机器学习-Sklearn-11(支持向量机SVM-SVC真实数据案例:预测明天是否会下雨)
#11、SVC真实数据案例:预测明天是否会下雨
#这个案例的核心目的,是通过巧妙的预处理和特征工程来向大家展示,在现实数据集上我们往往如何做数据预处理,或者我们都有哪些预处理的方式和思路。预测天气是一个非常非常困难的主题,因为影响天气的因素太多,而Kaggle的这份数据也丝毫不让我们失望,是一份非常难的数据集,难到我们目前学过的所有算法在这个数据集上都不会有太好的结果,尤其是召回率recall,异常地低。在这里,我为大家抛砖引玉,在这个15W行数据的数据集上,随机抽样5000个样本来为大家演示我的数据预处理和特征工程的过程,为大家提供一些数据预处理和特征工程的思路。不过,特征工程没有标准答案,因此大家应当多尝试,希望使用原数据集的小伙伴们可以到Kaggle下载最原始版本,Kaggle下载链接走这里:https://www.kaggle.com/jsphyg/weather-dataset-rattle-package
#=======================================
#jupyter lab 操作快捷键
#分裂的快捷键ctrl shift -
#合并:首先需要按住shift选择合并的cell,再按合并的快捷键shift m
#在上方添加一个cell的快捷键ESC a enter
#在下方添加一个cell的快捷键ESC b enter
#删除cell的快捷键ESC d d
#=======================================
#1、 导库导数据,探索特征
#导入需要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
#导入数据,探索数据
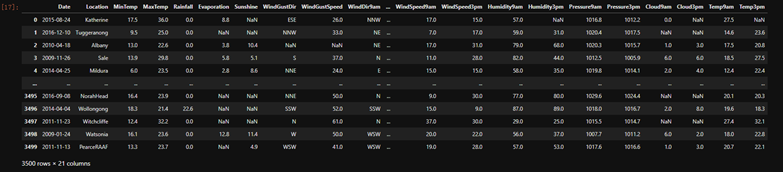
weather = pd.read_csv(r"D:\whole_development_of_the_stack_study\RS_Algorithm_Course\Practical\machine_learning\08_09_10_11SVM_01\weatherAUS5000.csv",index_col=0)
weather.head() #查看前五行

#来查看一下各个特征都代表了什么:

#将特征矩阵和标签Y分开
X = weather.iloc[:,:-1]
Y = weather.iloc[:,-1]
X.shape #已经处理过的,在原数据中随机选取的5000行
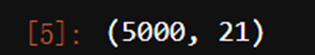
#探索数据类型
X.info()

#发现Date、location、WindGustDir、WindDir9am、WindDir3am不是浮点数字类型
#探索缺失值
#.isnull()是缺失值的返回true
X.isnull().mean()
#缺失值所占的比例,即isnull().sum(全部的True)/X.shape[0]行数
#我们要有不同的缺失值填补策略。因为有的缺的多有的缺的少。

Y.shape
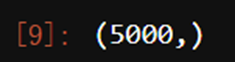
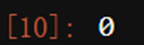
Y.isnull().sum()
#探索标签的分类
np.unique(Y) #不重复的值,结果为:二分类

#粗略观察可以发现,这个特征矩阵由一部分分类变量和一部分连续变量组成,其中云层遮蔽程度虽然是以数字表示,但是本质却是分类变量。
#大多数特征都是采集的自然数据,比如蒸发量,日照时间,湿度等等,而少部分特征是人为构成的。
#还有一些是单纯表示样本信息的变量,比如采集信息的地点,以及采集的时间。
#=======================================
#2、分集,优先探索标签
#分训练集和测试集,是随机抽样
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y,test_size=0.3,random_state=420)
Xtrain.head() #发现索引是乱序的,一定要恢复索引的正常顺序

#恢复索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0]) #0到行数-1
Xtrain
Ytrain

#先探索处理一下标签,因为标签处理起来非诚容易。
#是否有样本不平衡问题?
#样本不平衡问题:标签中某一类天生就占据很大的比例
Ytrain.value_counts()

Ytest.value_counts()

Ytrain.value_counts()[0]/Ytrain.value_counts()[1]

#存在轻微的样本不均衡问题
#将标签编码
#二分类问题使用LabelEncoder进行编码
from sklearn.preprocessing import LabelEncoder #标签专用,第三章讲过
encorder = LabelEncoder().fit(Ytrain) #允许一维数据输入的
#认得了:有两类,yes和no,yes是1(yes是少数类所有是1),no是0,使其有了这种认知。
#使用训练集进行训练,然后再训练集和测试集上分别进行tansform
#即:在使用训练集的训练结果来对训练集和测试集分别进行改造。
#使用上面训练的认知来转化Ytrain和Ytest
Ytrain = pd.DataFrame(encorder.transform(Ytrain))
Ytest = pd.DataFrame(encorder.transform(Ytest))
#虽然该流程和以前我先一股脑的全部转换成0和1之后,再做分训练集和测试集对于标签的结果是一样的。
#但是逻辑思路是不同的。
#如果我们的测试集中,出现了训练集中没有出现过的标签类别
#比如说,测试集中有YES,NO,UNKNOWN
#而我们的训练集中只有YES和NO,在使用训练集的训练结果来对训练集和测试集分别进行改造,这种情况下对测试集进行transform会报错误。
#因为在对训练集建模时只有两类,而测试集Ytest中出现了认知以外的类型,所以会报错。
#而当一股脑的全部进行数据预处理,再划分训练集和测试集,这种错误是不会产生的。
#在现实中,如果标签出现了新的类别就要重新建模。
Ytrain

Ytest

#在现实中,标签处理完毕后,建议将标签保存起来。
Ytrain.to_csv(r"D:\whole_development_of_the_stack_study\RS_Algorithm_Course\Practical\machine_learning\08_09_10_11SVM_01\Ytrain.csv")
#=======================================
#3、探索特征,开始处理特征矩阵
#=======================================
#(1)描述性统计与异常值
#描述性统计
#describe中括号中的数表示分位置,如果什么都不写,会自动返回25%,50%,75%的分位数。
#这里这样分是为了观察极值,查看数据有没有存在偏态现象。
#.T表示转至,为了更好显示数据,将其横向显示
Xtrain.describe([0.01,0.05,0.1,0.25,0.5,0.75,0.9,0.99]).T
#得到所有特征上面的描述性统计结果
#发现数据之间的量纲是不同的。
#通过常识判断一下:
#哪些特征是可以存在负数的?发现这些特征正负数都是合理的。
#哪些特征的最大值是不合理的?降雨量是严重偏态的数据。

Xtest.describe([0.01,0.05,0.1,0.25,0.5,0.75,0.9,0.99]).T
#Xtest描述性统计与Xtrain相似。

"""
对于去kaggle上下载了数据的小伙伴们,以及坚持要使用完整版数据的(15W行)小伙伴们,如果你发现了异常值,首先你要观察,这个异常值出现的频率
如果异常值只出现了一次,多半是输入错误,直接把异常值删除;
如果异常值出现了多次,去跟业务人员沟通,可能这是某种特殊表示,如果是人为造成的错误,异常值留着是没有用的,只要数据量不是太大,都可以删除;
如果异常值占到你总数据量的10%以上了,不能轻易删除。可以考虑把异常值替换成非异常但是非干扰的项,比如说用0来进行替换,或者把异常当缺失值,用均值或者众数来进行替换。
'''
#下面cell的是处理异常的代码:
#先查看原始的数据结构
Xtrain.shape
Xtest.shape
#观察异常值是大量存在,还是少数存在
Xtrain.loc[Xtrain.loc[:,"Cloud9am"] == 9,"Cloud9am"]
Xtest.loc[Xtest.loc[:,"Cloud9am"] == 9,"Cloud9am"]
Xtest.loc[Xtest.loc[:,"Cloud3pm"] == 9,"Cloud3pm"]
#少数存在,于是采取删除的策略
#注意如果删除特征矩阵,则必须连对应的标签一起删除,特征矩阵的行和标签的行必须要一一对应
Xtrain = Xtrain.drop(index = 71737)
Ytrain = Ytrain.drop(index = 71737)
#删除完毕之后,观察原始的数据结构,确认删除正确
Xtrain.shape
Xtest = Xtest.drop(index = [19646,29632])
Ytest = Ytest.drop(index = [19646,29632])
Xtest.shape
#进行任何行删除之后,千万记得要恢复索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
Xtrain.head()
Xtest.head()
'''
"""
#=======================================
#(2)处理困难特征:日期
#即文字型变量转化为数字型变量。
#数字型变量存在分类型和连续型,判断这两种不同类型会对我们的数据预处理造成什么样的影响。
#存在缺失值,需要将缺失值填上。
#以上这些问题,需要按照什么顺序来进行处理呢?
#编码文字型变量的类是不能接受空值作为单独一类的,所以我们必须先填缺失值,然后再做编码或者哑变量。
#在填补缺失值时,分类型变量与连续型变量需要分开填,填补分类型变量与连续型变量的手段是不一样的。
#填缺失值时,必须要是数字。所以这就产生了死循环。
#非常纠结,所以这里提供一个通用的基本顺序。
#首先处理那些很难的特征,算法很难理解的,或者其含义很难被算法吸收的特征,比如说日期或者时间,这样的特征很难,需要先将其想办法转化成某一个带有有效信息的这样一个标准,然后才能将其当做是数字也好、文字也好去对它进行处理。
#处理完毕后先填补缺失值,缺失值填补完毕后,再进行编码。
#所以将缺失值填补完毕后才能做后续的处理。
#首先处理困难特征:日期。
Xtrain.head() #日期是第一列

#切片出来
Xtrain.iloc[0,0]

#切片出来的第一行第一列的日期为字符串类型
type(Xtrain.iloc[0,0])
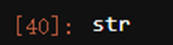
#首先需要将其转化为数字类型
#处理成怎样的数字才合适呢?
#我们现在拥有的日期特征,是连续型特征,还是分类型特征。
#2019-1-6;
#2019-1-6.5这样的天数是不存在的;
#日期是一年分了365类的分类型变量。
#我们的日期特征中,日期是否有重复。
Xtrain.iloc[:,0].value_counts()
#发现日期不是连续型变量

#首先,日期不是独一无二的,日期有重复
#其次,在我们分训练集和测试集之后,日期也不是连续的,而是分散的
#某一年的某一天倾向于会下雨?或者倾向于不会下雨吗?
#不是日期影响了下雨与否,反而更多的是这一天的日照时间,湿度,温度等等这些因素影响了是否会下雨
#光看日期,其实感觉它对我们的判断并无直接影响
#如果我们把它当作连续型变量处理,那算法会认为它是一系列1~3000左右的数字,不会意识到这是日期
Xtrain.iloc[:,0].value_counts().count()
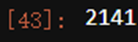
#如果我们把它当作分类型变量处理,类别太多,有2141类,如果换成数值型,会被直接当成连续型变量,如果做成哑变量,我们特征的维度会爆炸
#所以日期既不是连续型变量也不是分类型变量,会给模型带来误解。
#如果我们的思考简单一些,我们可以直接删除日期这个特征。
#首先它不是一个直接影响我们标签的特征,并且要处理日期其实是非常困难的。
#如果大家认可这种思路,那可以直接运行下面的代码来删除我们的日期:
#Xtrain = Xtrain.drop(["Date"],axis=1)
#Xtest = Xtest.drop(["Date"],axis=1)
#但在这里,很多人可能会持不同意见,怎么能够随便删除一个特征(哪怕我们已经觉得它可能无关)?
#其实我们可以想到,日期必然是和我们的结果有关的,它会从两个角度来影响我们的标签:
#首先,我们可以想到,昨天的天气可能会影响今天的天气,而今天的天气又可能会影响明天的天气。
#也就是说,随着日期的逐渐改变,样本是会受到上一个样本的影响的。但是对于算法来说,普通的算法是无法捕捉到样本与样本之间的联系的,我们的算法捕捉的是样本的每个特征与标签之间的联系(即列与列之间的联系),而无法捕捉样本与样本之间的联系(行与行的联系)。
#要让算法理解上一个样本的标签可能会影响下一个样本的标签,我们必须使用时间序列分析。
#时间序列分析是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。
#时间序列分析的主要目的是根据已有的历史数据对未来进行预测。
#然而,(据我所知)时间序列只能在单调的,唯一的时间上运行,即一次只能够对一个地点进行预测,不能够实现一次性预测多个地点,除非进行循环。
#而我们的时间数据本身,不是单调的,也不是唯一的,经过抽样之后,甚至连连续的都不是了,我们的时间是每个混杂在多个地点中,每个地点上的一小段时间。
#如何使用时间序列来处理这个问题,就会变得复杂。
#时间为什么有重复:
#是因为存在不同的地点有相同时间的观察
Xtrainc = Xtrain.copy()
#特征矩阵按照地点排序:
Xtrainc.sort_values(by="Location")
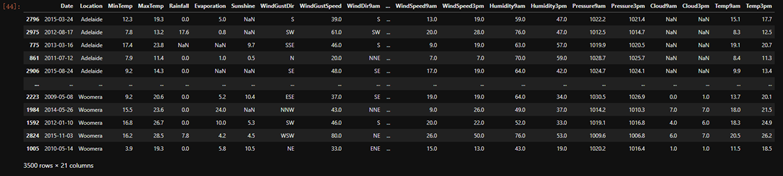
#不同地点上一段相似的时间的数据:
Xtrain.loc[Xtrain.iloc[:,0] == '2015-08-24',:]

#那我们可以换一种思路,既然算法处理的是列与列之间的关系,我是否可以把”今天的天气会影响明天的天气“这个指标转换成一个特征呢?我们就这样来操作。
#我们观察到,我们的特征中有一列叫做“Rainfall",这是表示当前日期当前地区下的降雨量,换句话说,也就是”今天的降雨量“。
#凭常识我们认为,今天是否下雨,应该会影响明天是否下雨,比如有的地方可能就有这样的气候,一旦下雨就连着下很多天,也有可能有的地方的气候就是一场暴雨来得快去的快。
#因此,我们可以将时间对气候的连续影响,转换为”今天是否下雨“这个特征,巧妙地将样本对应标签之间的联系,转换成是特征与标签之间的联系了。
Xtrain["Rainfall"].head(20)

#存在空值
#假设没有下雨
Xtrain["Rainfall"].isnull().sum()

#RainToday这一列在dataframe中不存在的话,pandas会自动创建RainToday这一列。
Xtrain.loc[Xtrain["Rainfall"] >= 1,"RainToday"] = "Yes"
Xtrain.loc[Xtrain["Rainfall"] < 1,"RainToday"] = "No"
Xtrain.loc[Xtrain["Rainfall"] == np.nan,"RainToday"] = np.nan
Xtest.loc[Xtest["Rainfall"] >= 1,"RainToday"] = "Yes"
Xtest.loc[Xtest["Rainfall"] < 1,"RainToday"] = "No"
Xtest.loc[Xtest["Rainfall"] == np.nan,"RainToday"] = np.nan
Xtrain.head()

Xtrain.loc[:,'RainToday'].value_counts()

Xtest.head()

Xtest.loc[:,'RainToday'].value_counts()

#如此,我们就创造了一个特征,今天是否下雨“RainToday”。
#那现在,我们是否就可以将日期删除了呢?对于我们而言,日期本身并不影响天气,但是日期所在的月份和季节其实是影响天气的,如果任选梅雨季节的某一天,那明天下雨的可能性必然比非梅雨季节的那一天要大。
#虽然我们无法让机器学习体会不同月份是什么季节,但是我们可以对不同月份进行分组,算法可以通过训练感受到,“这个月或者这个季节更容易下雨”。
#因此,我们可以将月份或者季节提取出来,作为一个特征使用,而舍弃掉具体的日期。
#如此,我们又可以创造第二个特征,月份"Month"。
Xtrain.loc[0,"Date"].split("-") #按照“-”进行分割,且返回列表

int(Xtrain.loc[0,"Date"].split("-")[1]) #提取出月份
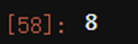
#apply是对dataframe上的某一列进行处理的一个函数。
#lambda匿名函数,lambda x匿名函数,请在dataframe上这一列中的每一行帮我执行冒号后的命令。
#其中lambda x中的x表示某一列的每一个对象。
#用这种方式代替了循环,循环非常缓慢,在工作中,能不用循环就不用循环。
Xtrain["Date"] = Xtrain["Date"].apply(lambda x:int(x.split("-")[1]))
Xtrain.head() #发现date这列只有月份了

Xtrain.loc[:,'Date'].value_counts()

#替换完毕后,我们需要修改列的名称
#以前使用的是Xtrain.columns = ['列名1','列名2'...]这种方式,该方式需替换全部列名。
#但是我们这里只要修改一个列名。
#rename是比较少用的,可以用来修改单个列名的函数
#我们通常都直接使用 df.columns = 某个列表 这样的形式来一次修改所有的列名
#但rename允许我们只修改某个单独的列
Xtrain = Xtrain.rename(columns={"Date":"Month"})
Xtrain.head()

#我们处理完了训练集的后,对测试集也进行处理。
Xtest["Date"] = Xtest["Date"].apply(lambda x:int(x.split("-")[1]))
Xtest = Xtest.rename(columns={"Date":"Month"})
Xtest.head()

#通过时间date,我们处理出两个新特征,“今天是否下雨”和“月份”。
#=======================================
#(3)处理困难特征:地点
#接下来,让我们来看看如何处理另一个更加困难的特征,地点。
Xtrain.loc[:,'Location'].value_counts().count()
#超过25个类别的分类变量都会被算法判断为连续型变量
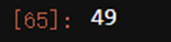
#如果我们能够将地点转换为这个地方的气候的话,我们就可以将不同城市打包到同一个气候中,
#而同一个气候下反应的降雨情况应该是相似的。
#那我们如何将城市转换为气候呢?
#基于气象局和ABCB的数据,我为大家制作了澳大利亚主要城市所对应的气候类型数据,并保存在csv文件city_climate.csv当中。
#为什么我们会需要城市的经纬度呢?
#我曾经尝试过直接使用样本中的城市来爬取城市本身的气候,然而由于样本中的地点名称,其实是气候站的名称,而不是城市本身的名称,因此不是每一个城市都能够直接获取到城市的气候。
#比如说,如果我们搜索“海淀区气候”,搜索引擎返回的可能是海淀区现在的气温,而不是整个北京的气候类型。
#因此,我们需要澳大利亚气象局的数据,来找到这些气候站所对应的城市。
#我们有了澳大利亚全国主要城市的气候,也有了澳大利亚主要城市的经纬度(地点),我们就可以通过计算我们样本中的每个气候站到各个主要城市的地理距离,来找出一个离这个气象站最近的主要城市,而这个主要城市的气候就是我们样本点所在的地点的气候。
#爬虫的代码如下所示,大家可以把谷歌的主页换成百度,修改一下爬虫的命令,就可以自己试试看这段代码。注意要先定义你需要爬取的城市名称的列表cityname哦。
import time
from selenium import webdriver #导入需要的模块,其中爬虫使用的是selenium
import pandas as pd
import numpy as np
#导入元数据
city = pd.read_csv(r'D:\whole_development_of_the_stack_study\RS_Algorithm_Course\Practical\machine_learning\08_09_10_11SVM_01\Cityclimate.csv')
city.head() #第一列是城市名,第二列是气候。

#提取城市名
cityname = city.iloc[:,0]
cityname

#开始爬虫
df =pd.DataFrame(index = cityname.index) #创建新dataframe用于存储爬取的数据
driver = webdriver.Chrome() #调用谷歌浏览器
time0 = time.time() #计时开始
#循环开始
for num,city in enumerate(cityname): #在城市名称中进行遍历
#首先打开谷歌浏览器
driver.get('https://www.google.co.uk/webhp?hl=en&sa=X&ved=0ahUKEwimtcX24cTfAhUJE7wKHVkWB5AQPAgH')
#停留1秒让我们知道发生了什么
time.sleep(1)
#锁定谷歌的搜索框 ,因为谷歌搜索框的name="q"
search_box = driver.find_element_by_name('q')
#在输入框中输入“城市” 澳大利亚 经纬度
search_box.send_keys("%s Australia Latitude and longitude" % (city))
#enter,确认开始搜索
search_box.submit()
#爬取需要的经纬度
result = driver.find_element_by_xpath('//div[@class="Z0LcW"]').text
#将爬取的结果用split进行分割
resultsplit = result.split(" ")
#向提前创建好的df中输入爬取的数据,第一列是城市名
df.loc[num,"City"] = city
#第二列是纬度
df.loc[num,"Latitude"] = resultsplit[0]
#第三列是经度
df.loc[num,'Longitude'] = resultsplit[2]
#第四列是纬度的方向
df.loc[num,"Latitudedir"] = resultsplit[1]
#第五列是经度的方向
df.loc[num,"Longitudedir"] = resultsplit[3]
#每次爬虫成功之后,就打印“城市”成功了
print("%i webcrawler successful for city %s" %(num, city))
time.sleep(1) #全部爬取完毕后,停留1秒钟
driver.quit() #关闭浏览器
print(time.time()-time0) #打印所需的时间

df #所有城市的经纬度

df.to_csv(r"D:\whole_development_of_the_stack_study\RS_Algorithm_Course\Practical\machine_learning\08_09_10_11SVM_01\csv\cityll.csv")
#让我们把cityll.csv和cityclimate.csv来导入,来看看它们是什么样子:
cityll = pd.read_csv(r"D:\whole_development_of_the_stack_study\RS_Algorithm_Course\Practical\machine_learning\08_09_10_11SVM_01\cityll.csv",index_col=0)
city_climate = pd.read_csv(r"D:\whole_development_of_the_stack_study\RS_Algorithm_Course\Practical\machine_learning\08_09_10_11SVM_01\Cityclimate.csv")
#每个城市对应的经纬度,这些城市是澳大利亚统计局做的那张地图上的城市
cityll.head()

#澳大利亚统计局做的每个城市对应的气候
city_climate.head()

#接下来,我们来将这两张表处理成可以使用的样子,首先要去掉cityll中经纬度上带有的度数符号,然后要将两张表合并起来。
#切到倒数第一个位置,并转换成为浮点数
#纬度
float(cityll.loc[0,'Latitude'][:-1])

#去掉度数符号
cityll["Latitudenum"] = cityll["Latitude"].apply(lambda x:float(x[:-1]))
cityll["Longitudenum"] = cityll["Longitude"].apply(lambda x:float(x[:-1]))
cityll.head()

#观察一下所有的经纬度方向都是一致的,全部是南纬,东经,因为澳大利亚在南半球,东半球
#所以经纬度的方向我们可以舍弃了
#所有城市都是南半球的
cityll.loc[:,"Latitudedir"].value_counts()

citylld = cityll.iloc[:,[0,5,6]]
citylld

#将city_climate中的气候添加到我们的citylld中
#这里直接合并是因为顺序完全相同,如果两者参照的city列中的名称顺序不同,则需要使用map函数来合并。
#map使用方法:
# define square(x):
# return (x ** 2)
# df['col2'] = df['col1'].map(square)
citylld["climate"] = city_climate.iloc[:,-1]
citylld.head()

#查看气候类型
citylld.loc[:,"climate"].value_counts()

#接下来,我们如果想要计算距离,我们就会需要所有样本数据中的城市。
#我们认为,只有出现在训练集中的地点才会出现在测试集中,基于这样的假设,我们来爬取训练集中所有的地点所对应的经纬度,并且保存在一个csv文件samplecity.csv中:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
weather = pd.read_csv(r"D:\whole_development_of_the_stack_study\RS_Algorithm_Course\Practical\machine_learning\08_09_10_11SVM_01\weatherAUS5000.csv",index_col=0)
#将特征矩阵和标签Y分开
X = weather.iloc[:,:-1]
Y = weather.iloc[:,-1]
#分训练集和测试集,是随机抽样
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y,test_size=0.3,random_state=420)
#恢复索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0]) #0到行数-1
#训练集中所有的地点
cityname = Xtrain.iloc[:,1].value_counts().index.tolist()
cityname
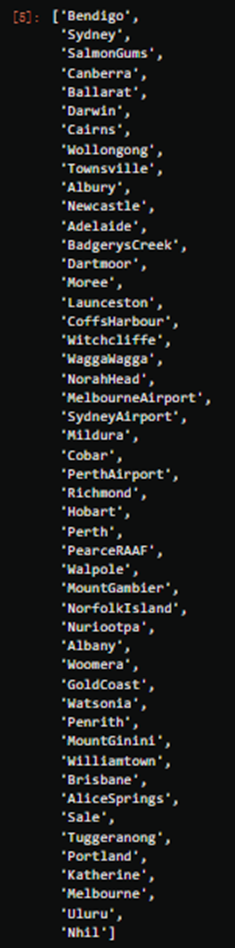
#开始爬虫
import time
from selenium import webdriver #导入需要的模块,其中爬虫使用的是selenium
df = pd.DataFrame(index=range(len(cityname))) #创建新dataframe用于存储爬取的数据
driver = webdriver.Chrome() #调用谷歌浏览器
time0 = time.time() #计时开始
#循环开始
for num, city in enumerate(cityname): #在城市名称中进行遍历
driver.get('https://www.google.co.uk/webhp?hl=en&sa=X&ved=0ahUKEwimtcX24cTfAhUJE7wKHVkWB5AQPAgH')
#首先打开谷歌主页
time.sleep(0.5)
#停留0.5秒让我们知道发生了什么
search_box = driver.find_element_by_name('q') #锁定谷歌的搜索输入框
search_box.send_keys('%s Australia Latitude and longitude' % (city)) #在输入框中输入“城市” 澳大利亚 经纬度
search_box.submit() #enter,确认开始搜索
result = driver.find_element_by_xpath('//div[@class="Z0LcW"]').text #?爬取需要的经纬度,就是这里,怎么获取的呢?
resultsplit = result.split(" ") #将爬取的结果用split进行分割
df.loc[num,"City"] = city #向提前创建好的df中输入爬取的数据,第一列是城市名
df.loc[num,"Latitude"] = resultsplit[0] #第二列是经度
df.loc[num,"Longitude"] = resultsplit[2] #第三列是纬度
df.loc[num,"Latitudedir"] = resultsplit[1] #第四列是经度的方向
df.loc[num,"Longitudedir"] = resultsplit[3] #第五列是纬度的方向
print("%i webcrawler successful for city %s" % (num,city)) #每次爬虫成功之后,就打印“城市”成功了
time.sleep(1) #全部爬取完毕后,停留1秒钟
driver.quit() #关闭浏览器
print(time.time() - time0) #打印所需的时间

df

df.to_csv(r"D:\whole_development_of_the_stack_study\RS_Algorithm_Course\Practical\machine_learning\08_09_10_11SVM_01\csv\samplecity.csv")
#来查看一下我们爬取出的内容是什么样子:
samplecity = pd.read_csv(r"D:\whole_development_of_the_stack_study\RS_Algorithm_Course\Practical\machine_learning\08_09_10_11SVM_01\samplecity.csv",index_col=0)
samplecity.head()

#我们对samplecity也执行同样的处理:去掉经纬度中度数的符号,并且舍弃我们的经纬度的方向
samplecity["Latitudenum"] = samplecity["Latitude"].apply(lambda x:float(x[:-1]))
samplecity["Longitudenum"] = samplecity["Longitude"].apply(lambda x:float(x[:-1]))
samplecityd = samplecity.iloc[:,[0,5,6]]
samplecityd.head()

#计算城市之间的距离
#好了,我们现在有了澳大利亚主要城市的经纬度和对应的气候,也有了我们的样本的地点所对应的经纬度,接下来我们要开始计算我们样本上的地点到每个澳大利亚主要城市的距离,而离我们的样本地点最近的那个澳大利亚主要城市的气候,就是我们样本点的气候。
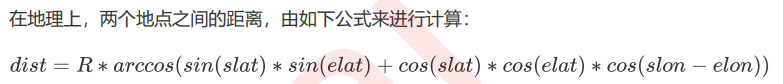
#首先使用radians将角度转换成弧度
from math import radians, sin, cos, acos
citylld.loc[:,"slat"] = citylld.iloc[:,1].apply(lambda x : radians(x))
citylld.loc[:,"slon"] = citylld.iloc[:,2].apply(lambda x : radians(x))
samplecityd.loc[:,"elat"] = samplecityd.iloc[:,1].apply(lambda x : radians(x))
samplecityd.loc[:,"elon"] = samplecityd.iloc[:,2].apply(lambda x : radians(x))
citylld.head()

samplecityd.head()

slat = citylld.loc[:,"slat"]
slat

import sys
for i in range(samplecityd.shape[0]):
slat = citylld.loc[:,"slat"]
slon = citylld.loc[:,"slon"]
elat = samplecityd.loc[i,"elat"]
elon = samplecityd.loc[i,"elon"]
dist = 6371.01 * np.arccos(np.sin(slat)*np.sin(elat) +
np.cos(slat)*np.cos(elat)*np.cos(slon.values - elon))
city_index = np.argsort(dist)[0] #.argsort是进行排序并且返回索引,取得离气象站最近距离的城市的索引值
#每次计算后,取距离最近的城市,然后将最近的城市和城市对应的气候都匹配到samplecityd中
samplecityd.loc[i,"closest_city"] = citylld.loc[city_index,"City"]
samplecityd.loc[i,"climate"] = citylld.loc[city_index,"climate"]
#查看最后的结果,需要检查城市匹配是否基本正确
samplecityd.head(5)
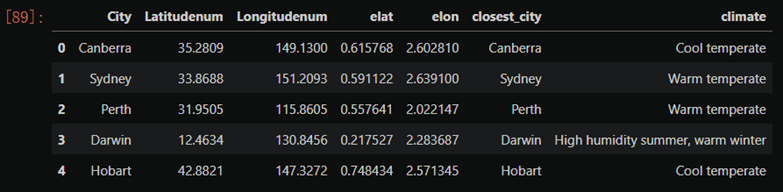
#查看气候的分布
samplecityd["climate"].value_counts()

#确认无误后,取出样本城市所对应的气候,并保存
locafinal = samplecityd.iloc[:,[0,-1]]
locafinal.head()

locafinal.columns = ["Location","Climate"]
locafinal.head()

#在这里设定locafinal的索引为地点,是为了之后进行map的匹配
locafinal = locafinal.set_index(keys="Location")
locafinal

locafinal.to_csv(r"D:\whole_development_of_the_stack_study\RS_Algorithm_Course\Practical\machine_learning\08_09_10_11SVM_01\samplelocation.csv")
locafinal.head()

#有了每个样本城市所对应的气候,我们接下来就使用气候来替掉原本的城市,原本的气象站的名称。
#在这里,我们可以使用map功能,map能够将特征中的值一一对应到我们设定的字典中,并且用字典中的值来替换样本中原本的值,我们在评分卡中曾经使用这个功能来用WOE替换我们原本的特征的值。
#是否还记得训练集长什么样呢?
Xtrain.head()

#将location中的内容替换,并且确保匹配进入的气候字符串中不含有逗号,气候两边不含有空格
#我们使用re这个模块来消除逗号
#re.sub(希望替换的值,希望被替换成的值,要操作的字符串) #去掉逗号
#x.strip()是去掉空格的函数
#把localtion替换成气候的是我们的map的映射
import re
#气象站的名字替换成了对应的城市对应的气候
Xtrain["Location"] = Xtrain["Location"].map(locafinal.iloc[:,0])
Xtrain.head()

#城市的气候中所含的逗号和空格都去掉
#sub()第一个参数是想要替换的值,第二个参数是替换成为的值,第三个参数表示想要替换的东西是什么。
#x.strip()把内容中的两边的空格都去掉
Xtrain["Location"] = Xtrain["Location"].apply(lambda x:re.sub(",","",x.strip()))
Xtrain.head()
#在sklearn中有些类是不处理逗号的,如果用字符串做哑变量,会报这里面有逗号,需要去除掉。

#测试集执行相同的命令
Xtest["Location"] = Xtest["Location"].map(locafinal.iloc[:,0]).apply(lambda x:re.sub(",","",x.strip()))
#修改特征内容之后,我们使用新列名“Climate”来替换之前的列名“Location”
#注意这个命令一旦执行之后,就再没有列"Location"了,使用索引时要特别注意
Xtrain = Xtrain.rename(columns={"Location":"Climate"})
Xtest = Xtest.rename(columns={"Location":"Climate"})
Xtrain.head()

Xtest.head()

#到这里,地点就处理完毕了。其实,我们还没有将这个特征转化为数字,即还没有对它进行编码。我们稍后和其他的分类型变量一起来编码。
#=======================================
#(4)处理分类型变量:缺失值填补
#首先我们要注意到,由于我们的特征矩阵由两种类型的数据组成:分类型和连续型,因此我们必须对两种数据采用不同的填补缺失值策略。
#传统地,如果是分类型特征,我们则采用众数进行填补。如果是连续型特征,我们则采用均值来填补。
#查看缺失值的缺失情况
Xtrain.isnull().mean()
#在现实当中,缺失值所占比例小于0.01一下的,可以直接将样本行删除,缺的太少就没有必要去补充了。

Xtrain.info()
#查看信息后,一般分类型的数据类型为object,大多数是文字

#查看分类型特征有哪些
Xtrain.dtypes
#返回了每个特征所对应的数据类型

#返回布尔序列
Xtrain.dtypes == 'object'

Xtrain.columns

#分类型特征
#首先找出,分类型特征都有哪些
cate = Xtrain.columns[Xtrain.dtypes == "object"].tolist()
cate

#除了特征类型为"object"的特征们,还有虽然用数字表示,但是本质为分类型特征的云层遮蔽程度
#0到8,代表不同云层遮蔽程度,一个是早上9点,一个是下午3点。
cloud = ["Cloud9am","Cloud3pm"]
cate = cate + cloud
cate

#对于分类型特征,我们使用众数来进行填补
from sklearn.impute import SimpleImputer #升级到0.20版本
#参数一:缺失值是什么;参数二:填补缺失值的方式。
si = SimpleImputer(missing_values=np.nan, strategy="most_frequent")
#实例化SimpleImputer
#注意,我们使用训练集数据来训练我们的填补器,本质是在生成训练集中的众数
#要训练的部分只是我们的分类型特征的部分。
si.fit(Xtrain.loc[:,cate])

#然后我们用训练集中的众数来同时填补训练集和测试集
Xtrain.loc[:,cate] = si.transform(Xtrain.loc[:,cate])
Xtest.loc[:,cate] = si.transform(Xtest.loc[:,cate])
Xtrain.head()

Xtest.head()

#查看分类型特征是否依然存在缺失值
Xtrain.loc[:,cate].isnull().mean()

Xtest.loc[:,cate].isnull().mean()

#以上分类型特征的缺失值填补完毕。
#=======================================
(5)处理分类型变量:将分类型变量编码
#只有分类型变量需要编码,而连续型变量是不需要编码的
#我们也是需要先用训练集fit模型,本质是将训练集中已经存在的类别转换成是数字,然后我们再使用接口transform分别在测试集和训练集上来编码我们的特征矩阵。
#当我们使用接口在测试集上进行编码的时候,如果测试集上出现了训练集中从未出现过的类别,那代码就会报错,表示说“我没有见过这个类别,我无法对这个类别进行编码”,此时此刻你就要思考,你的测试集上或许存在异常值,错误值,或者的确有一个新的类别出现了,而你曾经的训练数据中并没有这个类别。以此为基础,你需要调整你的模型。
#将所有的分类型变量编码为数字,一个类别是一个数字。
#我们需要考虑编码的本质,Climate、WindGustDir、RainToday这些是不能加减的
#Cloud9am、Cloud3pm云层遮蔽程度之间是可以加减的。
#这样是否说明Climate、WindGustDir、RainToday这些特征作为哑变量呢?
#如果做了哑变量后特征会变得非常多,对支持向量机是一个很大的负担。
#所以先不做哑变量,先作为普通编码,如果不好再做哑变量。
#这里只做普通编码
from sklearn.preprocessing import OrdinalEncoder #只允许二维以上的数据进行输入的类
oe = OrdinalEncoder()
#利用训练集进行fit,训练分类变量特征列
oe = oe.fit(Xtrain.loc[:,cate])
#用训练集的编码结果来编码训练和测试特征矩阵
#在这里如果测试特征矩阵报错,就说明测试集中出现了训练集中从未见过的类别
Xtrain.loc[:,cate] = oe.transform(Xtrain.loc[:,cate])
Xtest.loc[:,cate] = oe.transform(Xtest.loc[:,cate])
Xtrain.loc[:,cate].head()

Xtest.loc[:,cate].head()

Xtrain.head()

#到这里分类型变量就处理完毕了,注意,一定是先填缺失值,再进行编码。
#=======================================
(6)处理连续型变量:填补缺失值
#连续型变量往往已经是数字,无需进行编码转换。
#与分类型变量中一样,我们也是使用训练集上的均值对测试集进行填补。
#如果学过随机森林填补缺失值的小伙伴,可能此时会问,为什么不使用算法来进行填补呢?
#使用算法进行填补也是没有问题的,但在现实中,其实我们非常少用到算法来进行填补,有以下几个理由:
#1. 算法是黑箱,解释性不强。如果你是一个数据挖掘工程师,你使用算法来填补缺失值后,你不懂机器学习的老板或者同事问你的缺失值是怎么来的,你可能需要从头到尾帮他/她把随机森林解释一遍,这种效率过低的事情是不可能做的,而许多老板和上级不会接受他们无法理解的东西。
#2. 算法填补太过缓慢,运行一次森林需要有至少100棵树才能够基本保证森林的稳定性,而填补一个列就需要很长的时间。在我们并不知道森林的填补结果是好是坏的情况下,填补一个很大的数据集风险非常高,有可能需要跑好几个小时,但填补出来的结果却不怎么优秀,这明显是一个低效的方法。
#因此在现实工作时,我们往往使用易于理解的均值或者中位数来进行填补。
#当然了,在算法比赛中,我们可以穷尽一切我们能够想到的办法来填补缺失值以追求让模型的效果更好,不过现实中,除了模型效果之外,我们还要追求可解释性。
#取出所有列名称
Xtrain.columns

col = Xtrain.columns.tolist()
col

#分类型变量的列名
cate

#剔除分类型标签:
for i in cate:
col.remove(i)
col #剩下的只有连续型特征了

#实例化模型,填补策略为"mean"表示均值
impmean = SimpleImputer(missing_values=np.nan,strategy = "mean")
#用训练集来fit模型
impmean = impmean.fit(Xtrain.loc[:,col])
#分别在训练集和测试集上进行均值填补
Xtrain.loc[:,col] = impmean.transform(Xtrain.loc[:,col])
Xtest.loc[:,col] = impmean.transform(Xtest.loc[:,col])
Xtrain.isnull().sum()

Xtest.isnull().sum()

#连续型变量还需要进行数据的无量纲化处理
#=======================================
#(7)处理连续型变量:无量纲化
#这个操作我们不对分类型变量进行。
#发现分类型里面不包含月份
cate
#月份为分类型

#需要将连续型特征中移除月份这个特征
col.remove("Month")
col

#标准化
#StandardScaler数据转换为均值为0,方差为1的数据
#StandardScaler标准化不改变数据分布,即不会变成正态分布,只能让数据变成均值为0,方差为1,其他什么都没有。
#注意:任何一个数据集均值为0、方差为1,和这个数据集满足均值为0、方差为1的正太分布是完全不同的两种概念。
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss = ss.fit(Xtrain.loc[:,col])
Xtrain.loc[:,col] = ss.transform(Xtrain.loc[:,col])
Xtest.loc[:,col] = ss.transform(Xtest.loc[:,col])
Xtrain.head()

Xtest.head()

#已经做完全部的特征工程了
#将数据处理完毕之后,建议大家都使用to_csv来保存我们已经处理好的数据集,避免我们在后续建模过程中出现覆盖了原有的数据集的失误后,需要从头开始做数据预处理。在开始建模之前,无比保存好处理好的数据,然后在建模的时候,重新将数据导入。
#=======================================
#4、建模与模型评估
from time import time #随时监控我们的模型的运行时间
import datetime
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import roc_auc_score, recall_score
Ytrain = Ytrain.iloc[:,0].ravel()
Ytest = Ytest.iloc[:,0].ravel()
#建模选择自然是我们的支持向量机SVC,首先用核函数的学习曲线来选择核函数
#我们希望同时观察,精确性,recall以及AUC分数
times = time() #因为SVM是计算量很大的模型,所以我们需要时刻监控我们的模型运行时间
for kernel in ["linear","poly","rbf","sigmoid"]:
clf = SVC(kernel = kernel
,gamma="auto"
,degree = 1
,cache_size = 10000 #设定越大,代表允许我们的算法使用越多的内存来进行计算。
).fit(Xtrain, Ytrain)
result = clf.predict(Xtest) #获取模型的预测结果
score = clf.score(Xtest,Ytest) #接口score返回的是准确度accuracy
recall = recall_score(Ytest, result) #recall召回的分数 ,参数是真实值和预测值
auc = roc_auc_score(Ytest,clf.decision_function(Xtest)) #roc曲线auc面积的值,参数1:真实值;参数2:置信度(概率、距离)
print("%s 's testing accuracy %f, recall is %f', auc is %f" %(kernel,score,recall,auc))
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
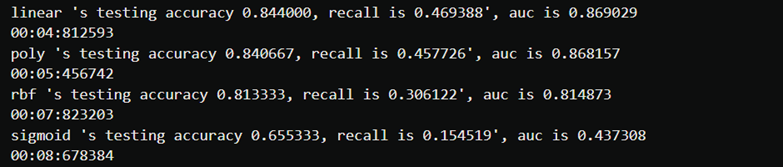
#归一化后的数据,线性要好于其他的kernel情况,就说明数据呈现线性状态。
#我们可以有不同的目标:
#一,我希望不计一切代价判断出少数类,得到最高的recall。
#二,我们希望追求最高的预测准确率,一切目的都是为了让accuracy更高,我们不在意recall或者AUC。
#三,我们希望达到recall,ROC和accuracy之间的平衡,不追求任何一个也不牺牲任何一个。
#=======================================
5、模型调参
#=======================================
(1)追求最高Recall
#如果要求较好的召回率,首选调整class_weight这个参数。
#如果我们想要的是最高的recall,可以牺牲我们准确度,希望不计一切代价来捕获少数类,
#那我们首先可以打开我们的class_weight参数,使用balanced模式来调节我们的recall:
times = time()
for kernel in ["linear","poly","rbf","sigmoid"]:
clf = SVC(kernel = kernel
,gamma="auto"
,degree = 1
,cache_size = 10000
,class_weight = "balanced"
).fit(Xtrain, Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest, result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print("%s 's testing accuracy %f, recall is %f', auc is %f" %(kernel,score,recall,auc))
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
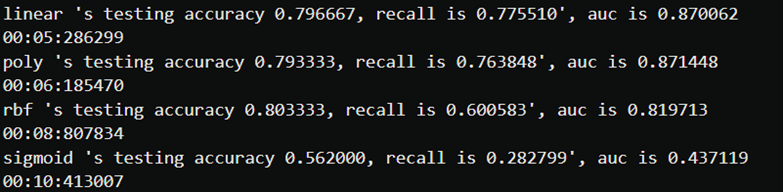
#确定使用线性核函数:
#在锁定了线性核函数之后,我甚至可以将class_weight调节得更加倾向于少数类,来不计代价提升recall。
times = time()
clf = SVC(kernel = "linear"
,gamma="auto"
,cache_size = 10000
,class_weight = {1:10} #注意 这里1:10表示,前面1表示类别1,后面10表示少数类1的权重为10,而隐藏了多数类0的权重为1
).fit(Xtrain, Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest, result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print("testing accuracy %f, recall is %f', auc is %f" %(score,recall,auc))
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))

#随着recall地无节制上升,我们的精确度下降得十分厉害,不过看起来AUC面积却还好,稳定保持在0.86左右。
#如果此时我们的目的就是追求一个比较高的AUC分数和比较好的recall,那我们的模型此时就算是很不错了。
#虽然现在,我们的精确度很低,但是我们的确精准地捕捉出了每一个雨天。
#=======================================
#(2)追求最高准确率
#在我们现有的目标(判断明天是否会下雨)下,追求最高准确率而不顾recall其实意义不大, 但出于练习的目的,我们来看看我们能够有怎样的思路。
#此时此刻我们不在意我们的Recall了,那我们首先要观察一下,我们的样本不均衡状况。
#如果我们的样本非常不均衡,但是此时却有很多多数类被判错的话,那我们可以让模型任性地把所有地样本都判断为0,完全不顾少数类。
valuec = pd.Series(Ytest).value_counts()
valuec
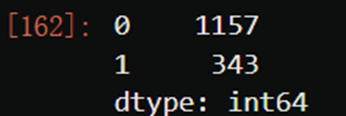
valuec[0]/valuec.sum()

#初步判断,可以认为我们其实已经将大部分的多数类判断正确了,所以才能够得到现在的正确率。
#为了证明我们的判断,我们可以使用混淆矩阵来计算我们的特异度,如果特异度非常高,则证明多数类上已经很难被操作了。
#查看模型的特异度
from sklearn.metrics import confusion_matrix as CM
clf = SVC(kernel = "linear"
,gamma="auto"
,cache_size = 5000
).fit(Xtrain, Ytrain)
result = clf.predict(Xtest)
result

cm = CM(Ytest,result,labels=(1,0))
cm

specificity = cm[1,1]/cm[1,:].sum()
specificity #几乎所有的0都被判断正确了,还有不少1也被判断正确了

#可以看到,特异度非常高,此时此刻如果要求模型将所有的类都判断为0,则已经被判断正确的少数类会被误伤,整体的准确率一定会下降。
#而如果我们希望通过让模型捕捉更多少数类来提升精确率的话,却无法实现,因为一旦我们让模型更加倾向于少数类,就会有更多的多数类被判错。
#可以试试看使用class_weight将模型向少数类的方向稍微调整,已查看我们是否有更多的空间来提升我们的准确率。
#如果在轻微向少数类方向调整过程中,出现了更高的准确率,则说明模型还没有到极限。
irange = np.linspace(0.01,0.05,10)
irange

for i in irange:
times = time()
clf = SVC(kernel = "linear"
,gamma="auto"
,cache_size = 10000
,class_weight = {1:1+i}
).fit(Xtrain, Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest, result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print("under ratio 1:%f testing accuracy %f, recall is %f', auc is %f" %(1+i,score,recall,auc))
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))

#惊喜出现了,我们的最高准确度是84.53%,超过了我们之前什么都不做的时候得到的84.40%。可见,模型还是有潜力的。
#我们可以继续细化我们的学习曲线来进行调整:
irange_ = np.linspace(0.018889,0.027778,10)
for i in irange_:
times = time()
clf = SVC(kernel = "linear"
,gamma="auto"
,cache_size = 10000
,class_weight = {1:1+i}
).fit(Xtrain, Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest, result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print("under ratio 1:%f testing accuracy %f, recall is %f', auc is %f" %(1+i,score,recall,auc))
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))

#模型的效果没有太好,并没有再出现比我们的84.53%精确度更高的取值。
#可见,模型在不做样本平衡的情况下,准确度其实已经非常接近极限了,让模型向着少数类的方向调节,不能够达到质变。如果我们真的希望再提升准确度,只能选择更换模型的方式,调整参数已经不能够帮助我们了。
#想想看什么模型在线性数据上表现最好呢?
from sklearn.linear_model import LogisticRegression as LR
logclf = LR(solver="liblinear").fit(Xtrain, Ytrain)
logclf.score(Xtest,Ytest)

#逻辑回归调整参数C
C_range = np.linspace(3,5,10)
for C in C_range:
logclf = LR(solver="liblinear",C=C).fit(Xtrain, Ytrain)
print(C,logclf.score(Xtest,Ytest))

#尽管我们实现了非常小的提升,但可以看出来,模型的精确度还是没有能够实现质变。
#也许,要将模型的精确度提升到90%以上,我们需要集成算法:
#比如,梯度提升树。大家如果感兴趣,可以自己下去试试看。
#=======================================
#(3)追求平衡
#我们前面经历了多种尝试,选定了线性核,并发现调节class_weight并不能够使我们模型有较大的改善。
#现在我们来试试看调节线性核函数的C值能否有效果:
###======【TIME WARNING:10mins】======###
import matplotlib.pyplot as plt
C_range = np.linspace(0.01,20,20)
recallall = []
aucall = []
scoreall = []
for C in C_range:
times = time()
clf = SVC(kernel = "linear",C=C,cache_size = 20000
,class_weight = "balanced"
).fit(Xtrain, Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest, result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
recallall.append(recall)
aucall.append(auc)
scoreall.append(score)
print("under C %f, testing accuracy is %f,recall is %f', auc is %f" %(C,score,recall,auc))
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))
print(max(aucall),C_range[aucall.index(max(aucall))])
plt.figure()
plt.plot(C_range,recallall,c="red",label="recall")
plt.plot(C_range,aucall,c="black",label="auc")
plt.plot(C_range,scoreall,c="orange",label="accuracy")
plt.legend()
plt.show()


#可以观察到几个现象。
#首先,我们注意到,随着C值逐渐增大,模型的运行速度变得越来越慢。
#对于SVM这个本来运行就不快的模型来说,巨大的C值会是一个比较危险的消耗。所以正常来说,我们应该设定一个较小的C值范围来进行调整。
#其次,C很小的时候,模型的各项指标都很低,但当C到1以上之后,模型的表现开始逐渐稳定,在C逐渐变大之后,模型的效果并没有显著地提高。
#可以认为我们设定的C值范围太大了,然而再继续增大或者缩小C值的范围,AUC面积也只能够在0.86上下进行变化了,调节C值不能够让模型的任何指标实现质变。
#我们把目前为止最佳的C值带入模型,看看我们的准确率,Recall的具体值:
times = time()
clf = SVC(kernel = "linear",C=3.1663157894736838,cache_size = 5000
,class_weight = "balanced"
).fit(Xtrain, Ytrain)
result = clf.predict(Xtest)
score = clf.score(Xtest,Ytest)
recall = recall_score(Ytest, result)
auc = roc_auc_score(Ytest,clf.decision_function(Xtest))
print("testing accuracy %f,recall is %f', auc is %f" % (score,recall,auc))
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))

#可以看到,这种情况下模型的准确率,Recall和AUC都没有太差,但是也没有太好,这也许就是模型平衡后的一种结果。
#现在,光是调整支持向量机本身的参数,已经不能够满足我们的需求了,要想让AUC面积更进一步,我们需要绘制ROC曲线,查看我们是否可以通过调整阈值来对这个模型进行改进。
from sklearn.metrics import roc_curve as ROC
import matplotlib.pyplot as plt
FPR, Recall, thresholds = ROC(Ytest,clf.decision_function(Xtest),pos_label=1)
area = roc_auc_score(Ytest,clf.decision_function(Xtest))
plt.figure()
plt.plot(FPR, Recall, color='red',
label='ROC curve (area = %0.2f)' % area)
plt.plot([0, 1], [0, 1], color='black', linestyle='--')
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('Recall')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()

#以此模型作为基础,我们来求解最佳阈值:
maxindex = (Recall - FPR).tolist().index(max(Recall - FPR))
thresholds[maxindex]

#基于我们选出的最佳阈值,我们来认为确定y_predict,并确定在这个阈值下的recall和准确度的值:
from sklearn.metrics import accuracy_score as AC
times = time()
clf = SVC(kernel = "linear",C=3.1663157894736838,cache_size = 5000
,class_weight = "balanced"
).fit(Xtrain, Ytrain)
prob = pd.DataFrame(clf.decision_function(Xtest))
prob.loc[prob.iloc[:,0] >= thresholds[maxindex],"y_pred"]=1
prob.loc[prob.iloc[:,0] < thresholds[maxindex],"y_pred"]=0
prob.head()

#查看阈值判断后是否有缺失值
prob.loc[:,"y_pred"].isnull().sum()

#检查模型本身的准确度
score = AC(Ytest,prob.loc[:,"y_pred"].values)
recall = recall_score(Ytest, prob.loc[:,"y_pred"])
print("testing accuracy %f,recall is %f" % (score,recall))
print(datetime.datetime.fromtimestamp(time()-times).strftime("%M:%S:%f"))

#反而还不如我们不调整时的效果好。
#可见,如果我们追求平衡,那SVC本身的结果就已经非常接近最优结果了。
#调节阈值,调节参数C和调节class_weight都不一定有效果。
#但整体来看,我们的模型不是一个糟糕的模型,但这个结果如果提交到kaggle参加比赛是绝对不足够的。
#如果大家感兴趣,还可以更加深入地探索模型,或者换别的方法来处理特征,以达到AUC面积0.9以上,或是准确度或recall都提升到90%以上。