第四章. Pandas进阶
4.2 数据格式化
1.设置小数位数(round函数)
DataFrame.round(decimals=0,*args,**kwargs)
参数说明:
decimals:用于设置保留的小数位数
args,kwargs:附加关键字的参数
返回值:返回DataFrame对象
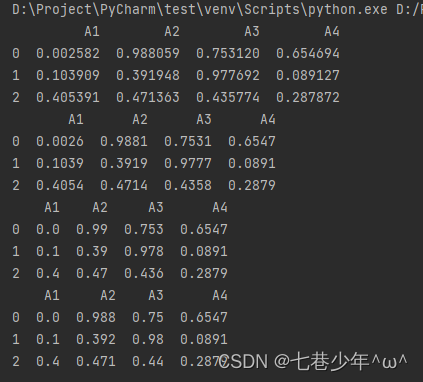
1).示例:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([3, 4]), columns=['A1', 'A2', 'A3', 'A4'])
print(df)
# decimals: int
df1 = df.round(4)
print(df1)
# decimals:dict[IndexLabel, int]
df1 = df.round({'A1': 1, 'A2': 2, 'A3': 3, 'A4': 4})
print(df1)
# Series
coeff=pd.Series(data=[1,3,2,4],index=['A1', 'A2', 'A3', 'A4'])
df1 = df.round(coeff)
print(df1)
结果展示:
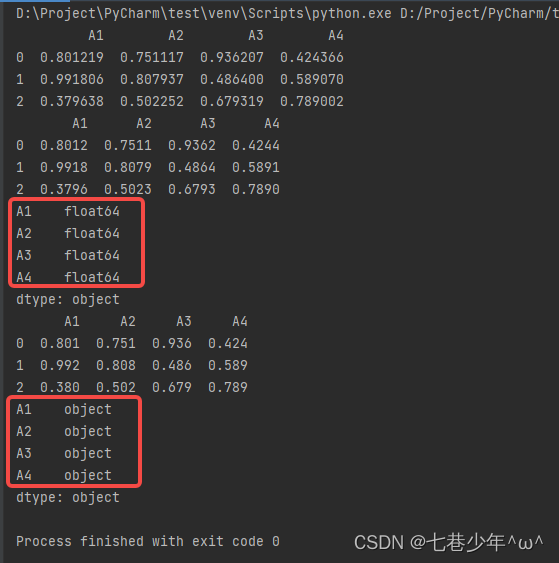
2).保留小数位数也可以使用自定义函数,但是需要注意处理后的数据是对象型数据,不在是浮点型数据,后续计算则需要先转换成浮点型
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([3, 4]), columns=['A1', 'A2', 'A3', 'A4'])
print(df)
# decimals: int
df1 = df.round(4)
print(df1)
print(df1.dtypes)
#自定义
df1 = df.applymap(lambda x:'%.3f'%x)
print(df1)
print(df1.dtypes)
结果展示:
2.设置百分比(apply+format函数):
DataFrame.mean([axis=0,skipna=1,level,...])
参数说明:
axis:轴,0:表示列 1:表示行,默认值:0
skipna:skipna=1:表示NaN值自动转换成0,skipna=0:表示NaN值不自动转换,默认为1
level:表示索引等级
返回值:返回Series对象或DataFrame对象,一组含有行列数据计算后的结果
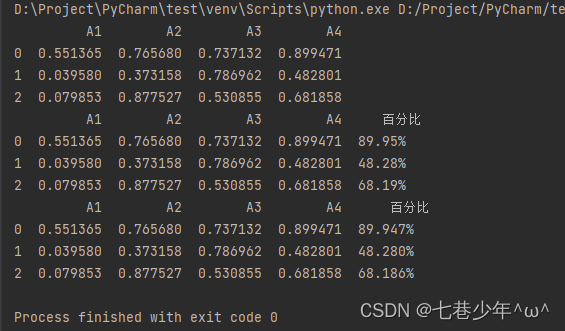
1).示例:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.random([3, 4]), columns=['A1', 'A2', 'A3', 'A4'])
print(df)
df['百分比'] = df["A4"].apply(lambda x: format(x, '.2%'))
print(df)
df['百分比'] = df["A4"].map(lambda x: '{:.3%}'.format(x))
print(df)
结果展示:
3.设置千位分隔符(apply+format函数):
DataFrame.max([axis=0,skipna=1,level,...])
参数说明:
axis:轴,0:表示列 1:表示行,默认值:0
skipna:skipna=1:表示NaN值自动转换成0,skipna=0:表示NaN值不自动转换,默认为1
level:表示索引等级
返回值:返回Series对象或DataFrame对象,一组含有行列数据计算后的结果
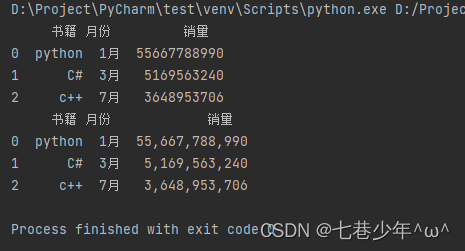
1).示例:
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
data = [['python', '1月', 55667788990], ['C#', '3月', 5169563240], ['c++', '7月', 3648953706]]
columns = ['书籍', '月份', '销量']
df = pd.DataFrame(data=data, columns=columns)
print(df)
df['销量'] = df['销量'].apply(lambda x: format(int(x), ','))
print(df)
结果展示:
注:设置千位分隔符后,不在是数值型,而是字符串,后续的计算需要转换成数值型会很麻烦,因此需慎用