义原(Sememe)在语言学中是指最小的不可再分的语义单位,而知网(HowNet)则是最著名的义原知识库。近些年来,包括知网在内的语言知识库在深度学习模型中的重要性越来越显著,然而,这些人工构建的语言知识库往往面临新词不断出现的挑战。知网也不例外,而且其只为中、英文词标注了义原,这限制了它在其他语言的 NLP 任务中的应用。
近日,在雷锋网 AI 研习社公开课上,清华大学计算机系在读博士岂凡超就分享了采用机器学习的方法为中文新词自动推荐义原,并进一步为其他语言的词语推荐义原。公开课回放视频网址:http://www.mooc.ai/open/course/555?=aitechtalkqifanchao
岂凡超:清华大学计算机系在读博士,导师是孙茂松教授,主要研究方向为自然语言处理,其研究工作曾在 EMNLP 等发表。
分享主题:义原的介绍和义原的自动推荐
分享提纲:
义原和知网介绍
中文新词的义原推荐 [IJCAI 2017, ACL2018]
跨语言词汇的义原推荐 [EMNLP 2018]
雷锋网 AI 研习社将其分享内容整理如下:
今天跟大家分享义原的介绍和义原的自动推荐 。
义原和知网介绍
首先讲一下义原的基本概念。在自然语言处理中,我们会对语言中不同的语义单位进行分析和处理,语义单位包括从比较大的篇章、段落到比较小的句子、短语和词。对一般的自然语言处理任务来说,最小的语义单位可能就是词了,但实际上比词更小的语义单位是存在的——义原。

根据语言学家的定义,义原是最小的不可分的语义单位。有的语言学家认为,包括词在内的所有概念的语义都可使用一个有限的义原集合去表示。而义原是比较隐含的语义单位,所以人们需要利用已经构建好的义原知识库才能够获取一个词所对应的义原。
提到义原知识库,最著名的就是知网(HowNet),它是由董振东和董强两位先生花费了十几年时间,通过人工标注而成的义原知识库,大概使用了 2000 多个义原标注了约 10 万个中文/英文词或短语。左边的图就是知网中对一个词的义原标注的例子。
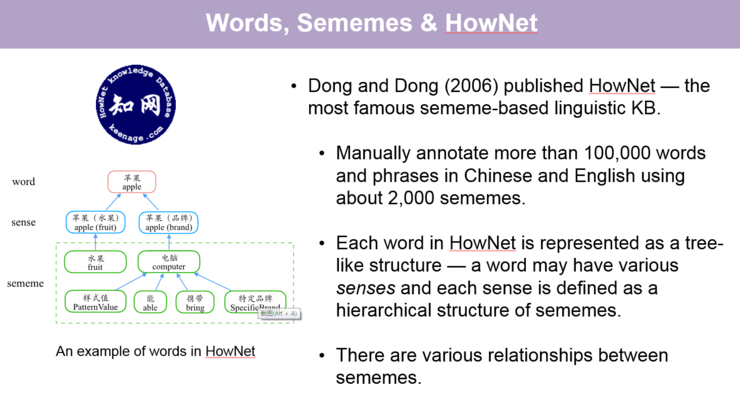
【关于更多对知网的词的案例讲解,请回看视频 00:02:40 处,http://www.mooc.ai/open/course/555?=aitechtalkqifanchao】
知网对词进行了更细粒度的义原标注,因而被广泛用于各项自然语言处理的任务中。比如 2017 年的 Improved Word Representation Learning with Sememes 这篇论文,通过引入义原可以解决词义消歧的问题,并进一步更细致地捕捉到词与词之间的关系来学习更好的词向量。另一例子是今年的一篇论文 Language Modeling with Sparse Product of Sememe Experts,它将义原作为我们称之为「专家」的信息引入语言模型中,也可以更好地预测到一个词出现后下一个词以怎样的方式出现,在义原层面又有一些怎样的关系。
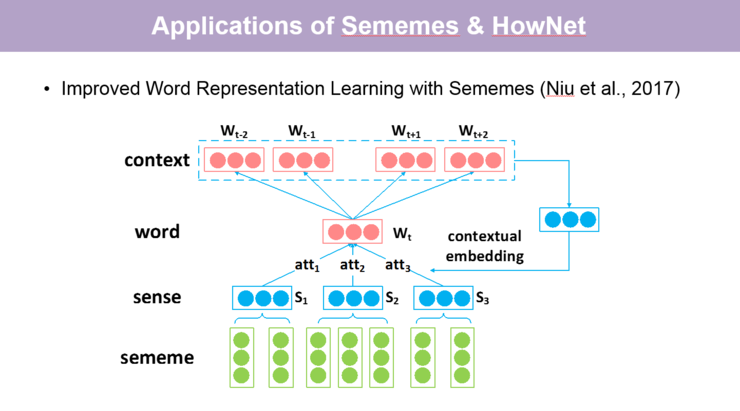
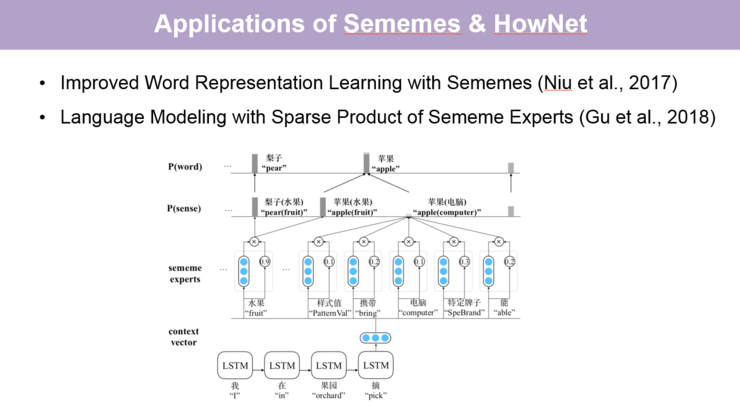
实际上,上世纪 90 年代知网就已经发布,在零几年的时候非常热门,相关的论文也比较多。

【关于两篇论文及其他应用的详细讲解,请回看视频 00:04:50 处,http://www.mooc.ai/open/course/555?=aitechtalkqifanchao】
刚刚我们也提到两位语言学家花费了十几年的时间为词标注义原,然而,每年都有新词不断出现,同时也需要不断去更新、纠正以及完善义原标注体系,而人工的方式非常耗时耗力,所以我们很自然地想到用机器学习来为新词自动标注义原,这是我们做义原预测主要的 motivation。
中文新词的义原推荐 [IJCAI 2017, ACL2018]
关于义原预测,我们组最早有一篇文章,定义了这项任务并提出了两个效果还不错的模型。我首先介绍一下这篇文章,它的核心思路是根据与待标注目标词相似的已标注词的义原标注信息来预测义原,其基本假设是:相似词的义原标注也相似。基于这个思路,这篇文章提出了两个基于推荐系统的模型:第一个是基于协同过滤(collaborative filtering )的方法 SPWE;第二个是基于矩阵分解(matrix factorization )的方法 SPSE。需要补充的是,这两个方法都做了简化,一是忽略了义原的层次结构;二是将词的多义性忽略掉了。
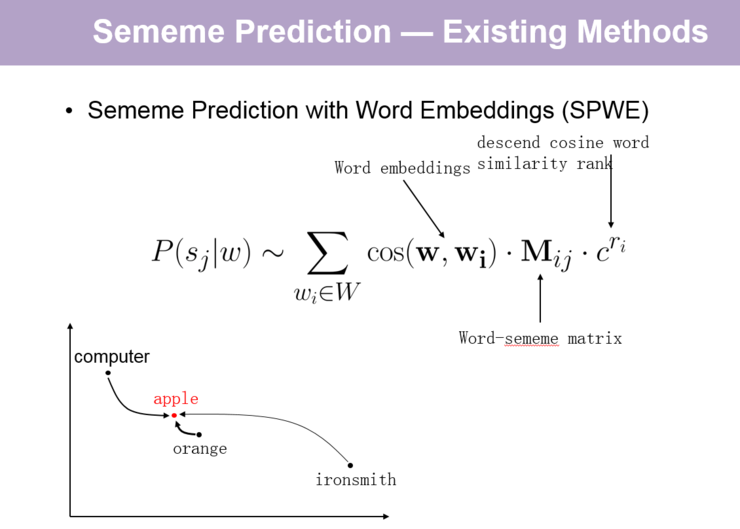

【关于这篇文章的两个模型的具体介绍,请回看视频 00:09:50 处,http://www.mooc.ai/open/course/555?=aitechtalkqifanchao】
但是,这篇文章还有很多问题没有考虑到,比如刚刚提到的这两个模型只考虑了外部信息——预训练的词向量,而词向量是根据外部语料得到的。此外,它们对于语料中出现频率比较少的词的预测效果不好,另外这种方法也无法为语料中没有出现的词推荐义原。

因此我们进行了第二项工作,本次工作考虑到大部分中文词都是合成词——词最终的意义跟组成这个词的各个字的意义紧密相关,比如「铁匠」这个词的合成性就非常明显。由于这项工作利用的是词的内部信息,它对于低频词来说是非常有用的。在这个工作中我们提出了字增强的义原预测(Character-enhanced Sememe Prediction )模型,将词的内部信息和从语料中学到的外部信息(词向量)都用上。

【关于这篇文章的两个模型的具体介绍,请回看视频 00:09:50 处,http://www.mooc.ai/open/course/555?=aitechtalkqifanchao】
在利用词内部信息的模型中,我们用到的第一个方法是 Sememe Prediction with Word-to-Character Filtering(SPWCF),它利用了词到字的过滤来做义原预测,它认为词有三个位置(Begin、 Middle、End),首先统计某个字在某个位置出现时对应的词拥有某个义原的概率,将其作为该字在该位置出现时词拥有该义原的置信度,再把待预测词中各个位置的字所对应的义原置信度相加起来,得到当前待预测词的义原置信度,从而根据义原置信度的排序实现义原预测。

第二个方法是 Sememe Prediction with Character and Sememe Embeddings (SPCSE),这一方法采用了类似 SPSE 的矩阵分解的思路,但是用词中某个字的字向量作为词向量的代表参与分解,来得到义原向量。
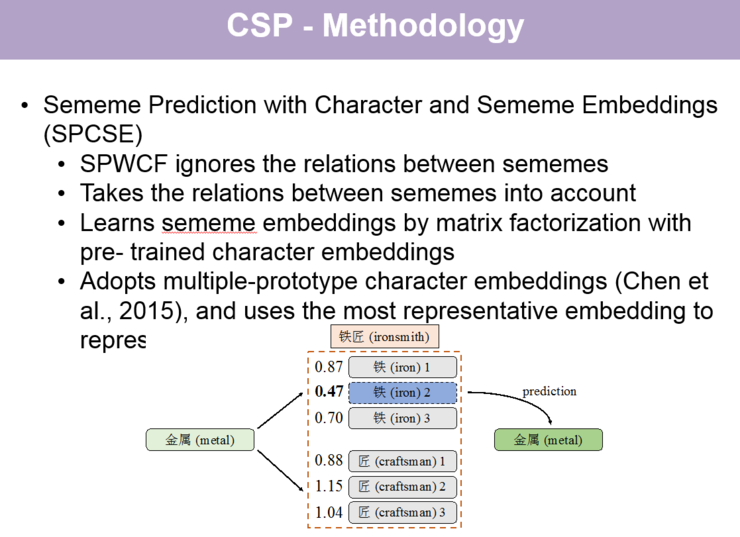
【关于 SPWCF 和 SPCSE 这两个义原预测方法的具体讲解,请回看视频 00:23:18 处,http://www.mooc.ai/open/course/555?=aitechtalkqifanchao】
下面讲一下实验,我们在这个实验中的设置有:
第一,义原筛选,去掉知网中出现频率低于 5 次的义原,剩余 1400 个比较常见的义原;
第二,选了知网中 6 万个高频词;
第三,训练集、开发集 和测试集分别为 48000、6000 和 6000;
第四,词向量和字向量的学习用的语料是 Sogou-T。
第五,用 GloVe 的方法学习词向量,用 2015 年的一篇文章 Cluster-based Character Embeddings 来学习字向量
第六,做义原预测评价的指标是 Mean Average Precision (MAP)
其他设置大家可以看一下论文进行了解。
实验结果如下:
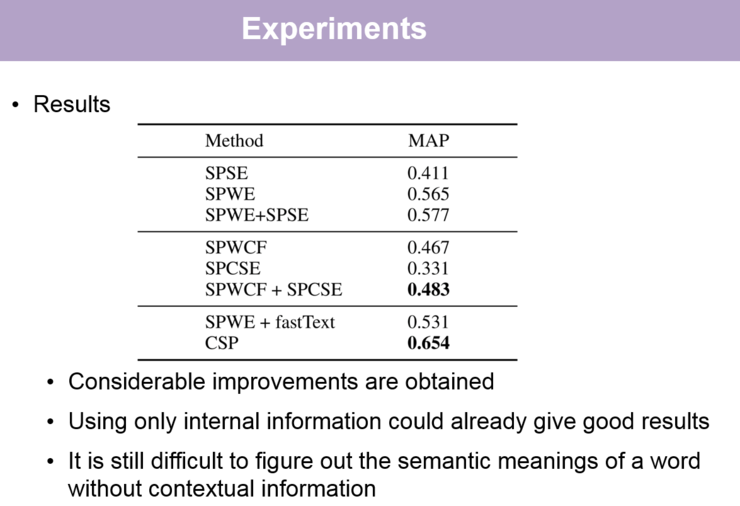
【关于实验结果的讲解,请回看视频 00:37:00 处,http://www.mooc.ai/open/course/555?=aitechtalkqifanchao】
这里对我们的这两个工作做一下小结:
首先,我们定义了义原预测任务并对该任务做了简化。
在第一篇文章中,我们用了推荐系统中两个基本、主流的思路——协同过滤和矩阵分解做义原预测。
在第二篇文章中,我们考虑到第一篇文章只使用了外部信息,而没有用词的内部信息,于是将词的内部信息用到了义原预测中。
我们将来的研究方向包括使用义原的结构,将义原扩展到更加通用性的应用,以及更充分地利用词的内部信息——因为第二个工作使用的方法还是相对比较简单。另外,我们的代码都开源在 Github(https://github.com/thunlp/sememe_prediction, https://github.com/thunlp/Character-enhanced-Sememe-Prediction )上了,大家可以去下载。
跨语言词汇的义原推荐 [EMNLP 2018]
接下来讲一下我们在跨语言义原预测方面所做的工作。这项工作的 motivation 是:大多数语言其实没有像知网这样的义原知识库。刚刚我们提到,义原的标注需要「专家」信息,往往需要耗费很大的时间和人力成本,因此我们想要利用机器学习方法自动进行跨语言义原预测。在这项工作中,我们方法的主要思路是,将现有的知网义原知识库迁移到其他语言。
由于跨语言的义原预测是一个全新的任务,对我们来说存在一些难度,比如直接将知网翻译成其他语言是行不通的,因为不同语言词的语义不完全一致。
我们在这个工作中采用的方法分为两个大模块:
第一个模块是双语词向量学习模块。其目标是学习在同一个语义空间的源语言和目标语言的词向量,其中源语言是指已知义原标注的语言,目标语言则是不知道义原标注的语言。该模块又可以分成三个子模块:单语词向量的学习、双语词向量的对齐以及将义原信息融入源语言词向量中,单语词向量学习采用了经典的 Skip-gram 方法;双语词向量对齐采用了种子词典作为跨语言信号,此外还借鉴了 Bilingual Lexicon Induction From Non-Parallel Data With Minimal Supervision 这篇文章中的匹配机制(Matching Mechanism);义原信息的融入子模块中,分别采用了基于近义词(即义原标注相近的词)词向量靠近的方法 CLSP-WR 和基于矩阵分解的方法 CLSP-SE。
第二个模块使目标语言的义原预测模块。

【关于这两大模块的具体讲解,请回看视频 00:42:05 处,http://www.mooc.ai/open/course/555?=aitechtalkqifanchao】
实验的数据集如下:
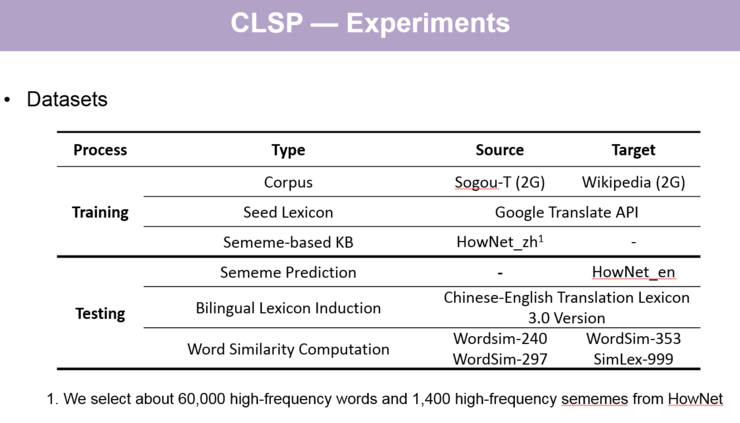
【关于实验数据集的讲解,请回看视频 00:52:20 处,http://www.mooc.ai/open/course/555?=aitechtalkqifanchao】
跨语言义原预测主实验结果:
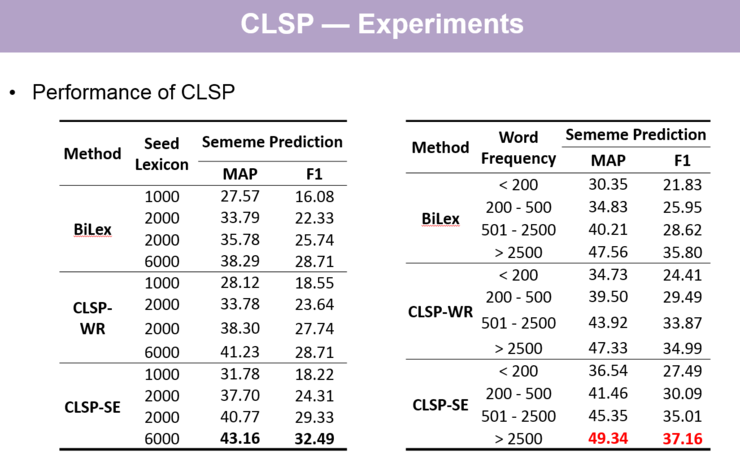
【关于跨语言义原预测主实验结果的讲解,请回看视频 00:54:15 处,http://www.mooc.ai/open/course/555?=aitechtalkqifanchao】
然后我们也做了两个子实验。第一个是做了双语词典翻译的实验,因为模型中第一个模块是学习在一个空间的双语词向量,很自然可以去做这样中译英、英译中的翻译实验。第二个子实验是单语词相似度计算的实验。从两项实验结果中可以看到,我们的模型比基线方法 BiLex 直接学习中文或英文的双语词向量的效果都要好一些。同时,这两个子实验的结果也可以解释我们的模型为什么能够预测到更好的的义原。
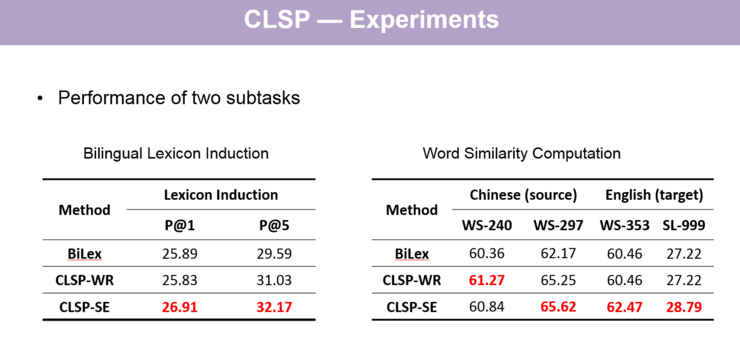
关于实验,有两个具体的案例:

【关于两个具体的案例的讲解,请回看视频 00:57:40 处,http://www.mooc.ai/open/course/555?=aitechtalkqifanchao】
最后总结一下,我们第三个工作也是定义了一个新的任务——为跨语言词做义原推荐,提出了基于双语词向量学习的方法,并通过实验证明了我们方法的有效性。
将来的工作中,第一,我们会考虑到词的多义性,这是在我们现在的工作中被忽略掉的一个方面;第二是将义原的结构信息利用起来;第三是在其他语言上做测试,我们这项工作是在英文上做测试,因为英文已有语言标注,而其他的语言则需要我们人工去做标注。我们工作的数据和代码都放在了 Github(https://github.com/thunlp/Character-enhanced-Sememe-Prediction )上,大家可以下载使用。
以上就是本期嘉宾的全部分享内容。更多公开课视频请到雷锋网(公众号:雷锋网) AI 研习社社区(https://club.leiphone.com/)观看。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。
















