Abstract
人眼可以基于一些较小的显着区域来识别人的身份。然而,当使用现有方法计算图像的相似度时,通常会隐藏这种有价值的显着信息。此外,许多现有的方法学习区别性特征并以监督的方式处理急剧的视点变化,并要求为不同的摄像机视图对标注新的训练数据。在本文中,我们提出了一种基于无监督显着性学习的人员重新识别的新颖视角。在训练过程中无需识别标签即可提取出独特的特征。首先,我们应用邻接约束补丁匹配来建立图像对之间的密集对应,这显示了在处理由较大视点和姿势变化引起的未对准方面的有效性。其次,我们以无人监督的方式学习人类的显着性。为了提高人员重新识别的性能,将人的显着性纳入补丁匹配中,以找到可靠且有区别的匹配补丁。我们的方法的有效性在广泛使用的VIPeR数据集和ETHZ数据集上得到了验证。
1. Introduction
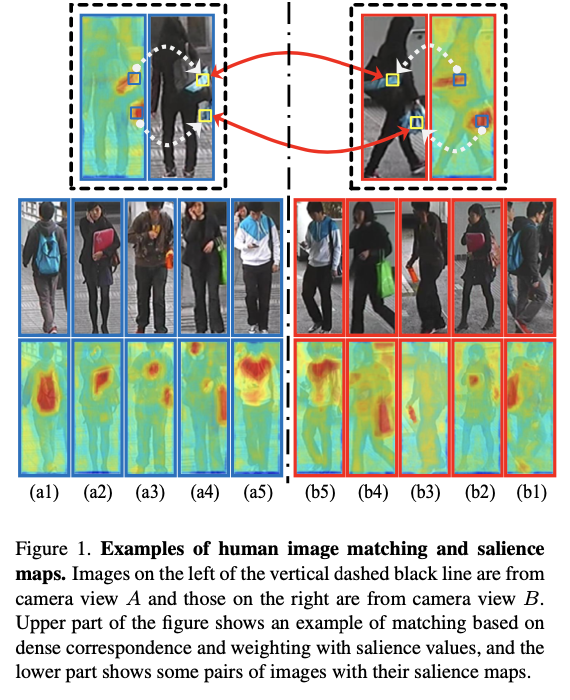
行人重识别可处理非重叠摄像机视图中的行人匹配和排列。 通过节省大量人力从大量视频序列中搜索人的工作量,它在视频监控中具有许多重要的应用。 但是,这也是一项非常具有挑战性的任务。 监控摄像头可以在一天之内观察数百名公共区域的行人,其中一些人的外表相似。 在不同的摄像机视图中观察到的同一个人通常在视点,姿势,摄像机设置,照明,遮挡和背景方面会发生显着变化,通常使不同视角下人的差异甚至比不同人差异更大,如图1所示。
我们的工作主要来自三个方面。 现有的大多数作品[25、15、8、29、16、24]通过采用监督模型来处理交叉视图变异问题并提取区分特征,监督模型需要带有身份标签的训练数据。 另外,由于不同的摄像机视图对的交叉视图转换不同,因此大多数摄像机在更改摄像机设置时都需要标记新的训练数据。 这在许多应用中是不切实际的,尤其是对于大型摄像机网络。 在本文中,我们提出了一种通过无监督学习来学习区分和可靠描述行人的新方法。 因此,它对一般摄像机视图设置具有更好的适应性。
在人物重新识别中,视点变化和姿势变化会导致图像之间不可控的不对齐。 例如,在图1中,图像(a1)的中心区域是相机视图A中的背包,而它变成相机视图B中图像(b1)中的手臂。因此,无法直接比较空间未对齐的特征向量。 在我们的方法中,应用补丁匹配来解决不对齐问题。 另外,基于对行人结构的先验知识,在补丁匹配中增加了一些约束条件,以提高匹配精度。 通过贴片匹配,我们可以将女士手提包上的蓝色倾斜条纹对准图1中黑色虚线框。
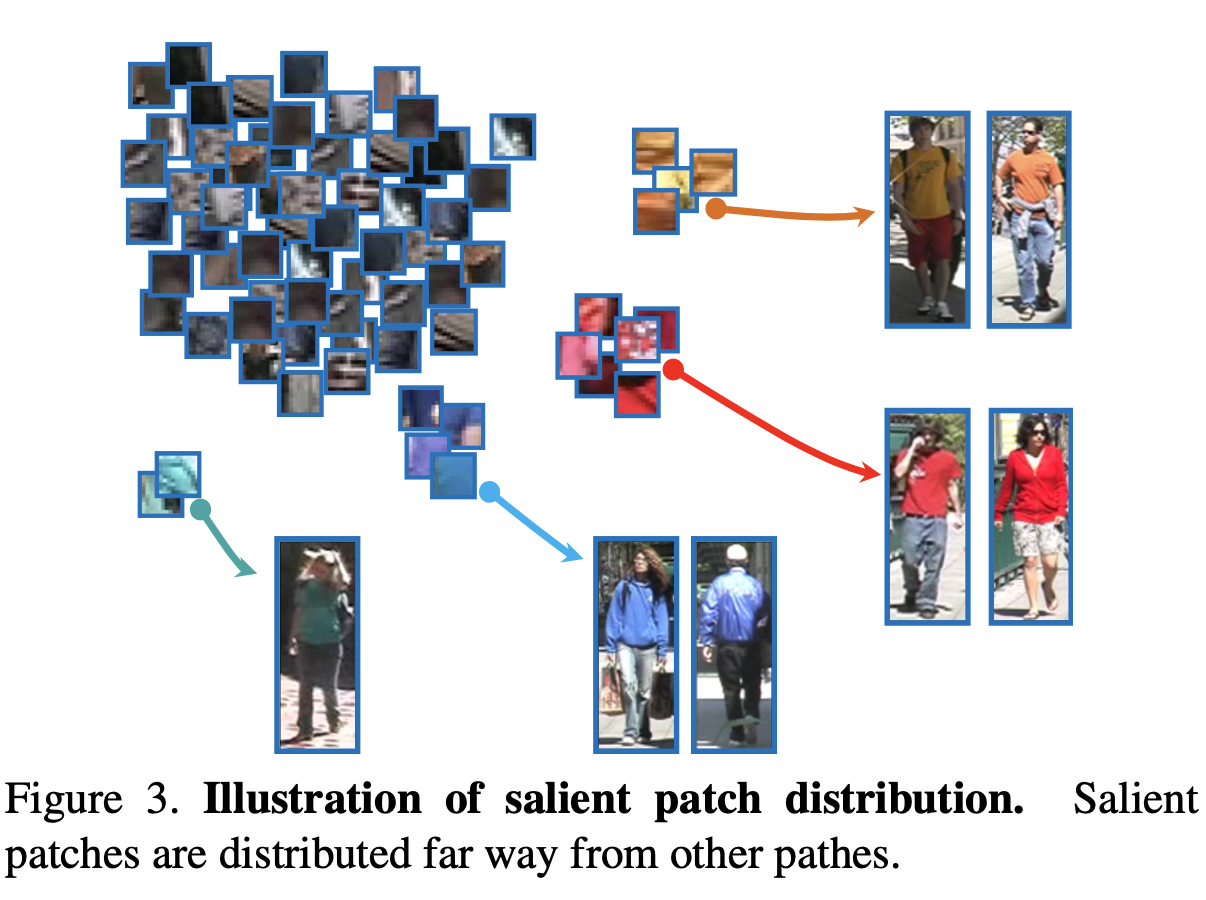
行人图像中的显着区域为识别提供了宝贵的信息。但是,如果尺寸较小,则在计算图像相似度时通常会隐藏显着性信息。在本文中,显着性意味着不同的特征:1)在使人从同伴中脱颖而出时是有区别的,2)在不同的观点中找到同一人是可靠的。例如,在图1中,如果数据集中的大多数人穿着相似的衣服和裤子,则很难识别它们。但是,人眼很容易识别匹配对,因为它们具有不同的特征,例如人(a1-b1)的背包带有倾斜的蓝色条纹,人(a2-b2)的手臂下有一个红色文件夹,人(a3-b3)的手中有一个红色的瓶子。这些独特的功能在区分一个人和其他人时具有区别性,并且可以在不同的相机视图之间进行匹配。凭直觉,如果一个摄像机视图中的身体部位是突出的,那么在另一摄像机视图中的身体部位也通常是突出的。此外,我们的显着性计算是基于与来自大型参考数据集而不是一小群人的图像的比较。因此,它在大多数情况下都非常稳定。但是,现有方法可能会将这些明显的特征视为要去除的遗留物,因为其中一些特征(例如行李或文件夹)不属于身体部位。衣服和裤子通常被认为是重新识别人身的最重要区域。在补丁匹配的辅助下,这些具有区别性和可靠性的功能已在本白皮书中用于人员重新识别。
本文的贡献可以概括为三个方面。首先,提出了一种无监督的框架来提取个性特征以供人员重新识别,而无需在训练过程中手动标记人员身份。其次,利用补丁匹配和邻接约束来处理由视点改变,姿势变化和打手势引起的错位问题。我们表明,受约束的补丁匹配极大地提高了人员重新识别的准确性,因为它可以灵活地处理较大的视点变化。第三,以无人监督的方式学习人类的显着性。与一般的图像显着性检测方法[4]不同,我们的显着性是专为人体匹配而设计的,具有以下特性。 1)对视点变化,姿势变化和清晰度具有鲁棒性。 2)仅当两个摄像机视图中的色块匹配且不同时,才将它们视为突出。 3)人的显着性本身是行人匹配的有用描述。例如,只有上身显着的人和只有下身显着的人必须具有不同的身份。
2. Related Work
3. Dense Correspondence
密集对应已应用于人脸和场景对齐[23,20]。 继承了基于零件和基于区域的方法的特征,细粒度的方法(包括像素级的光流,关键点特征匹配和局部面片匹配)通常是更好的选择,可以实现更可靠的对齐。 在我们的方法中,考虑到远场监视摄像机捕获的人像的中等分辨率,我们采用中级本地补丁来匹配人员。 为了确保匹配的鲁棒性,在每个图像中都对局部斑块进行了密集采样。 与一般的补丁匹配方法不同,对匹配的补丁搜索施加了一个简单但有效的水平约束,这使得补丁匹配在人的重新识别方面更具适应性。
mid-level local patches
a simple but effective horizontal constraint is imposed on searching matched patches
3.1. Feature Extraction
Dense Color Histogram
每个人的图像被密集地分割成局部补丁的网格。 从每个色标中提取一个LAB颜色直方图。 为了可靠地捕获颜色信息,还应在降采样后的比例上计算LAB颜色直方图。 为了与其他功能组合,将所有直方图进行L2归一化。
LAB color histograms
Dense SIFT
为了处理视点和照明变化,SIFT描述符用作颜色直方图的补充功能。 与提取密集的颜色直方图的设置相同,在每个人的图像上采样密集的补丁网格。 我们将每个面片划分为4×4个单元,将局部梯度的方向量化为8个面元,并获得4×4×8 = 128的三维SIFT特征。 SIFT特征也经过L2标准化。
密集的颜色直方图和密集的SIFT特征被组合为每个补丁的最终多维描述符向量。 在我们的实验中,特征提取的参数如下:在网格步长为4的密集网格上采样大小为10×10像素的小块; 分别在L,A,B通道中计算32-bin彩色直方图,在每个通道中,使用3个级别的下采样,比例因子分别为0.5、0.75和1。 还从3个颜色通道中提取SIFT特征,从而为每个色标生成128×3特征向量。 总之,每个补丁最终都由长度为32×3×3 + 128×3 = 672的判别描述符向量表示。我们将组合特征向量表示为dColorSIFT。
3.2. Adjacency Constrained Search
X表示相机A,m,n表示图像p的第m行,第n列。下面这个式子是相机A拍摄的图像p中第m行第集合。
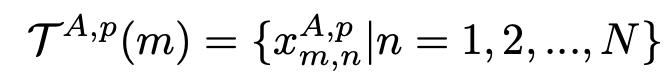
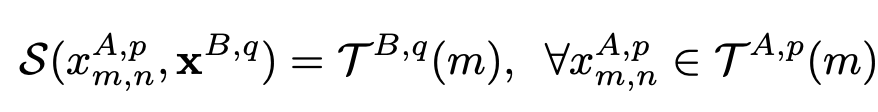
搜索集是B相机拍摄的图像q,将搜索集限制在了第m行。然而,bounding boxes并不总是对齐的。因此设置了一个搜索集行的浮动范围。
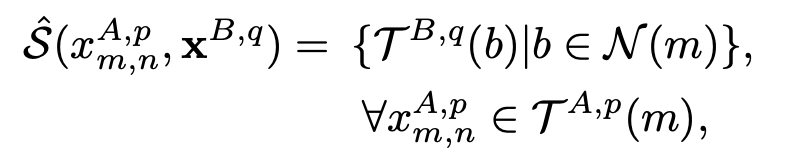
Adjacency Searching

patch matching是计算机视觉比较成熟的技术。作者使用的是KNN,根据欧式距离返回最近的邻居。aggregaing similarity scores比minimizing accumulated distances效率更好。通过转换为相似度,它们的效果可能会降低。
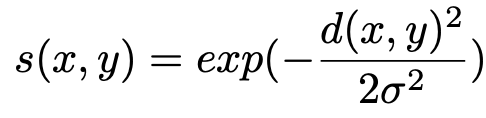
4. Unsupervised Salience Learning
通过密集的通信,我们可以在无监督的方法下学习人类的显着性。 在本文中,我们提出了两种学习人类显着性的方法:K最近邻(KNN)和一类SVM(OCSVM)。
4.1. K-Nearest Neighbor Salience
拜尔斯等发现KNN距离可用于去除杂波。 为了将KNN距离应用于行人重识别,我们在dense correspon的输出集中搜索测试补丁的K最近邻。 通过这种策略,显着性更适合于重新识别问题。 遵循异常检测和显着性检测的共同目标,我们在任务中重新定义了显着补丁,如下所示:
Salience for person re-identification
显着补丁是那些在特定集合中具有唯一性的补丁。

这个集合里包括的是Nr张参考图像中每个与test patch最相似的。
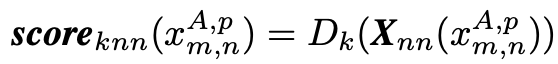
其中Dk表示第k近的邻居的距离,这里Dk引用论文5的计算方法。如果参考集的分布很好地反映了测试场景,则显着补丁只能找到有限数量的视觉相似邻居。
0 <α<1是一个比例参数,反映了我们对显着斑块统计分布的期望。 由于k取决于参考集的大小,因此即使参考大小很大,定义的显着性分数也可以很好地发挥作用。
Choosing the Value of k
对人员进行重新识别的显着检测的目标是识别具有独特外观的人员。我们假设,如果一个人的外观如此独特,则参考集中超过一半的人与他/她不相似。通过这种假设,我们的实验中使用了k = Nr / 2。为了寻求一种更原则的计算人类显着性的方法,将在第4.2节中讨论一类SVM显着性。
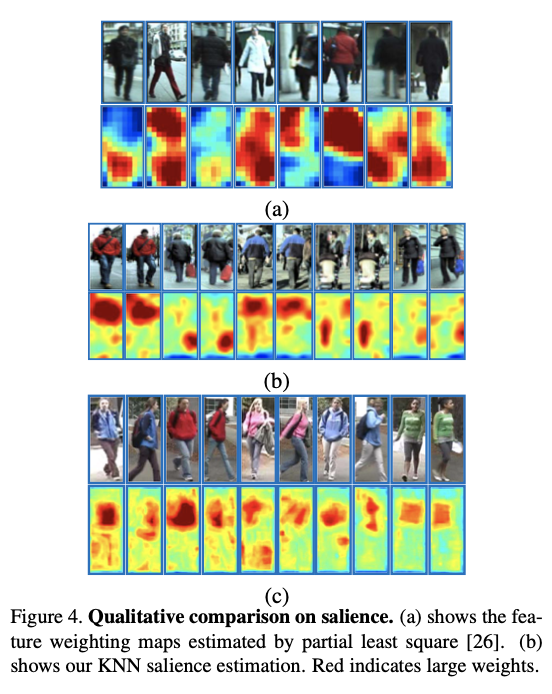
为了与复杂的监督学习方法进行定性比较,图4(a)显示了由偏最小二乘(PLS)估计的特征权重图[26]。 PLS用于减小尺寸,并且第一投影矢量的权重显示为每个块中特征权重的平均值。我们的无监督KNN显着性结果显示在ETHZ数据集的图4(b)和VIPeR数据集的图4(c)中。显着性分数分配给补丁的中心,显着性贴图经过上采样以获得更好的可视化效果。我们的无监督学习方法可以更好地捕获显着区域。
4.2. One-class SVM Salience
一类SVM [14]已被广泛用于离群值检测。 在训练中仅使用阳性样本。 一类SVM的基本思想是使用超球在特征空间中描述数据,并将大多数数据放入超球中。 该问题被归纳为目标函数,如下所示:
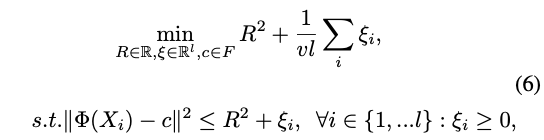
优化目标函数的目的是使超球面尽可能小,并包括大多数训练数据。 可以通过QP优化方法以双重形式解决优化问题[6],决策函数为:
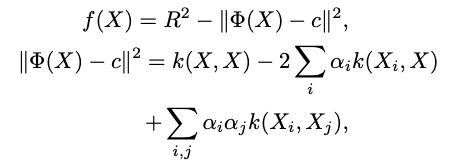
其中αi和αj是对偶问题中每个约束的参数。 在我们的任务中,我们使用半径基函数(RBF)K(X,Y)= exp {-∥X-Y∥2/2σ2} 作为kernel在一类SVM中处理高维,非线性, 多模式分布。 如图[6]所示,一类内核支持向量机的决策函数可以很好地捕获特征分布的密度和模态。 为了以非参数形式近似KNN显着性算法(第4.1节),根据内核一类SVM决策函数重新定义了决策函数:
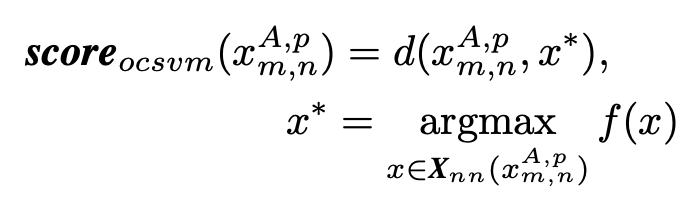
其中d是面片要素之间的欧式距离。 其中xA,p和xB,q是两个图像中补丁特征的集合,即xA,p = {xA,p}和xB,q =我们的实验显示,在两种显着性检测方法的人重新识别中,结果非常相似 。 在某些情况下,scoreocsvm的性能略好于scoreknn。
5. Matching for re-identification
5.1. Bi-directional Weighted Matching
设计了双向加权匹配机制,以将显着性信息合并到密集的对应匹配中。首先,我们考虑一对图像之间的匹配。然后,在图库中搜索最匹配的图像可以公式化为找到最大相似度得分。
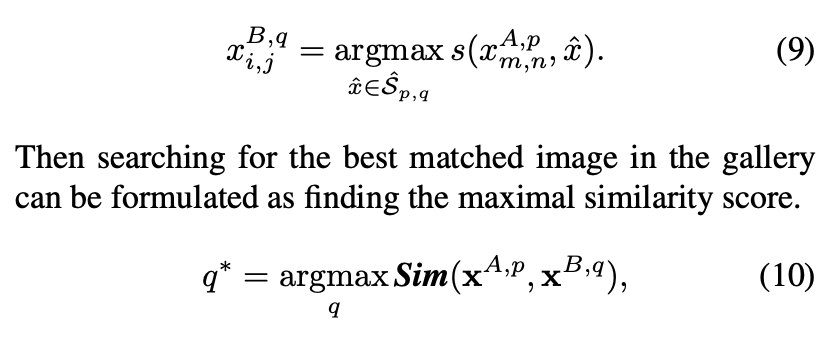
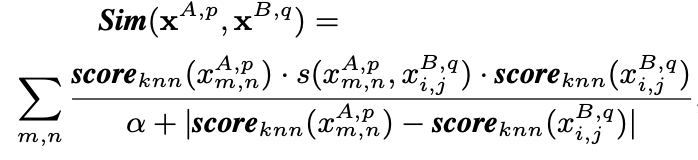
其中xA,p和xB,q是两张图片的patch特征集合。

5.2. Combination with existing approaches
我们的方法是对现有方法的补充。 为了将现有方法的相似性得分与等式中的相似性得分相结合。 (11),两个图像之间的距离可以计算如下:
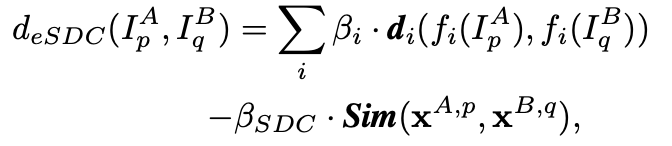
其中βi(> 0)是第i个距离度量的权重,而βSDC(> 0)是我们的方法的权重。 di和fi对应于[10]中的距离度量和特征(wHSV和MSCR)。 在实验中,{βi}的选择与[10]中的相同。 βSDC固定为1。
6. Experiments
我们在两个公开可用的数据集VIPeR数据集[12]和ETHZ数据集[26]上评估了我们的方法。 这两个数据集被最广泛地用于评估,并反映了现实世界中的人员重新识别应用程序中的大多数挑战,例如,视点,姿势和照明变化,低分辨率,背景杂波和遮挡。 结果显示在标准的“累积匹配特性”(CMC)曲线中[27]。 提供了与基于最新功能的方法的比较,并且我们还展示了与一些经典度量学习算法的比较。
VIPeR Dataset
VIPeR数据集1是在室外学术环境中由两台摄像机捕获的,每个人都有两张从不同角度观看的图像。它是最具挑战性的人员重新识别数据集之一,该数据集的视点发生显着变化,姿势变化以及两个相机视图之间的照明差异很大。它包含632对行人,每对包含从不同视点看到的同一个人的两幅图像,一个来自CAM A,另一个来自CAMB。所有图像均被标准化为128×48。 CAM A主要从0度到90度捕获图像,而CAM B主要从90度到180度捕获图像,并且大多数图像对显示的视点变化大于90度。
按照[13]中的评估协议,我们随机抽取一半的数据集,即316个图像对,进行训练(但是,不使用身份信息),并进行测试。在第一轮中,将来自CAM A的图像用作探针,并将来自CAM B的图像用作图库。每个探针图像都与每个图库图像匹配,并获得正确匹配的等级。等级k识别率是对等级k的匹配的期望,而CMC曲线是所有等级的识别率的累积值。在这一轮之后,探针和通道被切换。我们将一次试验的结果作为两轮CMC曲线的平均值。重复进行10次评估试验以获得稳定的统计数据,并报告平均结果。
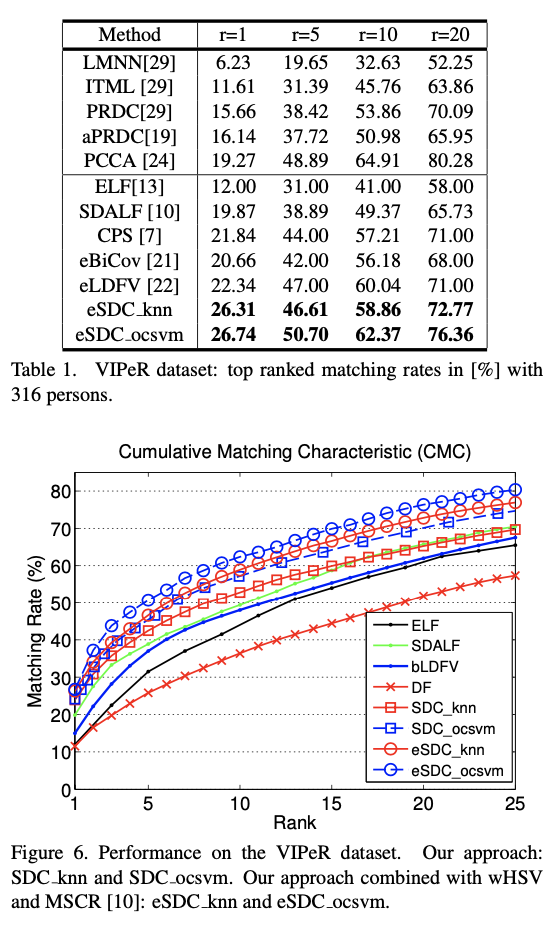
由于ELF [13],SDALF [10]和LDFV [22]已将其结果发布在VIPeR数据集上,因此将它们用于比较。这些方法中的分配分配2用于我们的实验中。图6报告了比较结果。可以看出,我们基于两种显着性检测的方法(SDC knn和SDC ocsvm)优于所有这三种基准测试方法。特别是,排名第一的匹配率对于SDC knn约为24%,对于SDC ocsvm为25%,而SDALF为20%,LDFV为15%,ELF为12%。对于SDC knn,排名10的匹配率约为52%,对于SDC ocsvm,匹配率约为56%,而SDALF的匹配率为49%,LDFV的匹配率为48%,ELF的匹配率为44%。改进归因于我们方法的两个方面。首先,密集的对应匹配可以容忍更大程度的姿势和外观变化。其次,我们结合人类显着性信息来指导密集的对应关系。通过与其他描述符的组合,eSDC knn的等级1匹配率达到26.31%,eSDC ocsvm达到26.74%。这显示了我们的SDC方法与其他功能的互补性。表1中显示了更多的比较结果。比较的方法包括经典的度量学习方法,例如LMNN [29]和ITML [29],以及为个人重新识别而修改的变体,例如PRDC [29],属性PRDC(表示为aPRDC)[19]和PCCA [24]。
ETHZ Dataset
该数据集3包含从移动摄像机捕获的三个视频序列。 它包含许多处于不受控制状态的不同人。 有了这些视频序列,Schwartz等人。 [26]为每个人提取了一组图像,以测试他们的偏最小二乘方法。 由于原始视频序列是从移动的摄像机捕获的,因此图像在人的外观和照明方面都有一定范围的变化,甚至有些图像受严重遮挡的影响。 按照[26]中的设置,所有图像样本均被标准化为64×32像素,并且数据集的结构如下:SEQ。#1包含83个人(4,857张图像); SEQ。#2包含35个人(1,936张图像); SEQ。#3包含28个人(共1,762张图片)。
复制[10,26]中相同的实验设置以进行合理的比较。 与它们类似,我们使用单次评估策略。 对于每个人,随机选择一个图像来构建画廊集,而其余图像形成探针集。 探针中的每个图像都与每个图库图像匹配,并获得正确的匹配等级。 重复整个过程10次,平均CMC曲线如图7所示。
如图7所示,我们的方法在所有三个序列上均优于三种基准测试方法,即PLS,SDALF和eBiCov [21]。 表2中列出了与监督学习方法PLS和RPLM的比较。在SEQ。#2和SEQ。#3上,我们的eSDC knn和eSDC ocsvm优于所有其他方法。 在SEQ。#1上,我们的SDC方法比受监督的方法PLS和RPLM具有更好的结果,并且与最近提出的eLDFV具有可比的性能[22]。
7. Conclusion
在这项工作中,我们提出了一种用于对人员进行重新识别的,具有显着性检测功能的无监督框架。 补丁匹配与邻接约束一起用于处理视点和姿势变化。 它在跨较大视点变化进行匹配时显示出极大的灵活性。 无监督地学习了人的显着性,以寻求具有区别性和可靠性的补丁匹配。 实验表明,我们的无监督显着性学习方法极大地提高了人员重新识别的性能。
总结
实现思路
这套无监督的行人重定位方法首先进行Dense Correspondence,或者说分别进行特征提取和邻接约束搜索。
特征提取将图像分割成小块,对每个小块提取LAB color histogram,并进行L2正则化。为了应对视角和光照的改变,还使用了SIFT描述子作为补充,将每个patch分割为4✖️4的cell,量化到8个bins里,形成4 ✖️ 4 ✖️ 8 = 128维的SIFT特征,同样经过了L2正则化,两者最终合并为32 ✖️ 3 ✖️ 3 + 128 ✖️ 3 = 672维的特征,称为dColorSIFT。
得到特征以后进行邻接约束搜索,在一定行索引弹性变动的情况下将另一个机位的某一行作为搜索集合,搜索过程采similarity score,由欧式距离计算得到。
然后便可以进行无监督的显著性学习。一个是基于KNN的显著性学习,一个是基于一类SVM的显著性学习。前者在每张图片中搜索similarity score最大的patch,构成一个集合,在这个集合中计算KNN距离,选取k个最接近的。后者的方法核心思想是使用一个超球来描述特征空间中的数据,并将大部分的数据放进去。问题在于使超球尽可能的校并且包括大多数的训练数据,可以通过QP优化方法解决。本文使用RBF作为一类SVM的kernel来处理高维度、非线性和多模式分布。
Dense correspondence和salience可以用于下面的具体行人重识别过程。首先在搜索集合中找到相似度最大的patch进行对应,然后寻找最匹配的图像就可以转换为下面的公示:
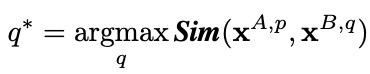
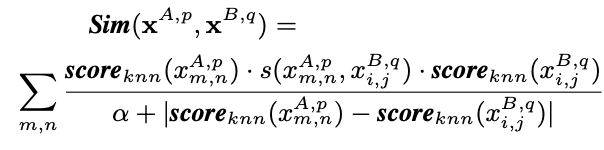
为了与现有方法合并,也可以使用下面的公式得到距离。

核心贡献与步骤创新
首先,提出了一种无监督的框架来提取个性特征以供人员重新识别,而无需在训练过程中手动标记人员身份。其次,利用补丁匹配和邻接约束来处理由视点改变,姿势变化等引起的错位问题。我们表明,受约束的补丁匹配极大地提高了人员重新识别的准确性,因为它可以灵活地处理较大的视点变化。第三,以无人监督的方式学习人类的显着性。与一般的图像显着性检测方法[4]不同,我们的显着性是专为人体匹配而设计的,具有以下特性。 1)对视点变化,姿势变化和清晰度具有鲁棒性。 2)仅当两个摄像机视图中的色块匹配且不同时,才将它们视为突出。 3)人的显着性本身是行人匹配的有用描述。例如,只有上身显着的人和只有下身显着的人必须具有不同的身份。
因为缺乏对这个领域的了解,所以这里理解的不是很深入。感觉上来说,首先作者构建了一套非监督学习的框架,采用patch match技术并采用约束。其设计了一个效果很好的特征,然后通过knn与svm等机器学习方式来进行分类。感觉和行人检测hog+svm由很多相似之处。如果是无监督的一般不好用cnn去自动提取特征,所以比较依赖特征的设计。然后就是设计了score来进行匹配,分类器只是个工具,核心还是相似度的评判标准。
实验目的
检索出不同摄像头下的相同行人图片。
衡量指标
衡量指标主要是匹配率。
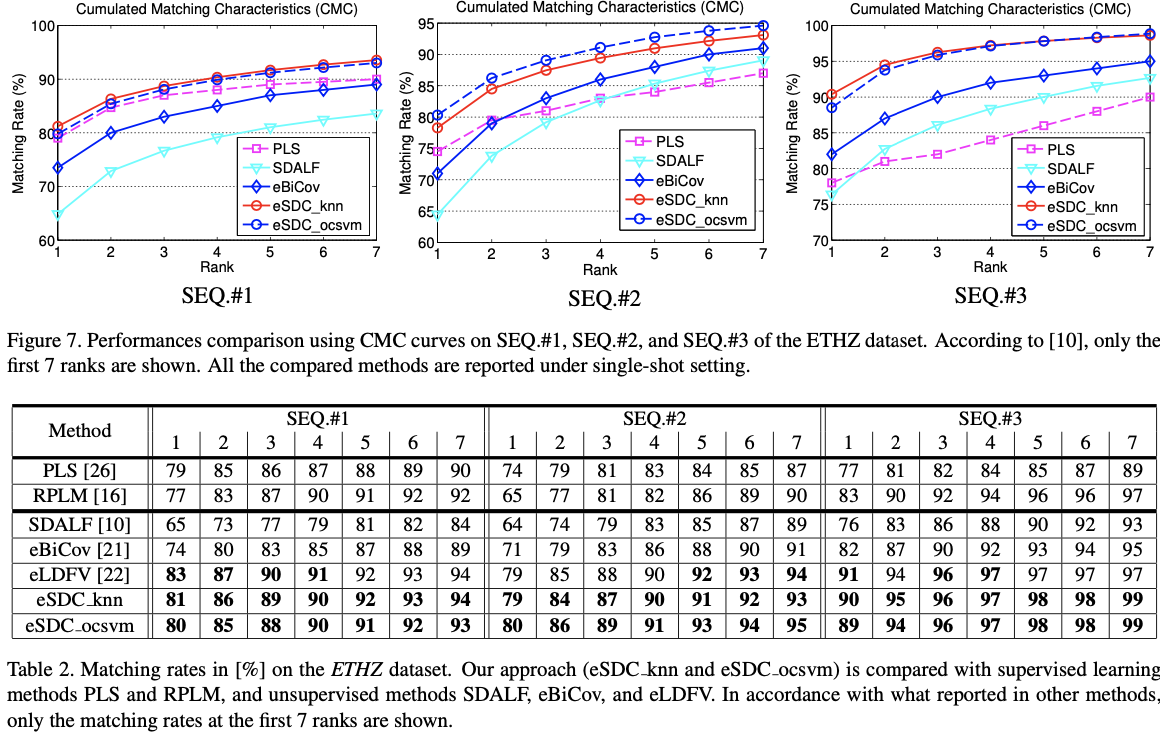
实验设计
实验设计方面主要包括各个rank下的匹配率对比、VIPeR和ETHZ上的对比、作者的方法与其他方法结合以及别人方法的对比、ETHZ还有它的三个seq的对比。
改进方案
(如有新的想法,后续更新
改进方案还是要从其基本步骤出发,包括特征表示与提取、邻接约束搜索、显著性学习。
首先对于不同摄像机位下可能存在一些色彩偏差,可以考虑能不能矫正。然后KNN还是有改进的余地,在不改变核心方法的情况下这些细节的调整应该也能小幅度提高效果。另外我不太明白为什么非要在同一行寻找,可以增大搜索范围。
另外,跳出作者的方法还可以考虑构建一个机位关系。一定的时间内,相邻的机位更有可能出现同一个人。