288 LSTM神经网络输入输出究竟是怎样的?
@YJango,本题解析来源:https://www.zhihu.com/question/41949741
2017年1月4日文章Recurrent Layers——介绍
下面就解释为什么你会看到训练数据会是矩阵和张量
输入矩阵形状:(n_samples, dim_input)
输出矩阵形状:(n_samples, dim_output)
注:真正测试/训练的时候,网络的输入和输出就是向量而已。加入n_samples这个维度是为了可以实现一次训练多个样本,求出平均梯度来更新权重,这个叫做Mini-batch gradient descent。 如果n_samples等于1,那么这种更新方式叫做Stochastic Gradient Descent (SGD)。
Feedforward 的输入输出的本质都是单个向量。
- 常规Recurrent (RNN/LSTM/GRU) 输入和输出:张量
输入张量形状:(time_steps, n_samples, dim_input)
输出张量形状:(time_steps, n_samples, dim_output)
注:同样是保留了Mini-batch gradient descent的训练方式,但不同之处在于多了time step这个维度。
Recurrent 的任意时刻的输入的本质还是单个向量,只不过是将不同时刻的向量按顺序输入网络。所以你可能更愿意理解为一串向量 a sequence of vectors,或者是矩阵。
python代码表示预测的话:
-
-
-
#当前所累积的hidden_state,若是最初的vector,则hidden_state全为0
-
hidden_state=np.zeros((n_samples, dim_input))
-
-
#print(inputs.shape): (time_steps, n_samples, dim_input)
-
outputs = np.zeros((time_steps, n_samples, dim_output))
-
-
for i in
range(time_steps):
-
#输出当前时刻的output,同时更新当前已累积的hidden_state
-
outputs[i],hidden_state = RNN.predict(inputs[i],hidden_state)
-
#print(outputs.shape): (time_steps, n_samples, dim_output)
但需要注意的是,Recurrent nets的输出也可以是矩阵,而非三维张量,取决于你如何设计。
- 若想用一串序列去预测另一串序列,那么输入输出都是张量 (例如语音识别 或机器翻译 一个中文句子翻译成英文句子(一个单词算作一个向量),机器翻译还是个特例,因为两个序列的长短可能不同,要用到seq2seq;
- 若想用一串序列去预测一个值,那么输入是张量,输出是矩阵 (例如,情感分析就是用一串单词组成的句子去预测说话人的心情)
Feedforward 能做的是向量对向量的one-to-one mapping,
Recurrent 将其扩展到了序列对序列 sequence-to-sequence mapping.
但单个向量也可以视为长度为1的序列。所以有下图几种类型: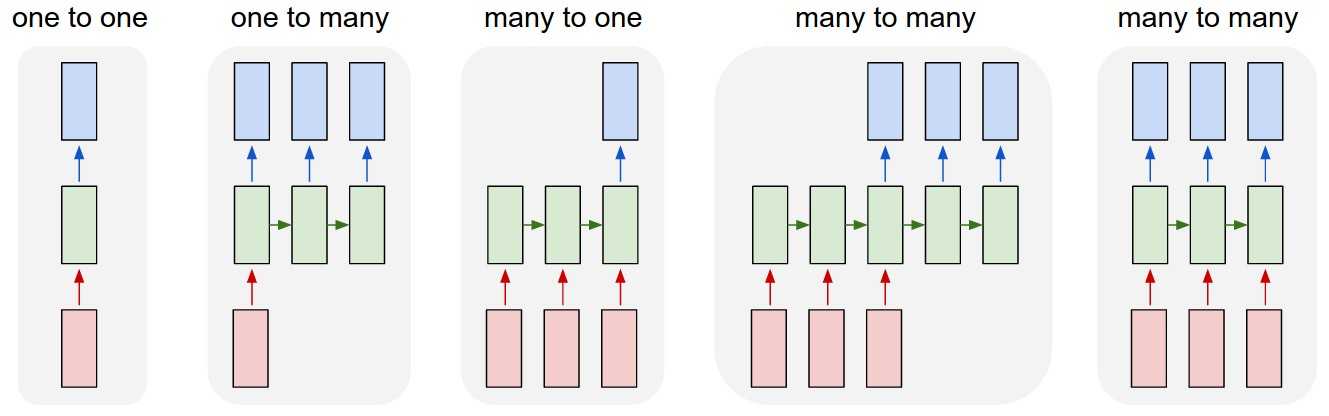
除了最左侧的one to one是feedforward 能做的,右侧都是Recurrent所扩展的
若还想知道更多
- 可以将Recurrent的横向操作视为累积已发生的事情,并且LSTM的memory cell机制会选择记忆或者忘记所累积的信息来预测某个时刻的输出。
- 以概率的视角理解的话:就是不断的conditioning on已发生的事情,以此不断缩小sample space
- RNN的思想是: current output不仅仅取决于current input,还取决于previous state;可以理解成current output是由current input和previous hidden state两个输入计算而出的。并且每次计算后都会有信息残留于previous hidden state中供下一次计算
289 以下关于PMF(概率质量函数),PDF(概率密度函数),CDF(累积分布函数)描述错误的是?
A.PDF描述的是连续型随机变量在特定取值区间的概率
B.CDF是PDF在特定区间上的积分
C.PMF描述的是离散型随机变量在特定取值点的概率
D.有一个分布的CDF函数H(x),则H(a)等于P(X<=a)
正确答案:A
解析:
概率质量函数 (probability mass function,PMF)是离散随机变量在各特定取值上的概率。
概率密度函数(p robability density function,PDF )是对 连续随机变量 定义的,本身不是概率,只有对连续随机变量的取值进行积分后才是概率。
累积分布函数(cumulative distribution function,CDF) 能完整描述一个实数随机变量X的概率分布,是概率密度函数的积分。
290 对于所有实数x 与pdf相对。线性回归的基本假设有哪些?(ABDE)
A.随机误差项是一个期望值为0的随机变量;
B.对于解释变量的所有观测值,随机误差项有相同的方差;
C.随机误差项彼此相关;
D.解释变量是确定性变量不是随机变量,与随机误差项之间相互独立;
E.随机误差项服从正态分布处理类别型特征时,事先不知道分类变量在测试集中的分布。要将 one-hot encoding(独热码)应用到类别型特征中。那么在训练集中将独热码应用到分类变量可能要面临的困难是什么?
A. 分类变量所有的类别没有全部出现在测试集中
B. 类别的频率分布在训练集和测试集是不同的
C. 训练集和测试集通常会有一样的分布
答案为:A、B ,如果类别在测试集中出现,但没有在训练集中出现,独热码将不能进行类别编码,这是主要困难。如果训练集和测试集的频率分布不相同,我们需要多加小心。
291 假定你在神经网络中的隐藏层中使用激活函数 X。在特定神经元给定任意输入,你会得到输出「-0.0001」。X 可能是以下哪一个激活函数?
A. ReLU
B. tanh
C. SIGMOID
D. 以上都不是
答案为:B,该激活函数可能是 tanh,因为该函数的取值范围是 (-1,1)。
292 下面哪些对「类型 1(Type-1)」和「类型 2(Type-2)」错误的描述是正确的?
A. 类型 1 通常称之为假正类,类型 2 通常称之为假负类。
B. 类型 2 通常称之为假正类,类型 1 通常称之为假负类。
C. 类型 1 错误通常在其是正确的情况下拒绝假设而出现。
答案为(A)和(C):在统计学假设测试中,I 类错误即错误地拒绝了正确的假设即假正类错误,II 类错误通常指错误地接受了错误的假设即假负类错误。
293 在下面的图像中,哪一个是多元共线(multi-collinear)特征?
A. 图 1 中的特征
B. 图 2 中的特征
C. 图 3 中的特征
D. 图 1、2 中的特征
E. 图 2、3 中的特征
F. 图 1、3 中的特征
答案为(D):在图 1 中,特征之间有高度正相关,图 2 中特征有高度负相关。所以这两个图的特征是多元共线特征。
鉴别了多元共线特征。那么下一步可能的操作是什么?
A. 移除两个共线变量B. 不移除两个变量,而是移除一个
C. 移除相关变量可能会导致信息损失,可以使用带罚项的回归模型(如 ridge 或 lasso regression)。
答案为(B)和(C):因为移除两个变量会损失一切信息,所以我们只能移除一个特征,或者也可以使用正则化算法(如 L1 和 L2)
294 给线性回归模型添加一个不重要的特征可能会造成?
A. 增加 R-square
B. 减少 R-square
答案为(A):在给特征空间添加了一个特征后,不论特征是重要还是不重要,R-square 通常会增加。
295 假定目标变量的类别非常不平衡,即主要类别占据了训练数据的 99%。现在你的模型在测试集上表现为 99% 的准确度。那么下面哪一项表述是正确的?
A. 准确度并不适合于衡量不平衡类别问题
B. 准确度适合于衡量不平衡类别问题
C. 精确率和召回率适合于衡量不平衡类别问题
D. 精确率和召回率不适合于衡量不平衡类别问题
答案为(A)和(C)
296 什么是偏差与方差?
泛化误差可以分解成偏差的平方加上方差加上噪声。偏差度量了学习算法的期望预测和真实结果的偏离程度,刻画了学习算法本身的拟合能力,方差度量了同样大小的训练集的变动所导致的学习性能的变化,刻画了数据扰动所造成的影响,噪声表达了当前任务上任何学习算法所能达到的期望泛化误差下界,刻画了问题本身的难度。偏差和方差一般称为bias和variance,一般训练程度越强,偏差越小,方差越大,泛化误差一般在中间有一个最小值,如果偏差较大,方差较小,此时一般称为欠拟合,而偏差较小,方差较大称为过拟合。偏差: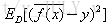 方差:
方差: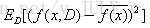
297 解决bias和Variance问题的方法是什么?交叉验证
High bias解决方案:Boosting、复杂模型(非线性模型、增加神经网络中的层)、更多特征
High Variance解决方案:agging、简化模型、降维
298 采用 EM 算法求解的模型有哪些,为什么不用牛顿法或梯度下降法?
用EM算法求解的模型一般有GMM或者协同过滤,k-means其实也属于EM。EM算法一定会收敛,但是可能收敛到局部最优。由于求和的项数将随着隐变量的数目指数上升,会给梯度计算带来麻烦。
xgboost怎么给特征评分?在训练的过程中,通过Gini指数选择分离点的特征,一个特征被选中的次数越多,那么该特征评分越高。[python] # feature importance
print(model.feature_importances_)
# plot pyplot.bar(range(len(model.feature_importances_)), model.feature_importances_)
pyplot.show() ==========
# plot feature importance
plot_importance(model)
pyplot.show()
299 什么是OOB?随机森林中OOB是如何计算的,它有什么优缺点?
bagging方法中Bootstrap每次约有1/3的样本不会出现在Bootstrap所采集的样本集合中,当然也就没有参加决策树的建立,把这1/3的数据称为袋外数据oob(out of bag),它可以用于取代测试集误差估计方法。
袋外数据(oob)误差的计算方法如下:
对于已经生成的随机森林,用袋外数据测试其性能,假设袋外数据总数为O,用这O个袋外数据作为输入,带进之前已经生成的随机森林分类器,分类器会给出O个数据相应的分类,因为这O条数据的类型是已知的,则用正确的分类与随机森林分类器的结果进行比较,统计随机森林分类器分类错误的数目,设为X,则袋外数据误差大小=X/O;这已经经过证明是无偏估计的,所以在随机森林算法中不需要再进行交叉验证或者单独的测试集来获取测试集误差的无偏估计。
300 假设张三的mp3里有1000首歌,现在希望设计一种随机算法来随机播放。与普通随机模式不同的是,张三希望每首歌被随机到的概率是与一首歌的豆瓣评分(0~10分)成正比的,如朴树的《平凡之路》评分为8.9分,逃跑计划的《夜空中最亮的星》评分为9.5分,则希望听《平凡之路》的概率与《夜空中最亮的星》的概率比为89:95。现在我们已知这1000首歌的豆瓣评分:(1)请设计一种随机算法来满足张三的需求。(2)写代码实现自己的算法。
#include <iostream>
#include <time.h>
#include <stdlib.h>
using namespace std;
int findIdx(double songs[],int n,double rnd){undefined
int left=0;
int right=n-1;
int mid;
while(left<=right){undefined
mid=(left+right)/2;
if((songs[mid-1]<=rnd) && (songs[mid]>=rnd))
return mid;
if(songs[mid]>rnd)
right=mid-1;
else
left=mid+1;
}
// return mid;
}
int randomPlaySong(double sum_scores[],int n){undefined
double mx=sum_scores[n-1];
double rnd= rand()*mx/(double)(RAND_MAX);
return findIdx(sum_scores,n,rnd);
}
int main()
{undefined
srand(time(0));
double scores[]={5.5,6.5,4.5,8.5,9.5,7.5,3.5,5.0,8.0,2.0};
int n=sizeof(scores)/sizeof(scores[0]);
double sum_scores[n];
sum_scores[0]=scores[0];
for(int i=1;i<n;i++)
sum_scores[i]=sum_scores[i-1]+scores[i];
cout<<"Calculate the probability of each song: "<<endl;
int totalScore=sum_scores[n-1];
for(int i=0;i<n;i++)
cout<<scores[i]/totalScore<<" ";
cout<<endl;
int counts[n];
for(int i=0;i<n;i++)
counts[i]=0;
int i=0;
int idx;
int MAX_ITER=100000000;
while(i<MAX_ITER){undefined
idx=randomPlaySong(sum_scores,n);
counts[idx]++;
i++;
}
cout<<"After simulation, probability of each song: "<<endl;
for(int i=0;i<n;i++)
cout<<1.0*counts[i]/MAX_ITER<<" ";
cout<<endl;
return 0;
}
301 对于logistic regession问题:prob(t|x)=1/(1+exp(w*x+b))且label y=0或1,请给出loss function和权重w的更新公式及推导。
Logistic regression 的loss function 是log loss, 公式表达为:
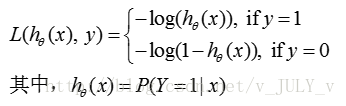
w的更新公式可以由最小化loss function得到,即: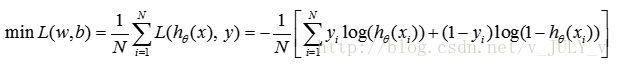
其中大括号里面的部分,等价于逻辑回归模型的对数似然函数,所以也可以用极大似然函数方法求解,根据梯度下降法,其更新公式为:
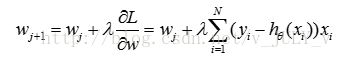
302 决策树的父节点和子节点的熵的大小关系是什么?
A. 决策树的父节点更大
B. 子节点的熵更大
C. 两者相等
D. 根据具体情况而定
正确答案:B。在特征选择时,应该给父节点信息增益最大的节点,而信息增益的计算为 IG(Y|X) = H(Y) - H(Y/X),H(Y/X) 为该特征节点的条件熵, H(Y/X) 越小,即该特征节点的属性对整体的信息表示越“单纯”,IG更大。 则该属性可以更好的分类。H(Y/X) 越大,属性越“紊乱”,IG越小,不适合作为分类属性。
303 欠拟合和过拟合的原因分别有哪些?如何避免?
欠拟合的原因:模型复杂度过低,不能很好的拟合所有的数据,训练误差大;
避免欠拟合:增加模型复杂度,如采用高阶模型(预测)或者引入更多特征(分类)等。
过拟合的原因:模型复杂度过高,训练数据过少,训练误差小,测试误差大;
避免过拟合:降低模型复杂度,如加上正则惩罚项,如L1,L2,增加训练数据等。
304 语言模型的参数估计经常使用MLE(最大似然估计)。面临的一个问题是没有出现的项概率为0,这样会导致语言模型的效果不好。为了解决这个问题,需要使用(A)
A. 平滑
B. 去噪
C. 随机插值
D. 增加白噪音
后记
熟悉我的朋友可能已经知道,我个人从 2010 年开始在CSDN写博客,写了十年,如今接近1700万PV,创业做「七月在线」则已五年,五年已30多万学员。这五年经历且看过很多的人和事,比如我们的机器学习集训营帮助了超过1000人就业、转型、提升,他们就业后有的同学会分享面经,当看到那一篇篇透露着面经作者本人的那股努力、那股不服输的劲的面经的时候,则让我倍感励志。比如“双非渣本三年 100 次面试经历精选:从最初 iOS 前端到转型面机器学习” 这篇面经,便让我印象非常深刻。在佩服主人公毅力和意志的同时,也对他愿意分享对众多人有着非常重要参考价值和借鉴意义的成功经验倍感欣慰。
- 科班,或非科班;
- 985、211,或双非院校;
- 研究生或本科,甚至大专;
- 学生,或在职;
- 至于传统IT转型 AI 的就更多了,有从 Java、PHP、C、C++等偏后端服务转型的,也有从 Android、iOS、前端等偏客户端开发转型的,当然也有数据分析、大数据方向等转型的。
但令人振奋的是,他们都转型成功了,而且他们中的很多人都通过集训营/就业班三个月到半年的学习,成功实现薪资翻倍——这些成功的经验就更值得借鉴了。
就业部的同事特地将这些宝贵的经验整理出来,希望可以帮到更多人。
限于篇幅,完整版可以扫码领取,添加时备注:领取面经100篇
