions.filename || path.basename(packageDir)
// 定义输出类型对应的编译项
const outputConfigs = {
'esm-bundler': {
file: resolve(`dist/${name}.esm-bundler.js`),
format: `es`
},
'esm-browser': {
file: resolve(`dist/${name}.esm-browser.js`),
format: `es`
},
cjs: {
file: resolve(`dist/${name}.cjs.js`),
format: `cjs`
},
global: {
name: name,
file: resolve(`dist/${name}.global.js`),
format: `iife`
}
}
const packageFormats = ['esm-bundler', 'cjs']
const packageConfigs = packageFormats.map(format => createConfig(format, outputConfigs[format]))
export default packageConfigs
function createConfig(format, output, plugins = []) {
// 是否输出声明文件
const shouldEmitDeclarations = !!pkg.types
const minifyPlugin = format === 'global' && format === 'esm-browser' ? [terser()] : []
return {
input: resolve('src/index.ts'),
// Global and Browser ESM builds inlines everything so that they can be
// used alone.
external: [
...['path', 'fs', 'os', 'http'],
...Object.keys(pkg.dependencies||{}),
...Object.keys(pkg.peerDependencies || {}),
...Object.keys(pkg.devDependencies||{}),
],
plugins: [
json({
namedExports: false
}),
...minifyPlugin,
...plugins
],
output,
onwarn: (msg, warn) => {
if (!/Circular/.test(msg)) {
warn(msg)
}
},
treeshake: {
moduleSideEffects: false
}
}
}
多包同时编译
根目录下新建scripts目录,并新建build.js用于打包编译执行。为了实现多包同时进行打包操作,我们首先需要获取packages下的所有子包
js
复制代码
const fs = require('fs')
const {rm} = require('fs/promises')
const path = require('path')
const allTargets = (fs.readdirSync('packages').filter(f => {
// 过滤掉非目录文件
if (!fs.statSync(`packages/${f}`).isDirectory()) {
return false
}
const pkg = require(`../packages/${f}/package.json`)
// 过滤掉私有包和不带编译配置的包
if (pkg.private && !pkg.buildOptions) {
return false
}
return true
}))
获取到子包之后就可以执行build操作,这里我们借助 execa[6] 来执行rollup命令。代码如下:
js
复制代码
const build = async function (target) {
const pkgDir = path.resolve(`packages/${target}`)
const pkg = require(`${pkgDir}/package.json`)
// 编译前移除之前生成的产物
await rm(`${pkgDir}/dist`,{ recursive: true, force: true })
// -c 指使用配置文件 默认为rollup.config.js
// --environment 向配置文件传递环境变量 配置文件通过proccess.env.获取
await execa(
'rollup',
[
'-c',
'--environment',
[
`TARGET:${target}`
]
.filter(Boolean)
.join(',')
],
{ stdio: 'inherit' }
)
}
同步编译多个包时,为了不影响编译性能,我们需要控制并发的个数,这里我们暂定并发数为4,编译入口大概长这样:
js
复制代码
const targets = allTargets // 上面的获取的子包
const maxConcurrency = 4 // 并发编译个数
const buildAll = async function () {
const ret = []
const executing = []
for (const item of targets) {
// 依次对子包执行build()操作
const p = Promise.resolve().then(() => build(item))
ret.push(p)
if (maxConcurrency <= targets.length) {
const e = p.then(() => executing.splice(executing.indexOf(e), 1))
executing.push(e)
if (executing.length >= maxConcurrency) {
await Promise.race(executing)
}
}
}
return Promise.all(ret)
}
// 执行编译操作
buildAll()
最后,我们将脚本添加到根目录的package.json中即可。
json
复制代码
{
"scripts": {
"build": "node scripts/build.js"
},
}
现在我们简单运行pnpm run build即可完成所有包的编译工作。(注:还需要添加后面的TS插件才能工作)。
此时,在每个包下面会生成dist目录,因为我们默认的是esm-bundler和cjs两种format,所以目录下生成的文件是这样的
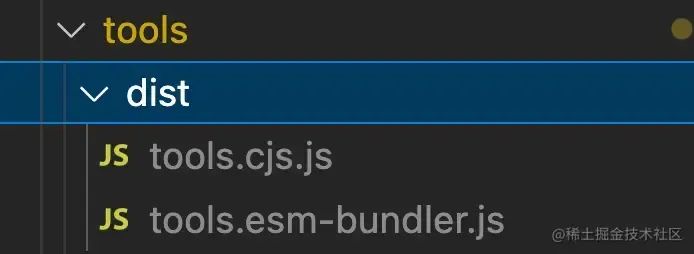 image.png
image.png
那么,如果我们想自定义生成文件的格式该怎么办呢?
子包自定义编译输出格式
最简单的方法其实就是在package.json里做配置,在打包的时候我们直接取这里的配置即可,比如我们在包tools里做如下配置:
json
复制代码
{
"buildOptions": {
"name": "tools", // 定义global时全局变量的名称
"filename": "tools", // 定义输出的文件名 比如tools.esm-browser.js 生成的文件为[filename].[format].js
"formats": [ // 定义输出
"esm-bundler",
"esm-browser",
"cjs",
"global"
]
},
}
这里我们只需要在基础配置文件rollup.config.mjs里去做些改动即可:
js
复制代码
const defaultFormats = ['esm-bundler', 'cjs']
const packageFormats = packageOptions.formats || defaultFormats // 优先使用每个包里自定义的formats
const packageConfigs = packageFormats.map(format => createConfig(format, outputConfigs[format]))
命令行自定义打包并指定其格式
比如我想单独打包tools并指定输出的文件为global类型,大概可以这么写:
arduino
复制代码
pnpm run build tools --formats global
这里其实就是将命令行参数接入到打包脚本里即可。 大概分为以下几步:
使用minimist[7]取得命令行参数
js
复制代码
const args = require('minimist')(process.argv.slice(2))
const targets = args._.length ? args._ : allTargets
const formats = args.formats || args.f
将取得的参数传递到rollup的环境变量中,修改execa部分
js
复制代码
await execa(
'rollup',
[
'-c',
'--environment', // 传递环境变量 配置文件可通过proccess.env.获取
[
`TARGET:${target}`,
formats ? `FORMATS:${formats}` : `` // 将参数继续传递
]
.filter(Boolean)
.join(',')
],
{ stdio: 'inherit' }
)
在rollup.config.mjs中获取环境变量并应用
js
复制代码
const defaultFormats = ['esm-bundler', 'cjs']
const inlineFormats = process.env.FORMATS && process.env.FORMATS.split(',') // 获取rollup传递过来的环境变量process.env.FORMATS
const packageFormats = inlineFormats || packageOptions.formats || defaultFormats
TS打包
对于ts编写的项目通常也会发布声明文件,只需要在package.json添加types字段来指定声明文件即可。那么,我们其实在做打包时就可以利用这个字段来判断是否要生成声明文件。对于rollup,我们利用其插件rollup-plugin-typescript2来解析ts文件并生成声明文件。 在rollup.config.mjs中添加如下配置:
js
复制代码
// 是否输出声明文件 取每个包的package.json的types字段
const shouldEmitDeclarations = !!pkg.types
const tsPlugin = ts({
tsconfig: path.resolve(__dirname, 'tsconfig.json'),
tsconfigOverride: {
compilerOptions: {
target: format === 'cjs' ? 'es2019' : 'es2015',
sourceMap: true,
declaration: shouldEmitDeclarations,
declarationMap: shouldEmitDeclarations
}
}
})
return {
...
plugins: [
json({
namedExports: false
}),
tsPlugin,
...minifyPlugin,
...plugins
],
}
将生成的声明文件整理到指定文件
以上配置运行后会在每个包下面生成所有包的声明文件,如图:
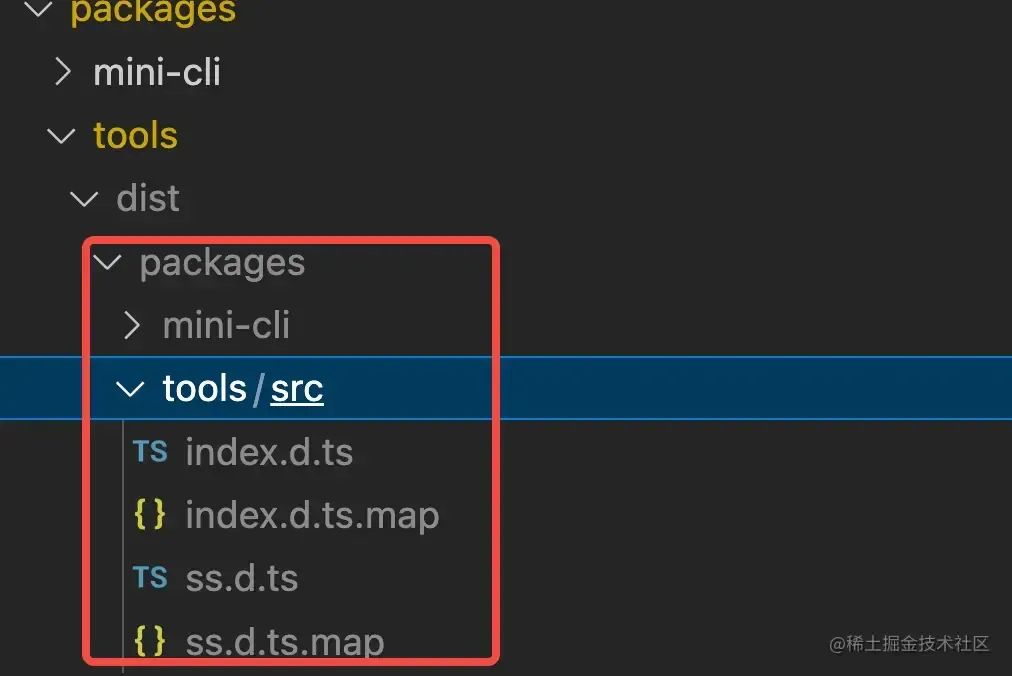 image.png
image.png
这并不是我们想要的,我们期望在dist目录下仅生成一个 .d.ts文件就好了,使用起来也方便。这里我们借助api-extractor[8]来做这个工作。这个工具主要有三大功能,我们要使用的是红框部分的功能,如图:
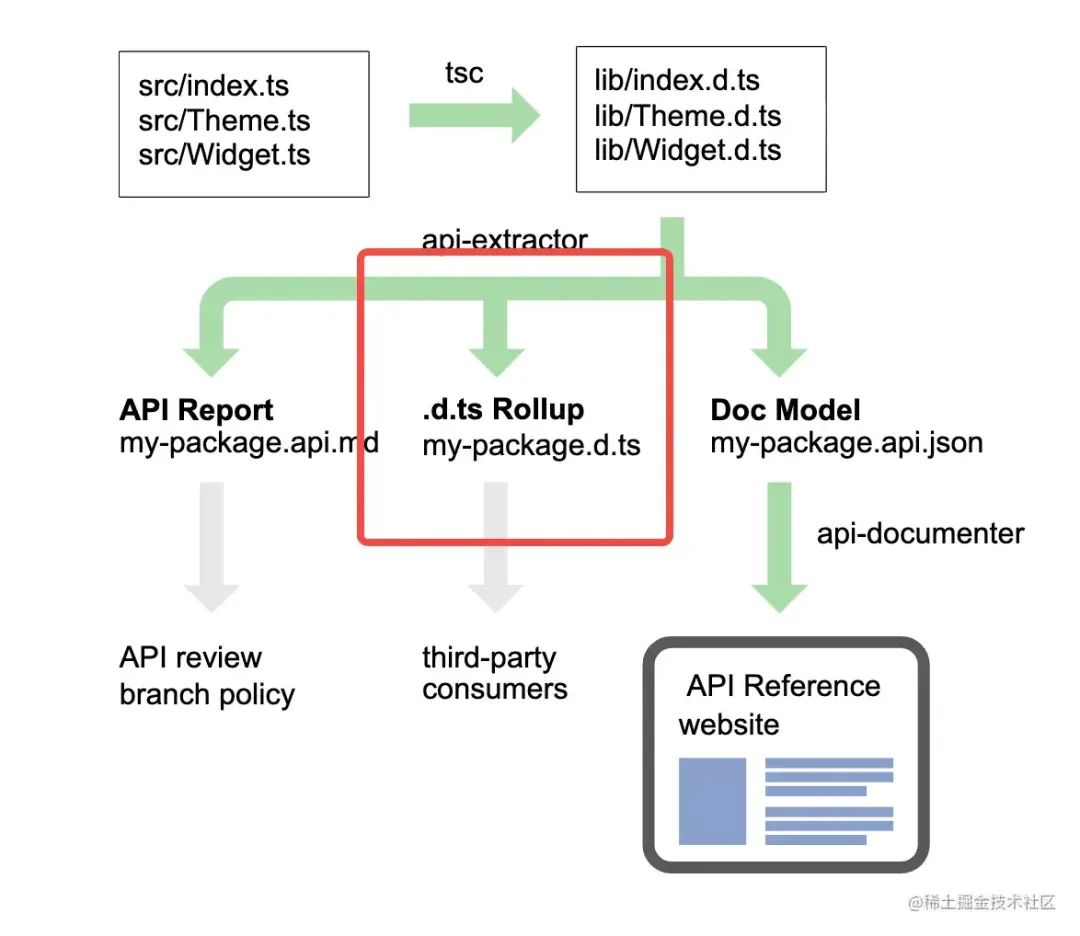 关键实现步骤:
关键实现步骤:
根目录下生成api-extractor.json并将dtsRollup设置为开启
子包下添加api-extractor.json并定义声明文件入口及导出项,如下所示:
json
复制代码
{
"extends": "../../api-extractor.json",
"mainEntryPointFilePath": "./dist/packages/<unscopedPackageName>/src/index.d.ts", // rollup生成的声明文件
"dtsRollup": {
"publicTrimmedFilePath": "./dist/<unscopedPackageName>.d.ts" // 抽离为一个声明文件到dist目录下
}
}
在rollup执行完成后做触发API Extractor操作,在build方法中增加以下操作:
js
复制代码
build(target) {
await execa('rollup')
// 执行完rollup生成声明文件后
// package.json中定义此字段时执行
if (pkg.types) {
console.log(
chalk.bold(chalk.yellow(`Rolling up type definitions for ${target}...`))
)
// 执行API Extractor操作 重新生成声明文件
const { Extractor, ExtractorConfig } = require('@microsoft/api-extractor')
const extractorConfigPath = path.resolve(pkgDir, `api-extractor.json`)
const extractorConfig =
ExtractorConfig.loadFileAndPrepare(extractorConfigPath)
const extractorResult = Extractor.invoke(extractorConfig, {
localBuild: true,
showVerboseMessages: true
})
if (extractorResult.succeeded) {
console.log(`API Extractor completed successfully`);
process.exitCode = 0;
} else {
console.error(`API Extractor completed with ${extractorResult.errorCount} errors`
+ ` and ${extractorResult.warningCount} warnings`);
process.exitCode = 1;
}
// 删除ts生成的声明文件
await rm(`${pkgDir}/dist/packages`,{ recursive: true, force: true })
}
}
删除rollup生成的声明文件
那么,到这里,整个打包流程就比较完备了。
changesets的使用
对于pnpm workspace实现的monorepo,如果要管理包版本并发布,需要借助一些工具,官方推荐使用如下工具:
我们这里主要学习一下changesets的使用,它的主要作用有两个:
对于monorepo项目使用它会更加方便,当然单包也可以使用。主要区别在于项目下有没有pnpm-workspace.yaml,如果未指定多包,那么会当作普通包进行处理。 那么,我们来看一下具体的步骤:
1. 安装
sql
复制代码
pnpm add @changesets/cli -Dw
2. 初始化changeset配置
csharp
复制代码
npx changeset init
这个命令会在根目录下生成.changeset文件夹,文件夹下包含一个config文件和一个readme文件。生成的config文件长这样:
json
复制代码
{
"$schema": "https://unpkg.com/@changesets/config@2.3.0/schema.json",
"changelog": "@changesets/cli/changelog",
"commit": false, // 是否提交因changeset和changeset version引起的文件修改
"fixed": [], // 设置一组共享版本的包 一个组里的包,无论有没有修改、是否有依赖,都会同步修改到相同的版本
"linked": [], // 设置一组需要关联版本的包 有依赖关系或有修改的包会同步更新到相同版本 未修改且无依赖关系的包则版本不做变化
"access": "public", // 发布为私有包/公共包
"baseBranch": "main",
"updateInternalDependencies": "patch", // 确保依赖包是否更新、更新版本的衡量单位
"ignore": [] // 忽略掉的不需要发布的包
}
关于每个配置项的详细含义参考:config.json[11] 这里有几点需要注意的:
access 默认restricted发布为私有包,需要改为public公共包,否则发布时会报错
对于依赖包版本的控制,我们需要重点理解一下 **fixed**[12] 和 **linked**[13] 的区别
fixed和linked的值为二维数组,元素为具体的包名或匹配表达式,但是这些包必须在pnpm-workspace.yaml添加过
3. 生成发布包版本信息
运行npx changeset,会出现一系列确认问题,包括:
yaml
复制代码
---
'@scope/mini-cli': major
'@scope/tools': minor
---
update packages
—-- 中间为要更新版本的包列表 以及包对应的更新版本,最下面是修改信息
4. 更新包版本并生成changelog
运行npx changeset version 这个命令会做以下操作
依据上一步生成的md文件和changeset的config文件更新相关包版本
为版本更新的包生成CHANGELOG.md文件 填入上一步填写的修改信息
删除上一步生成的Markdown文件,保证只使用一次
建议执行此操作后,pulish之前将改动合并到主分支
5. 版本发布
这个没啥好说的,直接执行命令npx changeset publish即可
为了保证发布功能,添加如下脚本:
json
复制代码
{
"scripts": {
"release": "run-s build releaseOnly",
"releaseOnly": "changeset publish"
}
}
预发布版本
changeset提供了带tag的预发布版本的模式,这个模式使用时候需要注意:
通过pre enter/exit进入或退出预发布模式,在这个模式下可以执行正常模式下的所有命令,比如version、publish
为了不影响正式版本,预发布模式最好在单独分支进行操作,以免带来不好修复的问题
预发布模式下,版本号为正常模式下应该生成的版本号加-<tag>.<num>结尾。tag为pre命令接的tag名,num每次发布都会递增 从0开始
预发布的版本并不符合语义化版本的范围,比如我的依赖包版本为"^1.0.0",那么,预发布版本是不满足这个版本的,所以依赖包版本会保持不变
一个完整的预发布包大概要执行以下操作:
changeset pre enter <tag> 进入预发布模式
changeset 确认发布包版本信息
changeset version 生成预发布版本号和changelog
changeset publish 发布预发布版本
这里的tag可以是我们常用的几种类型:
| 名称 |
功能 |
| alpha |
是内部测试版,一般不向外部发布,会有很多Bug,一般只有测试人员使用 |
| beta |
也是测试版,这个阶段的版本会一直加入新的功能。在Alpha版之后推出 |
| rc |
(Release Candidate) 发行候选版本。RC版不会再加入新的功能了,主要着重于除错 |
每次需要更新版本时从第二步往后再次执行即可
如果需要发布正式版本,退出预发布模式changeset pre exit,然后切换到主分支操作即可
代码格式校验
这里主要对代码风格进行校验, 校验工具为eslint (主要对js、ts等js语言的文件)和 prettier(js、css等多种类型的文件)
辅助工具为
配置如下:
json
复制代码
{
"simple-git-hooks": {
"pre-commit": "pnpm lint-staged" // 注册提交前操作 即进行代码格式校验
},
"lint-staged": {
"*.{js,json}": [
"prettier --write"
],
"*.ts?(x)": [
"eslint",
"prettier --parser=typescript --write"
]
},
}
对于钩子函数的注册通过simple-git-hooks来实现,在项目安装依赖之后触发钩子注册。可以添加以下脚本。(如果钩子操作改变,则需要重新执行安装依赖操作来更新)
json
复制代码
"scripts": {
"postinstall": "simple-git-hooks",
},
代码规范提交
这里主要用到以下三个工具:
1. Commitizen的使用
安装Commitizen
复制代码
npm install -g commitizen
安装Commitizen的适配器,确定使用的规范,这里使用cz-conventional-changelog[19],也可以选择其他的适配器
复制代码
npm install -g cz-conventional-changelog
全局指定适配器
json
复制代码
// mac用户
echo '{ "path": "cz-conventional-changelog" }' > ~/.czrc
这个时候执行命令git cz会自动进入交互式生成commit message的询问中,如图:
2. Commitlint如何配置
我们可以通过配置的git cz命令进行规范的代码提交,那么,如果其他同事依然使用的是git commit来提交代码的话,那么,提交信息就会比较乱。这时候就需要对commit mesaage进行校验了,如果不通过则中断提交。这个校验就可以通过Commitlint来完成。
对于按照何种规则来校验,我们就需要单独安装检验规则的包来进行检验,比如@commitlint/config-conventional[20]
如果想定义自己的规则可以参考cz-customizable[21]
首先安装这两个包:
sql
复制代码
pnpm add @commitlint/config-conventional @commitlint/cli -Dw
根目录下写入commitlint配置,指定规则包
arduino
复制代码
echo "module.exports = {extends: ['@commitlint/config-conventional']}" > commitlint.config.js
配置git钩子执行校验操作 (执行pnpm install更新钩子)
json
复制代码
"simple-git-hooks": {
"commit-msg": "npx --no -- commitlint --edit ${1}"
},
这个时候再提交会对commit message进行校验,不符合规范则会出现以下提示:
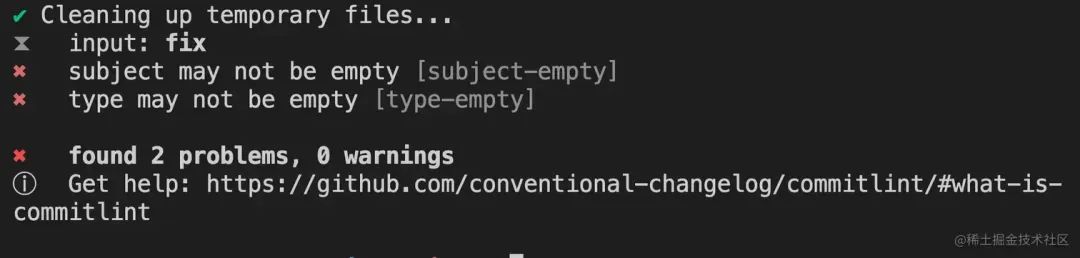 image.png
image.png
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。

“分享、点赞、在看” 支持一下